12、Hive优化-文件存储格式和压缩格式优化与job执行优化(执行计划、MR属性、join、优化器、谓词下推和数据倾斜优化)详细介绍及示例
Apache Hive 系列文章
1、apache-hive-3.1.2简介及部署(三种部署方式-内嵌模式、本地模式和远程模式)及验证详解
2、hive相关概念详解–架构、读写文件机制、数据存储
3、hive的使用示例详解-建表、数据类型详解、内部外部表、分区表、分桶表
4、hive的使用示例详解-事务表、视图、物化视图、DDL(数据库、表以及分区)管理详细操作
5、hive的load、insert、事务表使用详解及示例
6、hive的select(GROUP BY、ORDER BY、CLUSTER BY、SORT BY、LIMIT、union、CTE)、join使用详解及示例
7、hive shell客户端与属性配置、内置运算符、函数(内置运算符与自定义UDF运算符)
8、hive的关系运算、逻辑预算、数学运算、数值运算、日期函数、条件函数和字符串函数的语法与使用示例详解
9、hive的explode、Lateral View侧视图、聚合函数、窗口函数、抽样函数使用详解
10、hive综合示例:数据多分隔符(正则RegexSerDe)、url解析、行列转换常用函数(case when、union、concat和explode)详细使用示例
11、hive综合应用示例:json解析、窗口函数应用(连续登录、级联累加、topN)、拉链表应用
12、Hive优化-文件存储格式和压缩格式优化与job执行优化(执行计划、MR属性、join、优化器、谓词下推和数据倾斜优化)详细介绍及示例
13、java api访问hive操作示例
文章目录
- Apache Hive 系列文章
- 一、Hive中文件格式及数据压缩的优化
-
- 1、文件格式
-
- 1)、文件格式-概述
- 2)、文件格式-TextFile
- 3)、文件格式-SequenceFile
- 4)、文件格式-Parquet
- 5)、文件格式-ORC
- 2、数据压缩
-
- 1)、数据压缩-概述
- 2)、Hive中压缩配置
- 3)、Hive中压缩测试
- 3、优化
-
- 1)、避免小文件生成
- 2)、ORC文件索引
-
- 1、Row Group Index
- 2、Bloom Filter Index
- 3)、ORC矢量化查询
- 二、Job作业执行优化
-
- 1、Explain查询计划
- 2、MapReduce属性优化
-
- 1)、本地模式
- 2)、并行执行
- 3、Join优化
-
- 1)、Map Join
- 2)、Reduce Join
- 3)、Bucket Join
- 4、优化器
-
- 1)、关联优化
- 2)、优化器引擎
- 5、谓词下推(PPD)
- 6、数据倾斜
-
- 1)、Group by、Count(distinct)
- 2)、Join
本文介绍了hive的数据存储和压缩形式与优化方向、通过job作业方向的几种(比如查询计划、MR属性优化、join优化、优化器、谓词下推和数据倾斜)优化方式。
本文依赖是hive环境可用。
本文分为2个部分,即数据存储与数据压缩、job执行优化。
一、Hive中文件格式及数据压缩的优化
1、文件格式
1)、文件格式-概述
Hive数据存储的本质还是HDFS,所有的数据读写都基于HDFS的文件来实现;
为了提高对HDFS文件读写的性能,Hive提供了多种文件存储格式:TextFile、SequenceFile、ORC、Parquet等;
不同的文件存储格式具有不同的存储特点,有的可以降低存储空间,有的可以提高查询性能。

Hive的文件格式在建表时指定,默认是TextFile。
2)、文件格式-TextFile
TextFile是Hive中默认的文件格式,存储形式为按行存储。
工作中最常见的数据文件格式就是TextFile文件,几乎所有的原始数据生成都是TextFile格式,所以Hive设计时考虑到为了避免各种编码及数据错乱的问题,选用了TextFile作为默认的格式。
建表时不指定存储格式即为TextFile,导入数据时把数据文件拷贝至HDFS不进行处理。

3)、文件格式-SequenceFile
SequenceFile是Hadoop里用来存储序列化的键值对即二进制的一种文件格式。
SequenceFile文件也可以作为MapReduce作业的输入和输出,hive也支持这种格式。

