浅学Mybatis
目录
什么是Mybatis?
什么是MybatisPlus?
Count(1),Count(*),Count(列名)的区别?
平均值用什么,分组用什么
聚集函数:
两个相同列的结果集求并集用什么
完整查询SQL中的关键字的定义顺序
完整的多表JOIN查询,SQL中关键字的执行顺序
笛卡尔积
Left Join 和Join的区别?
数据库三范式【3NF】
模糊查询 like 语句该怎么写
MyBatis中#{}取值和${}取值的区别
MyBatis关联查询中,延迟加载和饥饿加载的区别
MyBatis对象关联查询和集合关联查询怎么做
MyBatis一级缓存和二级缓存的区别
什么是Mybatis?Mybatis和Hibernate的区别?
为什么说 Mybatis 是半自动 ORM 映射工具?它与全自动的区别在哪里?
MyBaits的Mapper接口没有实现类为什么可以用@Autowired直接注入?
在MyBatis如何动态修改SQL
MyBatis的动态SQL标签有哪些?
Mybatis的mapper如何传递多个参数
MyBatis在insert时返回自增长id值
Mybatis,关联对象查询,使用嵌套子查询和JOIN连表有什么区别
为什么要使用连接池【面向数据库连接】
为什么使用线程池?
mybatis的mapper接口没有实现为什么可以调用?
MyBatis如何使用乐观锁?
什么是Mybatis?
Mybatis是一款优秀的持久层框架(封装了JDBC),将数据能够保存在磁盘当中,出现宕机时,数据不会丢失。支持自定义SQL查询、存储过程和高级映射,消除了几乎所有的JDBC代码和参数的手动设置以及结果集的检索。MyBatis可以使用简单的XML或者注解进行映射和配置,通过将参数映射到配置的SQL最终解析为执行的SQL语句,查询后将SQl结果集映射成java对象返回。
什么是MybatisPlus?
MyBatis-plus是一款MyBatis的增强工具,在MyBatis 的基础上只做增强不做改变(AOP原理)。其是国内团队苞米豆在MyBatis基础上开发的增强框架,扩展了一些功能,以提高效率。引入 Mybatis-Plus 不会对现有的 Mybatis 构架产生任何影响,而且 MyBatis-plus 支持所有 Mybatis 原生的特性
1通用CRUD操作,帮助我们快速的生成一张表的CRUD操作。
2预防SQL注入问题,内置 Sql 注入剥离器,有效预防Sql注入攻击 。
3损耗小:启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作 。
4内置分页插件:基于 Mybatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通List查询。
等等,反正牛皮就对了。
什么是ORM?
即Object-Relationl Mapping(对象关系映射),它的作用是在关系型数据库和对象之间作一个映射,这样,我们在具体的操作数据库的时候,就不需要再去和复杂的SQL语句打交道,只要像平时操作对象一样操作它就可以了 。
总的来说,ORM可以实现利用对象操纵数据库中的表。
Count(1),Count(*),Count(列名)的区别?
1、count(*)查询全表,在统计结果的时候,不会忽略列值为NULL。
2、count(1)在统计结果的时候,不会忽略列值为NUL,比count(*)查询效率高。
3、count(列名)只对列名那一列进行统计,在统计结果的时候,会忽略列值为空。
当表orders中有以下数据时:
+----+--------+---------+
| id | name | price |
+----+--------+---------+
| 1 | apple | 5.99 |
| 2 | orange | 4.99 |
| 3 | banana | 2.99 |
| 4 | NULL | 1.99 |
+----+--------+---------+
COUNT(1)会返回表中非NULL行的数量4。
