Linux下安装配置各种软件和服务
1. JDK
1.1. 解压Linux版本的JDK压缩包
yum -y install glibc.i686 #安装jdk源glibc(需要联网下载源)
mkdir /usr/local/src/jdk #按习惯用户自己安装的软件存放到/usr/local/src目录下
cd /usr/local/src/jdk #进入刚刚创建的目录
rz 上传jdk tar包 #利用xshell的rz命令上传文件
tar -xvf jdk-8u111-linux-x64.tar.gz #解压压缩包
chown -R root:root jdk1.8.0_111 #修改整个目录所属用户
1.2. 配置环境变量
-
编辑配置文件
vi /etc/profile -
在尾行添加以下内容
#set java environment export JAVA_HOME=/usr/java/jdk1.8.0_111 export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar注意
JAVA_HOME要和自己系统中的jdk目录保持一致,如果是使用的rpm包安装的jdk,安装完之后jdk的根目录为:/usr/java/jdk1.8.0_111 -
保存编辑的文件,然后退出
-
使更改的配置立即生效
source /etc/profile -
查看JDK版本信息,如显示版本号则证明成功。
java -version
2. Scala
2.1. 解压Linux版本的scala压缩包
tar -xvf scala-2.12.12.tgz
chown -R root:root scala-2.12.12
然后将压缩包移动到合适的位置。
2.2. 配置环境变量
-
编辑配置文件
vi /etc/profile -
在尾行添加以下内容
export SCALA_HOME=/data/soft/scala-2.12.12 export PATH=$PATH:$SCALA_HOME/bin注意
SCALA_HOME要和自己系统中的scala目录保持一致。 -
保存文件,然后退出编辑
-
使更改的配置立即生效
source /etc/profile -
查看JDK版本信息。如显示版本号则证明成功。
scala -version
3. Python
3.1. 下载
地址
找到自己想要下载的版本,然后下载如下图所示的源码。对于 linux 上 Python 的安装需要自己编译,官网并没有提供对应的二进制包。
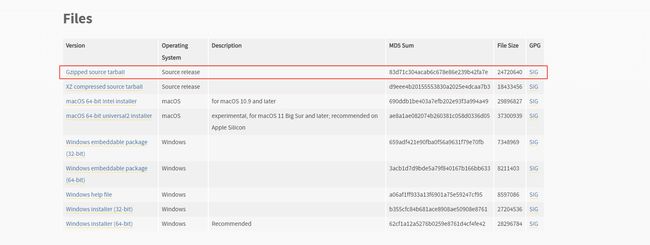
下载之后上传到 linux 机器上。注意,后面安装的目录和上传到机器上的目录可以不一样。
也可以在机器上直接通过 wget 命令直接下载。
3.2. 解压
tar -xvf Python-3.8.10.tgz
之后对其进行重命名以及目录所属用户修改操作
mv Python-3.8.10/ python-3.8.10
chown -R root:root python-3.8.10/
3.3. 准备编译环境
yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel libffi-devel gcc make
3.4. 编译安装
切换到 python 目录下,然后依次执行以下命令
# 注意,--prefix 后面指定的是安装 python 的目录
./configure --prefix=/data/soft/python-3.8.10
make && make install
如果没有出现错误则表示安装成功。
如果出现了错误,则可以运行以下命令重新安装
# make clean 表示清除上次编译时产生的文件
make clean
make && make install
3.5. 建立软连接
先通过以下命令来查看是否已有 python3 和 pip3 的软连接
ll /usr/bin | grep python
ll /usr/bin | grep pip

从该图中也可以看出,系统默认 python 版本为 2 。

如果没有,则通过下面的命令来创建软连接
ln -s /data/soft/python-3.8.10/bin/python3.8 /usr/bin/python3
ln -s /data/soft/python-3.8.10/bin/pip3.8 /usr/bin/pip3
如果提示已存在,或者想要改变软连接位置,则可以添加 -f 参数。
通过下面的命令进入 python 客户端,或者是查看 python 的版本号
python3
python3 --version
退出 python 客户端的命令为 exit() 。
如果想要改变系统默认的 python 版本为自己安装的版本,而且想要输入 python 命令时直接使用自己安装的 python 环境,则可以改变系统默认的 python 软连接。不建议修改,因为 yum 命令是使用 python2 编写的,如果修改为 python3 则 yum 命令使用会报错。
cd /usr/bin
ln -s -f python3 python
然后直接执行 python 就可以看到使用的 python 版本就是自己安装的版本了。
如果想要改回去,只需要重新创建连接指向原来的版本即可。
ln -s -f python2 python
3.6. 配置环境变量
vim /etc/profile
export PYTHON_HOME=/data/soft/python-3.8.10
export PATH=$PYTHON_HOME/bin:$PATH
4. maven
4.1. 解压Linux版本的maven压缩包
tar -xvf apache-maven-3.8.6-bin.tar.gz
然后将压缩包移动到合适的位置。
4.2. 配置环境变量
-
编辑配置文件
vi /etc/profile -
在尾行添加以下内容
export MAVEN_HOME=/data/soft/apache-maven-3.8.6 export PATH=$PATH:$MAVEN_HOME/bin注意
MAVEN_HOME要和自己系统中的maven目录保持一致。 -
保存文件,然后退出编辑
-
使更改的配置立即生效
source /etc/profile -
查看JDK版本信息。如显示版本号则证明成功。
maven -v
4.3. 仓库地址
4.3.1. maven设置使用
<mirror>
<id>nexus-aliyunid>
<name>aliyun mavenname>
<url>https://maven.aliyun.com/repository/publicurl>
<mirrorOf>centralmirrorOf>
mirror>
<mirror>
<id>maven cn repoid>
<name>oneof the central mirrors in chinaname>
<url>http://maven.net.cn/content/groups/public/url>
<mirrorOf>centralmirrorOf>
mirror>
<mirror>
<id>maven cn repoid>
<name>oneof the central mirrors in chinaname>
<url>http://maven.net.cn/content/groups/public/url>
<mirrorOf>centralmirrorOf>
mirror>
<mirror>
<id>maven repoid>
<name>Maven Repository Switchboardname>
<url>http://repo1.maven.org/maven2/url>
<mirrorOf>centralmirrorOf>
mirror>
<mirror>
<id>maven repo2id>
<mirrorOf>centralmirrorOf>
<name>Human Readable Name for this Mirror.name>
<url>http://repo2.maven.org/maven2/url>
mirror>
4.3.2. 项目pom文件使用
下面的代码添加到pom文件根节点下可以对项目单独设置
<repositories>
<repository>
<id>alimavenid>
<name>aliyun mavenname>
<url>http://maven.aliyun.com/nexus/content/repositories/central/url>
repository>
<repository>
<id>nexus-aliyunid>
<name>aliyun mavenname>
<url>http://maven.aliyun.com/nexus/content/groups/public/url>
repository>
<repository>
<id>maven cn repoid>
<name>oneof the central mirrors in chinaname>
<url>http://maven.net.cn/content/groups/public/url>
repository>
<repository>
<id>maven cn repoid>
<name>oneof the central mirrors in chinaname>
<url>http://maven.net.cn/content/groups/public/url>
repository>
<repository>
<id>maven repoid>
<name>Maven Repository Switchboardname>
<url>http://repo1.maven.org/maven2/url>
repository>
<repository>
<id>maven repo2id>
<name>Human Readable Name for this Mirror.name>
<url>http://repo2.maven.org/maven2/url>
repository>
repositories>
5. MySQL-5.x
5.1. 卸载centos7自带MySQL
rpm -qa | grep postfix
rpm -e postfix --nodeps
rpm -qa | grep mariadb
rpm -e mariadb-libs --nod eps
rpm -qa | grep mysql
说明:本案例中将mysql及其数据文件全部放到 /usr/local 目录下,这个要根据实际情况存放。通过 df -h 命令可以看到各个分区的实际大小,一定要安装到空间最大的分区。下面为两个案例:
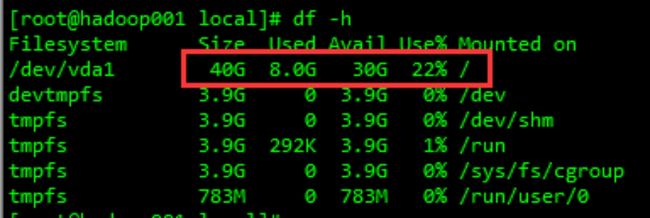
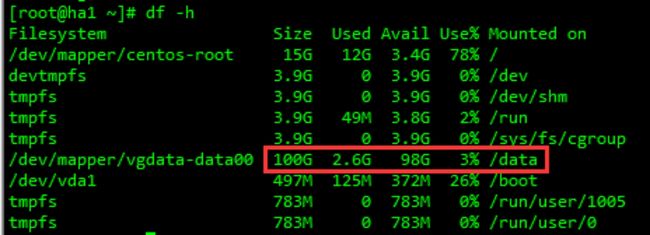
另外,本步骤是按照`` /usr/local/mysql`目录来安装mysql的,如果在实际操作中修改了mysql的安装位置,一定要注意修改每一步中有关mysql目录的步骤。
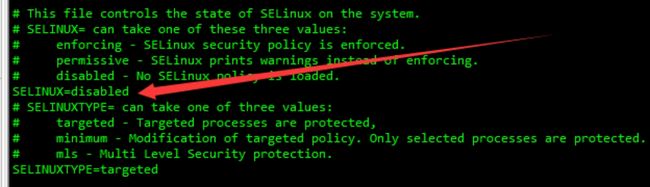
5.2. 关闭selinux
临时关闭
setenforce 0 # 临时关闭
getenforce # 查看运行状态(Permissive/Disabled表示关闭,Enforcing表示运行)
永久关闭
vim /etc/selinux/config
5.3. 解压及创建目录
切换到 /usr/local 目录下
cd /usr/local
要保证解压之后的的文件在 ``/usr/local` 下
tar -xzvf mysql-5.7.27-linux-glibc2.12-x86_64.tar.gz
mv mysql-5.7.27-linux-glibc2.12-x86_64 mysql
mkdir mysql/arch mysql/data mysql/tmp
chown -R root.root mysql
5.4. 创建my.cnf文件
vim /etc/my.cnf
一定要注意下面所有有关目录的配置,一定要修改为自己安装的对应目录,另外,还要注意有关内存的一些设置,生产环境下,可以适当调大。
[client]
port = 3306
socket = /usr/local/mysql/data/mysql.sock
default-character-set=utf8
[mysqld]
port = 3306
socket = /usr/local/mysql/data/mysql.sock
character_set_server=utf8
tls_version = TLSv1.2
skip-slave-start
default-time_zone = '+8:00'
log_timestamps=SYSTEM
explicit_defaults_for_timestamp=true
character-set-server=utf8
init_connect='SET NAMES utf8'
transaction_isolation=READ-COMMITTED
skip-external-locking
key_buffer_size = 256M
sort_buffer_size = 2M
read_buffer_size = 2M
read_rnd_buffer_size = 4M
query_cache_size= 32M
max_allowed_packet = 64M
myisam_sort_buffer_size=128M
tmp_table_size=32M
sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
table_open_cache = 256
open-files-limit=10000
thread_cache_size = 8
wait_timeout = 86400
interactive_timeout = 86400
max_connections = 1000
# Try number of CPU's*2 for thread_concurrency
#thread_concurrency = 32
#isolation level and default engine
default-storage-engine = INNODB
transaction-isolation = READ-COMMITTED
server-id = 81
basedir = /usr/local/mysql
datadir = /usr/local/mysql/data
pid-file = /usr/local/mysql/data/hadoop01.pid
#open performance schema
log-warnings
sysdate-is-now
binlog_format = ROW
log_bin_trust_function_creators=1
log-error = /usr/local/mysql/data/hadoop01.err
log-bin = /usr/local/mysql/arch/mysql-bin
expire_logs_days = 7
innodb_write_io_threads=16
relay-log = /usr/local/mysql/relay_log/relay-log
relay-log-index = /usr/local/mysql/relay_log/relay-log.index
relay_log_info_file= /usr/local/mysql/relay_log/relay-log.info
log_slave_updates=1
gtid_mode=OFF
enforce_gtid_consistency=OFF
event_scheduler=1
# slave
slave-parallel-type=LOGICAL_CLOCK
slave-parallel-workers=4
master_info_repository=TABLE
relay_log_info_repository=TABLE
relay_log_recovery=ON
#other logs
#general_log =1
#general_log_file = /usr/local/mysql/data/general_log.err
slow_query_log=1
long_query_time=1
slow_query_log_file=/usr/local/mysql/data/slow_log.err
#for replication slave
sync_binlog = 500
#for innodb options
innodb_data_home_dir = /usr/local/mysql/data/
innodb_data_file_path = ibdata1:1G;ibdata2:1G:autoextend
innodb_log_group_home_dir = /usr/local/mysql/arch
innodb_log_files_in_group = 4
innodb_log_file_size = 1G
innodb_log_buffer_size = 200M
#根据生产需要,调整pool size
innodb_buffer_pool_size = 3G
#innodb_additional_mem_pool_size = 50M #deprecated in 5.6
tmpdir = /usr/local/mysql/tmp
innodb_flush_method=O_DIRECT
innodb_lock_wait_timeout = 1000
#innodb_thread_concurrency = 0
innodb_flush_log_at_trx_commit = 2
transaction-isolation=READ-COMMITTED
#innodb io features: add for mysql5.5.8
performance_schema
innodb_read_io_threads=4
innodb-write-io-threads=4
innodb-io-capacity=200
#purge threads change default(0) to 1 for purge
innodb_purge_threads=1
innodb_use_native_aio=on
#case-sensitive file names and separate tablespace
innodb_file_per_table = 1
lower_case_table_names=1
[mysqldump]
quick
[mysql]
no-auto-rehash
default-character-set=utf8
[mysql.server]
default-character-set=utf8
[mysqlhotcopy]
interactive-timeout
[myisamchk]
key_buffer_size = 256M
sort_buffer_size = 256M
read_buffer = 2M
write_buffer = 2M
5.5. 创建用户组及用户
groupadd -g 101 dba
useradd -u 514 -g dba -G root -d /usr/local/mysql mysqladmin
注意上面粗体部分,这个目录是mysql安装路径
id mysqladmin
uid=514(mysqladmin) gid=101(dba) groups=101(dba),0(root)
## 一般不需要设置mysqladmin的密码,直接从root或者LDAP用户sudo切换
passwd mysqladmin
## 如果mysqladmin用户已存在,则使用以下命令修改用户的所属组
usermod -u 514 -g dba -G root -d /usr/local/mysql mysqladmin
5.6. 拷贝环境变量
拷贝环境变量配置文件至 mysqladmin 用户的 home 目录中,为了以下步骤配置个人环境变量
cp /etc/skel/.* /usr/local/mysql
5.7. 配置环境变量
vim mysql/.bash_profile
注意下面有关目录的设置
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
export MYSQL_BASE=/usr/local/mysql
export PATH=${MYSQL_BASE}/bin:$PATH
unset USERNAME
#stty erase ^H
set umask to 022
umask 022
PS1=`uname -n`":"'$USER'":"'$PWD'":>"; export PS1
## end
5.8. 赋权限和用户组
chown mysqladmin:dba /etc/my.cnf
chmod 640 /etc/my.cnf
chown -R mysqladmin:dba /usr/local/mysql
chmod -R 755 /usr/local/mysql
5.9. 配置服务及开机自启动
root 用户操作
cd /usr/local/mysql
#将服务文件拷贝到init.d下,并重命名为mysql
cp support-files/mysql.server /etc/rc.d/init.d/mysql
#赋予可执行权限
chmod +x /etc/rc.d/init.d/mysql
#删除服务
chkconfig --del mysql
#添加服务
chkconfig --add mysql
chkconfig --level 345 mysql on
#查看服务状况
chkconfig --list
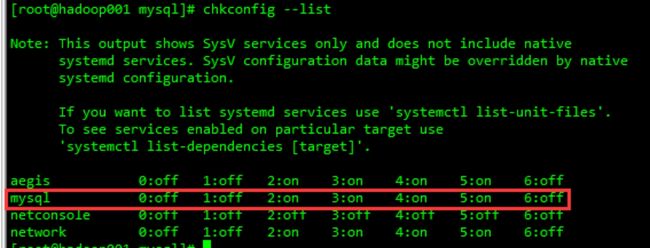
5.10. 服务初始化
yum -y install libaio
su - mysqladmin
后面有关数据库的操作,均在 mysqladmin 用户下操作,因为之前已经设置了 mysql 目录用户为 mysqladmin,注意下面命令中有关 mysql 的目录设置
./bin/mysqld --defaults-file=/etc/my.cnf --user=mysqladmin --basedir=/usr/local/mysql/ --datadir=/usr/local/mysql/data/ --initialize

