K8s in Action 阅读笔记——【13】Securing cluster nodes and the network
K8s in Action 阅读笔记——【13】Securing cluster nodes and the network
13.1 Using the host node’s namespaces in a pod
Pod中的容器通常在不同的Linux名称空间下运行,这使得它们的进程与其他容器或节点默认名称空间下运行的进程隔离开来。
例如,我们学习到每个Pod都拥有自己的IP和端口空间,因为它使用其自己的网络名称空间。同样,每个Pod也拥有自己的进程树,因为它有自己的PID名称空间,并且它还使用自己的IPC名称空间,只允许在同一Pod中的进程通过IPC(Inter-Process Communication)机制相互通信。
13.1.1 Using the node’s network namespace in a pod
某些Pod(通常是系统Pod)需要在主机的默认名称空间中运行,允许它们查看和操作节点级别的资源和设备。例如,一个Pod可能需要使用节点的网络适配器而不是自己的虚拟网络适配器。可以通过将Pod规范中的hostNetwork属性设置为true来实现这一点。
在这种情况下,Pod使用节点的网络接口而不是它自己的网络接口,如图13.1所示。这意味着Pod不会获得自己的IP地址,如果它运行绑定端口的进程,该进程将绑定到节点的端口。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eVGECMzg-1686405749288)(https://note-image-1307786938.cos.ap-beijing.myqcloud.com/typora/image-20230610150830900.png)]
运行Pod后,可以使用以下命令查看其确实使用主机的网络名称空间(例如,它可以看到所有主机的网络适配器)。
kubectl exec pod-with-host-network -- ifconfig
cni0 Link encap:Ethernet HWaddr 0E:DB:96:27:9A:29
......
docker0 Link encap:Ethernet HWaddr 02:42:5D:5E:AE:54
inet addr:172.17.0.1 Bcast:172.17.255.255 Mask:255.255.0.0
......
ens3 Link encap:Ethernet HWaddr 1E:00:49:00:00:59
inet addr:33.33.33.108 Bcast:33.33.33.255 Mask:255.255.255.0
......
flannel.1 Link encap:Ethernet HWaddr FA:36:23:30:02:19
inet addr:10.244.1.0 Bcast:0.0.0.0 Mask:255.255.255.255
......
ifb0 Link encap:Ethernet HWaddr A6:98:4B:6B:61:AB
inet6 addr: fe80::a498:4bff:fe6b:61ab/64 Scope:Link
......
lo Link encap:Local Loopback
......
tunl0 Link encap:UNSPEC HWaddr 00-00-00-00-00-00-00-00-00-00-00-00-00-00-00-00
......
veth3d45ae3c Link encap:Ethernet HWaddr 92:E5:55:02:3D:36
......
当Kubernetes控制面组件作为Pod部署时,会发现这些Pod使用了hostNetwork选项,让它们表现得好像它们没有运行在Pod中一样。
13.1.2 Binding to a host port without using the host’s network namespace
允许Pod绑定到节点的默认名称空间中的端口,但仍具有自己的网络名称空间。这是通过在Pod规范的spec.containers.ports字段中使用容器端口(hostPort)属性来实现的。
不要将使用hostPort的Pod与通过NodePort服务暴露的Pod混淆。它们是两个不同的东西,如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KFL4zOlz-1686405749290)(https://note-image-1307786938.cos.ap-beijing.myqcloud.com/typora/image-20230610152136088.png)]
首先,在图中你会注意到,当一个Pod使用hostPort时,连接到节点的端口直接转发到在该节点上运行的Pod上,而使用NodePort服务时,连接到节点的端口将被转发到一个随机选择的Pod上(可能在另一个节点上)。另一个区别是,使用hostPort的Pod只会在运行此类Pod的节点上绑定节点的端口,而NodePort服务会在所有节点上绑定端口,即使在不运行此类Pod的节点上(如图13.2中的节点3上)也会绑定端口。
重要的是要理解,如果一个Pod使用特定的hostPort,每个节点只能安排一个该Pod的实例,因为两个进程不能绑定到同一个host端口。调度器在调度Pod时会考虑到这一点,因此不会将多个Pod调度到同一节点上,如图13.3所示。如果有三个节点并想要部署四个Pod副本,则只会安排三个Pod(一个Pod将保持挂起状态)。

让我们看看如何在Pod的YAML定义中定义hostPort。下面的示例显示了运行的kubia Pod并将其绑定到节点的端口9000的YAML:
# pod-with-host-network.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-with-host-network
spec:
hostNetwork: true
