数据治理 | 数据分析与清洗工具:Pandas 数据选取与修改
查看原文:【数据seminar】数据治理 | 数据分析与清洗工具:Pandas 数据选取与修改
我们将在数据治理板块中推出一系列原创推文,帮助读者搭建一个完整的社科研究数据治理软硬件体系。该板块将涉及以下几个模块:
1. 计算机基础知识
(1) 社科研究软硬件体系搭建——虚拟化技术概述与实践
2. 编程基础
(1) 数据治理 | 带你学Python之 环境搭建与基础数据类型介绍篇
(2) 数据治理 | 带你学Python之控制结构与函数
(3) 数据治理 | 带你学Python之面向对象编程基础
(4) 数据治理 | 还在用Excel做数据分析呢?SQL它不香吗
(5) 数据治理 | 普通社科人如何学习SQL?一篇文章给您说明白
(6) 数据治理 | 如何实现SQL数据库的横向匹配
3. 数据采集
(1) 数据治理 | 快速get数据采集技能:理论知识篇
(2) 数据治理 | 数据采集实战:静态网页数据采集
(3) 数据治理 | 数据采集实战:动态网页数据采集
4. 数据存储
(1) 安装篇:数据治理 | 遇到海量数据stata卡死怎么办?这一数据处理利器要掌握
(2) 管理篇: 数据治理 | 多人协同处理数据担心不安全?学会这一招,轻松管理你的数据团队
(3) 数据导入:数据治理 | “把大象装进冰箱的第二步”:海量微观数据如何“塞进”数据库?
(4) 数据治理|Stata如何直连关系型数据库
5. 数据清洗
(1) 数据治理 | 数据清洗必备 — 正则表达式
(2) 数据治理 | 数据分析与清洗工具:Pandas基础
(3)本期内容:数据治理 | 数据分析与清洗工具:Pandas数据选取
6. 数据实验室搭建
目录
Part 1 前言
Part 2 数据选取
1、列选取
(1) 使用 Excel
(2) 使用 Pandas
2、行选取
(1) 使用 Excel
(2) 使用 pandas
3、局部选取
(1) 使用 Excel
(2) 使用 pandas
Part 3 修改选取的数据值
1、按列修改
(1) 使用 Excel
(2) 使用 Pandas
(1) 使用 Excel
(2) 使用 Pandas
(1) 使用 Excel
(2) 使用 Pandas
2、精准修改
(1) 使用 Excel
(2) 使用 Pandas
3、修改单个值
Part 4 总结&预告
Part 1 前言
近期的技术文章中,我们将会为大家介绍 Python 中数据分析与数据清洗的重要模块—— Pandas。在上期文章中,我们为大家讲解了 Pandas 基础知识,包括二维数据类型 DataFrame 的一些属性和方法,以及使用 Pandas 读取 csv数据、Excel表为 DataFrame;将 DataFrame 数据写入本地,保存为csv 数据或者 Excel 表等。本期文章将会介绍 Pandas 模块的数据选取功能,学会它,你将可以根据数据索引随意选取你想要的数据,更有价值的是,我们可以为所选取出来的部分数据重新赋值来达到修改数据值的目的。
接下来的讲解,我们会将 Pandas 和 Excel 的操作方法进行对比,方便大家直观感受操作流程和结果。
本文中所有 Python 代码均在集成开发环境 Visual Studio Code (VScode) 中使用交互式开发环境 Jupyter Notebook 中编写。
Part 2 数据选取
大家都有过裁剪手机截图的经验,一张屏幕截图中只有一部分图像是我们想要保留的,这时候我们需要手动裁剪整张截图,把想要的部分截取出来单独生成一个图片。这种操作就类似于二维表格数据的数据选取,不同之处在于裁剪图片使用的是我们的视觉判断,表格数据的选取使用的是表格索引(通俗来说就是列名称和行序号)。同时,数据选取不仅可以获取局部数据,还可以修改数据中指定位置的数据值。
为了直观的查看数据选取的效果,我们使用 Python 生成一个适合展示数据选取效果的 DataFrame,代码和数据如下:
# 导入 pandas 模块,取别名为 pd
import pandas as pd
data_list = [['A0', 'B0', 'C0', 'D0', 'E0', 'F0', 'G0', 'H0', 'I0', 'J0'],
['A1', 'B1', 'C1', 'D1', 'E1', 'F1', 'G1', 'H1', 'I1', 'J1'],
['A2', 'B2', 'C2', 'D2', 'E2', 'F2', 'G2', 'H2', 'I2', 'J2'],
['A3', 'B3', 'C3', 'D3', 'E3', 'F3', 'G3', 'H3', 'I3', 'J3'],
['A4', 'B4', 'C4', 'D4', 'E4', 'F4', 'G4', 'H4', 'I4', 'J4']]
# 生成 DataFrame
data = pd.DataFrame(data_list, columns=list('ABCDEFGHIJ'))
# 打印上面生成的数据
data

