深入理解 Java ServiceLoader、Dubbo ExtensionLoader 源码结合实战篇

- 介绍
- Java SPI
-
- Driver 实现类
- DriverManager 驱动管理器类
-
- loadInitialDrivers 方法
- registerDriver 方法
- getConnection 方法
- ServiceLoader 核心类
-
- LazyIterator#hasNextService 方法
- LazyIterator#nextService 方法
- Dubbo SPI
-
- 加载策略
- Filter
- ExtensionLoader
-
- ExtensionLoader#getExtensionLoader
- ExtensionLoader#getAdaptiveExtension
- ExtensionLoader#loadExtensionClasses
- Dubbo SPI 实战篇
- 总结
介绍
SPI 全称为 (Service Provider Interface) 服务提供接口,JDK 内置的一种服务提供发现机制
SPI 是一种动态替换发现的机制, 比如有个接口,想在运行时动态的给它添加实现,你只需要添加一个实现类
经常遇到的就是 java.sql.Driver 接口,其他不同厂商可以针对同一接口做出不同的实现,MySQL、PostgreSQL 都有不同的实现提供给用户,而 Java 的 SPI 机制可以为某个接口寻找服务实现
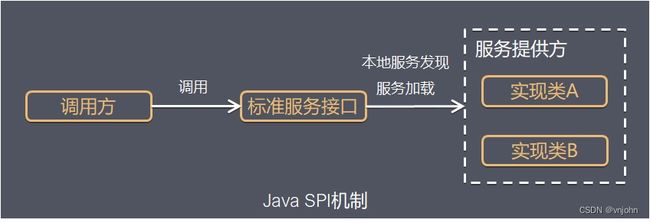
如上图所示,接口对应的抽象 SPI 接口;实现方实现 SPI 接口;调用方依赖 SPI 接口,在概念上更依赖调用方;组织上位于调用方所在的包中,实现位于独立的包中
当服务提供者提供了一种接口的实现之后,需要在 classpath 路径下的 META-INF/services/ 目录里创建一个以服务接口命名的文件,这个文件里的内容就是这个接口的具体的实现类全路径名称;当其他的应用程序需要这个服务的时候,就可以通过查找这个 jar 包(一般都是以 jar 包做依赖) META-INF/services/ 中的配置文件,配置文件中有接口的具体实现类名,可以根据这个类名进行加载实例化,就可以使用该服务了。JDK 中查找服务实现的工具类是:java.util.ServiceLoader
接口所在的提供方定义一组规范,一般是由开发人员定义出来
服务提供者,基于接口规范实现、自定义自己的逻辑,便于其他应用程序进行 Call
调用者,基于全限定路径接口名,在服务提供方加载此接口的实现类,做应用程序中自身的特殊处理,此调用者可以是其他服务
总之,通过 SPI 机制,应用程序可以以插件化的方式扩展功能,而无需显式地依赖具体的实现类。这种松耦合的设计使得应用程序更加灵活、可扩展和可维护
Java SPI
数据库:DriverManager、Spring、Dubbo 等都使用到了 SPI 机制,这里以 JDBC DriverManager 为例,看一下其是如何实现的
DriverManager 是 JDBC 里管理、注册不同数据库 Driver 工具类,针对一个数据库,可能会存在多种不同的数据库驱动实现;当我们希望在使用特定的驱动实现时,不希望修改现有的代码,而是直接通过一个简单的配置就能达到效果。
当我们在运用 Class.forName("com.mysql.jdbc.Driver") 加载 MySQL驱动后,就会执行其中的静态代码将 Driver 注册到 DriverManager 中,以便后续的使用
在使用 MySQL 驱动时,会有一个疑问,DriverManager 是如何获取确定的驱动类的,下面来具体介绍它的实现过程。
Driver 实现类
驱动类的静态代码块中,调用 DriverManager#registerDriver 注册驱动方法,通过 new 实例化一个驱动类作为参数传递给驱动管理器

public class Driver extends NonRegisteringDriver implements java.sql.Driver {
static {
try {
java.sql.DriverManager.registerDriver(new Driver());
} catch (SQLException E) {
throw new RuntimeException("Can't register driver!");
}
}
/**
* 构造一个新的实例并会将其注册到驱动管理器中
* @throws SQLException if a database error occurs.
