DINO:自监督ViT的新特性
Caron, Mathilde, Hugo Touvron, Ishan Misra, Herv'e J'egou, Julien Mairal, Piotr Bojanowski and Armand Joulin. “Emerging Properties in Self-Supervised Vision Transformers.” ArXiv abs/2104.14294 (2021).
1. Abstract
在本文中,我们质疑自监督学习是否能为视觉Transformer(ViT)提供比卷积网络(ConvNet)更突出的新特性。我们观察到,将自监督方法应用到ViT架构时效果特别好;自监督ViT的特征包含图像语义分割的显式信息,这在有监督的ViT和卷积网络中都没有清晰地呈现出来;自监督ViT的特征也是优秀的k-NN分类器,在ImageNet上使用较小的ViT就达到了78.3%的top-1精度。我们的研究还强调了动量编码器(Momentum Encoder)、多裁剪训练(Multi-crop Training)和使用较小的ViT patches的重要性。我们将我们的发现实现为一个简单的自监督方法DINO,我们将其解释为一种无标签的自蒸馏形式。我们通过使用ViT-Base在ImageNet上实现了80.1%的top-1线性评估精度,展示了DINO和ViT之间的协同作用。开源代码:https://github.com/facebookresearch/dino
2. Method, Experiment & Result

图1. 使用无监督方法训练的8x8 patches ViT的自注意力。我们查看的是最后一层heads上的[CLS] token的自注意力。这个token与标签或监督无关。这些注意力图显示,该模型能够自动学习class-specific特征,从而实现无监督的对象分割。
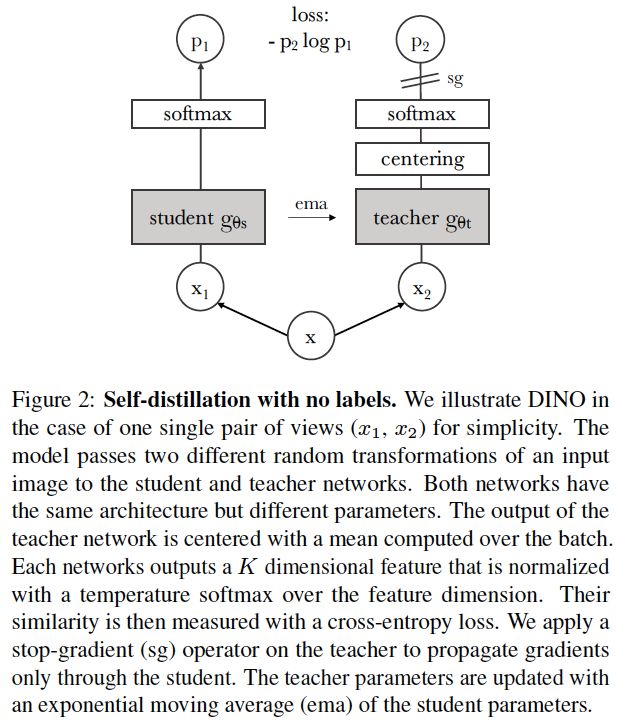
图2. 无标签的自蒸馏。为了简单起见,我们以一对视图(x1, x2)为例说明DINO。该模型对输入图像x进行两种不同的随机变换,得到一对视图(x1, x2),然后分别传递给学生网络和教师网络。两个网络具有相同的架构,但参数不同。教师网络的输出以批量计算的平均值为中心。每个网络输出一个K维特征,并在特征维度上用温度softmax归一化。然后用交叉熵损失来衡量它们的相似度。我们对教师网络应用停止梯度(stop-gradient)算子,只通过学生网络传播梯度。我们用学生网络参数的指数移动平均值(ema)更新教师网络的参数。