containers:
- name: main
image: alpine
command: ["/bin/sleep", "999999"]
创建此Pod后,可以通过该Pod调度的节点的9000端口访问它。如果有多个节点,则会看到在其他节点上无法通过该端口访问Pod。
$ curl http://yjq-k8s4:9000
You've hit kubia-hostport
hostPort功能主要用于公开系统服务,这些服务使用DaemonSet部署到每个节点。
13.1.3 Using the node’s PID and IPC namespaces
与hostNetwork选项类似的是hostPID和hostIPC Pod规范属性。当你将它们设置为true时,Pod的容器将使用节点的PID和IPC名称空间,分别允许在容器中运行的进程查看节点上的所有其他进程或通过IPC与它们通信。参见以下示例。
# pod-with-host-pid-and-ipc.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-with-host-pid-and-ipc
spec:
hostPID: true
hostIPC: true
containers:
- name: main
image: alpine
command: ["/bin/sleep", "999999"]
你应该还记得,Pod通常只能看到它们自己的进程,但是如果你运行此Pod,然后在容器内列出进程,你会看到运行在主机节点上的所有进程,而不仅仅是在容器中运行的进程,如以下示例所示。
# kubectl exec pod-with-host-pid-and-ipc -- ps aux | head -10
PID USER TIME COMMAND
1 root 5h43 {systemd} /sbin/init
2 root 0:06 [kthreadd]
3 root 0:00 [rcu_gp]
4 root 0:00 [rcu_par_gp]
6 root 0:00 [kworker/0:0H-kb]
8 root 0:00 [mm_percpu_wq]
9 root 3:22 [ksoftirqd/0]
10 root 52:55 [rcu_sched]
11 root 0:56 [migration/0]
通过将hostIPC属性设置为true,Pod的容器中的进程也可以通过Inter-Process Communication与运行在节点上的所有其他进程通信。
13.2 Configuring the container’s security context
除了允许Pod使用主机的Linux名称空间之外,还可以通过securityContext属性在Pod及其容器上配置其他安全相关功能,可以直接在Pod规范下指定,也可以在各个容器的规范中指定。
配置安全上下文允许你执行各种操作:
- 指定容器中的进程将以哪个用户(用户ID)身份运行。
- 防止容器以root用户身份运行(容器默认以容器镜像中定义的用户身份运行,因此可能希望防止容器以root用户身份运行)。
- 以特权模式运行容器,使其对节点的内核具有完全访问权限。
- 通过添加或删除权限,配置细粒度的权限,与在特权模式下给予容器所有可能权限的方式相反。
- 设置SELinux(安全增强Linux)选项,以对容器进行强制锁定。
- 防止进程写入容器的文件系统。
首先,运行一个默认的安全上下文选项的Pod(完全不指定它们),这样你就可以看到与自定义安全上下文的Pod相比它的行为如何:
$ kubectl run pod-with-defaults --image alpine --restart Never -- /bin/sleep 999999
pod/pod-with-defaults created
现在让我们看看容器运行的用户和组ID,以及它所属的组。你可以通过在容器内运行id命令来查看:
$ kubectl exec pod-with-defaults -- id
uid=0(root) gid=0(root) groups=0(root), 1(bin), 2(daemon), 3(sys), 4(adm), 6(disk), 10(wheel), 11(floppy),20(dialout),26(tape),27(video)
容器以用户ID(uid)0,也就是root,和组ID(gid)0(也是root)运行。它还是多个其他组的成员。
容器运行的用户是指定在容器镜像中的。在一个Dockerfile中,使用USER指令来实现这一点。如果省略了这一指令,则容器以root身份运行。
现在,将运行一个容器以不同用户身份运行的Pod。
13.2.1 Running a container as a specific user
要在容器镜像中内嵌的用户ID不同的情况下运行pod,需要设置pod的securityContext.runAsUser属性。通过如下的示例,你可以将容器运行为用户名为guest 的用户,该用户在alpine容器镜像中的用户ID为405。
# pod-as-user-guest.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-as-user-guest
spec:
containers:
- name: main
image: alpine
command: ["/bin/sleep", "999999"]
securityContext:
runAsUser: 405
现在,为了查看runAsUser属性的效果,在这个新的pod中运行id命令,就像之前那样:
$ kubectl exec pod-as-user-guest -- id
uid=405(guest) gid=100(users) groups=100(users)
可以看到,容器正在以guest用户身份运行。
13.2.2 Preventing a container from running as root
假设你不关心容器以哪个用户身份运行,但你仍然希望防止其以root身份运行,该怎么办呢?
