NumPy入门
NumPy介绍
NumPy(Numerical Python)是Python的一个开源的数值计算库。可用来存储和处理大型矩阵,比Python自身的嵌套列表结构要高效得多,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库,包括数学、逻辑、形状操作、排序、选择、输入输出、离散傅里叶变换、基本线性代数、基本统计运算和随机模拟等等
几乎所有从事Python工作的数据分析师都利用NumPy的强大功能
第一章 Jupyter Notebook

Anaconda
Anaconda是一个开源的Python发行版本,Anaconda包括Conda、Python以及一大堆安装好的工具包,比如:numpy、pandas等,是数据分析、机器学习过程中常用的库
Anaconda包括了Jupyter Notebook编辑器和IPython解释器,我们可以在Jupyter Notebook中使用IPython解释器编写代码
IPython
IPython是一个基于Python的交互式解释器,提供了强大的编辑和交互功能
在命令窗口提示符中输入ipython,即可使用

Jupyter Notebook
Jupyter Notebook(此前被称为 IPython Notebook)是一个交互式笔记本,支持运行40多种编程语言
Jupyter Notebook的本质是一个Web应用程序,便于创建和共享文学化程序文档,支持实时代码、数学方程、可视化和markdown
用途包括:数据清理和转换、数值模拟、统计建模、机器学习等
Jupyter Notebook:集文本、代码、图像、公式的展现于一体的超级python web界面
两种模式
Jupyter Notebook有两种键盘输入模式
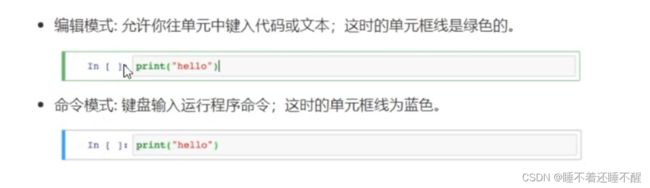
快捷键
编辑模式:
Tab: 代码补全或缩进
Shift+Tab: 提示
Shift+Enter: 运行本单元,选中下一单元
Ctrl+Enter: 运行本单元
Alt+Enter: 运行本单元,在下面插入一单元
命令模式(按键Esc开启):
Shift+Enter:运行本单元,选中下个单元
Ctrl+Enter:运行本单元
Alt+Enter:运行本单元,在其下面插入新的单元
Y:单元转入代码状态
M:单元转入markdown状态
A:在上方插入新单元
B:在下方插入新单元
DD:删除选中的单元
其他常用快捷键:
Ctrl+A:全选
Ctrl+Z:撤销
Ctrl+C:复制
Ctrl+V:粘贴
Ctrl+/:注释或者取消注释
IPython的帮助文档和自动补全
1.通过以下命令来获得帮助文档:
help(len)
2.使用问号:
len?
3.使用双引号 :
len??
与单引号不同的是,双引号会尽量显示源码

自动补全:
1.tab:代码补全或缩进

2.shift+tab:可以查看函数参数
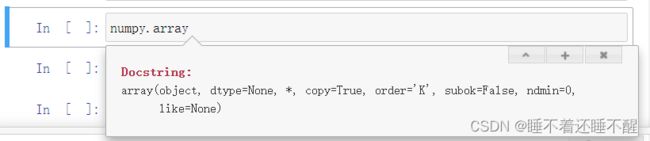
IPython魔法命令
1.运行外部python文件

使用魔法命令:%run *.ipynb

尤其要注意的是,当我们使用魔法命令执行了一个外部文件时,该文件的函数就能在当前会话中使用

2.用下面命令计算statement的运行时间:
%time statement
%time一般用来统计耗时较长的代码的运行时长

用timeit 计算statement的平均运行时间:
%timeit statement
timeit会多次运行statement,最后得到一个更为精确的预期运行时间

也可以自己指定运行次数和每次运行循环的次数:

可以使用两个百分号来测试多行代码的平均运行时间:

3.其他魔法命令
查看当前会话的所有变量和函数名称的详细信息
%whos
返回一个字符串列表,里面元素是当前会话的所有变量与函数名称:
%who_ls
4.安装包
使用pip命令安装,比如:
pip install numpy
如果安装不了,可以加感叹号强制安装
!pip install numpy
5.更多魔法命令
列出所有魔法命令
lsmagic
Jupyter Notebook练习题
练习1:封装函数求闰年
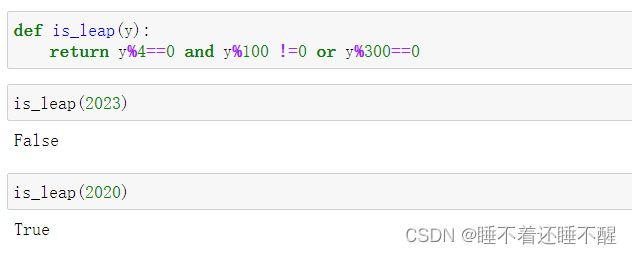
练习2:封装函数实现冒泡排序