SELECT COUNT(1) FROM orders;
-- 结果为:4
COUNT(*)会返回表中所有行的数量,包括NULL行,结果也是4。
SELECT COUNT(*) FROM orders;
-- 结果为:4
COUNT(price)会返回表中price列非NULL值的数量,即3。
SELECT COUNT(price) FROM orders;
-- 结果为:3
需要注意的是,在进行SELECT查询时,如果结果集为空,则聚合函数COUNT将会返回0,而不是NULL。例如:
SELECT COUNT(*) FROM orders WHERE name = 'watermelon';
-- 结果为:0聚集函数:
COUNT:统计结果记录数 如果列的值为null 不会计算在内的
MAX: 统计计算最大值
MIN: 统计计算最小值
SUM: 统计计算求和
AVG: 统计计算平均值 如果列的值为null 不会计算在内的
两个相同列的结果集求并集用什么
Union:对两个结果集进行合并去重,相当于distinct;
Union All:对两个结果集进行合并不去重;
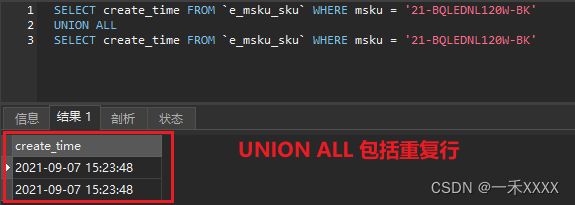
union all比union性能好;(因为不去重不排序不浪费时间)
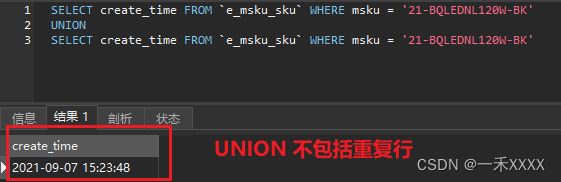
union:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序;union 在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算,删除重复的记录再返回结果。实际大部分应用中是不会产生重复的记录,最常见的是过程表与历史表 union。
SELECT create_time FROM `e_msku_sku` WHERE msku = '21-BQLEDNL120W-BK'
UNION
SELECT create_time FROM `e_msku_sku` WHERE msku = '21-BQLEDNL120W-BK'结果·
UnionAll
SELECT create_time FROM `e_msku_sku` WHERE msku = '21-BQLEDNL120W-BK'
UNION ALL
SELECT create_time FROM `e_msku_sku` WHERE msku = '21-BQLEDNL120W-BK'结果·
完整查询SQL中的关键字的定义顺序

以下是这些关键字的解析:
SELECT:选择要从表中检索哪些列,可以选择计算值或者使用别名。FROM:指定要从哪张表中检索数据。JOIN:可选关键字,用于将多个表组合为一个查询的结果集。ON:当语句包含JOIN时使用,在此指定连接条件。WHERE:筛选要返回的行。GROUP BY:将返回的行按指定列进行分组。通常需要将函数用于结果集上的列。HAVING:筛选要返回的分组,在应用GROUP BY后执行。ORDER BY:通过指定一个或多个列对结果进行排序。通常需要在ORDER BY子句中指定一个列,以便为结果集定义排序顺序。
完整的多表JOIN查询,SQL中关键字的执行顺序
from【从那张表】>on【联表查询的条件】 >join【另一张表】>where【条件】>group by【分了组才使用聚合函数】>having【使用聚合函数--条件】>select【获取所有满足条件的】>order by【升序降序-默认升序ASC】>limit【显示多少条】
笛卡尔积
假设集合A={a, b},集合B={0, 1, 2},则两个集合的笛卡尔积为
{(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)}。
mysql left 笛卡尔积_mysql 内连接、左连接会出现笛卡尔积?_辉煌之欢的博客-CSDN博客
笛卡尔积就是两个数据库的数据取并集。
Left Join 和Join的区别?