假设你部署了一个pod,其中包含了一个使用了Dockerfile中的USER daemon指令的容器镜像,它使得容器在daemon用户下运行。那如果一个攻击者可以访问你的镜像注册表并在相同标签下推送一个不同的镜像会怎么样呢?攻击者的镜像被配置为root用户下运行。当Kubernetes调度了一个你的pod的新实例后,Kubelet会下载攻击者的镜像,并运行其中的所有代码。
尽管容器大多数情况下与主机系统相互隔离,但以root身份运行容器的进程仍然被认为是一种糟糕的做法。例如,当主机目录被挂载到容器中时,如果在容器中运行的进程以root身份运行,它将完全访问挂载的目录,但如果以非root身份运行,则不会。
为了防止前面描述的攻击场景,你可以指定pod的容器需要以非root身份运行,如下所示:
# pod-run-as-non-root.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-run-as-non-root
spec:
containers:
- name: main
image: alpine
command: ["/bin/sleep", "999999"]
securityContext:
runAsNonRoot: true # 不允许以root身份运行
如果你部署这个pod,它将会被调度但不被允许运行:
$ kubectl get pod pod-run-as-non-root
NAME READY STATUS RESTARTS AGE
pod-run-as-non-root 0/1 CreateContainerConfigError 0 92s
# Error: container has runAsNonRoot and image will run as root
13.2.3 Running pods in privileged mode
有时候,pod需要能够执行其所在节点的所有操作,例如使用受保护的系统设备或其他内核特性,这是常规容器无法访问的。
其中一个这样的pod的例子是kube-proxy pod,它需要修改节点的iptables规则以使服务正常工作。
为了完全访问节点的内核,pod的容器运行在特权模式下。这可以通过将容器的securityContext属性中的privileged权限设置为true来实现。你可以使用下面清单中的YAML创建一个特权的pod:
# pod-privileged.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-privileged
spec:
containers:
- name: main
image: alpine
command: ["/bin/sleep", "999999"]
securityContext:
privileged: true
现在,你可以部署这个pod并与之前运行的非特权pod进行比较。
如果你熟悉Linux,你可能知道它有一个特殊的文件目录称为/dev,它包含了系统上所有设备的设备文件。这些不是磁盘上的常规文件,而是用于与设备通信的特殊文件。现在,我们通过列出非特权容器在它的/dev目录中可见的文件来查看哪些设备可见,如下:
$ kubectl exec -it pod-with-defaults -- ls /dev
core null shm termination-log
fd ptmx stderr tty
full pts stdin urandom
mqueue random stdout zero
该清单显示了所有设备。设备列表相当短。现在,将其与下面的清单进行比较,该清单显示了特权pod可以看到的设备文件:
$ kubectl exec -it pod-privileged -- ls /dev
autofs snapshot tty45 ttyS30
bsg snd tty46 ttyS31
btrfs-control sr0 tty47 ttyS4
bus stderr tty48 ttyS5
core stdin tty49 ttyS6
cpu stdout tty5 ttyS7
cpu_dma_latency termination-log tty50 ttyS8
cuse tty tty51 ttyS9
dri tty0 tty52 ttyprintk
ecryptfs tty1 tty53 udmabuf
fb0 tty10 tty54 uhid
fd tty11 tty55 uinput
full tty12 tty56 urandom
fuse tty13 tty57 userio
hidraw0 tty14 tty58 vcs
hpet tty15 tty59 vcs1
hwrng tty16 tty6 vcs2
i2c-0 tty17 tty60 vcs3
input tty18 tty61 vcs4
......
