K8s in Action 阅读笔记——【10】StatefulSets: deploying replicated stateful applications
K8s in Action 阅读笔记——【10】StatefulSets: deploying replicated stateful applications
10.1 Replicating stateful pods
ReplicaSet通过单个Pod模板创建多个Pod副本。这些副本除了名称和IP地址外,并无差异。如果Pod模板包含一个卷,该卷引用了特定的PersistentVolumeClaim,ReplicaSet的所有副本将使用相同的PersistentVolumeClaim,因此也使用相同的由该PersistentVolumeClaim绑定的PersistentVolume(如图10.1所示)。
由于对声明的引用位于用于创建多个Pod副本的Pod模板中,因此无法使每个副本使用其自己的独立PersistentVolumeClaim。至少通过单个ReplicaSet,无法使用ReplicaSet运行分布式数据存储,因为每个实例需要其自己的独立存储。需要其他的解决方案。

10.1.1 Running multiple replicas with separate storage for each
如何运行多个Pod副本并使每个Pod使用自己的存储卷?ReplicaSet创建Pod的精确副本,因此无法将其用于此类Pod。那么可以使用什么呢?
手动创建Pod
可以手动创建Pod,并使每个Pod使用自己的PersistentVolumeClaim,但由于没有ReplicaSet来管理它们,需要手动管理它们,并在其消失时重新创建(例如节点故障)。因此,这不是一个可行的选项。
每个Pod实例使用一个ReplicaSet
可以创建多个ReplicaSet,每个Pod都有一个ReplicaSet,每个ReplicaSet的期望副本数设置为1,并且每个ReplicaSet的Pod模板引用一个专用的PersistentVolumeClaim(如图10.2所示)。
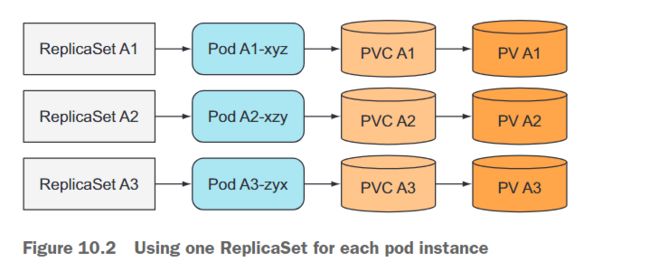
虽然这样做可以在节点故障或意外删除Pod时自动重新调度,但与拥有单个ReplicaSet相比,这样做更加繁琐。例如,考虑如何扩展这种情况下的Pod。无法更改期望的副本数,而是必须创建额外的ReplicaSet。
因此,使用多个ReplicaSet并不是最佳解决方案。
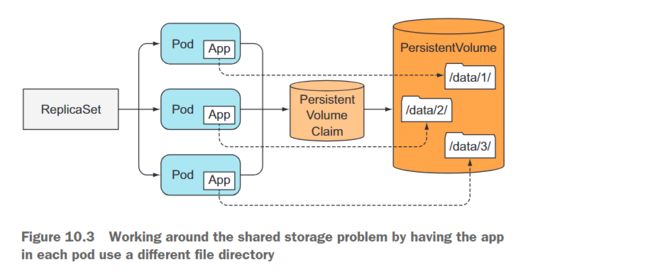
在同一个存储卷中使用多个目录
使用相同的PersistentVolume,但在该卷内为每个Pod创建单独的文件目录,是一个可以使用的技巧(如图10.3所示)。
由于无法从单个Pod模板中对副本进行不同配置,因此无法告诉每个实例应该使用哪个目录。但是,可以使每个实例自动选择一个当前没有其他实例使用的数据目录。这种解决方案需要实例之间的协调,并且不容易正确实现。
10.1.2 Providing a stable identity for each pod
某些应用程序要求每个实例具有稳定的网络标识,除了存储之外。Pod可能会不时地被终止并用新的Pod替换。当ReplicaSet替换一个Pod时,新的Pod是一个全新的Pod,具有新的主机名和IP地址,尽管其存储卷中的数据可能是被终止的Pod的数据。对于某些应用程序来说,使用旧实例的数据启动但具有全新的网络标识可能会引发问题。
为什么某些应用程序需要稳定的网络标识?这个要求在分布式有状态应用程序中非常常见。某些应用程序要求管理员在每个成员的配置文件中列出所有其他集群成员及其IP地址(或主机名)。但在Kubernetes中,每次重新调度Pod时,新的Pod都会获得一个新的主机名和一个新的IP地址,因此整个应用程序集群在每次成员被重新调度时都需要重新配置。
为每个 Pod 实例使用专用Service
为了解决这个问题,你可以使用一个诀窍,为集群成员提供稳定的网络地址,通过为每个单独的成员创建一个专用的Kubernetes Service。因为服务的IP是稳定的,所以你可以在配置中通过其服务IP(而不是Pod IP)指向每个成员。
这类似于为每个成员创建一个ReplicaSet来为它们提供独立的存储,如前面所述。将这两种技术结合起来,可以得到图10.4所示的设置(还显示了覆盖整个集群成员的附加服务,因为通常需要一个用于集群的客户端)。

这种解决方案不仅不美观,而且仍然不能解决所有问题。单独的Pod无法知道它们通过哪个Service公开(因此无法知道它们的稳定IP),因此它们无法在其他Pod中使用该IP进行自注册。
幸运的是,Kubernetes为我们提供了StatefulSet。
10.2 Understanding StatefulSets
10.2.1 Comparing StatefulSets with ReplicaSets
使用“宠物”与“牛群”类比来理解有状态的Pods
你可能已经听说过“宠物”与“牛群”的类比。如果没有,让我解释一下。我们可以将应用程序的实例视为宠物或牛群。
注意:StatefulSets最初被称为PetSets。这个名称来源于这里解释的“宠物”与“牛群”的类比。
我们倾向于将应用程序实例视为宠物,为每个实例赋予一个名称,并对每个实例进行个别关注。但通常更好的做法是将实例视为牛群,不对每个个体实例给予特别关注。这样可以轻松替换不健康的实例,而无需多加考虑,就像农民替换不健康的牛一样。
无状态应用程序的实例行为很像牛群的一头牛。如果一个实例死了,你可以创建一个新实例,人们不会察觉到任何差异。
然而,对于有状态的应用程序,一个应用程序实例更像是宠物。当一个宠物死去时,你不能去买一只新宠物,并期望人们没有注意到。要替换丢失的宠物,你需要找到一只看起来和行为方式完全像旧宠物的新宠物。对于应用程序来说,这意味着新实例需要具有与旧实例相同的状态和标识。
将StatefulSets与ReplicaSets或ReplicationControllers进行比较
由ReplicaSet或ReplicationController管理的Pod副本就像牛群。因为它们大多是无状态的,可以随时用完全新的Pod副本替换它们。有状态的Pod需要采用不同的方法。当有状态的Pod实例死亡(或其所在的节点故障)时,需要在另一个节点上重新启动该Pod实例,但新实例需要获得与其替换的旧实例相同的名称、网络标识和状态。这就是通过StatefulSet管理Pod时发生的情况。
