Airflow 实践笔记-从入门到精通一
数据处理逻辑多,脚本相互依赖强,运维管理监测难,怎么办?!为了解决这些问题,最近比较深入研究Airflow的使用方法,重点参考了官方文档和Data Pipelines with Apache Airflow,特此笔记,跟大家分享共勉。
Airflow项目
2014年在Airbnb的Maxime Beauchemin开始研发airflow,经过5年的开源发展,airflow在2019年被apache基金会列为高水平项目Top-Level Project。
Maxime目前是Preset(Superset的商业化版本)的CEO,作为Apache Airflow 和 Apache Superset 的创建者,世界级别的数据工程师,他这样描述“数据工程师”(原文):随着大数据和云计算的普及,数据工程师的角色和责任也更加多样化,包括ETL开发、维护数据平台、搭建基于云的数据基础设施、数据治理,同时也是负责良好数据习惯的守护者、守门人,负责在数据团队中推广和普及最佳实践,尤其是在效率(处理增量负载)、数据建模和编码标准方面,依靠数据可观察性和 DataOps 来确保每个人都以相同的方式处理数据。
源自创建者深刻的理解和设计理念,加上开源社区在世界范围聚集人才的组织力,Airflow取得当下卓越的成绩。作为一款优秀的数据工作流的管理工具,已被广泛的应用在包括Adobe, Airbnb, Etsy, Google, ING, Lyft, PayPal, Reddit, Square, Twitter, and United Airlines等世界知名的公司。Airflow完全是python语言编写的,加上其开源的属性,具有非常强的扩展和二次开发的功能,能够最大限度的跟其他大数据产品进行融合使用,包括AWS S3, Docker, Apache Hadoop HDFS, Apache Hive, Kubernetes, MySQL, Postgres, Apache Zeppelin等。
Airflow可实现的功能
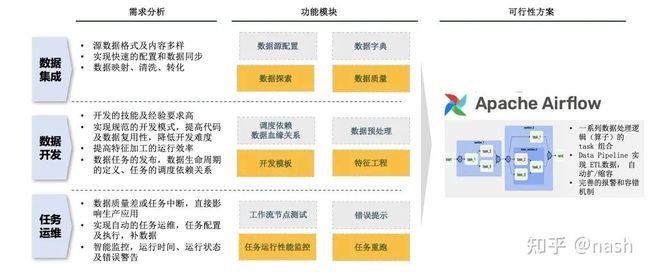
Apache Airflow提供基于DAG有向无环图来编排工作流的、可视化的分布式任务调度,与Oozie、Azkaban等任务流调度平台类似。采用Python语言编写,提供可编程方式定义DAG工作流,可以定义一组有依赖的任务,按照依赖依次执行, 实现任务管理、调度、监控功能。此外提供WebUI可视化界面,提供了工作流节点的运行监控,查看每个节点的运行状态、运行耗时、执行日志等。
主要概念
Data Pipeline:数据管道或者数据流水线,可以理解为贯穿数据处理分析过程中不同工作环节的流程,例如加载不同的数据源,数据加工以及可视化。
DAGs:是有向非循环图(directed acyclic graphs),可以理解为有先后顺序任务的多个Tasks的组合。图的概念是由节点组成的,有向的意思就是说节点之间是有方向的,转成工业术语我们可以说节点之间有依赖关系;非循环的意思就是说节点直接的依赖关系只能是单向的,不能出现 A 依赖于 B,B 依赖于 C,然后 C 又反过来依赖于 A 这样的循环依赖关系。每个 Dag 都有唯一的 DagId,当一个 DAG 启动的时候,Airflow 都将在数据库中创建一个DagRun记录,相当于一个日志。
Task:是包含一个具体Operator的对象,operator实例化的时候称为task。DAG图中的每个节点都是一个任务,可以是一条命令行(BashOperator),也可以是一段 Python 脚本(PythonOperator)等,然后这些节点根据依赖关系构成了一个图,称为一个 DAG。当一个任务执行的时候,实际上是创建了一个 Task实例运行,它运行在 DagRun 的上下文中。
Connections:是管理外部系统的连接对象,如外部MySQL、HTTP服务等,连接信息包括conn_id/hostname/login/password/schema等,可以通过界面查看和管理,编排workflow时,使用conn_id进行使用。
Pools: 用来控制tasks执行的并行数。将一个task赋给一个指定的pool,并且指明priority_weight权重,从而干涉tasks的执行顺序。
XComs:在airflow中,operator一般是原子的,也就是它们一般是独立执行,不需要和其他operator共享信息。但是如果两个operators需要共享信息,例如filename之类的,则推荐将这两个operators组合成一个operator;如果一定要在不同的operator实现,则使用XComs (cross-communication)来实现在不同tasks之间交换信息。在airflow 2.0以后,因为task的函数跟python常规函数的写法一样,operator之间可以传递参数,但本质上还是使用XComs,只是不需要在语法上具体写XCom的相关代码。
Trigger Rules:指task的触发条件。默认情况下是task的直接上游执行成功后开始执行,airflow允许更复杂的依赖设置,包括all_success(所有的父节点执行成功),all_failed(所有父节点处于failed或upstream_failed状态),all_done(所有父节点执行完成),one_failed(一旦有一个父节点执行失败就触发,不必等所有父节点执行完成),one_success(一旦有一个父节点执行成功就触发,不必等所有父节点执行完成),dummy(依赖关系只是用来查看的,可以任意触发)。另外,airflow提供了depends_on_past,设置为True时,只有上一次调度成功了,才可以触发。
Backfill: 可以支持重跑历史任务,例如当ETL代码修改后,把上周或者上个月的数据处理任务重新跑一遍。
Airflow 2.0 API,是一种通过修饰函数,方便对图和任务进行定义的编码方式,主要差别是2.0以后前一个任务函数作为后一个任务函数的参数,通过这种方式来定义不同任务之间的依赖关系。