--sequencefile
create table tb_sogou_seq(
stime string,
userid string,
keyword string,
clickorder string,
url string
)
row format delimited fields terminated by '\t'
stored as sequencefile;
insert into table tb_sogou_seq
select * from tb_sogou_source;
下面图示是插入原始txt文件大概有1.07G1260万条数据存储成sequencefile的文件大小。

4)、文件格式-Parquet
Parquet是一种支持嵌套结构的列式存储文件格式。作为大数据系统中OLAP查询的优化方案,它已经被多种查询引擎原生支持,并且部分高性能引擎将其作为默认的文件存储格式。
通过数据编码和压缩,以及映射下推和谓词下推功能,Parquet的性能也较之其它文件格式有所提升。

下图是互联网上关于其的性能比较


--Parquet格式
create table tb_sogou_parquet(
stime string,
userid string,
keyword string,
clickorder string,
url string
)
row format delimited fields terminated by '\t'
stored as parquet;
insert into table tb_sogou_parquet
select * from tb_sogou_source;
下面图示是插入原始txt文件大概有1.07G1260万条数据存储成sequencefile的文件大小。

5)、文件格式-ORC
ORC(OptimizedRC File)文件格式也是一种Hadoop生态圈中的列式存储格式;
它的产生早在2013年初,最初产生自Apache Hive,用于降低Hadoop数据存储空间和加速Hive查询速度。

--ORC格式
create table tb_sogou_orc(
stime string,
userid string,
keyword string,
clickorder string,
url string
)
row format delimited fields terminated by '\t'
stored as orc;
insert into table tb_sogou_orc
select * from tb_sogou_source;
下面图示是插入原始txt文件大概有1.07G1260万条数据存储成sequencefile的文件大小。

2、数据压缩
1)、数据压缩-概述
Hive底层运行MapReduce程序时,磁盘I/O操作、网络数据传输、shuffle和merge要花大量的时间,尤其是数据规模很大和工作负载密集的情况下。
鉴于磁盘I/O和网络带宽是Hadoop的宝贵资源,数据压缩对于节省资源、最小化磁盘I/O和网络传输非常有帮助。
Hive压缩实际上说的就是MapReduce的压缩。
该部分在hadoop专栏中有关于数据压缩的详细说明,请参考链接:7、大数据中常见的文件存储格式以及hadoop中支持的压缩算法

- 压缩的优点
减小文件存储所占空间
加快文件传输效率,从而提高系统的处理速度
降低IO读写的次数 - 压缩的缺点
使用数据时需要先对文件解压,加重CPU负荷,压缩算法越复杂,解压时间越长
Hive中的压缩就是使用了Hadoop中的压缩实现的,所以Hadoop中支持的压缩在Hive中都可以直接使用。 - Hadoop中支持的压缩算法:


要想在Hive中使用压缩,需要对MapReduce和Hive进行相应的配置
2)、Hive中压缩配置
--开启hive中间传输数据压缩功能
--1)开启hive中间传输数据压缩功能
set hive.exec.compress.intermediate=true;
--2)开启mapreduce中map输出压缩功能
set mapreduce.map.output.compress=true;
--3)设置mapreduce中map输出数据的压缩方式
set mapreduce.map.output.compress.codec= org.apache.hadoop.io.compress.SnappyCodec;
--开启Reduce输出阶段压缩
--1)开启hive最终输出数据压缩功能
set hive.exec.compress.output=true;
--2)开启mapreduce最终输出数据压缩
set mapreduce.output.fileoutputformat.compress=true;
--3)设置mapreduce最终数据输出压缩方式
set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec;
--4)设置mapreduce最终数据输出压缩为块压缩
set mapreduce.output.fileoutputformat.compress.type=BLOCK;
3)、Hive中压缩测试
数据可以自己造,尽可能的多一点数据以便查看结果。
- textfile格式snappy压缩
--创建表,指定为textfile格式,并使用snappy压缩
create table tb_sogou_snappy
stored as textfile
as select * from tb_sogou_source;
查看结果数据