这是创建的 root 对应的临时密码。
如果没有显示临时密码,可以去 data 目录下的 hostname.err 文件中查找密码,关键字:password
如果没有临时密码,则参考下面的步骤。
如果能找到临时密码,则跳过下面的步骤。
5.10.1. 修改root用户密码
在初始安装之后找不到root密码,或者是后来忘了root密码,则可以按照下面的步骤来修改root密码。
-
首先确认服务器出于安全的状态,也就是没有人能够任意地连接MySQL数据库。因为在重新设置MySQL的root密码的期间,MySQL数据库完全出于没有密码保护的状态下,其他的用户也可以任意地登录和修改MySQL的信息。可以采用将MySQL对外的端口封闭,并且停止Apache以及所有的用户进程的方法实现服务器的准安全状态。最安全的状态是到服务器的Console上面操作,并且拔掉网线。
-
修改MySQL的登录设置(注意MySQL修改的是
my.cnf文件)。vim /etc/my.cnf在
[mysqld]的段中加上两句:skip-grant-tables 、 skip-networking ,保存并且退出 vim,如下图所示: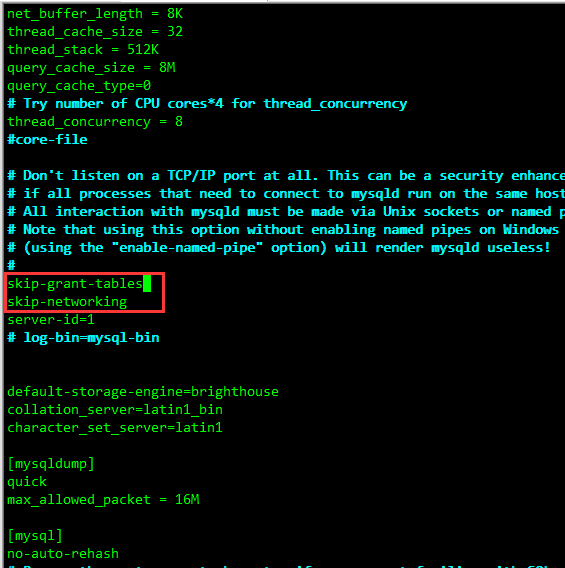 -
重新启动mysqld
/etc/init.d/mysql restart #或者是 service mysql restart -
登录并修改MySQL的root密码
mysql -uroot mysql> USE mysql; mysql> UPDATE user SET authentication_string = password ('root') WHERE User = 'root'; mysql> flush privileges; mysql> quit; -
将MySQL的登录设置修改回来
vim /etc/my.cnf注释掉或删除刚才在
[mysqld]的段中加上的 skip-grant-tables和 skip-networking 。
保存并且退出vim。 -
重新启动mysqld
/etc/init.d/mysqld restart #或者是 service mysqld restart systemctl restart mysqld.service -
恢复服务器到正常工作状态
5.11. 启动
启动时,必须通过 mysqladmin 用户登录,然后通过 service mysql start 来执行,如果提示需要输入 root 用户的密码,则直接终止命令执行(Ctral+C),然后重新执行即可。
5.12. 登录及修改用户密码
hadoop39.ruoze:mysqladmin:/usr/local/mysql/data:>mysql -uroot -p'o1Xunzy5Pq alter user root@localhost identified by 'root';
Query OK, 0 rows affected (0.05 sec)
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION;
Query OK, 0 rows affected, 1 warning (0.02 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
mysql> exit;
Bye
5.13. 配置主从数据库
具体参考 MySQL-8.x 章节中对应的内容,这里不做赘述。
6. MySQL-8.x
6.1. 卸载centos7自带MySQL
rpm -qa | grep postfix
rpm -e postfix --nodeps
rpm -qa | grep mariadb
rpm -e mariadb-libs --nodeps
rpm -qa | grep mysql
说明:
本案例中将mysql及其数据文件全部放到 /usr/local 目录下,这个要根据实际情况存放。通过 df -h 命令可以看到各个分区的实际大小,一定要安装到空间最大的分区。下面为两个案例:

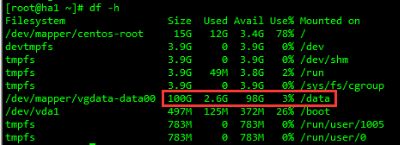
另外,本步骤是按照 /usr/local/mysql目录来安装mysql的,如果在实际操作中修改了mysql的安装位置,一定要注意修改每一步中有关mysql目录的步骤。
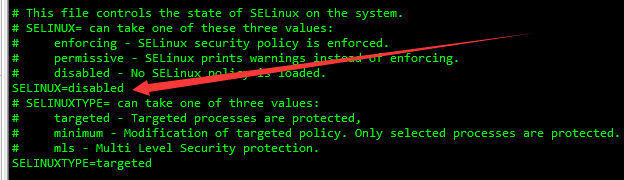
6.2. 关闭selinux
临时关闭:
setenforce 0 #临时关闭
getenforce #查看运行状态(Permissive/Disabled表示关闭,Enforcing表示运行)
永久关闭:
vim /etc/selinux/config
6.3. 目录切换
切换到 /usr/local 目录下
cd /usr/local
6.4. 解压及创建目录
要保证解压之后的文件在 /usr/local下
tar -xvf mysql-8.0.30-linux-glibc2.17-x86_64-minimal.tar.xz
mv mysql-8.0.30-linux-glibc2.17-x86_64 mysql
mkdir mysql/arch mysql/data mysql/tmp
chown -R root.root mysql
6.5. 创建my.cnf
vim /etc/my.cnf
注意下面配置文件中特殊说明的地方,要注意修改
[client]
port = 3306
# 注意 socket 文件的位置,要放到自己解压的 mysql 目录中
socket = /usr/local/mysql/data/mysql.sock
default-character-set=utf8
[mysqld]
port = 3306
# 注意 socket 文件的位置,要放到自己解压的 mysql 目录中
socket = /usr/local/mysql/data/mysql.sock
tls_version = TLSv1.2
skip_replica_start
default-time_zone = '+8:00'
log_timestamps=SYSTEM
explicit_defaults_for_timestamp=true
character-set-server=UTF8MB4
init_connect='SET NAMES utf8'
skip-external-locking
key_buffer_size = 256M
sort_buffer_size = 2M
read_buffer_size = 2M
read_rnd_buffer_size = 4M
max_allowed_packet = 32M
myisam_sort_buffer_size=128M
tmp_table_size=32M
table_open_cache = 512
open-files-limit=10000
thread_cache_size = 8
wait_timeout = 86400
interactive_timeout = 86400
max_connections = 600
# Try number of CPU's*2 for thread_concurrency
#thread_concurrency = 32
#isolation level and default engine
default-storage-engine = INNODB
transaction-isolation = READ-COMMITTED
# 要注意一台机器上的多个 mysql 运行实例 id 要不一样
server-id = 173
# 注意下面这三个目录和文件的位置,要放在自己解压的 mysql 的目录下
basedir = /usr/local/mysql
datadir = /usr/local/mysql/data
pid-file = /usr/local/mysql/data/hostname.pid
#open performance schema
sysdate-is-now
binlog_format = ROW
log_bin_trust_function_creators=1
# 注意下面这两个目录和文件的位置,要放在自己解压的 mysql 的目录下
log-error = /usr/local/mysql/data/hostname.err
log-bin = /usr/local/mysql/arch/mysql-bin
binlog_expire_logs_seconds = 86400
innodb_write_io_threads=16
# 注意下面这三个目录和文件的位置,要放在自己解压的 mysql 的目录下
relay-log = /usr/local/mysql/relay_log/relay-log
relay-log-index = /usr/local/mysql/relay_log/relay-log.index
log_replica_updates=1
gtid_mode=OFF
enforce_gtid_consistency=OFF
event_scheduler=1
# slave
replica_parallel_workers=4
relay_log_recovery=ON
#for replication slave
sync_binlog = 500
#for innodb options
# 注意下面这个目录和文件的位置,要放在自己解压的 mysql 的目录下
innodb_data_home_dir = /usr/local/mysql/data/
innodb_data_file_path = ibdata1:1G;ibdata2:1G:autoextend
# 注意下面这个目录和文件的位置,要放在自己解压的 mysql 的目录下
innodb_log_group_home_dir = /usr/local/mysql/arch
innodb_redo_log_capacity=4294967296
innodb_log_buffer_size = 200M
#根据生产需要,调整pool size
innodb_buffer_pool_size = 2G
# 注意下面这个目录和文件的位置,要放在自己解压的 mysql 的目录下
tmpdir = /usr/local/mysql/tmp
innodb_lock_wait_timeout = 1000
#innodb_thread_concurrency = 0
innodb_flush_log_at_trx_commit = 2
#innodb io features: add for mysql5.5.8
performance_schema
innodb_read_io_threads=4
innodb-write-io-threads=4
innodb-io-capacity=200
#purge threads change default(0) to 1 for purge
innodb_purge_threads=1
innodb_use_native_aio=on
#case-sensitive file names and separate tablespace
innodb_file_per_table = 1
lower_case_table_names=1
[mysqldump]
quick
[mysql]
no-auto-rehash
default-character-set=utf8mb4
[mysqlhotcopy]
interactive-timeout
[myisamchk]
key_buffer_size = 256M
sort_buffer_size = 256M
read_buffer = 2M
write_buffer = 2M
6.6. 创建用户组及用户
groupadd -g 101 dba
# 注意 -d 后面的参数,这个目录是mysql安装路径
useradd -u 514 -g dba -G root -d /usr/local/mysql mysqladmin
id mysqladmin
# 运行结果如下,则正确
# uid=514(mysqladmin) gid=101(dba) groups=101(dba),0(root)
## 一般不需要设置mysqladmin的密码,直接从root或者LDAP用户sudo切换
passwd mysqladmin
## 如果mysqladmin用户已存在,则使用以下命令修改用户的所属组
usermod -u 514 -g dba -G root -d /usr/local/mysql mysqladmin
6.7. 拷贝环境变量
copy 环境变量配置文件至mysqladmin用户的home目录中,为了以下步骤配置个人环境变量
cp /etc/skel/.* /usr/local/mysql
6.8. 配置环境变量
vim mysql/.bash_profile
内容如下:
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
export MYSQL_BASE=/usr/local/mysql
export PATH=${MYSQL_BASE}/bin:$PATH
unset USERNAME
#stty erase ^H
set umask to 022
umask 022
PS1=`uname -n`":"'$USER'":"'$PWD'":>"; export PS1
## end
6.9. 赋权限和用户组
chown mysqladmin:dba /etc/my.cnf
chmod 640 /etc/my.cnf
chown -R mysqladmin:dba /usr/local/mysql
chmod -R 755 /usr/local/mysql
6.10. 配置服务及开机自启动
使用root用户操作
cd /usr/local/mysql
#将服务文件拷贝到init.d下,并重命名为mysql
cp support-files/mysql.server /etc/rc.d/init.d/mysql
#赋予可执行权限
chmod +x /etc/rc.d/init.d/mysql
#删除服务
chkconfig --del mysql
#添加服务
chkconfig --add mysql
chkconfig --level 345 mysql on
#查看服务状况
chkconfig --list
查看服务情况,正确结果应该如下
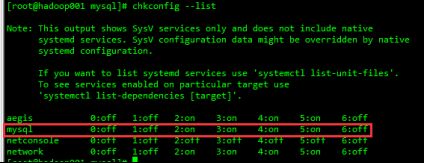
6.11. 配置全局变量
在/etc/profile文件中添加如下代码
export MYSQL_HOME=/data/soft/mysql
export PATH=$PATH:$MYSQL_HOME/bin
6.12. 安装libaio及安装mysql的初始db
yum -y install libaio
su - mysqladmin
后面有关数据库的操作,均在mysqladmin用户下操作,因为之前已经设置了mysql目录用户为mysqladmin。注意下面命令中有关mysql的目录。
./bin/mysqld --defaults-file=/etc/my.cnf --user=mysqladmin --initialize --console
操作成功,界面如下

