An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion (Paper reading)
Rinon Gal, Tel-Aviv University, Israel, arXiv2022, Cited:182, Paper, Code
1. 前言
文本到图像的模型为通过自然语言引导创作提供了前所未有的自由。然而,目前尚不清楚如何利用这种自由度来生成特定独特概念的图像,修改它们的外观,或将它们组合到新的角色和新颖场景中。换句话说,我们要问:如何利用语言引导的模型将我们的猫变成一幅画,或根据我们最喜欢的玩具想象出一种新产品?在这里,我们提出了一种简单的方法,可以实现这种创造性的自由。我们仅使用用户提供的概念(如物体或风格)的3-5张图像,通过冻结的文本到图像模型的嵌入空间中的新“词”来学习表示它。这些“词”可以组合成自然语言句子,以直观的方式引导个性化创作。值得注意的是,我们发现单个词嵌入足以捕捉到独特而多样的概念。我们将我们的方法与各种基线进行比较,并证明在各种应用和任务中,它可以更忠实地描绘这些概念。
2. 整体思想
和Dreambooth很相似,将特定的主题整合到文本prompt中的特定word。训练模型,让模型理解这个特定的word。
3. 方法
在电影《泰坦尼克号》的一个著名场景中,罗斯向杰克提出了一个请求:“……像你的法国女孩一样画我。”尽管简单,这个请求包含了丰富的信息。它表明杰克应该画一幅画;它暗示着它的风格和构图应该与杰克以前的作品的某个子集相匹配;最后,通过一个词“我”,罗斯表明这幅画应该描绘一个特定的、独特的主题:罗斯本人。在提出请求时,罗斯依赖于杰克推理这些概念——既广泛又具体——并将它们融入到新的创作中。
我们提出在预训练的文本到图像模型的文本嵌入空间中找到新的词。我们考虑文本编码过程的第一阶段(图2)。在这里,输入字符串首先被转换为一组标记。然后,每个标记被替换为其自己的嵌入向量,并且这些向量被馈送到下游模型。我们的目标是找到代表新的、特定概念的新嵌入向量。
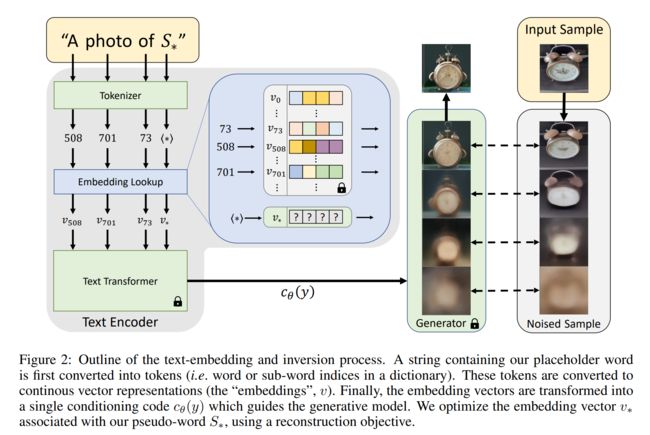
我们用一个新的伪词(pseudo-word)表示一个新的嵌入向量,我们用 S ∗ S_∗ S∗表示。然后,这个伪词被当作其他单词一样对待,可以用来组成生成模型的新文本查询。因此,你可以要求“ S ∗ S_∗ S∗在海滩上的照片”,“ S ∗ S_∗ S∗挂在墙上的油画”,甚至组合两个概念,比如“以 S ∗ 1 S^1_∗ S∗1的风格画 S ∗ 2 S^2_∗ S∗2”。重要的是,这个过程不会改变生成模型。通过这样做,我们保留了在将视觉和语言模型微调到新任务时通常会丢失的丰富文本理解和泛化能力。为了找到这些伪词,我们将任务定为反演的一种形式。我们有一个固定的、预训练的文本到图像模型和一个包含该概念的小型(3-5张)图像集。我们的目标是找到一个单词嵌入向量,使得形式为“一张 S ∗ S_∗ S∗的照片”的句子能够重建我们小型图像集中的图像。这个嵌入向量是通过一个我们称之为“文本反演”的优化过程找到的。