第二章 NumPy

开始使用NumPy
数据分析三剑客:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.imread()读取图片的数字
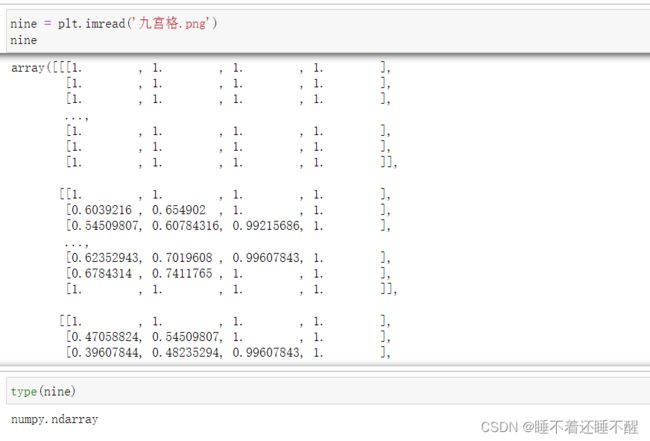
plt.imshow(nine)显示图片:

图片:三维数据是彩色
二维数据是黑白
视频:四维数据(x,886,886,4)
一切皆数据,一切皆矩阵
创建ndarray数组
1.使用np.array() 由python list创建
n=np.array(list)
注意:
numpy默认ndarray的所有元素的类型是相同的
如果传进来的列表中包含不同的类型,则统一为同一类型,优先级:str>float>int
ndarray的常见数据类型:
int:int8、unit8、int16、int32、int64
float:float16、float32、float64
str:字符串

2.使用np的routines函数创建
1)np.ones(shape,dtype=None,order='C')
创建一个所有元素都为1的多维数组
参数说明:
shape:形状
dtype=None:元素类型
order:{'C','F'},可选,默认值:C是否在内存中以行主(C-风格)或列主(Fortran-风格)顺序存储多维数组

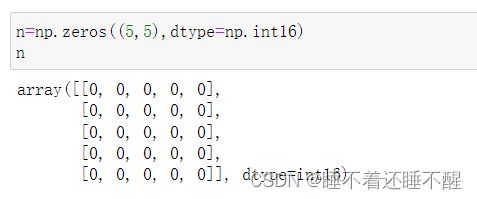
2)np.zeros(shape,dtype=float,order='C')
创建一个所有元素都为0的多维数组
参数说明:
shape:形状
dtype=None:元素类型
3)np.full(shape,fill_value,dtype=None,order='C')
创建一个所有元素都为指定元素的多维数组
参数说明:
shape:形状
fill_value:填充值
dtype=None:元素类型

4)np.eye(N,M=None,k=0,dtype=float)
主对角线为1其他位置为0的二维数组
参数说明:
N:行数
M:列数,默认为None,表示和行数一样
k=0:向右偏移0个位置
dtype=None:元素类型
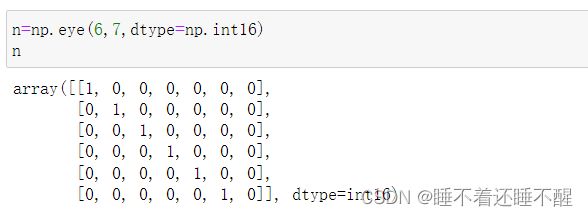
k=2:向右偏移2个位置

5)np.linspace(start,stop,num=50,endpoint=True,retstep=False,dtype=None)
创建一个等差数列
参数说明:
start:开始值
stop:结束值
num=50:等差数列中默认有50个数
endpoint=True:是否包含结束值
retstep=False:是否返回等差值(步长)
dtype=None:元素类型

6)np.arrange([start,]stop,[step,]dtype=None)
创建一个数值范围的数组
和Python中的range功能类似
参数说明:
start:开始值(可选)
stop:结束值(不包含)
step:步长(可选)
dtype=None:元素类型