这是创建的root对应的临时密码
如果没有显示临时密码,可以去data目录下的hostname.err文件中查找密码,关键字:password。
如果没有临时密码,则参考下面的步骤。
如果能找到临时密码,则跳过下面的步骤。
6.12.1. 修改root用户密码
在初始安装之后找不到root密码,或者是后来忘了root密码,则可以按照下面的步骤来修改root密码。
-
首先确认服务器出于安全的状态,也就是没有人能够任意地连接MySQL数据库。因为在重新设置MySQL的root密码的期间,MySQL数据库完全出于没有密码保护的状态下,其他的用户也可以任意地登录和修改MySQL的信息。可以采用将MySQL对外的端口封闭,并且停止Apache以及所有的用户进程的方法实现服务器的准安全状态。最安全的状态是到服务器的Console上面操作,并且拔掉网线。
-
修改MySQL的登录设置(注意MySQL修改的是
my.cnf文件)。vim /etc/my.cnf在
[mysqld]的段中加上两句:skip-grant-tables 、 skip-networking ,保存并且退出vim,如下图所示:
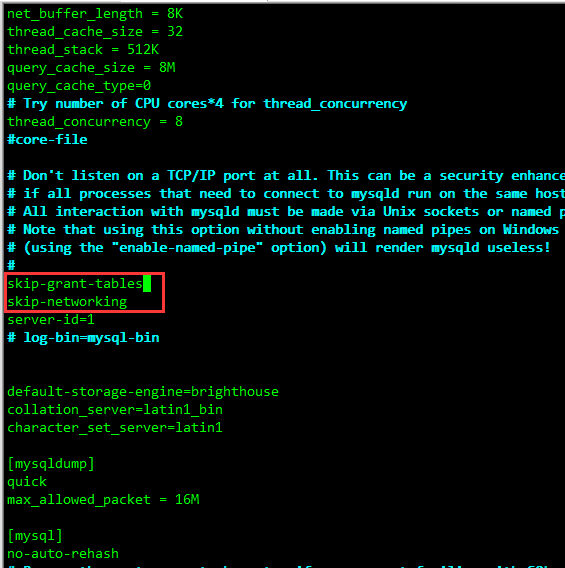
-
重新启动mysqld
/etc/init.d/mysql restart #或者是 service mysql restart -
登录并修改MySQL的root密码
mysql -uroot mysql> USE mysql; mysql> UPDATE user SET authentication_string = password ('root') WHERE User = 'root'; mysql> flush privileges; mysql> quit; -
将MySQL的登录设置修改回来
vim /etc/my.cnf注释掉或删除刚才在
[mysqld]的段中加上的 skip-grant-tables和 skip-networking 。
保存并且退出vim。 -
重新启动mysqld
/etc/init.d/mysqld restart #或者是 service mysqld restart systemctl restart mysqld.service -
恢复服务器到正常工作状态
6.13. 启动
启动时,必须通过mysqladmin用户登录,然后通过service mysql start来执行。该安装可能会有操作权限的问题。
6.14. 登录及修改用户密码
hadoop39.ruoze:mysqladmin:/usr/local/mysql/data:>mysql -uroot -p'o1Xunzy5Pq alter user root@localhost identified by 'root';
Query OK, 0 rows affected (0.05 sec)
mysql> use mysql;
Database changed
mysql> update user set user.host='%' where user.user='root';
Query OK, 0 rows affected, 1 warning (0.02 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
mysql> exit;
Bye
6.15. 配置主从数据库
6.15.1. 停止mysql服务
systemctl stop mysqld.service
systemctl status mysqld.service
6.15.2. 配置主从关系
6.15.2.1. 修改主配置文件
编辑主master服务器配置文件/etc/my.cnf
在[mysqld]节点下加入两句话
server-id=1
log-bin=mysql-bin #启用二进制日志;
6.15.2.2. 修改从配置文件
修改/etc/my.cnf,增加一行,注意只增加service-id,不需要开启二进制文件,因为从库产生的是relay中继日志文件,以后添加新的从数据库,只需要添加新的server-id即可,不过要不一致。
server-id=2
注意:在修改完数据库的配置文件之后,要记得重启数据库服务。
6.15.2.3. 配置主从关系
登录主数据库,执行以下 mysql 命令:
flush tables with read lock; #数据库锁表,设置为只读
show master status; #查看master状态,主要看file和position值
unlock tables; #从服务启动之后,要记得解除锁定
登录从数据库,执行以下 mysql 命令:
change master to master_host='192.168.170.43', #主数据库IP地址
master_port=3306, #主数据库端口号
master_user='root', #主数据库用户名
master_password='root', #主数据库密码
master_log_file='mysql-bin.000007', #主数据库二进制文件名(注意要修改该值)
master_log_pos=609; #主数据库二进制文件位置(注意要修改该值)
FLUSH PRIVILEGES;
start slave; #开启从服务
stop slave; #停止从服务
reset slave; #重置从服务
show slave status; #查看从服务状态
注意:
在配置从服务时,需要主服务锁表,然后运行代码配置从服务,并启动从服务,查看从服务状态,如果状态正确,则主服务解锁。
配置第二个从服务时,需要停止第一个从服务,并且主服务锁表。
如果第二个从服务配置失败,重新配置前需要停止本从服务,并且重置本从服务,然后重新配置。
从服务配置好启动之后,要记得主服务解锁之后,才能对主服务进行写操作。
6.15.3. 同步部分库或表
实际应用中可能会用到单个表的同步,或者部分表的同步,只需要在主库的/etc/my.cnf里加上
replicate-do-table=tablename #只复制某个表
replicate-wild-do-table=tablename% #只复制某些表(可用匹配符)
replicate-do-db=dbname #只复制某个库
replicte-wild-do-db=dbname% #只复制某些库
replicate-ignore-table=tablename #不复制某个表
配置,然后重启数据库即可。
7. redis
7.1. 安装源
yum -y install gcc g++ gcc-c++ make cpp binutils glibc glibc-kernheaders glibc-common glibc-devel
7.2. 安装redis
mkdir -p data01/app/study
cd data01/app/study
wget http://download.redis.io/releases/redis-5.0.8.tar.gz #这是从网上下载,也可以拷贝。
tar -xvf redis-5.0.8.tar.gz
cd redis-5.0.8/src
make MALLOC=libc #编译,这种方式编译之后可以将脚本文件生成到bin目录中
make install #进行安装
make install PREFIX=/usr/local/src/redis #指定安装目录,注意该安装方式只会将脚本文件放到指定目录下的bin目录,不会移动配置文件,可以不添加后面的PREFIX。
注:
如果报错:
cc: error: ../deps/hiredis/libhiredis.a: No such file or directory
cc: error: ../deps/lua/src/liblua.a: No such file or directory
则进入redis目录下的deps目录下运行如下命令,就OK了
make lua hiredis linenoise
7.3. 配置
编译redis.conf文件,修改以下参数,注意不要写后面的注释
bind 172.16.22.123 #修改为本机IP地址,不要使用127.0.0.1,表示外部访问需要通过该IP地址访问(可以注释掉该配置,不限制访问IP)
protected-mode no #去除保护模式,如果为yes,则只能在本机访问,别的机器都访问不了
port 6379 #设置redis服务的端口号,如果配置多个实例,需要多个实例的端口号不一致
timeout 30 #设置连接redis的超时时间(秒),所有上线的项目必须设置这个值
daemonize yes #设置服务后台运行
databases 16 #设置redis内存数据库数量,默认即可
pidfile /data01/app/study/redis-5.0.8/redis_6379.pid #设置pid文件位置
dir ./ #AOF文件和RDB文件所在目录,如果有主从配置,需要指定具体目录
logfile /data01/app/study/redis-5.0.8/log/redis-6379.log # 日志文件目录,默认空字符串不会将日志记录到文件中
save m n #表示在时间m秒内被修改的键的个数大于n时,会触发BGSAVE命令的执行。它是BGSAVE命令自动触发的条件;如果没有设置该配置,则表示自动的RDB持久化被关闭
dbfilename dump-6379.rdb #设置数据落地的存储文件名,如果配置多实例,必须更改该值,否则会发生数据落地错误
maxmemory 512mb #设置redis占用系统内存的大小,一般为512mb/1gb/2gb/5gb,在实际开发中必须设置,如果不设置,redis会占领所有的物理内存。
requirepass 123 #设置客户端连接后进行任何其他指定前需要使用的密码,这个是客户端连接密码,如果这个节点为主节点,则从节点的masterauth属性值则该属性的值,建议主从节点都设置这两个属性,用于从节点提升为主节点时使用
7.4. 启动
./bin/redis-server redis.conf & 如果添加 & 符号,表示是后台启动,不过在配置文件中指定后台运行,则可省略这个
./bin/redis-cli 默认连接:IP 127.0.0.1 端口 6379
./bin/redis-cli –h 172.16.22.123 –p 6379 指定IP端口
7.5. 停止
./bin/redis-cli -h 172.16.22.123 -p 6379 -a 123456 shutdown -a 指定密码,如果没有设置,可以不指定
7.6. 多实例
redis多实例,复制redis.conf,修改端口号、数据存储文件名和配置文件名即可,一个配置文件对应一个redis实例。
启动命令:
redis-server redis6380.conf
要启动多个实例,只需按照上面的命令启动多个配置文件即可。
7.7. 主从复制
启动三个节点,然后选择两个节点作为从节点,都设置对应的主节点即可。
7.7.1. 注意
为了区分不同主从不同节点的文件,可以新建一个目录专门用户保存备份文件(AOF、RDB)、配置文件、日志文件,主从配置中都需要修改dir、logfile、dbfilename、pidfile属性,比如创建的目录为/data01/app/study/redis-5.0.8/cluster,配置了集群模式,则dir配置为/data01/app/study/redis-5.0.8/cluster,logfile配置为/data01/app/study/redis-5.0.8/cluster/log.log,dbfilename配置只需要修改dump-6379.rdb中的端口号,用于辨认即可,pidfile配置为/data01/app/study/redis-5.0.8/cluster/redis.pid。如果所有节点都在同一个机器上,可以再增加一个目录,目录名即为端口号,用于区分不同端口号节点信息。最后增加slaveof 配置,用于配置连接的主节点IP和端口号即可,具体一个slave实例如下,注意,该节点是在redis安装的根目录下创建了cluster/6380目录,然后所有文件统一放到该目录下。
将单节点配置好的文件复制到对应目录下,修改名称为redis-6380.conf
port 6380
pidfile /data01/app/study/redis-5.0.8/cluster/6380/redis_6380.pid
slaveof 172.16.22.123 6379 #配置主节点IP和端口号
dbfilename dump-6380.rdb
dir /data01/app/study/redis-5.0.8/cluster/6380
logfile /data01/app/study/redis-5.0.8/cluster/6380/redis_6380.log
masterauth 123 #如果主节点设置了requirepass,则从节点需要设置这个参数和主节点密码保持一致,用于连接主节点时验证使用
7.7.2. 启动
./bin/redis-server cluster/6380/redis-6380.conf
多节点需要指定对应的配置文件启动多次
7.7.3. 停止
./bin/redis-cli shutdown -h 172.16.22.123 -p 6380
7.7.4. 检查配置
./bin/redis-cli -h 172.16.22.123 -p 6379 -a 123
info #查看所有信息
info Replication #只查看Replication片段信息
7.8. 哨兵
主要是设置配置文件的端口号和监控redis节点
修改sentinel.conf配置文件
bind 127.0.0.1 172.16.22.156
protected-mode no
port 26379
daemonize yes
pidfile /data01/app/study/redis-5.0.8/sentinel/1002/sentinel_1002.pid
logfile pidfile /data01/app/study/redis-5.0.8/sentinel/1002/log_1002.log
sentinel monitor mymaster 172.16.22.156 1001 2 #mymaster表示监视集群名称,监视多个集群,需要配置不同的集群名称,后面跟着的是主节点的IP和端口号,最后的是选举,多少个sentinel角色认为主节点挂了,才客观认为主节点挂了
sentinel auth-pass mymaster 123 #监视集群主节点的密码
启动
./bin/redis-sentinel sentinel.conf #启动哨兵
./bin/redis-sentinel sentinel2.conf #启动哨兵2,形成哨兵的高可用
7.9. 集群
7.9.1. 配置集群
在单节点配置的基础上修改一下配置,需要几个节点,就赋值几个配置文件用以启动节点服务即可
cluster-enabled yes
cluster-config-file /data/app/redis-5.0.8/cluster/7001/nodes-7001.conf
7.9.2. 启动各个节点
按照单节点配置的命令启动即可,启动之后,查看
ps -ef|grep redis #查看redis启动状态
7.9.3. 创建集群
执行以下命令,只需要执行一次
./bin/redis-cli --cluster create --cluster-replicas 1 -a 123456 192.168.163.201:7000 192.168.163.201:7001 192.168.163.201:7002 192.168.163.201:7003 192.168.163.201:7004 192.168.163.201:7005 192.168.163.201:7006 192.168.163.201:7007 192.168.163.201:7008
7.9.4. 登录集群
redis-cli -c -h 192.168.161.41 -p 7000 -a 123 #注意IP地址为集群所在系统的IP地址
8. zookeeper
8.1. 安装ZooKeeper
tar -xvf apache-zookeeper-3.6.3-bin.tar.gz
mv apache-zookeeper-3.6.3-bin/ zookeeper-3.6.3
chown -R root:root zookeeper-3.6.3/
cd zookeeper-3.6.3 #进入zookeeper根目录
mkdir log #创建日志文件路径
mkdir data #创建数据文件路径,默认/tmp/zookeeper下
cd data #进入数据目录
vim myid #创建myid文件,这个文件在data目录中,第一个 zookeeper节点,这个文案内容为1,对应zoo.cfg中配置的server.1(注意,必须是server.后面的那个数字)
8.2. 配置zoo.cfg文件
cd conf #进入配置目录
cp zoo_sample.cfg zoo.cfg #复制模板文件
vim zoo.cfg #修改模板文件
需修改文件内容如下
tickTime=2000 #tickTime心跳时间,
clientPort=2181 #访问端口
dataDir=/usr/local/src/zookeeper/zookeeper-3.6.3/data #设置数据文件路径(注意路径)
dataLogDir=/usr/local/src/zookeeper/zookeeper-3.6.3/log #设置日志路径
autopurge.purgeInterval=1 # 开启日志与镜像(ZooKeeper快照)文件自动清理,否则运行一段时间后日志与镜像文件会占满磁盘
server.1=192.168.163.5:2888:3888 #配置集群,最少3个节点,注意IP地址(注意,必须是以server.开头,后面跟一个数字,这个数字和data目录下的myid文件里面的数字保持一致)
server.2=192.168.163.6:2888:3888 #2888指follower连接leader端口,原子广播端口
server.3=192.168.163.7:2888:3888 #3888指定选举的端口
server.3=192.168.163.7:2888:3888:observe #设置该节点为观察者,可选设置
然后将整个目录拷贝到其他机器,并且修改myid文件内容为对应机器的编号,即可完成多节点 zookeeper 的部署。
8.3. 启动
sh bin/zkServer.sh start #启动ZK服务
sh bin/zkServer.sh start-foreground #日志启动方式
sh bin/zkServer.sh stop #停止ZK服务
sh bin/zkServer.sh restart #重启ZK服务
jps #检查服务
sh bin/zkServer.sh status #查看ZK状态
9. rabbitMQ
9.1. 安装Erlang
添加yum支持
cd /usr/local/src/
mkdir rabbitmq
cd rabbitmq
在线安装(比较慢)
wget http://packages.erlang-solutions.com/erlang-solutions-1.0-1.noarch.rpm
rpm -ivh erlang-solutions-1.0-1.noarch.rpm
yum -y install erlang
注意上面的命令将下载60个rpm,可能因为网络慢而其中某个下载失败,再次运行即可,成功的会自动跳过。
或者手动安装
#下载
https://packages.erlang-solutions.com/erlang/esl-erlang-src/otp_src_17.0-rc2.tar.gz
#上传
esl-erlang_17.3-1~centos~6_amd64.rpm
#安装
yum install esl-erlang_17.3-1~centos~6_amd64.rpm
#上传
esl-erlang-compat-R14B-1.el6.noarch.rpm
#安装
yum install esl-erlang-compat-R14B-1.el6.noarch.rpm
9.2. 安装rabbitMQ
上传:rabbitmq-server-3.6.1-1.noarch.rpm文件到/usr/local/src/rabbitmq/
安装:
rpm –ivh rabbitmq-server.3.6.1-1.noarch.rpm
9.3. 开启远程用户访问
默认只允许localhost用户访问。
cp /usr/share/doc/rabbitmq-server-3.6.1/rabbitmq.config.example /etc/rabbitmq/rabbitmq.config
安装目录:/usr/share/doc/rabbitmq-server-3.6.1
vi /etc/rabbitmq/rabbitmq.config
修改第64行
注意:文件有两处下面代码,vi/vim都有提示行数,必须找到64行的修改,否则会导致启动失败。
%% {loopback_users, []},
修改1:去掉前面的两个%%
修改2:最后面的逗号,保存。
9.4. 开启后台web管理界面
rabbitmq-plugins enable rabbitmq_management
9.5. 防火墙打开15672和5672端口
/sbin/iptables –I INPUT –p tcp --dport 15672 –j ACCEPT #控制台端口
/sbin/iptables –I INPUT –p tcp --dport 5672 –j ACCEPT #程序访问端口
/etc/rc.d/init.d/iptables save
/etc/init.d/iptables status
9.6. 启动、停止、重启服务
service rabbitmq-server start
service rabbitmq-server stop
service rabbitmq-server restart
chkconfig rabbitmq-server on #设置开机启动
错误日志目录:/var/log/rabbitmq/startup_err
9.7. 登录rabbitMQ
9.7.1. 登录
http://localhost:15672/
默认用户名密码都为guest
9.7.2. 创建用户

