6.验证面试高频问题整理(附答案)
目录
Q126.top-down phase、bottom-up phase有哪些
Q127.为什么build_phase是top-down phase,connect_phase是bottom-up phase
Q128.$size用于packed array和unpacked array分别得到的什么
Q129.class和struct的异同
Q130.class和module的异同
Q131.对象创建的初始化顺序
Q132.子类和父类中是否可以定义相同名称的成员变量和方法(非虚方法)
Q133.为什么需要随机
Q134.线程间通信控制共享资源的原因是什么
Q135.uvm_transaction和uvm_seq_item的关系
Q136.p_sequencer是什么?
Q137.m_sequencer是什么?
Q138.new()和create有什么区别
Q139.如何启动sequence
Q140.copy和clone的区别
Q141.Agent中的Active mode和Passive mode区别
Q412.在UVM的工厂机制中,为什么要使用注册机制
Q143.简述UVM的工厂机制
Q144.UVM中的RAL什么,可以用来干什么?
Q145.简述系统级、子系统级和模块级验证
Q146.IP和VIP分别指的是什么
Q147.set_config_*和uvm_config_db区别
Q148.$stop、$finish和final如何使用
Q149.简述virtual sequence和virtual sequencer作用
Q150.简述code review的重要性
Q126.top-down phase、bottom-up phase有哪些
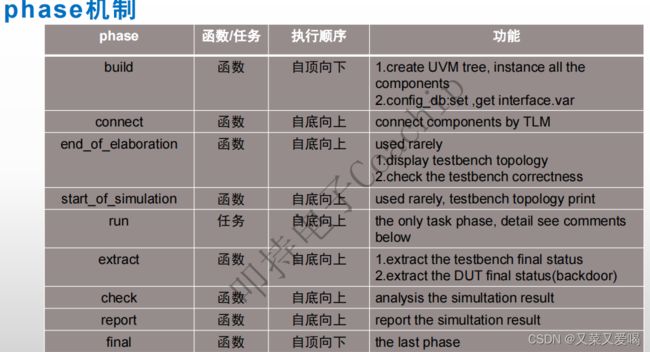
Q127.为什么build_phase是top-down phase,connect_phase是bottom-up phase
build_phase需要验证平台根据高层次组件的配置来决定建立低层次的组件,所以其是top-down phase。
connect_phase需要在build_phase之后完成验证组件之间TLM连接
Q128.$size用于packed array和unpacked array分别得到的什么
得到的是高维度的array size。

Q129.class和struct的异同
二者都可以定义数据成员
类变量在声明之后,需要构造函数才构建对象实体,class在声明变量时已经开辟内存
类不仅可以声明数据变量成员,而且可以声明方法,这是struct做不到的
从根本上说,struct是一种数据结构,而class包含数据成员以及针对这些成员的操作方法
Q130.class和module的异同
数据和方法定义方面:两者都使用相同的模板来创建实例,都可以作为封闭的容器来存储数据和方法。
例化方面:module例化是静态的,在编译链接时就完成;而SV中class的例化是动态的,可以在仿真的任何阶段声明并动态创建新的对象,这也使类的例化方式更加灵活而节省空间。
封装性方面:模块内的变量和方法对外部都是开放的,而类可以根据需要来确定外部访问的权限:pubilc,protected,local
继承性方面:模块没有继承性而言
Q131.对象创建的初始化顺序
(1)给对象分配内存。
(2)将对象的实例变量自动初始化为其变量类型的默认值。
(3)初始化对象,给实例变量赋予正确的初始值。
Q132.子类和父类中是否可以定义相同名称的成员变量和方法(非虚方法)
可以;
当父类的句柄执行子类的对象时,调用父类的方法时,默认只输出父类的内容,因为父类未声明虚方法,所以不会进一步调用子类的方法输出重写的部分。
Q133.为什么需要随机
验证的目的是通过大量的测试激励去验证DUT功能的完备性,如果只是依靠定向测试,这样的工作量的很大的,而且定向测试可能会遗漏掉某些验证场景,所以我们在验证中一般都会采用随机的方法,随机出感兴趣的验证激励,通过不断更换随机种子,对某一验证场景进行充分验证,以保证验证的完备性。
Q134.线程间通信控制共享资源的原因是什么
在uvm中,对线程通信的资源都会放到一个资源池中,该资源池作为一个全局变量可以供验证需要,完成线程间的通信。
Q135.uvm_transaction和uvm_seq_item的关系
uvm_transaction是从uvm_object派生的用于对事务进行建模的基类。
sequence item是在uvm_transaction的基础上还添加了一些其他信息的类,例如:sequence id。建议使用uvm_sequence_item实现基于sequence的激励。
Q136.p_sequencer是什么?
p_sequencer 通常需要通过在定义sequence时声明`uvm_declare_p_sequencer(SQR),间接定义p_sequencer成员变量,m_sequencer和p_sequencer均指向同一挂载的sequencer句柄,只是前者是父类句柄,后者是子类句柄。
Q137.m_sequencer是什么?
