数据库存储过程和函数
MySQL存储过程和存储函数
MySQL中提供存储过程(procedure)与存储函数(function)机制,我们先将其统称为存储程序,一般的SQL语句需要先编译然后执行,存储程序是一组为了完成特定功能的SQL语句集,经编译后存储在数据库中,当用户通过指定存储程序的名字并给定参数(如果该存储程序带有参数)来调用才会执行。
存储程序优缺点
优点
通常存储过程有助于提高应用程序的性能。当创建,存储过程被编译之后,就存储在数据库中。 但是,MySQL实现的存储过程略有不同。 MySQL存储过程按需编译。 在编译存储过程之后,MySQL将其放入缓存中。 MySQL为每个连接维护自己的存储过程高速缓存。 如果应用程序在单个连接中多次使用存储过程,则使用编译版本,否则存储过程的工作方式类似于查询。
1)性能:存储过程有助于减少应用程序和数据库服务器之间的流量,因为应用程序不必发送多个冗长的SQL语句,而只能发送存储过程的名称和参数。
2)复用:存储的程序对任何应用程序都是可重用的和透明的。 存储过程将数据库接口暴露给所有应用程序,以便开发人员不必开发存储过程中已支持的功能。
3)安全:存储的程序是安全的。 数据库管理员可以向访问数据库中存储过程的应用程序授予适当的权限,而不向基础数据库表提供任何权限。
缺点
1)如果使用大量存储过程,那么使用这些存储过程的每个连接的内存使用量将会大大增加。
此外,如果在存储过程中过度使用大量逻辑操作,则CPU使用率也会增加,因为数据库服务器的设计不偏于逻辑运算。
2)很难调试存储过程。只有少数数据库管理系统允许调试存储过程。不幸的是,MySQL不提供调试存储过程的功能。
数据库存储过程
一、存储过程的概念
存储过程是定义在服务器上的一段子程序代码,存储过程时数据库对象之一。
存储过程在服务器端运行,需要时调用,执行速度快,方便使用
确保数据库的安全,存储过程可以完成所有的数据库操作
降低网络负载,客户端不必提交sql语句
可以接受用户参数,也可以返回参数
二、存储过程类型
系统存储过程 【名字以sp为前缀,存储在master库中】
本地存储过程 【存储在用户定义的数据库中】
扩展存储过程 【名字都已xp为前缀,储存在master库中】
临时存储过程 【名字以#开头的】
三、创建并调用存储过程
创建一个存储过程的语句:
delimiter $$ //这是定义一个结束符$$
create procedure [存储过程名称]([参数])
begin
......
end$$
delimiter ; //重新定义结束符为 ;
创建一个统计课程数量的存储过程:
create procedure count_course()
begin
select count(*) from course;
end$$
- delimiter 重新定义结束符号
调用count_course存储过程
call count_course$$
四、存储过程的变量
1、变量定义
使用declare声明变量
declare number1 int default 20;
一句declare只声明一个变量
作用域在begin…end范围中
变量具有与sql语句相同的数据类型和长度,还可以指定默认值与字符集和排序规则
变量使用set赋值,也可以使用select into赋值
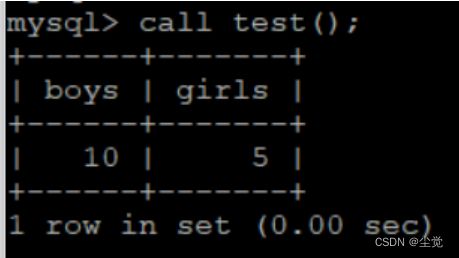
创建test()存储过程函数显示男和女的人数:
create procedure test()
begin
declare boys int(10);
declare girls int(10);
select count(*) into boys from student where Ssex='男';
select count(*) into girls from student where Ssex='女';
select boys,girls;
end$$
注意 在无参数的情况下返回变量值,可以用select语句
2、变量的作用域
- 一个函数可以有多个begin…end块,一个块里还可以嵌套多个begin…end块
- 在函数父作用块中定义的变量对所有子块可用
- 在单个begin…end块中,变量是局部变量,不能跨兄弟块使用
- 函数传入参数属于全局变量,可以在所有块中使用
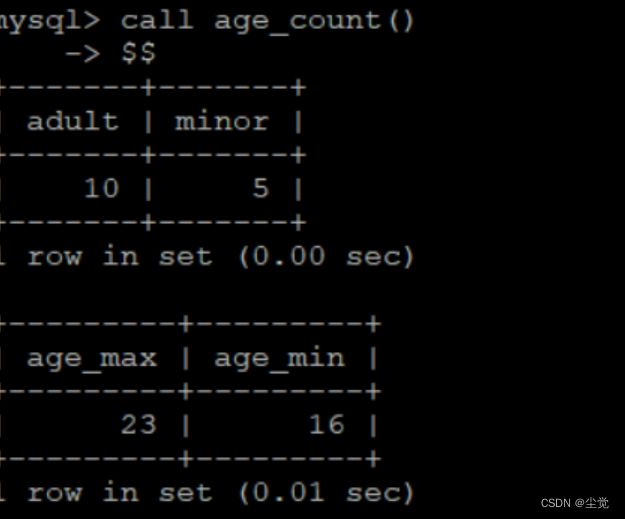
创建一个显示成年人和未成年人数量的表以及最大年龄和最小年龄的存储过程函数:
delimiter $$
create procedure age_count()
begin
begin
declare adult int;
declare minor int;
select count(*) into adult from student where Sage>=18;
select count(*) into minor from student where Sage<18;
select adult,minor;
end;
begin
declare age_max int;
declare age_min int;
select max(Sage) into age_max from student;
select min(Sage) into age_min from student;
select age_max,age_min;
end;
end$$
delimiter ;
- 在每个嵌套块的结尾end要加上 ; sql结尾符
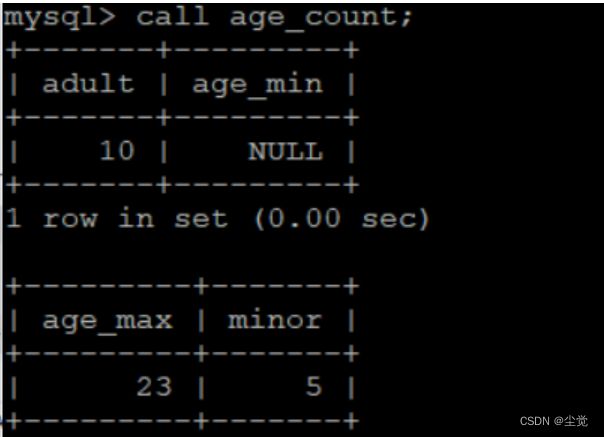
把变量提到父begin块后,变量可以在两个块之间交换使用
drop procedure age_count;
delimiter $$
create procedure age_count()
begin
declare adult int;
declare minor int;
declare age_max int;
declare age_min int;
begin
select count(*) into adult from student where Sage>=18;
select count(*) into minor from student where Sage<18;
select adult,age_min;
end;
begin
select max(Sage) into age_max from student;
select min(Sage) into age_min from student;
select age_max,minor;
end;
end$$
delimiter ;
五、存储过程参数
前面提到的函数都是没带参数的,只使用select返回结果集
函数可以带的参数分为:传入参数in 传出参数out 传入传出参数inout;
函数不指定参数类型的情况下,传进来的参数默认是in类型
drop procedure findname;
delimiter $$
create procedure findname(sno int)
begin
declare name varchar(10);
select Sname into name from student where Sno=sno limit 1;
select name;
end$$
delimiter ;

- 使用 select into 语句赋值的时候要确保该语句只返回一条结果,或者加上 limit 1 来限制返回结果的行数
- SQL变量名不能和列名一样
使用 out 类型的参数输出,结果应该与上题一致
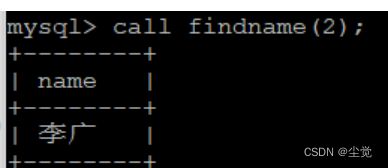
drop procedure findname;
delimiter $$
create procedure findname(in sno int,out sname varchar(10))
begin
select Sname into sname from student where Sno=sno limit 1;
end$$
delimiter ;
call findname(2,@name);
select * @name;
六、定义条件和定义处理的程序
定义条件:
事先定义好程序执行过程中可能遇到的问题
处理程序:
对已经定义好的问题作出相应处理,并保证存储函数在遇到警告或错误时能继续执行,避免程序异常停止工作
定义条件
declare [condition_name] condition for [错误码/错误值];
declare command_not_allowed condition for sqlstate '42000';//错误值
declare command_not_allowed condition for 42000;//错误码
处理程序
declare [handler_type] handler for [condition_name]
......