9.7.3. 添加Virtual Hosts
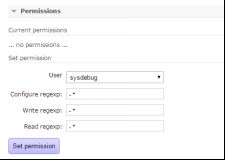
9.7.4. 设置权限
9.7.5. 选择可以访问的用户
10. Hadoop单机搭建-2.x
10.1. 提前工作
安装配置jdk、关闭防火墙
10.2. 修改主机名
查看主机名:
hostname
临时修改:
hostname node01
永久修改:
hostnamectl set-hostname node01
10.3. 配置hosts文件
vim /etc/hosts
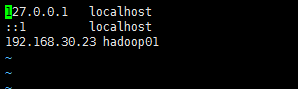
修改hosts文件,以后用到IP连接的地方就可以直接使用hadoop01代替IP地址了。
10.4. 配置免密登录
ssh-keygen
ssh-copy-id root@hadoop01 #想从这台机器免密登录哪个机器,就把公钥文件发送到哪个机器上。
10.5. 上传解压
过程省略,解压路径为:
![]()
要记着这个路径,后面的配置要用到。
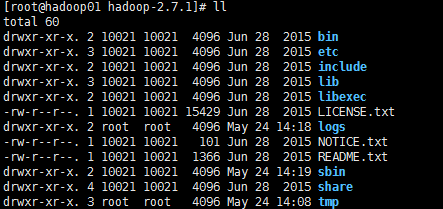
bin目录:命令脚本
etc/hadoop:存放hadoop的配置文件
lib目录:hadoop运行的依赖jar包
sbin目录:启动和关闭hadoop等命令都在这里
libexec目录:存放的也是hadoop命令,但一般不常用
最常用的就是bin和etc目录
10.6. 在根目录下创建tmp目录
mkdir tmp #存放Hadoop运行时产生的文件目录
10.7. 配置hadoop-env.sh文件
cd etc/hadoop
vim hadoop-env.sh
修改JAVA_HOME路径和HADOOP_CONF_DIR路径,注意路径一定要写对,里面原始的获取系统路径的方式可能不起作用。
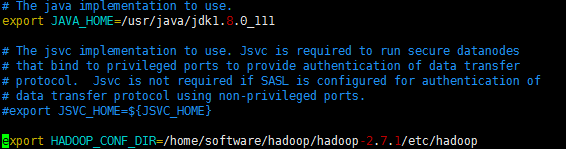
source hadoop-env.sh #使配置立即生效
10.8. 修改core-site.xml
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://hadoop01:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/software/hadoop/hadoop-2.7.1/tmpvalue>
property>
<property>
<name>fs.trash.intervalname>
<value>1440value>
property>
configuration>
10.9. 修改hdfs-site.xml
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
configuration>
10.10. 修改mapred-site.xml
cp mapred-site.xml.template mapred-site.xml #拷贝模板文件并重命名
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
10.11. 修改yarn-site.xml
vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>hadoop01value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>
10.12. 配置slaves文件
vim slaves
添加主机名
hadoop01
10.13. 配置hadoop的环境变量
vim /etc/profile #修改配置文件,使hadoop命令可以在任何目录下执行,下面是修改后的代码
JAVA_HOME=/usr/java/jdk1.8.0_111
HADOOP_HOME=/home/software/hadoop/hadoop-2.7.1
JAVA_BIN=/usr/java/jdk1.8.0_111/bin
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HAME/sbin:$PATH
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME JAVA_BIN PATH CLASSPATH HADOOP_HOME
注意PATH多个参数值之间用冒号隔开,所有的参数都在**$PATH**之前
source /etc/profile #使配置文件生效
10.14. 格式化namenode
hadoop namenode -format
中间如果提示是否需要重新格式化,则根据自己的需求输入即可。

如果出现successfully formatted,则表示格式化成功。
10.15. 启动分布式文件系统
进入Hadoop安装目录下的sbin目录,执行:
sh start-dfs.sh
如果要停止,执行
sh stop-dfs.sh
之后执行
jps
如果出现下图则表示执行成功

10.16. HDFS控制台页面
通过浏览器访问:http://node01:50070来查看hdfs系统
11. Hadoop集群搭建-3.x
11.1. 角色介绍
| node01 | node02 | node03 | |
|---|---|---|---|
| NameNode | nn1 | nn1 | |
| JournalNode | √ | √ | √ |
| DataNode | √ | √ | √ |
| ZKFC | √ | √ | |
| ResourceManager | rm1 | rm2 | |
| NodeManager | √ | √ | √ |
11.2. 准备工作
永久关闭每台机器的防火墙(略),安装配置JDK(略),配置open file
无需重启
ulimit -n 131072
需重启
vim /etc/security/limits.conf
增加以下内容
* soft nofile 131072
* hard nofile 131072
11.3. 修改每台主机名
查看主机名
hostname
临时修改
hostname node01
永久修改
hostnamectl set-hostname node01
11.4. 配置每台主机的hosts文件
vim /etc/hosts
增加以下内容
192.168.244.101 node01
192.168.244.102 node02
192.168.244.103 node03
可以手动配置每台主机的hosts文件,也可以通过:scp /etc/hosts root@node02:/etc/ 命令将 node01 的 hosts 文件远程拷贝至所有的主机。
11.5. 为所有主机之间配置免密登录
可以在每台主机上手动执行 ssh-keygen、ssh-copy-id root@node01来生成密钥文件,然后分别拷贝至所有的主机(包括自己),也可以写一个脚本文件来简化操作,下面是脚本文件代码示例:
#!/bin/bash
echo "\n","\n","\n" > ssh-keygen
echo yes,root > ssh-copy-id root@node01
echo yes,root > ssh-copy-id root@node02
echo yes,root > ssh-copy-id root@node03
编写完这个脚本文件之后,修改该文件的权限,增加可执行权限,之后直接执行即可。
将这个脚本文件远程传输给所有的主机之后,分别修改脚本文件的权限,之后执行。执行完之后所有主机之间就可以互相免密登录了。
11.6. 安装配置zookeeper
安装和配置zookeeper
11.7. 安装和配置01节点的hadoop
11.7.1. 解压
解压hadoop文件
tar -xvf hadoop-3.2.4.tar.gz
11.7.2. 修改hadoop环境文件
cd hadoop-3.2.4/etc/hadoop/
hadoop-env.sh
#Java安装目录,建议使用JDK 1.8:
export JAVA_HOME=/data/soft/jdk1.8.0_341
#hadoop配置文件目录:
export HADOOP_CONF_DIR=/data/soft/hadoop-3.2.4/etc/hadoop
#配置Hadoop NameNode运行堆内存为12 GB
export HDFS_NAMENODE_OPTS="-Xmx12g -Xms12g -Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS"
#配置Hadoop DataNode运行堆内存为12 GB
export HDFS_DATANODE_OPTS="-Xmx12g -Xms12g -Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS"
#配置Hadoop进程id文件路径,默认路径为/tmp操作系统重启的时候可能会被清除
export HADOOP_PID_DIR=/home/hadoop/hadoop-3.2.4/pid
export HADOOP_SECURE_PID_DIR=/data/app/hadoop-3.2.4/pid
mapred-env.sh
export HADOOP_MAPRED_PID_DIR=/data/soft/hadoop-3.2.4/pid
yarn-env.sh
export HADOOP_PID_DIR=/data/soft/hadoop-3.2.4/pid
切换到 hadoop-3.2.4/sbin/ 目录下
hadoop-daemon.sh
export HADOOP_PID_DIR=/data/soft/hadoop-3.2.4/pid
yarn-daemon.sh
export YARN_PID_DIR=/data/soft/hadoop-3.2.4/pid
11.8. 配置01节点的core-site.xml
切换到 hadoop-3.2.4/etc/hadoop 目录下
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://hadoopClustervalue>
<final>truefinal>
property>
<property>
<name>io.file.buffer.sizename>
<value>131072value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/data/soft/hadoop-3.2.4/tmpvalue>
property>
<property>
<name>ha.zookeeper.quorumname>
<value>node01:2181,node02:2181,node03:2181value>
property>
<property>
<name>io.compression.codecsname>
<value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.SnappyCodec
value>
property>
<property>
<name>fs.trash.intervalname>
<value>1440value>
property>
<property>
<name>fs.trash.checkpoint.intervalname>
<value>720value>
property>
<property>
<name>ha.failover-controller.cli-check.rpc-timeout.msname>
<value>60000value>
property>
<property>
<name>ipc.client.connect.timeoutname>
<value>60000value>
property>
<property>
<name>hadoop.proxyuser.root.hostsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.root.groupsname>
<value>*value>
property>
configuration>
11.9. 配置01节点的hdfs-site.xml
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.nameservicesname>
<value>hadoopClustervalue>
property>
<property>
<name>dfs.ha.namenodes.hadoopClustername>
<value>nn1,nn2value>
property>
<property>
<name>dfs.ha.automatic-failover.enabled.nsname>
<value>truevalue>
property>
<property>
<name>ha.zookeeper.quorumname>
<value>node01:2181,node02:2181,node03:2181value>
property>
<property>
<name>dfs.namenode.rpc-address.hadoopCluster.nn1name>
<value>node01:9000value>
property>
<property>
<name>dfs.namenode.rpc-address.hadoopCluster.nn2name>
<value>node02:9000value>
property>
<property>
<name>dfs.namenode.http-address.hadoopCluster.nn1name>
<value>node01:50070value>
property>
<property>
<name>dfs.namenode.http-address.hadoopCluster.nn2name>
<value>node02:50070value>
property>
<property>
<name>dfs.namenode.servicerpc-address.hadoopCluster.nn1name>
<value>node01:53310value>
property>
<property>
<name>dfs.namenode.servicerpc-address.hadoopCluster.nn2name>
<value>node02:53310value>
property>
<property>
<name>dfs.namenode.name.dir.hadoopClustername>
<value>file:/data/soft/hadoop-3.2.4/nnvalue>
<final>truefinal>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://node01:8485;node02:8485;node03:8485/hadoopClustervalue>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.hadoopClustername>
<value>
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
value>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/data/soft/hadoop-3.2.4/tmp/journalvalue>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>sshfencevalue>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/root/.ssh/id_rsavalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>/data/soft/hadoop-3.2.4/dnvalue>
<final>truefinal>
property>
<property>
<name>dfs.namenode.checkpoint.dir.hadoopClustername>
<value>/data/soft/hadoop-3.2.4/dfs/namesecondaryvalue>
<final>truefinal>
property>
<property>
<name>dfs.datanode.du.reservedname>
<value>32212254720value>
<final>truefinal>
property>
<property>
<name>dfs.hosts.excludename>
<value>/data/soft/hadoop-3.2.4/etc/hadoop/hosts.excludevalue>
property>
<property>
<name>dfs.replicationname>
<value>3value>
<final>truefinal>
property>
<property>
<name>dfs.datanode.balance.bandwidthPerSecname>
<value>104857600value>
property>
<property>
<name>dfs.client.read.shortcircuitname>
<value>truevalue>
property>
<property>
<name>dfs.domain.socket.pathname>
<value>/data/soft/hadoop-3.2.4/dn_socketvalue>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
<property>
<name>dfs.datanode.fsdataset.volume.choosing.policyname>
<value>org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicyvalue>
property>
<property>
<name>>dfs.datanode.available-space-volume-choosing-policy.balanced-space-thresholdname>
<value>107374182400value>
property>
configuration>
11.10. 配置01节点的mapred-site.xml
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>node01:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>node01:19888value>
property>
<property>
<name>mapreduce.cluster.local.dirname>
<value>/data/soft/hadoop-3.2.4/mapred/localvalue>
property>
<property>
<name>mapreduce.jobtracker.system.dirname>
<value>${hadoop.tmp.dir}/mapred/systemvalue>
property>
<property>
<name>mapreduce.jobtracker.heartbeats.in.secondname>
<value>100value>
property>
<property>
<name>mapreduce.tasktracker.outofband.heartbeatname>
<value>truevalue>
property>
<property>
<name>mapreduce.jobtracker.staging.root.dirname>
<value>${hadoop.tmp.dir}/mapred/stagingvalue>
property>
<property>
<name>mapreduce.cluster.temp.dirname>
<value>${hadoop.tmp.dir}/mapred/tempvalue>
property>
<property>
<name>mapreduce.map.memory.mbname>
<value>2048value>
property>
<property>
<name>mapreduce.map.java.optsname>
<value>-Xmx2048mvalue>
property>
<property>
<name>mapreduce.reduce.java.optsname>
<value>-Xmx2048mvalue>
property>
<property>
<name>mapreduce.map.cpu.vcoresname>
<value>1value>
property>
<property>
<name>mapreduce.reduce.cpu.vcoresname>
<value>1value>
property>
<property>
<name>mapreduce.map.output.compressname>
<value>truevalue>
property>
<property>
<name>mapreduce.map.output.compress.codecname>
<value>org.apache.hadoop.io.compress.SnappyCodecvalue>
property>
<property>
<name>mapreduce.output.fileoutputformat.compressname>
<value>truevalue>
property>
<property>
<name>mapreduce.output.fileoutputformat.compress.typename>
<value>BLOCKvalue>
property>
<property>
<name>mapreduce.output.fileoutputformat.compress.codecname>
<value>org.apache.hadoop.io.compress.SnappyCodecvalue>
property>
<property>
<name>mapreduce.task.timeoutname>
<value>180000value>
property>
<property>
<name>mapreduce.jobtracker.handler.countname>
<value>60value>
property>
<property>
<name>mapreduce.reduce.shuffle.parallelcopiesname>
<value>20value>
property>
<property>
<name>mapreduce.tasktracker.http.threadsname>
<value>60value>
property>
<property>
<name>mapreduce.job.reduce.slowstart.completedmapsname>
<value>0.8value>
property>
<property>
<name>mapreduce.task.io.sort.factorname>
<value>60value>
property>
<property>
<name>mapreduce.reduce.input.buffer.percentname>
<value>0.8value>
property>
<property>
<name>mapreduce.map.combine.minspillsname>
<value>3value>
property>
<property>
<name>mapreduce.jobtracker.taskschedulername>
<value>org.apache.hadoop.mapred.FairSchedulervalue>
property>
configuration>
11.11. 配置01节点的yarn-site.xml
vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.ha.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.ha.rm-idsname>
<value>rm1,rm2value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm1name>
<value>node01value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm2name>
<value>node02value>
property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1name>
<value>node01:8088value>
property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2name>
<value>node02:8088value>
property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2name>
<value>node02:8088value>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>node01value>
property>
<property>
<name>yarn.resourcemanager.recovery.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.store.classname>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStorevalue>
property>
<property>
<name>yarn.resourcemanager.zk-addressname>
<value>node01:2181,node02:2181,node03:2181value>
property>
<property>
<name>yarn.resourcemanager.cluster-idname>
<value>yarn-havalue>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
<property>
<name>yarn.resourcemanager.scheduler.classname>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacitySchedulervalue>
property>
<property>
<name>yarn.resourcemanager.scheduler.monitor.enablename>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.scheduler.monitor.policiesname>
<value>org.apache.hadoop.yarn.server.resourcemanager.monitor.capacity.ProportionalCapacityPreemptionPolicyvalue>
property>
<property>
<name>yarn.resourcemanager.monitor.capacity.preemption.observe_onlyname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.monitor.capacity.preemption.total_preemption_per_roundname>
<value>1value>
property>
<property>
<name>yarn.resourcemanager.monitor.capacity.preemption.max_ignored_over_capacityname>
<value>0value>
property>
<property>
<name>yarn.resourcemanager.monitor.capacity.preemption.natural_termination_factorname>
<value>1value>
property>
<property>
<name>yarn.nodemanager.resource.cpu-vcoresname>
<value>12value>
property>
<property>
<name>yarn.nodemanager.local-dirsname>
<value>/home/hadoop/data01/nm-local-dirvalue>
<final>truefinal>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>604800value>
property>
<property>
<name>yarn.application.classpathname>
<value>
/data/soft/hadoop-3.2.4/etc/hadoop,
/data/soft/hadoop-3.2.4/share/hadoop/common/*,
/data/soft/hadoop-3.2.4/share/hadoop/common/lib/*,
/data/soft/hadoop-3.2.4/share/hadoop/hdfs/*,
/data/soft/hadoop-3.2.4/share/hadoop/hdfs/lib/*,
/data/soft/hadoop-3.2.4/share/hadoop/mapreduce/*,
/data/soft/hadoop-3.2.4/share/hadoop/mapreduce/lib/*,
/data/soft/hadoop-3.2.4/share/hadoop/yarn/*,
/data/soft/hadoop-3.2.4/share/hadoop/yarn/lib/*
value>
property>
<property>
<name>yarn.log.server.urlname>
<value>http://node01:19888/jobhistory/logsvalue>
property>
<property>
<description>The hostname of the Timeline service web application.description>
<name>yarn.timeline-service.hostnamename>
<value>node01value>
property>
<property>
<description>Address for the Timeline server to start the RPC server.description>
<name>yarn.timeline-service.addressname>
<value>${yarn.timeline-service.hostname}:10200value>
property>
<property>
<description>The http address of the Timeline service web application.description>
<name>yarn.timeline-service.webapp.addressname>
<value>${yarn.timeline-service.hostname}:8188value>
property>
<property>
<description>The https address of the Timeline service web application.description>
<name>yarn.timeline-service.webapp.https.addressname>
<value>${yarn.timeline-service.hostname}:8190value>
property>
<property>
<description>Handler thread count to serve the client RPC requests.description>
<name>yarn.timeline-service.handler-thread-countname>
<value>60value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.client.thread-countname>
<value>60value>
property>
<property>
<name>yarn.resourcemanager.scheduler.client.thread-countname>
<value>60value>
property>
<property>
<name>yarn.nodemanager.vmem-check-enabledname>
<value>falsevalue>
property>
<property>
<name>yarn.scheduler.maximum-allocation-mbname>
<value>4086value>
property>
<property>
<name>yarn.scheduler.minimum-allocation-mbname>
<value>1024value>
property>
<property>
<name>yarn.nodemanager.vmem-pmem-rationame>
<value>4value>
property>
<property>
<name>mapred.child.java.optsname>
<value>-Xmx1024mvalue>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log.server.urlname>
<value>http://node01:19888/jobhistory/logsvalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>604800value>
property>
configuration>
11.12. 配置01节点的workers文件
vim workers
内容为主机名称
node01
node02
node03
11.13. 远程拷贝
将整个hadoop文件夹远程拷贝至其他所有的主机上对应的位置。
scp -r hadoop-3.2.4/ node02:/data/soft/
scp -r hadoop-3.2.4/ node03:/data/soft/
11.14. 配置hadoop的环境变量
vim /etc/profile
增加以下内容
export HADOOP_HOME=/data/soft/hadoop-3.2.4
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HAME/sbin:$PATH
export HADOOP_CLASSPATH=`hadoop classpath`
# 设置 hadoop 允许以 root 用户运行
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_JOURNALNODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HADOOP_SHELL_EXECNAME=root
使修改生效
source /etc/profile
修改所有主机的profile文件,然后分别使他们生效。
11.15. 启动zookeeper集群
分贝进入01、02、03节点zookeeper的bin目录下,然后执行:
sh zkServer.sh start
如果之前已经启动了 zookeeper 集群,就不需要执行了。
11.16. 格式化zookeeper
在01节点上执行
hdfs zkfc -formatZK
这个指令的作用是在zookeeper集群上生成ha节点,而且这个命令只可在初始化时执行一次。集群运行过程中出现了问题,要尽量使用其他方式进行解决,最后的手段才应该是使用该命令格式化 zookeeper 中数据。
11.17. 启动journalnode集群
根据 hdfs-site.xml 文件中 dfs.namenode.shared.edits.dir 配置,在所有节点上执行(注意观察日志,看是否都起来了).
hdfs --daemon start journalnode
在 3.x 版本,所有角色的启动,都可以使用上面的 hdfs 命令进行启动。
11.18. 格式化01节点的namenode
在01节点上执行(bin目录下)
hdfs namenode -format

