NTIRE 2022 Challenge on Stereo Image Super-Resolution比赛报告解读
NTIRE 2022 Challenge on Stereo Image Super-Resolution: Methods and Results
0. 简介
NTIRE 的全称为New Trends in Image Restoration and Enhancement Challenges,即“图像复原和增强挑战中的新趋势”,是CVPR(IEEE Conference on Computer Vision and Pattern Recognition)举办的极具影响力的计算机视觉底层任务比赛,主要涉及的研究方向有:图像超分辨率、图像去噪、去模糊、去摩尔纹、重建和去雾等。
其中在2022年,CVPR开展的NTIRE相关挑战有:
- 光谱恢复(spectral recovery);
- 光谱去马赛克(spectral demosaicing);
- 感知图像质量评估(perceptual image quality assessment);
- 修复(inpainting);
- 夜间摄影渲染(night photography rendering);
- 高效超分辨率(efficient super-resolution);
- 学习超分辨率空间(learning the super-resolution space);
- 压缩视频的超分辨率和视频增强(super-resolution and quality enhancement of compression video);
- 高范围动态(high dynamic range);
- 双目超分辨率(stereo super-resolution);
- 真实世界超分辨率(burst super resolution)。
同时,以上的这些挑战也蕴含着当前的一些研究难点及挑战,需要研究学者们集思广益,提出针对提升任务性能的想法,为共同解决近年来的难题贡献出一份力量。
本篇文章着重于NTIRE 2022双目超分辨率(stereo super-resolution)挑战赛的参赛者们解决方案的解读,总结报告中能够提升任务的tricks,以期给相关的科研任务一些启发。
1. 摘要
在NTIRE 2022 Challenge on Stereo Image Super-Resolution比赛报告中,回顾了举办的第一届双目超分辨率的解决方案和结果。双目超分辨率是通过输入两张存在视差的低分辨率图片(可以认为分别是左眼和右眼看到的同样一个场景的图片),然后对其进行超分辨率重建,希望能够恢复大量的细节。
与单张图像超分辨率相比,双目超分辨率能够获取的信息更多,但是如何利用好存在视差的左右图像的信息,是提升双目超分辨率重建质量的关键。此次的双目超分辨率挑战只有一个赛道,即只有一个目标,那就是着重于对标准的双三次退化的左右图像进行双目超分辨率重建。
据统计,一共有238位参与者成功注册比赛,21只队伍完成了最后测试阶段的提交。其中,一共有20只队伍提交结果的PSNR(RGB)超过了baseline(比赛设定的基线模型)。最后,此次挑战为双目超分辨率建立了一个新的benchmark(标准)。
2. 引言
