面向动态图的极低时延 GNN 推理采样服务
GraphLearn是阿里云机器学习平台PAI 团队和达摩院智能计算实验室图计算团队共建的工业界大规模图神经网络训练框架, 也是一站式图计算平台GraphScope的图学习引擎。GraphLearn最新开源了面向动态图的GNN在线推理实时采样服务(DGS)。DGS具备处理实时高吞吐图更新的能力,并能保证低时延、高并发的推理采样查询处理。其图更新和采样查询的性能在分布式环境下线性可扩展。近期,GraphLearn团队和浙大联合发表的《Dynamic Graph Sampling Service for Real-time GNN Inference at Scale》被评选为EuroSys2023 best poster。

Poster地址:https://2023.eurosys.org/docs/posters/eurosys23posters-final40.pdf
开源项目地址: GraphLearn, GraphScope
背景介绍
GNN模型通过图结构表征高阶邻域信息,在大规模工业落地中,一种常用的训练方式是通过邻域采样的方式来降低通信和计算的开销,从而获得分布式的扩展性。与此同时,在推荐、金融反欺诈等真实业务场景中,图的结构和属性往往会随着时间动态变化,GNN模型需要能实时采样并表征这些邻域的动态信息。
由于在线学习容易造成模型的抖动,在实际生产应用中,模型的部署也通常需要经过复杂的生产链路,因此一般采用近线模型进行部署,为了让GNN模型能够实时表征邻域信息,在GNN模型的推理过程中,需要通过实时的采样图结构和属性来进行实时推理。
为保证用户体验,这种实时推理的任务具有极低时延的需求,留给采样查询的时延空间非常小。同时,由于工业大图的数据规模和在线推理服务的QPS往往超出单机的存储和计算能力。因此,我们需要提供一个在大规模的动态图上保障极低时延的面向GNN模型推理的实时采样服务(P99在20毫秒以内),并具备在分布式环境下线性扩展的能力。
挑战
实时图采样服务的直观做法是维护一个动态图的存储和查询模块,在推理请求到达时对请求的点进行邻居采样计算和属性收集,采样计算得到的样本作为模型服务的输入进行推理。但是图数据的分布和推理采样的负载特性,导致这种直观的做法难以在分布式的动态图上实现稳定的低延时采样,具体地,存在以下挑战:
- 邻居采样需要遍历所有的邻居,并且随着图的动态变化,邻居不断变化,难以保证复杂的采样计算的低时延,超点的存在也造成了时延的不稳定。
- 由于图数据分布存在不均衡的特点,各个图分片上的存储和计算负载分布不均,造成采样延时的不稳定,也为分布式下线性扩展带来挑战。
- 推理采样一般为多跳采样,并且需要收集顶点或边上的动态属性,在分布式图上,多跳采样和属性访问带来的网络和本地I/O开销,对时延造成很大的影响。
关键设计
与一般图数据库的负载不同,动态图推理采样服务在服务于一个给定的模型的在线推理时,其对应的图采样具有固定的pattern。如一个常见User-Item,Item-Item二部图上的GraphSAGE模型,这个图采样的pattern一般是对于请求的用户ID(feed_id),根据时间戳作为概率采样它最新2个最新购买的商品,对这2个商品采样他们相关系数最高的2个商品。用GraphLearn提供的GSL(Graph Sampling Language)表达成如下Query:

图1: 二跳采样Query
这种固定pattern的Query,给大规模的动态图采样提供了稳定的低延时服务的机会。
DGS系统设计的关键点:
1.存算分离和感知Query的Cache
DGS将图存储和采样计算进行分离。采样计算一般是指随机采样,最新邻居采样(topk timestamp),或通过边权重(或边timestamp)做概率分布采样。前两种采样的时间复杂度为O(1),概率分布采样通常使用Alias Method实现,在动态图中变化的概率分布上需要反复计算Alias Table,其时间和空间复杂度均为O(N), 其中,N为顶点的邻居数,并不断发生变化。与图存储的简单读写不同,图采样过程包含存储的读写与复杂的计算,因此我们首先将存储和计算进行分离,并且在计算侧,系统预先将服务的特定Query所需要访问的数据cache起来,以提升图采样计算的空间局部性。
2.Event-driven预采样
为了加速采样请求的响应,DGS将每个顶点的采样计算从请求输入的时刻提前到图更新事件发生的时刻,利用空间换取时间,使得采样请求发生时仅需要完成点查。同时,为了降低图更新事件从发生到样本生成之间的staleness,DGS采用流采样的方式,通过带权重的蓄水池采样算法,在每个更新到达时,根据预安装的Query,进行流式采样。这种图更新事件驱动的采样前置的方式,使得对每个顶点的图数据存储空间和计算时间都变成了常数*O(K),其中K为蓄水池大小。通过将图采样计算的结果预先存储在cache中解决了挑战1中的问题。
3.Multi-hop拆解和Lazy拼接
至此,DGS解决了输入顶点的实时一跳采样。然而DGS主要服务于多跳采样,以二跳采样为例,输入顶点的一跳结果更新后,对应的二跳结果也需要更新(同时更新收集的属性)。在跳数更多的情况下,这种连锁反应造成的指数级增长的读写开销,对采样请求的时延产生巨大的影响。DGS解决该问题的方式是根据预安装的Query,将图采样按照每一跳进行拆解。对于每一跳采样,对图中对应顶点类型的所有顶点进行对应的流式预采样和存储。例如,图1中的Query可以拆解位图2所示,结合Event-driven预采样,每个顶点对应的样本在蓄水池中存储和更新如图3所示。
并且,DGS将多跳样本的拼接推迟到对应的推理采样请求发生的时刻(Lazy拼接),以避免提前拼接后持续更新。