11.19. 启动01节点的namenode
在01节点上执行
hdfs --daemon start namenode
jps -ml | grep namenode
11.20. 启动02节点的namenode节点
复制元数据,注意路径为 dfs.namenode.name.dir.hadoopCluster 配置的路径
scp -r /data/soft/hadoop-3.2.4/nn node02:/data/soft/hadoop-3.2.4/
在02节点上执行
hdfs --daemon start namenode
jps -ml | grep namenode
11.21. 启动zkfc
FalioverControllerActive失败重启,高可用
在01,02节点上执行
hdfs --daemon start zkfc
jps -ml | grep DFSZKFailoverController
11.22. 在01,02,03节点上启动datanode节点
在01,02,03节点上分别执行(sbin目录下)
hdfs --daemon start datanode
jps -ml | grep datanode
曾发现错误:
自动生成的一些本地目录,所属用户和所属用户组并不是安装用户导致无法启动,因此需要查看安装目录下自动生成的目录权限,如果不对,则需要修改所属用户。
11.23. 在01节点上启动yarn进程
在01节点上执行
yarn --daemon start resourcemanager
jps -ml | grep resourcemanager
启动成功后,01节点上应该有 resourcemanager 的进程
11.24. 在02节点上启动副Resoucemanager
在02节点上执行
yarn --daemon start resourcemanager
jps -ml | grep resourcemanager
11.25. 启动所有NodeManager
在所有节点执行
yarn --daemon start nodemanager
jps -ml | grep nodemanager
11.26. 启动historyserver服务
根据mapred-site.xml文件中的配置mapreduce.jobhistory.address值,在对应的机器上执行以下命令:
mapred --daemon start historyserver
11.27. 测试
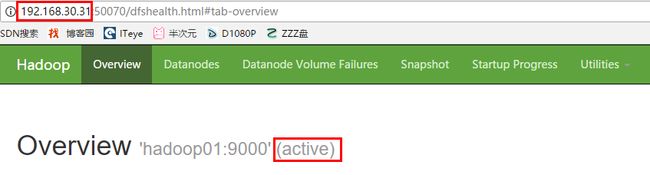
输入地址:http://192.168.30.31:50070,查看 namenode 的信息,是active状态的
输入地址:http://192.168.30.322:50070,查看*namenode的信息,是standby**状态
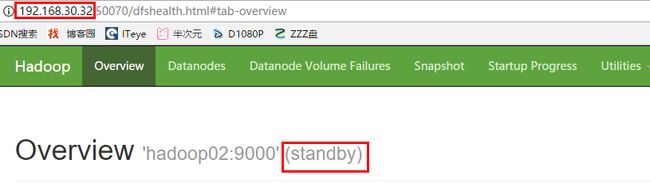
然后停掉01节点的namenode,此时发现02节点standby的namenode变为active。之后再次启动01节点的namenode,发现01节点的namenode为standby状态。
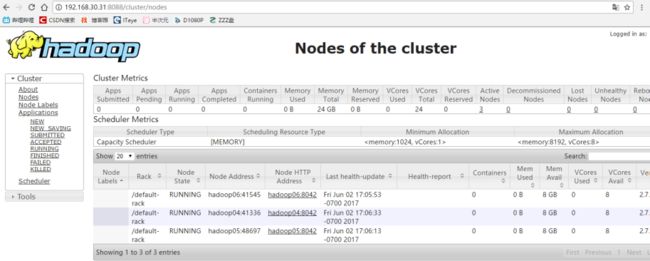
11.28. 查看yarn的管理界面
地址为01节点:http://192.168.30.31:8088
12. hive
hive 可多客户端部署,以方便很多组件去连接 hive 。
12.1. 要求
java、mysql、zookeeper、hadoop、均已安装完毕
12.2. 解压
解压hive
tar -xvf apache-hive-3.1.3-bin.tar.gz
mv apache-hive-3.1.3-bin/ hive-3.1.3
chown -R root:root hive-3.1.3/
配置/etc/profile文件
export HIVE_HOME=/data/soft/hive-3.1.3
export PATH=$PATH:$HIVE_HOME/bin
进入 hive 目录,创建 logs 目录,存放运行日志
mkdir logs
12.3. 修改配置文件
切换到hive的conf目录下
cp hive-env.sh.template hive-env.sh #拷贝环境文件
cp hive-log4j2.properties.template hive-log4j2.properties #拷贝日志文件
cp hive-default.xml.template hive-site.xml #拷贝生成xml文件
修改hive-env.sh文件
HADOOP_HOME=/data/soft/hadoop-3.2.4
export HIVE_CONF_DIR=/data/soft/hive-3.1.3/conf
修改hive-log4j2.properties文件
property.hive.log.dir = /data/soft/hive-3.1.3/logs
修改hive-site.xml文件
> hive-site.xml
vim hive-site.xml
<configuration>
<property>
<name>hive.metastore.warehouse.dirname>
<value>/user/hive/warehousevalue>
property>
<property>
<name>hive.querylog.locationname>
<value>/data/soft/hive-3.1.3/iotmpvalue>
<description>Location of Hive run time structured log filedescription>
property>
<property>
<name>hive.exec.local.scratchdirname>
<value>/data/soft/hive-3.1.3/iotmpvalue>
<description>Local scratch space for Hive jobsdescription>
property>
<property>
<name>hive.downloaded.resources.dirname>
<value>/data/soft/hive-3.1.3/iotmpvalue>
<description>Temporary local directory for added resources in the remote file system.description>
property>
<property>
<name>hive.cli.print.headername>
<value>truevalue>
property>
<property>
<name>hive.cli.print.current.dbname>
<value>truevalue>
property>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://node01:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8&allowPublicKeyRetrieval=truevalue>
<description>JDBC connect string for a JDBC metastoredescription>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
<description>username to use against metastore databasedescription>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>rootvalue>
<description>password to use against metastore databasedescription>
property>
<property>
<name>hive.metastore.db.typename>
<value>mysqlvalue>
<description>
Expects one of [derby, oracle, mysql, mssql, postgres].
Type of database used by the metastore. Information schema & JDBCStorageHandler depend on it.
description>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.cj.jdbc.Drivervalue>
<description>Driver class name for a JDBC metastoredescription>
property>
<property>
<name>hive.metastore.schema.verificationname>
<value>falsevalue>
property>
<property>
<name>hive.metastore.urisname>
<value>thrift://node01:9083value>
property>
<property>
<name>hive.server2.thrift.portname>
<value>10000value>
property>
<property>
<name>hive.server2.thrift.bind.hostname>
<value>node01value>
property>
configuration>
12.4. 在hdfs上创建hive元数据路径
hdfs dfs -mkdir /tmp
hdfs dfs -mkdir -p /user/hive/warehouse
hdfs dfs -chmod g+w /tmp
hdfs dfs -chmod g+w /user/hive/warehouse
12.5. 添加mysql驱动
将mysql驱动放到hive的lib目录下
12.6. 初始化mysql元数据库
初始化mysql元数据库
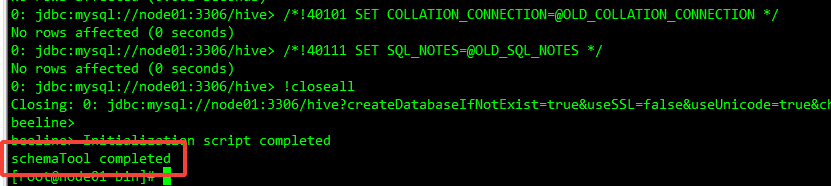
切换到 hive 的 bin 目录下,然后执行以下命令:
./schematool -initSchema -dbType mysql --verbose
成功之后如下图所示:
12.6.1. 初始化时报错
错误1:
Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1357)
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1338)
at org.apache.hadoop.mapred.JobConf.setJar(JobConf.java:536)
at org.apache.hadoop.mapred.JobConf.setJarByClass(JobConf.java:554)
at org.apache.hadoop.mapred.JobConf.(JobConf.java:448)
at org.apache.hadoop.hive.conf.HiveConf.initialize(HiveConf.java:5144)
at org.apache.hadoop.hive.conf.HiveConf.(HiveConf.java:5107)
at org.apache.hive.beeline.HiveSchemaTool.(HiveSchemaTool.java:96)
at org.apache.hive.beeline.HiveSchemaTool.main(HiveSchemaTool.java:1473)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:323)
at org.apache.hadoop.util.RunJar.main(RunJar.java:236)
这是因为 hadoop 下的 guava 包和 hive 下的 guava 包版本不一致造成的。
我们需要将 hadoop 下的 guava 包拷贝到 hive 下,并删除 hive 下的 guava 包。
hadoop 下的 guava 包位置:hadoop-home/share/hadoop/common/lib/guava-27.0-jre.jar。
hive 下的 guava 包位置:hive-home/lib/guava-19.0.jar。
12.7. 修改mysql表字符集
登录 mysql 然后执行以下 sql 语句,以防止建表语句中出现中文时显示乱码,下面是 mysql8 的示例。
use hive;
alter database hive character set latin1;
alter table columns_v2 modify column COMMENT varchar(256) character set UTF8MB4;
alter table table_params modify column PARAM_VALUE varchar(4000) character set UTF8MB4;
alter table partition_params modify column PARAM_VALUE varchar(4000) character set UTF8MB4;
alter table partition_keys modify column PKEY_COMMENT varchar(4000) character set UTF8MB4;
alter table index_params modify column PARAM_VALUE varchar(4000) character set UTF8MB4;
12.8. 启动元数据服务和hiveserver2服务
进入 hive 的 bin 目录,然后执行以下命令
nohup ./hive --service metastore > ../logs/metastore.log 2>&1 &
nohup ./hive --service hiveserver2 > ../logs/hiveserver2.log 2>&1 &
12.9. 进入hive客户端测试
旧客户端
hive
新客户端
beeline -u jdbc:hive2://192.168.244.101:10000
如果没有设置密码,在输入用户名和密码的地方直接回车就行。
13. Hbase
13.1. 准备工作
安装jdk、Hadoop、zookeeper,并且配置jdk和Hadoop环境变量
13.2. 上传解压
上传解压Hbase,将hadoop下的hdfs-site.xml和core-site.xml复制到hbase配置文件目录。
cp /home/hadoop/hadoop-2.6.5/etc/hadoop/hdfs-site.xml /home/hadoop/hbase-1.2.6/conf/
cp /home/hadoop/hadoop-2.6.5/etc/hadoop/core-site.xml /home/hadoop/hbase-1.2.6/conf/
13.3. 增加环境变量
vim /etc/profile
增加以下内容
export HBASE_HOME=/home/hadoop/hbase-1.2.6
export PATH=$HBASE_HOME/bin:$PATH
13.4. 修改conf/hbase-env.sh
vim hbase-env.sh
export JAVA_HOME=/data/soft/jdk1.8.0_271
export HADOOP_HOME=/home/hadoop/hadoop-2.6.5
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HBASE_HOME=/home/hadoop/hbase-1.2.6
export HBASE_MANAGES_ZK=false #禁用Hbase对zookeeper的管理
#配置HBase HMaster进程运行堆内存为16GB
export HBASE_MASTER_OPTS="-Xmx16384m"
#配置HBase分区服务器进程运行JVM参数,读者需要根据节点内存做调整,下面是16核64G服务器示例代码。
export HBASE_REGIONSERVER_OPTS="-Xss256k -Xmx24g -Xms24g -Xmn8g -XX:SurvivorRatio=8 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:MaxTenuringThreshold=10 -XX:CMSInitiatingOccupancyFraction=80 -XX:+UseCMSCompactAtFullCollection -XX:+UseCMSInitiatingOccupancyOnly -XX:+DisableExplicitGC -XX:+HeapDumpOnOutOfMemoryError -verbose:gc -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+PrintGCDetails -XX:+PrintTenuringDistribution -XX:+PrintCommandLineFlags -XX:ErrorFile=${HBASE_HOME}/logs/hs_err_pid-$(hostname).log -XX:HeapDumpPath=${HBASE_HOME}/logs/ -Xloggc:${HBASE_HOME}/logs/gc-$(hostname)-hbase.log"
export HBASE_SSH_OPTS="-p 16120"
export HBASE_LOG_DIR=${HBASE_HOME}/logs
export HBASE_PID_DIR=${HBASE_HOME}/pid
#配置HBase运行相关的依赖库地址
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:${HADOOP_HOME}/lib/native/:/usr/local/lib/
export HBASE_LIBRARY_PATH=${HBASE_LIBRARY_PATH}:${HBASE_HOME}/lib/native/Linux-amd64-64:/usr/local/lib/:${HADOOP_HOME}/lib/native/
13.5. 修改hbase-site.xml
vim hbase-site.xml
<configuration>
<property>
<name>hbase.rootdirname>
<value>hdfs://hadoopCluster/user/hbasevalue>
property>
<property>
<name>zookeeper.znode.parentname>
<value>/hbasevalue>
property>
<property>
<name>hbase.cluster.distributedname>
<value>truevalue>
property>
<property>
<name>hbase.tmp.dirname>
<value>/home/hadoop/data01/hbase/hbase_tmpvalue>
property>
<property>
<name>hbase.zookeeper.property.dataDirname>
<value>/home/hadoop/data01/hbase/zookeeper_datavalue>
property>
<property>
<name>hbase.unsafe.stream.capability.enforcename>
<value>falsevalue>
property>
<property>
<name>hbase.master.portname>
<value>61000value>
property>
<property>
<name>hbase.zookeeper.quorumname>
<value>master1,master2,slave1value>
property>
<property>
<name>hbase.zookeeper.property.clientPortname>
<value>2181value>
property>
<property>
<name>hbase.client.keyvalue.maxsizename>
<value>0value>
property>
<property>
<name>hbase.master.distributed.log.splittingname>
<value>truevalue>
property>
<property>
<name>hbase.client.scanner.cachingname>
<value>500value>
property>
<property>
<name>hfile.block.cache.sizename>
<value>0.2value>
property>
<property>
<name>hbase.hregion.max.filesizename>
<value>107374182400value>
property>
<property>
<name>hbase.hregion.memstore.flush.sizename>
<value>268435456value>
property>
<property>
<name>hbase.regionserver.handler.countname>
<value>100value>
property>
<property>
<name>hbase.regionserver.global.memstore.lowerLimitname>
<value>0.38value>
property>
<property>
<name>hbase.regionserver.global.memstore.sizename>
<value>0.45value>
property>
<property>
<name>hbase.hregion.memstore.block.multipliername>
<value>8value>
property>
<property>
<name>hbase.server.thread.wakefrequencyname>
<value>1000value>
property>
<property>
<name>hbase.rpc.timeoutname>
<value>400000value>
property>
<property>
<name>hbase.hstore.blockingStoreFilesname>
<value>5000value>
property>
<property>
<name>hbase.client.scanner.timeout.periodname>
<value>1000000value>
property>
<property>
<name>zookeeper.session.timeoutname>
<value>180000value>
property>
<property>
<name>hbase.rowlock.wait.durationname>
<value>90000value>
property>
<property>
<name>hbase.client.scanner.timeout.periodname>
<value>180000value>
property>
<property>
<name>hbase.regionserver.optionallogflushintervalname>
<value>5000value>
property>
<property>
<name>hbase.client.write.buffername>
<value>5242880value>
property>
<property>
<name>hbase.hstore.compactionThresholdname>
<value>5value>
property>
<property>
<name>hbase.hstore.compaction.maxname>
<value>12value>
property>
<property>
<name>hbase.regionserver.regionSplitLimitname>
<value>1value>
property>
<property>
<name>hbase.regionserver.thread.compaction.largename>
<value>8value>
property>
<property>
<name>hbase.regionserver.thread.compaction.smallname>
<value>5value>
property>
<property>
<name>hbase.master.logcleaner.ttlname>
<value>3600000value>
property>
<property>
<name>hbase.bucketcache.ioenginename>
<value>offheapvalue>
property>
<property>
<name>hbase.bucketcache.percentage.in.combinedcachename>
<value>0.9value>
property>
<property>
<name>hbase.bucketcache.sizename>
<value>16384value>
property>
<property>
<name>hbase.replicationname>
<value>truevalue>
property>
<property>
<name>hbase.snapshot.enabledname>
<value>truevalue>
property>
<property>
<name>replication.source.per.peer.node.bandwidthname>
<value>104857600value>
property>
<property>
<name>replication.source.rationame>
<value>1value>
property>
<property>
<name>hbase.hregion.majorcompactionname>
<value>604800000value>
property>
configuration>
13.6. 配置region服务器
13.6.1. 修改regionservers文件
如果配置的是主机名,需要修改每个Linux系统的主机名,而且还需要在hosts文件中配置所有主机名和IP地址的对应关系
vim regionservers
hadoop01
hadoop02
hadoop03
配置所有hbase主机,每个主机名独占一行,hbase在启动或关闭时会按照该配置顺序启动或关闭对应主机中的hbase。
13.6.2. 修改backup-masters文件
配置备用主节点,可以配置多个,启动多个备用节点。
vim backup-masters
hadoop04
13.7. 拷贝
将配置好的整个Hbase目录远程拷贝至其他所有的Linux系统。
13.8. 启动集群
启动zookeeper
启动hadoop
启动hbase集群master(进入bin目录)
sh hbase-daemon.sh start master #在两台主节点上分别启动master服务
启动HBase分区服务器
sh hbase-daemon.sh start regionserver #在所有需要启动regionserver的节点上执行
sh hbase shell #通过shell脚本进入Hbase
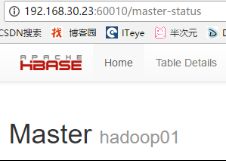
13.9. 访问http://192.168.30.23:16010
访问web界面,通过web界面管理hbase
Active Master界面:

如果上面启动了多个master,这儿就会有多个。
Backup Master界面:
13.10. 关闭集群
sh stop-hbase.sh #该指令会关闭整个Hbase集群,不需要一个一个关闭。
13.11. 集群增加节点
13.11.1. hadoop
-
在集群所有节点的hosts文件中添加新机器名与ip的绑定。
-
在hadoop的
etc/hadoop/slaves文件中添加新节点机器名。 -
刷新集群节点,在namenode上运行以下命令:
/hadoop-2.5.6/bin/hadoop dfsadmin -refreshNodes
- 在新节点上启动dataNode服务,命令如下:
hadoop-2.6.5/sbin/hadoop-daemon.sh start datanode
- 运行数据的负载均衡,命令如下:
/hadoop-2.5.6/bin/hdfs balancer -threshold 5
5表示如果集群每个节点存储百分比差距在5%以内则结束该次负载均衡
13.11.2. Hbase
-
增加HBase分区服务器,在所有hbase节点上的
/hbase-1.2.6/conf/regionservers文件中添加新节点机器名 -
在新节点上启动HBase分区服务器,命令如下:
hbase-1.2.6/bin/hbase-daemon.sh start regionserver
13.12. 集群删除节点
13.12.1. hbase
下线HBase分区服务器,在下线节点上执行如下命令
hbase-1.2.6/bin/graceful_stop.sh slave2
13.12.2. hadoop
-
在 hadoop-2.6.5/etc/hadoop/hdfs-site.xml 文件中添加如下内容
<property> <name>dfs.hostsname> <value>/home/hadoop/hadoop2.6.5/etc/hadoop/slavesvalue> property> <property> <name>dfs.hosts.excludename> <value>/home/hadoop/hadoop2.6.5/etc/hadoop/exclude-slavesvalue> property> -
执行节点刷新命令,下线Hadoop数据节点
hadoop-2.5.6/bin/hadoop dfsadmin -refreshNodes然后执行命令
hadoop dfsadmin -report或者用浏览器打开链接 http://master1:50070,可以看到,该数据节点状态转为正在退役(Decommission In Progress),等退役进程完成数据迁移后,数据节点的状态会变成已退役(Decommissioned),然后数据节点进程会自动停止。此时节点slave2已经转移到下线节点(dead nodes)列表中。
-
清理slave2。将
slaves与exclude-slaves文件中slave2这行数据删除,然后执行刷新hadoop节点命令,到此slave2即已经成功下线。
14. Phoenix
14.1. 下载
https://phoenix.apache.org/download.html
注意看好自己 hbase 的版本。
14.2. 上传到linux进行解压
14.3. 拷贝jar包
这个jar包就在Phoenix的根目录下
将phoenix-4.14.3-HBase-1.4-server.jar包拷贝到所有的master和regionserver上hbase安装的lib目录下
14.4. 修改配置
bin/hbase-site.xml
添加如下代码:
namespace和schema的对应关系
<property>
<name>phoenix.schema.isNamespaceMappingEnabledname>
<value>truevalue>
property>
<property>
<name>phoenix.schema.mapSystemTablesToNamespacename>
<value>truevalue>
property>
支持二级索引
<property>
<name>hbase.regionserver.wal.codecname>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodecvalue>
property>
<property>
<name>hbase.region.server.rpc.scheduler.factory.classname>
<value>org.apache.hadoop.hbase.ipc.PhoenixRpcSchedulerFactoryvalue>
<description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata
updates
description>
property>
<property>
<name>hbase.rpc.controllerfactory.classname>
<value>org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactoryvalue>
<description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata
updates
description>
property>
将该配置文件拷贝到phoenix的bin目录下,替换原本的hbase-site.xml文件。
重启hbase集群。
14.5. 配置HBase的环境变量
vim /etc/profile
增加以下内容
export HBASE_HOME=/home/hadoop/hbase-1.2.6
source /etc/profile
14.6. 测试
进入Phoenix的lib目录执行(注意不能用sh指令执行该脚本,这个使用Python语言编写的,并不是shell脚本):
./sqlline.py hadoop01,hadoop02,hadoop03:2181
如果进不去命令行,重启即可
如果进入Phoenix命令行状态,则证明Phoenix安装完成
14.7. 启动thin-client支持
启动queryserver:
./queryserver.py start
连接:
./sqlline-thin.py hadoop:8765
15. kafka
15.1. 下载Kafka安装包
https://kafka.apache.org/downloads
15.2. 上传解压
tar -xvf kafka_2.12-3.2.1.tgz
chown -R root:root kafka_2.12-3.2.1/
15.3. 修改一些linux参数
所有机器上都要修改
ulimit -a #查看 open_file、max_user_processes 等参数值,如果是1024,则需要修改
临时修改:
ulimit -u 131072
永久修改:
vim /etc/security/limits.conf
在最后添加如下内容:
* soft nproc 131072
* hard nproc 131072
* soft nofile 131072
* hard nofile 131072
nofile对应open_files,nproc对应max_user_processes
15.4. 定期删除kafka自身运行日志
脚本clean-logs-7.sh的代码:
#!/usr/bin/env bash
#清理kafka自身七天之前的运行日志
find /data/soft/kafka_2.12-3.2.1/logs -mtime +7 -name "*log*" -exec rm -rf {} \;
exit 0
添加可执行权限:
chmod 754 clean-logs-7.sh
linux添加定时任务:
crontab -e
增加以下内容:
#清理kafka自身7天前的运行日志
00 00 * * * sh /data/soft/kafka_2.12-3.2.1/bin/clean-logs-7.sh
15.5. 修改server.properties文件
在config目录下,修改server.properties,在文件中修改如下参数:
broker.id=0 #当前server编号
listeners=PLAINTEXT://172.16.22.156:9092 #配置访问地址和端口号
#advertised.listeners=PLAINTEXT://172.16.22.156:9092 #如果是多网卡,并且对外提供服务,需要用到外网网卡,则上面配置内网地址,这儿配置外网地址
log.dirs=/data/soft/kafka_2.12-3.2.1/topic_log #日志存储目录(主题数据全部存放在该目录下,一定要修改,不能使用默认的/tmp目录)
compression.type=lz4 #指定主题数据日志文件压缩类型,指定之后,生产者如果指定了压缩类型,要和此处保持一致
message.max.bytes=5242880 #单条消息的最大大小,默认976k,有可能较小,根据需要修改
replica.fetch.max.bytes=6291456 #replica角色拉取leader角色日志数据最大大小,要大于单条消息的最大大小,默认1M
offsets.topic.replication.factor=3 #offsets主题的副本数量,默认为1,一定要修改,至少要大于3
transaction.state.log.replication.factor=3 #事务副本数量,默认为1,如果用不到kafka的事务保证exactly once,可以不配置
log.retention.hours=168 #主题数据保存时间,这是7天,ms配置优先级大于该参数
auto.create.topics.enable=false #是否可以自动创建主题,而不是通过kafka脚本创建,线上建议设置为false,以控制kafka主题数量
delete.topic.enable=true #是否可以删除kafka主题,建议为true,删除主题之后,集群自动删除主题所有数据
zookeeper.connect=hadoop01:2181,hadoop02:2181,hadoop03:2181 #zookeeper连接信息,如果是多个主题,可以在最后添加 /kafka2 节点区分。
15.6. 拷贝
将kafka目录远程拷贝至其他主机对应的目录,然后修改server.properties文件中的broker.id、listeners、advertised.listeners值。
15.7. 启动
启动zookeeper
启动kafka
在各个机器的kafka的bin目录下执行(必须指定配置文件的具体路径):
sh kafka-server-start.sh -daemon ../config/server.properties
16. sqoop
-
准备sqoop安装包,官网地址:http://sqoop.apache.org
-
配置jdk环境变量和Hadoop的环境变量,因为sqoop在使用时会去找环境变量中对应的路径,从而完成工作。
-
sqoop解压后即可使用(前提是环境变量都配好了)
-
将要连接数据库的驱动包放入sqoop的
lib目录下 -
利用指令操作sqoop。
17. tess4j安装
17.1. 下载
tesseract-ocr-3.02.02.tar.gz及安装需要的leptonica-1.68.tar.gz ,英文语言包 eng.traineddata.gz

17.2. 编译环境
yum -y install gcc gcc-c++ make autoconf automake libtool libjpeg-devel libpng-devel libtiff-devel zlib-devel
17.3. 安装leptonica
下载 leptonica-1.78.tar.gz
上传解压
tar -zxvf leptonica-1.78.tar.gz
进入 leptonica-1.78文件夹内,然后执行下面的命令
./configure
make
make install
ldconfig
如果make的时候发现错误,提示如下
pngio.c:119: error: ‘Z_DEFAULT_COMPRESSION’ undeclared here (not in a function)
这是因为pngio.c这个文件有个BUG,在MAC下无法找到zlib1g包,修改Leptionica/src/pngio.c文件,在#include "png.h"后插入一下代码即可
#ifdef HAVE_LIBZ
#include "zlib.h"
#endif
17.4. 安装tesseract
下载 tesseract-ocr-3.02.02.tar.gz
上传解压
进入 tesseract-ocr-3.02.02文件夹内,执行以下命令
./autogen.sh
./configure
make
make install
ldconfig
如果需要在linux上运行带tess4j的项目,需要将**/usr/local/lib下相关的tesseract和leptonica的library.so的文件复制到/usr/lib**下
17.5. 安装语言包
将 eng.traineddata文件 拷贝到 /usr/local/share/tessdata下 ,如果没有tessdata文件夹,就去tesseract的安装文件位置,将目录下的tessdata拷贝到**/usr/local/share/**
17.6. 执行安装命令
如果出现下图,就安装成功了