- orc格式snappy压缩
--创建表,指定为orc格式,并使用snappy压缩
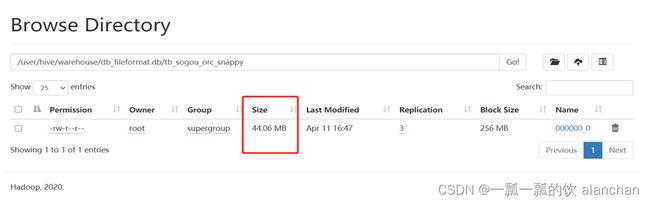
create table tb_sogou_orc_snappy
stored as orc tblproperties ("orc.compress"="SNAPPY")
as select * from tb_sogou_source;
查看结果数据
3、优化
1)、避免小文件生成
Hive的存储本质还是HDFS,HDFS是不利于小文件存储的,因为每个小文件会产生一条元数据信息,并且不利用MapReduce的处理,MapReduce中每个小文件会启动一个MapTask计算处理,导致资源的浪费,所以在使用Hive进行处理分析时,要尽量避免小文件的生成。
Hive中提供了一个特殊的机制,可以自动的判断是否是小文件,如果是小文件可以自动将小文件进行合并。
-- 如果hive的程序,只有maptask,将MapTask产生的所有小文件进行合并
set hive.merge.mapfiles=true;
-- 如果hive的程序,有Map和ReduceTask,将ReduceTask产生的所有小文件进行合并
set hive.merge.mapredfiles=true;
-- 每一个合并的文件的大小(244M)
set hive.merge.size.per.task=256000000;
-- 平均每个文件的大小,如果小于这个值就会进行合并(15M)
set hive.merge.smallfiles.avgsize=16000000;
如果遇到数据处理的输入是小文件的情况,怎么解决呢?
Hive中也提供一种输入类CombineHiveInputFormat,用于将小文件合并以后,再进行处理。
-- 设置Hive中底层MapReduce读取数据的输入类:将所有文件合并为一个大文件作为输入
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
2)、ORC文件索引
在使用ORC文件时,为了加快读取ORC文件中的数据内容,ORC提供了两种索引机制:Row Group Index 和 Bloom Filter Index可以帮助提高查询ORC文件的性能
当用户写入数据时,可以指定构建索引,当用户查询数据时,可以根据索引提前对数据进行过滤,避免不必要的数据扫描。
1、Row Group Index
一个ORC文件包含一个或多个stripes(groups of row data),每个stripe中包含了每个column的min/max值的索引数据;
当查询中有大于等于小于的操作时,会根据min/max值,跳过扫描不包含的stripes。而其中为每个stripe建立的包含min/max值的索引,就称为Row Group Index行组索引,也叫min-max Index大小对比索引,或者Storage Index。

