9、hive的explode、Lateral View侧视图、聚合函数、窗口函数、抽样函数使用详解
Apache Hive 系列文章
1、apache-hive-3.1.2简介及部署(三种部署方式-内嵌模式、本地模式和远程模式)及验证详解
2、hive相关概念详解–架构、读写文件机制、数据存储
3、hive的使用示例详解-建表、数据类型详解、内部外部表、分区表、分桶表
4、hive的使用示例详解-事务表、视图、物化视图、DDL(数据库、表以及分区)管理详细操作
5、hive的load、insert、事务表使用详解及示例
6、hive的select(GROUP BY、ORDER BY、CLUSTER BY、SORT BY、LIMIT、union、CTE)、join使用详解及示例
7、hive shell客户端与属性配置、内置运算符、函数(内置运算符与自定义UDF运算符)
8、hive的关系运算、逻辑预算、数学运算、数值运算、日期函数、条件函数和字符串函数的语法与使用示例详解
9、hive的explode、Lateral View侧视图、聚合函数、窗口函数、抽样函数使用详解
10、hive综合示例:数据多分隔符(正则RegexSerDe)、url解析、行列转换常用函数(case when、union、concat和explode)详细使用示例
11、hive综合应用示例:json解析、窗口函数应用(连续登录、级联累加、topN)、拉链表应用
12、Hive优化-文件存储格式和压缩格式优化与job执行优化(执行计划、MR属性、join、优化器、谓词下推和数据倾斜优化)详细介绍及示例
13、java api访问hive操作示例
文章目录
- Apache Hive 系列文章
- 一、UDTF的explode函数
-
- 1、示例
- 2、explode使用限制
- 3、UDTF语法限制解决
- 二、Lateral View侧视图
-
- 1、示例
- 三、Aggregation聚合函数
-
- 1、基本示例
- 2、grouping_sets、cube、rollup用法
-
- 1)、grouping sets
- 2)、cube
- 3)、rollup
- 4)、示例
- 四、Windows Functions窗口函数
-
- 1、介绍
- 2、语法
- 3、示例1:sum和窗口函数聚合
- 4、示例2:综合示例窗口函数
- 5、窗口表达式
-
- 1)、介绍
- 2)语法
- 3)、示例
- 6、窗口排序函数--row_number家族
- 7、窗口排序函数--ntile
- 8、窗口分析函数
-
- 1)、语法
- 2)、示例
- 五、Sampling抽样函数
-
- 1、Random 随机抽样
- 2、Block 基于数据块抽样
- 3、Bucket table 基于分桶表抽样
本文介绍了hive的explode函数、Lateral View侧视图、聚合函数、窗口函数和抽样函数内容及详细的使用示例。
本文依赖hive环境可用。
本文分为5个部分,即explode函数、侧视图、聚合函数、窗口函数和抽样函数。
本文部分数据来源于互联网。
一、UDTF的explode函数
explode接收map、array类型的数据作为输入,然后把输入数据中的每个元素拆开变成一行数据,一个元素一行。
explode执行效果正好满足于输入一行输出多行,所有叫做UDTF函数。
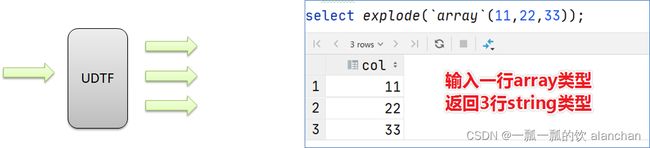
一般情况下,explode函数可以直接单独使用即可;也可以根据业务需要结合lateral view侧视图一起使用。
explode(array) 将array里的每个元素生成一行;
explode(map) 将map里的每一对元素作为一行,其中key为一列,value为一列;
0: jdbc:hive2://server4:10000> select explode(`array`(11,22,33)) as item;
+-------+
| item |
+-------+
| 11 |
| 22 |
| 33 |
+-------+
0: jdbc:hive2://server4:10000> select explode(`map`("id",10086,"name","zhangsan","age",18));
+-------+-----------+
| key | value |
+-------+-----------+
| id | 10086 |
| name | zhangsan |
| age | 18 |
+-------+-----------+
1、示例
使用Hive建表映射成功数据,对数据拆分,要求拆分之后数据如下所示
- 字段之间以‘,’分割
- 总冠军年份之间以‘|’进行分割

源数据自己造,按照图片内容即可。
create table the_nba_championship(
team_name string,
champion_year array<string>
) row format delimited
fields terminated by ','
collection items terminated by '|';
load data inpath '/hivetest/test/The_NBA_Championship.txt' into table the_nba_championship;
0: jdbc:hive2://server4:10000> select * from the_nba_championship;
+---------------------------------+----------------------------------------------------+
| the_nba_championship.team_name | the_nba_championship.champion_year |
+---------------------------------+----------------------------------------------------+
| Chicago Bulls | ["1991","1992","1993","1996","1997","1998"] |
| San Antonio Spurs | ["1999","2003","2005","2007","2014"] |
| Golden State Warriors | ["1947","1956","1975","2015","2017","2018","2022"] |
| Boston Celtics | ["1957","1959","1960","1961","1962","1963","1964","1965","1966","1968","1969","1974","1976","1981","1984","1986","2008"] |
| L.A. Lakers | ["1949","1950","1952","1953","1954","1972","1980","1982","1985","1987","1988","2000","2001","2002","2009","2010","2020"] |
| Miami Heat | ["2006","2012","2013"] |
| Philadelphia 76ers | ["1955","1967","1983"] |
| Detroit Pistons | ["1989","1990","2004"] |
| Houston Rockets | ["1994","1995"] |
| New York Knicks | ["1970","1973"] |
| Cleveland Cavaliers | ["2016"] |
| Toronto Raptors | ["2019"] |
| Milwaukee Bucks | ["2021"] |
+---------------------------------+----------------------------------------------------+
2、explode使用限制
- explode函数属于UDTF表生成函数,explode执行返回的结果可以理解为一张虚拟的表,其数据来源于源表
- 在select中只查询源表数据没有问题,只查询explode生成的虚拟表数据也没问题,但是不能在只查询源表的时候,既想返回源表字段又想返回explode生成的虚拟表字段,即有两张表,不能只查询一张表但是又想返回分别属于两张表的字段。如下图所示
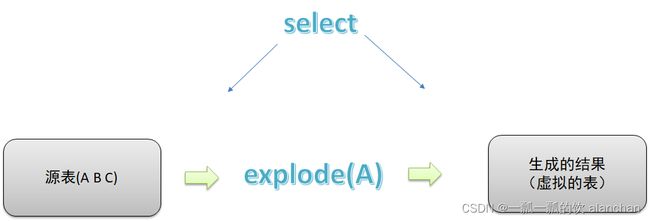
3、UDTF语法限制解决
- 从SQL层面上来说上述问题的解决方案是:对两张表进行join关联查询;
- Hive专门提供了语法lateral View侧视图,专门用于搭配explode这样的UDTF函数,以满足上述需要。
实现sql如下
select a.team_name,b.year
from the_nba_championship a lateral view explode(champion_year) b as year
order by b.year desc;
二、Lateral View侧视图
Lateral View是一种特殊的语法,主要搭配UDTF类型函数一起使用,用于解决UDTF函数的一些查询限制的问题。
一般只要使用UDTF,就会固定搭配lateral view使用。
官方链接:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+LateralView
将UDTF的结果构建成一个类似于视图的表,然后将原表中的每一行和UDTF函数输出的每一行进行连接,生成一张新的虚拟表。这样就避免了UDTF的使用限制问题。
使用lateral view时也可以对UDTF产生的记录设置字段名称,产生的字段可以用于group by、order by 、limit等语句中,不需要再单独嵌套一层子查询。
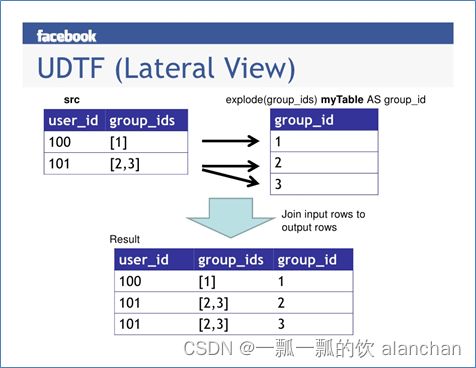
1、示例
针对explode案例中NBA冠军球队年份排名案例,使用explode函数+lateral view侧视图
--lateral view侧视图基本语法如下
select …… from tabelA lateral view UDTF(xxx) 别名 as col1,col2,col3……;
select a.team_name ,b.year
from the_nba_championship a lateral view explode(champion_year) b as year;
--根据年份倒序排序
select a.team_name ,b.year
from the_nba_championship a lateral view explode(champion_year) b as year
order by b.year desc;
--统计每个球队获取总冠军的次数 并且根据倒序排序
select a.team_name ,count(*) as nums
from the_nba_championship a lateral view explode(champion_year) b as year
group by a.team_name
order by nums desc;
0: jdbc:hive2://server4:10000> select a.team_name ,count(*) as nums
. . . . . . . . . . . . . . .> from the_nba_championship a lateral view explode(champion_year) b as year
. . . . . . . . . . . . . . .> group by a.team_name
. . . . . . . . . . . . . . .> order by nums desc;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+------------------------+-------+
| a.team_name | nums |
+------------------------+-------+
| Boston Celtics | 17 |
| L.A. Lakers | 17 |
| Golden State Warriors | 7 |
| Chicago Bulls | 6 |
| San Antonio Spurs | 5 |
| Philadelphia 76ers | 3 |
| Miami Heat | 3 |
| Detroit Pistons | 3 |
| New York Knicks | 2 |
| Houston Rockets | 2 |
| Milwaukee Bucks | 1 |
| Toronto Raptors | 1 |
| Cleveland Cavaliers | 1 |
+------------------------+-------+
三、Aggregation聚合函数
聚合函数的功能是对一组值执行计算并返回单一的值。
聚合函数是典型的输入多行输出一行,使用Hive的分类标准,属于UDAF类型函数。
通常搭配Group By语法一起使用,分组后进行聚合操作。
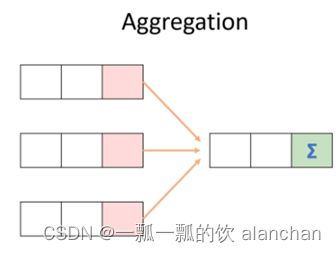
HQL提供了几种内置的UDAF聚合函数,例如max(…),min(…)和avg(…),称之为聚合函数。
通常情况下聚合函数会与GROUP BY子句一起使用。如果未指定GROUP BY子句,默认情况下,它会汇总所有行数据。
注意結構體的用法。
1、基本示例
--1、测试数据准备
drop table if exists student;
create table student(
num int,
name string,
sex string,
age int,
dept string)
row format delimited
fields terminated by ',';
--加载数据
load data local inpath '/usr/local/bigdata/students.txt' into table student;
--验证
select * from student;
--設置統計數量
set hive.compute.query.using.stats=false
--通過MR統計表數據的數量
--场景1:没有group by子句的聚合操作
--count(*):所有行进行统计,包括NULL行
--count(1):所有行进行统计,包括NULL行
--count(column):对column中非Null进行统计
select count(*) as cnt1,count(1) as cnt2 from student;
select count(sex) as cnt3 from student;
--场景2:带有group by子句的聚合操作 注意group by语法限制
select sex,count(*) as cnt from student group by sex;
--场景3:select时多个聚合函数一起使用
select count(*) as cnt1,avg(age) as cnt2 from student;
