【AIGC】15、Grounding DINO | 将 DINO 扩展到开集目标检测

文章目录
-
- 一、背景
- 二、方法
-
- 2.1 特征抽取和加强
- 2.2 Language-Guided Query Selection
- 2.3 Cross-Modality Decoder
- 2.4 Sub-sentence level text feature
- 2.5 Loss Function
- 3、效果
-
- 3.1 zero-shot transfer of grounding DINO
- 3.2 Referring Object detection
- 3.3 Ablations
- 3.4 从 DINO 到 Grounding DINO
论文:Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
代码:https://github.com/IDEA-Research/GroundingDINO
出处:清华、IDEA
时间:2023.03.20
贡献:
- 本文提出了一种 open-set 的目标检测器,Grounding DINO,将 Transformer based 检测器 DINO 和 grounded pre-training 结合起来,能够根据任何输入(如类别或其他形容词)来输出任意类别目标的检测框
- 本文提出了将 open-set object detection 的测评扩展到 REC(表示根据输入描述提取出一个目标)数据集上,能够帮助测评模型在 free-form 文本输入情况下的表现
一、背景

理解视觉新概念是视觉模型应该具有的基本能力,基于此,作者提测了一个强大的检测器 open-set object detection,能够检测任意的能用人类语言描述的目标
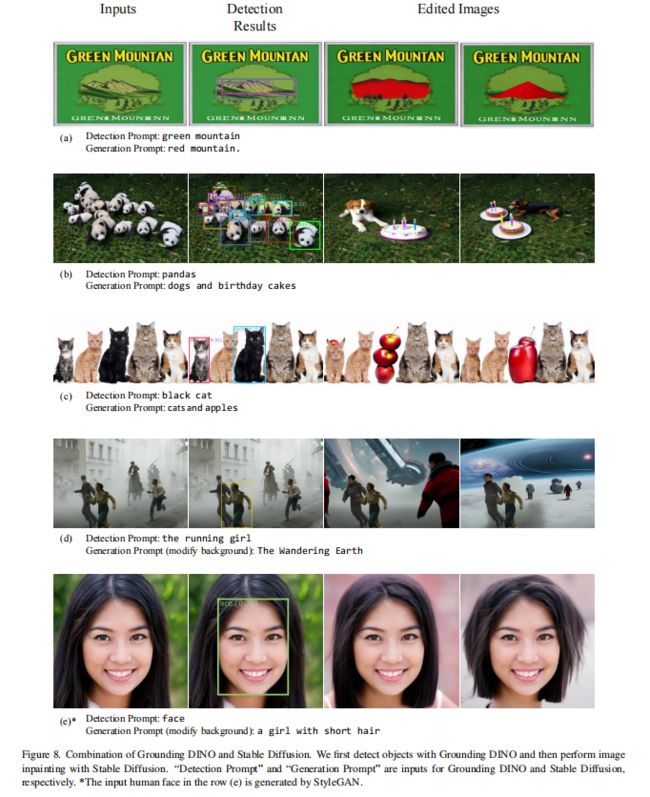
而且该任务也能和其他模型结合使用,有很大的潜力,如图 1b 所示,和生成模型结合起来就能进行图像编辑
open-set 目标检测的关键点在于将语言模型引入到 closed-set 目标检测器中,来实现 open-set 的泛化,能够认识没有见过的目标
如 GLIP 将目标检测定义为一个 phrase groundig task,并使用对比训练来训练目标区域和语言短语,在各种各样的数据集上都获得了很好的效果,包括 closed-set 和 open-set 检测
由于 closed-set 和 open-set 检测很类似,所以肯定能将两者联系起来来做一个更好的 open-set 检测器
本文基于 DINO[58] 提出了一个 open-set detector,且在目标检测上获得了很好的效果
Grounding DINO 相比 GLIP 的优势:
- 基于 Transformer 结构,能同时适用于图像和语言数据
- Transformer 结构能从大型数据集上获得更多的信息
- DINO 可以端到端的优化模型,不需要使用后处理等(如 NMS)
现有的一些 open-set 检测器是怎么做的:
- 使用语言模型的信息来将 closed-set 检测器扩展到 open-set 检测器
closed-set 检测器的三个重要模块:
- backbone:抽取图像特征
- neck:特征增强
- head:回归和分类等
如何使用语言模型将 closed-set 检测器扩展到 open-set 检测器:
- 学习 language-aware regiong embedding
- 这样就可以将每个目标区域划分到语言语义信息对应的空间去
- 其关键在于 neck 或 head 输出的地方,在 region output 和 language features 之间使用对比学习,来帮助模型学习如何对齐这两种多模态信息
- 如图 2 展示了三个不同的阶段进行特征融合的示例,neck(A)、query initialization(B)、head(C)

