初探 transformer
大部分QA的问题都可以使用seq2seq来实现。或者说大多数的NLP问题都可以使用seq2seq模型来解决。
但是呢最好的办法还是对具体的问题作出特定的模型训练。
概述
Transformer就是一种seq2seq模型。
我们先看一下seq2seq这个模型的大体框架(其实就是一个编码器和一个解码器):
编码器
我们先看编码器(并结合transformer)这个部分
我们将这个encode进行细化,看看里面是什么样子的,下图就是encode的内部:
可以看出encode里面是有若干个Block模块构成的,而这个模块是由transformer来构成的。
**注意:**上述Block的self-attention的实现在原始的模型不是那么简单的,而是更加复杂,实现的结果如下图所示:
那么transformer的encode部分又可以重新定义如下(对add和norm部分作出了解释,就是上图中提到的):
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g0DVomf0-1686470176975)(null)]
进步一了解这个模型上的一些小改动
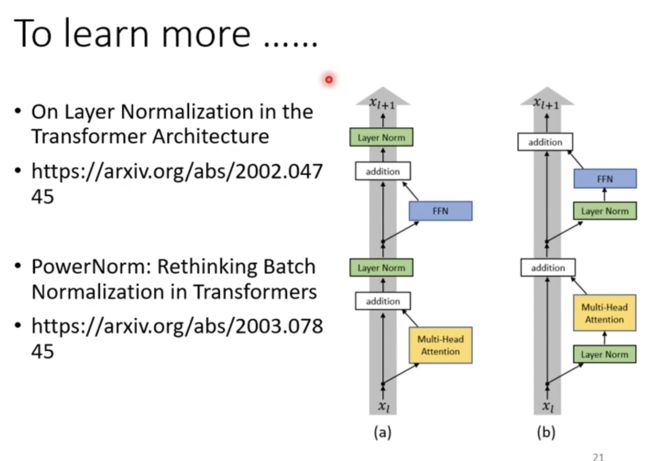
解码器
解码器主要是有两种形式,一种是Autoregressive。
Autoregressive
先放一个动画:
https://vdn3.vzuu.com/SD/cf255d34-ec82-11ea-acfd-5ab503a75443.mp4?disable_local_cache=1&auth_key=1636876035-0-0-1b8200d56431047742a6772de99b7384&f=mp4&bu=pico&expiration=1636876035&v=tx
参考: https://www.zhihu.com/question/337886108/answer/893002189
简单介绍
这里我们直接从encode的输出来看结果是什么样子的或者说如何输出结果的,这里以翻译为例:
Begin是用于判断输入的开始的,这样可以便于定位。
接下来我们来看输出的结果是什么:
根据不同的语言,输出的结果就是一个字点集向量(如果是中文,我们可以输出2000个常用词;如果是英文,那么输出的结果既可以是26个英文字母,也可以是常见的词汇;因此要因情况而定)。
那么接下来就来看看下一步的输出是怎么得到的——是将前面的输出作为下一步的输入(也就是当前的输入是前一步的输出):
说到这里,这种处理方法存在一个问题:如果前一步的翻译结果是错误的,那么不就是后面的每一步都是错误的吗,也就是一步错步步错?那么这种情况该怎么解决呢?
这个问题我们先忽略掉,后面再讲这个问题
内部结构
那么我们接下来看这个Decoder的里面是什么样子的:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xhyXKXRL-1686470177458)(null)]
与Encode的对比
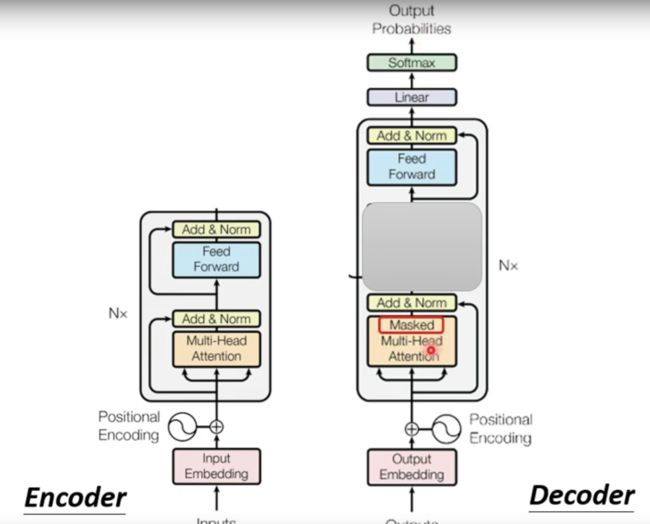
根据上图可以看出,Decoder和Encoder不同的地方在于多了一个阴影遮挡的地方,并且还在第一个多头注意力的地方添加了一个Masked 。那么这个是什么呢?
Masked
下面这张图是我们前面讨论的Self-attention机制的处理:
下面是所谓的Masked Self-attention的处理方法:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fIp6fTKf-1686470176987)(null)]
从图中可以看出,与Self- attention不同的地方在于,Masked Self-attention是只考虑前面的数据,而不是像Self-attention一样将全部的输入一起考虑来输出的。
讲得更具体一点,接下来进步一看看如何计算的:
这是原来的,我们需要将下面的框起来的地方给去掉:

现在就变成了下面的这个样子:
那么问题来了,为什么这样做?为什么要做一个Masked?
可以从Decode的实现过程来考虑分析这个问题。
因为在Decode的输出过程中,是靠着一个个的前面的输出作为下一步的输入来考虑的,这也就是说,当前的输出仅需要考虑前面的输出既可,也就不用再考虑全部的输入了。
如何停止
现在我们思考这样的问题——输出如何停止呢?
