自旋锁
并发解决方法二(自旋锁)
文章目录
- 并发解决方法二(自旋锁)
- spin_lock
- spin_lock的变体
- 自旋锁的使用
- 读写自旋锁
设计自旋锁的最初目的是在多处理器系统中提供对共享数据的保护,其背后的核心思想是:设置一个在多处理器之间共享的全局变量锁v,并定义当V=I时为上锁状态,V=0为解锁状态·如果处理器A上的代码要进入临界区.它要先读取V的值,判断其是否为0,如果V不等于0表明有其他处理器上的代码正在对共享数据进行访问,此时处理器A进入忙等待即自旋状态,如果V=O表明当前没有其他处理器上的代码进入临界区,此时处理器A可以访问该资源,它先把V置1(自旋锁的上锁状态).然后进入临界区,访问完毕离开临界区时将V置0(自旋锁的解锁状态)。
上述自旋锁的设计思想在用具体代码实现时的关键之处在于,必须确保处理器A“读取v,判断v的值与更新”这一操作序列是个原子操作(atomic operation)•所谓原子操作,简单地说就是执行这个操作的指令序列在处理器上执行时等同于单条指令,也即该指令序列在执行时是不可分割的。
spin_lock
不同的处理器上有不同的指令用以实现上述的原子操作,所以spin_lock的相关代码在不同体系架构上有不同的实现,为了帮助读者对spin_lock这一机制建立具体的印象·下面以ARM处理器上的实现为例,仔细考察spin_lock的幕后行为·下面的讨论先以多处理器为主·然后再讨论spin_lock及其变体在单处理器上的演进。
在给出实际源码细节之前,先做个简短的说明,为了让读者更清楚地理解这里的代码,下面会对代码进行轻微调整,使之外在的表现形式更加紧凑而又不影响其内涵,同时也不会关注一些调试相关的数据成员,所以在摘录的代码中己将其移除。
下面是Linux源码中提供给设备驱动程序等内核模块使用的spin_lock接口函数的定义:
static inline void spin_lock(spinlock_t *lock)
{
raw_spin_lock(&lock->rlock);
}
代码中的数据结构spinlock_t,就是前面提到的在多处理器之间共享的自旋锁在现实源码中的具体表现,透过层层的定义,会发现实际上它就是个volatile unsigned int型变量:
typedef struct spinlock {
union {
struct raw_spinlock rlock;
#ifdef CONFIG_DEBUG_LOCK_ALLOC
# define LOCK_PADSIZE (offsetof(struct raw_spinlock, dep_map))
struct {
u8 __padding[LOCK_PADSIZE];
struct lockdep_map dep_map;
};
#endif
};
} spinlock_t;
typedef struct raw_spinlock {
arch_spinlock_t raw_lock;
#ifdef CONFIG_GENERIC_LOCKBREAK
unsigned int break_lock;
#endif
#ifdef CONFIG_DEBUG_SPINLOCK
unsigned int magic, owner_cpu;
void *owner;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
} raw_spinlock_t;
typedef struct {
volatile unsigned int slock;
} arch_spinlock_t;
spin_lock函数中调用的raw_spin_lock是个宏·其实现是处理器相关的,对于ARM处理器而言,最终展开为
static inline void __raw_spin_lock(raw_spinlock_t *lock)
{
preempt_disable();
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);
LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);
}
函数首先调用preempt_disable宏,后者在定义了CONFIG_PREEMPT,也即在支持内核可抢占的调度系统中时,将关闭调度器的可抢占特性。在没有定义CONFIG_PREEMPT时,preempt_disable是个空定义,什么也不做。
真正的上锁操作发生在后面的do_raw_spin_lock函数中,不过在讨论该函数的实现细节前,先来看看为什么raw_spin_lock要先调用preempt_disable来关闭系统的可抢占性·在一个打开了CONFIG_PREEMPI•特性的Linux系统中,一个在内核态执行的路径也有可能被切换出处理器,典型地,比如当前进程正在内核态执行某一系统调用时,发生了一个外部中断·当中断处理函数返回时,因为内核的可抢占性,此时将会出现一个调度点,如果CPU的运行队列中出现了一个比当前被中断进程优先级更高的进程,那么被中断的进程将会被换出处理器,即便此时它正运行在内核态·单处理器上的这种因为内核的可抢占性所导致的两个不同进程并发执行的情形,非常类似于SMP系统上运行在不同处理器上的进程之间的并发,因此为了保护共享的资源不会受到破坏·必須在进入临界区前关闭内核的可抢占性·因为Linux内核源码试图统一自旋锁的接口代码,即不论是单处理器还是多处理器,不论内核是否配置了可抢占特性,提供给外部模块使用的相关自旋锁代码都只有一份,所以可以看到在上述的raw_spin_lock函数中加入了内核可抢占性相关的代码,即便是在没有配置内核可抢占的系统上.外部模块也都统一使用相同的spin_lock和spin_unlock接口函数。
函数接着调用do_raw_spin_lock开始真正的上锁操作
void do_raw_spin_lock(raw_spinlock_t *lock)
{
debug_spin_lock_before(lock);
if (unlikely(!arch_spin_trylock(&lock->raw_lock)))
__spin_lock_debug(lock);
debug_spin_lock_after(lock);
}
与spin_lock相对的是spin_unlock,这是一个应该在离开临界区时调用的函数,用来释放此前获得的自旋锁·其外部接口定义如下
static inline void spin_unlock(spinlock_t *lock)
{
raw_spin_unlock(&lock->rlock);
}
最终调用
#define __UNLOCK(lock) \
do { preempt_enable(); ___UNLOCK(lock); } while (0)
函数先调用面raw_spin_unlock做实际的解锁操作,然后调用preempt_enable函数打开内核可抢占性,对于没有定义CONFIG_PREEMPT的系统,该宏是个空定义·do_raw_spin_unlock函数在ARM处理器上的代码如下:
void do_raw_spin_unlock(raw_spinlock_t *lock)
{
debug_spin_unlock(lock);
arch_spin_unlock(&lock->raw_lock);
}
解锁操作比获得锁的操作要相对简单,只需史新锁变量为0即可,在ARM平台上利用单条指令嘶就可以完成该任务,所以代码非常简单,熹接用指令将自旋锁的状态更新为0,即解锁状态·针对spin_lock应该调用spin_unlock而不是其他形式的释放锁函数,驱动程序员必须确保这种获得锁和释放锁函数调用的一致性.
spin_lock的变体
在前面讨论spin_lock函数时,spin_lock对多处理器系统中这种进程间真正的并发执行引起的竞态问題解决得很好,但是考虑图1所示这样一个场景:
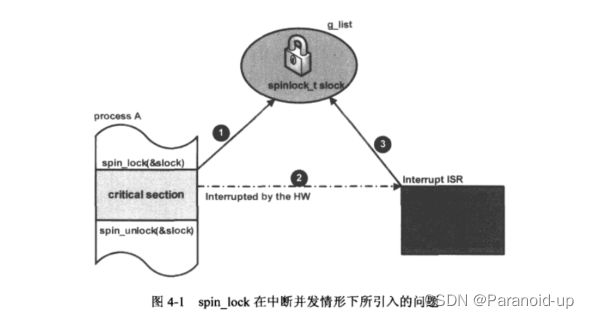