到底什么时候来进行特征融合比较好呢:
- 一般认为,在整个 pipeline 中进行特征的融合的效果会更好
- 类似于 CLIP 形式的检索结构为了高效,只需要对最后的特征来进行对比即可
- 但是对于 open-set detection,模型的输入是 image 和 text,所以 tight(and early)fusion 的效果更好,也就是更多的融合效果更好
- 但是以前的检测器(如 Faster RCNN)很难在这三个阶段都将语言特征引入来进行融合,但 图像 Transformer 结构和 language 的结构很类似,所以本文作者设计了三个特征融合器,分别在 neck、query initialization、head 阶段进行融合
Neck 结构:
- stacking self-attention
- text-to-image cross-attention
- image-to-text cross attention
Head:
- query 的初始化:使用 language-guided query 选择方式来初始化
- 如何提高 query 特征表达:对 image 和 text 进行 cross-attention ,来作为 cross-modality decoder
很多现有的 open-set 目标检测器都会在新类别上来测试其效果,如图 1b 所示
但作者认为,只要是能描述的对象,都应该被考虑其中
本文将这个任务命名为 Referring Expression Comprehension(REC),即参照表示理解
作者在图 1b 的右侧展示了一些 REC 的例子
作者在下面三种数据集上进行了实验:
- closed-set
- open-set
- referring

二、方法
Grounding DINO 会在给定一个输入 (image, text) 的基础上输出多个 [object boxes, noun phrases] pairs
如图 3 所示,模型会根据输入的图像和文字描述 ‘cat’ 和 ’table’ 来框出输入图像中的 cat 和 table
目标检测和 REC 任务都可以使用这个 pipeline 来对齐,类似于 GLIP:
- 如何实现目标检测:将所有类别的名字作为输入 text 来
- 如何实现 REC:对每个输入 text,REC 只需要返回一个 bbox 即可, 所以作者使用输出目标的最大得分作为 REC 的输出
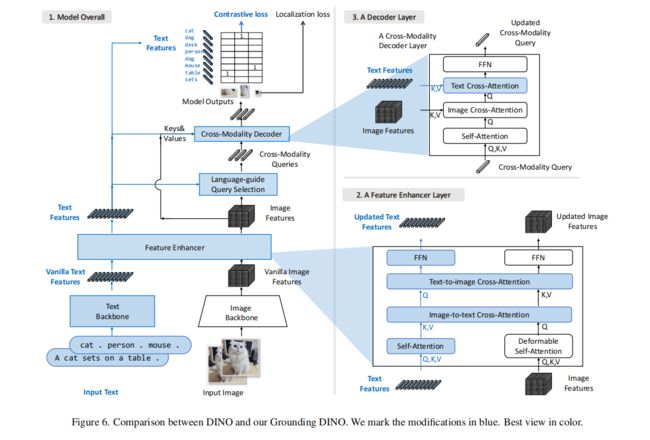
Grounding DINO 的结构:dual-encoder-single-decoder 的结构,整体结构如图 3 所示
- 一个 image backbone 来抽取图像信息
- 一个 text backbone 来抽取文本信息
- 一个 feature enhancer 来对图像和文本信息进行融合
- 一个 language-guided query 选择模块来进行 query 初始化
- 一个 cross-modality decoder 来进行 box 的修正
对每个(image, text)pair 的操作过程如下:
- 首先,使用 image backbone 和 text backbone 来抽取原始的图像特征和文本特征
- 然后,将这两组特征输入 feature enhancer 模块来进行跨模态特征融合,得到跨模态融合特征
- 接着,使用 language-guided query selection 模型来从 image feature 中选择跨模态特征的 query,并输入跨模态 decoder 来从这两个模态的特征中提前需要的特征并且更新 query
- 最后,最后一层 decoder 的输出 query 被用于预测 object box 并且提取对应的 phrases