建立ORC格式表时,指定表参数’orc.create.index’=’true’之后,便会建立Row Group Index;
为了使Row Group Index有效利用,向表中加载数据时,必须对需要使用索引的字段进行排序
--1、开启索引配置
set hive.optimize.index.filter=true;
--2、创建表并制定构建索引
create table tb_sogou_orc_index
stored as orc tblproperties ("orc.create.index"="true")
as select * from tb_sogou_source
distribute by stime
sort by stime;
--3、当进行范围或者等值查询(<,>,=)时就可以基于构建的索引进行查询
select count(*) from tb_sogou_orc_index where stime > '12:00:00' and stime < '18:00:00';
2、Bloom Filter Index
建表时候通过表参数orc.bloom.filter.columns=columnName……来指定为哪些字段建立BloomFilter索引,在生成数据的时候,会在每个stripe中,为该字段建立BloomFilter的数据结构;
当查询条件中包含对该字段的等值过滤时候,先从BloomFilter中获取以下是否包含该值,如果不包含,则跳过该stripe。
--创建表指定创建布隆索引
create table tb_sogou_orc_bloom
stored as orc tblproperties ("orc.create.index"="true","orc.bloom.filter.columns"="stime,userid")
as select * from tb_sogou_source
distribute by stime
sort by stime;
--stime的范围过滤可以走row group index,userid的过滤可以走bloom filter index
select
count(*)
from tb_sogou_orc_index
where stime > '12:00:00' and stime < '18:00:00'
and userid = '3933365481995287' ;
3)、ORC矢量化查询
Hive的默认查询执行引擎一次处理一行,而矢量化查询执行是一种Hive针对ORC文件操作的特性,目的是按照每批1024行读取数据,并且一次性对整个记录整合(而不是对单条记录)应用操作,提升了像过滤、联合、聚合等等操作的性能。
注意:要使用矢量化查询执行,就必须以ORC格式存储数据。
-- 开启矢量化查询
set hive.vectorized.execution.enabled = true;
set hive.vectorized.execution.reduce.enabled = true;
二、Job作业执行优化
1、Explain查询计划
HiveQL是一种类SQL的语言,从编程语言规范来说是一种声明式语言,用户会根据查询需求提交声明式的HQL查询,而Hive会根据底层计算引擎将其转化成Mapreduce/Tez/Spark的job。
explain命令可以帮助用户了解一条HQL语句在底层的实现过程。通俗来说就是Hive打算如何去做这件事。
explain会解析HQL语句,将整个HQL语句的实现步骤、依赖关系、实现过程都会进行解析返回,可以了解一条HQL语句在底层是如何实现数据的查询及处理的过程,辅助用户对Hive进行优化。
官网:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Explain
语法命令如下
EXPLAIN [FORMATTED|EXTENDED|DEPENDENCY|AUTHORIZATION|] query
-- FORMATTED:对执行计划进行格式化,返回JSON格式的执行计划
-- EXTENDED:提供一些额外的信息,比如文件的路径信息
-- DEPENDENCY:以JSON格式返回查询所依赖的表和分区的列表
-- AUTHORIZATION:列出需要被授权的条目,包括输入与输出
-- 每个查询计划由以下几个部分组成
-- The Abstract Syntax Tree for the query:抽象语法树(AST):Hive使用Antlr解析生成器,可以自动地将HQL生成为抽象语法树
-- The dependencies between the different stages of the plan:Stage依赖关系:会列出运行查询划分的stage阶段以及之间的依赖关系
-- The description of each of the stages:Stage内容:包含了每个stage非常重要的信息,比如运行时的operator和sort orders等具体的信息
示例
explain select count(*) as cnt from tb_emp where deptno = '10';



2、MapReduce属性优化
1)、本地模式
使用Hive的过程中,有一些数据量不大的表也会转换为MapReduce处理,提交到集群时,需要申请资源,等待资源分配,启动JVM进程,再运行Task,一系列的过程比较繁琐,本身数据量并不大,提交到YARN运行返回会导致性能较差的问题。
Hive为了解决这个问题,延用了MapReduce中的设计,提供本地计算模式,允许程序不提交给YARN,直接在本地运行,以便于提高小数据量程序的性能。
- 配置
-- 开启本地模式
set hive.exec.mode.local.auto = true;

