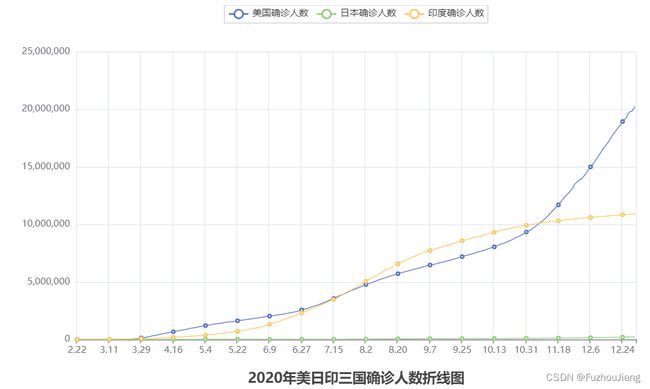
pyecharts案例一——生成美日印三国疫情确诊人数折线图
数据获取
首先从美国的疫情数据的json字符串中获取出我们需要的日期和确诊数量数据
,可以使用json格式化工具里面的试图查看嵌套结构,从而获取我们期望的数据。
再强调{} 是字典,[]是列表
完整代码
import json
from pyecharts.charts import Line
from pyecharts.options import TitleOpts, LabelOpts
f_us = open("./美国.txt", "r", encoding="UTF-8")
us_data = f_us.read() # 获取文件中的全部内容
f_jp = open("./日本.txt", "r", encoding="UTF-8")
jp_data = f_jp.read() # 获取文件中的全部内容
f_in = open("./印度.txt", "r", encoding="UTF-8")
in_data = f_in.read() # 获取文件中的全部内容
# 去掉不符合JSON规范的开头结尾
us_data = us_data.replace("jsonp_1629344292311_69436(", "")
us_data = us_data[:-2]
jp_data = jp_data.replace("jsonp_1629350871167_29498(", "")
jp_data = jp_data[:-2]
in_data = in_data.replace("jsonp_1629350745930_63180(", "")
in_data = in_data[:-2]
# json 转为python的字段
us_dict = json.loads(us_data)
jp_dict = json.loads(jp_data)
in_dict = json.loads(in_data)
# 获取trend的value
us_trend_data = us_dict['data'][0]['trend']
jp_trend_data = jp_dict['data'][0]['trend']
in_trend_data = in_dict['data'][0]['trend']
# 获取日期数据,只取2020年数据
us_x_data = us_trend_data['updateDate'][:314]
jp_x_data = jp_trend_data['updateDate'][:314]
in_x_data = in_trend_data['updateDate'][:314]
#获取确诊人数的数据,只取2020年数据
us_y_data = us_trend_data['list'][0]['data'][:314]
jp_y_data = jp_trend_data['list'][0]['data'][:314]
in_y_data = in_trend_data['list'][0]['data'][:314]
# 生成图表
line = Line()
# 添加x轴数据,即日期
line.add_xaxis(us_x_data)
# 添加y轴数据
line.add_yaxis("美国确诊人数", us_y_data, label_opts=LabelOpts(is_show=False))
line.add_yaxis("日本确诊人数", jp_y_data, label_opts=LabelOpts(is_show=False))
line.add_yaxis("印度确诊人数", in_y_data, label_opts=LabelOpts(is_show=False))
# 设置全局选项
line.set_global_opts(
title_opts=TitleOpts(title="2020年美日印三国确诊人数折线图", pos_left="center", pos_bottom="1%")
)
line.render()
f_us.close()
f_jp.close()
f_in.close()
结果