双目图像对可以将 3D 场景线索编码为左右图像之间的立体对应关系。随着双目相机在移动手机,自动驾驶和机器人领域的流行,双目视觉在学术界和工业界越来越受关注。近年来,深度学习技术使得图像超分辨率(super-resolution, SR)不断进步,现有的方法大都专注于单张图像超分。然而,这些方法(单张图像超分)不能充分利用双目图像的跨视角信息。最近,基于CNN的视频超分方法利用时序信息和多帧图像来在统一的网络中完成光流估计和超分。然而,由于视差比感受野大得多,这些方法展示出的性能极为有限。
双目超分辨率旨在从给定的低分辨率(low-resolution, LR)图像对中重建高分辨率(high-resolution, HR)的双目图像对。由于基线、焦距、深度和分辨率的不同,双目图像的视差会存在很大的差异,因此将双目相关的信息应用在双目图像超分非常具有挑战性。
2022年,主办方(国防科技大学等)举办第一届双目单张图像超分比赛,以Flick 1024作为数据集,并使用标准的双三次下采样进行图像退化操作。
3. 相关工作
相关工作中回顾了一些主流的单幅图像超分和双目图像超分领域的方法。
3.1 单幅图像超分
- Dong等人提出了第一个基于CNN的超分方法——SRCNN。
- Kim等人提出了一个更深(20层)的网络来提高超分性能——VDSR。
- Lim等人使用局部和残差连接,提出了EDSR。
- Zhang等人将残差连接和密集连接结合起来,提出了残差密集网络——RDN。
- Li等人为了充分利用图像不同尺度的特征,提出了一个多尺度残差网络——MSRN。
- Transformer最近广泛应用于计算机视觉,Liang等人使用Swin Transformer进行图像复原,并设计了SwinIR网络来达到图像超分的SOTA性能。
- Lu等人提出了一个高效超分Transformer——ESRT,可以减少GPU的内存占用。
3.2 双目图像超分
单幅图像超分通常只有该图像内的上下文信息可以利用的。而双目图像超分可以借助第二幅图像提供的辅助信息(交叉视图信息)来提高超分的性能,然而实际情况中,同一个物体会被投影到双目图像对的不同位置,这会阻碍交叉视图信息的充分利用。
- Jeon等人通过联合训练两个级联的子网络来学习视差先验,提出了StereoSR网络。
- Wang等人提出了一个视差注意力模块——PAM,来用全局感受野来建模双目对应关系。他们提出的PASSRnet超分效果比StereoSR更好,应对视差的变化也更为灵活。
- Ying等人在视差注意力机制的基础上,提出了双目注意力模块,并将其嵌入到预训练好的超分网络中进行超分。
- Song等人结合自注意力和视差注意力,提出了SPAMnet。
- Yan等人提出了域自适应双目超分网络——DASSR,首先使用预训练的双目匹配网络来估计视差,视图被变换到另一边来包含交叉视图信息。
- Xu等人将双边网格处理的思想结合到 CNN 框架中,并提出了一个双边双目超分网络。
- Wang等人将PAM修改成双向且对称的,提出了一个改进版本的PASSRnet——iPASSR,来解决一系列超分遇到的实际问题(如光照变化和遮挡等)。
- Dai等人提出了一个反馈网络,以递归方式交替解决视差估计和双目图像超分问题。
- Ma等人提出了一个基于GAN的面向感知的双目图像超分网络,可以生成一些逼真的、符合双目一致性的细节。
- Xu等人通过同时地使用交叉视野和时序信息,解决了双目视频超分的问题。
4. NTIRE 2022 Challenge
4.1 数据集