2.1 特征抽取和加强
给定(Image,Text)pair,从类似 Swin Transformer 的结构中抽取多级图像特征,从类似 BERT 的结构中抽取文本特征
然后使用 DETR-like 的 detectors,来输出检测结果
抽取特征之后,将两组特征输入 enhancer 中来进行跨模态的特征融合,enhancer 结构包括多个 enhancer layers,其中一个如图 3 block2 所示。
使用 Deformable self-attention 来增强图像特征,使用普通的 self-attention 来增强文本特征
和 GLIP 一样,本文也使用了两个 cross-attention 来进行特征融合:
- image-to-text
- text-to-image
2.2 Language-Guided Query Selection
Grounding DINO 为了更好的利用 input text 来指导目标检测,设计了 language-guided query selection 模型,来选择和 input text 相关性更大的 features 来作为 decoder queries,pytorch 伪代码如 Algorithm 1 所示:
- num_query:decoder 中的 queries 数量,实际使用时设定为 900
- bs:batch size
- ndim:feature dimension
- num_img_tokens:image token 的数量
- num_text_tokens:text token 的数量

language-guided query selection module 的输出:
- num_query 索引,可以根据这个输出的索引来来初始化 queries
2.3 Cross-Modality Decoder
如图 3 block3 所示,作者使用 cross-modality decoder 来将 image 和 text 的特征进行结合
2.4 Sub-sentence level text feature
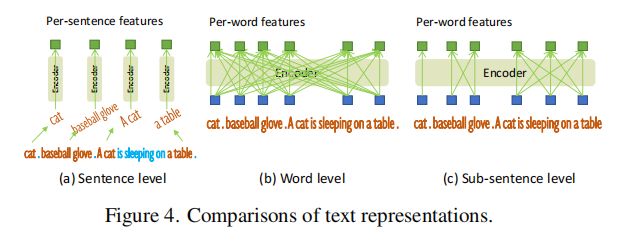
前面的 work 可以获得两种 text prompt,如图 4 所示
- sentence level representation:如图 4a,将整个句子的特征编码为一个特征,如果一个句子有多个短语,则会抽取这些短语,忽略其他 word
- word level representation:如图 4b,会对一个句子中的所有 word 进行关联性编码,会引入不必要的依赖关系,一些并不相关的单词也会被关联起来
基于上面两种编码方式的问题,作者提出了 sub-sentence level 表达的方式,就是只对 sub-sentence 内的 word 进行关联学习,不会引入不必要的联系
2.5 Loss Function
- 回归 loss:L1 loss 和 GIoU loss
- 分类 loss:对比学习 loss(预测的和 language token 之间的对比)
3、效果
作者在三种不同设置上进行了实验:
- 闭集: COCO 检测数据集
- 开集:zero-shot COCO、LVIS、ODinW
- Referring detection:RefCOCO/+/g
设置细节:
- 作者训练了两个模型变体:
- Grounding-DINO-T(swin-T)
- Grounding-DINO-L(swin-L)
- text backbone 为 BERT-base(from Hugging Face)
3.1 zero-shot transfer of grounding DINO
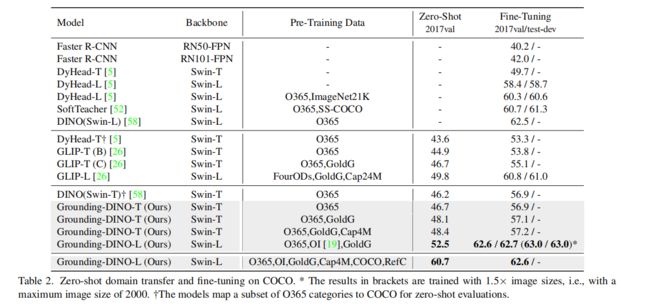
1、COCO Benchmark:
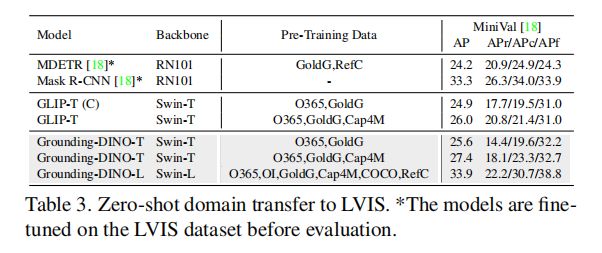
2、LVIS Benchmark
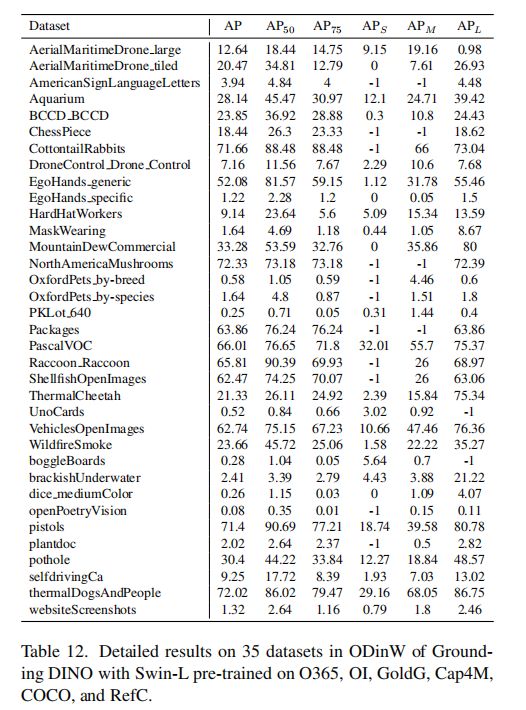
3、ODinW Benchmark
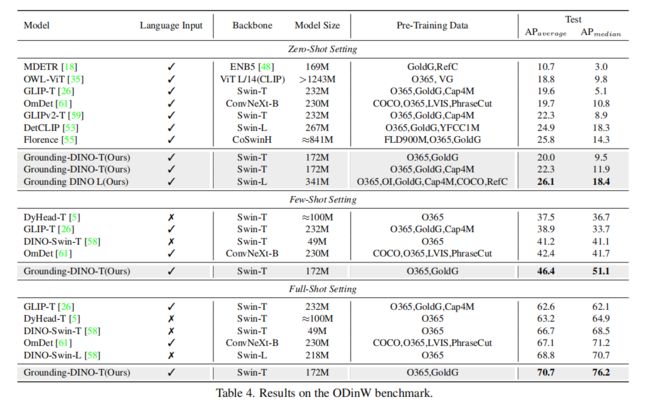
3.2 Referring Object detection