下面我们将会使用上面生成的 data 来演示数据选取的相关操作。同时我们生成一份相同的 Excel 数据,然后对比两个工具在同一个操作中的
1、列选取
(1) 使用 Excel
在 Excel 工具中选取需要的数据列是非常简单的,只需要简单的复制粘贴就可以完成。选取不相邻的数据列时,先选取一个区域,再按住【ctrl】键,就可以继续选取其他区域。如下图所示:

(2) 使用 Pandas
当在一张表中,我们需要保留所有的数据行,但却只需要保留一部分列(字段)的时候,就意味着只需要对数据列做选取,即选取我们需要的数据列。在 Pandas 中,常见的表示一列的方法有以下两种:
# 方法1:DataFrame.column, 数据在前,列名在后,中间使用‘.’来连接
data.A
# 方法2:DataFrame[columns], 数据在前,后跟列名,列名使用中括号包裹
data['A']
以上两种方法得到的结果都是一维数据 Series,大多数情况下,我们都使用上述方法中的第二种来表示数据列,因为第二种方法不仅可以表示数据的某一列,还可以可以表示多个数据列。方法是把一个包含列名的列表传入方法2中的中括号,假设我们只需要获取数据的A、B、C 三列,那么就可以像下面这样操作:
# 由 data 中三个列的列名组成的列表
columns = ['A','B','C']
# 等同于 data[['A','B','C']]
data[columns]

这样就可以取出数据 data 的 A,B,C 三列。这里需要注意,由于多列数据属于二维数据,所以它的数据类型是 DataFrame,这样就方便我们保存选取后的数据。另外,我们也可以通过这种方式调整数据列之间的排列顺序。只需要将排序后的列名称存放在列名列表中即可,这里不再多赘述。
上期文章我们介绍过删除数据列的 drop 方法(传送门:数据治理 | 数据分析与清洗工具:Pandas 基础)。不难理解,既然可以通过取出所需数据列的方法得到数据,也可以通过删除不需要的数据列来保留需要的数据列,假设我们需要保留数据中的 A、B、C、D、E 列,那么可以通过删除 F、G、H、I、J 列来实现。操作代码如下:
# 将删除多余列的新数据重新赋值给变量 Target,这样原始数据 data 就不会改变
Target = data.drop(['F','G','H','I','J'], axis=1)
Target

2、行选取
(1) 使用 Excel
在 Excel 选取行的操作与选取列的操作类似,只需要选中数据行最左侧的数字序号就可以选中整行数据,最后复制粘贴即可,如下图所示:

(2) 使用 pandas
行选取的含义与前面的列选取类似,只不过行选取操作的是数据行,会保留所有列。Pandas 中没有使用行索引(默认从 0 开始)直接表示一行数据的快捷方法。因为表示数据行的快捷方法只接收一个范围参数,当给定的范围参数长度为 1 时,才能表示一行数据。假设我们需要数据 data 中行索引为1 到 3 的行数据,则操作代码如下:
# 必须传入一个范围,使用英文冒号隔开
# 该区间左闭右开,因此右边要比 3 大 1,即为 4
data[1:4]
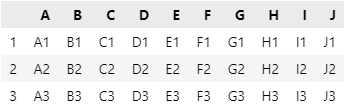
这样就可以获取所需要的行数据。需要注意的是,当使用行选取只获取一行数据时,尽管所得数据是一维数据,但是它的数据类型依然是 DataFrame:
# 左闭右开区间,包含 0,但不包含 1,所以只表示 1 行。
data[0:1]