left join:左边全部数据+右边满足条件的数据
right join:右边全部数据+左边满足条件的数据
join:交集
以下是 LEFT JOIN 与 JOIN 的使用示例:
LEFT JOIN:
SELECT *
FROM table1
LEFT JOIN table2
ON table1.id = table2.id;
上述 SQL 语句中,使用 LEFT JOIN 返回 table1 表中的所有行以及 table2 表中与 table1 中 id 列匹配的行,如果不存在匹配,则返回 NULL 代替 table2 中的列。
JOIN:
SELECT *
FROM table1
JOIN table2
ON table1.id = table2.id;
上述 SQL 语句中,使用 JOIN 返回 table1 和 table2 中都存在匹配的行。如果不存在匹配,则不返回该行。
一分钟让你搞明白 left join、right join和join的区别_往事随风_h的博客-CSDN博客_join和leftjoin的区别
数据库三范式
数据库三范式【看了就有收获,最简单的例子解释】_GuGuBirdXXXX的博客-CSDN博客_第三范式
范式就是规范,就是要遵守的原则。一般要遵守有三种范式
1NF(1范式): 设计数据库表的列的时候,这些列唯一,不可拆分。 列的原子性,其实这种范式可以不用管,关系型数据库默认都满足。
2NF(2范式):表中行是唯一,通常设计一个主键来实现。
3NF(3范式): 如果一张表的数据能够通过其他表的外键推导出来,不应该单独设计,通过外键的方式关联查询出来。【就是一个表中有冗余字段的出现】
综合下来:可以发现三个范式,就是将表中的数据拆分成对应的更细的表【增删改查一个不会对其他的所有表的数据造成影响】,
注意:原则上是不能违反三范式的,但是有的时候我们为了增强查询效率【变多表查询为单表查询】,会设计一些冗余字段,变多表查询为单表查询。称之为反三范式
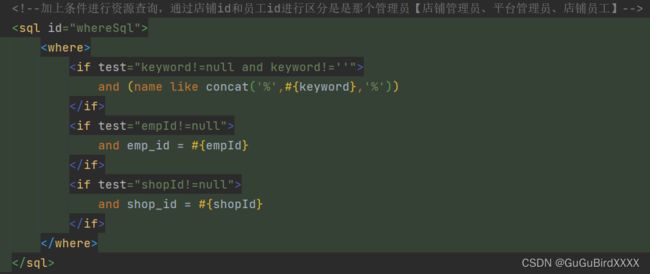
模糊查询 like 语句该怎么写
1)在 java 中拼接通配符,通过#{}赋值 2)在 Sql 语句中使用concat进行拼接通配符
select * from tbl_school where school_name like '%$name$%'
===>sql1:select * from tbl_school where school_name like '%巴中⼀中%' or '1%' = '1%'(会出现sql注入问题--)
mysql: select * from tbl_school where school_name like concat('%',#name#,'%')[不会出现sql注入]
MyBatis中#{}取值和${}取值的区别
#{}底层是preparestatement对象,mybatis在处理#{}时,会将sql中的#{}使用?充当占位符,然后使用preparestatement的set方法进行赋值,不会出现sql注入问题。而且效率比较高,是预先进行编译的。
${}底层是statement对象,mybatis在处理${}时,会将${}使用字符串替换的方式,会出现sql注入问题。不会预编译,效率比较低。
========================详解================================
** 动态 sql 是 mybatis 的主要特性之一,在 mapper 中定义的参数传到 mapper.xml 中之后,在查询之前 mybatis 会对其进行动态解析**
使用#时会,Mybatis会**预编译将#解析为占位符?,Mybatis会在动态数据自动添加一个单引号。可以一定程序上预防sql注入【会加上单引号】**
举例:#对传入的参数视为字符串,也就是它会预编译,select * from user where name = #{name},比如我传一个csdn,那么传过来就是 select * from user where name = 'csdn';(会加上单引号)
使用$时相当于直接显示数据,容易出现sql注入【rookie后面加上or 1 =1】
$不会将传入的值进行预编译, select * from user where user_name= ${rookie} ,那么传过来的sql就是:select * from user where user_name=rookie;