2)、并行执行
- Hive在实现HQL计算运行时,会解析为多个Stage,有时候Stage彼此之间有依赖关系,只能挨个执行,但是在一些别的场景下,很多的Stage之间是没有依赖关系的
- 例如Union语句,Join语句等等,这些Stage没有依赖关系,但是Hive依旧默认挨个执行每个Stage,这样会导致性能非常差,我们可以通过修改参数,开启并行执行,当多个Stage之间没有依赖关系时,允许多个Stage并行执行,提高性能
-- 开启Stage并行化,默认为false
SET hive.exec.parallel=true;
-- 指定并行化线程数,默认为8
SET hive.exec.parallel.thread.number=16;
3、Join优化
Hive Join的底层是通过MapReduce来实现的,Hive实现Join时,为了提高MapReduce的性能,提供了多种Join方案来实现。例如适合小表Join大表的Map Join,大表Join大表的Reduce Join,以及大表Join的优化方案Bucket Join等。
1)、Map Join
应用场景:适合于小表join大表或者小表Join小表
将小的那份数据给每个MapTask的内存都放一份完整的数据,大的数据每个部分都可以与小数据的完整数据进行join,底层不需要经过shuffle,需要占用内存空间存放小的数据文件
2)、Reduce Join
应用场景:适合于大表Join大表
- 将两张表的数据在shuffle阶段利用shuffle的分组来将数据按照关联字段进行合并必须经过shuffle,利用Shuffle过程中的分组来实现关联
- Hive会自动判断是否满足Map Join,如果不满足Map Join,则自动执行Reduce Join
3)、Bucket Join
应用场景:适合于大表Join大表
将两张表按照相同的规则将数据划分、根据对应的规则的数据进行join、减少了比较次数,提高了性能
- 使用Bucket Join
语法:clustered by colName
参数:set hive.optimize.bucketmapjoin = true;
要求:分桶字段 = Join字段 ,桶的个数相等或者成倍数 - 使用Sort Merge Bucket Join(SMB)
基于有序的数据Join
语法:clustered by colName sorted by (colName)
参数
set hive.optimize.bucketmapjoin = true;
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.auto.convert.sortmerge.join.noconditionaltask=true;
要求:分桶字段 = Join字段 = 排序字段 ,桶的个数相等或者成倍数
4、优化器
1)、关联优化
当一个程序中如果有一些操作彼此之间有关联性,是可以在一个MapReduce中实现的,但是Hive不会选择,Hive会使用两个MapReduce来完成这两个操作。
例如:当我们执行 select …… from table group by id order by id desc。该SQL语句转换为MapReduce时有两种方案来实现:
- 方案一
第一个MapReduce做group by,经过shuffle阶段对id做分组
第二个MapReduce对第一个MapReduce的结果做order by,经过shuffle阶段对id进行排序 - 方案二
因为都是对id处理,可以使用一个MapReduce的shuffle既可以做分组也可以排序
在这种场景下,Hive会默认选择用第一种方案来实现,这样会导致性能相对较差。可以在Hive中开启关联优化,对有关联关系的操作进行解析时,可以尽量放在同一个MapReduce中实现。
--配置:
set hive.optimize.correlation=true;
2)、优化器引擎
Hive默认的优化器在解析一些聚合统计类的处理时,底层解析的方案有时候不是最佳的方案。
例如当前有一张表【共1000条数据】,id构建了索引,id =100值有900条
需求:查询所有id = 100的数据,SQL语句为:select * from table where id = 100;
-
方案一
由于id这一列构建了索引,索引默认的优化器引擎RBO,会选择先从索引中查询id = 100的值所在的位置,再根据索引记录位置去读取对应的数据,但是这并不是最佳的执行方案。 -
方案二
有id=100的值有900条,占了总数据的90%,这时候是没有必要检索索引以后再检索数据的,可以直接检索数据返回,这样的效率会更高,更节省资源,这种方式就是CBO优化器引擎会选择的方案。 -
CBO优化器
RBO、rule basic optimise:基于规则的优化器,根据设定好的规则来对程序进行优化
CBO、cost basic optimise:基于代价的优化器,根据不同场景所需要付出的代价来合适选择优化的方案
对数据的分布的信息【数值出现的次数,条数,分布】来综合判断用哪种处理的方案是最佳方案
Hive中支持RBO与CBO这两种引擎,默认使用的是RBO优化器引擎。
根据不同的应用场景,可以选择CBO,设置方式如下
set hive.cbo.enable=true;
set hive.compute.query.using.stats=true;
set hive.stats.fetch.column.stats=true;
- Analyze分析器
用于提前运行一个MapReduce程序将表或者分区的信息构建一些元数据【表的信息、分区信息、列的信息】,搭配CBO引擎一起使用
-- 构建分区信息元数据
ANALYZE TABLE tablename
[PARTITION(partcol1[=val1], partcol2[=val2], ...)]
COMPUTE STATISTICS [noscan];
-- 构建列的元数据
ANALYZE TABLE tablename
[PARTITION(partcol1[=val1], partcol2[=val2], ...)]
COMPUTE STATISTICS FOR COLUMNS ( columns name1, columns name2...) [noscan];
-- 查看元数据
DESC FORMATTED [tablename] [columnname];
--分析优化器
--构建表中分区数据的元数据信息
ANALYZE TABLE tb_login_part PARTITION(logindate) COMPUTE STATISTICS;
--构建表中列的数据的元数据信息
ANALYZE TABLE tb_login_part COMPUTE STATISTICS FOR COLUMNS userid;
--查看构建的列的元数据
desc formatted tb_login_part userid;
5、谓词下推(PPD)
谓词用来描述或判定客体性质、特征或者客体之间关系的词项。比如"3 大于 2"中"大于"是一个谓词。
谓词下推Predicate Pushdown(PPD)基本思想是将过滤表达式尽可能移动至靠近数据源的位置,以使真正执行时能直接跳过无关的数据。
简单点说就是在不影响最终结果的情况下,尽量将过滤条件提前执行。
Hive中谓词下推后,过滤条件会下推到map端,提前执行过滤,减少map到reduce的传输数据,提升整体性能。
-- 开启参数【默认开启】
hive.optimize.ppd=true;
-- 推荐形式1的方式,先过滤再join。
select a.id,a.value1,b.value2 from table1 a
join (select b.* from table2 b where b.ds>='20181201' and b.ds<'20190101') c
on (a.id=c.id)
select a.id,a.value1,b.value2 from table1 a
join table2 b on a.id=b.id
where b.ds>='20181201' and b.ds<'20190101'

