【数据结构(28)】6.4 图的存储结构
文章目录
- 前言
- 一、邻接矩阵(数组)表示法
-
- 1. 无向图的邻接矩阵
-
- 1.1 无向图邻接矩阵的特点
- 2. 有向图的邻接矩阵
-
- 2.1 有向图邻接矩阵的特点
- 3. 网(有权图)的邻接矩阵
- 4. 采用邻接矩阵创建无向网
- 5. 邻接矩阵的优缺点
- 二、邻接表(链式)
-
- 1. 无向图的邻接表
- 2. 有向图的邻接表
-
- 2.1 邻接表
- 2.2 逆邻接表
- 3. 图的邻接表存储表示
- 4. 采用邻接表表示法创建无向图
- 5. 邻接表表示法的优缺点
- 6. 邻接矩阵与邻接表示法的关系
- 三、十字链表
- 四、邻接多重表
前言
- 由于图的结构比较复杂,任意连个顶点之间都可能存在联系,因此无法以数据元素在存储区中的物理位置来表示元素之间的关系,即图没有顺序存储结构,但是可以借助二维数组来表示元素之间的关系,即邻接矩阵表示法。
- 另一方面,由于图的任意两个顶点减都可能存在关系,因此,用链式存储表示图是很自然的事情,图的链式存储方式有多种,有邻接表、十字链表、邻接多重表。
重点介绍
- 邻接矩阵(数组)表示法。
- 邻接表(链式)表示法。
一、邻接矩阵(数组)表示法
建立一个顶点表(记录各个顶点的信息)和一个邻接矩阵(表示各个顶点之间的关系)
- 假设图 A = (V,E) 有 n 个顶点,则:

- 图的邻接矩阵是一个二维数组 A.arcs[n][n],定义为:

1. 无向图的邻接矩阵
图有 n 个顶点,这个邻接矩阵就用 n x n来表示。
因为要描述任意两个顶点之间的关系,任意两个顶点都需要描述它们两个之间有没有边。
下图有五个顶点,那么就需要一个 5x5的方阵。
- 如果两个顶点之间存在邻接(有边)关系,那么邻接矩阵的值就是 1,反之为 0。

- 先观察 V1,V1到V2、V4有边记为1,其余顶点没有边记为0。

- 观察 V2,V2 到 V1、V3、V5 都有边记为1,其余记为0。

- 之后再观察 V3、V4、V5 到其余各顶点的情况,最后就得到了这个图的邻接矩阵。

1.1 无向图邻接矩阵的特点
- 对角线上的值都是 0。
- 因为对角线上都是每一个顶点和自身之间的关系,顶点没有到自身的边。

- 无向图的邻接矩阵是个对称矩阵。
- 无向图的某两个顶点之间存在边,V1和V2之间存在边,是邻接关系。同理V2和V1之间也存在着边,也是邻接关系。
- 两个顶点之间如果有边,这两个顶点之间互为邻接关系。

- 顶点 i 的度 = 第 i 行(列)中为 1的个数。
- 如:V1 所在的那一行有两个1,所以V1的度(与该顶点相关联的边的数量)为2。
特别:完全图的邻接矩阵中,对角元素为 0,其余为1。
2. 有向图的邻接矩阵
- 首先,矩阵有几行几列任然取决于顶点的个数。
- 在有向图中两个顶点之间的关系是有向的,顶点之间的边称作弧。

矩阵表示
如果存在着由当前顶点发出的弧,就在邻接矩阵当中记录一个1。没有发出弧的顶点在邻接矩阵中的值全为0。
- 从 V1 顶点出发,发出了两条弧,一条弧到 V2,一条弧到 V3,那么就在 V1 行的 V2 列和 V3 列记录一个1,其余记为 0。

