基于Istio的高级流量管理二(Envoy流量劫持、Istio架构、高级流量管理)
文章目录
-
- 一、Envoy流量劫持机制(Iptables规则流转)
-
-
- 1、流量出向劫持流程
-
-
- (1)envoy怎样劫持入向流量?
- (2)Envoy劫持到流量之后,干什么?(查询目的地)
- (3)获取目的地址之后,怎么到达目的地呢?
-
- 2、流量入向劫持流程
- 3、流量出入总结图
-
- 二、Istio、Envoy整体请求流程架构
- 三、Istio高级流量管理实践
-
-
- 1、Istio流量控制简介
- 2、Istio基本配置对象解析
-
-
- (1)Gateway(一般用IngressGateway,EgressGateway一般不用)
- (2)VirtualService
-
- 3、istio实际配置场景
-
-
- (1)规则匹配的优先(类似location规则匹配的优先级)
- (2)rewrite跳转
- (3)设置HTTPS网站
- (4)金丝雀发布
- (5)两个版本服务之间按比例拆分流量
- (6)超时与重试
- (7)错误注入(混沌测试)
- (8)条件规则
- (9)流量镜像
- (10)规则委托
- (11)熔断器与服务访问请求数限制
- (12)外部服务纳入Istio管控
- (13)遥测(监控收集请求的metrics)
-
- 4、请求跟踪(服务调用链路的可观测性)
-
-
- (1)jaeger的安装
- (2)jaeger的使用
- (3)链路监控的必要条件 Headers 传递
- (4)采集频率控制
-
-
在看下面内容之前,先看下这个图,你必须要明白, 什么时候查路由表做路由判决,什么时候去匹配iptables规则。
一、Envoy流量劫持机制(Iptables规则流转)
k create ns sidecar
// 设置这个 namespace 要自动注入 istio sidecar
kubectl label namespace sidecar istio-injection=enabled

其实,一个业务pod被创建,不只是会注入一个envoy sidecar,还会注入一个init container,它的主要作用就是设置一些iptables,使所有请求业务pod的流量和业务pod请求出去的流量都要被envoy抓上来,即下图所描述的那样:
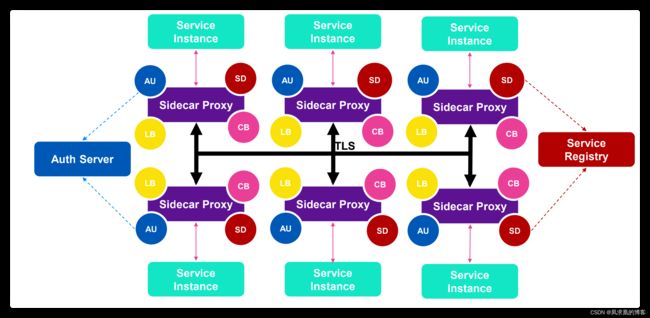
我们这个部分的目的就是讲清楚这些iptables规则,让你对Envoy的流量劫持有个详细的了解!
现在我们要在一个toolbox容器内,访问一个nginx容器,他们都是在sidecar命名空间下,执行下面这个命令:
# 因为在一个命名空间所以可以省去后缀
curl nginx
未使用service mesh,一般的数据包流转是,kube_DNS将nginx解析成service ip,变成访问service ip,然后因为我们现在在容器中嘛,因此先通过默认路由到主机,后面就是在主机上的操作了,主机发现访问service ip,先做routing decision,因为service没有路由(因为serivce ip其实就是一个虚拟ip,他的作用就是对一组pod ip的映射,因此iptables postrouting就是完成这个映射的),那么路由判决应该就走主机默认路由所属的网卡出。再根据主机上的kube-proxy 配置的iptables规则 kube_svc chain 去以1/3、1/2、1的概率分别转到几个pod中。多说一句,kube proxy实际上就是一个控制循环,watch service 、endpoint、node资源的变更,然后通过修改ipvs或者iptables达到转发到后端pod的目的。
那么用了service mesh又该怎样流转呢?
1、流量出向劫持流程
(1)envoy怎样劫持入向流量?
curl nginx,首先也还是kube_DNS解析成service ip,然后再做route decision(注意这里是在容器上做的路由判决,上面未使用service mesh的数据包流转的流程,是在主机上做的路由判决,其实也要在容器上做路由判决,但是由于主要操作都在主机上,因此只说了主机的路由判决,因此就没提容器的,但是istio主要操作是在容器里的),没有service路由,路由判决应该就走容器默认路由所属的网卡出,然后就到了output chain、postrouting chain。下面就是Initcontainer注入的所有Iptables规则:
docker inspect 5273deaee3a6|grep -i pid
nsenter -t 2777406 -n iptables-save -t nat

