小白python爬虫入门实例2—— 翻页爬取京东商城商品数据
通过分析京东的网址,寻找翻页时网址的变化规律,从而获取需要用到的数据。在这里我将展示在京东商城爬取书包的价格以及其商品全称,如果觉得这篇文章ok的亲们,可以换个网站,用淘宝如法炮制,祝您成功!
一、源代码
import requests
from bs4 import BeautifulSoup
def getText(url):
try:
kv = {'user-agent': 'Mozilla/5.0'}
r = requests.get(url, headers=kv,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def parsePage(ilt , html):
soup = BeautifulSoup(html,"html.parser")
plt = soup.find_all('div',class_='p-price') #价钱所在的div的class标签为“p-price"
tlt = soup.find_all('div',class_='p-name') #价钱所在的div的class标签为“p-name p-name-type-2"
for i in range(len(plt)):
price = plt[i]('i')
title = tlt[i]('em')
ilt.append([price[0].get_text(),title[0].get_text()])
def printGoodsList(ilt):
print("{:^4}\t{:^8}\t{:^16}".format("序号","价格","商品名称"))
count = 0
for g in ilt:
count += 1
print("{:^4}\t{:^8}\t{:^16}".format(count,g[0],g[1]))
def main():
goods = input("请输入商品名称:")
depth = 2
start_url = "https://search.jd.com/Search?keyword=" + goods
infoList = []
for i in range(depth):
url = start_url + '&page=' + str(2 * i - 1)
html = getText(url)
parsePage(infoList, html)
printGoodsList(infoList)
main()测试代码
##测试
goods = input("请输入商品名称:")
kv = {'user-agent': 'Mozilla/5.0'}
dept = 2
url = "https://search.jd.com/Search?keyword=" + goods
info = []
for i in range(dept):
url1 = url + '&page=' + str(2 * i - 1)
r = requests.get(url1, headers=kv)
print(r.status_code)
r.encoding = r.apparent_encoding
html = r.text
soup = BeautifulSoup(html, "html.parser")
plt = soup.find_all('div', class_='p-price')
nlt = soup.find_all('div', class_='p-name')
for j in range(len(plt)):
price = plt[j]('i')
name = nlt[j]('em')
info.append([price[0].get_text(),name[0].get_text()])
print(info[j])二、函数解析
1、getText(url):以目标网页作为参数,获取网页文本内容并返回。
url:为传入函数的目标网址;
“try... except...":为了防止长时间无法响应网站而死机,设置响应时间为30秒;
def getText(url):
try:
kv = {'user-agent': 'Mozilla/5.0'}
r = requests.get(url, headers=kv,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""2、parsePage(ilt , html):分析目标网页中需要的内容(商品全称,商品价格),存储在列表ilt中。
ilt:传入的空白列表参数,用于保存查询到的商品信息(商品全称,商品价格);
html:该参数中保存了目标网站的网页内容;
soup:调用引入的BeautifulSoup库(使用方法请自行搜索,这里不做解释);
plt:用于保存价格数据的列表。用BeautifulSoup库中的find_all()函数寻找需要的价格数据;
tlt:用于保存商品名称数据的列表。用BeautifulSoup库中的find_all()函数寻找需要的商品名称数据;
price:用于保存查找到的信息中,文本内容的价格字符;