StatefulSet确保Pod以保留其标识和状态的方式重新调度。它还允许你轻松地扩展宠物的数量。StatefulSet像ReplicaSet一样具有期望的副本计数字段,用于确定你想要在该时间运行的宠物数量。类似于ReplicaSets,Pod是从作为StatefulSet的一部分指定的Pod模板创建的。但与由ReplicaSets创建的Pod不同,由StatefulSet创建的Pod并不是完全相同的副本。每个Pod可以拥有自己的一组卷,,这使其与其他Pod不同。宠物Pod还具有可预测(且稳定)的标识,而不是每个新的Pod实例获得完全随机的标识。
10.2.2 Providing a stable network identity
GOVERNING SERVICE
每个由StatefulSet创建的Pod都被分配一个序号索引(从零开始),该索引用于生成Pod的名称和主机名,并将稳定的存储附加到Pod上。因此,Pod的名称是可预测的,因为每个Pod的名称都是从StatefulSet的名称和实例的序号索引派生而来。与随机名称的Pod不同,它们的命名方式很有条理,如下图所示。

与常规Pod不同,有状态的Pod有时需要通过其主机名进行寻址,而无状态的Pod通常不需要这样做。毕竟,每个无状态的Pod都像其他任何一个Pod一样。当你需要一个时,你可以选择其中任何一个。但是对于有状态的Pod,你通常希望操作特定的Pod。
因此,StatefulSet要求你创建一个相应的控制无头服务(governing headless Service),用于为每个Pod提供实际的网络标识。通过这个服务,每个Pod都会获得自己的DNS条目,因此它的同伴和可能是集群中的其他客户端可以通过其主机名寻址该Pod。例如,如果控制服务属于default命名空间,名称为foo,并且其中一个Pod的名称是A-0,你可以通过其完全合格的域名访问该Pod,该域名是a-0.foo.default.svc.cluster.local。使用ReplicaSet管理的Pod无法做到这一点。
此外,你还可以使用DNS来查找StatefulSet中所有Pod的名称。
替换Pod
当由StatefulSet管理的Pod实例消失时(因为Pod所在的节点故障、Pod被驱逐出节点或有人手动删除了Pod对象),StatefulSet会确保用一个新实例替换它,类似于ReplicaSet的做法。但与ReplicaSet不同,新的Pod会获得与消失的Pod相同的名称和主机名(ReplicaSet和StatefulSet之间的区别如图10.6所示)。

新的Pod不一定会被调度到相同的节点上,但正如你之前学到的那样,Pod运行在哪个节点上并不重要。即使Pod被调度到不同的节点上,它仍然可以在以前的主机名下可用和可访问。
StatefulSet的扩缩容
调整StatefulSet的规模会创建一个带有下一个未使用的序数索引的新Pod实例。如果你将实例数量从两个扩展到三个,新实例将获得索引2(现有实例显然具有索引0和1)。
调整StatefulSet的规模向下缩放的好处在于你总是知道将被删除的Pod。同样,这与缩减ReplicaSet的规模形成了对比,在那里你不知道将删除哪个实例,甚至无法指定你想要首先删除哪个实例(但这个功能可能在未来引入)。缩减StatefulSet总是首先删除具有最高序数索引的实例(如图10.7所示)。这使得缩减规模的效果可预测。
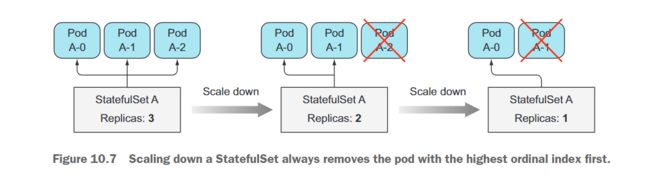
由于某些有状态应用程序无法很好地处理快速缩减规模,因此StatefulSets一次只缩减一个Pod实例。例如,一个分布式数据存储如果多个节点同时下线可能会丢失数据。例如,如果复制的数据存储配置为存储每个数据条目的两个副本,那么如果同时关闭了两个节点,如果数据条目正好存储在这两个节点上,那么数据条目将会丢失。如果缩减规模是顺序进行的,分布式数据存储将有时间在其他地方创建一个额外的数据条目副本来替换(单个)丢失的副本。
因此,出于这个确切的原因,StatefulSets不允许在任何实例不健康时进行缩减操作。如果一个实例不健康,并且你同时缩减一个实例,你实际上一次性丢失了两个集群成员。
10.2.3 Providing stable dedicated storage to each stateful instance
你已经了解到StatefulSets如何确保有状态的Pod具有稳定的标识,但存储又是如何处理的呢?每个有状态的Pod实例都需要使用自己的存储,而且如果有状态的Pod被重新调度(用与之前相同的标识替换为新实例),新实例必须附带相同的存储。StatefulSets是如何实现这一点的呢?
显然,有状态的Pod的存储需要是持久性的,并且与Pod分离。在第6章中,你学习了关于PersistentVolumes和PersistentVolumeClaims的内容,它们允许通过引用Pod中的PersistentVolumeClaim来连接持久性存储。因为PersistentVolumeClaims与PersistentVolumes是一对一的关系,StatefulSet中的每个Pod实例都需要引用一个不同的PersistentVolumeClaim来拥有自己独立的PersistentVolume。由于所有的Pod实例都是从同一个Pod模板复制出来的,它们如何分别引用不同的PersistentVolumeClaim呢?那么是谁创建这些声明呢?
将Pod模板与Volume Claim模板合作
StatefulSet不仅要创建Pod,还要创建PersistentVolumeClaims,就像创建Pod一样。因此,StatefulSet还可以具有一个或多个Volume Claim模板,以便与每个Pod实例一起生成PersistentVolumeClaims(参见图10.8)。

PersistentVolumeClaims的PersistentVolumes可以由管理员预先分配,也可以通过动态分配PersistentVolumes进行实时创建。
PersistentVolumeClaims的创建与删除
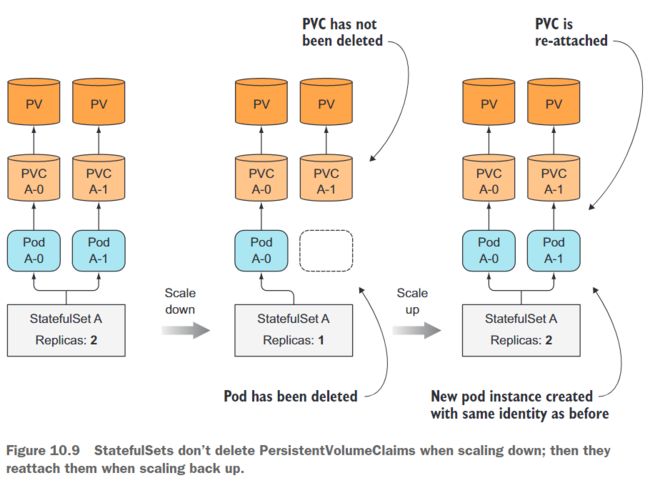