本次比赛使用Flickr 1024数据集。Flickr 1024数据集有1024对RGB图像对,其中800对用于训练,112对用于验证,剩下112对用于测试。Flickr 1024是人工采集的高质量图像数据集,内容多样、细节丰富。本次比赛中,我们依旧使用Flickr1024用于训练和验证,但是测试是使用收集的另外100张LR双目图像对(为了保证比赛公平性,groundtruth HR图像不公开)。
4.2 赛道和比赛
赛道:双三次退化。使用标准的双三次退化(Matlab的默认参数的imresize函数)将训练集、验证集和测试集中的HR图像制作成LR双目图像。
比赛阶段
- 开发阶段:将提供Flickr 1024数据集中的训练集(LR-HR图像对)和验证集(LR图像)。参赛者可以将超分后的验证集提交到系统,能够获得较快的评分反馈,这有利于测试方法是否有效。同时,也会有关于验证集提交分数的排行榜,供参赛者了解分数情况。
- 测试阶段:将提供测试集的LR图像给参赛者,参赛者需要在截止日期前提交超分后的测试集图像,源代码和方法的详细说明。在比赛的尾声阶段,将会向参赛者展示最后的结果。
评价指标
评价指标为PSNR和SSIM,这些指标将会分别在RGB通道和Y通道上计算。最终将所有图像计算的指标平均起来。注意:最终排名的依据是在RGB通道上计算的PSNR指标。
5. 比赛结果
一共有238名参赛者注册,21只队伍成功完成最后的测试阶段,并提交了他们的结果、代码和方法说明。下表展示了比赛最后的结果,以及各个队伍的排名,20只队伍的PSNR(RGB)超过了baseline。

-
网络结构和主要的ideas
全部队伍都使用了深度学习技术,有16只队伍使用了Transformer(尤其是SwinIR)作为基本架构。为了利用到交叉视野信息,14只队伍使用了视差注意力机制(PAM)来获取双目对应关系。
-
复原保真度
排名前2的队伍几乎达到了近乎相同的PSNR指标(只相差0.08dB)。第6名的队伍也只比第1名队伍的PSNR值低0.21dB。
-
数据增强
大部分队伍都使用了数据增强的技术,比如随机翻转等。此外,随机水平平移、随机RGB通道打乱、Cutblur等也是一些提升性能的数据增强手段。
-
集成和融合
一些队伍也使用集成(Ensembles)策略(包括数据集成和模型集成)来提升超分模型最后的性能。数据集成方面,输入图像会被翻转,超分的结果对齐原来的输入(所谓的对齐,就是超分结果翻转回去,因为这样才能够跟正常的超分结果进行加权平均),通过平均操作获得更好的结果。
比赛结论
- 参赛者们提出的方法刷新了双目图像超分的SOTA。
- Transformer在双目图像超分任务上愈发流行,获得的性能提升超过了CNN。
- 蕴含在视差中的交叉视野信息对于双目视觉超分任务非常关键,能够帮助模型获得更好的性能。
- 受益于一系列的tricks(包括精细的数据增强策略),一些单幅图像超分也能够取得优秀的结果。
6. 各个队伍的方法介绍
6.1 第一名:The Fat, The Thin and The Young Team
这支队伍提出了NAFNet用于图像复原,通过使用NAFnet的模块用于特征提取,他们通过引入交叉注意力模块获得交叉视野信息,将NAFNet扩展到了NAFSSR,用于进行图像超分。更多的细节可以参考《Nafssr: Stereo image super-resolution using nafnet》这篇论文。
如下图,NAFSSR有两个共享权重的分支,用来分别处理左视图和右视图。同时,左右分支之间也插入了几个注意力模块,用来交互交叉视野信息。与biPAM类似,注意力模块计算沿着水平极线的特征相关性,然后通过执行相关性操作融合这些特征。