- V2 顶点没有发出任何弧,那么从 V2 顶点到其他所有顶点的邻接矩阵的值都为0。

- 剩下的 V3 只发出来一条到 V4 的弧,V4 只发出了一条到 V1 的弧。

注:在有向图的邻接矩阵中
- 第 i 行含义:以结点为 Vi 为尾的弧(即出度边)。
- 第 i 列含义:以结点 Vi 为头的弧(即入度边)。
2.1 有向图邻接矩阵的特点
- 有向图的邻接矩阵可能是不对称的。
- 顶点的出度 = 第 i 行元素之和。顶点的入度 = 第 i 列元素之和。
- V1 的出度就是看矩阵的第一行有多少1。
- V1 的入度就是看矩阵的第一列有多少1。
- 顶点 i 的度 = 第 i 行元素之和 + 第 i 列元素之和。
- 例如V1的度就是V1所在行的两个1加上V1所在列的一个1相加为,V1的度就是3。

3. 网(有权图)的邻接矩阵
网当中的边带有一个有特殊意义的值,这个值称为权值。
将网的邻接矩阵的值定义为:

- 如果两个顶点之间存在着 边/弧,就在矩阵当中记录这两个顶点之间的边的权值。
- 如果两个顶点之间不存在 边/弧,就在矩阵当中记录 ∞。
举个栗子

- 从 V1 出发的弧到各个顶点之间的权值记录为

- 从 V2 出发的弧到其余顶点的权值。

- 以此类推其余顶点到其他各个顶点的值

4. 采用邻接矩阵创建无向网
邻接矩阵的存储表示
- 用两个数组分别存储顶点表(一维数组)和邻接矩阵(二维数组)。
形式定义
//图的邻接矩阵存储表示
#define MaxInt 32767 //表示极大值,即 ∞
#define MVNum 100 //最大顶点数
typedef char VerTexType;//假设顶点的数据类型为字符型
typedef int ArcType;//假设边的权值为整型
typedef struct
{
VerTexType vexs[MVNum];//顶点表
ArcType arcs[MVNum][MVNum];//邻接矩阵
int vexnum;//图的当前点数
int arcnum;//图的当前边数
}AMGraph;
- 无向网都搞定了的话,建立无向图、有向图、有向网只需要稍稍改动就可以了。

算法步骤
- 输入总顶点数和总边数。
- 依次输入点的信息存入顶点表中。
- 初始化邻接矩阵,使每个权值初始化为极大值。
- 构造邻接矩阵。依次输入每条边依附的顶点和其权值,确定两个顶点在图中的位置之后,使相应的边赋予相应的权值,同时使其对城边赋予相同的权值。
算法描述
//采用邻接矩阵表示法,创建无向网 G
Status CreatUDN(AMGrph &G)
{
int i,j,k;
cin >> G.vexnum >> G.arcnum;//输入总顶点数,总边数
//依次输入顶点的信息
for(i = 0;i < G.vexnum;i++)
{
cin >> G.vexs[i]);
}
//初始化邻接矩阵,边的权值
for(i = 0;i < G.vexnum;i++)
{
for(j = 0;j < G.vexnum;j++)
{
G.arcs[i][j] = MAXInt;每个值都先置为极大值
}
}
//构造邻接矩阵
for(k = 0;k < G.arcnum;k++)
{
cin >> v1 >> v2 >> w;//输入一条边依附的顶点及权值
//确定 v1和v2 在 G 中的位置,即顶点数组的下标
i = LocateVex(G,v1);
j = LocateVex(G,v2);
G.arcs[i][j] = w;//边的权值置为 w
G.arcs[j][i] = G.arcs[i][j];//置的对称边的权值为 w
}
return 0;
}
//补充算法,在图中查找顶点
int LocateVex(AMGraph G,VertexType u)
//在图 G 中查找顶点 u ,存在则返回顶点表中的下标,否则返回-1
{
int i;
for(i = 0;i <g.vexnum;i++)
{
if(G.vexs[i] == u)
{
return i;
}
}
return -1;
}
算法分析
- 该算法的时间复杂度是 O(n2)。
- 若要建立无向图,只需要对上述算法做两处改动:
- 一是初始化邻接矩阵时,将边的权值均初始化为 0。
- 二是构造邻接矩阵时,将权值 w 改为常量值 1 即可。
5. 邻接矩阵的优缺点
优点
- 直观、简单、好理解。
- 便于判断啊两个顶点之间是否有边,即根据 A[i][j] = 0 或 1来判断。
- 方便找任一顶点的所有 邻接点(有边直接相连的的顶点)。
- 便于计算各个顶点的度。
- 无向图:对于行(或列)非 0 元素的个数;
- 有向图:对应非 0 元素的个数是“出度”;对应列 非 0 元素的个数为“入度”(行出列入)。
缺点
- 不便于增加和删除顶点。
- 不便于统计边的数目,需要扫描邻接矩阵所有元素才能统计完毕,时间复杂度为 O(n2)。
- 空间复杂度高。
- 如果是有向图:n 个邻接矩阵需要 n2 个单元存储边。
- 如果是无向图:因其邻接矩阵时对称的,所以对规模较大的邻接矩阵可以采用压缩存储的方式,仅存储下三角(或上三角)的元素,这样需要 n(n-1)/2个单元即可。
二、邻接表(链式)
- 邻接表是图的一种链式存储结构。
- 在邻接表中,对图中每个顶点啊 Vi 建立一个单链表,把与 VI 相邻接的顶点放在这个链表中。
- 邻接表中每个单链表的第一个结点存放有关顶点的信息,把这一个结点看成链表的表头,其余结点存放有关边的信息,这样邻接表便由两部分组成:表头结点表和边表