18. Elasticsearch单机搭建
18.1. 新建es用户
下面的命令使用root用户执行
useradd -d /app_data/bonces -m #es用户根目录自己指定
设置es用户密码
passwd es
18.2. 修改/etc/sysctl.conf
vim /etc/sysctl.conf
添加以下内容
vm.max_map_count=655360
fs.file-max=655360
执行
sysctl -p
命令使其生效
18.3. 修改/etc/security/limits.conf
vim /etc/security/limits.conf
添加以下内容
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096
es soft memlock unlimited
es hard memlock unlimited
18.4. 上传解压
上传并解压elasticsearch-7.7.1-linux-x86_64.tar.gz,最好是将elasticsearch解压到es用户的家目录,不过要注意后面配置的数据文件路径要有es的读写权限,日志放在elasticsearch的安装目录下就行。
解压之后,要修改elasticsearch解压目录的所属用户为es用户。
tar -xvf elasticsearch-7.7.1-linux-x86_64.tar.gz
mv elasticsearch-7.7.1 /home/es/
cd /home/es/
chown -R es:es elasticsearch-7.7.1/
mkdir /data/soft/elasticsearch_data #这是创建给es使用的数据目录
chown -R es:es /data/soft/elasticsearch_data/
18.5. 修改配置文件
下面的命令使用es用户执行
修改elasticsearch.yml
path.data: /data/soft/elasticsearch_data
path.logs: /home/es/elasticsearch-7.7.1/logs
network.host: 192.168.244.151
http.port: 9200
discovery.seed_hosts: ["node1"] #注意在linux中安装时,需要配置这个,即使是单机,也需要配置那个机器的主机名。
cluster.initial_master_nodes: ["node1"]
http.cors.enabled: true
http.cors.allow-origin: "*"
注意,path.data是上面创建的给es使用的数据目录。
18.6. 启动ES
./elasticsearch -d
18.7. 单机启动多实例
./elasticsearch -E node.name=node1 -E cluster.name=wzq -E path.data=../node1_data -E http.port=9200 -d
./elasticsearch -E node.name=node2 -E cluster.name=wzq -E path.data=../node2_data -E http.port=9201 -d
./elasticsearch -E node.name=node3 -E cluster.name=wzq -E path.data=../node3_data -E http.port=9202 -d
18.8. 验证
浏览器访问http://172.16.87.116:9200,查看信息
浏览器访问http://172.16.87.116:9200/_cat/nodes,查看所有节点信息
18.9. cerebro插件
18.9.1. 下载
地址:https://github.com/lmenezes/cerebro/releases
18.9.2. 解压并配置
将压缩包解压到某一目录,然后修改所属用户
unzip cerebro-0.9.2.zip
chown -R root:root cerebro-0.9.2/
18.9.2.1. cerebro的配置
在conf目录下找到application.conf文件,在文件最后的hosts配置中配置要连接集群的地址和名称,格式如下:
hosts = [
{
host = "http://some-authenticated-host:9200"
name = "Secured Cluster"
auth = {
username = "username"
password = "secret-password"
}
}
]
上面的是一个完整的配置,包含了验证用户名和密码,如果用不到用户名和密码,可以不设置。
也可以直接配置多个集群信息,如下:
hosts = [
{
host = "http://localhost:9200"
name = "wzq"
},
{
host = "http://localhost:9201"
name = "wzq2"
}
]
18.9.2.2. elasticsearch配置
在conf目录下找到elasticsearch.yml文件,然后配置:
http.cors.enabled: true
http.cors.allow-origin: "*"
18.9.3. 启动
切换到cerebro的bin目录下,然后执行
nohup ./cerebro >/dev/null &
启动。
18.9.4. 访问
http://192.168.244.151:9000/
启动成功,则会出现上述界面。
Known clusters下面显示的是在配置文件中配置的集群信息,点击某个集群就可以连上。
Node address下面的输入框可以填写其他集群的访问地址,然后点击Connect按钮就可以连接到其他集群。
19. Elasticsearch集群搭建
注意以下1~4步骤,所有节点都需要做。
19.1. 1.新建es用户
下面的命令使用root用户执行
useradd es #用户根目录自己指定
设置es用户密码
passwd es
19.2. 2.修改/etc/sysctl.conf
vim /etc/sysctl.conf
添加以下内容
vm.max_map_count=655360
fs.file-max=655360
执行
sysctl -p
使其生效。
19.3. 3.修改/etc/security/limits.conf
vim /etc/security/limits.conf
添加以下内容
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096
es soft memlock unlimited
es hard memlock unlimited
19.4. 4.创建数据目录
这是创建给es使用的数据目录
mkdir -p /data/soft/elasticsearch_data
chown -R es:es /data/soft/elasticsearch_data
19.5. 上传解压
以下步骤可以在一个节点上做,然后拷贝到其他节点,修改配置文件即可。
上传并解压elasticsearch-7.7.1-linux-x86_64.tar.gz,最好是将elasticsearch解压到es用户的家目录,不过要注意后面配置的数据文件路径要有es的读写权限,日志放在elasticsearch的安装目录下就行。
解压之后,要修改elasticsearch解压目录的所属用户为es用户。
tar -xvf elasticsearch-7.7.1-linux-x86_64.tar.gz
mv elasticsearch-7.7.1 /home/es/
cd /home/es/
chown -R es:es elasticsearch-7.7.1/
19.6. 修改配置文件
打开es的配置文件
vim config/elasticsearch.yml
cluster.name: es-1 #设置集群的名称,使用同一个集群名称的节点会组成集群,不要使用默认值
node.master: true #是否允许节点成为一个master节点,ES默认集群中的第一台机器成为master,如果这台机器停止就会重新选举
node.data: true #许该节点存储索引数据(默认开启)
node.name: node-1 #节点名称,每个节点必须不一样
path.data: /data/soft/elasticsearch_data #注意不同机器,这个数据目录位置。如果有多块磁盘,可以配置多个目录,中间用英文逗号隔开。
path.logs: /home/es/elasticsearch-7.7.1/logs
bootstrap.memory_lock: true #使用内存锁可以在ES启动时,锁住一段堆内存,保证堆内存不被挤到磁盘中。锁定内存大小一般为可用内存的一半左右。
network.host: 192.168.244.151 #注意不同机器,配置对应机器的ip地址
http.port: 9200
discovery.seed_hosts: ["node1", "node2", "node3"] #集群发现,所有配置到这里的节点,都会被添加到该集群
cluster.initial_master_nodes: ["node1", "node2"] #手动指定可以成为 mater 的所有节点的 name 或者 ip,这些配置将会在第一次选举中进行计算
http.cors.enabled: true #开启跨域访问
http.cors.allow-origin: "*" #开启跨域访问后的地址限制,*表示无限制
19.7. 修改内存大小
vim config/jvm.options
-Xms1g
-Xmx1g
上面这两个参数分别指定初始堆大小和最大堆大小,建议设置为相同的值,并且不超过30G。建议不要超过物理内存的一半,因为es要先将数据写入到文件缓存中,需要给操作系统留下足够的内存。
19.8. 拷贝至其他节点
scp -r elasticsearch-7.7.1/ node2:/home/es/
scp -r elasticsearch-7.7.1/ node3:/home/es/
修改配置文件中需要修改的节点名称和IP信息。
19.9. 启动
分别在每个节点执行
bin/elasticsearch -d
19.10. 停止
只能通过**kill**的方式结束进程。
19.11. 访问
http://192.168.244.151:9200/_cat/nodes
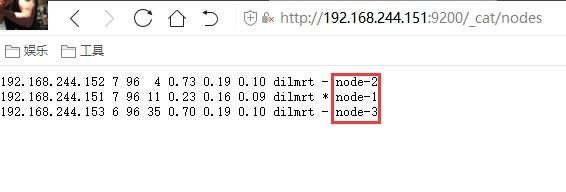
20. kibana
20.1. 上传解压
将kibana压缩包上传到机器上,然后解压,并修改目录所属用户。将kibana安装到es的安装用户的目录下即可,用户也是用安装es的用户。
tar -xvf kibana-7.7.1-linux-x86_64.tar.gz
chown -R es:es kibana-7.7.1-linux-x86_64/
20.2. 修改配置文件
切换到conf目录下,修改kibana.yml文件
server.port: 5601
server.host: "192.168.244.151"
server.name: "kib-server"
elasticsearch.hosts: ["http://192.168.244.151:9200","http://192.168.244.152:9200","http://192.168.244.153:9200"]
i18n.locale: "zh-CN"
elasticsearch.username: "kibana"
elasticsearch.password: "pass"
i18n.locale用来设置kibana界面语言,zh-CN表示中文。
20.3. 启动
切换到bin目录下,然后执行以下命令:
nohup ./kibana >> log.log &
可以先直接执行:
./kibana
命令在前台运行,看是否能正确运行,然后在切换到后台运行。
20.4. 访问
http://192.168.244.151:5601
20.5. ES JDBC
先后在kibana中执行以下访问:
激活免费试用:
POST /_license/start_trial?acknowledge=true
查看许可证信息:
GET /_license
21. logstash
注意以下安装作为一个演示使用,演示的是从文件中导入数据到ES。
21.1. 上传解压
tar -xvf logstash-7.7.1.tar.gz
chown -R root:root logstash-7.7.1
21.2. 下载样例文件
https://grouplens.org/datasets/movielens/
https://gitee.com/fengjun5/geektime-ELK/tree/master/part-1/2.4-Logstash%E5%AE%89%E8%A3%85%E4%B8%8E%E5%AF%BC%E5%85%A5%E6%95%B0%E6%8D%AE
将下载好的样例文件movies.csv上传到linux某一目录下。
21.3. 添加配置文件
切换到logstash的conf目录下,然后拷贝logstash-sample.conf文件
cp logstash-sample.conf logstash.conf
然后修改logstash.conf文件,内容如下(注意修改待导入文件的路径和ES的访问地址):
input {
file {
path => "/data/data/movies.csv"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
csv {
separator => ","
columns => ["id","content","genre"]
}
mutate {
split => { "genre" => "|" }
remove_field => ["path", "host","@timestamp","message"]
}
mutate {
split => ["content", "("]
add_field => { "title" => "%{[content][0]}"}
add_field => { "year" => "%{[content][1]}"}
}
mutate {
convert => {
"year" => "integer"
}
strip => ["title"]
remove_field => ["path", "host","@timestamp","message","content"]
}
}
output {
elasticsearch {
hosts => "http://192.168.244.151:9200"
index => "movies"
document_id => "%{id}"
}
stdout {}
}
21.4. 启动
./bin/logstash -f config/logstash.conf
-f后面指定的是要使用的自定义的配置文件,配置文件中配置的是要输入、转化和输出的信息。
运行成功之后,可以在cerebro中看到新建的索引。

22. InfluxDB
22.1. 添加yum源
直接执行下面的 linux 命令即可
cat <<EOF | sudo tee /etc/yum.repos.d/influxdb.repo
[influxdb]
name = InfluxDB Repository - RHEL \$releasever
baseurl = https://repos.influxdata.com/rhel/\$releasever/\$basearch/stable
enabled = 1
gpgcheck = 1
gpgkey = https://repos.influxdata.com/influxdb.key
EOF
22.2. 安装
yum -y install influxdb
22.3. 修改配置文件
vim /etc/influxdb/influxdb.conf
[http]下配置bind-address参数
![]()
[meta]下修改 dir 参数,该参数设置的是元数据存储地址,目录统一放到一个固定的influxdb下,注意该目录应该有充足的空间。

[data]下修改dir和wal-dir,他们分别设置数据存储目录和预写日志目录,目录统一放到一个固定的influxdb下。
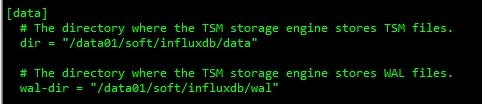
22.4. 修改用户
修改配置文件中influxdb目录的所属用户
chown -R influxdb:influxdb /data01/soft/influxdb
22.5. 启动和停止
systemctl status influxdb
systemctl start influxdb
systemctl statop influxdb
23. mongodb
23.1. 上传解压
tar -xvf mongodb-linux-x86_64-rhel70-4.2.6.tgz
23.2. 修改/etc/profile
添加以下内容
export MONGODB_HOME=/data01/soft/mongodb-4.2.6
export PATH=$MONGODB_HOME/bin:$PATH
source /etc/profile #使文件修改生效
23.3. 创建目录
创建用于存放数据和日志文件的文件夹
进入mongodb根目录
mkdir -p data/db
mkdir logs
cd logs
touch mongodb.log

23.4. mongodb启动配置
进入到bin目录,增加一个配置文件
cd bin
vim mongodb.conf
增加以下内容
dbpath = /data01/soft/mongodb-4.2.6/data/db #数据文件存放目录
logpath = /data01/soft/mongodb-4.2.6/mongodb.log #日志文件存放目录
port = 27017 #端口
fork = true #以守护程序的方式启用,即在后台运行
23.5. 启动/停止
cd bin
./mongod -f mongodb.conf
./mongod --shutdown -f mongodb.conf
23.6. 控制台登录
./mongo
23.7. 设置密码
use admin
db.createUser({user:"admin",pwd:"admin",roles:["root"]})
db.auth("admin", "admin")
24. Neo4j
24.1. 创建neo4j用户
useradd neo4j
24.2. 给该用户安装jdk11
上传并解压jdk11到neo4j用户的家目录
tar -xvf openjdk-11.0.2_linux-x64_bin.tar.gz
编辑neo4j用户家目录下的**.bash_profile**文件,添加以下代码
export JAVA_HOME=/home/neo4j/jdk-11.0.2
export JRE_HOME=$JAVA_HOME/jre
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
使**.bash_profile**文件生效
source .bash_profile
24.3. 上传并解压neo4j压缩包
tar -zxvf neo4j-community-4.0.3-unix.tar.gz
24.4. 修改neo4j的配置文件
cd neo4j-community-4.0.3
vim conf/neo4j.conf
修改如下:
dbms.default_listen_address=172.16.32.142
dbms.default_advertised_address=172.16.32.142