同样地,也可以通过删除不需要的行数据来保留需要的行数据。假设依然是获取行索引为1 到 3 的行数据,则只需要删除行索引为 0 和 4 的行数据即可,操作代码如下:
# 将删除多余列的新数据重新赋值给变量 Target,这样原始数据 data 就不会改变
Target = data.drop([0,4], axis=0)
Target

3、局部选取
(1) 使用 Excel
依然可以使用框选区域,然后复制粘贴的方式来完成,如下图所示:

这种方式使用的是视觉选取所需的行列,如果需要使用列名称来进行数据选取的话,Excel 并不如 Pandas 方便,下面来介绍 Pandas 的操作。
(2) 使用 pandas
列选取和行选取仅支持单独操作列数据或者行数据。当需要同时选取行和列时,就需要同时使用行索引和列索引,或者同时使用列序号和行序号。这两种情况分别对应着两种数据选取方法 loc 和 iloc 。与 Excel 数据选取存在极大不同的是,Pandas 选取的数据都是有索引的,包括列索引(即列名称),这对查看数据的帮助非常大。
1) loc
pd.DataFrame.loc 方法可以接收的参数形式很多,这里介绍常见的三种参数方式和使用效果。首先,loc 方法接收两个参数,参数之间用逗号分隔。其中第一个参数表示行的范围,第二个参数表示列的范围。这样就可以灵活地查找二维数据表中的任何位置、任何矩形区域的数据。需要注意的是,这两个参数的形式有多种,既可以是单个索引,也可以是一个列表或者索引范围(类似前面讲到的行选取中的范围参数,例如:1:4,实际上是一个 slice 切片对象,为了容易理解,我们称其为范围),并且两个参数的形式可以随意组合。下面将演示常用的参数形式。
① 参数为索引值
场景1:获取 data 中行索引为 0, 列名称为 A 的数据值。
# 行范围参数和列范围参数之间使用逗号分隔 data.loc[0, 'A'] # 行范围是 0, 列范围是 A # 输出为: 'A0'当行范围参数和列范围参数都是单个索引时,可以唯一确定数据的值,即目标既不是 Series,也不是 DataFrame, 而是一个值,该值的数据类型就是数据中对应数据的类型。
② 参数为索引列表
场景2:获取 data 中,行索引在列表 [0,2,4] 中,列名称在列表 ['B','D','J'] 中的所有数据。
data.loc[[0,2,4], ['B','D','J']]

前面说到,行范围参数和列范围参数的类型可以是不一样的,例子如下:
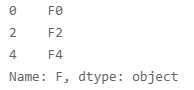
场景3:获取 data 中,行索引在列表 [0,2,4] 中,列名称为 F 的所有数据。
data.loc[[0,2,4], 'F']
得到的数据类型为 Series
③ 参数为索引范围
注意:loc 方法中的范围区间参数不再是左闭右开,而是左闭右闭。
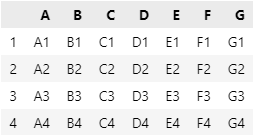
场景4:获取 data 中行索引为 从 1 到 4(包含4),列名称为 从 A 到 G 的所有数据。
data.loc[1:4, 'A':'G']
参数形式可以随意混用。
场景5:获取 data 中行索引为 从 3 ,列名称为 从 A 到 G 的所有数据。
# 方法 1:行索引使用单个索引 data.loc[3, 'A':'G']
# 方法 2:行索引使用范围参数 data.loc[3:3, 'A':'G']
# 方法 3:行索引使用列表参数,但只包含单个值 data.loc[[3], 'A':'G']
# 方法 4:行索引,列索引都是用使用列表参数,但都只包含单个值 # 尽管你只有一个值,其类型依然为二维表 DataFrame data.loc[[3], ['C']]