表头结点表
由顶点构成的一维数组称为表头结点表
- 表头结点包括数据域 (data) 和 链域(firstarc)。

- 数据域用来存储顶点 Vi 的名称或其他有关信息。
- 链域是用来指向链表中的第一个结点(即与顶点 Vi 邻接的顶点)。
边表
由表示图中顶点间关系的 2n 个边链表组成
- 边链表中包含邻接点域 (adjvex) 和 链域 (nextarc)。

- 邻接点域(adjvex): 存放与 Vi 邻接的顶点在标表头数组中的下标。
- 如: V1 的下一个邻接的顶点是位于数组下标 3 的 V4 顶点,然后 V1 顶点还与 位于下标 1 的 V2 有一条边。
- 链域(nextarc):链域指示与顶点 Vi 邻接的下一条边的结点。
1. 无向图的邻接表
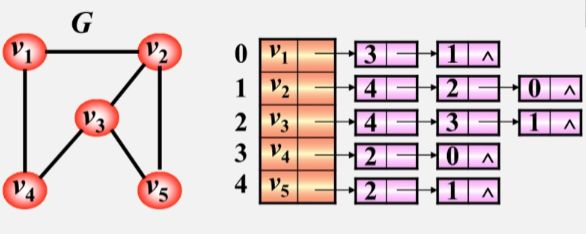
- 图 G 中有 5 个顶点,一维数组就开辟五个空间存储这些顶点。
- 每个元素空间还有一个指针,用来指向与该顶点邻接的第一个邻接点。
- 因为 下标 3 的 V4 是 V1 的邻接点,下标为 1 的 V2 也是 V1 的邻接点,所以 3、1 的位置是可以互换的。
无向图邻接表的特点

- 邻接表不唯一(与某个顶点连接的边的顺序是可变的)。
- 若无向图中有 n 个顶点,e 条边。
- 则其邻接表需要 n 个头结点和 2e 个表结点。
- 所以无向图邻接表需要 O(n + 2e) 的存储空间,适合存储稀疏图。
- 无向图中顶点 Vi 的度为 第 i 个单链表中的结点数。
- 每个顶点有多少个表结点,则和这个顶点关联的边就有几个。
- 如:V1 有 2 个表结点,所以和V1 关联的边有两条,V1 的度为2
2. 有向图的邻接表
2.1 邻接表

- 在有向图中,只需要保存以当前顶点为弧尾的这一条边(每条弧只保存一次,只保存发出的弧)。
- 没有发出弧的顶点的头结点表的链域就置为NULL。
有向图邻接表的特点
- 顶点 Vi 的 出度为第 i 个单链表中的结点个数。
- 顶点 Vi 的入度为整个单链表中邻接点域值是 i-1 的结点个数。
- 如:想求V1的入度,就得去找邻接点域是1-1=0的结点有多少个。
2.2 逆邻接表
- 既然可以用每个结点来存储顶点的出度边,那么当然也能反过来存入度边。
- 在逆邻接表中,单链表当中的结点是入度边