--场景4:聚合函数和case when条件转换函数、coalesce函数、if函数使用
select
sum(CASE WHEN sex = '男'THEN 1 ELSE 0 END)
from student;
select
sum(if(sex = '男',1,0))
from student;
--场景5:聚合参数不支持嵌套聚合函数
select avg(count(*)) from student;
--场景6:聚合操作时针对null的处理
CREATE TABLE tmp_1 (val1 int, val2 int);
INSERT INTO TABLE tmp_1 VALUES (1, 2),(null,2),(2,3);
select * from tmp_1;
--第二行数据(NULL, 2) 在进行sum(val1 + val2)的时候会被忽略
select sum(val1), sum(val1 + val2) from tmp_1;
--可以使用coalesce函数解决
select
sum(coalesce(val1,0)),
sum(coalesce(val1,0) + val2)
from tmp_1;
0: jdbc:hive2://server4:10000> select * from tmp_1;
+-------------+-------------+
| tmp_1.val1 | tmp_1.val2 |
+-------------+-------------+
| 1 | 2 |
| NULL | 2 |
| 2 | 3 |
+-------------+-------------+
0: jdbc:hive2://server4:10000> select sum(val1), sum(val1 + val2) from tmp_1;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+------+------+
| _c0 | _c1 |
+------+------+
| 3 | 8 |
+------+------+
0: jdbc:hive2://server4:10000> select
. . . . . . . . . . . . . . .> sum(coalesce(val1,0)),
. . . . . . . . . . . . . . .> sum(coalesce(val1,0) + val2)
. . . . . . . . . . . . . . .> from tmp_1;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+------+------+
| _c0 | _c1 |
+------+------+
| 3 | 10 |
+------+------+
--场景7:配合distinct关键字去重聚合
--此场景下,会编译期间会自动设置只启动一个reduce task处理数据 可能造成数据拥堵
select count(distinct sex) as cnt1 from student;
--可以先去重 在聚合 通过子查询完成
--因为先执行distinct的时候 可以使用多个reducetask来跑数据
select count(*) as gender_uni_cnt
from (select distinct sex from student) a;
--案例需求:找出student中男女学生年龄最大的及其名字
--age、name作爲一個結構體
select struct(age, name) from student;
--age、name作爲一個結構體,並查出結構體第一個列,即age
select struct(age, name).col1 from student;
--age、name作爲一個結構體,並查出最大的age
select max(struct(age, name)) from student;
0: jdbc:hive2://server4:10000> select struct(age, name) from student;
+---------------------------+
| _c0 |
+---------------------------+
| {"col1":20,"col2":"李勇"} |
| {"col1":19,"col2":"刘晨"} |
| {"col1":22,"col2":"王敏"} |
| {"col1":19,"col2":"张立"} |
| {"col1":18,"col2":"刘刚"} |
| {"col1":23,"col2":"孙庆"} |
| {"col1":19,"col2":"易思玲"} |
| {"col1":18,"col2":"李娜"} |
| {"col1":18,"col2":"梦圆圆"} |
| {"col1":19,"col2":"孔小涛"} |
| {"col1":18,"col2":"包小柏"} |
| {"col1":20,"col2":"孙花"} |
| {"col1":21,"col2":"冯伟"} |
| {"col1":19,"col2":"王小丽"} |
| {"col1":18,"col2":"王君"} |
| {"col1":21,"col2":"钱国"} |
| {"col1":18,"col2":"王风娟"} |
| {"col1":19,"col2":"王一"} |
| {"col1":19,"col2":"邢小丽"} |
| {"col1":21,"col2":"赵钱"} |
| {"col1":17,"col2":"周二"} |
| {"col1":20,"col2":"郑明"} |
+---------------------------+
0: jdbc:hive2://server4:10000> select struct(age, name).col1 from student;
+-------+
| col1 |
+-------+
| 20 |
| 19 |
| 22 |
| 19 |
| 18 |
| 23 |
| 19 |
| 18 |
| 18 |
| 19 |
| 18 |
| 20 |
| 21 |
| 19 |
| 18 |
| 21 |
| 18 |
| 19 |
| 19 |
| 21 |
| 17 |
| 20 |
+-------+
0: jdbc:hive2://server4:10000> select max(struct(age, name)) from student;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+--------------------------+
| _c0 |
+--------------------------+
| {"col1":23,"col2":"孙庆"} |
+--------------------------+
--age、name作爲一個結構體,按sex分組,查詢各年齡最大的記錄
select sex,max(struct(age, name)) from student group by sex;
0: jdbc:hive2://server4:10000> select sex,max(struct(age, name)) from student group by sex;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+------+--------------------------+
| sex | _c1 |
+------+--------------------------+
| 女 | {"col1":22,"col2":"王敏"} |
| 男 | {"col1":23,"col2":"孙庆"} |
+------+--------------------------+
--这里使用了struct来构造数据 然后针对struct应用max找出最大元素 然后取值
select sex,
max(struct(age, name)).col1 as age,
max(struct(age, name)).col2 as name
from student
group by sex;
0: jdbc:hive2://server4:10000> select sex,
. . . . . . . . . . . . . . .> max(struct(age, name)).col1 as age,
. . . . . . . . . . . . . . .> max(struct(age, name)).col2 as name
. . . . . . . . . . . . . . .> from student
. . . . . . . . . . . . . . .> group by sex;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+------+------+-------+
| sex | age | name |
+------+------+-------+
| 女 | 22 | 王敏 |
| 男 | 23 | 孙庆 |
+------+------+-------+
2、grouping_sets、cube、rollup用法
增强聚合包括grouping_sets、cube、rollup这几个函数;主要适用于OLAP多维数据分析模式中,多维分析中的维指的分析问题时看待问题的维度、角度。
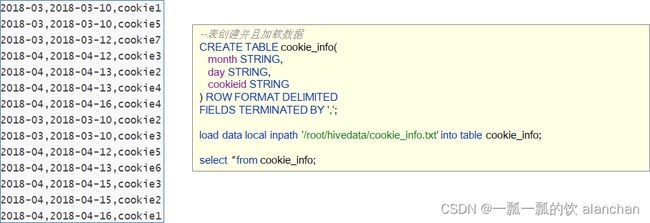
示例数据中字段含义:月份、天、用户标识cookieid。
1)、grouping sets
grouping sets是一种将多个group by逻辑写在一个sql语句中的便利写法。等价于将不同维度的GROUP BY结果集进行UNION ALL。GROUPING__ID表示结果属于哪一个分组集合。
2)、cube
cube表示根据GROUP BY的维度的所有组合进行聚合。
对于cube来说,如果有n个维度,则所有组合的总个数是:2的n次方
比如cube有a,b,c 3个维度,则所有组合情况是: (a,b,c),(a,b),(b,c),(a,c),(a),(b),©,()
3)、rollup
cube的语法功能指的是根据GROUP BY的维度的所有组合进行聚合。
rollup是cube的子集,以最左侧的维度为主,从该维度进行层级聚合。
比如ROLLUP有a,b,c3个维度,则所有组合情况是:(a,b,c),(a,b),(a),()
4)、示例
--表创建并且加载数据
CREATE TABLE cookie_info(
month STRING,
day STRING,
cookieid STRING
) ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';
load data local inpath '/usr/local/bigdata/cookie_info.txt' into table cookie_info;
select * from cookie_info;
---group sets---------
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS nums,
GROUPING__ID
FROM cookie_info
GROUP BY month,day
GROUPING SETS (month,day) --这里是关键
ORDER BY GROUPING__ID;
--grouping_id表示这一组结果属于哪个分组集合,
--根据grouping sets中的分组条件month,day,1是代表month,2是代表day
--等价于
SELECT month,NULL,COUNT(DISTINCT cookieid) AS nums,1 AS GROUPING__ID FROM cookie_info GROUP BY month
UNION ALL
SELECT NULL as month,day,COUNT(DISTINCT cookieid) AS nums,2 AS GROUPING__ID FROM cookie_info GROUP BY day;
0: jdbc:hive2://server4:10000> SELECT
. . . . . . . . . . . . . . .> month,
. . . . . . . . . . . . . . .> day,
. . . . . . . . . . . . . . .> COUNT(DISTINCT cookieid) AS nums,
. . . . . . . . . . . . . . .> GROUPING__ID
. . . . . . . . . . . . . . .> FROM cookie_info
. . . . . . . . . . . . . . .> GROUP BY month,day
. . . . . . . . . . . . . . .> GROUPING SETS (month,day) --这里是关键
. . . . . . . . . . . . . . .> ORDER BY GROUPING__ID;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+----------+-------------+-------+---------------+
| month | day | nums | grouping__id |
+----------+-------------+-------+---------------+
| 2018-04 | NULL | 6 | 1 |
| 2018-03 | NULL | 5 | 1 |
| NULL | 2018-04-16 | 2 | 2 |
| NULL | 2018-04-15 | 2 | 2 |
| NULL | 2018-04-13 | 3 | 2 |
| NULL | 2018-04-12 | 2 | 2 |
| NULL | 2018-03-12 | 1 | 2 |
| NULL | 2018-03-10 | 4 | 2 |
+----------+-------------+-------+---------------+
--再比如
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS nums,
GROUPING__ID
FROM cookie_info
GROUP BY month,day
GROUPING SETS (month,day,(month,day)) --1 month 2 day 3 (month,day)
ORDER BY GROUPING__ID;
0: jdbc:hive2://server4:10000> SELECT
. . . . . . . . . . . . . . .> month,
. . . . . . . . . . . . . . .> day,
. . . . . . . . . . . . . . .> COUNT(DISTINCT cookieid) AS nums,
. . . . . . . . . . . . . . .> GROUPING__ID