通过增加一个Pod实例,StatefulSet会创建两个或多个API对象(一个是Pod,另一个或多个是由Pod引用的PersistentVolumeClaims)。然而,缩减实例时,只会删除Pod,而保留PersistentVolumeClaims不变。这是因为考虑到删除一个PersistentVolumeClaim的后果是显而易见的。当一个PersistentVolumeClaim被删除后,它所绑定的PersistentVolume会被回收或删除,并且其中的数据会丢失。
需要手动删除PersistentVolumeClaims以释放底层的PersistentVolume。
PersistentVolumeClaim在缩减操作后保留下来意味着随后的扩展操作可以重新将相同的PersistentVolumeClaim与已绑定的PersistentVolume及其内容附加到新的Pod实例上(如图10.9所示)。如果意外缩减了StatefulSet,可以通过再次扩展操作来撤消此错误,新的Pod实例将再次获取相同的持久化状态(以及相同的名称)。
10.2.4 Understanding StatefulSet guarantees
常规的无状态Pod是可互换的,而有状态的Pod则不是。我们已经看到,有状态的Pod始终会被替换为一个完全相同的Pod(具有相同的名称和主机名,使用相同的持久化存储等)。当Kubernetes发现旧的Pod不再存在时(例如手动删除Pod),它会进行替换。
但是,如果Kubernetes无法确定Pod的状态怎么办?如果它创建一个具有相同标识的替代Pod,那么系统中可能会运行两个具有相同标识的应用实例。它们还将绑定到相同的存储,因此两个具有相同标识的进程将同时写入相同的文件。对于由ReplicaSet管理的Pod来说,这不是问题,因为显然这些应用程序可以在相同的文件上工作。此外,ReplicaSets会使用随机生成的标识创建Pod,因此不存在两个具有相同标识的进程同时运行的情况。
因此,Kubernetes必须非常小心地确保不会同时运行具有相同标识并绑定到相同PersistentVolumeClaim的两个有状态的Pod实例。StatefulSet必须对有状态的Pod实例提供至多一次的语义保证。
这意味着在创建替代Pod之前,StatefulSet必须确保旧的Pod已经停止运行。这对于处理节点故障具有重大影响,我们将在本章后面进行演示。
10.3 Using a StatefulSet
10.3.1 Creating the app and container image
对之前的kubia程序进行扩展,以便在每个Pod实例上允许存储和检索单个数据条目。如下所示:
const http = require('http');
const os = require('os');
const fs = require('fs');
const dataFile = "/var/data/kubia.txt";
function fileExists(file) {
try {
fs.statSync(file);
return true;
} catch (e) {
return false;
}
}
var handler = function(request, response) {
if (request.method == 'POST') {
var file = fs.createWriteStream(dataFile);
file.on('open', function (fd) {
request.pipe(file);
console.log("New data has been received and stored.");
response.writeHead(200);
response.end("Data stored on pod " + os.hostname() + "\n");
});
} else {
var data = fileExists(dataFile) ? fs.readFileSync(dataFile, 'utf8') : "No data posted yet";
response.writeHead(200);
response.write("You've hit " + os.hostname() + "\n");
response.end("Data stored on this pod: " + data + "\n");
}
};
var www = http.createServer(handler);
www.listen(8080);
每当应用程序收到一个POST请求时,它会将请求体中接收到的数据写入到文件/var/data/kubia.txt中。在收到GET请求时,它会返回主机名和存储的数据(文件内容)。
Dockerfile文件如下:
FROM node:7
ADD app.js /app.js
ENTRYPOINT ["node", "app.js"]
10.3.2 Deploying the app through a StatefulSet
要部署你的应用程序,你需要创建两种(或三种)不同类型的对象:
- 用于存储数据文件的PersistentVolumes(如果集群不支持动态提供PersistentVolumes,则需要手动创建)。
- StatefulSet所需的控制性Service。
- StatefulSet本身。
对于每个Pod实例,StatefulSet将创建一个PersistentVolumeClaim,该PersistentVolumeClaim将绑定到一个PersistentVolume。如果你的集群支持动态提供,你就不需要手动创建任何PersistentVolumes(可以跳过下一部分)。如果不支持,你需要按照下一部分的说明进行创建。
创建持久化卷
你将需要三个PersistentVolumes,因为你将把StatefulSet扩展到三个副本。如果你计划将StatefulSet扩展到更多副本,就需要创建更多PersistentVolumes。
使用如下文件创建PersistentVolume:
# 1. 创建持久卷PV
apiVersion: v1
kind: PersistentVolume
metadata:
# PV卷名称
name: mongodb-pv1
spec:
# 容量
capacity:
# 存储大小: 100MB
storage: 100Mi
# 该卷支持的访问模式
accessModes:
- ReadWriteOnce # RWO, 该卷可以被一个节点以读写方式挂载
- ReadOnlyMany # ROX, 该卷可以被多个节点以只读方式挂载
# 回收策略: 保留
persistentVolumeReclaimPolicy: Retain
# 该持久卷的实际存储类型: 此处使用HostPath类型卷
hostPath:
path: /tmp/mongodb1
---
# 1. 创建持久卷PV
apiVersion: v1
kind: PersistentVolume
metadata:
# PV卷名称
name: mongodb-pv2
spec:
# 容量
capacity:
# 存储大小: 100MB
storage: 100Mi
# 该卷支持的访问模式
accessModes:
- ReadWriteOnce # RWO, 该卷可以被一个节点以读写方式挂载
- ReadOnlyMany # ROX, 该卷可以被多个节点以只读方式挂载
# 回收策略: 保留
persistentVolumeReclaimPolicy: Retain
# 该持久卷的实际存储类型: 此处使用HostPath类型卷
hostPath:
path: /tmp/mongodb2
---
# 1. 创建持久卷PV
apiVersion: v1
kind: PersistentVolume
metadata:
# PV卷名称
name: mongodb-pv3
spec:
# 容量
capacity:
# 存储大小: 100MB
storage: 100Mi
# 该卷支持的访问模式
accessModes:
- ReadWriteOnce # RWO, 该卷可以被一个节点以读写方式挂载
- ReadOnlyMany # ROX, 该卷可以被多个节点以只读方式挂载
# 回收策略: 保留
persistentVolumeReclaimPolicy: Retain
# 该持久卷的实际存储类型: 此处使用HostPath类型卷
hostPath:
path: /tmp/mongodb3
$ kubectl apply -f mongodb-pv.yaml
persistentvolume/mongodb-pv1 created
persistentvolume/mongodb-pv2 created
persistentvolume/mongodb-pv3 created
$ kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
mongodb-pv1 100Mi RWO,ROX Retain Available 5s
mongodb-pv2 100Mi RWO,ROX Retain Available 5s
mongodb-pv3 100Mi RWO,ROX Retain Available 5s
创建管理Service
如前所述,在部署StatefulSet之前,你首先需要创建一个无头服务(headless Service),用于为你的有状态pod提供网络标识。下面的清单显示了服务的定义
# kubia-service-headless.yaml
apiVersion: v1
kind: Service
metadata:
name: kubia
spec:
clusterIP: None
selector:
app: kubia
ports:
- name: http
port: 80
创建StatefulSet配置文件
配置文件如下:
# kubia-statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: kubia
spec:
serviceName: kubia
replicas: 2
selector:
matchLabels:
app: kubia # has to match .spec.template.metadata.labels
template:
metadata:
labels:
app: kubia
spec:
containers:
- name: kubia
image: luksa/kubia-pet
ports:
- name: http
containerPort: 8080
volumeMounts:
- name: data
mountPath: /var/data
volumeClaimTemplates:
- metadata:
name: data
spec:
resources:
requests:
storage: 1Mi
accessModes:
- ReadWriteOnce
StatefulSet清单与你之前创建的ReplicaSet或Deployment清单并没有太大的不同。不同之处在于volumeClaimTemplates列表。在其中,你定义了一个名为data的卷申领模板,它将用于为每个pod创建一个PersistentVolumeClaim。一个pod通过在清单中包含persistentVolumeClaim来申请卷空间。在之前的pod模板中,你将找不到这样的卷。
创建StatefulSet
$ kubectl create -f kubia-statefulset.yaml
statefulset.apps/kubia created
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
kubia-0 1/1 Running 0 57s
kubia-1 1/1 Running 0 39s
Pod会等前一个pod创建了才接着创建。
测试生成的Pod
让我们仔细查看下面清单中的第一个pod的spec,以了解StatefulSet是如何根据pod模板和PersistentVolumeClaim模板构建pod的。
$ kubectl get po kubia-0 -o yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: "2023-06-04T08:23:10Z"
generateName: kubia-
labels:
app: kubia