有向图逆邻接表的特点
- 顶点 Vi 的入度为第 i 个单链表中的结点个数。
- 顶点 Vi 的出度为整个单链表中邻接点域是是 i-1 的结点个数。
练习:已知某网的邻接(出边)表,请画出该网络。
从出边可以得知,这是个有向网

- 每一个单链表都是一个以当前顶点为弧尾。
- 如:以顶点1为弧尾的出度弧有两条,分别邻接 2 顶点和 5 顶点。

- 依次找到所有的顶点出发的到其他顶点的弧,有向网就画出来了。

3. 图的邻接表存储表示
顶点的结点结构定义

//顶点结构定义
typedef struct VNode
{//顶点的结构包含两个成员
VerTexType data;//顶点的数据域,用来存储顶点信息
ArcNode* firstarc;//指向边结点的指针
}VNode,AdjList[MVNum];//AdjList 表示邻接表类型
//说明:例如,AdjList v; 相当于:VNode v[MVNum]
弧(边)的结点结构定义

//边结点的结构定义
#define MVNum 100 //最大顶点数
typedef sturct ArcNode //边结点
{
int adjvex;//指向相邻的邻接点位置的下标
struct ArcNode* nextarc;//指向自身结点结构的指针
OtherInfo info;//和边相关的信息,如:权值
}ArcNode;
图的结构定义
typedef struct
{
AdjList vertices;//邻接表类型的数组,存储所有的顶点
int vexnum;//图的当前顶点数
int arcnum;//图的当前弧数
}ALGraph;
邻接表操作举例

4. 采用邻接表表示法创建无向图
算法步骤
- 输入总顶点数和总边数。
- 建立顶点表。
- 依次输入点的信息存入顶点表中。
- 使每个表头结点的指针域初始为NULL。
- 创建邻接表
- 依次输入每条边连接的两个顶点。
- 查找这两个顶点的序号 i 和 j ,建立边结点。
- 将此边结点分别插入到 Vi 和 Vj 对应的两个边链表的头部。
算法描述
//采用邻接表表示法,创建无向图 G
Status CreateUDG(ALGraph &G)
{
cin >> G.vexnum >> G.arcnum;//输入总定点数,总边数
for(i = 0;i < G.vexnum;i++)//输入各点,构造表头结点表
{
cin >> G.vertices[i].data;//输入顶点值
G.vertices[i].firstarc = NULL;/初始化表头结点的指针域为 NULL
}
for(k = 0;k < G.arcnum;k++)//输入各边,构造邻接表,数组中有几个顶点就循环多少次
{
cin >> v1 >> v2;//输入一条边连接的两个顶点
//确定 V1 和 V2 在G中的位置,即顶点G.vertices中的序号
i = LocateVex(G,v1);
j = LocateVex(G,v2);
p1 = nex ArcNode;//生成一个新的边结点*p1
p1->adjvex = j;//邻接带你序号为j
//将新结点*p1插入到顶点Vi的边表头部
p1->nextarc = G.vertices[i].firstarc;
G.vertices[i].firstarc = p1;
p2 = nex ArcNode;//生成另一个对称的新的边结点*p2
p2->adjvex = i;//邻接点序号为i
//将新结点*p2插入到顶点Vj的边表头部
p2->nextarc = G.vertices[j].firstarc;
G.vertices[j].firstarc = p2;
}
return OK;
}
算法分析
- 该算法的时间复杂度是O(n+e)
5. 邻接表表示法的优缺点
优点
- 便于增加和删除顶点。
- 便于统计边的数目,按顶点表顺序扫描所有边表即可得到边的数目,其时间复杂度为 O(n+e)。
- 空间效率高 对于一个具有 n 个顶点 e 条边的图 G:
- 若 G 是无向图:则在其邻接表表示中有 n 个顶点表结点和 2e 个边表结点。
- 若 G 是有向图:则在它的邻接表表示或逆邻接表表示中均有 n 个顶点表结点和 e 个边表结点
缺点
- 不便于判断顶点之间是否有边,要判定 Vi 和 Vj 之间是否有边,就需要扫描第 i 个边表,最坏的情况下要耗费 O(n) 的时间。
- 不便于计算各个顶点的度:
- 对于无向图:在邻接表表示中顶点 Vi 的度是第 i 个边表中的结点个数。
- 对于有向图:在第 i 个边表上的结点个数是顶点 Vi 的出度,但是求 Vi 的入度比较困难。
- 若有向图采用逆邻接表表示,则与邻接表表示相反,求顶点的入度容易,求出度难。
6. 邻接矩阵与邻接表示法的关系
联系