除了网络设计外,一些高效的tricks也被用于提升超分性能。在训练阶段的数据增强技巧有:随即裁剪、随机水平或垂直翻转、随机平移和随机RGB通道打乱(random RGB channel shuffling)。在测试阶段,使用了4个模型进行集成,也采用了测试时数据增强(test-time augmentation)策略,包括水平、垂直翻转,RGB通道打乱。同时,他们也使用了左右视图交换的技巧。
这支队伍解决了训练/测试阶段不一致的问题,即训练阶段使用图像块,而测试阶段用的是整张图像。使用local-SE模块能够带来0.1dB的PSNR提升。此外,stochastic depth strategy和skip-init strategy能够用来解决过拟合问题,并且加速训练。
6.2 第二名:The BigoSR Team
这支队伍结合Swin Transformer和视差注意力机制(parallax attention mechanism),提出了SwiniPASSR网络。为了使用LR图像对的交叉视野信息,他们在网络中使用了biPAM。如下图所示,SwiniPASSR包含三部分:特征提取、交叉视野交互和重构。基于类似SwinIR的框架,使用了biPAM模块插入到连续的RSTB块中,通过建模交叉视野信息来解决遮挡和边界问题。为了保持语义结构和基于卷积的biPAM模块的一致性,在biPAM前使用了layer normalization和patch unembedding模块。
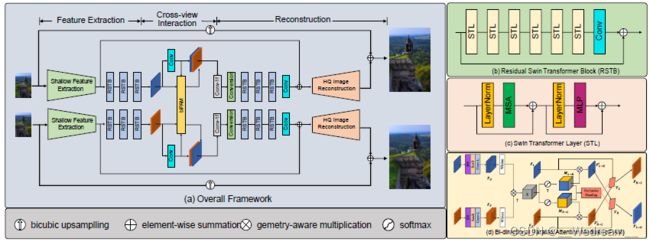
在训练阶段,为了加快对双目对应关系(stereo correspondence)的学习,他们使用了多阶段的训练策略。在第一个阶段,双目图像对被拆分为单一的图像,使用基于Swin Transformer的网络来训练单张图像超分。在这一阶段,网络试图学习图像的结构信息,建模局部空间联系。在第二阶段,使用biPAM模块插在RSTBs的中间,来建模双目图像对的双目对应关系。在第三阶段,输入的图像块尺寸从 24 × 24 24\times24 24×24放大到 48 × 48 48\times48 48×48,来帮助biPAM大范围地集成交叉视野信息。在最后一个阶段,stereo loss在总体损失函数的比重扩大10倍,在微调中鼓励网络更关注于交叉视野信息。
6.3 第三名:The NUDTCV&CPLab Team
受SwinIR的启发,这支队伍提出了SSRFormer来处理双目图像超分,其网络结构如下图所示。SSRFormer采用孪生网络结构,拥有两个共享权重的分支。首先,四个RSTBs块来提取深度特征。其次,受到视差注意力机制的启发,使用基于注意力的特征匹配模块(anttention-based feature matching, AFM)来提取丰富的跨视野信息,而无需显式地对齐左图和右图。
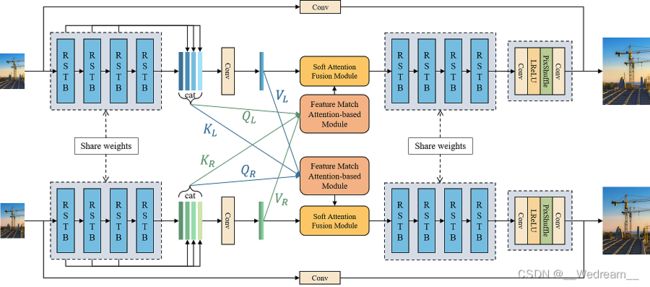
在训练阶段,使用800对双目图像作为训练集。HR图像随机裁剪为 192 × 192 192\times192 192×192的图块,LR图像也进行相应的裁剪。使用随机翻转作为数据增强的手段。SSRFormer首先在两张2080ti显卡上训练300k次迭代,batch size为8,使用的损失函数为L1损失。接着,模型进一步在四张2080ti显卡上训练了124k次迭代,使用的batchsize为16。在这期间,前60k次迭代使用了L1损失,剩余的迭代使用的是L2损失。初始的学习率为 2 × 1 0 − 4 2\times10^{-4} 2×10−4,并在250k、300k、375k、400k时学习率减半。