. . . . . . . . . . . . . . .> FROM cookie_info
. . . . . . . . . . . . . . .> GROUP BY month,day
. . . . . . . . . . . . . . .> GROUPING SETS (month,day,(month,day)) --1 month 2 day 3 (month,day)
. . . . . . . . . . . . . . .> ORDER BY GROUPING__ID;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+----------+-------------+-------+---------------+
| month | day | nums | grouping__id |
+----------+-------------+-------+---------------+
| 2018-03 | 2018-03-10 | 4 | 0 |
| 2018-04 | 2018-04-16 | 2 | 0 |
| 2018-04 | 2018-04-13 | 3 | 0 |
| 2018-04 | 2018-04-12 | 2 | 0 |
| 2018-04 | 2018-04-15 | 2 | 0 |
| 2018-03 | 2018-03-12 | 1 | 0 |
| 2018-03 | NULL | 5 | 1 |
| 2018-04 | NULL | 6 | 1 |
| NULL | 2018-04-16 | 2 | 2 |
| NULL | 2018-04-15 | 2 | 2 |
| NULL | 2018-04-13 | 3 | 2 |
| NULL | 2018-04-12 | 2 | 2 |
| NULL | 2018-03-12 | 1 | 2 |
| NULL | 2018-03-10 | 4 | 2 |
+----------+-------------+-------+---------------+
--等价于
SELECT month,NULL,COUNT(DISTINCT cookieid) AS nums,1 AS GROUPING__ID FROM cookie_info GROUP BY month
UNION ALL
SELECT NULL,day,COUNT(DISTINCT cookieid) AS nums,2 AS GROUPING__ID FROM cookie_info GROUP BY day
UNION ALL
SELECT month,day,COUNT(DISTINCT cookieid) AS nums,3 AS GROUPING__ID FROM cookie_info GROUP BY month,day;
------cube---------------
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS nums,
GROUPING__ID
FROM cookie_info
GROUP BY month,day
WITH CUBE
ORDER BY GROUPING__ID;
--等价于
SELECT NULL,NULL,COUNT(DISTINCT cookieid) AS nums,0 AS GROUPING__ID FROM cookie_info
UNION ALL
SELECT month,NULL,COUNT(DISTINCT cookieid) AS nums,1 AS GROUPING__ID FROM cookie_info GROUP BY month
UNION ALL
SELECT NULL,day,COUNT(DISTINCT cookieid) AS nums,2 AS GROUPING__ID FROM cookie_info GROUP BY day
UNION ALL
SELECT month,day,COUNT(DISTINCT cookieid) AS nums,3 AS GROUPING__ID FROM cookie_info GROUP BY month,day;
0: jdbc:hive2://server4:10000> SELECT
. . . . . . . . . . . . . . .> month,
. . . . . . . . . . . . . . .> day,
. . . . . . . . . . . . . . .> COUNT(DISTINCT cookieid) AS nums,
. . . . . . . . . . . . . . .> GROUPING__ID
. . . . . . . . . . . . . . .> FROM cookie_info
. . . . . . . . . . . . . . .> GROUP BY month,day
. . . . . . . . . . . . . . .> WITH CUBE
. . . . . . . . . . . . . . .> ORDER BY GROUPING__ID;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+----------+-------------+-------+---------------+
| month | day | nums | grouping__id |
+----------+-------------+-------+---------------+
| 2018-03 | 2018-03-10 | 4 | 0 |
| 2018-04 | 2018-04-16 | 2 | 0 |
| 2018-04 | 2018-04-13 | 3 | 0 |
| 2018-04 | 2018-04-12 | 2 | 0 |
| 2018-04 | 2018-04-15 | 2 | 0 |
| 2018-03 | 2018-03-12 | 1 | 0 |
| 2018-03 | NULL | 5 | 1 |
| 2018-04 | NULL | 6 | 1 |
| NULL | 2018-04-16 | 2 | 2 |
| NULL | 2018-04-15 | 2 | 2 |
| NULL | 2018-04-13 | 3 | 2 |
| NULL | 2018-04-12 | 2 | 2 |
| NULL | 2018-03-12 | 1 | 2 |
| NULL | 2018-03-10 | 4 | 2 |
| NULL | NULL | 7 | 3 |
+----------+-------------+-------+---------------+
--rollup-------------
--比如,以month维度进行层级聚合:
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS nums,
GROUPING__ID
FROM cookie_info
GROUP BY month,day
WITH ROLLUP
ORDER BY GROUPING__ID;
--把month和day调换顺序,则以day维度进行层级聚合:
SELECT
day,
month,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM cookie_info
GROUP BY day,month
WITH ROLLUP
ORDER BY GROUPING__ID;
0: jdbc:hive2://server4:10000> SELECT
. . . . . . . . . . . . . . .> month,
. . . . . . . . . . . . . . .> day,
. . . . . . . . . . . . . . .> COUNT(DISTINCT cookieid) AS nums,
. . . . . . . . . . . . . . .> GROUPING__ID
. . . . . . . . . . . . . . .> FROM cookie_info
. . . . . . . . . . . . . . .> GROUP BY month,day
. . . . . . . . . . . . . . .> WITH ROLLUP
. . . . . . . . . . . . . . .> ORDER BY GROUPING__ID;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+----------+-------------+-------+---------------+
| month | day | nums | grouping__id |
+----------+-------------+-------+---------------+
| 2018-04 | 2018-04-16 | 2 | 0 |
| 2018-04 | 2018-04-15 | 2 | 0 |
| 2018-04 | 2018-04-13 | 3 | 0 |
| 2018-04 | 2018-04-12 | 2 | 0 |
| 2018-03 | 2018-03-12 | 1 | 0 |
| 2018-03 | 2018-03-10 | 4 | 0 |
| 2018-04 | NULL | 6 | 1 |
| 2018-03 | NULL | 5 | 1 |
| NULL | NULL | 7 | 3 |
+----------+-------------+-------+---------------+
-------------------------------------------------------------------
--验证测试count(*),count(1),count(字段)
select * from t_all_hero_part_dynamic where role ="archer";
select count(*),count(1),count(role_assist) from t_all_hero_part_dynamic where role ="archer";
四、Windows Functions窗口函数
1、介绍
窗口函数(Window functions)也叫做开窗函数、OLAP函数,其最大特点是输入值是从SELECT语句的结果集中的一行或多行的“窗口”中获取的。
如果函数具有OVER子句,则它是窗口函数。
窗口函数可以简单地解释为类似于聚合函数的计算函数,但是通过GROUP BY子句组合的常规聚合会隐藏正在聚合的各个行,最终输出一行,窗口函数聚合后还可以访问当中的各个行,并且可以将这些行中的某些属性添加到结果集中。
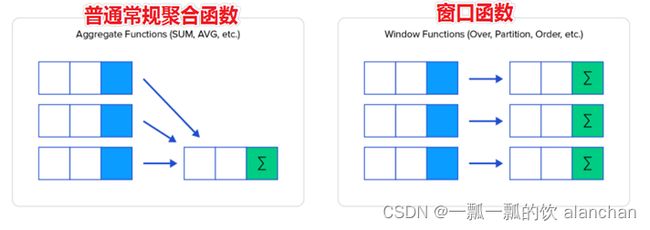
通过sum聚合函数进行普通常规聚合和窗口聚合,来直观感受窗口函数的特点
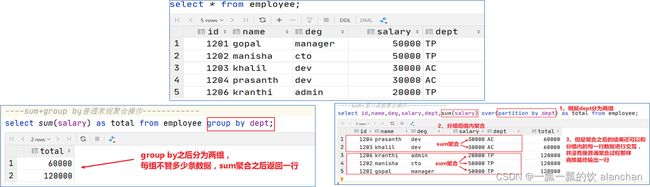
所谓窗口聚合函数指的是sum、max、min、avg这样的聚合函数在窗口中的使用
这里以sum()函数为例,其他聚合函数使用类似
--1、求出每个用户总pv数 sum+group by普通常规聚合操作
select cookieid,sum(pv) as total_pv from website_pv_info group by cookieid;
--2、sum+窗口函数 总共有四种用法 注意是整体聚合 还是累积聚合
--sum(...) over( )对表所有行求和
--sum(...) over( order by ... ) 连续累积求和
--sum(...) over( partition by... ) 同组内所行求和
--sum(...) over( partition by... order by ... ) 在每个分组内,连续累积求和
2、语法
-------窗口函数语法树
Function(arg1,..., argn) OVER ([PARTITION BY <...>] [ORDER BY <....>] [<window_expression>])
--其中Function(arg1,..., argn) 可以是下面分类中的任意一个
--聚合函数:比如sum max avg等
--排序函数:比如rank row_number等
--分析函数:比如lead lag first_value等
--OVER [PARTITION BY <...>] 类似于group by 用于指定分组 每个分组你可以把它叫做窗口
--如果没有PARTITION BY 那么整张表的所有行就是一组
--[ORDER BY <....>] 用于指定每个分组内的数据排序规则 支持ASC、DESC
--[] 用于指定每个窗口中 操作的数据范围 默认是窗口中所有行
3、示例1:sum和窗口函数聚合
--建表加载数据
CREATE TABLE employee(
id int,
name string,
deg string,
salary int,
dept string
) row format delimited
fields terminated by ',';
load data local inpath '/root/hivedata/employee.txt' into table employee;
select * from employee;
0: jdbc:hive2://server4:10000> select * from employee;
+--------------+----------------+---------------+------------------+----------------+
| employee.id | employee.name | employee.deg | employee.salary | employee.dept |
+--------------+----------------+---------------+------------------+----------------+
| 1201 | gopal | manager | 50000 | TP |
| 1202 | manisha | cto | 50000 | TP |
| 1203 | khalil | dev | 30000 | AC |
| 1204 | prasanth | dev | 30000 | AC |
| 1206 | kranthi | admin | 20000 | TP |
+--------------+----------------+---------------+------------------+----------------+
----sum+group by普通常规聚合操作------------
select dept,sum(salary) as total from employee group by dept;
0: jdbc:hive2://server4:10000> select dept,sum(salary) as total from employee group by dept;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+-------+---------+
