【深蓝学院】手写VIO第3章--基于优化的 IMU 与视觉信息融合--作业
0. 题目

1. T1
T1.1 绘制阻尼因子曲线
将尝试次数和lambda保存为csv,绘制成曲线如下图
iter, lambda
1, 0.002000
2, 0.008000
3, 0.064000
4, 1.024000
5, 32.768000
6, 2097.152000
7, 699.050667
8, 1398.101333
9, 5592.405333
10, 1864.135111
11, 1242.756741
12, 414.252247
13, 138.084082
14, 46.028027
15, 15.342676
16, 5.114225
17, 1.704742
18, 0.568247
19, 0.378832
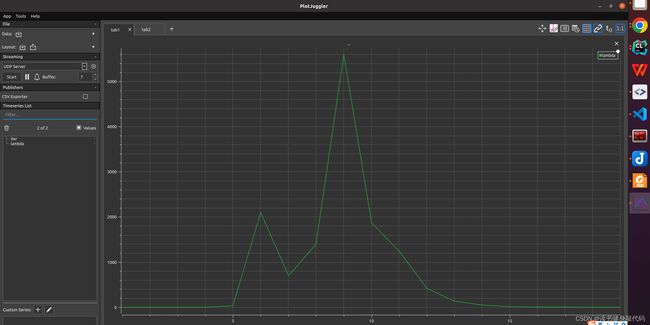
发现起始时刻的 μ \mu μ较小,步长 Δ x \Delta x Δx较大,导致cost上升,并未收敛,根据Nielsen策略,迅速调大 μ \mu μ,在求解 H Δ X = b H \Delta X=b HΔX=b时减小步长,不断迭代,在迭代过程中逐渐减小 μ \mu μ以增大步长加快收敛速度,满足优化终止条件之后停止优化(本题停止条件之一是误差下降超过1e6倍则停止优化)。
T1.2 更改目标函数
3处修改:
- 修改函数:

- 修改residual

- 修改Jocabian

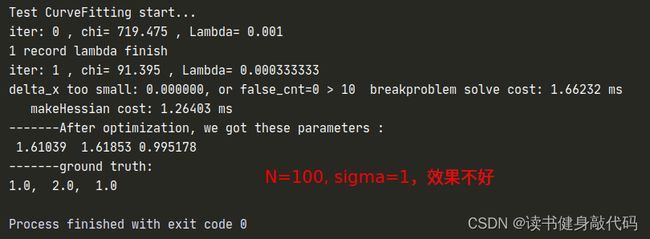
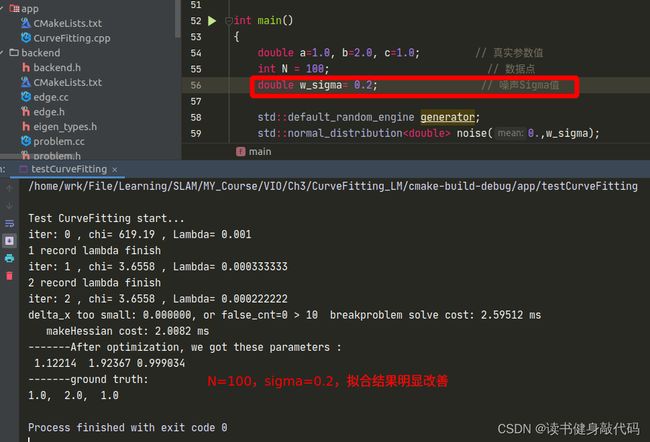
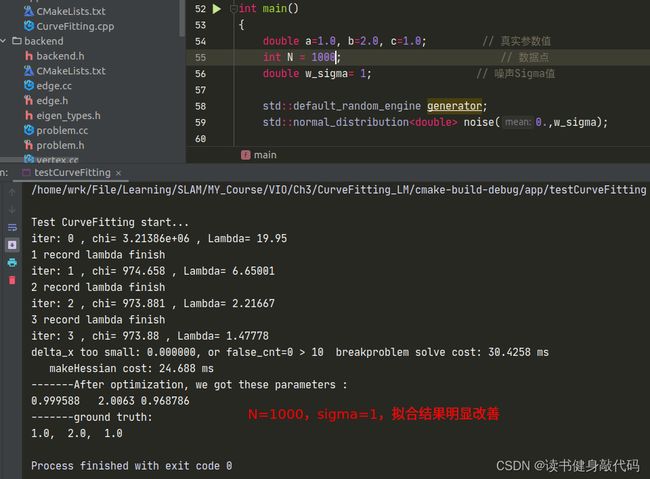
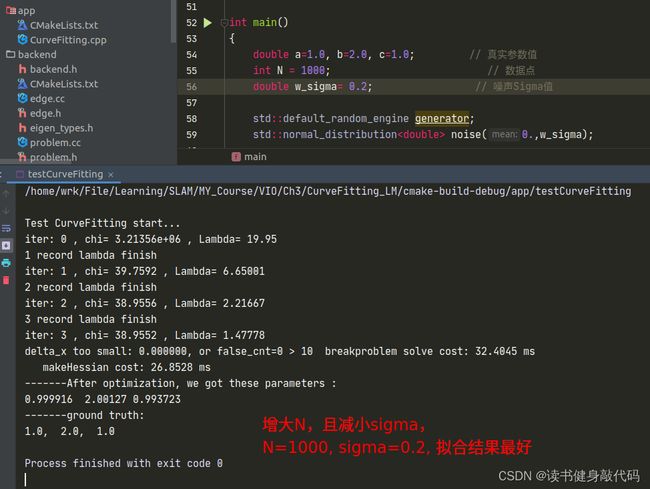
但是修改完之后发现拟合效果并不好,原观测数据服从 N ( 0 , 1 ) N(0,1) N(0,1)的正态分布,但是从 e x p ( a x 2 + b x + c ) exp(ax^2+bx+c) exp(ax2+bx+c)修改为 a x 2 + b x + c ax^2+bx+c ax2+bx+c之后, σ = 1 \sigma=1 σ=1显得有些大了(这个应该能从exp和二次函数的曲线分析出来,x正半轴二次函数比exp上升更快,真值相对于噪声观测值的误差也变得越大),所以要想获得更好的曲线拟合效果:1. 增加数据量;2. 减小噪声的variance以下是一些对比:
T1.3 不同的LM阻尼因子μ设置策略
参考论文 Henri Gavin. “The Levenberg-Marquardt method for nonlinear least squares curve-fitting problems”. In:Department of Civil and Environmental Engineering, Duke University (2011), pp. 1–15. 的4.1.1节:

使用T1.2中的N=1000, σ = 0.2 \sigma=0.2 σ=0.2的参数进行实验。
1.3.1 策略3
第三种方法显然是Nelsion的设置方法,

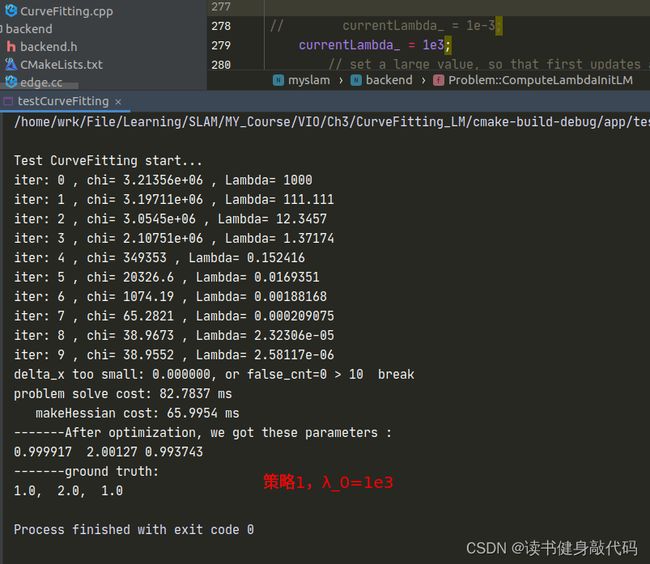
1.3.2 策略1
函数ComputeLambdaInitLM()
currentLambda_ = 1e-3; //选择不同的初值来实验
// currentLambda_ = 1e3;
// set a large value, so that first updates are small steps in the steepest-descent direction
增减 λ \lambda λ:
void Problem::AddLambdatoHessianLM() {
ulong size = Hessian_.cols();
assert(Hessian_.rows() == Hessian_.cols() && "Hessian is not square");
for (ulong i = 0; i < size; ++i) {
// Hessian_(i, i) += currentLambda_;
Hessian_(i, i) += currentLambda_ * Hessian_(i, i); //理解: H(k+1) = H(k) + λ H(k) = (1+λ) H(k)
}
}
void Problem::RemoveLambdaHessianLM() {
ulong size = Hessian_.cols();
assert(Hessian_.rows() == Hessian_.cols() && "Hessian is not square");
// TODO:: 这里不应该减去一个,数值的反复加减容易造成数值精度出问题?而应该保存叠加lambda前的值,在这里直接赋值
for (ulong i = 0; i < size; ++i) {
// Hessian_(i, i) -= currentLambda_;
Hessian_(i, i) /= 1.0 + currentLambda_;//H回退: H(k) = 1/(1+λ) * H(k+1)
}
}
判断 λ \lambda λ是否好:
bool Problem::IsGoodStepInLM() {
// 统计所有的残差
double tempChi = 0.0;
for (auto edge: edges_) {
edge.second->ComputeResidual();
tempChi += edge.second->Chi2();//计算cost
}
assert(Hessian_.rows() == Hessian_.cols() && "Hessian is not square");
ulong size = Hessian_.cols();
MatXX diag_hessian(MatXX::Zero(size, size));
for(ulong i = 0; i < size; ++i) {
diag_hessian(i, i) = Hessian_(i, i);
}
double scale = delta_x_.transpose() * (currentLambda_ * diag_hessian * delta_x_ + b_);//scale就是rho的分母
double rho = (currentChi_ - tempChi) / scale;//计算rho
// update currentLambda_
double epsilon = 0.75;
double L_down = 9.0;
double L_up = 11.0;
if(rho > epsilon && isfinite(tempChi)) {
currentLambda_ = std::max(currentLambda_ / L_down, 1e-7);
currentChi_ = tempChi;
return true;
} else {
currentLambda_ = std::min(currentLambda_ * L_up, 1e7);
return false;
}
}