6.4 第四名:The BUPTPRIV Team
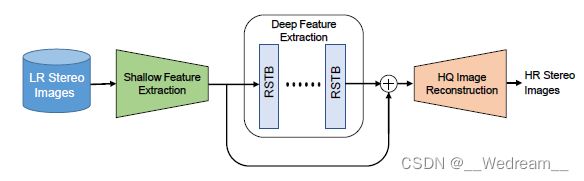
这支队伍有些特殊,他们纯靠单张图像超分技术拿到了第四名,没有使用双目图像的视差信息,respect!这支队伍开发了改进的SwinIR来分别超分左图和右图。其网络结构图如图4所示。尽管跨视野信息没有被用到,凭借着高效的数据增广和测试时数据增广(TTA)策略,这支队伍提出的方法获得了极具竞争力的超分性能。此外,除了SwinIR最初使用的数据增强外,他们还是用了一系列的tricks:
-
在训练阶段,他们调整了选择训练样本的概率,使得更高分辨率的图像更有机会被选到;
-
有50%的概率随机打乱RGB通道;
-
训练了三种不同结构和损失结合的模型;
-
在测试阶段,使用了一系列测试时数据增强策略(包括翻转,self-ensemble和RGB通道随机打乱);
-
与SwinIR里的窗口尺寸设置为8不同,在这个方法里面被设置为16。
6.5 第五名:The NKU caroline Team
这支队伍与很多其他队伍一样,都有类似的idea,通过结合SwinIR和视差注意力机制,开发了PAMSwin网络用于双目图像超分任务。网络结构不再详细介绍(想要深入了解的可以看报告原文),如下图所示。
这支队伍强调输入左右图的顺序也蕴含着先验信息,并且影响模型的性能。如果在训练阶段使用乱序的左右图像对(一会先输入左图再右图,一会先输入右图再输入左图),在他们的实验中将会降低超分的性能。
训练阶段分为三个阶段,首先PAMSwin将从头开始训练500k次迭代。接着,使用Cutblur等数据增广策略微调(fine-tune)前面500k次迭代表现最好的模型,也是迭代500k次。注意,在这个微调阶段,biPAM的参数被固定住了。最后,使用小学习率微调第二个阶段里面超分性能最好的模型,同样微调500k次。在测试阶段,使用了self-ensemble策略来提高模型性能。
6.6 第六名:The BUAAMC2 Team
这支队伍提出了StereoSRT(Stereo Image Super-Resolution Transformer),其结构如下图所示,网络结构不再详细介绍(想要深入了解的可以看报告原文)。在训练阶段,使用了L1损失用于超分,使用L2损失用于增强。初始学习率设置为 4 × 1 0 − 4 4\times10^{-4} 4×10−4,模型同样经历了多个阶段的训练 。在第一个阶段,模型只训练STL部分,patch size为 64 × 64 64\times64 64×64,训练200k个迭代次数。第二个阶段MAL部分被优化200k个迭代次数,此时STL部分被固定住,不被训练。在第三个阶段,整个网络端到端地优化100k个迭代次数。在第四个阶段,flow module加入到MAL中,并固定住STL,再优化300k个迭代次数。最后,整个网络使用 96 × 96 96\times96 96×96的patch size微调100k个迭代次数。

6.7 第七名:The NoWar Team