通过以上四种不同的参数组合,可以得出结论:当只有一个参数是单个索引 (或者单个列名) 时,得到的数据类型是一维数据 Series;两个参数都是单个索引时,得到的数据是单个数据(对应位置的数据)。
2) iloc
pd.DataFrame.iloc方法可以接收的参数形式也有很多,这里同样介绍常见的三种参数方式和使用效果。同样地,iloc 方法也接收两个参数,参数之间用逗号分隔。但是与 loc 方法完全不相同的是,iloc 方法的参数值既不是行索引,也不是列名称,而是行的整数序号(第 0 行,第 1 行,第 2 行……,与行索引无关)和列的整数序号(第 0 列,第 1 列,第 2 列……,与列名称无关)。参数形式上与 loc 方法类似,即单个序号,存放序号的列表和序号范围。两个参数的类型也可以随意组合。
为了直观地理解 iloc 中序号的使用方法,我们将数据 data 索引和序号区分开来。将原来的数字行索引更改为汉字索引,代码和效果如下:
data.index = ['第零列','第一列','第二列','第三列','第四列']
data
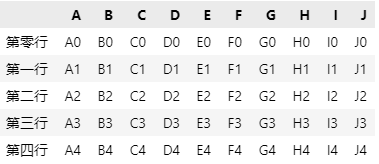
同时下文中,行序号也会使用从 0 开始算起的原则。
① 参数为序号值
场景6:获取数据 data 中第 0 行,第 4 列的数据值。
# 序号和索引一样,同样是从 0 开始 # A 列的列序号是 0,那么 E 列的列序号就是 4 data.iloc[0,4] # 输出得到:'E0'查看该值在数据中的位置:
这样就可以理解,我们通俗意义上理解的第 1 行,第 1 列在 Python 的二维数据表中所对应的列序号却是第 0 行,第 0 列,这和列表的索引规则一模一样。

② 参数为序号列表
场景7:获取数据 data 中第 0、2 行,第 4、5、6 列的所有数据。
data.iloc[[0,2], [4,5,6]]
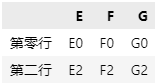
③ 参数为序号范围
场景8:获取数据 data 中所有行,第 3 列的所有数据。
# 写法 1: # 根据左闭右开原则,0:5 对应的范围是 0,1,2,3,4,即 data 中所有行的序号 data.iloc[0:5, 3]
根据我们在前面
loc方法中总结的规则,因为两个范围参数中其中一个为单个序号,所以所得数据的类型是一维数据 Series。# 写法 2: data.iloc[:, 3]

写法 2 中的所得结果与写法 1 所得结果完全一样,但是参数形式却大不相同。可以看出,写法 1 的范围参数和写法 2 中的范围参数存在差异。分别为 0:5 和 :,这是因为这里的范围参数是有省略写法的,左边的 0 是范围起点,省略时就代表从最开始的位置开始计算;右边的 5 是范围终点(不包含本身),省略时就代表计算到最末尾的位置(包含最末尾的位置)。同样地,第二个范围参数也可以这样表示,例如:
场景9:获取数据 data 中前 3 行,后 4 列的所有数据。
# 倒数第 4 列的列序号是 6,所以列序号从 6 开始算起 data.iloc[:3, 6:]

iloc 方法和 loc 方法的使用方式是极其类似的,区别在于一个根据序号取值,一个根据索引取值。但是参数的传入方式和所得数据的类型是完全一样的,这里就不再过多举例说明了。
Part 3 修改选取的数据值
取出部分数据或许并不是我们真正的目的,我们可以取出任意部分的数据,同时也可以为取出的数据重新赋值(修改原始的数据值)。重新赋值后,新的值将会替换原始的值,直接应用在原始数据上,也就是说,修改数据的操作是不可逆的。修改数据值的方式上,我们既可以修改单个数据值(最最最常用的修改数据值的方法),也可以修改一部分数据区域的值。
下面继续使用数据 data 来说明修改数据值的用法。
我们依然使用上面讲到的 场景9:数据 data 中前 3 行,后 4 列的所有数据。
场景 9 中,所得数据是一个 3 行 4 列二维数据 Dataframe:

1、按列修改
上例所选数据共 4 列,我们可以分别为这四列的三行数据赋值,但是一列中的值必须全部一样。
(1) 使用 Excel
复制一个数量与所选区域列数相同的一行数据,每个值将会对应在所选区域的列中,如图:
(2) 使用 Pandas
只需要将各列要赋予的值存放在一个元组 (tuple) 中,再赋值给区域数据即可,例如:
# 为这四列数据分别赋值 1, 'new', 100, 100-1 # 元组中数据的数量必须和所选区域的列数量一样 data.iloc[:3, 6:] = (1,'new', 100, 100-1) data


可以将一个区域的所有值都修改为同一个值:
(1) 使用 Excel
只需要复制一个值,然后将它粘贴在所选区域即可。如图:
(2) 使用 Pandas
将一个值赋值给所选区域:
data.iloc[:3, 6:] = 'same' data


也可以一次性修改一整列数据的值:
(1) 使用 Excel
复制一个值,然后将它粘贴在数据列即可。当数据行数很多时,可以先点击一列的第一个数据值,然后按住【ctrl】+【shift】,随后按一下方向下键,就可以选中这一列的所有数据值,而不会将下方的空白区域一并选中。如图:
(2) 使用 Pandas
将一个值赋值给一个数据列即可,这种方法还可以生成一个新的列。
data['D'] = 'D列' data
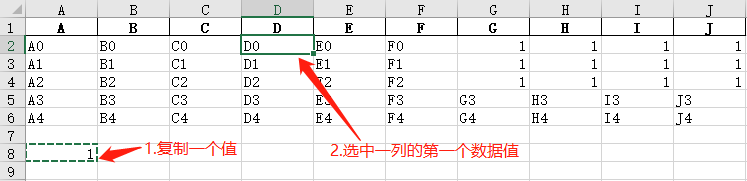

2、精准修改
如果不希望将一列中所有的值都设置为一样,而是希望每一个值都会被修改成我们想要的数据值。
(1) 使用 Excel
首先复制一个与要修改的数据区域形状一样数据区域,然后粘贴到要修改数据区域就可以了,如图:
(2) 使用 Pandas
将一个和要修改的数据区域形状一样的列表或者 array 赋值给所选数据区域。例如:
data.iloc[:3, 6:] = [[1, 'x', 0, 'x'], [1, 0, 'x', 0], [1, 'x', 0, 'x']] data


3、修改单个值
一次性只修改数据一个值,虽然效率不高,但是这是最常用的修改数据的方法。对应的 Excel 操作就不需要做介绍了,大家都会。我们直接介绍 Pandas 的方法。
场景 10:修改行索引为 "第二行", 列索引(列名称)为 B 的数据值为 'NB'。
data.loc['第二行', B] = 'NB' data

Excel 与 Pandas 的差异
综上,在 Excel 中完成这些数据选取和修改操作是简单的,只需要复制粘贴就可以完成。与 Pandas 相比,两者的自由度都比较高。但是在大数据集面前,Pandas 的优势就会凸显出来,在大数据集的分选取、修改和分析中,Pandas 都更加实用。在配合 Python 中的循环操作,Pandas 的自由性和功能会更强大。但不可否认的是,Excel 在小数据的简单处理方面会更加方便。
最后,我们将最终得到的数据保存为 Excel 表。
# 将数据保存在桌面文件夹,命名为 【数据选取.xlsx】,xlsx是 Excel数据的后缀名
# 多输入一个参数 index=False,表示保存数据时不会将数据的行索引也存入 Excel
data.to_excel(r'C:\Users\Ren\Desktop\数据选取.xlsx', index=False)
使用 Excel 打开保存的数据,效果如下图。在 Excel 中,字符类型和数字类型在 Excel 中单元格中的位置是不一样的,我们在图中也可以看出,DataFrame 数据保存为 Excel 数据时,会将数据类型保存为 Excel 中对应的数据类型。

Part 4 总结&预告
本期文章中,我们介绍了数据选取功能的使用。我们不仅可以通过数据的行列索引或者行列序号获取数据,还可以修改所选取数据区域的数据值。数据选取的使用场景非常多,学习完这一部分之后,我们就可以为学习更实用的数据分析技巧打下基础。
下期文章我们将使用真实社科数据来介绍 Pandas 中根据条件来查询数据的方法,教你像使用数据库查询一样在数据表中查询符合相关条件的数据。