| dept | total |
+-------+---------+
| AC | 60000 |
| TP | 120000 |
+-------+---------+
----sum+窗口函数聚合操作------------
select id,name,deg,salary,dept,sum(salary) over(partition by dept) as total from employee;
0: jdbc:hive2://server4:10000> select * from t_all_hero_part_dynamic where role ="archer";
Error: Error while compiling statement: FAILED: SemanticException [Error 10001]: Line 1:14 Table not found 't_all_hero_part_dynamic' (state=42S02,code=10001)
0: jdbc:hive2://server4:10000> select id,name,deg,salary,dept,sum(salary) over(partition by dept) as total from employee;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+-------+-----------+----------+---------+-------+---------+
| id | name | deg | salary | dept | total |
+-------+-----------+----------+---------+-------+---------+
| 1204 | prasanth | dev | 30000 | AC | 60000 |
| 1203 | khalil | dev | 30000 | AC | 60000 |
| 1206 | kranthi | admin | 20000 | TP | 120000 |
| 1202 | manisha | cto | 50000 | TP | 120000 |
| 1201 | gopal | manager | 50000 | TP | 120000 |
+-------+-----------+----------+---------+-------+---------+
4、示例2:综合示例窗口函数
----------------------建表并且加载数据
create table website_pv_info(
cookieid string,
createtime string, --day
pv int
) row format delimited
fields terminated by ',';
create table website_url_info (
cookieid string,
createtime string, --访问时间
url string --访问页面
) row format delimited
fields terminated by ',';
load data local inpath '/usr/local/bigdata/website_pv_info.txt' into table website_pv_info;
load data local inpath '/usr/local/bigdata/website_url_info.txt' into table website_url_info;
select * from website_pv_info;
0: jdbc:hive2://server4:10000> select * from website_pv_info;
+---------------------------+-----------------------------+---------------------+
| website_pv_info.cookieid | website_pv_info.createtime | website_pv_info.pv |
+---------------------------+-----------------------------+---------------------+
| cookie1 | 2018-04-10 | 1 |
| cookie1 | 2018-04-11 | 5 |
| cookie1 | 2018-04-12 | 7 |
| cookie1 | 2018-04-13 | 3 |
| cookie1 | 2018-04-14 | 2 |
| cookie1 | 2018-04-15 | 4 |
| cookie1 | 2018-04-16 | 4 |
| cookie2 | 2018-04-10 | 2 |
| cookie2 | 2018-04-11 | 3 |
| cookie2 | 2018-04-12 | 5 |
| cookie2 | 2018-04-13 | 6 |
| cookie2 | 2018-04-14 | 3 |
| cookie2 | 2018-04-15 | 9 |
| cookie2 | 2018-04-16 | 7 |
+---------------------------+-----------------------------+---------------------+
select * from website_url_info;
0: jdbc:hive2://server4:10000> select * from website_url_info;
+----------------------------+------------------------------+-----------------------+
| website_url_info.cookieid | website_url_info.createtime | website_url_info.url |
+----------------------------+------------------------------+-----------------------+
| cookie1 | 2018-04-10 10:00:02 | url2 |
| cookie1 | 2018-04-10 10:00:00 | url1 |
| cookie1 | 2018-04-10 10:03:04 | 1url3 |
| cookie1 | 2018-04-10 10:50:05 | url6 |
| cookie1 | 2018-04-10 11:00:00 | url7 |
| cookie1 | 2018-04-10 10:10:00 | url4 |
| cookie1 | 2018-04-10 10:50:01 | url5 |
| cookie2 | 2018-04-10 10:00:02 | url22 |
| cookie2 | 2018-04-10 10:00:00 | url11 |
| cookie2 | 2018-04-10 10:03:04 | 1url33 |
| cookie2 | 2018-04-10 10:50:05 | url66 |
| cookie2 | 2018-04-10 11:00:00 | url77 |
| cookie2 | 2018-04-10 10:10:00 | url44 |
| cookie2 | 2018-04-10 10:50:01 | url55 |
+----------------------------+------------------------------+-----------------------+
-----窗口聚合函数的使用-----------
--1、求出每个用户总pv数 sum+group by普通常规聚合操作
select cookieid,sum(pv) as total_pv from website_pv_info group by cookieid;
--2、sum+窗口函数 总共有四种用法 注意是整体聚合 还是累积聚合
--sum(...) over( )对表所有行求和
--sum(...) over( order by ... ) 连续累积求和
--sum(...) over( partition by... ) 同组内所行求和
--sum(...) over( partition by... order by ... ) 在每个分组内,连续累积求和
--需求:求出网站总的pv数 所有用户所有访问加起来
--sum(...) over( )对表所有行求和
select cookieid,createtime,pv,
sum(pv) over() as total_pv --注意这里窗口函数是没有partition by 也就是没有分组 全表所有行
from website_pv_info;
0: jdbc:hive2://server4:10000> select cookieid,createtime,pv,
. . . . . . . . . . . . . . .> sum(pv) over() as total_pv --注意这里窗口函数是没有partition by 也就是没有分组 全表所有行
. . . . . . . . . . . . . . .> from website_pv_info;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+-----------+-------------+-----+-----------+
| cookieid | createtime | pv | total_pv |
+-----------+-------------+-----+-----------+
| cookie2 | 2018-04-16 | 7 | 61 |
| cookie2 | 2018-04-15 | 9 | 61 |
| cookie2 | 2018-04-14 | 3 | 61 |
| cookie2 | 2018-04-13 | 6 | 61 |
| cookie2 | 2018-04-12 | 5 | 61 |
| cookie2 | 2018-04-11 | 3 | 61 |
| cookie2 | 2018-04-10 | 2 | 61 |
| cookie1 | 2018-04-16 | 4 | 61 |
| cookie1 | 2018-04-15 | 4 | 61 |
| cookie1 | 2018-04-14 | 2 | 61 |
| cookie1 | 2018-04-13 | 3 | 61 |
| cookie1 | 2018-04-12 | 7 | 61 |
| cookie1 | 2018-04-11 | 5 | 61 |
| cookie1 | 2018-04-10 | 1 | 61 |
+-----------+-------------+-----+-----------+
--需求:求出每天数累积到当天用户总pv
--sum(...) over( order by ... ) 连续累积求和
select cookieid,createtime,pv,
sum(pv) over(order by createtime) as total_pv
from website_pv_info;
0: jdbc:hive2://server4:10000> select cookieid,createtime,pv,
. . . . . . . . . . . . . . .> sum(pv) over(order by createtime) as total_pv
. . . . . . . . . . . . . . .> from website_pv_info;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+-----------+-------------+-----+-----------+
| cookieid | createtime | pv | total_pv |
+-----------+-------------+-----+-----------+
| cookie2 | 2018-04-10 | 2 | 3 |
| cookie1 | 2018-04-10 | 1 | 3 |
| cookie1 | 2018-04-11 | 5 | 11 |
| cookie2 | 2018-04-11 | 3 | 11 |
| cookie2 | 2018-04-12 | 5 | 23 |
| cookie1 | 2018-04-12 | 7 | 23 |
| cookie2 | 2018-04-13 | 6 | 32 |
| cookie1 | 2018-04-13 | 3 | 32 |
| cookie2 | 2018-04-14 | 3 | 37 |
| cookie1 | 2018-04-14 | 2 | 37 |
| cookie2 | 2018-04-15 | 9 | 50 |
| cookie1 | 2018-04-15 | 4 | 50 |
| cookie2 | 2018-04-16 | 7 | 61 |
| cookie1 | 2018-04-16 | 4 | 61 |
+-----------+-------------+-----+-----------+
--需求:求出每个用户总pv数
--sum(...) over( partition by... ),同组内所行求和
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid) as total_pv
from website_pv_info;
0: jdbc:hive2://server4:10000> select cookieid,createtime,pv,
. . . . . . . . . . . . . . .> sum(pv) over(partition by cookieid) as total_pv
. . . . . . . . . . . . . . .> from website_pv_info;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+-----------+-------------+-----+-----------+
| cookieid | createtime | pv | total_pv |
+-----------+-------------+-----+-----------+
| cookie1 | 2018-04-10 | 1 | 26 |
| cookie1 | 2018-04-16 | 4 | 26 |
| cookie1 | 2018-04-15 | 4 | 26 |
| cookie1 | 2018-04-14 | 2 | 26 |
| cookie1 | 2018-04-13 | 3 | 26 |
| cookie1 | 2018-04-12 | 7 | 26 |
| cookie1 | 2018-04-11 | 5 | 26 |