这支队伍提出的网络结构如下图所示,网络结构如下图所示,不再详细介绍(想要深入了解的可以看报告原文)。在训练阶段,输入的图像块被裁减成 128 × 128 128\times128 128×128,步长为20,batch size设置为4。为了防止模型过拟合,这支队伍采用了model ensemble策略,即选择五个不相邻的epochs的模型,将他们的权重进行平均,获得最后用于测试的模型。

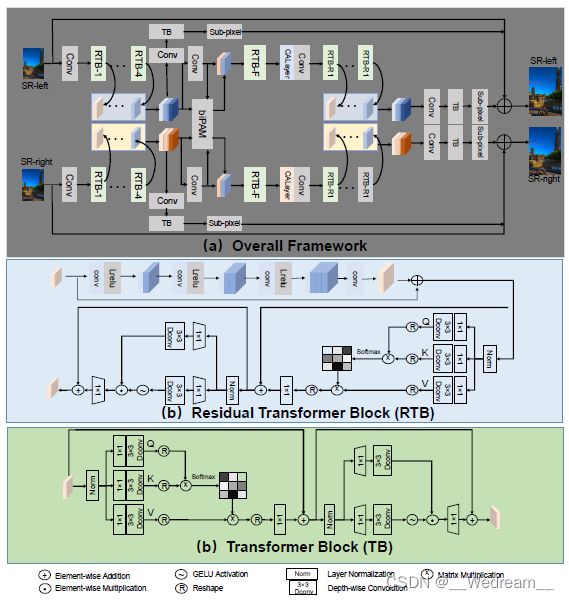
6.8 第八名:The GDUT 506 Team
这支队伍通过结合Transformers和视差注意力机制,开发了PRTN(Parallax ResTransformer Network),网络结构如下图所示,不再详细介绍(想要深入了解的可以看报告原文)。在训练阶段,使用随机水平和垂直翻转作为数据增强手段。在第一个阶段,使用L1损失训练PTRN的2倍超分模型。在第二个阶段,使用L1损失微调PTRN的4倍超分模型。最后,使用L2损失进一步微调PRTN的4倍超分。
6.9 第九名:The DSSR Team
这支队伍提出了DSSR(Deformable Stereo Super-Resolution)网络,网络结构如下图所示,不再详细介绍(想要深入了解的可以看报告原文)。在训练阶段,生成的LR图像将会被裁剪出 120 × 120 120\times120 120×120的图块,步长为40。这些图块将会进行水平翻转和垂直翻转,进行数据增强。模型使用Adam优化器进行优化,batch size设为36。初始学习率设置成 2 × 1 0 − 4 2\times10^{-4} 2×10−4,并且每30个epochs将会减半。训练将会在100个epochs之后停止。在早期的训练过程中,L1损失被用来加速模型收敛,然后L2损失被用来获得更高的PSNR值。

6.10 第十名:The Xiaozhazha Team
这支队伍基于SwinIR和快速傅里叶卷积(fast Fourier convolution)提出了SwinFIR,网络结构如下图所示,不再详细介绍(想要深入了解的可以看报告原文)。在训练阶段,使用的数据增强技术有随机水平翻转,随机垂直翻转,随机RGB通道打乱和mix-up。self-ensemble和multi-model ensemble同样用来提升模型的超分性能。
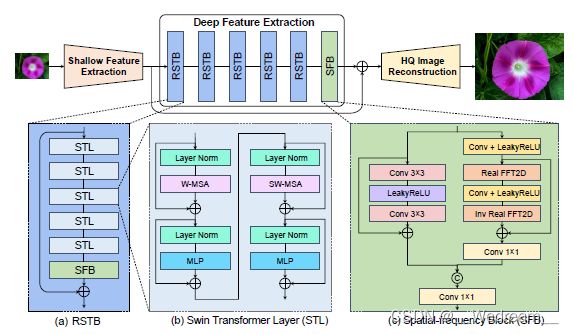
6.11 第十一名:The Zhang9678 Team
这支队伍提出了MPTnet(multi-stage progressive Transformer network)用于双目图像超分,网络结构如下图所示,不再详细介绍(想要深入了解的可以看报告原文)。

6.12 第十二名:The NTU607QCOSSR Team
这支队伍同样将双目超分任务看成是单张图片超分任务,采用SwinIR作为主干网络,网络结构如下图所示,不再详细介绍(想要深入了解的可以看报告原文)。在训练阶段,使用L1损失来优化300个epochs。其次,使用基于小波(wavelet-based)的L1损失进行微调。基于小波的损失使用小波变换生成与原图不同尺度和频率的子图。因为生成的子图具有高频信息,能够获得更好的性能。

6.13 第十三名:The Supersmart Team
这支队伍提出了SwinRSTB,网络结构如下图所示,不再详细介绍(想要深入了解的可以看报告原文)。由于SwinIR用于单幅图像超分,不能利用跨视野信息,他们结合了iPASSR和SwinIR用于双目图像超分。在SwinRSTB中,使用了SwinIR的RSTB模块代替iPASSR的RGB模块。