15001是什么进程呢?他是envoy监听的端口,用于接收出向流量的,15006是用于接收入向流量的。这样流量就进入了envoy。

(2)Envoy劫持到流量之后,干什么?(查询目的地)
注意envoy对流量分为outbound(15001端口)、inbound(15006端口),而且用了两个端口进行监听,然后因为我们要访问80端口,因此找outbound 80
//然后ctrl f在页面搜索15001,往下找80监听器, 当然你也可以指定参数--port 80,直接找到listener
// 因为要展示virtualOutbound就没指定参数
[root@vms120 httpbin]# istioctl proxy-config listener httpbin-85d76b4bb6-nrlqv -o json
{
"name": "virtualOutbound", // 虚拟监听器
"address": {
"socketAddress": {
"address": "0.0.0.0",
"portValue": 15001
}
},
...
"name": "0.0.0.0_80",
"address": {
"socketAddress": {
"address": "0.0.0.0",
"portValue": 80
}
},
"filterChains": [
{
"filterChainMatch": {
"transportProtocol": "raw_buffer",
"applicationProtocols": [
"http/1.1",
"h2c"
]
},
"filters": [
{
"name": "envoy.filters.network.http_connection_manager",
"typedConfig": {
"@type": "type.googleapis.com/envoy.extensions.filters.network.http_connection_manager.v3.HttpConnectionManager",
"statPrefix": "outbound_0.0.0.0_80", // outbound 80
"rds": {
"configSource": {
"ads": {},
"initialFetchTimeout": "0s",
"resourceApiVersion": "V3"
},
"routeConfigName": "80" // 路由配置命名为80
有人可能会纳闷,我80服务这么多,各个服务都要起个outbound 80监听器,这我咋识别,注意这个80只是做个分类,不是监听,所有80端口的服务都用这一个listener,然后用一个路由配置(比如上面的“80”)。至于到底那个服务,匹配那个路由还要根据domain来识别。
然后通过查看80 的RDS,确定自己需要转发的对象,因此我们执行:
// 这里面有所有80服务的路由,可以通过domains分辨那个服务匹配的是那个路由
[root@vms120 httpbin]# istioctl proxy-config route httpbin-85d76b4bb6-nrlqv --name 80 -ojson
{
"name": "nginx.sidecar.svc.cluster.local:80",
"domains": [
"nginx.sidecar.svc.cluster.local",
"nginx.sidecar.svc.cluster.local:80",
"nginx",
"nginx:80",
"nginx.sidecar.svc",
"nginx.sidecar.svc:80",
"nginx.sidecar",
"nginx.sidecar:80",
"10.99.179.59",
"10.99.179.59:80"
],
"routes": [
{
"name": "default",
"match": {
"prefix": "/" // 不管匹配的URL是什么,都会交给下面的cluster处理
},
"route": {
"cluster": "outbound|80||nginx.sidecar.svc.cluster.local", // cluster name
接下来我们就看"cluster": "outbound|80||nginx.sidecar.svc.cluster.local"是什么。
[root@vms120 httpbin]# istioctl proxy-config cluster httpbin-85d76b4bb6-nrlqv --fqdn=nginx.sidecar.svc.cluster.local
SERVICE FQDN PORT SUBSET DIRECTION TYPE DESTINATION RULE
nginx.sidecar.svc.cluster.local 80 - outbound EDS
我们可以发现CDS下面又关联了个EDS,那我们查一下这个EDS是干什么的。
[root@vms120 httpbin]# istioctl proxy-config endpoint httpbin-85d76b4bb6-nrlqv --cluster outbound|80||nginx.sidecar.svc.cluster.local
ENDPOINT STATUS OUTLIER CHECK CLUSTER
10.244.216.30:80 HEALTHY OK outbound|80||nginx.sidecar.svc.cluster.local
// 可以看到 CLUSTER nginx.sidecar.svc.cluster.local实际上的终点地址为 10.244.216.30:80
查看 pod 的IP 就是 CLUSTER nginx.sidecar.svc.cluster.local实际上的终点
[root@vms120 httpbin]# kubectl get po -A -o wide|grep 10.244.216.30
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-85b98978db-dbdjl 2/2 Running 2 (5h25m ago) 22h 10.244.216.30 vms121.rhce.cc <none> <none>
上面只是基本的寻址,你可以通过在istio配置各种复杂的流量管理策略,从而改变LDS、RDS配置,从而达到流量管理的效果。
(3)获取目的地址之后,怎么到达目的地呢?
现在我们知道了目的地是10.244.216.30:80,envoy就会设置目的地址为10.244.216.30,然后发出数据包,那么又会经过routing decision,目的是pod ip,在容器上路由判决还是在默认路由网卡,又会经过output,主机上又会进入ISTIO_OUTPUT Chain。