但是当我们使用order by ,group by 和表名时,需要用到$符号【有时你只是想直接在SQL语句中插入一个不改变的字符串】
原因:因为是用#时,Mybatis会在动态数据(不管是什么类型)自动添加上一个单引号(mybatis会解析不了)
MyBatis关联查询中,延迟加载和饥饿加载的区别
延迟加载(懒加载),如果有两张有关联关系的表A表和B表,延迟加载的情况,查询A表不会查询B表的数据,需要的时候才进行查询。
饥饿加载,在查询A表的同时就把B表的数据也查询出来加载到内存当中。
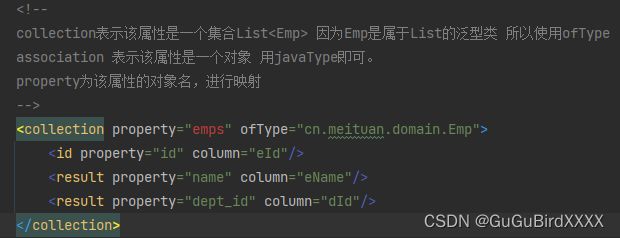
MyBatis对象关联查询和集合关联查询怎么做
单个关联对象用association ,适用于多对一(多个员工一个部门)的关联查询,使用javaType来定义实体类型,
集合用collection,适用于一对多的关联查询(一个部门多个员工),使用ofType来定义集合的泛型类型

MyBatis一级缓存和二级缓存的区别
链接这篇文章真的棒。
mybatis的一级缓存和二级缓存 -- 看完再也不懵逼_java叶新东老师的博客-CSDN博客

缓存,是指将从数据库查询出的数据存储在缓存中,下次使用相同的sq进行查询时不必再从数据库查询,而是直接从缓存中读取,从而减轻数据库的压力,提高查询效率。
一级缓存

mybaits中的一级缓存的是sqlsession级别的缓存,而且是默认开启的,在操作数据库的同时需要构造一个sqlsession对象,在对象中有一个HashMap用于存储缓存数据。使用同一个SqlSession执行两次的sql语句时,第一次会去数据库进查询并同步到缓存(内存),第二次进行查询则直接从缓存中获取数据,从而提高查询效率;
注意:如果一级缓存sqlsession在执行增删改、commit,close等操作时,Mybatis则会清除sqlSession的一级缓存,这样的目的就是为了保证缓存中存储的是最新的消息。避免出现脏读【无效数据的读取】现象。
一级缓存的生命周期和SqlSession一致,当调用SqlSession.close()方法时会释放缓存
二级缓存
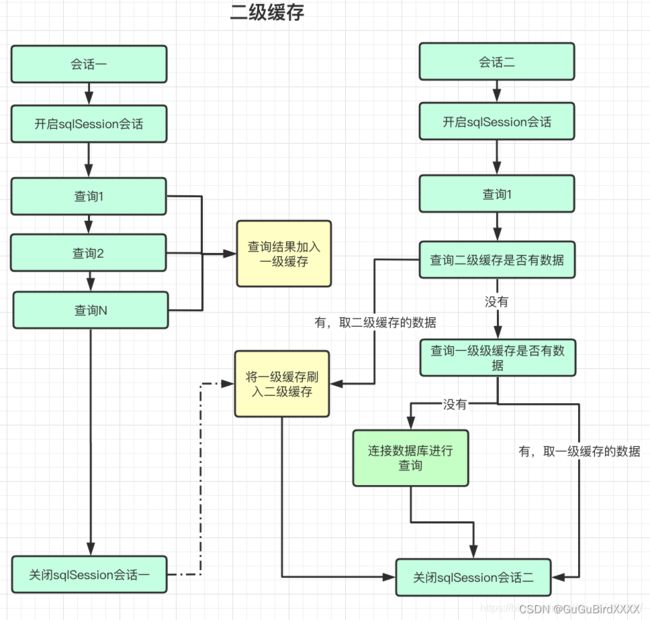
mybatis中的二级缓存是namespace级别的缓存,是全局的,也就是说多个请求可以公用一个缓存。二级缓存需要手动开启,缓存会先放在一次缓存,当sqlSession会话提交或者关闭的时候才会从一级缓存刷新到二级缓存中,所以在查询的时候会先去二级缓存中进行查询,查询不到再去一级缓存中进行查找。
如果某个对象要开启二级缓存,那么这个与数据库对应的Java对象必须实现序列化接口。
当SQL中执行了update()、delete()、insert()操作,则缓存中的数据都会清空,避免读取到脏数据。
========================================================
查询的时候先去二级缓存中进行查询,查询不到再去一级缓存中进行查询,最后去数据库进行查询。
存储缓存就是相反的顺序。
什么是Mybatis?Mybatis和Hibernate的区别?
Mybatis是一个优秀的持久化层框架,封装了JDBC(Java DataBase connectivity数据库连接)将数据可以保存到磁盘当中进行存储,从而保证数据可以保存在可掉电设备当中。
1Mybatis 学习门槛低,简单易学,
2直接编写原生态 sql,可严格控制 sql 执行性能,灵活度高,非常适合对关系数据模型【有二维表的模型】要求不高的软件开发,例如互联网软件、企业运营类软件等,因为这类软件需求变化频繁,一但需求变化要求成果输出迅速。
缺点:灵活的前提是 mybatis 无法做到数据库无关性【应用程序运行不依赖于某一数据库】,如果需要实现支持多种数据库的软件则需要自定义多套 sql 映射文件,工作量大。
Hibernate 对象/关系映射能力强,数据库无关性好,对于关系模型要求高的软件(例如需求固定的定制化软件)如果用 hibernate 开发可以节省很多代码,提高效率。
Hibernate 的缺点是学习门槛高,要精通门槛更高,而且怎么设计 O/R 映射,在性能和对象模型之间如何权衡,以及怎样用好 Hibernate 需要具有很强的经验和能力才行。
总之,按照用户的需求在有限的资源环境下只要能做出维护性、扩展性良好的软件架构都是好架构,所以框架只有适合才是最好。
为什么说 Mybatis 是半自动 ORM 映射工具?它与全自动的区别在哪里?