以上对比实验参考:https://note.youdao.com/ynoteshare/index.html?id=15a9ff86fedeb41d92f182e5cb3bace7&type=notebook&_time=1686390423162#/WEBbbb1c7ce04945f67a58c304455a56eda
但是得到了相反的结果,所以其结论我认为并不完全可信。而且原文中的时间相差并不大,不能说明什么问题,这只能说明lambda初值的设置对于收敛速度是有影响的。
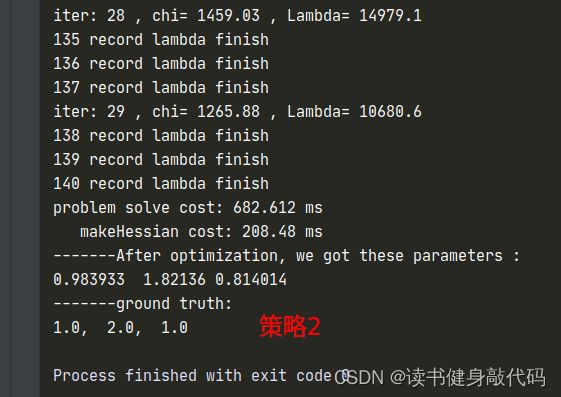
1.3.2 策略2
λ , Δ x , ρ \lambda, \Delta x,\rho λ,Δx,ρ计算同初值设置同策略3
只是计算cost时需要考虑 Δ x \Delta x Δx的系数,需要重新计算临时的cost,在满足更新x的条件之后在更新 α \alpha α和 x x x,自己实现了一版,但是这个运行时间让我感觉是有些问题的,放上代码和 λ \lambda λ的曲线,如果有大佬实现出来了告诉我一下~:
整个problem.cc文件
#include 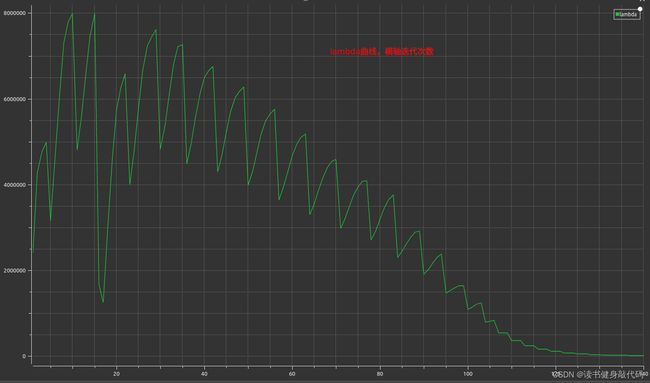
2. 推导公式
2.2 f 15 f_{15} f15
同样地, α b i b k + 1 \alpha_{b_ib_{k+1}} αbibk+1将a带入之后也只与下图的红色部分有关

于是剩下的为:(其实不明白为什么最后有的项还会有 ω \omega ω)
其中令 ϕ = ω δ t , δ ϕ = − δ b k g δ t \phi=\omega\delta t,\delta\phi=-\delta b_k^g\delta t ϕ=ωδt,δϕ=−δbkgδt很关键,并用了下述公式:

2.2 g 12 g_{12} g12
所以刚才的疑问,为什么有的会有 ω \omega ω,那是在那一项将 ω \omega ω展开之后也跟被导量无关的时候才会不展开 ω \omega ω,比如 f 22 f_{22} f22中, ω \omega ω的展开量对角度 θ \theta θ是无关的,所以可以保留 ω \omega ω。
2.3 推导总结
针对被导量,将分母展开,取与被导量有关的项进行求导,无关的都扔掉,比如大多数导数都对 n k g , n k a n_k^g,n_k^a nkg,nka无关,所以有时候干脆不写,直接扔掉了,但是像2.2节中的与n_k^g有关,所以就反而只与 n k g n_k^g nkg有关,把握这个原则就能推出其它。
3. T3
式(9)来源:


图片来自(不想去水印了):博客
数学基础太差,有些看不懂怎么把前面系数项移到右边的。
助教给的答案也看不太懂:

本章完。