这时候你可以回去看之前的iptables规则,你就会发现这样一条规则:
# 这个的意思就是来源于group id等于1337(Envoy)的数据包直接return放行
-A ISTIO_OUTPUT -m owner --gid-owner 1337 -j RETURN
2、流量入向劫持流程
进来先到prerouting chain,init container iptables规则如下:

如上图我们可以看到,是redirect到了15006端口,这个是envoy监听的端口,专门用作进流量的(inbound),出流量用的是15001。
到了Envoy以后,还是会先去找对应listener,15006是一个virtualInbound虚拟监听器,然后我们要找inbound 80 listener:
# 查看所有listener包括inbound outbound
// 其中输出的0.0.0.0
istioctl proxy-config listener nginx-5c78d859b9-ckd9z -n sidecar --port 80

我们从上图可以看出,outbound和inbound还是有点不一样,毕竟outbound的所有80服务的路由配置都在一个Route里面,但是inbound却是每个都拆开了,但是内容的确都是一样的。
然后根据Route的名字查询详细信息:
istioctl proxy-config route nginx-5c78d859b9-ckd9z -n sidecar --name music-quiz.music.svc.cluster.local:80 -o json

根据上面cluster中的fqdn,查看cluster信息:
istioctl proxy-config cluster nginx-5c78d859b9-ckd9z -n sidecar --fqdn music-quiz.music.svc.cluster.local

发现是个EDS,那就查endpoint信息:
# 根据cluster名字查endpoint
istioctl proxy-config endpoint nginx-5c78d859b9-ckd9z -n sidecar --cluster "outbound|80||music-quiz.music.svc.cluster.local" -o json
这里就可以得出ip了。其实上面这些路由配置、cluster、ep这些都和outbound是一样的。拿到pod ip发现是本地,然后envoy又发出去,又走output,gid 1337,因此return掉了,然后根据ip就路由到了业务pod。
3、流量出入总结图

二、Istio、Envoy整体请求流程架构
架构图如下(红方框代表istio watch哪些对象,红圆框是代码解读)
三、Istio高级流量管理实践

上面这个图是流量管理的常见业务场景,上图是金丝雀发布,下图是按照客户端的设备类型进行分流。
1、Istio流量控制简介
重点:Istio统一了入向流量(ingress)、mesh流量(envoy)、出向流量(egress)。
istio 引入了服务版本的概念,可以通过版本(v1、v2)或环境(staging、prod)对服务进一步的细分。这些版本不一定是不同的API版本,他们可能是部署在不同环境(staging、prod或者dev 等)中的同一服务的不同迭代(使用这种方式的常见场景包括A/B 测试或者金丝雀部署)。
istio 的流量路由规则可以根据服务版本来对服务之间流量进行附加控制。
- 故障处理

