LRU算法和LFU算法
文章目录
- 1、LRU算法
- 2、LFU算法
1、LRU算法
LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。该算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 t,当须淘汰一个页面时,选择现有页面中其 t 值最大的,即最近最少使用的页面予以淘汰。
简单的 LRU 算法的实现思路是这样的:
- 采用链表实现LRU算法,头部节点表示最近访问的节点,而尾部节点表示最近最久没有访问的节点。
- 当访问的的key所对应的节点在LRU链表中,就直接把该链表节点移动到链表的头部。
- 当访问的的key所对应的节点不在LRU链表中,就构建一个新的节点,放入到 LRU 链表的头部,如果LRU链表的大小超过一个阈值,还要淘汰 LRU 链表末尾的节点。
比如下图,假设 LRU 链表长度为 5,LRU 链表从左到右有 1,2,3,4,5。

如果访问了 3 ,因为 3 LRU链表中,所以把 3 移动到头部即可。
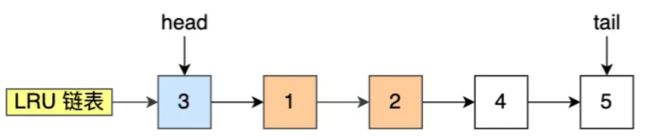
而如果接下来,访问了 8,因为 8 不在LRU链表中 ,所以需要先淘汰末尾的 5,然后再将 8 加入到头部。

LeetCode原题:460. LFU 缓存

class LRUCache {
public:
LRUCache(int capacity)
:cap(capacity)
{}
int get(int key)
{
if(map.find(key) == map.end()) return -1; //在map中找不到就返回-1
auto key_value = *map[key];//找到了,获取对应的key_val
cache.erase(map[key]);//将cache对应key_val的删除
cache.push_front(key_value);//将key_val插入到lru头部
map[key] = cache.begin();//更新映射
return key_value.second;
}
void put(int key, int value)
{
if(map.find(key) == map.end())
{
if(cache.size() == cap)//map中没有key,但容量满了,需要删除lru链表的最后一个元素,同时将map的映射删除
{
map.erase(cache.back().first);
cache.pop_back();
}
}
else
{
cache.erase(map[key]);//map中有key,则删除cache中的key_val,并把它插入到lru头部
}
cache.push_front({key, value});
map[key] = cache.begin();//更新映射
}
int cap;
list<pair<int, int>> cache;//lru链表
unordered_map<int, list<pair<int, int>>::iterator> map;//用于表示key_val是否存在,并指向lru链表中的具体位置
};
2、LFU算法
LFU是Least Frequently Used的缩写,即最近最不经常使用。择最近使用次数最少的页面予以淘汰。
对于每个节点,都需要维护其使用次数 count、最近使用时间 time。
cache容量为n,即最多存储n个节点。
那么当我需要插入新节点并且cache已经满了的时候,需要删除一个之前的节点。删除的策略是:优先删除使用次数count最小的那个节点,因为它最近最不经常使用,所以删除它。如果使用次数count最小值为min_cnt,这个min_cnt对应的节点有多个,那么在这些节点中删除最近使用时间time最早的那个节点(举个栗子:a资源和b资源都使用了两次,但a资源在5s的时候最后一次使用,b资源在7s的时候最后一次使用,那么删除a,因为b资源更晚被使用,所以b资源相比a资源来说,更有理由继续被使用,即时间局部性原理)。
可以采用哈希表+集合,集合负责对节点进行排序,哈希表则能在O(1)时间内查找key对应的节点。
LeetCode原题:460. LFU 缓存

class Node
{
public:
int count, time, key, value;
Node(int _count, int _time, int _key, int _value)
:count(_count)
,time(_time)
,key(_key)
,value(_value)
{}
//重载小于
bool operator<(const Node& node) const
{
return count == node.count ? time < node.time : count < node.count;
}
};
class LFUCache {
public:
//容量和时间戳
int capacity, time;
unordered_map<int, set<Node>::iterator> keyTable;
set<Node> S;
LFUCache(int _capacity)
:capacity(_capacity)
,time(0)
{
keyTable.clear();
S.clear();
}
int get(int key)
{
//如果LFUCache为0
if(capacity == 0)
{
return -1;
}
//哈希表没有对应的key-val
auto it = keyTable.find(key);
if(it == keyTable.end())
{
return -1;
}
//从哈希表中获得旧的缓存
Node cache = *(it->second);
S.erase(cache);
//更新旧缓存
cache.count += 1;
cache.time = ++time;
//将缓存从新放入到哈希表和set中
S.insert(cache);
it->second = S.find(cache);
return cache.value;
}
void put(int key, int value)
{
if(capacity == 0)
{
return;
}
auto it = keyTable.find(key);
//哈希表没有对应的key-val
if(it == keyTable.end())
{
//如果达到缓存容量上限
if(keyTable.size() == capacity)
{
//从哈希表和set中删除最近最少使用的缓存
keyTable.erase(S.begin()->key);
S.erase(S.begin());
}
//创建新缓存
Node cache = Node(1, ++time, key, value);
//将新缓存加入到哈希表和set中
S.insert(cache);
keyTable[cache.key] = S.find(cache);
}
else
{
//从哈希表中获得旧的缓存
Node cache = *(it->second);
S.erase(cache);
//更新旧缓存
cache.count += 1;
cache.time = ++time;
cache.value = value;
//将缓存从新放入到哈希表和set中
S.insert(cache);
it->second = S.find(cache);
}
}
};