3.3 Ablations
因为作者提出了 tight fusion 模式,为了验证该方式是否有用,作者移除了一些 fusion block,结果见图 6
所有模型都是使用 Swin-L 基于 O365 训练的,结果证明更紧密的 fusion 能够提升最终的效果

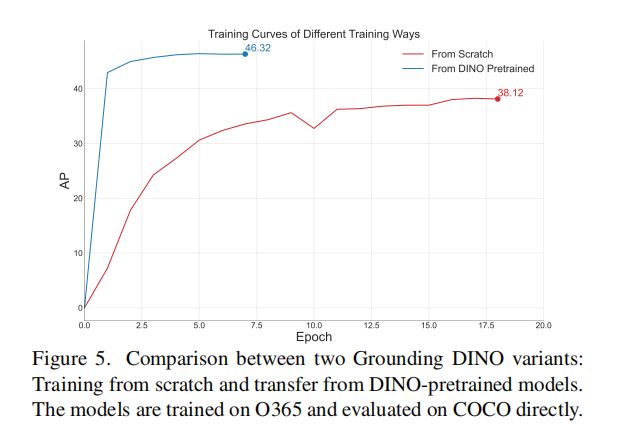
3.4 从 DINO 到 Grounding DINO
如果直接从头开始训练 Grounding DINO 的话,费时费力,所有作者尝试使用了训练好的 DINO 权重,冻结了两个模型共用的部分权重,微调其他部分的参数,结果见表 7。
结果表明,使用 DINO 预训练好的权重,只训练 text 和 fusion block, 就可以达到和重新训练一样的效果