- 规则
1、对于Join(Inner Join)、Full outer Join,条件写在on后面,还是where后面,性能上面没有区别;
2、对于Left outer Join ,右侧的表写在on后面、左侧的表写在where后面,性能上有提高;
3、对于Right outer Join,左侧的表写在on后面、右侧的表写在where后面,性能上有提高;
4、当条件分散在两个表时,谓词下推可按上述结论2和3自由组合。

6、数据倾斜
数据倾斜的现象就是数据分配不均衡。
1)、Group by、Count(distinct)
当程序中出现group by或者count(distinct)等分组聚合的场景时,如果数据本身是倾斜的,根据MapReduce的Hash分区规则,肯定会出现数据倾斜的现象。
根本原因是因为分区规则导致的,所以可以通过以下几种方案来解决group by导致的数据倾斜的问题。
- 方案一:开启Map端聚合
hive.map.aggr=true;
通过减少shuffle数据量和Reducer阶段的执行时间,避免每个Task数据差异过大导致数据倾斜
- 方案二:实现随机分区
select * from table distribute by rand();
distribute by用于指定底层按照哪个字段作为Key实现分区、分组等
通过rank函数随机值实现随机分区,避免数据倾斜
- 方案三:数据倾斜时自动负载均衡
hive.groupby.skewindata=true;
开启该参数以后,当前程序会自动通过两个MapReduce来运行
第一个MapReduce自动进行随机分布到Reducer中,每个Reducer做部分聚合操作,输出结果
第二个MapReduce将上一步聚合的结果再按照业务(group by key)进行处理,保证相同的分布到一起,最终聚合得到结果
2)、Join
Join操作时,如果两张表比较大,无法实现Map Join,只能走Reduce Join,那么当关联字段中某一种值过多的时候依旧会导致数据倾斜的问题;
面对Join产生的数据倾斜,核心的思想是尽量避免Reduce Join的产生,优先使用Map Join来实现;
但往往很多的Join场景不满足Map Join的需求,那么可以以下几种方案来解决Join产生的数据倾斜问题:
- 方案一:提前过滤,将大数据变成小数据,实现Map Join
select a.id,a.value1,b.value2 from table1 a
join (select b.* from table2 b where b.ds>='20181201' and b.ds<'20190101') c
on (a.id=c.id)
-
方案二:使用Bucket Join
如果使用方案一,过滤后的数据依旧是一张大表,那么最后的Join依旧是一个Reduce Join
这种场景下,可以将两张表的数据构建为桶表,实现Bucket Map Join,避免数据倾斜 -
方案三:使用Skew Join
Skew Join是Hive中一种专门为了避免数据倾斜而设计的特殊的Join过程
这种Join的原理是将Map Join和Reduce Join进行合并,如果某个值出现了数据倾斜,就会将产生数据倾斜的数据单独使用Map Join来实现
其他没有产生数据倾斜的数据由Reduce Join来实现,这样就避免了Reduce Join中产生数据倾斜的问题,最终将Map Join的结果和Reduce Join的结果进行Union合并。
-- 开启运行过程中skewjoin
set hive.optimize.skewjoin=true;
-- 如果这个key的出现的次数超过这个范围
set hive.skewjoin.key=100000;
-- 在编译时判断是否会产生数据倾斜
set hive.optimize.skewjoin.compiletime=true;
-- 不合并,提升性能
set hive.optimize.union.remove=true;
-- 如果Hive的底层走的是MapReduce,必须开启这个属性,才能实现不合并
set mapreduce.input.fileinputformat.input.dir.recursive=true;
以上,介绍了hive的数据存储和压缩形式与优化方向、通过job作业方向的集中优化方式。