因为Self-attention是靠前面的输出来作为输入的,也就是说,如果输出不停止,输入也就不会停止,那么最后就会一直输出:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8OCsVnFj-1686470176965)(null)]
解决的方法就是在输出的字典里面添加一个结束字段——"Stop Token"
通过这个Token,可以很好地解决输出的问题了,这样就可以以一定的概率来判断是否是可以停止输出了。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-efOOqnv0-1686470176941)(null)]
Non-Autoregressive
先直接上图,看Autoregressive和Non-Autoregressive两个的区别:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gx2m5eqV-1686470176954)(null)]
从图上可以看出,Autoregressive是一个接着一个的输出,但是Non-Autoregressive的输出是根据全部的输入一起输出而得到最好的结果。
那么NAT如何确定输出的长度的呢?有下面两种方法:
- 将Decoder的输入内容输入一个predictor,通过这个predictor来判断最后的输出长度;
- 将所有的输入送入到Decoder中,然后根据输出结果里面有没有“Stop token”,如果有一个的话,就将后面的输出全部舍弃。
那么NAT的优点是什么呢?
- 可以并行计算;
- 可以控制输出的长度;
另外,NAT现在是一个研究的热门方向,这里就不做详细的阐述了。
编码器和解码器的连接
至此可以考虑如何连接了,先从宏观的角度上来看一下解码器和编码器的连接情况:
从上图中可以看出,encoder的输出是在第二阶段作为了decoder的收入。
接下来具体来看是Cross attention是如何工作的:
下图是一开始的处理,先收入一个Begin Token用于输出第一个单词
接下来是第二个输出:
这里插一句,Cross Attention其实早在Self- attention之前就已经存在了,并且还已经实际应用在预测当中。
扩展问题
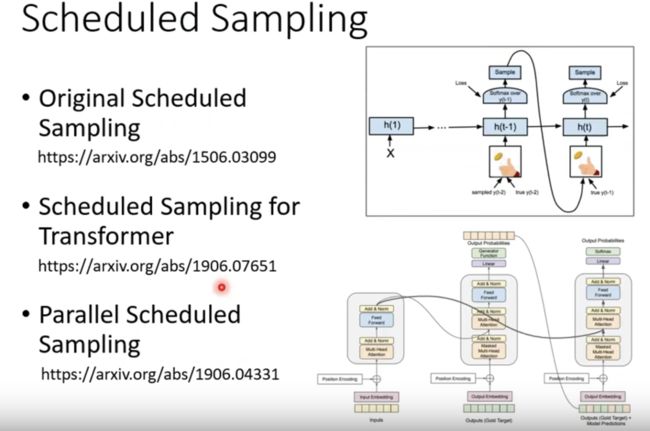
前面在提到Decoder的输出是按照前面的输出作为输入的,因此这里会出现问题就是——一步错,步步错: image-20211111235516449
处理方法就是上图中使用的方法——不仅仅给模型正确的输入,还要给错误的输入,这样可以让模型学得更好。
下面就是这个方法(Scheduled Samping)的论文依据:
补充资料
- 这里不得不提一下最经典,也是我目前看到最好的一篇博客,题目叫做《The Illustrated Transformer》。这样说可能大家不清楚,但是如果我放置下面这几张图,可能大家就知道很多地方都有他的身影:
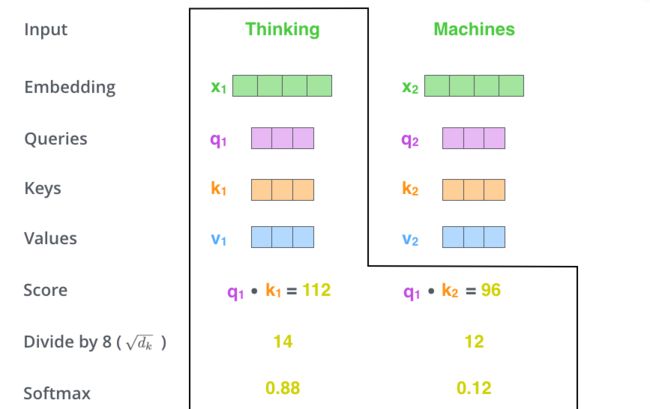


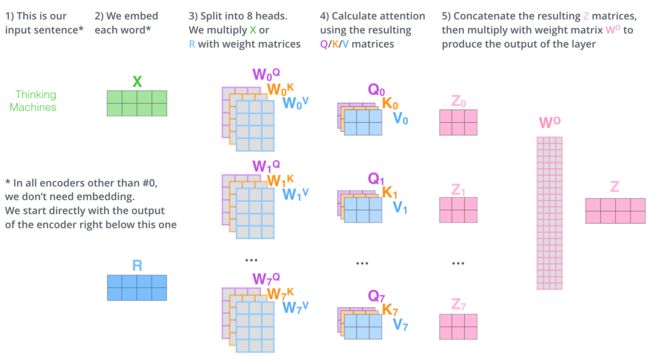
我个人认为这篇博客看懂了,几乎就看懂了transformer了;这里我也有一个[PPT的中文](https://pan.baidu.com/s/1LovEFd4Fswwk0jr8wIKkvA?pwd=ajh9 提取码:ajh9)内容很好地阐述了该博客的技术。
- 还有HuggingFace的介绍——Transformers 是如何工作的里面的内容也不错,并且很简洁,内容是中文的。