处理器上的当前进程A因为要对某一全局性的链表g-list进行操作,所以在操作前通过调用spin_lock来进入临界区(图中标号1所示),当它正处于临界区中时,进程A所在的处理器上发生了一个外部硬件中断,此时系统必须暫停当前进程A的执行转而去处理该中断(图中标号2所示假设该中断的处理例程中恰好也要操作g-list.因为这是一个共享的全局变量,所以在操作之前也要调用spinlock函数来对该共享变量进行保护(图中标号3所示),当中断处理例程中的spin-lock试图去获得自旋锁slock时,因为被它中断的进程A之前己经获得该锁,于是将导致中断处理例程进入自旋状态。**在中断处理例捍中出现一个自旋状态是非常致命的,因为中断处例程必须在尽可能短的时间内返回,而此时它却必须自旋。此时被它中断的进程A因中断处理函数不能返回而无行,也就不可能释放锁,所以将导致中断处理例程中的spin_lock一直下去,导致死锁。**出现这种特定情况的本质原因在于对锁的竞争发生在不能真正并发执行的两条路径上,如果可以并发执行,那么在上面的案例中,被中断的进程依然可以继续执行继而释放锁·对这种问题的解决导致了spin_lock函数其他变体的出现。
因处理外部的中断而引发spin_lock缺陷的例子,使得必须在这种情况下对spin_lock予以修正,于是出现了spin_lock_irq和spin_lock_irq_save函数·spin_lock_irq函数接口定义如下:
static inline void spin_lock_irq(spinlock_t *lock)
{
raw_spin_lock_irq(&lock->rlock);
}
最终调用
#define __LOCK_IRQ(lock) \
do { local_irq_disable(); __LOCK(lock); } while (0)
其中的raw_spin_lock_irq函数的实现,相对于raw_spin_lock只是在调用preempt_disable之前又调用了local_irq_disable,后者在本章前面部分己经讨论过,用来关闭本地处理器响应外部中断的能力,这样在获取一个锁时就可以确保不会发生中断,从而避免上面提到的死锁问題。local_irq_disable只能用来关闭本地处理器的中断,当一个通过调用spin_lock_irq拥有自旋锁V的进程在处理器A上执行时,虽然在处理器A上中断被关闭了,但是外部中断依然有机会发送到处理器B上,如果处理器B上的中断处理函数也试图去获得锁v,情况会怎样呢?因为此时处理器A上的进程可以继续执行,在它离开临界区时将释放锁,这样处理器B上的中断处理函数就可以结束此前的自旋状态·这从一个侧面说明通过自旋锁进入的临界区代码必须在尽可能短的时间内执行完毕,因为它执行的时间越长·别的处理器就越需要自旋以等待史长的时间(尤其是这种自旋发生在中断处理函数中).最糟糕的情况是进程在临界区中因为某种原因被换出处理器·所以作为使用自旋锁时一条确定的规则,任何拥有自旋锁的代码都必须是原子的,不能休眠。在实际的使用中,这条规则实践起来还远不像规则描述的那样直白,调用者需要仔细审视在拥有锁时的每个函数调用,因为睡眠有可能发生在这函数的内部,比如以GFP_KERNEL作为分配掩码通过kmalloc函数来分配一块内存时.系统中仝闲的内存不足以满足本次分配的情形虽然非常少见,但是毕竟存在这种可能性,一旦这种可能性被确定,kmalloc会阻塞从而会被切换出处理器,如果kmalloc的调用者在此之前拥有某个自旋锁·那么这种情形下将对系统的稳定性造成极大的威胁。
如此,当知道一个自旋锁在中断处理的上下文中有可能会被使用到时·应该使用
spin_lock_irq函数,而不是spin_lock•后者只有在能确定中断上下文中不会使用到自旋锁
的情形下才能使用。spin_lock_irq对应的释放锁函数为spin_unlock_irq,其接口定义为
static inline void spin_unlock_irq(spinlock_t *lock)
{
raw_spin_unlock_irq(&lock->rlock);
}
#define __UNLOCK_IRQ(lock) \
do { local_irq_enable(); __UNLOCK(lock); } while (0)