可以看到设备列表比之前长得多。事实上,特权容器可以看到主机节点的所有设备。这意味着它可以自由地使用任何设备。
13.2.4 Adding individual kernel capabilities to a container
与让一个容器拥有特权和无限权限相比,从安全的角度来看,更为安全的方法是仅赋予它访问它实际需要的内核功能。Kubernetes允许你为每个容器添加能力或删除其中的一部分,这使你可以微调容器的权限并限制攻击者潜在入侵的影响。
例如,通常情况下容器无法更改系统时间(硬件时钟的时间)。你可以通过尝试在pod-withdefaults pod中设置时间来确认这一点:
$ kubectl exec -it pod-with-defaults -- date +%T -s "12:00:00"
date: can't set date: Operation not permitted
12:00:00
如果你想允许容器更改系统时间,可以在容器能力列表中添加一个称为CAP_SYS_TIME的能力,如下所示:
# pod-add-settime-capability.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-add-settime-capability
spec:
containers:
- name: main
image: alpine
command: ["/bin/sleep", "999999"]
securityContext:
capabilities:
add:
- SYS_TIME
在这个新创建的pod的容器中运行相同的命令,系统时间会被成功更改。
像这样添加能力要比使用privileged:true给容器赋予完全的特权要好得多。但是这需要你了解每个能力的作用。
Linux内核能力的列表可以在Linux手册中找到。
13.2.5 Dropping capabilities from a container
之前你已经了解如何添加能力,但你也可以取消容器的某些可能存在的能力。例如,默认赋予容器的能力之一是CAP_CHOWN能力,它允许进程更改文件系统中的文件所有权。
你可以通过将pod-with-defaults pod中/tmp目录的所有权更改为guest用户来验证这一点,例如:
# pod-drop-chown-capability.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-drop-chown-capability
spec:
containers:
- name: main
image: alpine
command: ["/bin/sleep", "999999"]
securityContext:
capabilities:
drop:
- CHOWN
为了防止容器这样做,你需要通过在容器的securityContext.capabilities.drop属性下列出该能力,如下例所示,来撤销该能力:
$ kubectl exec pod-drop-chown-capability -- chown guest /tmp
chown: /tmp: Operation not permitted
command terminated with exit code 1
通过删除CHOWN能力,你不允许在此pod中更改/tmp目录的所有者。
13.2.6 Preventing processes from writing to the container’s filesystem
防止容器向其文件系统中写入数据,通过将容器的securityContext.readOnlyRootFilesystem属性设置为true可以实现点,如下例所示:
# pod-with-readonly-filesystem.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-with-readonly-filesystem
spec:
containers:
- name: main
image: alpine
command: ["/bin/sleep", "999999"]
securityContext:
readOnlyRootFilesystem: true
volumeMounts:
- name: my-volume
mountPath: /volume
readOnly: false
volumes:
- name: my-volume
emptyDir:
当你部署这个pod时,容器是作为root用户运行的,具有写入根目录的权限,但尝试在根目录中写入文件会失败:
$ kubectl exec -it pod-with-readonly-filesystem -- touch /new-file
touch: /new-file: Read-only file system
另一方面,允许向挂载的卷中写入数据:
$ kubectl exec -it pod-with-readonly-filesystem -- touch /volume/newfile
$ kubectl exec -it pod-with-readonly-filesystem -- ls -la /volume/newfile
-rw-r--r-- 1 root root 0 Jun 10 12:58 /volume/newfile
当你将容器文件系统设置为只读时,你可能需要在应用程序写入的每个目录中都挂载一个卷(例如,日志、磁盘缓存等)。
为了增强安全性,在生产环境中运行pod时,请将容器的readOnlyRootFilesystem属性设置为true。
13.2.7 Sharing volumes when containers run as different users
在第6章中,我们解释了如何使用卷在pod的容器之间共享数据。你可以在一个容器中写入文件并在另一个容器中读取文件,没有任何问题。