*/
public Driver() throws SQLException {
// Required for Class.forName().newInstance()
}
}
DriverManager 驱动管理器类
DriverManager 静态初始化代码块,如下:
// 通过检查 System 属性加载初始 JDBC 驱动程序,然后使用 ServiceLoader 机制
static {
loadInitialDrivers();
println("JDBC DriverManager initialized");
}
loadInitialDrivers 方法
其内部的静态代码块中有一个 loadInitialDrivers 方法,其用到了上文提到的 SPI 工具类ServiceLoader,如下:
private static void loadInitialDrivers() {
String drivers;
try {
drivers = AccessController.doPrivileged(new PrivilegedAction<String>() {
public String run() {
return System.getProperty("jdbc.drivers");
}
});
} catch (Exception ex) {
drivers = null;
}
// If the driver is packaged as a Service Provider, load it.
// Get all the drivers through the classloader
// exposed as a java.sql.Driver.class service.
// ServiceLoader.load() replaces the sun.misc.Providers()
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
// 会实例化 LazyIterator 懒迭代器以及 Driver 具体的实现类对象
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);
Iterator<Driver> driversIterator = loadedDrivers.iterator();
// 调用的是 ServiceLoader.LazyIterator 懒迭代器的 iterator 方法
try{
// 调用 ServiceLoader.LazyIterator#hasNextService 方法
// 会拼接 META-INF/services/ 前缀
while(driversIterator.hasNext()) {
// 调用 ServiceLoader.LazyIterator#nextService 方法
// 会调用 Class.forName 实例化具体的实现类对象
driversIterator.next();
}
} catch(Throwable t) {
// Do nothing
}
return null;
}
});
// 省略其他代码 .......
}
registerDriver 方法
通过以上静态方法执行完过后,当前服务内所有的驱动实现类都会被加载进来,然后继续分析 DriverManager#registerDriver 方法的调用,源码如下:
// List of registered JDBC drivers
private final static CopyOnWriteArrayList<DriverInfo> registeredDrivers = new CopyOnWriteArrayList<>();
public static synchronized void registerDriver(java.sql.Driver driver,
DriverAction da)
throws SQLException {
/* 将当前驱动添加到集合中,在获取连接时会用到该集合 */
if(driver != null) {
registeredDrivers.addIfAbsent(new DriverInfo(driver, da));
} else {
// This is for compatibility with the original DriverManager
throw new NullPointerException();
}
println("registerDriver: " + driver);
}
getConnection 方法
通过数据库地址、用户、密码信息,获取数据库连接
@CallerSensitive
public static Connection getConnection(String url,
String user, String password) throws SQLException {
java.util.Properties info = new java.util.Properties();
if (user != null) {
info.put("user", user);
}
if (password != null) {
info.put("password", password);
}
return (getConnection(url, info, Reflection.getCallerClass()));
}
getConnection 重载方法会遍历 registeredDrivers 集合,通过驱动实现类和基础信息来与数据库建立连接,开启会话与 MySQL 服务端进行通信,如下:
private static Connection getConnection(
String url, java.util.Properties info, Class<?> caller) throws SQLException {
// 获取类加载器
// 判别数据库地址
if(url == null) {
throw new SQLException("The url cannot be null", "08001");
}
println("DriverManager.getConnection(\"" + url + "\")");
// Walk through the loaded registeredDrivers attempting to make a connection.
// Remember the first exception that gets raised so we can reraise it.
