【IC设计】基于Verilog的8层矩阵乘法设计
文章目录
-
- 项目要求
-
- 基本要求
- 截断要求
-
- 低位截断
- 高位饱和
- 参考结果
- 项目实现
-
- 实现思路
- 实现代码
-
- matrix_multiplier_16.v
- tb_mm_mlp.v
- VCS&Verdi综合前仿真
- dc综合
- VCS&Verdi综合后仿真
- 不足之处
项目要求
基本要求
输入有9个矩阵,权重矩阵有8个,分别是Weight I0~I7,Input矩阵I -1。
8个矩阵都是都是16行*16列的,且矩阵中的每个元素是16位补码形式的有符号定点数(1位符号位,6位整数位,9位小数位)
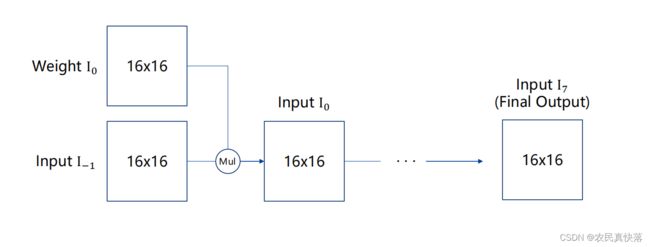
要求将Weight I0依次乘以Input I-1 ,Weight I1 ,Weight I2 ,Weight I3 ,Weight I4, Weight I5, Weight I6 , Weight I7,依次得到Input I0 ,Input I1 ,Input I2 ,Input I3 ,Input I4 ,Input I5 ,Input I6 ,Input I7
最终输出Input I7
截断要求
对于矩阵AB=C,C矩阵的第i行第j列元素是A的第i行和B的第j列进行乘加运算得到的,
由于矩阵的元素是16位,两个16位元素相乘结果需要用216-1=31位表示,再考虑相加,因此需要31+4=35位来表示。
在这个项目中不考虑相加后会超过31位的情况,只用31位表示。
对于Weight I0 * Input I-1=Input I0,Input I0中的每个元素都是31位的,有1位符号位,18位小数,12位整数,要求截断为16位再作为下一层的输入。

A[15:0]*B[15:0]=C_31[30:0] 要将C_31[30:0]转为C_16[15:0]需要考虑低位截断和高位饱和操作:
低位截断
低位C_31[8:0]截断,要考虑C_31[8]的四舍五入,
如果符号位为0,则向前进1,
如果符号位为1,直接截断。
这个操作的正确性证明如下:

高位饱和
C[15:9]能表示的范围在[-64:63],如果C_31[30:24]超过该范围,产生上/下溢,C_16[14:9]则取能表示的最大/最小值
如果符号位为0,C_31[29:24]存在1则上溢,
如果符号位为1,C_31[29:24]存在0则下溢。
参考结果
这里给出第一层和最后一层(第八层)的输出作为参考,需要注意的是矩阵AB和BA结果是不同的,这里第一层的结果是Weight I0在左边乘以Input -1 ,得到的Input 0


项目实现
实现思路
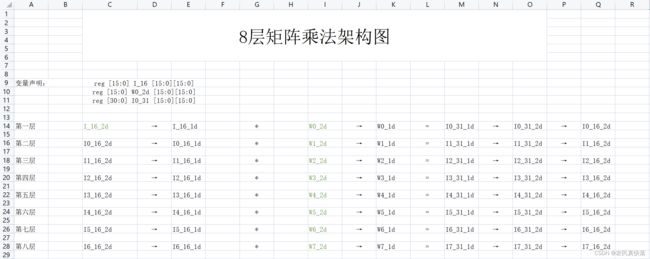
如图所示,其中标记绿色的是调用$readmemh从文件中直接读取的,项目实现思路如下:
-
首先,使用$readmemh从文件中读取
Weight I0,Input I-1 ,Weight I1 ,Weight I2 ,Weight I3 ,Weight I4, Weight I5, Weight I6 , Weight I7,
存储到对应的二维数组中,然后将这些二维数组转为一维数组(因为Verilog模块的端口不能使用多维数组)。 -
接着,实例化第一个16*16的模块matrix_multiplier_16,输入I_16_1d和W0_2d,得到相乘的结果I0_31_1d,将其转为二维矩阵I0_31_2d,然后按照截断要求转为I0_16_2d
-
下面,反复实例化matrix_multiplier_16,每次将上一层计算结果和对应的Weight矩阵作为输入,得到相乘的结果,最终结果是第八层的输出I7_16_2d。
实现代码
matrix_multiplier_16.v
`timescale 1ns / 1ps
//输入端口A矩阵,B矩阵是16行16列,每个元素16位有符号定点数(1位符号位,6位整数位,9位小数位)
//输出端口Result矩阵是A*B的结果,是16行16列,每个元素是31位有符号定点数(1位符号位,12位整数位,18位小数位)
//Verilog模块的端口只能是一维数组,所以每次调用该模块要保证输入的矩阵已经被转化成了一维长数组
module matrix_multiplier_16(A,B,Result);
input [16*16*16-1:0] A;
input [16*16*16-1:0] B;
output [16*16*31-1:0] Result;
reg [16*16*31-1:0] reg_result;
reg signed [15:0] A1[0:15][0:15];
reg signed [15:0] B1[0:15][0:15];
reg signed [30:0] Res1[0:15][0:15];
integer i,j,k;
always@(A or B) begin
//在模块内将一维转二维,方便计算
for(i=0;i<16;i=i+1) begin
for(j=0;j<16;j=j+1) begin
A1[i][j]=A[i*16*16+j*16+:16];