可见,在raw_spin_unlock_irq函数中除了调用__UNLOCK做实际的解锁操作外,还会打开本地处理器上的中断,以及开启内核的可抢占性。
与spin_lock_irq类似的还有一个spin_lock_save宏,它与spin_lock_irq函数最大的区别
是,在关闭中断前会将处理器当前的FLAGS寄存器的值保存在一个变量中,当调用对应
的spin_unlock_trqrestore来释放锁时·会将spin_lock_irq_save中保存的FLAGS值重新写回
到寄存器中·对于spin_lock_irq_save和spin_unlock_irq_restore的使用场合,可参考前面关于local_irq_save和local_irq_estore的讨论。
自旋锁的使用
自旋锁(Spin Lock) 是一种典型的对临界资源进行互斥访问的手段, 其名称来源于它的工作方式。为了获得一个自旋锁, 在某CPU上运行的代码需先执行一个原子操作, 该操作测试并设置(Test-AndSet) 某个内存变量。 由于它是原子操作, 所以在该操作完成之前其他执行单元不可能访问这个内存变量。 如果测试结果表明锁已经空闲, 则程序获得这个自旋锁并继续执行; 如果测试结果表明锁仍被占用,程序将在一个小的循环内重复这个“测试并设置”操作, 即进行所谓的“自旋”, 通俗地说就是“在原地打转”, 如图7.7所示。 当自旋锁的持有者通过重置该变量释放这个自旋锁后, 某个等待的“测试并设置”操作
向其调用者报告锁已释放。

理解自旋锁最简单的方法是把它作为一个变量看待, 该变量把一个临界区标记为“我当前在运行, 请稍等一会”或者标记为“我当前不在运行, 可以被使用”。 如果A执行单元首先进入例程, 它将持有自旋锁;当B执行单元试图进入同一个例程时, 将获知自旋锁已被持有, 需等到A执行单元释放后才能进入。
在ARM体系结构下, 自旋锁的实现借用了ldrex指令、 strex指令、 ARM处理器内存屏障指令dmb和dsb、 wfe指令和sev指令, 这类似于代码清单7.1的逻辑。 可以说既要保证排他性, 也要处理好内存屏障。
Linux中与自旋锁相关的操作主要有以下4种。
- 定义自旋锁
spinlock_t lock;
- 初始化自旋锁
spin_lock_init(lock);
该宏用于动态初始化自旋锁lock。
- 获得自旋锁
spin_lock(lock);
该宏用于获得自旋锁lock, 如果能够立即获得锁, 它就马上返回, 否则, 它将在那里自旋, 直到该自旋锁的保持者释放。
spin_trylock(lock);
该宏尝试获得自旋锁lock, 如果能立即获得锁, 它获得锁并返回true, 否则立即返回false, 实际上不再“在原地打转”。
- 释放自旋锁
spin_unlock(lock);
该宏释放自旋锁lock, 它与spin_trylock或spin_lock配对使用。
自旋锁一般这样写
/* 定义一个自旋锁*/
spinlock_t lock;
spin_lock_init(&lock);
spin_lock (&lock) ; /* 获取自旋锁, 保护临界区 */
. . ./* 临界区*/
spin_unlock (&lock) ;
自旋锁主要针对SMP或单CPU但内核可抢占的情况, 对于单CPU和内核不支持抢占的系统, 自旋锁退化为空操作。 在单CPU和内核可抢占的系统中, 自旋锁持有期间中内核的抢占将被禁止。 由于内核可抢占的单CPU系统的行为实际上很类似于SMP系统, 因此, 在这样的单CPU系统中使用自旋锁仍十分必要。 另外, 在多核SMP的情况下, 任何一个核拿到了自旋锁, 该核上的抢占调度也暂时禁止了, 但是没有禁止另外一个核的抢占调度。