24.5. 启动/停止
在bin目录下执行
./neo4j start
./neo4j stop
注:
需要切换到neo4j用户去执行启动/停止命令,而且切换到neo4j用户之后,需要使**.bach_profile**文件生效,以使neo4j用户读取到jdk11信息,具体命令如下:
source /home/neo4j/.bach_profile
25. EMQX集群
25.1. 安装unzip工具
yum -y install unzip zip
25.2. 上传并解压缩
unzip emqx-centos7-v3.2.7.zip
25.3. 修改配置文件
位于软件根目录下:etc/emqx.conf
cluster.name = emqxcl #集群名称
cluster.discovery = static #集群模式
cluster.static.seeds = [email protected],[email protected] #集群所有节点IP
node.name = [email protected] #具体节点名称和ip,集群模式只有这个配置不同
#node.name = [email protected]
25.4. 拷贝
将第一个节点的软件目录全部拷贝到其他节点,并修改配置文件中的node.name值为具体节点信息。
25.5. 启动/停止
./bin/emqx start
./bin/emqx stop
每个节点上都需要执行。
./emqx_ctl status #查看节点运行状态
./emqx_ctl cluster status #查看集群运行状态
25.6. 登录界面
http://某个节点IP:18083
如果能看到集群所有节点信息即为成功。
26. clickhouse单机
26.1. 准备文件
地址:
https://packagecloud.io/Altinity/clickhouse
https://repo.yandex.ru/clickhouse/rpm/stable/x86_64/
文件:
clickhouse-client-${version}.noarch.rpm
clickhouse-common-static-dbg-${version}.x86_64.rpm
clickhouse-common-static-${version}.x86_64.rpm
clickhouse-server-${version}.noarch.rpm
注意四个文件的版本号要完全一致。
26.2. 修改创建文件大小限制文件
vim /etc/security/limits.d/clickhouse.conf
增加以下内容
# 添加 core file size,允许程序 crash 时创建的 dump 文件大小
clickhouse soft core 1073741824
clickhouse hard core 1073741824
26.3. 安装
通过rpm命令直接安装即可,注意顺序,并且所有节点都需要安装。
rpm -ivh clickhouse-common-static-19.17.4.11-1.el7.x86_64.rpm
rpm -ivh clickhouse-common-static-dbg-19.17.4.11-1.el7.x86_64.rpm
rpm -ivh clickhouse-server-19.17.4.11-1.el7.x86_64.rpm
rpm -ivh clickhouse-client-19.17.4.11-1.el7.x86_64.rpm
安装过程中如果提示缺少依赖,则通过yum安装相应的依赖即可。
如果yum不能使用,则去网络上下载上传对应的rpm文件进行安装。
如果这些文件都在同一个目录下,可以直接使用 ipm -ivh *.rpm 直接安装。
26.4. 修改config.xml文件
说明:
默认日志文件目录:/var/log/clickhouse-server/
客户端和服务端配置目录如下:/etc/clickhouse-server、/etc/clickhouse-client
修改服务端配置文件:/etc/clickhouse-server/config.xml
<logger>
<level>tracelevel>
<log>/data/app/clickhouse/log/clickhouse-server/clickhouse-server.loglog>
<errorlog>/data/app/clickhouse/log/clickhouse-server/clickhouse-server.err.logerrorlog>
<size>1000Msize>
<count>10count>
logger>
<listen_host>::listen_host>
<path>/data/app/clickhouse/data/path>
<tmp_path>/data/app/clickhouse/tmp/tmp_path>
<user_files_path>/data/app/clickhouse/user_files/user_files_path>
<format_schema_path>/data/app/clickhouse/format_schemas/format_schema_path>
注意:上述文件位置应该放到剩余空间充足的目录下。
26.5. 新建目录
在上面指定的目录下新建clickhouse目录,并修改目录所属用户为clickhouse
cd /data/app
mkdir clickhouse
chown -R clickhouse:clickhouse clickhouse/
26.6. 启动
systemctl start clickhouse-server
systemctl status clickhouse-server
systemctl restart clickhouse-server
26.7. 进入客户端
clickhouse-client
直接运行上述命令,即可进入客户端
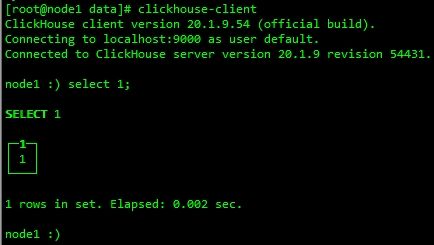
clickhouse-client -m
-m表示进入客户端之后,sql语句可以写多行来执行,用英文分号结束。
也可直接运行运行sql语句:
clickhouse-client --query "CREATE DATABASE IF NOT EXISTS tutorial"
26.8. 卸载
查看
rpm -qa | grep clickhouse
卸载命令:
rmp -e rpm包名
26.9. 密码设置
直接在linux里面运行以下命令生成密码
PASSWORD=$(base64 < /dev/urandom | head -c8); echo "$PASSWORD"; echo -n "$PASSWORD" | sha1sum | tr -d '-' | xxd -r -p | sha1sum | tr -d '-'
![]()
上面的是明文密码,通过mysql客户端连接时使用,下面的是加密之后的密文密码,需要配置到clickhouse的users.xml文件中
配置users.xml文件
vim /etc/clickhouse-server/users.xml
<password_double_sha1_hex>0226d1ddf78bb5626237b55b48d228aaafeb7058password_double_sha1_hex>
记得要删除里面的
如果要去掉设置的密码,则删除配置的标签,并且配置
27. Prometheus
官网:https://prometheus.io/
下载地址:https://prometheus.io/download
27.1. 安装Prometheus Server
注意,该角色只需要安装一台即可。
27.1.1. 上传
上传prometheus-2.26.0.linux-amd64.tar.gz到虚拟机的 /opt/software 目录。
27.1.2. 解压
-
解压到/opt/module目录下
tar -zxvf prometheus-2.26.0.linux-amd64.tar.gz -C /opt/module -
修改目录名
cd /opt/module mv prometheus-2.26.0.linux-amd64 prometheus-2.26.0 chown -R root:root prometheus-2.26.0
27.1.3. 修改配置文件prometheus.yml
cd prometheus-2.26.0
vim prometheus.yml
在scrape_configs配置项下添加配置,注意一定要保持该有的缩进,这是 yml 文件的固定格式:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["node01:9090"]
# 添加 PushGateway 监控配置,这个是为了从网关来拉取指标数据,比如 flink on yarn 任务
- job_name: 'pushgateway'
static_configs:
- targets: [ 'node01:9091' ]
labels:
instance: pushgateway
# 添加 Node Exporter 监控配置,拉取对机器的监控指标
- job_name: 'node_exporter'
static_configs:
- targets: [ 'node01:9100', 'node02:9100', 'node03:9100' ]
配置说明:
- global配置块:控制Prometheus服务器的全局配置
- scrape_interval:配置拉取数据的时间间隔,默认为1分钟。
- evaluation_interval:规则验证(生成alert)的时间间隔,默认为1分钟。
- rule_files配置块:规则配置文件
- scrape_configs配置块:配置采集目标相关,prometheus监视的目标。Prometheus自身的运行信息可以通过HTTP访问,所以Prometheus可以监控自己的运行数据。
- job_name:监控作业的名称
- static_configs:表示静态目标配置,就是固定从某个target拉取数据
- targets:指定监控的目标,其实就是从哪儿拉取数据。Prometheus会从http://hadoop1:9090/metrics上拉取数据。
- Prometheus是可以在运行时自动加载配置的。启动时需要添加:
--web.enable-lifecycle
27.1.4. 配置sysmtemctl
vim /usr/lib/systemd/system/prometheus.service
[Unit]
Description=https://prometheus.io
[Service]
Restart=on-failure
ExecStart=/opt/software/prometheus-2.26.0/prometheus --config.file=/opt/software/prometheus-2.26.0/prometheus.yml
[Install]
WantedBy=multi-user.target
设置开机自启
systemctl daemon-reload
systemctl enable prometheus
systemctl start prometheus
systemctl stop prometheus
systemctl status prometheus
27.2. 安装PushGateway
注意,该角色只需要安装一台即可。
27.2.1. 上传
上传pushgateway-1.4.0.linux-amd64.tar.gz到虚拟机的 /opt/software 目录
27.2.2. 解压
-
解压到/opt/module目录下
tar -zxvf pushgateway-1.4.0.linux-amd64.tar.gz -C /opt/module -
修改目录名
cd /opt/module mv pushgateway-1.4.0.linux-amd64 pushgateway-1.4.0 chown -R root:root pushgateway-1.4.0
27.2.3. 设置systemctl
vim /usr/lib/systemd/system/pushgateway.service
[Unit]
[Unit]
Description=https://pushgateway.io
[Service]
Restart=on-failure
ExecStart=/opt/module/pushgateway-1.4.0/pushgateway --web.listen-address :9091
[Install]
WantedBy=multi-user.target
设置开启自启和 systemctl
systemctl daemon-reload
systemctl enable pushgateway
systemctl start pushgateway
systemctl stop pushgateway
systemctl status pushgateway
27.3. 安装NodeExporter(可选)
注意,在需要监控机器性能的所有节点都需要安装。
27.3.1. 上传
上传node_exporter-1.1.2.linux-amd64.tar.gz到虚拟机的/opt/software目录
27.3.2. 安装
-
解压到/opt/module目录下
tar -zxvf node_exporter-1.1.2.linux-amd64.tar.gz -C /opt/module -
修改目录名
cd /opt/module mv node_exporter-1.1.2.linux-amd64 node_exporter-1.1.2 chown -R root:root node_exporter-1.1.2 -
启动并页面查看是否成功
cd node_exporter-1.1.2 ./node_exporter该命令为临时启动,下面使用了其他方式启动
浏览器输入:http://node01:9100/metrics,可以看到当前node exporter获取到的当前主机的所有监控数据。
27.3.3. 部署其他节点
将整个目录直接拷贝到其他节点即可。
该角色安装不需要修改任何配置文件,多个节点信息,最后会通过主机名来区分。
27.3.4. 修改prometheus配置文件
修改Prometheus配置文件prometheus.yml中需要对单个机器修改的地方,上面已经添加过配置,主要是添加需要收集的 node exporter 节点数据。
27.3.5. 设置为开机自启
-
创建service文件(所有机器都执行)
vim /usr/lib/systemd/system/node_exporter.service[Unit] Description=node_export After=network.target [Service] Type=simple User=root ExecStart=/opt/module/node_exporter-1.1.2/node_exporter Restart=on-failure [Install] WantedBy=multi-user.target注意修改目录。
-
设为开机自启动(所有机器都执行)
systemctl daemon-reload systemctl enable node_exporter -
启动服务(所有机器都执行)
systemctl start node_exporter systemctl status node_exporter
27.4. 启动Prometheus Server 和 Pushgateway
27.4.1. Prometheus Server
在 Prometheus Server 目录下执行启动命令
nohup ./prometheus > prometheus.log 2>&1 &
27.4.2. Pushgateway
nohup ./pushgateway --web.listen-address :9091 > pushgateway.log 2>&1 &
注意,不要删除指定的端口参数中的空格,这是 yml 文件的固定格式
27.4.3. 通过浏览器查看
浏览器输入:http://node01:9090
点击 Status,选中 Targets:
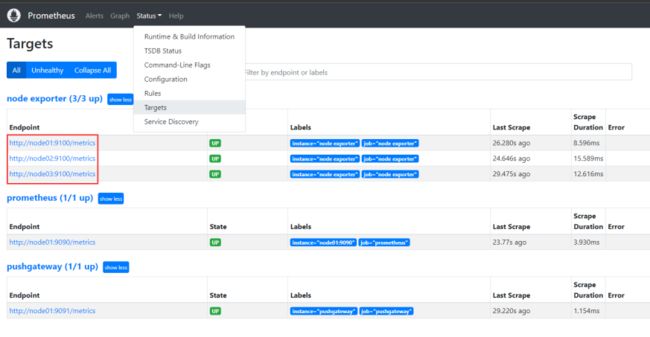
prometheus、pushgateway 和 node exporter 都是 up 状态,表示安装启动成功。
28. Flink的集成
Flink 提供的 Metrics 可以在 Flink 内部收集一些指标,通过这些指标让开发人员更好地理解作业或集群的状态。由于集群运行后很难发现内部的实际状况,跑得慢或快,是否异常等,开发人员无法实时查看所有的 Task 日志。 Metrics 可以很好的帮助开发人员了解作业的当前状况。
Flink 官方支持Prometheus,并且提供了对接 Prometheus 的 jar 包,很方便就可以集成。
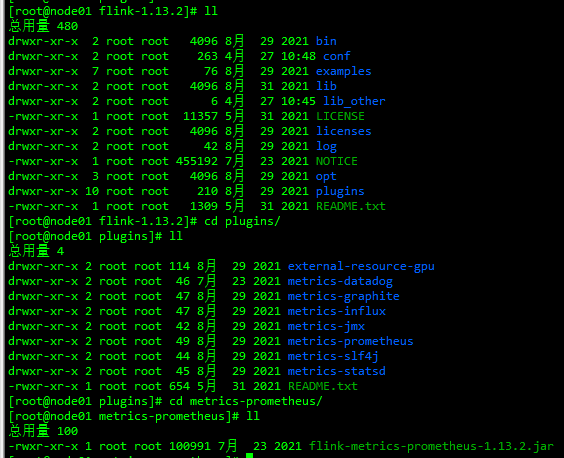
flink 的 plugin 目录下的 jar 包无需拷贝到 lib 目录下,可在运行时被 flink 加载。
28.1. 修改Flink配置
进入到Flink的conf目录,修改flink-conf.yaml
vim flink-conf.yaml
添加如下配置:
##### 与Prometheus集成配置 #####
metrics.reporter.promgateway.class: org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter
# PushGateway的主机名与端口号
metrics.reporter.promgateway.host: node01
metrics.reporter.promgateway.port: 9091
# Flink metric在前端展示的标签(前缀)与随机后缀
metrics.reporter.promgateway.jobName: flink-application
metrics.reporter.promgateway.randomJobNameSuffix: true
metrics.reporter.promgateway.deleteOnShutdown: false
metrics.reporter.promgateway.interval: 30 SECONDS
之后启动一个 flink 任务,然后就可以通过 grafana 来查询 prometheus 中网关的数据了。
29. Grafana
下载地址:https://grafana.com/grafana/download
有两种方式安装,第一种是下载 tar.gz 包,然后上传解压安装,另一种是下载 rpm 包,直接使用 yum 命令进行安装。推荐使用第二种,更方便。
29.1. tar
29.1.1. 上传并解压
将 grafana-enterprise-7.5.2.linux-amd64.tar.gz 上传并解压:
tar -zxvf grafana-enterprise-7.5.2.linux-amd64.tar.gz
mv grafana-enterprise-7.5.2.linux-amd64 grafana-7.5.2
chown -R root:root grafana-7.5.2
可修改 conf 目录下的 sample.ini 文件来修改一些配置,比如数据文件存放目录等。
29.1.2. 启动
nohup ./grafana-server web > grafana.log 2>&1 &
打开 web:http://node01:3000,默认用户名和密码:admin/admin
29.2. rpm
将 rpm 包上传之后,直接使用 yum 命令安装
yum -y install grafana-enterprise-7.5.2.x86_64.rpm
安装之后的服务名称为 grafana-server 之后就可以使用 systemctl 命令来对 grafana 服务进行启停。
systemctl status grafana-server
systemctl start grafana-server
systemctl stop grafana-server
systemctl restart grafana-server
29.2.1. 一些文件位置
安装之后的所有目录和文件所属用户均为:grafana
配置文件:/etc/grafana/grafana.ini
数据文件目录:/var/lib/grafana
运行日志文件:/var/log/grafana/grafana.log
如果想要修改一些配置,则可以直接修改配置文件,然后对 grafana-server 服务重启。
29.3. 监控方案
https://grafana.com/search/?term=flink&type=dashboard
通过上面的网址,我们可以去搜索到很多其他用户共享的监控方案,我们只需找到适合自己的方案,然后下载 json 文件,上传到自己的 grafana 即可。
30. nginx
30.1. 版本区别
常用版本分为四大阵营
Nginx开源版:[干净纯粹,二次开发难]:nginx news
Nginx plus 商业版 【可以直接使用】:Advanced Load Balancer, Web Server, & Reverse Proxy - NGINX
openresty [nginx + lua 整合 + 个人定制话功能 + 免费开源]:OpenResty® - 中文官方站
Tengine [性能高、无需二次开发、稳定]:The Tengine Web Server
30.2. windows下安装
-
下载nginx
地址:http://nginx.org/en/download.html
下载稳定版本即可。 -
解压
解压之后,目录如下:
-
启动
有很多种方法启动nginx
- 直接双击nginx.exe,双击后一个黑色的弹窗一闪而过即为启动成功。
- 打开cmd命令窗口,切换到nginx解压目录下,输入命令
nginx.exe,回车即可。
-
检查nginx是否启动成功
直接在浏览器地址栏输入网址 http://localhost:80,回车,出现以下页面说明启动成功!
-
关闭nginx
如果使用cmd命令窗口启动nginx,关闭cmd窗口是不能结束nginx进程的,可使用两种方法关闭nginx
-
输入nginx命令:
nginx -s stop(快速停止nginx) 或nginx -s quit(完整有序的停止nginx) -
使用taskkill命令:
taskkill /f /t /im nginx.exetaskkill 是用来终止进程的
/f 是强制终止
/t 终止指定的进程和任何由此启动的子进程
/im 用来指定进程名称
-
30.3. linux下安装
30.3.1. 安装必要的依赖
yum install gcc-c++ pcre pcre-devel zlib zlib-devel openssl openssl-devel
30.3.2. 下载安装包
地址:https://nginx.org/en/download.html
下载完毕上传到服务器上
30.3.3. 解压
tar -zxvf nginx-1.18.0.tar.gz
cd nginx-1.18.0
解压位置无所谓,下面编译安装的时候,可以指定具体的安装位置。
30.3.4. 配置
使用默认配置,在nginx根目录下执行
./configure
#或者是
./configure --prefix=/usr/local/nginx
make
make install
编译时,通过 –prefix 命令指定的参数,就是最后安装的位置,建议手动指定到自己想要安装的位置。
查找安装路径:
whereis nginx
30.3.5. 启动
切换到安装目录的 sbin 目录,然后执行:
./nginx
即可启动。
./nginx #启动
./nginx -s stop #快速停止
./nginx -s quit #优雅关闭,在退出前完成已经接受的连接请求
./nginx -s reload #重新加载配置
30.3.5.1. 防火墙设置
##关闭防火墙
systemctl stop firewalld.service
#禁止防火墙开机启动
systemctl disable firewalld.service
#放行端口
firewall-cmd --zone=public --add-port=80/tcp --permanent
#重启防火墙
firewall-cmd --reload
30.3.6. 配置为系统服务
-
创建服务脚本
vim /usr/lib/systemd/system/nginx.service内容:
[Unit] Description=nginx - web server After=network.target remote-fs.target nss-lookup.target [Service] Type=forking PIDFile=/usr/local/nginx/logs/nginx.pid ExecStartPre=/usr/local/nginx/sbin/nginx -t -c /usr/local/nginx/conf/nginx.conf ExecStart=/usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf ExecReload=/usr/local/nginx/sbin/nginx -s reload ExecStop=/usr/local/nginx/sbin/nginx -s stop ExecQuit=/usr/local/nginx/sbin/nginx -s quit PrivateTmp=true [Install] WantedBy=multi-user.target注意修改内容中有关 nginx 的相关文件的位置。
-
重新加载系统服务
systemctl daemon-reload -
测试系统命令
systemctl start nginx.service systemctl reload nginx.service systemctl status nginx.service systemctl enable nginx.service
31. keepalived
31.1. 下载+安装
地址:https://www.keepalived.org/download.html
下载之后解压,然后运行命令:
./configure
来编译安装。
在编译安装过程中出现一些依赖错误时,可以通过 yum 来安装对应的依赖。
31.2. yum安装
yum install keepalived -y
安装完之后,配置文件的位置为:/etc/keepalived/keepalived.conf
推荐使用 yum 来安装。
安装过程会将软件配置为系统服务,可以通过 systemctl 来进行服务的启动停止等操作。