| cookie2 | 2018-04-16 | 7 | 35 |
| cookie2 | 2018-04-15 | 9 | 35 |
| cookie2 | 2018-04-14 | 3 | 35 |
| cookie2 | 2018-04-13 | 6 | 35 |
| cookie2 | 2018-04-12 | 5 | 35 |
| cookie2 | 2018-04-11 | 3 | 35 |
| cookie2 | 2018-04-10 | 2 | 35 |
+-----------+-------------+-----+-----------+
--需求:求出每个用户截止到当天,累积的总pv数
--sum(...) over( partition by... order by ... ),在每个分组内,连续累积求和
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime) as current_total_pv
from website_pv_info;
0: jdbc:hive2://server4:10000> select cookieid,createtime,pv,
. . . . . . . . . . . . . . .> sum(pv) over(partition by cookieid order by createtime) as current_total_pv
. . . . . . . . . . . . . . .> from website_pv_info;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+-----------+-------------+-----+-------------------+
| cookieid | createtime | pv | current_total_pv |
+-----------+-------------+-----+-------------------+
| cookie1 | 2018-04-10 | 1 | 1 |
| cookie1 | 2018-04-11 | 5 | 6 |
| cookie1 | 2018-04-12 | 7 | 13 |
| cookie1 | 2018-04-13 | 3 | 16 |
| cookie1 | 2018-04-14 | 2 | 18 |
| cookie1 | 2018-04-15 | 4 | 22 |
| cookie1 | 2018-04-16 | 4 | 26 |
| cookie2 | 2018-04-10 | 2 | 2 |
| cookie2 | 2018-04-11 | 3 | 5 |
| cookie2 | 2018-04-12 | 5 | 10 |
| cookie2 | 2018-04-13 | 6 | 16 |
| cookie2 | 2018-04-14 | 3 | 19 |
| cookie2 | 2018-04-15 | 9 | 28 |
| cookie2 | 2018-04-16 | 7 | 35 |
+-----------+-------------+-----+-------------------+
5、窗口表达式
1)、介绍
在sum(…) over( partition by… order by … )语法完整的情况下,进行累积聚合操作,默认累积聚合行为是:从第一行聚合到当前行。
Window expression窗口表达式给我们提供了一种控制行范围的能力,比如向前2行,向后3行。
2)语法
关键字是rows between,包括下面这几个选项
- preceding:往前
- following:往后
- current row:当前行
- unbounded:边界
- unbounded preceding:表示从前面的起点
- unbounded following:表示到后面的终点
3)、示例
0: jdbc:hive2://server4:10000> select * from website_pv_info;
+---------------------------+-----------------------------+---------------------+
| website_pv_info.cookieid | website_pv_info.createtime | website_pv_info.pv |
+---------------------------+-----------------------------+---------------------+
| cookie1 | 2018-04-10 | 1 |
| cookie1 | 2018-04-11 | 5 |
| cookie1 | 2018-04-12 | 7 |
| cookie1 | 2018-04-13 | 3 |
| cookie1 | 2018-04-14 | 2 |
| cookie1 | 2018-04-15 | 4 |
| cookie1 | 2018-04-16 | 4 |
| cookie2 | 2018-04-10 | 2 |
| cookie2 | 2018-04-11 | 3 |
| cookie2 | 2018-04-12 | 5 |
| cookie2 | 2018-04-13 | 6 |
| cookie2 | 2018-04-14 | 3 |
| cookie2 | 2018-04-15 | 9 |
| cookie2 | 2018-04-16 | 7 |
+---------------------------+-----------------------------+---------------------+
---窗口表达式
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime) as pv1 --默认从第一行到当前行
from website_pv_info;
--第一行到当前行(第一行+第二行+...+当前行)
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between unbounded preceding and current row) as pv2
from website_pv_info;
0: jdbc:hive2://server4:10000> select cookieid,createtime,pv,
. . . . . . . . . . . . . . .> sum(pv) over(partition by cookieid order by createtime rows between unbounded preceding and current row) as pv2
. . . . . . . . . . . . . . .> from website_pv_info;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+-----------+-------------+-----+------+
| cookieid | createtime | pv | pv2 |
+-----------+-------------+-----+------+
| cookie1 | 2018-04-10 | 1 | 1 |
| cookie1 | 2018-04-11 | 5 | 6 |
| cookie1 | 2018-04-12 | 7 | 13 |
| cookie1 | 2018-04-13 | 3 | 16 |
| cookie1 | 2018-04-14 | 2 | 18 |
| cookie1 | 2018-04-15 | 4 | 22 |
| cookie1 | 2018-04-16 | 4 | 26 |
| cookie2 | 2018-04-10 | 2 | 2 |
| cookie2 | 2018-04-11 | 3 | 5 |
| cookie2 | 2018-04-12 | 5 | 10 |
| cookie2 | 2018-04-13 | 6 | 16 |
| cookie2 | 2018-04-14 | 3 | 19 |
| cookie2 | 2018-04-15 | 9 | 28 |
| cookie2 | 2018-04-16 | 7 | 35 |
+-----------+-------------+-----+------+
--向前3行至当前行(当前行+当前行的前面三行,总计4行)
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between 3 preceding and current row) as pv4
from website_pv_info;
0: jdbc:hive2://server4:10000> select cookieid,createtime,pv,
. . . . . . . . . . . . . . .> sum(pv) over(partition by cookieid order by createtime rows between 3 preceding and current row) as pv4
. . . . . . . . . . . . . . .> from website_pv_info;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+-----------+-------------+-----+------+
| cookieid | createtime | pv | pv4 |
+-----------+-------------+-----+------+
| cookie1 | 2018-04-10 | 1 | 1 |
| cookie1 | 2018-04-11 | 5 | 6 |
| cookie1 | 2018-04-12 | 7 | 13 |
| cookie1 | 2018-04-13 | 3 | 16 |
| cookie1 | 2018-04-14 | 2 | 17 |
| cookie1 | 2018-04-15 | 4 | 16 |
| cookie1 | 2018-04-16 | 4 | 13 |
| cookie2 | 2018-04-10 | 2 | 2 |
| cookie2 | 2018-04-11 | 3 | 5 |
| cookie2 | 2018-04-12 | 5 | 10 |
| cookie2 | 2018-04-13 | 6 | 16 |
| cookie2 | 2018-04-14 | 3 | 17 |
| cookie2 | 2018-04-15 | 9 | 23 |
| cookie2 | 2018-04-16 | 7 | 25 |
+-----------+-------------+-----+------+
--向前3行 向后1行(当前行的前面三行+当前行+当前行后面的一行,总计5行)
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between 3 preceding and 1 following) as pv5
from website_pv_info;
0: jdbc:hive2://server4:10000> select cookieid,createtime,pv,
. . . . . . . . . . . . . . .> sum(pv) over(partition by cookieid order by createtime rows between 3 preceding and 1 following) as pv5
. . . . . . . . . . . . . . .> from website_pv_info;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+-----------+-------------+-----+------+
| cookieid | createtime | pv | pv5 |
+-----------+-------------+-----+------+
| cookie1 | 2018-04-10 | 1 | 6 |
| cookie1 | 2018-04-11 | 5 | 13 |
| cookie1 | 2018-04-12 | 7 | 16 |
| cookie1 | 2018-04-13 | 3 | 18 |
| cookie1 | 2018-04-14 | 2 | 21 |
| cookie1 | 2018-04-15 | 4 | 20 |
| cookie1 | 2018-04-16 | 4 | 13 |
| cookie2 | 2018-04-10 | 2 | 5 |
| cookie2 | 2018-04-11 | 3 | 10 |
| cookie2 | 2018-04-12 | 5 | 16 |
| cookie2 | 2018-04-13 | 6 | 19 |
| cookie2 | 2018-04-14 | 3 | 26 |
| cookie2 | 2018-04-15 | 9 | 30 |
| cookie2 | 2018-04-16 | 7 | 25 |
+-----------+-------------+-----+------+
--当前行至最后一行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between current row and unbounded following) as pv6
from website_pv_info;
0: jdbc:hive2://server4:10000> select cookieid,createtime,pv,
. . . . . . . . . . . . . . .> sum(pv) over(partition by cookieid order by createtime rows between current row and unbounded following) as pv6
. . . . . . . . . . . . . . .> from website_pv_info;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+-----------+-------------+-----+------+
| cookieid | createtime | pv | pv6 |
+-----------+-------------+-----+------+
| cookie1 | 2018-04-10 | 1 | 26 |
| cookie1 | 2018-04-11 | 5 | 25 |
| cookie1 | 2018-04-12 | 7 | 20 |
| cookie1 | 2018-04-13 | 3 | 13 |
| cookie1 | 2018-04-14 | 2 | 10 |
| cookie1 | 2018-04-15 | 4 | 8 |
| cookie1 | 2018-04-16 | 4 | 4 |
| cookie2 | 2018-04-10 | 2 | 35 |