尽管用了自旋锁可以保证临界区不受别的CPU和本CPU内的抢占进程打扰, 但是得到锁的代码路径在执行临界区的时候, 还可能受到中断和底半部(BH, 稍后的章节会介绍) 的影响。 为了防止这种影响,就需要用到自旋锁的衍生。 spin_lock() /spin_unlock() 是自旋锁机制的基础, 它们和关中断local_irq_disable() /开中断local_irq_enable() 、 关底半部local_bh_disable() /开底半部local_bh_enable() 、 关中断并保存状态字local_irq_save() /开中断并恢复状态字local_irq_restore() 结合就形成了整套自旋锁机制, 关系如下
spin_lock_irq() = spin_lock() + local_irq_disable()
spin_unlock_irq() = spin_unlock() + local_irq_enable()
spin_lock_irqsave() = spin_lock() + local_irq_save()
spin_unlock_irqrestore() = spin_unlock() + local_irq_restore()
spin_lock_bh() = spin_lock() + local_bh_disable()spin_unlock_bh() = spin_unlock() + local_bh_enable()
spin_lock_irq( ) 、 spin_lock_irqsave( ) 、 spin_lock_bh( ) 类似函数会为自旋锁的使用系好“安全带”以避免突如其来的中断驶入对系统造成的伤害。
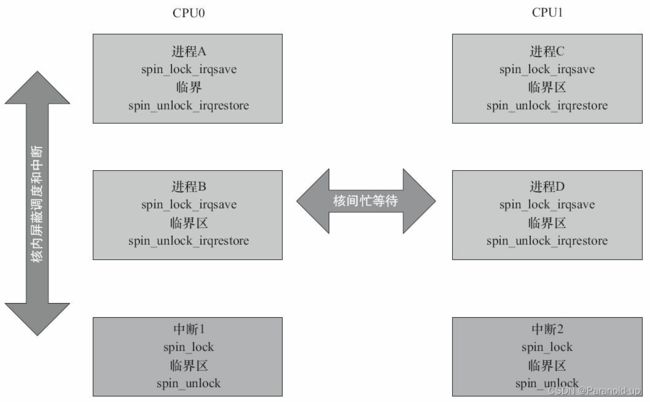
在多核编程的时候, 如果进程和中断可能访问同一片临界资源, 我们一般需要在进程上下文中调用spin_lock_irqsave( ) /spin_unlock_irqrestore( ) , 在中断上下文中调用spin_lock( ) /spin_unlock( ) , 如图7.8所示。 这样, 在CPU0上, 无论是进程上下文, 还是中断上下文获得了自旋锁, 此后, 如果CPU1无论是进程上下文, 还是中断上下文, 想获得同一自旋锁, 都必须忙等待, 这避免一切核间并发的可能性。同时, 由于每个核的进程上下文持有锁的时候用的是spin_lock_irqsave( ) , 所以该核上的中断是不可能进入的, 这避免了核内并发的可能性。
驱动工程师应谨慎使用自旋锁, 而且在使用中还要特别注意如下几个问题。
1) 自旋锁实际上是忙等锁, 当锁不可用时, CPU一直循环执行“测试并设置”该锁直到可用而取得该锁, CPU在等待自旋锁时不做任何有用的工作, 仅仅是等待。 因此, 只有在占用锁的时间极短的情况下,使用自旋锁才是合理的。 当临界区很大, 或有共享设备的时候, 需要较长时间占用锁, 使用自旋锁会降低系统的性能。
2) 自旋锁可能导致系统死锁。 引发这个问题最常见的情况是递归使用一个自旋锁, 即如果一个已经拥有某个自旋锁的CPU想第二次获得这个自旋锁, 则该CPU将死锁。图7.8 自
3) 在自旋锁锁定期间不能调用可能引起进程调度的函数。 如果进程获得自旋锁之后再阻塞, 如调用copy_from_user( ) 、 copy_to_user( ) 、 kmalloc( ) 和msleep( ) 等函数, 则可能导致内核的崩溃。
4) 在单核情况下编程的时候, 也应该认为自己的CPU是多核的, 驱动特别强调跨平台的概念。 比如, 在单CPU的情况下, 若中断和进程可能访问同一临界区, 进程里调用spin_lock_irqsave( ) 是安全的, 在中断里其实不调用spin_lock( ) 也没有问题, 因为spin_lock_irqsave( ) 可以保证这个CPU的中断服务程序不可能执行。 但是, 若CPU变成多核, spin_lock_irqsave() 不能屏蔽另外一个核的中断, 所以另外一个核就可能造成并发问题。 因此, 无论如何, 我们在中断服务程序里也应该调用spin_lock() 。
使用自旋锁使设备只能被一个进程打开
读写自旋锁