上图为DINO的伪代码。DINO的开源代码见:https://github.com/facebookresearch/dino
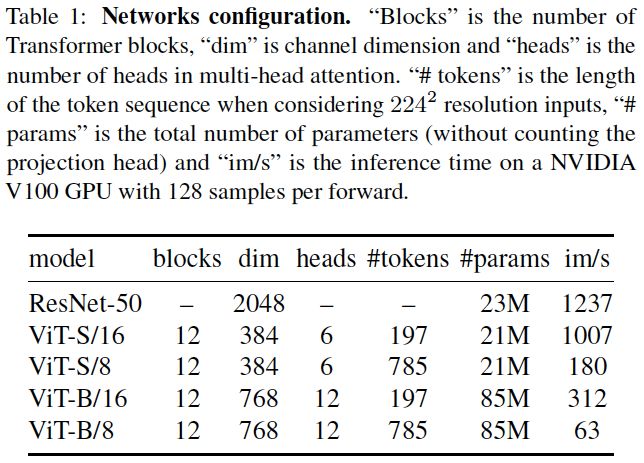
表1. 网络配置。“blocks”是Transformer块的数量,“dim”是通道的维度,“heads”是多头注意力中头的数量。“#tokens”是token序列的长度,“#params”是参数总数(不计算投影头),“im/s”是在NVIDIA V100 GPU上的推断时间。
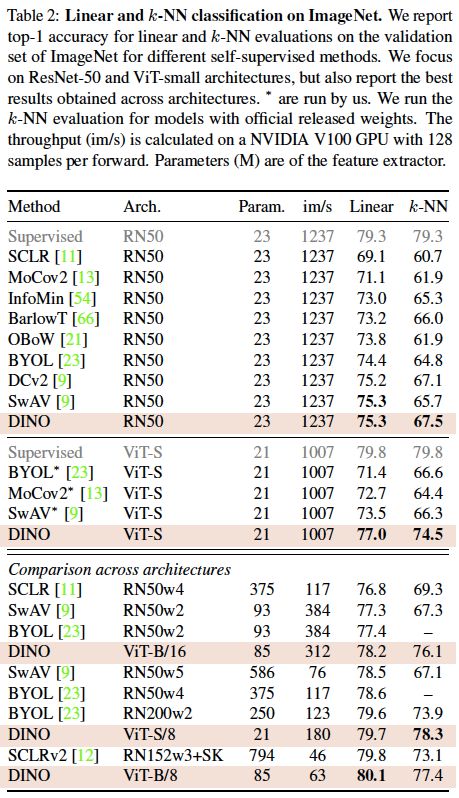
表2. ImageNet上的线性分类和k-NN分类。我们报告了不同自监督方法在ImageNet验证集上的线性评估和k-NN评估的top-1精度。我们主要关注ResNet-50和ViT-small架构,但也报告了跨架构获得的最佳结果。*表示是由我们运行的。我们使用官方发布的权重对模型进行k-NN评估。
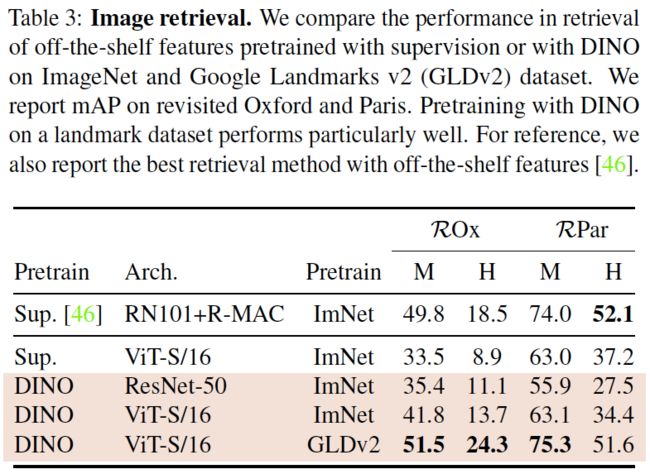
表3. 图像检索。我们比较了在ImageNet和Google Landmarks v2 (GLDv2)数据集上使用有监督方法或DINO预训练的现成特征的检索性能。我们报告了在Oxford和Paris上的平均精度。在landmark数据集上使用DINO进行预训练的效果特别好。作为参考,我们还报告了使用现成特征的最佳检索方法[46]。
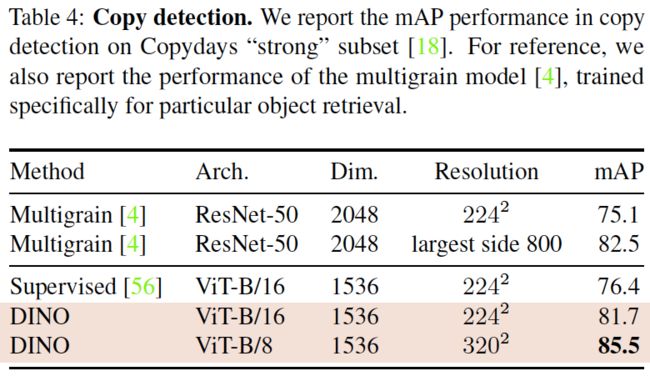
表4. 复制检测。我们报告了在Copydays “strong”子集上复制检测的mAP性能。作为参考,我们还报告了multigrain模型的性能[4],该模型是专门针对特定对象检索而训练的。
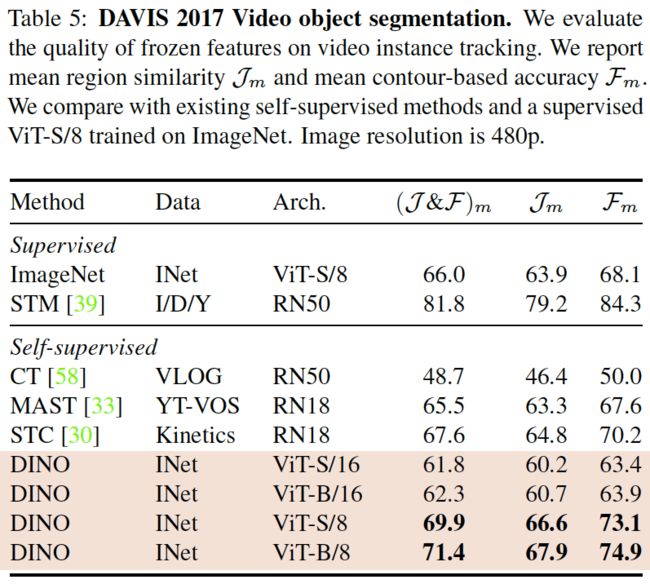
表5. DAVIS 2017视频对象分割。我们评估了视频实例跟踪中冻结特征的质量。我们报告了平均区域相似度Jm和平均contour-based精度Fm。我们比较了现有的自监督方法和在ImageNet上训练的有监督的ViT-S/8。图像分辨率为480p。