| cookie2 | 2018-04-11 | 3 | 33 |
| cookie2 | 2018-04-12 | 5 | 30 |
| cookie2 | 2018-04-13 | 6 | 25 |
| cookie2 | 2018-04-14 | 3 | 19 |
| cookie2 | 2018-04-15 | 9 | 16 |
| cookie2 | 2018-04-16 | 7 | 7 |
+-----------+-------------+-----+------+
--第一行到最后一行 也就是分组内的所有行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between unbounded preceding and unbounded following) as pv6
from website_pv_info;
6、窗口排序函数–row_number家族
用于给每个分组内的数据打上排序的标号
注意窗口排序函数不支持窗口表达式
row_number:在每个分组中,为每行分配一个从1开始的唯一序列号,递增,不考虑重复;
rank: 在每个分组中,为每行分配一个从1开始的序列号,考虑重复,挤占后续位置;
dense_rank: 在每个分组中,为每行分配一个从1开始的序列号,考虑重复,不挤占后续位置;

-----窗口排序函数
SELECT
cookieid,
createtime,
pv,
RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn1,
DENSE_RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn2,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn3
FROM website_pv_info
WHERE cookieid = 'cookie1';
0: jdbc:hive2://server4:10000> SELECT
. . . . . . . . . . . . . . .> cookieid,
. . . . . . . . . . . . . . .> createtime,
. . . . . . . . . . . . . . .> pv,
. . . . . . . . . . . . . . .> RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn1,
. . . . . . . . . . . . . . .> DENSE_RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn2,
. . . . . . . . . . . . . . .> ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn3
. . . . . . . . . . . . . . .> FROM website_pv_info
. . . . . . . . . . . . . . .> WHERE cookieid = 'cookie1';
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+-----------+-------------+-----+------+------+------+
| cookieid | createtime | pv | rn1 | rn2 | rn3 |
+-----------+-------------+-----+------+------+------+
| cookie1 | 2018-04-12 | 7 | 1 | 1 | 1 |
| cookie1 | 2018-04-11 | 5 | 2 | 2 | 2 |
| cookie1 | 2018-04-16 | 4 | 3 | 3 | 3 |
| cookie1 | 2018-04-15 | 4 | 3 | 3 | 4 |
| cookie1 | 2018-04-13 | 3 | 5 | 4 | 5 |
| cookie1 | 2018-04-14 | 2 | 6 | 5 | 6 |
| cookie1 | 2018-04-10 | 1 | 7 | 6 | 7 |
+-----------+-------------+-----+------+------+------+
--需求:找出每个用户访问pv最多的Top3 重复并列的不考虑
SELECT * from
(SELECT
cookieid,
createtime,
pv,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY pv DESC) AS seq
FROM website_pv_info) tmp
where tmp.seq <4;
0: jdbc:hive2://server4:10000> SELECT * from
. . . . . . . . . . . . . . .> (SELECT
. . . . . . . . . . . . . . .> cookieid,
. . . . . . . . . . . . . . .> createtime,
. . . . . . . . . . . . . . .> pv,
. . . . . . . . . . . . . . .> ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY pv DESC) AS seq
. . . . . . . . . . . . . . .> FROM website_pv_info) tmp
. . . . . . . . . . . . . . .> where tmp.seq <4;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+---------------+-----------------+---------+----------+
| tmp.cookieid | tmp.createtime | tmp.pv | tmp.seq |
+---------------+-----------------+---------+----------+
| cookie1 | 2018-04-12 | 7 | 1 |
| cookie1 | 2018-04-11 | 5 | 2 |
| cookie1 | 2018-04-16 | 4 | 3 |
| cookie2 | 2018-04-15 | 9 | 1 |
| cookie2 | 2018-04-16 | 7 | 2 |
| cookie2 | 2018-04-13 | 6 | 3 |
+---------------+-----------------+---------+----------+
7、窗口排序函数–ntile
将每个分组内的数据分为指定的若干个桶里(分为若干个部分),并且为每一个桶分配一个桶编号。
如果不能平均分配,则优先分配较小编号的桶,并且各个桶中能放的行数最多相差1。
应用场景
如果数据排序后分为三部分,只关心其中的一部分,如何将这中间的三分之一数据拿出来呢?NTILE函数即可以满足
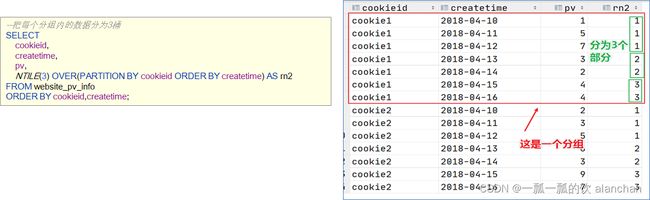
--把每个分组内的数据分为3桶
SELECT
cookieid,
createtime,
pv,
NTILE(3) OVER(PARTITION BY cookieid ORDER BY createtime) AS rn2
FROM website_pv_info
ORDER BY cookieid,createtime;
0: jdbc:hive2://server4:10000> SELECT
. . . . . . . . . . . . . . .> cookieid,
. . . . . . . . . . . . . . .> createtime,
. . . . . . . . . . . . . . .> pv,
. . . . . . . . . . . . . . .> NTILE(3) OVER(PARTITION BY cookieid ORDER BY createtime) AS rn2
. . . . . . . . . . . . . . .> FROM website_pv_info
. . . . . . . . . . . . . . .> ORDER BY cookieid,createtime;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+-----------+-------------+-----+------+
| cookieid | createtime | pv | rn2 |
+-----------+-------------+-----+------+
| cookie1 | 2018-04-10 | 1 | 1 |
| cookie1 | 2018-04-11 | 5 | 1 |
| cookie1 | 2018-04-12 | 7 | 1 |
| cookie1 | 2018-04-13 | 3 | 2 |
| cookie1 | 2018-04-14 | 2 | 2 |
| cookie1 | 2018-04-15 | 4 | 3 |
| cookie1 | 2018-04-16 | 4 | 3 |
| cookie2 | 2018-04-10 | 2 | 1 |
| cookie2 | 2018-04-11 | 3 | 1 |
| cookie2 | 2018-04-12 | 5 | 1 |
| cookie2 | 2018-04-13 | 6 | 2 |
| cookie2 | 2018-04-14 | 3 | 2 |
| cookie2 | 2018-04-15 | 9 | 3 |
| cookie2 | 2018-04-16 | 7 | 3 |
+-----------+-------------+-----+------+
--需求:统计每个用户pv数最多的前3分之1天。
--理解:将数据根据cookieid分 根据pv倒序排序 排序之后分为3个部分 取第一部分
SELECT * from
(SELECT
cookieid,
createtime,
pv,
NTILE(3) OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn
FROM website_pv_info) tmp
where rn =1;
0: jdbc:hive2://server4:10000> SELECT * from
. . . . . . . . . . . . . . .> (SELECT
. . . . . . . . . . . . . . .> cookieid,
. . . . . . . . . . . . . . .> createtime,
. . . . . . . . . . . . . . .> pv,
. . . . . . . . . . . . . . .> NTILE(3) OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn
. . . . . . . . . . . . . . .> FROM website_pv_info) tmp where rn =1;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+---------------+-----------------+---------+---------+
| tmp.cookieid | tmp.createtime | tmp.pv | tmp.rn |
+---------------+-----------------+---------+---------+
| cookie1 | 2018-04-12 | 7 | 1 |
| cookie1 | 2018-04-11 | 5 | 1 |
| cookie1 | 2018-04-16 | 4 | 1 |
| cookie2 | 2018-04-15 | 9 | 1 |
| cookie2 | 2018-04-16 | 7 | 1 |
| cookie2 | 2018-04-13 | 6 | 1 |
+---------------+-----------------+---------+---------+
select * from website_url_info;
8、窗口分析函数
1)、语法
- LAG(col,n,DEFAULT) ,用于统计窗口内往上第n行值
第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL); - LEAD(col,n,DEFAULT) ,用于统计窗口内往下第n行值
第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL); - FIRST_VALUE,取分组内排序后,截止到当前行,第一个值
- LAST_VALUE,取分组内排序后,截止到当前行,最后一个值
2)、示例
-----------窗口分析函数----------
--LAG
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
LAG(createtime,1,'1970-01-01 00:00:00') OVER(PARTITION BY cookieid ORDER BY createtime) AS last_1_time,
LAG(createtime,2) OVER(PARTITION BY cookieid ORDER BY createtime) AS last_2_time
FROM website_url_info;
0: jdbc:hive2://server4:10000> SELECT cookieid,
. . . . . . . . . . . . . . .> createtime,
. . . . . . . . . . . . . . .> url,
. . . . . . . . . . . . . . .> ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
. . . . . . . . . . . . . . .> LAG(createtime,1,'1970-01-01 00:00:00') OVER(PARTITION BY cookieid ORDER BY createtime) AS last_1_time,
. . . . . . . . . . . . . . .> LAG(createtime,2) OVER(PARTITION BY cookieid ORDER BY createtime) AS last_2_time
. . . . . . . . . . . . . . .> FROM website_url_info;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+-----------+----------------------+---------+-----+----------------------+----------------------+