自旋锁不关心锁定的临界区究竟在进行什么操作, 不管是读还是写, 它都一视同仁。 即便多个执行单元同时读取临界资源也会被锁住。 实际上, 对共享资源并发访问时, 多个执行单元同时读取它是不会有问题的, 自旋锁的衍生锁读写自旋锁(rwlock) 可允许读的并发。 读写自旋锁是一种比自旋锁粒度更小的锁机制, 它保留了“自旋”的概念, 但是在写操作方面, 只能最多有1个写进程, 在读操作方面, 同时可以有多个读执行单元。 当然, 读和写也不能同时进行。
- 定义和初始化读写自旋锁
rwlock_t my_rwlock;
rwlock_init(&my_rwlock); /* 动态初始化 */
- 读锁定
void read_lock(rwlock_t *lock);
void read_lock_irqsave(rwlock_t *lock, unsigned long flags);
void read_lock_irq(rwlock_t *lock);
void read_lock_bh(rwlock_t *lock);
- 读解锁
void read_unlock(rwlock_t *lock);
void read_unlock_irqrestore(rwlock_t *lock, unsigned long flags);
void read_unlock_irq(rwlock_t *lock);
void read_unlock_bh(rwlock_t *lock);
在对共享资源进行读取之前, 应该先调用读锁定函数, 完成之后应调用读解锁函数。
read_lock_irqsave() 、 read_lock_irq() 和read_lock_bh() 也分别是read_lock() 分别与local_irq_save() 、 local_irq_disable() 和local_bh_disable() 的组合, 读解锁函数read_unlock_irqrestore() 、 read_unlock_irq() 、 read_unlock_bh() 的情况与此类似
- 写锁定
void write_lock(rwlock_t *lock);
void write_lock_irqsave(rwlock_t *lock, unsigned long flags);
void write_lock_irq(rwlock_t *lock);
void write_lock_bh(rwlock_t *lock);
int write_trylock(rwlock_t *lock);
- 写解锁
void write_unlock(rwlock_t *lock);
void write_unlock_irqrestore(rwlock_t *lock, unsigned long flags);void write_unlock_irq(rwlock_t *lock);
void write_unlock_bh(rwlock_t *lock);
write_lock_irqsave( ) 、 write_lock_irq( ) 、 write_lock_bh( ) 分别是write_lock( ) 与local_irq_save( ) 、 local_irq_disable( ) 和local_bh_disable( ) 的组合, 写解锁函数write_unlock_irqrestore( ) 、 write_unlock_irq( ) 、 write_unlock_bh( ) 的情况与此类似。
在对共享资源进行写之前, 应该先调用写锁定函数, 完成之后应调用写解锁函数。 和spin_trylock( )一样, write_trylock( ) 也只是尝试获取读写自旋锁, 不管成功失败, 都会立即返回。
读写自旋锁一般这样被使用
rwlock_t lock; /* 定义rwlock */
rwlock_init(&lock); /* 初始化rwlock */
/* 读时获取锁*/
read_lock(&lock);
... /* 临界资源 */
read_unlock(&lock);
/* 写时获取锁*/
write_lock_irqsave(&lock, flags);
... /* 临界资源 */
write_unlock_irqrestore(&lock, flags);