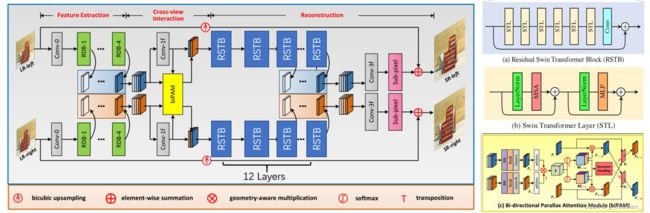
6.14 第十四名:The LIMMC HNU Team
这支队伍受到SwinIR和iPASSRnet的启发,提出了PAMSwinIR,网络结构如下图所示,不再详细介绍(想要深入了解的可以看报告原文)。在训练阶段,首先使用《Symmetric parallax attention for stereo image super-resolution》论文中的损失函数捕获跨视野对应关系。然后,只使用MSE损失进行微调。
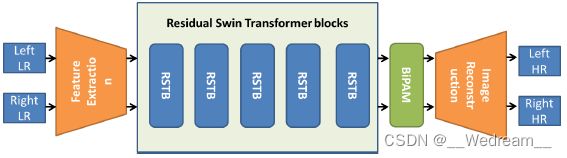
6.15 第十五名:The HITIIL Team
这支队伍使用SwinIR(网络结构如下图所示)作为基本的单幅图像超分模型,并且使用FFT损失进行优化。FFT损失度量的是超分图像和原图像在频域上的差异。相比于只使用L1损失来训练模型,额外添加的FFT损失能够帮助模型更快地收敛,达到更好的性能。

6.16 第十六名:The Hansheng Team
这支队伍基于SwinIR和iPASSR开发了一个双目图像超分网络,网络结构如下图所示,不再详细介绍(想要深入了解的可以看报告原文)。在训练阶段,输入的图像被裁剪成 48 × 48 48\times48 48×48的图块,STL块中的window size设置为8。

6.17 第十七名:The VIP-SSR Team
这支队伍基于SwinIR和iPASSR开发了一个双目图像超分网络,网络结构如下图所示,不再详细介绍(想要深入了解的可以看报告原文)。在训练阶段,输入的图像被裁剪成 48 × 48 48\times48 48×48的图块,STL块中的window size设置为8。

6.18 第十八名:The phc Team
这支队伍提出了Improved-PASSR,网络结构如下图所示,不再详细介绍(想要深入了解的可以看报告原文)。在训练阶段,使用Adam优化器训练100个epochs,batch size设置为32。初始的学习率为 2 × 1 0 − 4 2\times10^{-4} 2×10−4,并且每40个epochs减半。
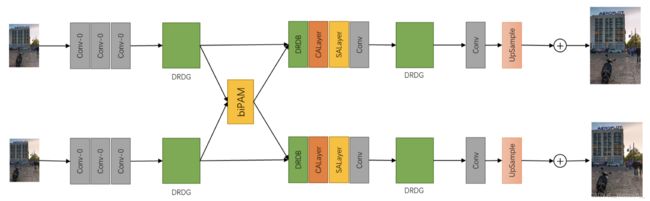
6.19 第十九名:The qylen Team
这支队伍结合iPASSR和Transformer来提高超分的性能,网络结构如下图所示,不再详细介绍(想要深入了解的可以看报告原文)
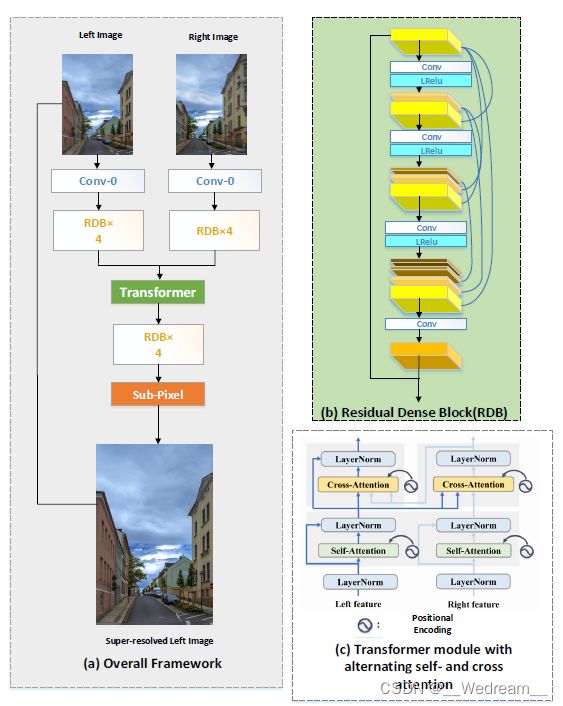
6.20 第二十名:The Modern_SR Team
这支队伍也特别有意思,他们将一对双目图像看成是两张连续的帧,并提出了Stereo-EDVR网络进行超分。他们想要探寻一个能够用于 不同超分任务的更为通用的超分框架。网络结构如下图所示,首先一个双目图像对通过复制左图或者右图,来组成一个三帧的序列。然后,使用包含更多通道的改进的EDVR模型重构出高分的左图或者右图。

最后感谢小伙伴们的学习噢~

最后附上2023年双目超分的比赛报告链接,欢迎大家多多阅读分享:NTIRE 2023 Challenge on Stereo Image Super-Resolution: Methods and Results