图2: 二跳采样Query拆解
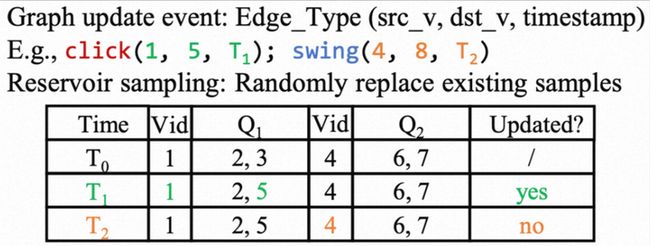
图3: Event-driven更新
1.订阅-发布机制
我们将多跳的拼接延迟到请求发生的时候,然而,多跳结果往往存储在不同分片上,跨机通信带来了大量的网络通信开销。因此,DGS设计了一套订阅-发布机制,即将请求的id根据特定的分片算法路由到对应的服务机器上,该机器上订阅这些id和它的多跳邻居的更新。随着邻居关系的改变,订阅表也不断更新。
2.读写隔离
根据以上的系统设计,当采样请求发生时,DGS将它路由到指定worker,进行本地的查询即可获得多跳采样结果。为了优先保障读的latency,同时保证写的staleness,DGS在调度读写task时进行优先级调度。同时,在系统架构上,将频繁计算和更新存储(写)的任务和响应采样请求(读)的任务放在不同的机器上,进行读写的隔离。
系统架构
DGS系统的核心组件架构如下图所示,主要为Sampling Worker和Server Worker组件。
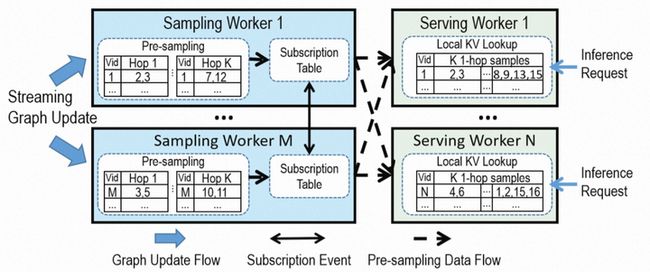
图4: DGS系统核心架构
图更新根据Key(例如顶点ID)分片发给Sampling Worker的对应分区。每个Sampling Worker负责特定的分区:进行一跳预采样并将结果发给Serving Worker。每个Serving Worker缓存从Sampling Worker接收到的K个一跳查询的采样结果,并响应全图中某一特定分片的顶点的推理采样请求。
Sampling Workers和Serving Workers可以独立的进行弹性扩缩容,以应对图更新和推理请求的负载变化。为了让生成完整K跳采样结果的延迟最小化,DGS将顶点  的所有K跳采样结果提前发送给响应 推理请求的Serving Worker,使得K跳图采样计算转化为仅需要访问Serving Worker上本地缓存的操作。为了实现这一点,每个Sampling Worker维护每个一跳查询的订阅表,记录订阅一跳查询结果的Serving Worker列表。例如,将顶点 从
的所有K跳采样结果提前发送给响应 推理请求的Serving Worker,使得K跳图采样计算转化为仅需要访问Serving Worker上本地缓存的操作。为了实现这一点,每个Sampling Worker维护每个一跳查询的订阅表,记录订阅一跳查询结果的Serving Worker列表。例如,将顶点 从 的一跳样本中增删会触发消息来将该事件发送到包含 的分区的Sampling Worker,并相应地更新 的订阅信息。
的一跳样本中增删会触发消息来将该事件发送到包含 的分区的Sampling Worker,并相应地更新 的订阅信息。
通过这种设计,DGS可以在高并发的推理采样的负载下,表现出非常稳定的延迟性能。
性能
在真实的阿里巴巴电子商务数据集上进行的实验表明,DGS可以将推理请求 (两跳随机采样查询)的P99延迟保持在20ms毫秒之内,单个Serving Worker的QPS约20,000,并可以线性扩展。图数据更新的吞吐达到109MB/s,也同样可以线性扩展。

图5: 实验配置和性能数据
结语
本文对DGS进行了技术解读,介绍了DGS核心模型的设计思路。实际上,DGS作为服务还包含了服务拉起模块、高可用模块、数据加载模块,以及和模型服务对接的客户端,借助DGS,用户可以基于实时变化的图结构和特征来推理得到最新的图表征。我们提供了一个端到端的基于GraphLearn的训练、模型部署和基于DGS在线推理的tutorial,欢迎试用!更多细节请参考源码和技术文档。
作者:沈雯婷
原文链接
本文为阿里云原创内容,未经允许不得转载。