但这仅仅是因为两个容器都作为root用户运行,它们可以完全访问卷中的所有文件。现在想象一下使用我们之前解释过的runAsUser选项。你可能需要将这两个容器作为两个不同的用户运行(也许你正在使用两个来自第三方容器镜像的容器,每个容器都在自己特定的用户下运行其进程)。如果这两个容器使用卷来共享文件,它们可能无法读取或写入彼此的文件。
这就是Kubernetes允许你为在容器中运行的所有pod指定补充组的原因,使它们可以共享文件,而不受它们运行的用户ID的影响。这可以使用以下两个属性来完成:fsGroup和supplementalGroups。
让我们看看如何在一个pod中使用它们,然后再看看它们的效果如何。下面的示例描述了一个有两个容器共享同一个卷的pod:
# pod-with-shared-volume-fsgroup.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-with-shared-volume-fsgroup
spec:
# 在pod级别定义
securityContext:
fsGroup: 555
supplementalGroups: [666, 777]
containers:
- name: first
image: alpine
command: ["/bin/sleep", "999999"]
securityContext:
# 第一个容器的用户id
runAsUser: 1111
volumeMounts:
- name: shared-volume
mountPath: /volume
readOnly: false
- name: second
image: alpine
command: ["/bin/sleep", "999999"]
securityContext:
# 第二个容器的用户id
runAsUser: 2222
volumeMounts:
- name: shared-volume
mountPath: /volume
readOnly: false
# 两个容器共享一个卷
volumes:
- name: shared-volume
emptyDir:
创建这个pod后,在第一个容器中运行一个shell,并查看容器运行的用户和组ID:
$ kubectl exec -it pod-with-shared-volume-fsgroup -c first -- sh
/ $ id
uid=1111 gid=0(root) groups=0(root),555,666,777
id命令显示该容器正在以1111用户ID运行,正如在pod定义中指定的一样。有效的组ID是0(root),但群组ID 555、666和777也与该用户相关联。
在pod定义中,你将fsGroup设置为555。因此,挂载的卷将由组ID为555拥有,如下所示:
ls -l / | grep volume
drwxrwsrwx 2 root 555 4096 Jun 10 13:08 volume
如果你在挂载的卷的目录中创建一个文件,该文件的所有者是用户ID 1111(这是容器正在运行的用户ID)和组ID 555:
/ $ echo foo > /volume/foo
/ $ ls -l /volume
total 4
-rw-r--r-- 1 1111 555 4 Jun 10 13:12 foo
这与其他情况下新创建的文件的所有权设置不同。通常,当一个用户创建文件时,使用的是用户的有效群组ID(在你的情况下为0)。你可以通过在容器的文件系统中创建文件而不是在卷中来查看这一点:
/ $ echo foo > /tmp/foo
/ $ ls -l /tmp
total 4
-rw-r--r-- 1 1111 root 4 Jun 10 13:13 foo
正如你所看到的,当进程在一个卷中创建文件时,会使用fsGroup安全上下文属性(但这取决于使用的卷插件),而supplementalGroups属性定义了用户关联的附加组ID列表。
这就结束了关于容器安全上下文配置的部分。接下来,我们将看到集群管理员如何限制用户这样做。
13.3 Restricting the use of security-related features in pods
集群管理员可以通过创建一个或多个PodSecurityPolicy资源来限制先前介绍的与安全相关的功能的使用。
13.3.1 Introducing the PodSecurityPolicy resource
PodSecurityPolicy是一个集群级别的(非namespaced)资源,它定义了用户可以或不能在他们的pod中使用的安全相关功能。维护PodSecurityPolicy资源中配置的策略的工作是由运行在API服务器中的PodSecurityPolicy admission控制插件执行的。
PodSecurityPolicy admission控制插件可能没有在你的集群中启用。在运行以下示例之前,请确保已启用该插件。
当有人向API服务器提交一个pod资源时,PodSecurityPolicy admission控制插件根据配置的PodSecurityPolicies验证pod定义。如果pod符合集群的策略,它被接受并存储到etcd中;否则它会被立即拒绝。插件还可以根据策略中配置的默认值修改pod资源。
13.4 Isolating the pod network
在本章的其余部分,我们将探讨如何通过限制哪些Pod可以连接到哪些Pod来保护Pod之间的网络。
这取决于在群集中使用的容器网络插件是否提供了相应的配置。如果网络插件支持,可以通过创建NetworkPolicy资源来配置网络隔离。
NetworkPolicy适用于匹配其标签选择器的Pod,并指定可以访问匹配Pod的源或可从匹配Pod访问的目标。这是通过分别设置入口规则和出口规则来配置的。两种类型的规则都可以匹配满足Pod选择器的Pod,满足Namespace选择器的所有具有标签的命名空间中的所有Pod,或使用无类域间路由(CIDR)表示法指定的网络IP块(例如,192.168.1.0/24)。