AIRFLOW_HOME 是 Airflow 寻找 DAG 和插件的基准目录。当数据工程师开发完python脚本后,需要以DAG模板的方式来定义任务流,然后把dag文件放到AIRFLOW_HOME下的DAG目录,就可以加载到airflow里开始运行该任务。
安装Airflow
Airflow适合安装在linux或者mac上,官方推荐使用linux系统作为生产系统。如果要在windows安装,就需要通过WSL2 (Windows Subsystem for Linux 2) 一种windows版本但是能运行linux命令的子系统,或者通过Linux Containers容器来安装。
这里我们选择在windows环境下(日常个人的开发环境是windows)通过容器来安装,首先要安装docker。如果在安装docker时有报错信息“Access denied. You are not allowed to use docker. You must be in the “docker-users” group”,看上去是权限问题,但实际上很有可能是因为windows版本的问题。具体查看windows安装容器前提条件:docs.docker.com/desktop,这是安装WSL 2 backend的指南。重要是其中两个步骤,一个是要开启WSL 2功能,一个是安装 Linux 内核更新包。
制作Dockerfile文件
使用freeze命令先把需要在python环境下安装的包依赖整理出来,看看哪些包是需要依赖的。使用命令 pip freeze > requirements.txt
准备镜像的时候,可以继承(extend)airflow已经做好的官方镜像,也可以自己重新customize自定义镜像。这里我们使用extend的方法,会更加快速便捷。
该镜像默认的airflow_home在容器内的地址是/opt/airflow/,dag文件的放置位置是 /opt/airflow/dags。这个镜像同时定义了“airflow”用户,所以如果要安装一些工具的时候(例如build-essential这种linux下的开发必要工具),需要切换到root用户,用pip的时候要切换回airflow用户。更多参考 airflow.apache.org/docs。
在官方镜像中,用户airflow的用户组ID默认设置为0(也就是root),所以为了让新建的文件夹可以有写权限,都需要把该文件夹授予权限给这个用户组。
以下是具体dockerfile的内容
#使用官方发布的镜像
FROM apache/airflow:2.3.0
# 安装软件的时候要用root权限
USER root
RUN apt-get update \
&& apt-get install -y --no-install-recommends \
vim \
&& apt-get autoremove -yqq --purge \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
# pip安装用airflow用户
USER airflow
COPY requirements.txt /tmp/requirements.txt
#使用requirements安装指定包的例子
RUN pip install -r /tmp/requirements.txt
# 一个用pip安装指定包的例子
#RUN pip install --no-cache-dir apache-airflow-providers-docker==2.5.1
# 拷贝DAG文件,并且设置权限给airflow
COPY --chown=airflow:root BY02_AirflowTutorial.py /opt/airflow/dags
COPY src/data.sqlite /opt/airflow/data.sqlite
#建立一个可以写的文件夹,这里的~指的是主目录
RUN umask 0002; \
mkdir -p ~/writeable_directory容器部署
准备好dockerfile以及相关的文件(例如脚本dag.py和数据库sqlite),具体部署有两种方法:
一种方法是采用docker命令。
运行命令来生成镜像:
docker build -t airflow:latest镜像做好以后,需要使用docker run来启动镜像,不要用docker desktop的启动按钮(会默认使用 airflow的命令,会报如下错误 airflow command error: the following arguments are required: GROUP_OR_COMMAND, see help above)。
运行下面的命令:其中 -it 意思是进入容器的bash输入, --env 是设置管理者密码
docker run -it --name test -p 8080:8080 --env "_AIRFLOW_DB_UPGRADE=true" --env "_AIRFLOW_WWW_USER_CREATE=true" --env "_AIRFLOW_WWW_USER_PASSWORD=admin" airflow:latest airflow standalone第二种方法是:按照官方教程使用docker compose(将繁琐多个的Docker操作整合成一个命令)来创建镜像并完成部署。
在windows环境下,安装docker desktop后默认就安装了docker-compose工具。Docker Compose使用的模板文件是docker-compose.yml,其中定义的每个服务都必须通过image指令指定镜像或使用Dockerfile的build指令进行自动构建,其它大部分指令跟docker run的选项类似。Compose 使用的三个步骤:
1)使用 Dockerfile 定义应用程序的环境。
2)使用 docker-compose.yaml 定义构成应用程序的服务,这样它们可以在隔离环境中一起运行。
3)执行 docker-compose up 命令来启动并运行整个应用程序。
Docker descktop的配置要把内存调整到4G以上,否则后续可能会报内存不足的错误。