handler_type 错误处理方式
mysql提供了三个值
-
continue //不处理错误,存储函数继续往下执行
-
exit //遇到错误立即退出
-
undo //遇到错误撤销之前操作
condition_name 错误类型
condition_name 可以自定义错误类型,mysql也有自带的错误类型:
- sqlstate_value:包含5个字符的字符串错误值;
- condition_name:表示declare condition定义的错误条件名称;
- SQLWARNING:匹配所有以01开头的sqlstate错误代码;
- NOT FOUND:匹配所有以02开头的sqlstate错误代码;
- SQLEXCEPTION:匹配所有未被SQLWARNING或NOT FOUND捕获的sqlstate错误代码;
七、流程控制
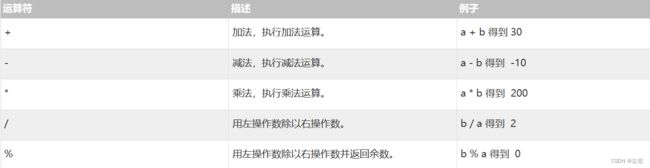
SQL 算术运算符
假设变量 a 的值是:10,变量 b 的值是:20,以下为各运算符执行结果:
SQL 比较运算符
假设变量 a 的值是:10,变量 b 的值是:20,以下为各运算符执行结果:

SQL 逻辑运算符:
这是在 SQL 所有的逻辑运算符的列表。

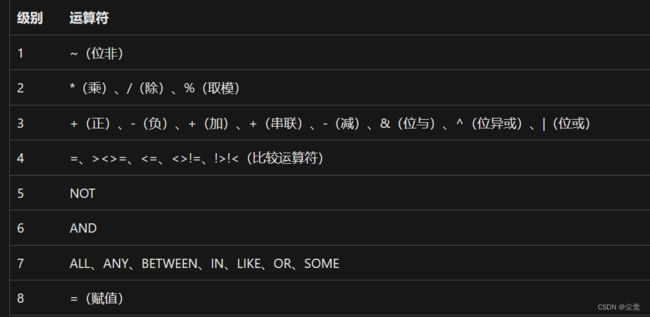
优先顺序
在较低级别的运算符之前先对较高级别的运算符进行求值。 在下表中,1 代表最高级别,8 代表最低级别。
条件语句
(1)if语句
基本结构:
单条件语句
begin
if(...)
then
......
else
......
end if;
end$$
多条件语句
begin
if(...)
then
......
elseif(...)
then
......
else
......