Hibernate 属于全自动 ORM 映射工具,使用 Hibernate 查询关联对象或者关联集合对象时,可以根据对象关系模型直接获取,所以它是全自动的。
而 Mybatis 在查询关联对象或关联集合对象时,需要手动编写 sql 来完成,所以,称之为半自动 ORM 映射工具。
MyBaits的Mapper接口没有实现类为什么可以用@Autowired直接注入?
使用了JDK动态代理,赋值给mapper接口的对象其实是一个代理对象,这个代理对象是由 JDK 动态代理创建的。在解析mapper的时候,mybatis会通过java反射,获取到接口所有的方法。当调用接口中方法时,将通过接口全限定名+方法名对应找到映射文件中namespace和id匹配的sql,然后进行执行sql语句。
在MyBatis如何动态修改SQL
mybatis拦截器,动态修改sql语句_非ban必选的博客-CSDN博客_mybatisplus 拦截器修改sql
使用Mybatis的拦截器动态修改sql
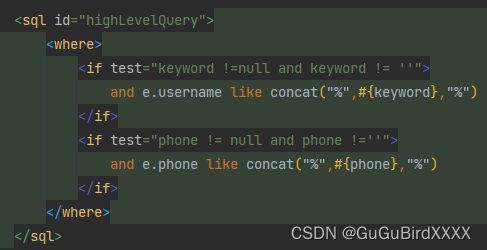
MyBatis的动态SQL标签有哪些?
动态sql,主要用于解决查询条件不确定的情况:在程序运行期间,根据用户提交的查询条件实现动态拼接sql语句进行查询数据。
这里的条件判断使用的表达式为OGNL表达式,常用的动态sql标签有
if标签:条件判断
where标签:判断包含节点有内容就插入 where,否则不插入
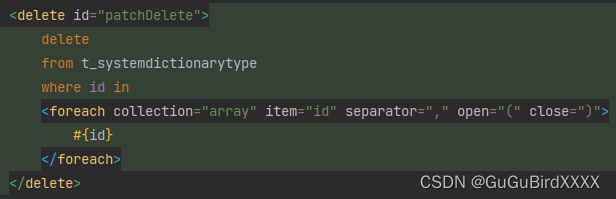
foreach标签:遍历元素

Mybatis的mapper如何传递多个参数
Mybatis mapper文件中传递多个参数的4种方式(干货)_yixuan30的博客-CSDN博客_mapper传参的几种方式
方法一:顺序传参法
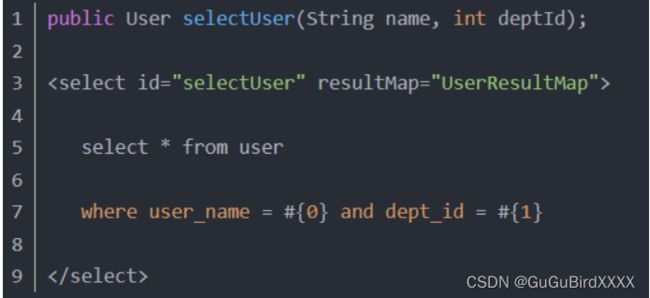
#{}里面的数字代表你传入参数的顺序。这种方法不建议使用,sql层表达不直观,且一旦顺序调整容易出错。
方法2:@Param注解传参法
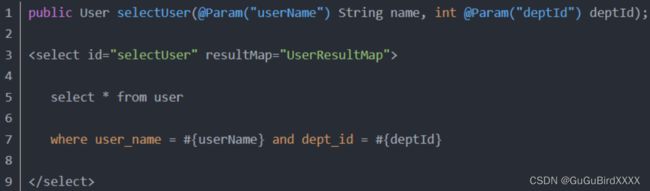
#{}里面的名称对应的是注解@Param括号里面修饰的名称。这种方法在参数不多的情况还是比较直观的,推荐使用。
方法3:Map传参法
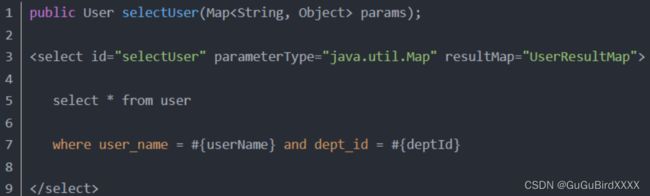
#{}里面的名称对应的是Map里面的key名称。这种方法适合传递多个参数,且参数易变能灵活传递的情况。
MyBatis在insert时返回自增长id值
1、开启useGeneratedKeys属性方法
useGeneratedKeys="true" 开启新增主键返回功能
keyProperty="id" user实体主键属性
keyColumn="id" user表中主键列