| cookieid | createtime | url | rn | last_1_time | last_2_time |
+-----------+----------------------+---------+-----+----------------------+----------------------+
| cookie1 | 2018-04-10 10:00:00 | url1 | 1 | 1970-01-01 00:00:00 | NULL |
| cookie1 | 2018-04-10 10:00:02 | url2 | 2 | 2018-04-10 10:00:00 | NULL |
| cookie1 | 2018-04-10 10:03:04 | 1url3 | 3 | 2018-04-10 10:00:02 | 2018-04-10 10:00:00 |
| cookie1 | 2018-04-10 10:10:00 | url4 | 4 | 2018-04-10 10:03:04 | 2018-04-10 10:00:02 |
| cookie1 | 2018-04-10 10:50:01 | url5 | 5 | 2018-04-10 10:10:00 | 2018-04-10 10:03:04 |
| cookie1 | 2018-04-10 10:50:05 | url6 | 6 | 2018-04-10 10:50:01 | 2018-04-10 10:10:00 |
| cookie1 | 2018-04-10 11:00:00 | url7 | 7 | 2018-04-10 10:50:05 | 2018-04-10 10:50:01 |
| cookie2 | 2018-04-10 10:00:00 | url11 | 1 | 1970-01-01 00:00:00 | NULL |
| cookie2 | 2018-04-10 10:00:02 | url22 | 2 | 2018-04-10 10:00:00 | NULL |
| cookie2 | 2018-04-10 10:03:04 | 1url33 | 3 | 2018-04-10 10:00:02 | 2018-04-10 10:00:00 |
| cookie2 | 2018-04-10 10:10:00 | url44 | 4 | 2018-04-10 10:03:04 | 2018-04-10 10:00:02 |
| cookie2 | 2018-04-10 10:50:01 | url55 | 5 | 2018-04-10 10:10:00 | 2018-04-10 10:03:04 |
| cookie2 | 2018-04-10 10:50:05 | url66 | 6 | 2018-04-10 10:50:01 | 2018-04-10 10:10:00 |
| cookie2 | 2018-04-10 11:00:00 | url77 | 7 | 2018-04-10 10:50:05 | 2018-04-10 10:50:01 |
+-----------+----------------------+---------+-----+----------------------+----------------------+
--LEAD
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
LEAD(createtime,1,'1970-01-01 00:00:00') OVER(PARTITION BY cookieid ORDER BY createtime) AS next_1_time,
LEAD(createtime,2) OVER(PARTITION BY cookieid ORDER BY createtime) AS next_2_time
FROM website_url_info;
0: jdbc:hive2://server4:10000> SELECT cookieid,
. . . . . . . . . . . . . . .> createtime,
. . . . . . . . . . . . . . .> url,
. . . . . . . . . . . . . . .> ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
. . . . . . . . . . . . . . .> LEAD(createtime,1,'1970-01-01 00:00:00') OVER(PARTITION BY cookieid ORDER BY createtime) AS next_1_time,
. . . . . . . . . . . . . . .> LEAD(createtime,2) OVER(PARTITION BY cookieid ORDER BY createtime) AS next_2_time
. . . . . . . . . . . . . . .> FROM website_url_info;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+-----------+----------------------+---------+-----+----------------------+----------------------+
| cookieid | createtime | url | rn | next_1_time | next_2_time |
+-----------+----------------------+---------+-----+----------------------+----------------------+
| cookie1 | 2018-04-10 10:00:00 | url1 | 1 | 2018-04-10 10:00:02 | 2018-04-10 10:03:04 |
| cookie1 | 2018-04-10 10:00:02 | url2 | 2 | 2018-04-10 10:03:04 | 2018-04-10 10:10:00 |
| cookie1 | 2018-04-10 10:03:04 | 1url3 | 3 | 2018-04-10 10:10:00 | 2018-04-10 10:50:01 |
| cookie1 | 2018-04-10 10:10:00 | url4 | 4 | 2018-04-10 10:50:01 | 2018-04-10 10:50:05 |
| cookie1 | 2018-04-10 10:50:01 | url5 | 5 | 2018-04-10 10:50:05 | 2018-04-10 11:00:00 |
| cookie1 | 2018-04-10 10:50:05 | url6 | 6 | 2018-04-10 11:00:00 | NULL |
| cookie1 | 2018-04-10 11:00:00 | url7 | 7 | 1970-01-01 00:00:00 | NULL |
| cookie2 | 2018-04-10 10:00:00 | url11 | 1 | 2018-04-10 10:00:02 | 2018-04-10 10:03:04 |
| cookie2 | 2018-04-10 10:00:02 | url22 | 2 | 2018-04-10 10:03:04 | 2018-04-10 10:10:00 |
| cookie2 | 2018-04-10 10:03:04 | 1url33 | 3 | 2018-04-10 10:10:00 | 2018-04-10 10:50:01 |
| cookie2 | 2018-04-10 10:10:00 | url44 | 4 | 2018-04-10 10:50:01 | 2018-04-10 10:50:05 |
| cookie2 | 2018-04-10 10:50:01 | url55 | 5 | 2018-04-10 10:50:05 | 2018-04-10 11:00:00 |
| cookie2 | 2018-04-10 10:50:05 | url66 | 6 | 2018-04-10 11:00:00 | NULL |
| cookie2 | 2018-04-10 11:00:00 | url77 | 7 | 1970-01-01 00:00:00 | NULL |
+-----------+----------------------+---------+-----+----------------------+----------------------+
--FIRST_VALUE
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
FIRST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime) AS first1
FROM website_url_info;
0: jdbc:hive2://server4:10000> SELECT cookieid,
. . . . . . . . . . . . . . .> createtime,
. . . . . . . . . . . . . . .> url,
. . . . . . . . . . . . . . .> ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
. . . . . . . . . . . . . . .> FIRST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime) AS first1
. . . . . . . . . . . . . . .> FROM website_url_info;
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+-----------+----------------------+---------+-----+---------+
| cookieid | createtime | url | rn | first1 |
+-----------+----------------------+---------+-----+---------+
| cookie1 | 2018-04-10 10:00:00 | url1 | 1 | url1 |
| cookie1 | 2018-04-10 10:00:02 | url2 | 2 | url1 |
| cookie1 | 2018-04-10 10:03:04 | 1url3 | 3 | url1 |
| cookie1 | 2018-04-10 10:10:00 | url4 | 4 | url1 |
| cookie1 | 2018-04-10 10:50:01 | url5 | 5 | url1 |
| cookie1 | 2018-04-10 10:50:05 | url6 | 6 | url1 |
| cookie1 | 2018-04-10 11:00:00 | url7 | 7 | url1 |
| cookie2 | 2018-04-10 10:00:00 | url11 | 1 | url11 |
| cookie2 | 2018-04-10 10:00:02 | url22 | 2 | url11 |
| cookie2 | 2018-04-10 10:03:04 | 1url33 | 3 | url11 |
| cookie2 | 2018-04-10 10:10:00 | url44 | 4 | url11 |
| cookie2 | 2018-04-10 10:50:01 | url55 | 5 | url11 |
| cookie2 | 2018-04-10 10:50:05 | url66 | 6 | url11 |
| cookie2 | 2018-04-10 11:00:00 | url77 | 7 | url11 |
+-----------+----------------------+---------+-----+---------+
--LAST_VALUE
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
LAST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime) AS last1
FROM website_url_info;
五、Sampling抽样函数
抽样、采样,一种用于识别和分析数据中的子集的技术,以发现整个数据集中的模式和趋势。
在HQL中,可以通过三种方式采样数据:随机采样,存储桶表采样和块采样。
1、Random 随机抽样
随机抽样使用rand()函数来确保随机获取数据,LIMIT来限制抽取的数据个数。
优点是随机,缺点是速度不快,尤其表数据多的时候。
-
推荐DISTRIBUTE+SORT,可以确保数据也随机分布在mapper和reducer之间,使得底层执行有效率
-
ORDER BY语句也可以达到相同的目的,但是表现不好,因为ORDER BY是全局排序,只会启动运行一个reducer
-
示例
--数据表
select * from student;
--需求:随机抽取2个学生的情况进行查看
SELECT * FROM student
DISTRIBUTE BY rand() SORT BY rand() LIMIT 2;
--使用order by+rand也可以实现同样的效果 但是效率不高
SELECT * FROM student
ORDER BY rand() LIMIT 2;
2、Block 基于数据块抽样
Block块采样允许随机获取n行数据、百分比数据或指定大小的数据。
采样粒度是HDFS块大小。
优点是速度快,缺点是不随机。
---block抽样
--根据行数抽样
SELECT * FROM student TABLESAMPLE(1 ROWS);
SELECT * FROM users_bucket_sort TABLESAMPLE(1 ROWS);
--根据数据大小百分比抽样
SELECT * FROM student TABLESAMPLE(50 PERCENT);
SELECT * FROM users_bucket_sort TABLESAMPLE(50 PERCENT);
--根据数据大小抽样
--支持数据单位 b/B, k/K, m/M, g/G
SELECT * FROM student TABLESAMPLE(1k);
SELECT * FROM users_bucket_sort TABLESAMPLE(1m);
3、Bucket table 基于分桶表抽样
这是一种特殊的采样方法,针对分桶表进行了优化。
优点是既随机速度也很快。
- 语法
TABLESAMPLE (BUCKET x OUT OF y [ON colname])
- 示例
---bucket table抽样
--总文件大小有1.1G(1260+行),分为10桶
create table users(
rownum int,
id string,