B1[i][j]=B[i*16*16+j*16+:16];
end
end
//初始化结果为0
for(i=0;i<16;i=i+1) begin
for(j=0;j<16;j=j+1) begin
Res1[i][j]=31'd0;
end
end
//使用矩阵相乘的定义计算Res1矩阵的结果
//Res1[i][j]是A的第i行和B的第j列相乘再相加的结果
for(i=0;i<16;i=i+1)begin
for(j=0;j<16;j=j+1)begin
for(k=0;k<16;k=k+1)begin
//A1[i][k]和B1[k][j]都是补码形式的有符号定点数
//A[补码]*B[补码]=(A*B)[补码]
Res1[i][j]=Res1[i][j]+A1[i][k]*B1[k][j];
end
end
end
//将二维转回一维,将Res1[0][0]存储在reg_result的最高位,Res[i][j]前面有i*16+j个数据,每个31位,因此转为1维的索引是
//16*16*31-1-(i*16+j)*31
//这里涉及到一个语法:A[7:3]和A[7-:4]是等价的 同理A[0+:3]和A[0:2]等价
for(i=0;i<16;i=i+1)begin
for(j=0;j<16;j=j+1)begin
//When 2d converted to 1d,it is stored from high bit to low bit.
reg_result[16*16*31-1-((i*16+j)*31) -: 31]=Res1[i][j];
end
end
end
assign Result=reg_result;
endmodule
tb_mm_mlp.v
命名为tb_mm_mlp是因为mm是matrix multiplier,mlp是多层感知机,深度学习中多层感知机的计算实际上就是矩阵乘法加激活函数。
`timescale 1ns/1ps
`define FILE_INPUT 1
`define PRINT_A_B_OUTPUT 1
module tb_mm_mlp();
reg signed [15:0] I_16_2d[0:15][0:15];
reg [16*16*16-1:0] I_16_1d;
reg signed [15:0] I0_16_2d[0:15][0:15];
reg signed [15:0] I1_16_2d[0:15][0:15];
reg signed [15:0] I2_16_2d[0:15][0:15];
reg signed [15:0] I3_16_2d[0:15][0:15];
reg signed [15:0] I4_16_2d[0:15][0:15];
reg signed [15:0] I5_16_2d[0:15][0:15];
reg signed [15:0] I6_16_2d[0:15][0:15];
reg signed [15:0] I7_16_2d[0:15][0:15];
reg [16*16*16-1:0] I0_16_1d;
reg [16*16*16-1:0] I1_16_1d;
reg [16*16*16-1:0] I2_16_1d;
reg [16*16*16-1:0] I3_16_1d;
reg [16*16*16-1:0] I4_16_1d;
reg [16*16*16-1:0] I5_16_1d;
reg [16*16*16-1:0] I6_16_1d;
reg [16*16*16-1:0] I7_16_1d;
reg signed [15:0] W0_2d[0:15][0:15];
reg signed [15:0] W1_2d[0:15][0:15];
reg signed [15:0] W2_2d[0:15][0:15];
reg signed [15:0] W3_2d[0:15][0:15];
reg signed [15:0] W4_2d[0:15][0:15];
reg signed [15:0] W5_2d[0:15][0:15];
reg signed [15:0] W6_2d[0:15][0:15];
reg signed [15:0] W7_2d[0:15][0:15];
reg [16*16*16-1:0] W0_1d;
reg [16*16*16-1:0] W1_1d;
reg [16*16*16-1:0] W2_1d;
reg [16*16*16-1:0] W3_1d;
reg [16*16*16-1:0] W4_1d;
reg [16*16*16-1:0] W5_1d;
reg [16*16*16-1:0] W6_1d;
reg [16*16*16-1:0] W7_1d;
reg signed [30:0] I0_31_2d[0:15][0:15];
reg signed [30:0] I1_31_2d[0:15][0:15];
reg signed [30:0] I2_31_2d[0:15][0:15];
reg signed [30:0] I3_31_2d[0:15][0:15];
reg signed [30:0] I4_31_2d[0:15][0:15];