SQLException reason = null;
// 遍历数据库驱动集合
for(DriverInfo aDriver : registeredDrivers) {
// 判断调用方是否有加载驱动程序的权限
if(isDriverAllowed(aDriver.driver, callerCL)) {
try {
println(" trying " + aDriver.driver.getClass().getName());
// 通过驱动实现类来获取数据库连接
Connection con = aDriver.driver.connect(url, info);
if (con != null) {
// Success!
println("getConnection returning " + aDriver.driver.getClass().getName());
return (con);
}
} catch (SQLException ex) {
if (reason == null) {
reason = ex;
}
}
} else {
println(" skipping: " + aDriver.getClass().getName());
}
}
// 省略其他代码 ......
}
ServiceLoader 核心类
首先看一下 ServiceLoader 类结构
// 配置文件的路径
private static final String PREFIX = "META-INF/services/";
// 加载服务类或者接口
private final Class<S> service;
// 类加载器
private final ClassLoader loader;
// 访问权限的上下文对象
private final AccessControlContext acc;
// 保存已经加载的服务类
private LinkedHashMap<String,S> providers = new LinkedHashMap<>();
// 内部类,它是用来真正加载服务类
private LazyIterator lookupIterator;
核心 load 方法创建了一些属性,重要的是实例化了内部类 > LazyIterator
private ServiceLoader(Class<S> svc, ClassLoader cl) {
// 要加载的接口
service = Objects.requireNonNull(svc, "Service interface cannot be null");
loader = (cl == null) ? ClassLoader.getSystemClassLoader() : cl;
acc = (System.getSecurityManager() != null) ? AccessController.getContext() : null;
reload();
}
public void reload() {
// 先清空
providers.clear();
// 实例化内部类
lookupIterator = new LazyIterator(service, loader);
}
查找要加载的接口实现类以及创建实现类过程,都在内部类 LazyIterator 中完成,当在 DriverManager 中调用 Iterator#hasNext、Iterator#next 方法时,实际上调用的都是 LazyIterator 相应的方法 hasNextService、nextService
LazyIterator#hasNextService 方法
private boolean hasNextService() {
if (nextName != null) {
return true;
}
if (configs == null) {
try {
// META-INF/services/ + 接口全限定类名,即文件服务类的文件
String fullName = PREFIX + service.getName();
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
// 将文件路径转成 URL 对象
configs = loader.getResources(fullName);
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
}
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
// 解析 URL 文件对象,读取内容,最后返回
pending = parse(service, configs.nextElement());
}
nextName = pending.next();
return true;
}
LazyIterator#nextService 方法
通过反射的方式创建实现类的实例对象并返回
private S nextService() {
if (!hasNextService()) throw new NoSuchElementException();
String cn = nextName;
nextName = null;
Class<?> c = null;
try {
// 创建实现类的 Class
c = Class.forName(cn, false, loader);
} catch (ClassNotFoundException x) {
fail(service, "Provider " + cn + " not found");
}