end if;
end$$
- if 语句需要有 end if 来结束 if 语句
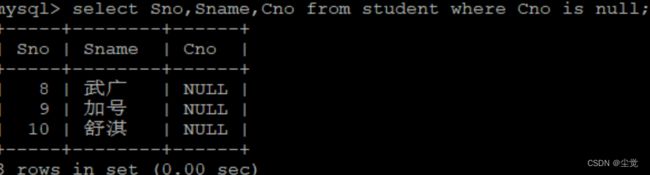
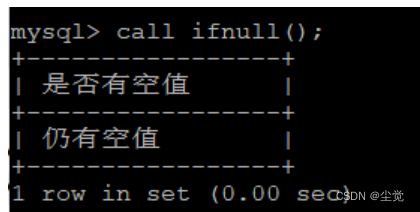
判断Cno是否有空值
delimiter $$
CREATE PROCEDURE ifnull()
begin
declare flag int;
select count(*) into flag from student where Cno is null;
if flag is null
then select '没有空值' as '是否有空值';
else select '仍有空值' as '是否有空值';
end if;
end
delimiter ;
(2)case语句
case语句可以计算多个条件式,并将其中一个符合条件的结果报答是返回
case [测试表达式]
when [测试值1] then [结果表达式1]
when [测试值2] then [结果表达式2]
when [测试值3] then [结果表达式3]
......
else [结果表达式0]
end
DROP PROCEDURE IF EXISTS testCase;
DELIMITER //
CREATE PROCEDURE testCase(OUT result VARCHAR(255))
BEGIN
DECLARE val VARCHAR(255);
SET val = 'a';
CASE val IS NULL
WHEN 1 THEN SET result = 'val is true';
WHEN 0 THEN SET result = 'val is false';
ELSE SELECT 'else';
END CASE;
END //
DELIMITER ;
set @result='';
CALL testCase(@result);
根据输入的课程名,添加一行课程类别
create procedure course_cate(cid varchar(10))
begin
update course set cate=
case(select cname from course where Cid=cid)
when '语文' then '文科'
when '数学' then '理科'
else 'x'
end case
end
循环语句
(3)while语句
基本结构:
begin
while([执行条件]) do
......
end while;
end;
新建一个Sscore列:
alter table student add Sscore int;
随机从1~100分插入成绩,输入参数i 作为需要修改成绩的人数,使用while循环一行行修改成绩
drop procedure add_math_score();
delimiter $$
create procedure add_math_score(i int)
begin
declare n int default 0;
declare score int default 0;
while(n<i) do
begin
set n=n+1;
set score=floor(100*rand());
select score ;
update student set Sscore=score where Sno=n;
end;
end while;
end$$
delimiter ;

- 修改前12人的成绩为随机数
(4)repeat UNTLL语句
REPEATE…UNTLL 语句的用法和 Java中的 do…while 语句类似,都是先执行循环操作,再判断条件,区别是REPEATE 表达式值为 false时才执行循环操作,直到表达式值为 true停止。
基本结构
begin
repeat
......
until [跳出条件]
end repeat;
end;
参照while的例子,结果相同
drop procedure add_math_score();
delimiter $$
create procedure add_math_score(i int)
begin
declare n int default 0;
declare score int default 0;
repeat
begin
set n=n+1;
set score=floor(100*rand());
select score ;
update student set Sscore=score where Sno=n;
end;
until n>=15
end repeat;
end$$
delimiter ;
- repeat 和 while 的区别在于两点,一是条件写的位置,while是在循环块的开头写循环条件,repeat是在结尾处写。
- 二是条件语句,while的条件语句是为真则执行,repeat是条件语句为真时跳出。
- repeat 的 until 哪一行不加分号;
-- 创建过程
DELIMITER $$
CREATE
PROCEDURE demo7(IN num INT,OUT SUM INT)
BEGIN
SET SUM = 0;
REPEAT-- 循环开始
SET num = num+1;
SET SUM = SUM+num ;
UNTIL num>=10
END REPEAT; -- 循环结束
END$$
DELIMITER;
CALL demo7(9,@sum);
SELECT @sum;
(5)loop语句
循环语句,用来重复执行某些语句。
执行过程中可使用 LEAVE语句或者ITEREATE来跳出循环,也可以嵌套IF等判断语句。
- LEAVE 语句效果对于Java中的break,用来终止循环;
- ITERATE 语句效果相当于Java中的continue,用来跳过此次循环。进入下一次循环。且ITERATE之下的语句将不在进行。
基本结构
begin
[循环名称]:loop
......