m_sequencer 是sequence或sequence_item 的成员变量,即sequence/item一旦挂载到某个sequencer上,那么该sequencer的句柄就被赋值为m_sequencer
(uvm_sequencer_base类)。
Q138.new()和create有什么区别
UVM推荐使用内置方法type_name::type_id::create(),而不是直接调用构造函数new()创建组件或事务对象。
create方法在内部调用factory机制以查找所请求创建的类型,然后调用构造函数new()以实际创建一个对象而无需更改任何代码。
Q139.如何启动sequence
启动sequence需要执行三个步骤,如下所示:
创建一个序列。使用工厂创建方法创建一个序列:
my_sequence_c seq;
seq = my_sequence_c ::type_id :: create(“ my_seq”)
配置或随机化序列。
seq.randomize()
开始一个sequence。使用sequence.start()方法启动序列。start方法需要输入一个指向sequencer的参数。关于sequence的启动,UVM进一步做了封装。还可以通过default_sequence自动启动,uvm_config_db#(uvm_object_wrapper):: set (this,sequencer.main_phase,default_sequence,sequence::type_id::get())
Q140.copy和clone的区别
create()方法用于构造一个对象。
copy()方法用于将一个对象复制到另一个对象。
clone()方法同时完成对象的创建和复制。
Q141.Agent中的Active mode和Passive mode区别
ACTIVE agent是可以在其操作的接口上生成激励,其包含driver和sequencer。
PASSIVE agent不生成激励,只能监视接口,这意味着在PASSIVE agent中将不会创建driver和sequencer。
Q412.在UVM的工厂机制中,为什么要使用注册机制
只有先将类进行注册,在利用工厂方法创建之后才可以应用工厂机制提供的方法对已经实例化的类以及已经注册的类型进行覆盖。
Q143.简述UVM的工厂机制
Factory机制也叫工厂机制,其存在的意义就是为了能够方便的替换TB中的实例或者已注册的类型。一般而言,在搭建完TB后,我们如果需要对TB进行更改配置或者相关的类信息,我们可以通过使用factory 机制进行覆盖,达到替换的效果,从而大大提高TB的可重用性和灵活性。要使用factory机制先要进行:
1.将类注册到factory表中
2.创建对象,使用对应的语句 (type_id::create)
3.编写相应的类对基类进行覆盖。
Q144.UVM中的RAL什么,可以用来干什么?
UVM RAL(寄存器抽象层)**是UVM支持的功能,有助于使用抽象寄存器模型来验证设计中的寄存器以及DUT的配置。UVM寄存器模型寄存器抽象模型反映了寄存器设计的结构规范,提供了一种跟踪DUT寄存器内容和位置的方式。这是硬件和软件工程师的共同参考。RAL的其他一些功能包括支持寄存器的front door和backdoor初始化以及内置的功能覆盖率支持。
Q145.简述系统级、子系统级和模块级验证
模块验证:侧重点在模块本身功能的验证,验证计划的重点是feature和验证架构,然后列出testcase,模块能够覆盖的绝不到下一级验证去覆盖。主要内容有:检查参数设置、寄存器读写、协议检查、中断和复位、状态机跳转、工作模式覆盖、RAM的读写功能边界等等。
子系统验证:侧重点在系统的互联性,更加关注系统的工作模式和复杂场景应用。主要内容有:中断的产生、DMA功能、IP的模式功能、Memory读写等等。
系统验证:侧重点在软硬件协同仿真,关键系统路径的覆盖,芯片工作模式和测试模式以及数据通路和性能等。主要内容有:基本IP功能、CLK/RESET、IO MUX 、多个IP同时工作、程序的启动、工作模式和应用场景测试。
Q146.IP和VIP分别指的是什么
数字 IC 验证领域的 IP 指的是 Intellectual Property(IP) core,VIP 指的是verificati on Intellectual Property(IP) core
Q147.set_config_*和uvm_config_db区别
set_config_*可以映射到相应的uvm_ config_db:
set_config_int(…)=>uvm_config_db#(uvm_bit_stream_t) :: set(cntxt, …)
set_config_string(…)>uvm_config_db#(string) :: set(cntxt,…)
set_config_object (…)>uvm_config_db#(uvm_object) :: set(cntxt,…)
Q148.$stop、$finish和final如何使用
$stop(), 函数触发,仿真会停止,但是还可以继续restart;
$finish(),函数触发,仿真会停止,不可以继续restart;
final 类似于initial,只执行一次,不同的是final在仿真结束时执行。
Q149.简述virtual sequence和virtual sequencer作用
virtual sequence是一个包含和执行多个子sequence的容器,virtual sequencer是包含其他sequencer的容器以使得virtual sequence中的每个子sequence都能在相应的sequencer上获得执行。
Q150.简述code review的重要性
- 提高代码质量
- 提前发现bug
- 统一代码规范
- 提高团队成员代码技能
前期找问题(代码规范、潜在缺陷、BUG,代码设计等等),后期演变成开发者技术交流和员工成长