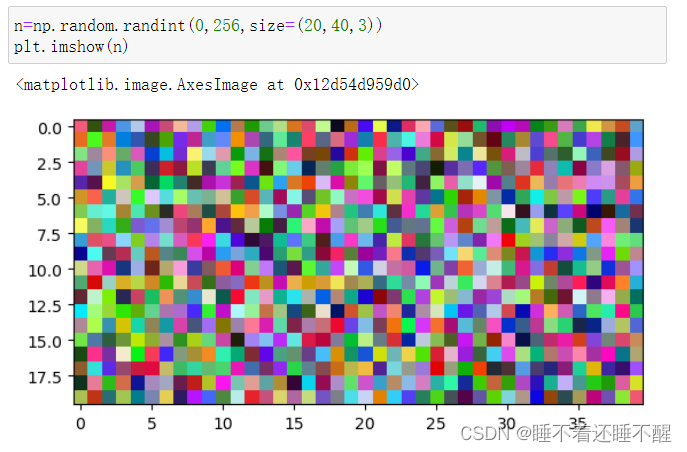
7)np.random.randint(low,high=None,size=None,dtype='l')
创建一个随机整数的多维数组
参数说明:
low:最小值
high=None:最大值
high=None时,生成的数值在[0,low)区间内
如果使用high这个值,则生成的数值在[low,high)区间
size=None:数组形状,默认只输出一个随机值
dtype=None:元素类型

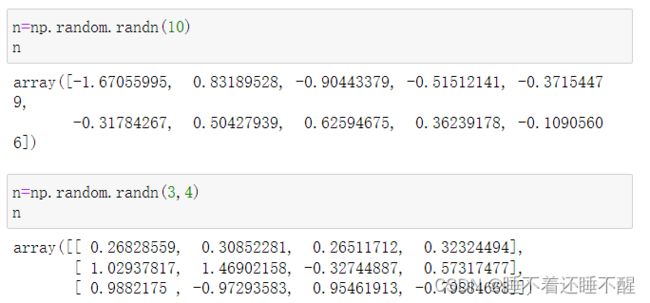
8)np.random.randn(d0,d1,...,dn)
创建一个服从标准正态分布的多维数组
标准正态分布又称为u分布,是以0为均数、以1为标准差的正态分布,记为(0,1)标准正态分布,在0左右出现的概率最大,越远离出现的概率越低
创建一个所有元素都为1的多维数组
参数说明:
dn:第n个维度的数值
9)np.random.normal(loc=0.0,scale=1.0,size=None)
创建一个服从正态分布的多维数组
参数说明:
loc=0.0:均值,对应着正态分布的中心
scale:标准差,对应分布的宽度,scale越大,正态分布的曲线越矮胖,scale越小,曲线越高瘦
size=None:数组形状


10)np.random.random(size=None)
创建一个元素为0~1(左闭右开)的随机数的多维数组
参数说明:
size=None:数组形状

11)np.random.rand(d0,d1,...,dn)
创建一个元素为0~1(左闭右开)的随机数的多维数组
和np.random.random功能类似
参数说明:
dn:第n个维度的数值

ndarray常用属性
ndim:维度
shape:形状(各维度的长度)
size:总长度
dtype:元素类型
shape:有几个数字就表示几维,比如(421,776,4)表示三维

NumPy的基本操作
1.索引
一维与列表完全一致,多维时同理


2.切片
按行:
一维:

高维:

按列:

NumPy案例——图片翻转

原图:
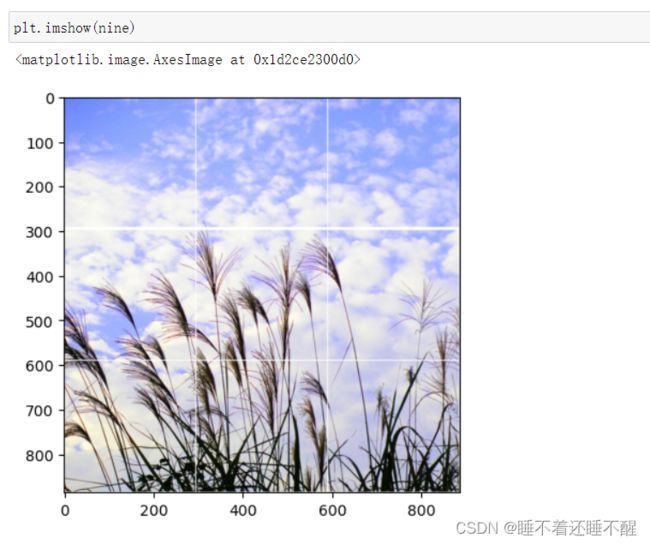
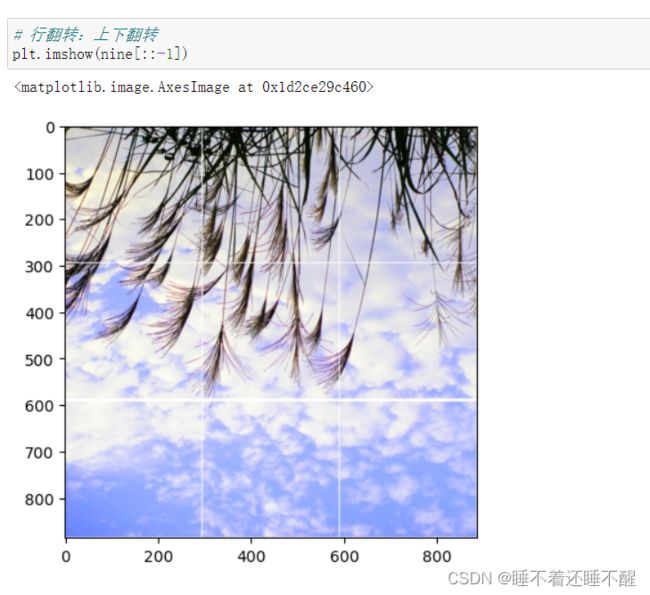
行翻转:
列翻转:

颜色翻转

模糊处理

NumPy数组的变形、级联和拆分
ndarray变形:reshape
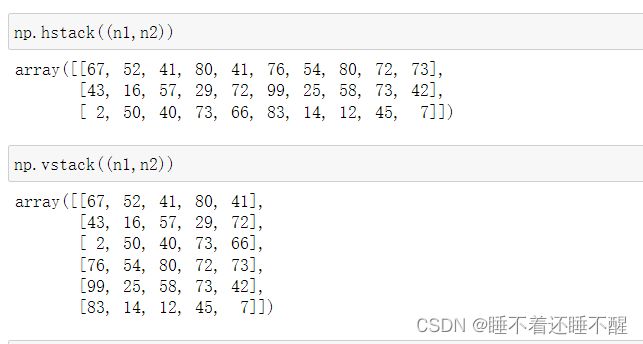
ndarray级联:concatenate、np.hstack、np.vstack
ndarray拆分:np.split、np.vsplit、np.hsplit
变形

级联
np.concatenate()
参数是列表或元组
级联的数组维度必须相同
可通过axis参数改变级联的方向

np.hstack水平级联
np.vstack垂直级联
拆分

按照指定的位置拆分:
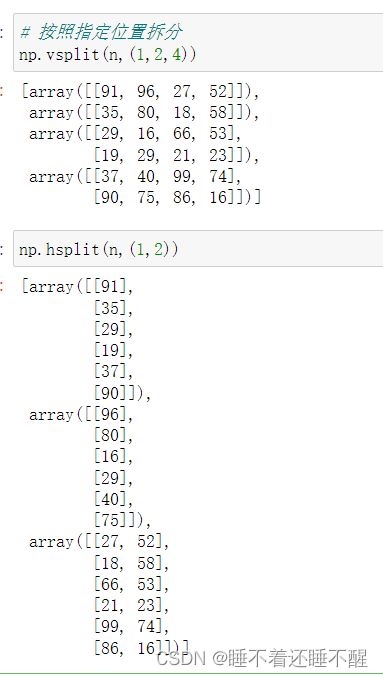
split可以做水平或垂直拆分
axis=0:行
axis=1:列
注意:数组的拆分应满足均匀拆分,否则会报错

数组的赋值与深拷贝
copy()函数创建副本
copy()相当于深拷贝,修改n2不会改变n的值
赋值相当于浅拷贝,n2和n指向同一片内存空间,n2[0]=100会修改n的n[0]

NumPy聚合操作
求和:np.sum

其他操作:
np.max(n) #最大值
np.min(n) #最小值
np.mean(n) #平均值
np.average(n) #平均值
np.median(n) #中位数
np.percentile(n,q=50) #百分位数,q=50表示中位数
n=n.reshape(-1)
display(n)
np.argmax(n) #第一个最大值对应的下标
np.argmin(n) #第一个最小值对应的下标
np.argwhere(n==np.max(n)) #按条件找到所有最大值的下标
np.power(n,3) #次方
np.std(n) #标准差
np.var(n) #方差np.sum和np.nansum
nan:数值类型,not a number:不是一个正常的数值,表示空
np.nan:float类型

NumPy矩阵操作
基本的矩阵操作:
算术运算符:加减乘除
矩阵和矩阵之间运算
数与矩阵运算
矩阵乘积
矩阵与矩阵相乘 np.dot
广播机制
为不同维度的矩阵尽量提供运算可能性
规则一:为缺失的维度补维度
规则二:缺失元素用已有值填充
基本矩阵操作

矩阵的加减乘除

线性代数
矩阵积 np.dot()
第一个矩阵的列数等于第二个矩阵的行数

其他矩阵操作:

广播机制
用已有数据复制填充


原理:

其他常见数学操作
abs、sqrt、square、exp、log、sin、cos、tan、round、ceil、floor、cumsum
数组的快速排序
Ndarray排序:
np.sort():不改变原数组

ndarray.sort():改变原数组,不多占内存空间

ndarray文件操作
保存数组:
save:保存ndarray到一个npy文件
savez:将多个array保存到一个npz文件中

csv、txt文件的读取操作

练习题一




练习题二





完结撒花~~❀