if [跳出条件] then leave [循环条件];
end if;
end loop [循环条件];
end
批量添加student表数据:
drop procedure add_data();
delimiter $$
create procedure add_data(i int)
begin
declare flag int default 0;
add_loop:loop
set flag=flag+1;
if flag>i then leave add_loop;
end if;
insert into student(Sname,Sno,Cno,Ssex,Sage,Sscore) values('批量人',flag+15,1002,'男',22,100);
end loop add_loop;
end
delimiter ;

DELIMITER $$
CREATE
PROCEDURE demo8(IN num INT,OUT SUM INT)
BEGIN
SET SUM = 0;
demo_sum:LOOP-- 循环开始
SET num = num+1;
IF num > 10 THEN
LEAVE demo_sum; -- 结束此次循环
ELSEIF num <= 9 THEN
ITERATE demo_sum; -- 跳过此次循环
END IF;
SET SUM = SUM+num;
END LOOP demo_sum; -- 循环结束
END$$
DELIMITER;
CALL demo8(0,@sum);
SELECT @sum;
使用存储过程插入信息
DELIMITER $$
CREATE
PROCEDURE demo9(IN s_student VARCHAR(10),IN s_sex CHAR(1),OUT s_result VARCHAR(20))
BEGIN
-- 声明一个变量 用来决定这个名字是否已经存在
DECLARE s_count INT DEFAULT 0;
-- 验证这么名字是否已经存在
SELECT COUNT(*) INTO s_count FROM student WHERE `name` = s_student;
IF s_count = 0 THEN
INSERT INTO student (`name`, sex) VALUES(s_student, s_sex);
SET s_result = '数据添加成功';
ELSE
SET s_result = '名字已存在,不能添加';
SELECT s_result;
END IF;
END$$
DELIMITER;
调用此函数
CALL demo9("Jim","女",@s_result);

八 存储过程的管理
显示存储过程
SHOW PROCEDURE STATUS

显示特定数据库的存储过程
SHOW PROCEDURE STATUS WHERE db = 'db名字' AND NAME = 'name名字';
显示特定模式的存储过程
SHOW PROCEDURE STATUS WHERE NAME LIKE '%mo%';

显示存储过程的源码
SHOW CREATE PROCEDURE 存储过程名;
![]()
删除存储过程
DROP PROCEDURE 存储过程名;
后端调用存储过程的实现
在mybatis当中,调用存储过程
<parameter property="name" jdbcType="VARCHAR" mode="IN"/>
<parameter property="sex" jdbcType="CHAR" mode="IN"/>
<parameter property="result" jdbcType="VARCHAR" mode="OUT"/>
parameterMap>
<insert id="saveUserDemo" parameterMap="savemap" statementType="CALLABLE">
{call saveuser(?, ?, ?)}
insert >
调用数据库管理
HashMap<String, Object> map = new HashMap<String, Object>();
map.put("name", "Jim");
map.put("sex","男");
userDao.saveUserDemo(map);
map.get(“result”);//获得输出参数
存储函数
函数
语法结构
CREATE FUNCTION存储函数名称(参数列表])
RETURNS type [characteristic ..]