controller-revision-hash: kubia-c94bcb69b
statefulset.kubernetes.io/pod-name: kubia-0
name: kubia-0
namespace: default
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: StatefulSet
name: kubia
uid: fe22c872-ed23-4497-aa63-489b28eb4ae3
resourceVersion: "3898989"
uid: 4d66ebd8-014c-4cb2-ae78-9e94d925b133
spec:
containers:
- image: luksa/kubia-pet
imagePullPolicy: Always
name: kubia
ports:
- containerPort: 8080
name: http
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/data
name: data
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: kube-api-access-zm4s7
readOnly: true
dnsPolicy: ClusterFirst
enableServiceLinks: true
hostname: kubia-0
nodeName: yjq-k8s2
preemptionPolicy: PreemptLowerPriority
priority: 0
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: default
serviceAccountName: default
subdomain: kubia
terminationGracePeriodSeconds: 30
tolerations:
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 300
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 300
volumes:
- name: data
persistentVolumeClaim: # 由StatefulSet创建的volume
claimName: data-kubia-0
- name: kube-api-access-zm4s7
projected:
defaultMode: 420
sources:
- serviceAccountToken:
expirationSeconds: 3607
path: token
- configMap:
items:
- key: ca.crt
path: ca.crt
name: kube-root-ca.crt
- downwardAPI:
items:
- fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
path: namespace
PersistentVolumeClaim模板用于创建PersistentVolumeClaim和pod内的卷,该卷引用了创建的PersistentVolumeClaim。
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
data-kubia-0 Bound mongodb-pv1 100Mi RWO,ROX 6m15s
data-kubia-1 Bound mongodb-pv2 100Mi RWO,ROX 5m57s
可以看到PersistentVolumeClaim确实被创建了。
10.3.3 Playing with your pods
使用API服务器与Pod通信
API服务器的一个有用功能是能够直接将连接代理到单个pod。如果想对kubia-0 pod执行请求,可以使用以下URL:
:/api/v1/namespaces/default/pods/kubia-0/proxy/
直接开启代理更方便:
$ kubectl proxy
Starting to serve on 127.0.0.1:8001
由于你将通过kubectl代理与API服务器进行通信,因此将使用localhost:8001而不是实际的API服务器主机和端口。你将像这样向kubia-0 pod发送请求:
$ curl localhost:8001/api/v1/namespaces/default/pods/kubia-0/proxy/
You've hit kubia-0
Data stored on this pod: No data posted yet
响应显示该请求确实已被kubia-0 pod中运行的应用程序接收和处理。
因为你是通过API服务器与pod进行通信,而你是通过kubectl代理连接到API服务器的,所以该请求经过了两个不同的代理(第一个是kubectl代理,另一个是API服务器,它将请求代理到pod)。为了更清楚地了解情况,请参考图10.10。

你发送给pod的请求是一个GET请求,但是你也可以通过API服务器发送POST请求。通过将POST请求发送到与GET请求相同的代理URL上来实现。
当你的应用程序接收到POST请求时,它会将请求体中的内容存储到一个本地文件中。向kubia-0 pod发送一个POST请求:
$ curl -X POST -d "Hey there! This greeting was submitted to kubia-0." localhost:8001/api/v1/namespaces/default/pods/kubia-0/proxy/
Data stored on pod kubia-0
你发送的数据现在应该存储在该pod中。让我们再次执行GET请求,看它是否返回存储的数据:
$ curl localhost:8001/api/v1/namespaces/default/pods/kubia-0/proxy/
You've hit kubia-0
Data stored on this pod: Hey there! This greeting was submitted to kubia-0.