reg signed [30:0] I5_31_2d[0:15][0:15];
reg signed [30:0] I6_31_2d[0:15][0:15];
reg signed [30:0] I7_31_2d[0:15][0:15];
wire [31*16*16-1:0] I0_31_1d;
wire [31*16*16-1:0] I1_31_1d;
wire [31*16*16-1:0] I2_31_1d;
wire [31*16*16-1:0] I3_31_1d;
wire [31*16*16-1:0] I4_31_1d;
wire [31*16*16-1:0] I5_31_1d;
wire [31*16*16-1:0] I6_31_1d;
wire [31*16*16-1:0] I7_31_1d;
integer i,j,k;
matrix_multiplier_16 DUT1(.A(W0_1d), .B(I_16_1d), .Result(I0_31_1d));
matrix_multiplier_16 DUT2(.A(W1_1d), .B(I0_16_1d), .Result(I1_31_1d));
matrix_multiplier_16 DUT3(.A(W2_1d), .B(I1_16_1d), .Result(I2_31_1d));
matrix_multiplier_16 DUT4(.A(W3_1d), .B(I2_16_1d), .Result(I3_31_1d));
matrix_multiplier_16 DUT5(.A(W4_1d), .B(I3_16_1d), .Result(I4_31_1d));
matrix_multiplier_16 DUT6(.A(W5_1d), .B(I4_16_1d), .Result(I5_31_1d));
matrix_multiplier_16 DUT7(.A(W6_1d), .B(I5_16_1d), .Result(I6_31_1d));
matrix_multiplier_16 DUT8(.A(W7_1d), .B(I6_16_1d), .Result(I7_31_1d));
initial begin
$display("Start read mem I-1,W0,W1...W7");
$fsdbDumpfile("mm_mlp.fsdb");
$fsdbDumpMDA();
$readmemb("I.mem",I_16_2d);
$readmemb("W0.mem",W0_2d);
$readmemb("W1.mem",W1_2d);
$readmemb("W2.mem",W2_2d);
$readmemb("W3.mem",W3_2d);
$readmemb("W4.mem",W4_2d);
$readmemb("W5.mem",W5_2d);
$readmemb("W6.mem",W6_2d);
$readmemb("W7.mem",W7_2d);
//2d to 1d
for(i=0;i<16;i=i+1) begin
for(j=0;j<16;j=j+1) begin
I_16_1d[i*16*16+j*16+:16]=I_16_2d[i][j];
W0_1d[i*16*16+j*16+:16]=W0_2d[i][j];
W1_1d[i*16*16+j*16+:16]=W1_2d[i][j];
W2_1d[i*16*16+j*16+:16]=W2_2d[i][j];
W3_1d[i*16*16+j*16+:16]=W3_2d[i][j];
W4_1d[i*16*16+j*16+:16]=W4_2d[i][j];
W5_1d[i*16*16+j*16+:16]=W5_2d[i][j];
W6_1d[i*16*16+j*16+:16]=W6_2d[i][j];
W7_1d[i*16*16+j*16+:16]=W7_2d[i][j];
I0_16_2d[i][j]=16'b0;
I1_16_2d[i][j]=16'b0;
I2_16_2d[i][j]=16'b0;
I3_16_2d[i][j]=16'b0;
I4_16_2d[i][j]=16'b0;
I5_16_2d[i][j]=16'b0;
I6_16_2d[i][j]=16'b0;
I7_16_2d[i][j]=16'b0;
end
end
#20
for(i=0;i<16;i=i+1)begin
for(j=0;j<16;j=j+1)begin
I0_31_2d[i][j]=I0_31_1d[16*16*31-1-((i*16+j)*31) -: 31];
//截断处理:
//1.1先赋值符号位
I0_16_2d[i][j][15]=I0_31_2d[i][j][30];
//1.2考虑低位截断(含有四舍五入)
if(I0_31_2d[i][j][8]==1'b1)begin
I0_31_2d[i][j][29:9]=I0_31_2d[i][j][29:9]+1;
end
//1.3考虑高位饱和(上溢、下溢、截断)
if(I0_31_2d[i][j][30]==1'b0&&I0_31_2d[i][j][29:18]>=64) begin