BEGIN
-- SQL语句RETURN ...;
END ;
characteristic说明
- deterministic相同的输入参数产生相同的结果
- no sql 不包含sql语句
- READS SQL DATA 包含读取数据的语句 但不包含写入数据的语句
案例
- 定义存储函数,获取学生表中成绩大于95分的学生数量
/*
定义存储函数,获取学生表中成绩大于95分的学生数量
*/
DELIMITER $
CREATE FUNCTION fun_test1()
RETURNS INT
BEGIN
-- 定义统计变量
DECLARE result INT;
-- 查询成绩大于95分的学生数量,给统计变量赋值
SELECT COUNT(*) INTO result FROM student WHERE score > 95;
-- 返回统计结果
RETURN result;
END$
DELIMITER ;
-- 调用fun_test1存储函数
SELECT fun_test1();
-- 删除存储函数
DROP FUNCTION fun_test1;
- 计算从1累加到n的值,n为传入的参数值
create function fun1(n int)
returns int DETERMINISTIC
begin
declare total int default 0;
while n>0 do
set total := total + n;
set n := n - 1;
end while;
return total;
end;
select fun1(100);
- 删除函数
drop function 函数名;
存储过程和函数区别
- 存储过程用户在数据库中完成特定操作或者任务(如插入,删除等),函数用于返回特定的数据
- 存储过程声明用procedure,
- 存储过程不需要返回类型,函数必须要返回类型
- 存储过程可独立执行,函数不能作为独立的plsql执行,必须作为表达式的一部分
- 存储过程只能通过out和in/out来返回值,函数除了可以使用out,in/out以外,还可以使用return返回值
- sql语句(DML或SELECT)中不可用调用存储过程,而函数可以
应用场景不同
- 如果需要返回多个值和不返回值,就使用存储过程;如果只需要返回一个值,就使用函数
- 存储过程一般用于执行一个指定的动作,函数一般用于计算和返回一个值
- 可以再SQL内部调用函数来完成复杂的计算问题,但不能调用存储过程
返回值不同
存储函数必须有一个且必须只有一个返回值,并且还要指定返回值的数值类型。
存储过程可以有返回值,也可以没有返回值,甚至可以有多个返回值。
两者赋值的方式不同:
存储函数可以采用select …into …方式和set值得方式进行赋值,只能用return返回结果集。
存储过程可以使用select的方式进行返回结果集。
使用方法不同:
函数可以直接用在sql语句当中,可以用来拓展标准的sql语句。
存储过程,需要使用call进行单独调用,不可以嵌入sql语句当中。
函数中函数体的限制较多:
不能使用显式或隐式方式打开transaction、commit、rollback、set autocommit=0等。
但是存储过程可以使用几乎所有的sql语句。
存储过程和函数相同点
- 封装程序逻辑 完成数据处理操作
- 都是预编译 比直接写查询语句执行速度快
- 都可以带参数 以适应数据处理的需求
存储过程不需要返回类型,函数必须要返回类型 - 存储过程可独立执行,函数不能作为独立的plsql执行,必须作为表达式的一部分
- 存储过程只能通过out和in/out来返回值,函数除了可以使用out,in/out以外,还可以使用return返回值
- sql语句(DML或SELECT)中不可用调用存储过程,而函数可以
应用场景不同
- 如果需要返回多个值和不返回值,就使用存储过程;如果只需要返回一个值,就使用函数
- 存储过程一般用于执行一个指定的动作,函数一般用于计算和返回一个值
- 可以再SQL内部调用函数来完成复杂的计算问题,但不能调用存储过程
返回值不同
存储函数必须有一个且必须只有一个返回值,并且还要指定返回值的数值类型。
存储过程可以有返回值,也可以没有返回值,甚至可以有多个返回值。
两者赋值的方式不同:
存储函数可以采用select …into …方式和set值得方式进行赋值,只能用return返回结果集。
存储过程可以使用select的方式进行返回结果集。
使用方法不同:
函数可以直接用在sql语句当中,可以用来拓展标准的sql语句。
存储过程,需要使用call进行单独调用,不可以嵌入sql语句当中。
函数中函数体的限制较多:
不能使用显式或隐式方式打开transaction、commit、rollback、set autocommit=0等。
但是存储过程可以使用几乎所有的sql语句。
存储过程和函数相同点
- 封装程序逻辑 完成数据处理操作
- 都是预编译 比直接写查询语句执行速度快
- 都可以带参数 以适应数据处理的需求
本章笔记是在网上找的资料 以及自己的理解总结出来的笔记希望可以帮助大家,感谢大家的耐心观看 如有错误请即使联系我 我会及时修正