-
邻接表中每个链表对应于邻接矩阵中的一行,链表中结点个数等于一行中非零元素的个数
-
对于邻接矩阵:顶点 Vi 所在的第 i 行有几个 1,就表示顶点 Vi 有几条边。
-
对于邻接表:顶点 Vi 的边结点有几个,则表示 Vi 有几条边。
区别
- 对于任一确定的无向图,邻接矩阵是唯一的(行列号与顶点编号一直),但邻接表不唯一(链接次序与顶点编号无关)。
- 邻接矩阵的空间复杂度为O(n2),而邻接表的空间复杂度为O(n+e)
用途
- 邻接矩阵多用于稠密图;而邻接表多用于稀疏图(边比较少)。
三、十字链表

- 十字链表是有向图的另一种链式存储结构。可以看成是将有向图的邻接表以及逆邻接表结合起来得到的一种新的链表。

- 同时有向图中的每个顶点在十字链表中对应有一个结点,叫做顶点结点,用来存放原来的第一个出、入度边。

- 有向图中的每一条弧对应十字链表中的一个弧结点。

补充

- 顶点结点的第二个元素指向该顶点的入度弧,第三个元素指向该顶点的出度弧。
- 因此顶点结点的第二个元素会指向箭头指向该顶点的那条弧。
- 因此顶点结点的第三个元素会指向箭头来自该顶点的那条弧。
- List item
- 一个弧结点就代表着一条弧。
- 第一个元素(tailvex)代表这个弧来自于哪个顶点。
- 第二个元素(headvex)代表这条弧指向哪个顶点。
- 第三个元素(hlink)指向下一个指向同一个顶点的弧。
- 第四个元素(tlink)指向下一条同一个顶点发出的弧。
四、邻接多重表
邻接表
- 优点:容易求得顶点和边的信息,
- 缺点:某些操作不方便(如:删除一条边需找表示此结边的两个结点)。

邻接多重表

在邻接多重表中,每一条边用一个边结点表示。
- 这样一个边结点就存储了从 0 号位置的 V1 到 1号位置的 V2 之间的边。
- 下次就不用再记录从 V2 到 V1 之间的边了,直接使用这个边结点即可。
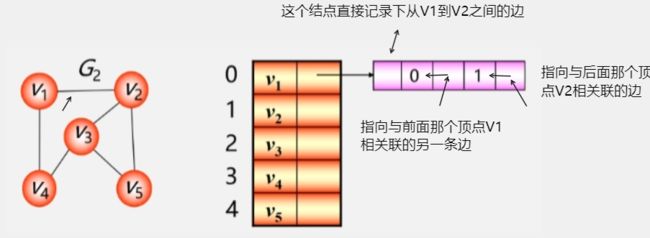
- 从 V1 到 V4 之间还有一条边,继续用一个边结点记录下来。这两条边都是从 0 号位置的 V1 开始的。
- 想找与 V1 相关的边就只需要找到第一条边就行了。

- 之后再找与 V2 相关联的边,V2 - V1 这条边已经有了,不需要再找一次了,直接拿来用,去找其余和 V2 有关联的边。
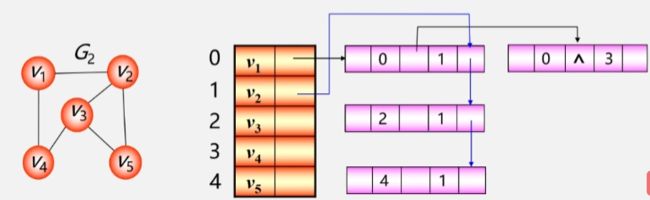
- 依次类推找到所有与其余顶点相关联的边。