同时需要把本地yaml所在文件夹加入到允许file sharing的权限,否则后续创建容器时可能会有报错信息“Cannot create container for service airflow-init: user declined directory sharing ”

Airflow官方教程中使用CeleryExecutor来进行容器部署,会使用compose命令建立多个容器,不同的容器承担不同的服务。直接使用官方提供的yaml文件(airflow.apache.org/docs)
这个yaml文件包含的操作主要是
1)安装airflow,使用官方镜像(也可以自定义镜像),定义环境变量(例如数据库的地址)
2)安装postgres服务,指定其对应的镜像
3)安装Redis,作为celery的broker
4)启动airflow的webserver服务
5)启动airflow的schedule服务
6)启动worker node
7)启动trigger服务,这是一个新的组件,目的是检查任务正确性
8)数据库初始化
同样的目录下,新建一个名字为.env文件,跟yaml文件在一个文件夹。里面内容为 AIRFLOW_UID=50000,主要是为了compose的时候赋予运行容器的userID, 50000是默认值。
在cmd界面进入yaml所在文件夹,运行以下命令就可以自动完成容器部署并且启动服务。运行docker ps应该可以看到6个在运行的容器
docker-compose up运行airflow
安装完airflow后,运行以下命令会将相关的服务启动起来
airflow standalone上面的命令等同于下面的命令,逐个启动相关服务
airflow db init
airflow users create \
--username admin \
--firstname Peter \
--lastname Parker \
--role Admin \
--email [email protected]
airflow webserver --port 8080
airflow scheduler在terminal初始化数据库,会在/Users/XXXX/airflow/下生成airflow.db的SQLiteDB(默认的数据库),可以进一步查看其底层设计的表结构。这个数据库被称为metastore元数据存储。
默认前台web管理界面会加载airflow自带的dag案例,如果不希望加载,可以在配置文件中修改AIRFLOW__CORE__LOAD_EXAMPLES=False,然后重新db init
参数配置
/Users/XXXX/airflow/airflow.cfg是配置表,里面可以配置连接数据库的字符串,配置变量是sql_alchemy_conn。
Airflow默认使用SQLite,但是如果生产环境需要考虑采用其他的数据库例如Mysql,PostgreSQL(因为SQLite只支持Sequential Executor,就是非集群的运行)。
当设置完这个配置变量,就可以airflow db init,自动生成后台数据表。配置文件中的secrets backend指的是一种管理密码的方法或者对象,数据库的连接方式是存储在这个对象里,无法直接从配置文件中看到,起到安全保密的作用。
AIRFLOW__CORE__DAGS_FOLDER 是放置DAG文件的地方,airflow会定期扫描这个文件夹下的dag文件,加载到系统里。当然这会消耗系统资源,所以可以通过设置其他的参数来减少压力。例如AIRFLOW__SCHEDULER__PROCESSOR_POLL_INTERVAL
AIRFLOW__CORE__EXECUTOR 配置使用哪种executor
如果不想加载airflow自带的案例,可以配置
n Set AIRFLOW__CORE__LOAD_EXAMPLES=False
n Set AIRFLOW__CORE__LOAD_DEFAULT_CONNECTIONS=False
如果需要对web管理界面自定义,例如 颜色、title等,参考https://airflow.apache.org/docs/apache-airflow/2.2.5/howto/customize-ui.html
如果需要配置邮件,参考 https://airflow.apache.org/docs/apache-airflow/2.2.5/howto/email-config.html
web管理界面
在界面中,先要把最左边的switch开关打开,然后再按最右边的开始箭头,就可以启动一个DAG任务流。启动任务流的方式还有两种:CLI命令行方式和HTTP API的方式

点击link->graph,可以进一步看到网状的任务图,点击每一个任务,可以看到一个菜单,里面点击log,可以看到具体的执行日志。如果某个任务失败了,可以点击图中的clear来清除状态,airflow会自动重跑该任务。

菜单点击link->tree,可以看到每个任务随着时间轴的执行状态。
菜单admin下的connections可以管理数据库连接conn变量,后续operator在调用外部数据库的时候,就可以直接调用conn变量。

篇幅有限,后续发布Airflow的其他特性。。。