I0_16_2d[i][j][14:9]=6'b111_111;
end else if(I0_31_2d[i][j][30]==1'b1&&I0_31_2d[i][j][29:24]!=63)begin
I0_16_2d[i][j][14:9]=6'b000_000;
end else begin
I0_16_2d[i][j][14:0]=I0_31_2d[i][j][23:9];
end
end
end
for(i=0;i<16;i=i+1) begin
for(j=0;j<16;j=j+1) begin
I0_16_1d[i*16*16+j*16+:16]=I0_16_2d[i][j];
end
end
#20
//I1截断处理
for(i=0;i<16;i=i+1)begin
for(j=0;j<16;j=j+1)begin
I1_31_2d[i][j]=I1_31_1d[16*16*31-1-((i*16+j)*31) -: 31];
//先赋值符号位
I1_16_2d[i][j][15]=I1_31_2d[i][j][30];
//考虑截断(含有四舍五入)
//这里其实只考虑了为1时向前进位,但实际上符号位为1时是不用进位的,原理见前面的低位截断分析
if(I1_31_2d[i][j][8]==1'b1)begin
I1_31_2d[i][j][29:9]=I1_31_2d[i][j][29:9]+1;
end
//再考虑饱和(上溢、下溢和截断)
if(I1_31_2d[i][j][30]==1'b0&&I1_31_2d[i][j][29:18]>=64) begin
I1_16_2d[i][j][14:9]=6'b111_111;
end else if(I1_31_2d[i][j][30]==1'b1&&I1_31_2d[i][j][29:24]!=63)begin
I1_16_2d[i][j][14:9]=6'b000_000;
end else begin
I1_16_2d[i][j][14:0]=I1_31_2d[i][j][23:9];
end
end
end
for(i=0;i<16;i=i+1) begin
for(j=0;j<16;j=j+1) begin
I1_16_1d[i*16*16+j*16+:16]=I1_16_2d[i][j];
end
end
#20
//I2截断处理
for(i=0;i<16;i=i+1)begin
for(j=0;j<16;j=j+1)begin
I2_31_2d[i][j]=I2_31_1d[16*16*31-1-((i*16+j)*31) -: 31];
//先赋值符号位
I2_16_2d[i][j][15]=I2_31_2d[i][j][30];
//考虑截断(含有四舍五入)
if(I2_31_2d[i][j][8]==1'b1)begin
I2_31_2d[i][j][29:9]=I2_31_2d[i][j][29:9]+1;
end
//再考虑饱和(上溢、下溢和截断)
if(I2_31_2d[i][j][30]==1'b0&&I2_31_2d[i][j][29:18]>=64) begin
I2_16_2d[i][j][14:9]=6'b111_111;
end else if(I2_31_2d[i][j][30]==1'b1&&I2_31_2d[i][j][29:24]!=63)begin
I2_16_2d[i][j][14:9]=6'b000_000;
end else begin
I2_16_2d[i][j][14:0]=I2_31_2d[i][j][23:9];
end
end
end
for(i=0;i<16;i=i+1) begin
for(j=0;j<16;j=j+1) begin
I2_16_1d[i*16*16+j*16+:16]=I2_16_2d[i][j];
end
end
#20
//I3截断处理
for(i=0;i<16;i=i+1)begin
for(j=0;j<16;j=j+1)begin
I3_31_2d[i][j]=I3_31_1d[16*16*31-1-((i*16+j)*31) -: 31];
//先赋值符号位
I3_16_2d[i][j][15]=I3_31_2d[i][j][30];
//考虑截断(含有四舍五入)
if(I3_31_2d[i][j][8]==1'b1)begin
I3_31_2d[i][j][29:9]=I3_31_2d[i][j][29:9]+1;
end
//再考虑饱和(上溢、下溢和截断)
if(I3_31_2d[i][j][30]==1'b0&&I3_31_2d[i][j][29:18]>=64) begin
I3_16_2d[i][j][14:9]=6'b111_111;
end else if(I3_31_2d[i][j][30]==1'b1&&I3_31_2d[i][j][29:24]!=63)begin
I3_16_2d[i][j][14:9]=6'b000_000;
end else begin
I3_16_2d[i][j][14:0]=I3_31_2d[i][j][23:9];