好的,目前为止一切都很顺利。现在让我们看看另一个集群节点(kubia-1 pod)返回了什么:
$ curl localhost:8001/api/v1/namespaces/default/pods/kubia-1/proxy/
You've hit kubia-1
Data stored on this pod: No data posted yet
正如预期的那样,每个节点都有自己的状态。但是这个状态是否被持久化了呢?让我们来验证一下。
检查Pod的状态是否是可持久化的
删除一个Pod,来检查一下:
$ kubectl delete pod kubia-0
pod "kubia-0" deleted
$ kubectl get po
NAME READY STATUS RESTARTS AGE
kubia-0 1/1 Terminating 0 20m
kubia-1 1/1 Running 0 19m
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
kubia-0 0/1 ContainerCreating 0 14s
kubia-1 1/1 Running 0 20m
可以看到一个相同名称的Pod被创建了。
这个新的pod可能被调度到集群中的任何节点,不一定是之前的pod所在的节点。旧的pod的整个身份(名称、主机名和存储)被有效地移动到新节点上(如图10.11所示)。
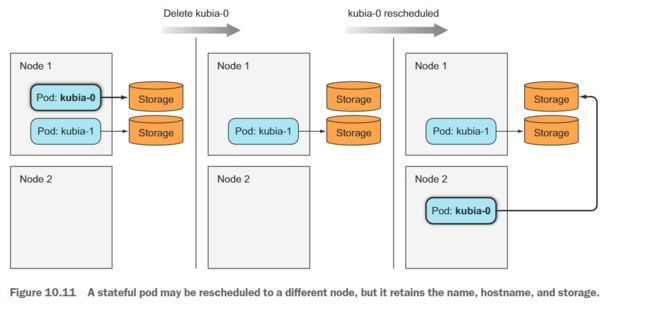
现在新的pod正在运行,让我们检查一下它是否具有与以前相同的身份:
$ curl localhost:8001/api/v1/namespaces/default/pods/kubia-0/proxy/
You've hit kubia-0
Data stored on this pod: Hey there! This greeting was submitted to kubia-0.
可以看到之前存储的数据也被持久化存储了。
缩放一个 StatefulSet
缩放一个 StatefulSet 的方式与删除一个 Pod 并立即由 StatefulSet 重新创建它没有太大差异。请记住,缩放 StatefulSet 仅会删除 Pod,而不会影响 PersistentVolumeClaims。
重要的是要记住,缩放(向下或向上)是逐步进行的,就像在创建 StatefulSet 时逐个创建 Pod 一样。当缩小超过一个实例时,最高序号的 Pod 会首先被删除。只有在 Pod 完全终止后,才会删除次高序号的 Pod。
访问集群内的服务
与使用一个 piggyback Pod 从集群内部访问 Service 相比,你可以使用 API 服务器提供的代理功能以相同的方式访问 Service。
首先创建如下Service:
# kubia-service-public.yaml
apiVersion: v1
kind: Service
metadata:
name: kubia-public
spec:
selector:
app: kubia
ports:
- port: 80
targetPort: 8080
代理请求到 Service 的 URI 路径的形式如下所示:
/api/v1/namespaces//services//proxy/
因此,你可以在本地机器上运行 curl,并通过 kubectl proxy 访问 Service,如下所示(之前你运行了 kubectl proxy,应该仍然在运行):
$ curl localhost:8001/api/v1/namespaces/default/services/kubia-public/proxy/
You've hit kubia-0
Data stored on this pod: Hey there! This greeting was submitted to kubia-0.