我们将探讨入口和出口规则以及所有三种匹配选项。
13.4.1 Enabling network isolation in a namespace
默认情况下,给定命名空间中的Pod可以被任何人访问。首先,你需要更改此设置。你将创建一个名为default-deny NetworkPolicy,这将防止所有客户端连接到你的命名空间中的任何Pod。NetworkPolicy定义如下:
# network-policy-default-deny.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny
spec:
# 适用于default命名空间下所有pod
podSelector:
当你在某个命名空间中创建此网络策略时,任何人都无法连接到该命名空间中的任何Pod。
在集群中使用的CNI插件或其他类型的网络解决方案必须支持NetworkPolicy,否则对Pod之间的连接性将没有任何影响
13.4.2 Allowing only some pods in the namespace to connect to a server pod
现在,要允许客户端连接到命名空间中的Pod,你必须明确表明谁可以连接到这些Pod,也就是说,哪些Pod。让我们通过一个例子来探讨如何实现这一点。
假设在名为foo的命名空间中有一个正在运行的PostgreSQL数据库Pod和一个使用该数据库的Web服务器Pod。还有其他Pod也在该命名空间中,你不希望它们连接到数据库。为了保护网络,你需要在与数据库Pod相同的命名空间中创建以下清单中显示的NetworkPolicy资源:
# network-policy-postgres.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: postgres-netpolicy
spec:
podSelector:
matchLabels:
app: database
ingress:
- from:
- podSelector:
matchLabels:
app: webserver
ports:
- port: 5432
此示例NetworkPolicy允许具有app=webserver标签的Pod连接到具有app=database标签的Pod,并且只能使用端口5432。其他Pod无法连接到数据库Pod,而且除了数据库Pod的端口5432之外,没有人(甚至是Web服务器Pod)可以连接到其他任何端口。图13.4显示了这一点。

客户端Pod通常通过Service与Server Pod连接而不是直接连接到Pod,但这并不会改变什么。在通过Service连接时,NetworkPolicy也会得到执行。
13.4.3 Isolating the network between Kubernetes namespaces
现在,让我们看另一个例子,在这个例子中,多个租户正在使用同一个Kubernetes集群。每个租户可以使用多个命名空间,每个命名空间都有一个标签指定它所属的租户。例如,其中一个租户是Manning。他们的所有命名空间都已标记为tenant:manning。在他们的某个命名空间中,他们运行一个购物车微服务,需要对他们任何命名空间中运行的所有Pod都可用。显然,他们不希望其他租户访问他们的微服务。
为了保护他们的微服务,他们创建以下清单中显示的NetworkPolicy资源。
# network-policy-cart.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: shoppingcart-netpolicy
spec:
podSelector:
matchLabels:
app: shopping-cart
ingress:
- from:
- namespaceSelector:
matchLabels:
tenant: manning
ports:
- port: 80
该NetworkPolicy确保只有运行在标记为tenant:manning的命名空间中的Pod可以访问他们的购物车微服务,如图13.5所示。
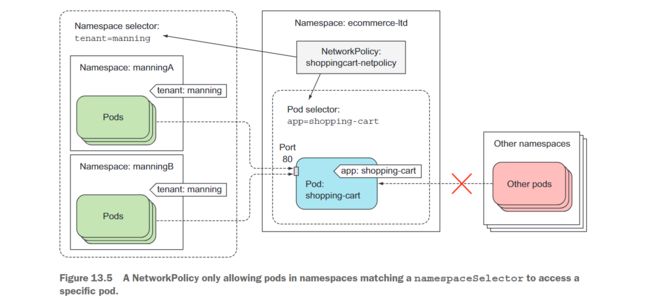
如果购物车提供商还想向其他租户(也许是他们的合作伙伴公司之一)提供访问权限,他们可以创建一个额外的NetworkPolicy资源或向其现有的NetworkPolicy添加一个额外的ingress规则。
在多租户的Kubernetes集群中,租户通常不能自己添加标签(或注释)到他们的命名空间。如果他们这样做,他们将能够规避基于namespaceSelector的ingress规则。
13.4.4 Isolating using CIDR notation
你可以使用CIDR表示法中的IP块来指定哪些可以访问NetworkPolicy中目标Pod。与其指定Pod或命名空间选择器不同。例如,要允许先前部分中的购物车Pod仅从192.168.1.1到255范围内的IP访问,可以如此指定:
ingress:
- from:
- ipBlock:
cidr: 192.168.1.0/24
13.4.5 Limiting the outbound traffic of a set of pods
在所有先前的例子中,你一直使用ingress规则限制匹配NetworkPolicy的Pod选择器的入站流量,但你也可以通过egress规则限制它们的出站流量。如下所示:
# network-policy-egress.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: egress-net-policy
spec:
podSelector:
matchLabels:
app: webserver
egress:
- to:
- podSelector:
matchLabels:
app: database
ports:
- port: 5432