title:用于保存查找到的信息中,文本内容的商品全称的字符;
def parsePage(ilt , html):
soup = BeautifulSoup(html,"html.parser")
plt = soup.find_all('div',class_='p-price') #价钱所在的div的class标签为“p-price"
tlt = soup.find_all('div',class_='p-name') #价钱所在的div的class标签为“p-name p-name-type-2",这里可以填p-name或者p-name-type-2
for i in range(len(plt)):
price = plt[i]('i')
title = tlt[i]('em')
ilt.append([price[0].get_text(),title[0].get_text()])3、printGoodsList(ilt):打印出列表ilt中存储的相关数据信息。
ilt:已经存储了所需要的信息的列表;
count:作为序号用于记录商品的数量,并同商品信息一并输出;
循环输出商品信息。
def printGoodsList(ilt):
print("{:^4}\t{:^8}\t{:^16}".format("序号","价格","商品名称"))
count = 0
for g in ilt:
count += 1
print("{:^4}\t{:^8}\t{:^16}".format(count,g[0],g[1]))三、网页及网址分析
以“书包”为例,进入京东官网"https://www.jd.com/",在搜索框中输入“书包”后,可以明显看到,网页变成了https://search.jd.com/Search?keyword=书包&enc=utf-8&wq=书包&pvid=015eefefd82d46e8829af2ceb43db206
分析网页网址可知,通过keyword后面的字段可以搜索到想要的商品,因此,可以通过用户输入获取商品初始网址。点击商品主页底部的翻页可以发现,网址再次发生了变化。
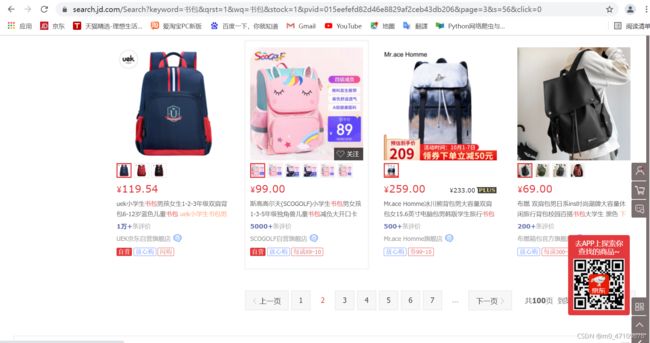
点击底部导航栏,选择第二页画面后观察网址,发现网址变化为:https://search.jd.com/Search?keyword=书包&qrst=1&wq=书包&stock=1&pvid=015eefefd82d46e8829af2ceb43db206&page=3&s=56&click=0
变化后的网址与首页网址的区别在于多了一个stock、page、s以及click参数,我们继续点击第三页内容进行对比观察
https://search.jd.com/Search?keyword=书包&qrst=1&wq=书包&stock=1&pvid=015eefefd82d46e8829af2ceb43db206&page=5&s=116&click=0
第二页与第三页的网址对比可以发现,stock没有变化,page从3变成了5,s从56变成了116,click没有变化。至此,可以推断出这几个变量的变化规律:
page=2*i-1(i的值表示第i页的商品内容);
s的值,好吧没找出规律来QAQ,欢迎大家在评论里批评指正;
因此,我们以获取两页的商品为例,将目标网页根据寻找到的规律重新订制。
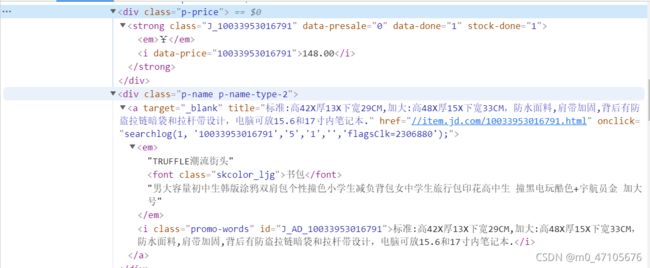
同样,我们在寻找目标数据时,先随便找到一个商品,右键点击“检查”,发现我们所需要的价格信息在class名为“p-price”的div中,商品全称在class名为“p-name”(或“p-name-type-2”,不熟悉html中命名规则的亲们可以自行查找相关资料学习,这里不做解释)的div中,而价格的文本内容在div下的i标签中,因此通过BeautifulSoup中的find_all()函数找到div,再将价格保存在price中;同上,商品全称的文本内容保存在em标签中,使用get_text()函数可以获取其中的非标签内容。
main():执行函数;
goods:通过用户输入获取商品名称;
depth:爬取目标网页的页数,这里以2页的内容为例,亲们可自行修改;
start_url:定义初始网址,将获取的商品数据加入网址中;
infoList:用于存放相关数据的列表;
url:翻页后的网址。
def main():
goods = input("请输入商品名称:")
depth = 2
start_url = "https://search.jd.com/Search?keyword=" + goods
infoList = []
for i in range(depth):
url = start_url + '&page=' + str(2 * i - 1)
html = getText(url)
parsePage(infoList, html)
printGoodsList(infoList)四、声明
本人是学习python爬虫路上的一名小白,如有不当之处(轻喷,小白需要鼓励),欢迎大佬们批评指正。