同样,客户端(在集群内部)可以使用 kubia-public Service 将数据存储到集群化的数据存储中并从中读取数据。当然,每个请求都会落在一个随机的集群节点上,所以每次你都会从一个随机的节点获取数据。你将在下一步进行改进。
10.4 Discovering peers in a StatefulSet
群应用的一个重要需求是对等节点的发现能力,也就是每个 StatefulSet 成员都需要能够轻松地找到其他所有成员。当然,它可以通过与 API 服务器通信来实现这一点,但 Kubernetes 的一个目标是提供一些特性,以帮助应用程序完全与 Kubernetes 无关。因此,让应用程序与 Kubernetes API 进行通信是不可取的。
那么,一个 Pod 如何在不与 API 进行通信的情况下发现其对等节点呢?有没有一种现有的、广为人知的技术可以实现这一点呢?比如域名系统(DNS)如何?根据你对 DNS 的了解程度,你可能知道 A、CNAME 或 MX 记录的用途。除此之外,还存在其他一些较少为人知的 DNS 记录类型,其中之一就是 SRV 记录。
A、CNAME和MX记录是DNS中常见的记录类型,用于解析域名到相应的IP地址或其他域名。A记录用于将域名解析为IPv4地址,CNAME记录用于创建域名的别名或指向其他域名,MX记录用于指定接收该域名电子邮件的邮件服务器。
SRV记录用于指向提供特定服务的主机名和端口的服务器。Kubernetes创建SRV记录来指向无头服务背后的Pod的主机名。
将通过在一个临时的新Pod中运行dig DNS查找工具来列出你的有状态Pod的SRV记录。使用以下命令:
$ kubectl run -it srvlookup --image=tutum/dnsutils --rm --restart=Never -- dig SRV kubia.default.svc.cluster.local
该命令运行一个一次性的Pod(–restart=Never),名称为srvlookup,附加到控制台(-it),并在终止后立即删除(–rm)。该Pod从tutum/dnsutils镜像运行一个容器,并运行以下命令:dig SRV kubia.default.svc.cluster.local。
$ kubectl run -it srvlookup --image=tutum/dnsutils --rm --restart=Never -- dig SRV kubia.default.svc.cluster.local
......
;; ANSWER SECTION:
kubia.default.svc.cluster.local. 30 IN SRV 0 50 80 kubia-1.kubia.default.svc.cluster.local.
kubia.default.svc.cluster.local. 30 IN SRV 0 50 80 kubia-0.kubia.default.svc.cluster.local.
;; ADDITIONAL SECTION:
kubia-0.kubia.default.svc.cluster.local. 30 IN A 10.244.1.126
kubia-1.kubia.default.svc.cluster.local. 30 IN A 10.244.1.125
;; Query time: 2 msec
;; SERVER: 10.96.0.10#53(10.96.0.10)
;; WHEN: Sun Jun 04 12:50:25 UTC 2023
;; MSG SIZE rcvd: 350
pod "srvlookup" deleted
ANSWER SECTION部分显示了两个SRV记录,指向支持无头服务的两个Pod的主机名。每个Pod还有自己的A记录,如ADDITIONAL SECTION所示。
要获取StatefulSet的所有其他Pod的列表,只需执行SRV DNS查找即可。例如,在Node.js中执行此查找的方法如下:
dns.resolveSrv("kubia.default.svc.cluster.local", callBackFunction);
你将在应用程序中使用此命令,以使每个Pod能够发现其对等节点。
返回的SRV记录的顺序是随机的,因为它们都具有相同的优先级。不要期望总是在kubia-1之前看到kubia-0列出。
10.4.1 Implementing peer discovery through DNS
你的远古数据存储尚未进行集群化。每个数据存储节点完全独立于其他节点运行,它们之间没有任何通信。接下来,你将使它们相互通信。
通过kubia-public服务连接到数据存储集群的客户端发送的数据会落到随机的集群节点上。集群可以存储多个数据条目,但客户端目前无法很好地查看所有这些条目。因为服务将请求随机转发到Pod,如果客户端希望从所有Pod获取数据,它需要执行许多请求,直到命中所有Pod为止。
你可以通过使节点返回所有集群节点的数据来改进此问题。为此,节点需要找到所有对等节点。你将利用你在StatefulSet和SRV记录方面的学习来实现此目的。
你将修改应用程序的源代码,如下面的示例所示:
const http = require('http');
const os = require('os');
const fs = require('fs');
const dns = require('dns');
const dataFile = "/var/data/kubia.txt";
const serviceName = "kubia.default.svc.cluster.local";
const port = 8080;
function fileExists(file) {
try {
fs.statSync(file);
return true;
} catch (e) {
return false;
}
}
function httpGet(reqOptions, callback) {
return http.get(reqOptions, function(response) {
var body = '';
response.on('data', function(d) { body += d; });
response.on('end', function() { callback(body); });
}).on('error', function(e) {
callback("Error: " + e.message);
});
}
var handler = function(request, response) {
if (request.method == 'POST') {
var file = fs.createWriteStream(dataFile);
file.on('open', function (fd) {
request.pipe(file);
response.writeHead(200);
response.end("Data stored on pod " + os.hostname() + "\n");
});
} else {