- 微调
Istio流量管理规则允许运维人员为每个服务/版本设置故障恢复的全局默认值。然而,服务的消费者也可以通过特殊的HTTP头提供的请求级别值覆盖超时和重试的默认值。在Envoy代理的实现中,对应的header分别是x-envoy-upstream-rq-timeout-ms和x-envoy-max-retries。 - 故障注入(混沌测试)
(1)为什么需要错误注入:微服务架构下,需要测试端到端的故障恢复能力。
(2)Istio允许在网络层面按协议注入错误来模拟错误,无需通过应用层面删除pod,或者人为在TCP层造成网络故障来模拟。
(3)注入的错误可以基于特定的条件,可以设置出现错误的比例:Delay- 提高网络延时、Aborts- 直接返回特定的错误码 - Envoy 在负载均衡池中的实例之间分发流量
(1)istio 目前仅允许三种负载均衡模式:轮询、随机、和带权重的最少请求。
(2)除了负载均衡外,Envoy 还会定期检查池中每个实例的运行状况。Envoy遵循熔断器风格模式, 根据健康检查API调用的失败率将实例分类为不健康和健康两种。当给定实例的健康检查失败次数超过预定阈值时,将会被从负载均衡池中弹出。类似地,当通过的健康检查数超过预定國值时,该实例将被添加回负载均衡池。您可以在处理故障中了解更多有关 Envoy 的故障处理功能。
(3)服务可以通过使用 HTTP 503 响应健康检查来主动减轻负担。在这种情况下,服务实例将立即从调用者的负载均衡池中删除。
2、Istio基本配置对象解析
之前分析了在pod中访问service的mesh流量的流程,是必须要经过envoy的。接下来我们要实践的是用户从外部访问域名的流量控制流程,这个是从IngressGateway进来的。因为金丝雀发布这些都是面向用户的这种外部流量嘛。
(1)Gateway(一般用IngressGateway,EgressGateway一般不用)
IngressGateway这其实对应的就是Envoy Listener。
[root@vms120 networking]# cat bookinfo-gateway.yaml
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: bookinfo-gateway
spec:
selector:
istio: ingressgateway // 这筛选的就是IngressGateway pod
servers:
- port:
number: 80
name: http
protocol: HTTP
hosts:
- "bookinfo.bianmc.com"
上面这个的语义就是向istio: ingressgateway这个selector筛选的pod的envoy插入一个监听80端口、http协议、domain为bookinfo.bianmc.com 的listener
(2)VirtualService
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: bookinfo
spec:
hosts:
- "bookinfo.bianmc.com"
gateways:
- bookinfo-gateway // 指定gateways 转发规则,要与这个listener关联
http:
- match:
- port: 80 // 默认,可以不写
uri:
exact: /productpage
route:
- destination:
host: productpage
port:
number: 9080
解读:访问域名 bookinfo.bianmc.com 如果 match 端口80,路径 /productpage ,就 destination 转发到目的地名为 productpage 的svc,svc的端口为9080,所以 VirtualService 对应的是Envoy中的路由 route 转发规则。
除了这两个基本对象之外,还有DestinationRule(金丝雀发布)、ServiceEntry和WorkloadEntry(外部服务纳入istio管控)三个扩展对象,这个就在后面讲解。
3、istio实际配置场景
(1)规则匹配的优先(类似location规则匹配的优先级)
重点看红色部分的字,规则匹配是从上到下匹配,当匹配到之后就不再往后匹配,因此我们应该把精确匹配,范围较小的匹配放在前面,像匹配所有这种或者范围大的应该放在后面。