username string,
password string,
phone string,
email string,
createday string
)
row format delimited fields terminated by '\t';
--导入1260万数据
--创建桶表
CREATE TABLE users_bucket_sort(
rownum int,
id string,
username string,
password string,
phone string,
email string,
createday string
)
CLUSTERED BY(username) sorted by (id) INTO 10 BUCKETS;
--桶表插入数据
insert into users_bucket_sort select * from users;
--TABLESAMPLE (BUCKET x OUT OF y [ON colname])
--1、y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。
--例如,table总共分了4份(4个bucket),当y=2时,抽取(4/2=)2个bucket的数据,当y=8时,抽取(4/8=)1/2个bucket的数据。
--2、x表示从哪个bucket开始抽取。
--例如,table总bucket数为4,tablesample(bucket 4 out of 4),表示总共抽取(4/4=)1个bucket的数据,抽取第4个bucket的数据。
--注意:x的值必须小于等于y的值,否则FAILED:Numerator should not be bigger than denominator in sample clause for table stu_buck
--3、ON colname表示基于什么抽
--ON rand()表示随机抽
--ON 分桶字段 表示基于分桶字段抽样 效率更高 推荐
--根据整行数据进行抽样
SELECT * FROM users_bucket_sort TABLESAMPLE(BUCKET 1 OUT OF 500000 ON rand());
--根据分桶字段进行抽样 效率更高
describe formatted users_bucket_sort ;
SELECT * FROM users_bucket_sort TABLESAMPLE(BUCKET 1 OUT OF 500000 ON username);
0: jdbc:hive2://server4:10000> SELECT * FROM users_bucket_sort TABLESAMPLE(BUCKET 1 OUT OF 500000 ON username);
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+---------------------------+-----------------------+-----------------------------+-----------------------------+--------------------------+--------------------------+------------------------------+
| users_bucket_sort.rownum | users_bucket_sort.id | users_bucket_sort.username | users_bucket_sort.password | users_bucket_sort.phone | users_bucket_sort.email | users_bucket_sort.createday |
+---------------------------+-----------------------+-----------------------------+-----------------------------+--------------------------+--------------------------+------------------------------+
| 9801921 | 1031178248 | alan52314 | 84466 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 9863613 | 1036482206 | alan52314 | 710173 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 10264809 | 1071356555 | alan52314 | 752370 | 13977776789 | alan.chan.chn@163.com | 2021-12-25 00:00:00.0 |
| 10342478 | 1077853253 | alan52314 | 576675 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 10505881 | 1100168203 | alan52314 | 477137 | 13977776789 | alan.chan.chn@163.com | 2021-12-25 00:00:00.0 |
| 10648068 | 1114316346 | alan52314 | 573302 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 11048102 | 1148836368 | alan52314 | 871112 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 11239982 | 1165836817 | alan52314 | 554216 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 11362843 | 1176470955 | alan52314 | 207748 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 11421889 | 1181545106 | alan52314 | 186464 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 11696725 | 1215543654 | alan52314 | 272234 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 11831536 | 1227136006 | alan52314 | 564323 | 13977776789 | alan.chan.chn@163.com | 2021-12-25 00:00:00.0 |
| 11850459 | 1228576890 | alan52314 | 623030 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 11853176 | 1228766834 | alan52314 | 124131 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 702191 | 140821328 | alan52314 | 806808 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 812945 | 146886034 | alan52314 | 810351 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 1078761 | 162407548 | alan52314 | 654657 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 1316209 | 176112428 | alan52314 | 742020 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 1950580 | 222618362 | alan52314 | 820080 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 2086161 | 230663448 | alan52314 | 157886 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 2112003 | 232076351 | alan52314 | 36435 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 2625960 | 261687306 | alan52314 | 372375 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 2832663 | 273470168 | alan52314 | 223350 | 13977776789 | alan.chan.chn@163.com | 2021-12-25 00:00:00.0 |
| 3172342 | 295442255 | alan52314 | 847721 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 3271147 | 308367438 | alan52314 | 225310 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 4243314 | 400435181 | alan52314 | 481605 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 4271088 | 404678216 | alan52314 | 581575 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 4385581 | 414526701 | alan52314 | 267756 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 4602971 | 433127802 | alan52314 | 678166 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 4821500 | 452074674 | alan52314 | 377844 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 5142209 | 479852791 | alan52314 | 576834 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 5367910 | 508806324 | alan52314 | 853134 | 13977776789 | alan.chan.chn@163.com | 2021-12-25 00:00:00.0 |
| 5455093 | 516561571 | alan52314 | 381221 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 6170091 | 577881016 | alan52314 | 711480 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 6251791 | 585305561 | alan52314 | 177047 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 6390994 | 610081841 | alan52314 | 27200 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 6919733 | 707357165 | alan52314 | 486232 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 7576882 | 763858240 | alan52314 | 410784 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 7852259 | 787653561 | alan52314 | 183183 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 7984811 | 808865904 | alan52314 | 125207 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 8058334 | 815575511 | alan52314 | 148088 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 8570937 | 859794785 | alan52314 | 108752 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 8613505 | 863216285 | alan52314 | 717061 | 13977776789 | alan.chan.chn@163.com | 2021-12-25 00:00:00.0 |
| 8903815 | 888381546 | alan52314 | 751567 | 13977776789 | alan.chan.chn@163.com | 2021-12-25 00:00:00.0 |
| 8989061 | 912035215 | alan52314 | 878101 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 9072828 | 926913226 | alan52314 | 887441 | 13977776789 | alan.chan.chn@163.com | 2021-12-25 00:00:00.0 |
| 9372303 | 978484975 | alan52314 | 544367 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
+---------------------------+-----------------------+-----------------------------+-----------------------------+--------------------------+--------------------------+------------------------------+
47 rows selected (88.273 seconds)
以上,介绍了hive的explode函数、Lateral View侧视图、聚合函数、窗口函数和抽样函数内容及详细的使用示例。