end
end
end
for(i=0;i<16;i=i+1) begin
for(j=0;j<16;j=j+1) begin
I3_16_1d[i*16*16+j*16+:16]=I3_16_2d[i][j];
end
end
#20
//I4截断处理
for(i=0;i<16;i=i+1)begin
for(j=0;j<16;j=j+1)begin
I4_31_2d[i][j]=I4_31_1d[16*16*31-1-((i*16+j)*31) -: 31];
//先赋值符号位
I4_16_2d[i][j][15]=I4_31_2d[i][j][30];
//考虑截断(含有四舍五入)
if(I4_31_2d[i][j][8]==1'b1)begin
I4_31_2d[i][j][29:9]=I4_31_2d[i][j][29:9]+1;
end
//再考虑饱和(上溢、下溢和截断)
if(I4_31_2d[i][j][30]==1'b0&&I4_31_2d[i][j][29:18]>=64) begin
I4_16_2d[i][j][14:9]=6'b111_111;
end else if(I4_31_2d[i][j][30]==1'b1&&I4_31_2d[i][j][29:24]!=63)begin
I4_16_2d[i][j][14:9]=6'b000_000;
end else begin
I4_16_2d[i][j][14:0]=I4_31_2d[i][j][23:9];
end
end
end
for(i=0;i<16;i=i+1) begin
for(j=0;j<16;j=j+1) begin
I4_16_1d[i*16*16+j*16+:16]=I4_16_2d[i][j];
end
end
#20
//I5截断处理
for(i=0;i<16;i=i+1)begin
for(j=0;j<16;j=j+1)begin
I5_31_2d[i][j]=I5_31_1d[16*16*31-1-((i*16+j)*31) -: 31];
//先赋值符号位
I5_16_2d[i][j][15]=I5_31_2d[i][j][30];
//考虑截断(含有四舍五入)
if(I5_31_2d[i][j][8]==1'b1)begin
I5_31_2d[i][j][29:9]=I5_31_2d[i][j][29:9]+1;
end
//再考虑饱和(上溢、下溢和截断)
if(I5_31_2d[i][j][30]==1'b0&&I5_31_2d[i][j][29:18]>=64) begin
I5_16_2d[i][j][14:9]=6'b111_111;
end else if(I5_31_2d[i][j][30]==1'b1&&I5_31_2d[i][j][29:24]!=63)begin
I5_16_2d[i][j][14:9]=6'b000_000;
end else begin
I5_16_2d[i][j][14:0]=I5_31_2d[i][j][23:9];
end
end
end
for(i=0;i<16;i=i+1) begin
for(j=0;j<16;j=j+1) begin
I5_16_1d[i*16*16+j*16+:16]=I5_16_2d[i][j];
end
end
#20
//I6截断处理
for(i=0;i<16;i=i+1)begin
for(j=0;j<16;j=j+1)begin
I6_31_2d[i][j]=I6_31_1d[16*16*31-1-((i*16+j)*31) -: 31];
//先赋值符号位
I6_16_2d[i][j][15]=I6_31_2d[i][j][30];
//考虑截断(含有四舍五入)
if(I6_31_2d[i][j][8]==1'b1)begin
I6_31_2d[i][j][29:9]=I6_31_2d[i][j][29:9]+1;
end
//再考虑饱和(上溢、下溢和截断)
if(I6_31_2d[i][j][30]==1'b0&&I6_31_2d[i][j][29:18]>=64) begin
I6_16_2d[i][j][14:9]=6'b111_111;
end else if(I6_31_2d[i][j][30]==1'b1&&I6_31_2d[i][j][29:24]!=63)begin
I6_16_2d[i][j][14:9]=6'b000_000;
end else begin
I6_16_2d[i][j][14:0]=I6_31_2d[i][j][23:9];
end
end
end
for(i=0;i<16;i=i+1) begin
for(j=0;j<16;j=j+1) begin
I6_16_1d[i*16*16+j*16+:16]=I6_16_2d[i][j];
end
end
#20
//I7截断处理
for(i=0;i<16;i=i+1)begin
for(j=0;j<16;j=j+1)begin
I7_31_2d[i][j]=I7_31_1d[16*16*31-1-((i*16+j)*31) -: 31];
//先赋值符号位
I7_16_2d[i][j][15]=I7_31_2d[i][j][30];