(2)rewrite跳转
rewrite跳转规则,只用修改VirtualService即可。
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: bookinfo
spec:
hosts:
- "bookinfo.bianmc.com"
gateways:
- bookinfo-gateway
http:
- match:
- uri:
exact: /productpage/hello
rewrite: // 跳转到那个url
uri: /productpage
route:
- destination:
host: productpage
port:
number: 9080
服务版本更新,原来的/productpage/hello接口被废弃了,现在变成了/productpage接口,但是用户不知道这个呀,用户还是去访问/productpage/hello,因此我们要将访问uri: /productpage/hello跳转到uri: /productpage的访问。
(3)设置HTTPS网站
- 生成 https 证书
[root@vms120 ~]# openssl req -x509 -sha256 -nodes -days 365 -newkey rsa:2048 -subj '/O=bianmc Inc./CN=*.bianmc.io' -keyout bianmc.io.key -out bianmc.io.crt
Generating a 2048 bit RSA private key
..................................+++
...........................................................................+++
writing new private key to 'bianmc.io.key'
-----
- 创建存放证书的 secret ,也可以在 VirtualService 中直接调用证书文件
[root@vms120 ~]# kubectl create secret tls bianmc-credential --key=bianmc.io.key --cert=bianmc.io.crt -n istio-system
secret/bianmc-credential created
- 创建 Gateway 和 VirtualService
[root@vms120 networking]# cat bookinfo-gateway.yaml
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: bookinfo-gateway
spec:
selector:
istio: ingressgateway # use istio default controller
servers:
- port:
number: 443 // https 端口
name: https
protocol: HTTPS // 协议HTTPS
tls: // 指定 存放证书的 secret
mode: SIMPLE
credentialName: bianmc-credential
// 也可以在 VirtualService 中直接调用证书文件
// serverCertificate: /etc/istio/ingressgateway-certs/tls.crt
// privateKey: /etc/istio/ingressgateway-certs/tls.key
hosts:
- "bookinfo.bianmc.com"
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: bookinfo
spec:
hosts:
- "bookinfo.bianmc.com"
gateways:
- bookinfo-gateway
http:
- match:
- uri:
exact: /productpage
port: 443 // 监听端口修改
route:
- destination:
host: productpage
port:
number: 9080
测试:
[root@vms120 ~]# curl --resolve bookinfo.bianmc.com:443:10.101.89.49 https://bookinfo.bianmc.com/productpage -v -k
(4)金丝雀发布
现在我们有两个版本的Service,一个version: v1,一个version: v2,现在我们就要对这两个版本做精细的流量控制,配置如下:
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: canary
spec:
hosts:
- canary
http:
- match:
- headers:
user:
exact: jesse
route:
- destination:
host: canary
subset: v2
- route:
- destination:
host: canary
subset: v1
我们先来看上面这个配置,匹配host = canary,匹配headers中 user = jesse这个用户的请求路由会发送subset: v2去,subset v2这是什么,这就引出DestinationRule这个对象:
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: canary
spec:
host: canary
trafficPolicy:
loadBalancer:
simple: RANDOM
subsets:
- name: v1
labels:
version: v1
- name: v2
labels:
version: v2
trafficPolicy:
loadBalancer:
simple: ROUND_ROBIN
观察这个对象我们可以看出,首先匹配host = canary,然后定义了一个默认的后端pod负载均衡策略是RANDOM,然后又定义了两个subset v1和v2,v1匹配Service中有label version: v1的,且采用默认的RANDOM策略,v2匹配Service中有label version: v2的,采用ROUND_ROBIN 轮询策略。
合在一起,就是jesse这个用户的请求会发送给version: v2 Service,且Service到后端pod的负载均衡策略是轮询。其他用户的请求会发送给version: v1 Service,且负载均衡策略是随机的。这样就做到了金丝雀发布。像什么新版本尝鲜申请,就是给你的用户请求,打了个header标记newversion = true,所有带着这个的请求都发到新版本,这样你就得到新版本的页面。
(5)两个版本服务之间按比例拆分流量

注意两个加起来weight值必须要达到100%。
(6)超时与重试

(7)错误注入(混沌测试)