response.writeHead(200);
if (request.url == '/data') {
var data = fileExists(dataFile) ? fs.readFileSync(dataFile, 'utf8') : "No data posted yet";
response.end(data);
} else {
response.write("You've hit " + os.hostname() + "\n");
response.write("Data stored in the cluster:\n");
dns.resolveSrv(serviceName, function (err, addresses) {
if (err) {
response.end("Could not look up DNS SRV records: " + err);
return;
}
var numResponses = 0;
if (addresses.length == 0) {
response.end("No peers discovered.");
} else {
addresses.forEach(function (item) {
var requestOptions = {
host: item.name,
port: port,
path: '/data'
};
httpGet(requestOptions, function (returnedData) {
numResponses++;
response.write("- " + item.name + ": " + returnedData + "\n");
if (numResponses == addresses.length) {
response.end();
}
});
});
}
});
}
}
};
var www = http.createServer(handler);
www.listen(port);
图10.12展示了当应用程序接收到GET请求时发生的情况。首先,接收到请求的服务器会执行对无头kubia服务的SRV记录查找,然后向支持该服务的每个Pod发送GET请求(甚至发送给自己,这显然是不必要的,但我希望代码尽可能简单)。然后,它返回了所有节点的列表以及每个节点上存储的数据。
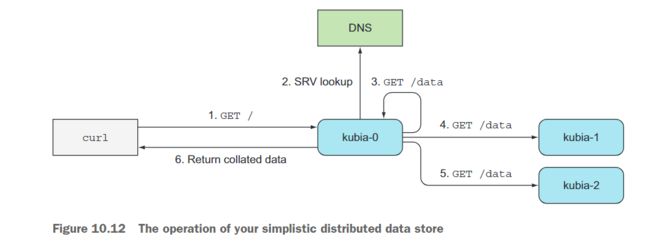
包含此应用程序新版本的容器镜像位于docker.io/luksa/kubia-pet-peers。
10.4.2 Updating a StatefulSet
你的StatefulSet已经在运行,因此让我们看看如何更新其Pod模板,使Pod使用新的镜像。同时,你还将将副本数设置为3。要更新StatefulSet,使用kubectl edit命令(patch命令是另一种选择):
这将在你的默认编辑器中打开StatefulSet的定义。在定义中,将changespec.replicas更改为3,并修改spec.template.spec.containers.image属性,使其指向新的镜像(luksa/kubia-pet-peers而不是luksa/kubia-pet)。保存文件并退出编辑器以更新StatefulSet。之前有两个副本正在运行,现在你应该会看到一个名为kubia-2的额外副本正在启动。列出Pod以确认:
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
kubia-0 1/1 Running 0 4h16m
kubia-1 1/1 Running 0 4h36m
kubia-2 0/1 ContainerCreating 0 12s
新的Pod实例正在运行新的镜像。但是现有的两个副本呢?从它们的年龄来看,它们似乎没有被更新。这是正常的,因为最初,StatefulSet更像是ReplicaSet而不是Deployment,因此在修改模板时它们不执行滚动更新。你需要手动删除副本,然后StatefulSet会根据新的模板重新创建它们:
从Kubernetes版本1.7开始,StatefulSet支持与Deployments和DaemonSets相同的滚动更新。有关更多信息,请使用kubectl explain命令查看StatefulSet的spec.updateStrategy字段的文档。
10.4.3 Trying out your clustered data store
一旦两个Pod运行起来,你可以看到你全新的Stone Age数据存储是否按预期工作。按照下面的示例,向集群发起一些请求。
$ curl -X POST -d "The sun is shining" localhost:8001/api/v1/namespaces/default/services/kubia-public/proxy/
Data stored on pod kubia-1
$ curl -X POST -d "The weather is sweet" localhost:8001/api/v1/namespaces/default/services/kubia-public/proxy/
Data stored on pod kubia-2
现在,按照下面的示例,读取存储的数据。
$ curl localhost:8001/api/v1/namespaces/default/services/kubia-public/proxy/
You've hit kubia-0
Data stored in the cluster:
- kubia-0.kubia.default.svc.cluster.local: Hey there! This greeting was submitted to kubia-0.
- kubia-1.kubia.default.svc.cluster.local: The sun is shining
- kubia-2.kubia.default.svc.cluster.local: The weather is sweet
当客户端请求到达你的集群节点时,它会发现所有的同伴,从它们那里收集数据,并将所有数据发送回客户端。即使你扩展或缩减了StatefulSet,服务客户端请求的Pod始终可以找到当时运行的所有同伴。
10.5 Understanding how StatefulSets deal with node failures
在10.2.4节中,我们提到在创建替代pod之前,Kubernetes必须确保状态为有状态的pod已经停止运行。当节点突然故障时,Kubernetes无法了解节点或其pod的状态。它无法确定pod是否已经停止运行,或者它们是否仍在运行,甚至可能仍然可达,只是Kubelet停止向主节点报告节点状态。
由于StatefulSet保证同一标识和存储的两个pod永远不会同时运行,所以当节点出现故障时,StatefulSet不能且不应创建替代的pod,直到确信先前的pod已经停止运行。
只有当集群管理员告知时,StatefulSet才能确定pod的状态。管理员可以通过删除特定的pod或删除整个节点来实现,后者将导致删除该节点上的所有pod。