//考虑截断(含有四舍五入)
if(I7_31_2d[i][j][8]==1'b1)begin
I7_31_2d[i][j][29:9]=I7_31_2d[i][j][29:9]+1;
end
//再考虑饱和(上溢、下溢和截断)
if(I7_31_2d[i][j][30]==1'b0&&I7_31_2d[i][j][29:18]>=64) begin
I7_16_2d[i][j][14:9]=6'b111_111;
end else if(I7_31_2d[i][j][30]==1'b1&&I7_31_2d[i][j][29:24]!=63)begin
I7_16_2d[i][j][14:9]=6'b000_000;
end else begin
I7_16_2d[i][j][14:0]=I7_31_2d[i][j][23:9];
end
end
end
#20
for(i=0;i<16;i=i+1) begin
for(j=0;j<16;j=j+1) begin
I7_16_1d[i*16*16+j*16+:16]=I7_16_2d[i][j];
end
end
#400
$finish;
end
endmodule
VCS&Verdi综合前仿真
综合前仿真是仿真自己写的RTL代码,步骤如下:
- 创建filelist.f文件,写入要编译的模块:
./matrix_multiplier_16.v
./tb_mm_mlp.v
- 使用vcs编译
vcs -full64 -fgp -y ./ic_lab/sim_ver +libext+.v -timescale=1ns/1ps -file ./filelist.f -kdb -fsdb -debug_access+all +lint=TFIPC +neg_tchk -negdelay -v ./ic_lab/data/PDK/verilog/*.v
- 使用verdi查看波形
verdi -ssf mm_mlp.fsdb
可以看到输出和参考结果的图一致

参考结果:
dc综合
dc_shell
set my_lib_path "./ic_lab/data/PDK/synopsys/ ./ic_lab/data/PDK/symbol/"
set search_path "$search_path $my_lib_path"
set design_dw_lib ./ic_lab/dw_foundation.sldb
set_app_var target_library "ih55lp_hs_rvt_tt_1p20_25c_basic.db"
set_app_var link_library "* ih55lp_hs_rvt_tt_1p20_25c_basic.db $design_dw_lib"
set_app_var synthetic_library "ih55lp_hs_rvt_tt_1p20_25c_basic.db $design_dw_lib"
set_app_var symbol_library "IH55LP_HS_RVT.sdb"
read_verilog ./matrix_multiplier_16.v
//这里可以添加一些时钟、时延控制,但我这个程序中没有写时钟信号,就不加了
set_max_area 0
compile
report_constraint -all_violators
report_area
write −format verilog −output ./matrix_multiplier_16_nelist.v
write_sdf ./matrix_multipleir_16.sdf
write −format verilog −output ./matrix_multiplier_16_nelist.v执行结果:
注意只编译这一个模块,就不要加hierarchy,因为hierarchy是层次化的意思,会自顶向下找其他模块,只编译一个模块加这个参数会报错。

write_sdf ./matrix_multiplier_16.sdf执行结果:

VCS&Verdi综合后仿真
综合后仿真是仿真dc综合出来的网表文件
- 原先写编译文件路径的filelist.f改为
./matrix_multiplier_netlist.v
./tb_mm_mlp.v
- 使用vcs编译
vcs -full64 -fgp -y ./ic_lab/sim_ver +libext+.v -timescale=1ns/1ps -file ./filelist.f -kdb -fsdb -debug_access+all +lint=TFIPC +neg_tchk -negdelay -v ./ic_lab/data/PDK/verilog/*.v
后方跑完截图

- 使用verdi查看波形
verdi -ssf mm_mlp.fsdb
不足之处
-
在实现矩阵乘法的过程中,没有使用sram,没有使用优化算法,如booth
encoding,加法树等进行优化,只是暴力实现了矩阵乘法。编译了几个小时才出结果,跑个后仿消耗了4.8G内存,有亿点离谱。 -
没有任何时钟和控制信号