文本嵌入:典型的文本编码模型,例如BERT,首先进行文本处理步骤(图2,左侧)。首先,输入字符串中的每个单词或子单词被转换为一个标记,该标记是预定义字典中的索引。然后,每个标记与一个唯一的嵌入向量相关联,可以通过基于索引的查找来检索。这些嵌入向量通常作为文本编码器 c θ c_θ cθ的一部分进行学习。在我们的工作中,我们选择这个嵌入空间作为反演的目标。具体来说,我们指定一个占位符字符串 S ∗ S_∗ S∗来表示我们希望学习的新概念。我们干预嵌入过程,用一个新的学习到的嵌入向量 v ∗ v_∗ v∗替换与标记化字符串相关联的向量,实质上是将该概念“注入”到我们的词汇中。通过这样做,我们可以像使用任何其他单词一样组成包含该概念的新句子。
文本反演: 为了找到这些新的嵌入向量,我们使用一个包含目标概念的小型图像集合(通常为3-5张),这些图像在多个不同的环境中展示了目标概念,例如不同的背景或姿势。我们通过直接优化来找到 v ∗ v_∗ v∗,即通过对从小型图像集合中采样的图像的LDM损失最小化。为了对生成进行条件设置,我们随机采样中立的上下文文本,这些文本来源于CLIP ImageNet模板。这些模板包含形式为“A photo of S∗”、“A rendition of S∗”等的提示语。
实现细节:除非另有说明,我们保留了LDM的原始超参数选择。词嵌入向量使用对象的单词粗略描述符的嵌入进行初始化(例如,图1中的两个概念的粗略描述符为“sculpture”和“cat”)。我们的实验使用了2个V100 GPU,并且批量大小为4。基本学习率设置为0.005。在LDM之后,我们根据GPU的数量和批量大小进一步缩放基本学习率,使得有效学习率为0.04。所有的结果是在进行了5,000个优化步骤后得出的。我们发现这些参数对大多数情况都有效。然而,我们注意到对于某些概念,可以通过减少步骤数或增加学习率来获得更好的结果。
4. 实验
我们首先展示了使用单个伪词来捕捉和重新创建物体的不同变化。在图3中,我们将我们的方法与两个基准方法进行了比较:由人类标题引导的LDM和由人类标题或图像提示引导的DALLE-2。我们使用Mechanical Turk收集了标题。参与者被提供了四张概念的图像,并被要求以一种让艺术家能够重新创建它的方式进行描述。我们要求提供一个简短(≤ 12个单词)和一个长(≤ 30个单词)的标题。总共,我们收集了每个概念的10个标题,其中五个是简短的,五个是长的。图3展示了使用随机选择的标题进行每种设置的多个结果。
正如我们的结果所展示的,我们的方法更好地捕捉了概念的独特细节。人类的标题通常能够捕捉到物体最显著的特征,但提供的细节不足以重新构建细微的特征,例如茶壶的颜色图案。在某些情况下(例如骷髅杯),通过自然语言描述对象本身可能非常困难。当提供了一张图像时,DALLE-2能够重新创建出更吸引人的样本,特别是对于细节有限的众所周知的物体(如阿拉丁的神灯)。然而,它在独特的个性化对象的细节方面仍然存在困难,因为图像编码器(CLIP)可能没有见过这些细节(如杯子、茶壶)。相反,我们的方法可以成功地捕捉到这些更精细的细节,并且只使用了一个单词的嵌入。然而,需要注意的是,虽然我们的创作更接近于源物体,但它们仍然是可能与源物体不同的变化。
在图1和图3中,我们展示了通过将学习到的伪词融入到新的条件文本中来组合新场景的能力。对于每个概念,我们展示了训练集中的示例,以及生成的图像和它们的条件文本。正如我们的结果所展示的,冻结的文本到图像模型能够同时对新概念和其大量的先前知识进行推理,将它们结合在一个新的创作中。重要的是,尽管我们的训练目标是生成性的,我们的伪词仍然包含了模型可以利用的语义概念。