insert into user(username,password) values (#{username},#{password})
Mybatis,关联对象查询,使用嵌套子查询和JOIN连表有什么区别
嵌套子查询,在一个SELECT语句中的WHERE子句或HAVING子句中嵌套另一个SELECT语句 的查询称为嵌套查询
连表join查询,指的是查询一个主对象的时候,使用join连表的方式把主对象和关联对象的数据一次性全部查出来,用resultmap映射结果
他们的区别,join连表查询只发一条sql就能把数据查询出来,嵌套子查询会有一个n+1的问题,就是说如果主查询出来n条数据,那么会额外发送n条子sql去查询对应的关联对象,加上主查询那1次,也就是n+1次,因此它的性能相对较低的,一般我们会使用join连表查询。
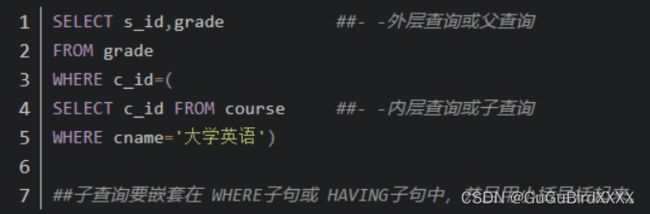
为什么要使用连接池【面向数据库连接】
对数据库的操作都需要取得连接,使用完都需要关闭连接,如果每次操作需要打开关闭连接,这样系统性能很低下。
连接池就可以动态的管理这些连接的申请,使用和释放,我们操作数据库只需要在连接池里获取连接,使用完放回连接池,这样大大节省了内存,提高效率。
数据库连接池的原理主要分为三部分
-
第一,连接池的建立,在系统初始化时连接池就创建了一部分连接以便使用。
-
第二,连接池的管理,客户请求连接数据库时,首先查看连接池中是否有空闲连接,如果有直接分配,如果没有就等待,直到超出最大等待时间,抛出异常
-
第三,连接池的关闭,当系统关闭时,连接池中所有连接关闭
为什么使用线程池?
如果没有线程池,当有1000个请求,就会创建1000个线程,比较浪费资源和时间。
线程池就是提前创建多个线程放在一个容器中,当需要使用的时候就不需要进行创建,而是直接从线程池进行获取,节省了创建线程需要的时间和资源的浪费,提高了代码的执行效率。
优点:
1避免线程的重复创建和销毁。通过重复利用提前创建好的线程降低线程的创建和销毁**造成的消耗。
2提高了执行效率,当有请求时,直接获取线程进行处理,就不用再去创建线程浪费时间了。
3可以有效控制最大并发线程数(在配置中进行配置线程数)
mybatis的mapper接口没有实现为什么可以调用?
【mapper是如何和mapper.xml对应起来的?】
使用了JDK动态代理,赋值给mapper接口的对象其实是一个代理对象,这个代理对象是由 JDK 动态代理创建的。在解析mapper的时候,mybatis会通过java反射,获取到接口所有的方法。当调用接口中方法时,将通过接口全限定名+方法名对应找到映射文件中namespace和id匹配的sql,然后进行执行sql语句。
MyBatis如何使用乐观锁?
MybatisPlus如何使用乐观锁?_GuGuBirdXXXX的博客-CSDN博客