图3. 来自多个头的注意力图。我们考虑了使用DINO训练的ViT-S/8的最后一层的头,并显示了[CLS] token查询的自注意力。不同的头关注不同的物体或部位,用不同的颜色表示(更多示例见附录)。

图4. 有监督方法和DINO分割结果的比较。在顶部,我们展示了使用有监督方法和DINO训练的ViT-S/8的mask结果。我们展示了两种模型的最好的head。底部的表格比较了PASCAL VOC12验证图像上的真值和掩码之间的Jaccard相似度。
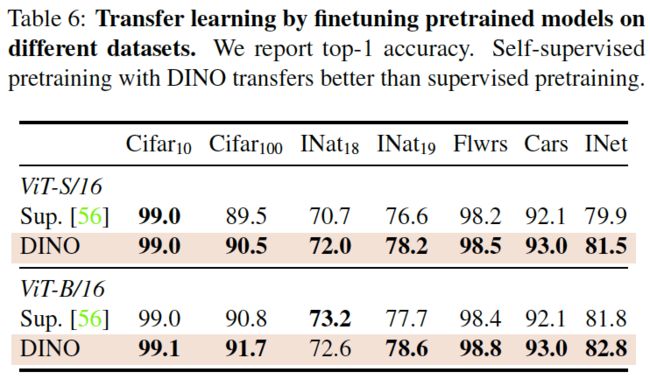
表6. 在不同数据集上微调预训练模型的迁移学习。我们报告的是top-1精度。使用DINO的自监督预训练优于有监督的预训练。
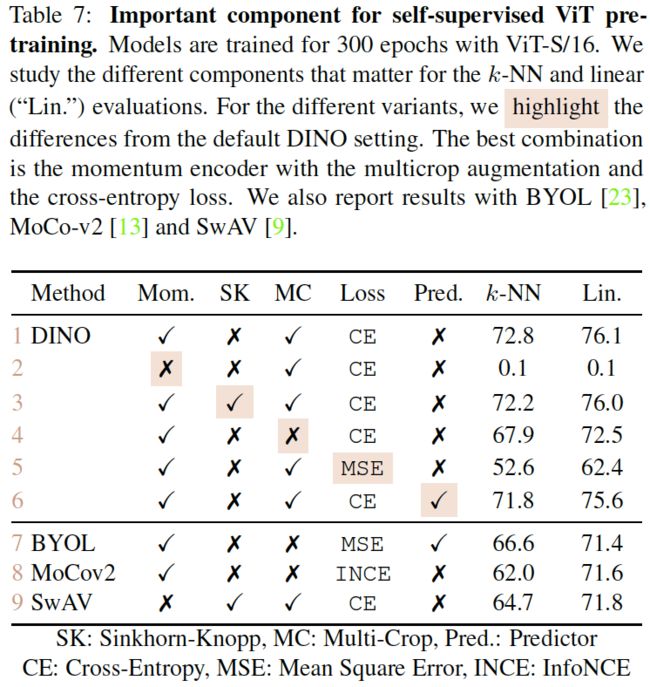
表7. 自监督ViT预训练的重要组件。使用ViT-S/16对模型进行300个epochs的训练。我们研究了不同组件对k-NN分类和线性分类的影响。我们突出显示了不同的变体与DINO默认设置的不同之处。最佳组合是动量编码器(Momentum Encoder)、多裁剪扩增(Multicrop Augmentation)和交叉熵损失(Cross-entropy Loss)。我们还报告了BYOL、MoCo-v2和SwAV的结果。

图5. Patch大小的影响。Patch越小,模型性能越好,但吞吐量随之降低。
3. Conclusion / Discussion
我们展示了通过自监督来预训练标准ViT模型的潜力,实现了与最佳卷积网络相媲美的性能。我们还发现了两个可以在未来应用中利用的特性:k-NN分类中的特征质量具有用于图像检索的潜力,特征中存在的场景布局信息有利于弱监督图像分割。
关注“多模态人工智能”公众号,一起进步!