(8)条件规则

(9)流量镜像
mirror规则可以使Envoy截取所有request,并在转发请求的同时,将request转发至Mirror版本中,同时在Header的Host/Authority加上-shadow。注意这些请求会工作在 fire and forget模式,所有response都会被丢弃。
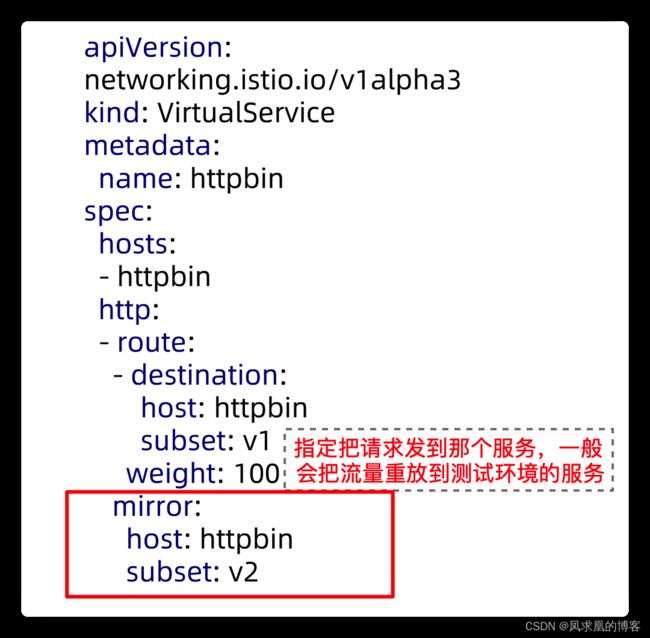
(10)规则委托

主要是减少主配置的复杂度,各个子业务线可以灵活配置自己的下面各个更小服务的路由规则。
(11)熔断器与服务访问请求数限制
注意熔断器是outlierDetection里面定义的,熔断器服务访问请求数限制这个是为了保护服务做的设置

(12)外部服务纳入Istio管控
Istio内部会维护一个服务注册表,可以用ServiceEntry向其中加入额外的条目。通常这个对象用来启用对istio服务网格之外的服务发出请求。
ServiceEntry中使用hosts字段来指定目标,字段值可以是一个完全限定名,也可以时个通配符域名。

这样就把一个外部的服务,变成了集群内部的一个Service了。就可以纳入istio管理。
(13)遥测(监控收集请求的metrics)

4、请求跟踪(服务调用链路的可观测性)
在微服务中往往一次请求会尽力N多服务,那么每个服务的响应状态这个业务经过哪些服务对开发或问题排查就显得额外重要,链路监控是其中的一种解决方案,把微服务中的调用链进行记录并且通过可视化的方式进行展示,行业中相对成熟的解决方案就是zipkin,但是因为zipkin的界面并不是那么友好一般我们配合着jaeger进行使用,istio也对它进行了整合.
(1)jaeger的安装
- 部署jaeger
kubectl apply -f https://raw.githubusercontent.com/istio/istio/release-1.17/samples/addons/jaeger.yaml
- Jaeger 部署完毕后,需要指定 Istio 代理向 jaeger Deployment 发送流量。在安装时,可以使用以下命令进行配置。
istioctl upgrade --set values.global.tracer.zipkin.address=<jaeger-collector-address>:9411
- jaeger service采用nodeport暴露出去,这样我们就可以通过浏览器访问jaeger的web页面了
> kubectl edit svc jaeger-query -n istio-system
ports:
- name: query-http
port: 16686
protocol: TCP
targetPort: 16686
nodePort: 30686
selector:
app: jaeger
sessionAffinity: None
type: NodePort
(2)jaeger的使用
在 Jaeger dashboard里从Service下选择productpage,点击Find Traces 按钮,可以看到跟踪信息:

进到下一层可以看到每个服务的调用层次以及总体消耗时间的分布:

再展开可以看到更多的相关内容:
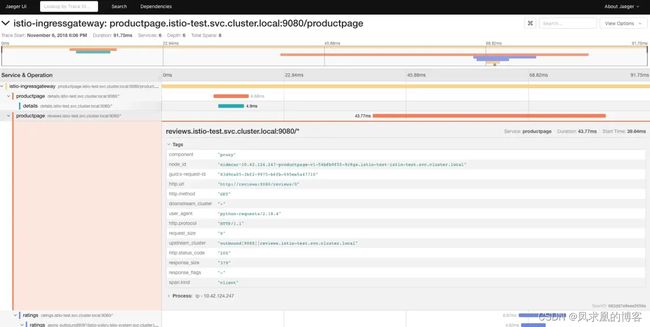
(3)链路监控的必要条件 Headers 传递
为什么使用服务网格之后还需要传递指定的Headers呢? 这里就要从链路监控的机制来说了,在服务网格之前需要链路监控每个程序都需要向链路监控服务器发送消息,由第一个程序找链接监控发起ID获取,接下来的每个程序被调用的时候都需要告知链路监控系统我是在这个链路ID之中,此时才能关联整个链路.
虽然 Istio 代理能够自动发送 Span 信息,但还是需要一些辅助手段来把整个跟踪过程统一起来。应用程序应该自行传播跟踪相关的 HTTP Header,这样在代理发送 Span 信息的时候,才能正确的把同一个跟踪过程统一起来。
为了完成跟踪的传播过程,应用应该从请求源头中收集下列的 HTTP Header,并传播给外发请求:
x-request-id
x-b3-traceid
x-b3-spanid
x-b3-parentspanid
x-b3-sampled
x-b3-flags
x-ot-span-context
如果查看示例服务,可以看到productpage服务(Python)从HTTP请求中提取所需的标头:
def getForwardHeaders(request):
headers = {}
incoming_headers = [ 'x-request-id',
'x-b3-traceid',
'x-b3-spanid',
'x-b3-parentspanid',
'x-b3-sampled',
'x-b3-flags',
'x-ot-span-context'
]
for ihdr in incoming_headers:
val = request.headers.get(ihdr)
if val is not None:
headers[ihdr] = val
#print "incoming: "+ihdr+":"+val
return headers
上面是python的写法,go语言的写法有点不一样:
func rootHandler(w http.ResponseWriter, r *http.Request) {
// 我现在是service0,然后去调用service1,我在调用service1的时候需要把header传过去
req, err := http.NewRequest("GET", "http://service1", nil)
if err != nil {
fmt.Printf("%s", err)
}
lowerCaseHeader := make(http.Header)
// go和python不一样的地方在于,把header拿出来的时候会把首字母变成大写,我们需要转成小写
for key, value := range r.Header {
lowerCaseHeader[strings.ToLower(key)] = value
}
req.Header = lowerCaseHeader
client := &http.Client{}
resp, err := client.Do(req)
if err != nil {
glog.Info("HTTP get failed with error: ", "error", err)
} else {
glog.Info("HTTP get succeeded")
}
if resp != nil {
resp.Write(w)
}
glog.V(4).Infof("Respond in %d ms", delay)
}
(4)采集频率控制
Istio 默认捕获所有请求的跟踪。例如,何时每次访问时都使用上面的 Bookinfo 示例应用程序 / productpage你在 Jaeger 看到了相应的痕迹仪表板。链路监控每次和链路服务器通讯也是有性能消耗的,在一个每天千万pv的业务下把所有链路全部采集下来是不合适的,无论从CPU还是磁盘空间都很容易出现瓶颈,并且链路监控并不是日志是一种排查手段,所以我们需要在生产环境下进行采集频率的限制:
找到pilot中PILOT_TRACE_SAMPLING环境变量从100%修改成10%的采集率:
> kubectl -n istio-system edit deploy istio-pilot
...
- name: PILOT_TRACE_SAMPLING
value: "10"
...
再去刷新页面10次在JaegerUI只会看到一次调用,这边最小精度是0.01%有效值是0.0~100.0(不需要此功能可以完全不开启)