if (!service.isAssignableFrom(c)) {
fail(service, "Provider " + cn + " not a subtype");
}
try {
// 通过 newInstance 方法实例化
S p = service.cast(c.newInstance());
providers.put(cn, p);
return p;
} catch (Throwable x) {
fail(service, "Provider " + cn + " could not be instantiated", x);
}
throw new Error(); // This cannot happen
}
Dubbo SPI
Dubbo 是一个基于Java的开源分布式服务框架,它提供了一种扩展机制,称为 Dubbo SPI(Service Provider Interface)。Dubbo SPI 机制是在 Java SPI 机制的基础上进行了扩展和优化
Dubbo SPI 机制的实现主要依赖于以下几个关键组件:
- 接口定义:Dubbo 服务接口定义了一组可供扩展的接口方法,例如 Protocol、Registry、Filter 等
- 扩展点注解:Dubbo 通过使用 @SPI 注解标记接口,并在注解中指定默认的扩展实现。该注解使得 Dubbo 能够根据配置文件中的扩展实现名称加载具体的实现类
- 配置文件:Dubbo 使用配置文件来定义每个扩展点的具体实现类。配置文件通常位于类路径下的
META-INF/dubbo/目录中,文件名与扩展接口的全限定名相对应 - 扩展加载器:Dubbo 提供了 ExtensionLoader 类作为扩展加载器,负责加载和管理扩展实现类。ExtensionLoader 基于 Java SPI 机制,通过读取配置文件、实例化扩展实现类并进行缓存,实现了对扩展的动态加载
- 扩展适配器:对于某些扩展点,Dubbo 还提供了适配器来简化使用。适配器类实现了扩展接口,并在内部封装了实际的扩展实现,提供了一些默认的实现逻辑
通过上述组件的协作,Dubbo SPI 机制实现了对扩展的自动加载和管理。应用程序可以通过配置文件指定要使用的扩展实现,Dubbo 会根据配置加载相应的实现类。如果没有指定配置,则会使用接口上 @SPI 注解中指定的默认实现
总结来说,Dubbo SPI 机制基于 Java SPI 机制进行了扩展和优化,通过配置文件和扩展加载器实现了对扩展的自动加载和管理。这使得 Dubbo 可以非常方便地扩展和替换各种核心组件,以满足不同的业务需求
加载策略
其次,在 Dubbo 提供了三种策略方便我们去自定义加载扩展接口的方式,如下三种:
- DubboInternalLoadingStrategy:支持 Dubbo 内部接口实现类加载的方式
- DubboLoadingStrategy:提供给客户端自定义一些实现类加载的方式,例如一些过滤器等
- ServicesLoadingStrategy:Java 内自带的提供的一些接口实现类,如上面的 Java SPI 篇章所描述的内容
- 自定义策略类,用于加载我们指定目录下的文件,提供了这样的入口给到了我们
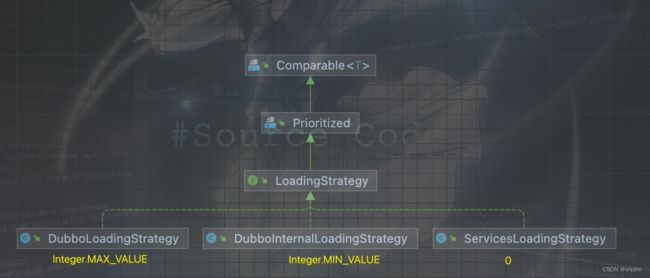
优先级: DubboInternalLoadingStrategy > DubboLoadingStrategy > ServicesLoadingStrategy
Filter
Dubbo 服务接口定义了一组可供扩展的接口方法,例如 Protocol、Registry、Filter 等,在这里我们以 Filter 为例作为入口开始分析,在 Dubbo 底层是如何通过 ExtensionLoader 扩展加载器一步步实现的
在应用程序调用时, Filter 过滤器肯定是不至一个的,包括 Dubbo 内置的、开发人员所定义的,所以需要组装过滤器链
Dubbo 内置过滤器,主要有:
1、GenericFilter:来拦截并实现泛化调用的功能
2、EchoFilter:在服务提供者接收到请求后,直接将请求内容作为响应返回给服务消费者,用于测试网络连接和服务可用性;一般用于诊断、测试,不适用于实际生产环境中。在实际部署中,建议将其从配置中移除或禁用,以避免不必要的性能开销
3、TokenFilter:服务之间调用的令牌验证,以 token 作为 name 拼接在 URL 后的方式
4、TpsLimitFilter:在服务提供者接收到请求时,通过配置的阈值限制每秒可以处理的请求数量。当请求数量超过设定的阈值时,该过滤器会拒绝处理额外的请求,以保护服务提供者免受过载的影响;要是没有配置这个阈值,该过滤器就不会进行处理了
接着继续来分析 Dubbo 是如何组装拦截器链的,入口:ProtocolFilterWrapper#buildInvokerChain

ExtensionLoader
ExtensionLoader 扩展类加载器, Dubbo SPI 提供扩展方式最重要的类,在它里面帮我们完成了很多公共处理工作
ExtensionLoader#getExtensionLoader
public static <T> ExtensionLoader<T> getExtensionLoader(Class<T> type) {
if (type == null) {
throw new IllegalArgumentException("Extension type == null");
}
if (!type.isInterface()) {
throw new IllegalArgumentException("Extension type (" + type + ") is not an interface!");
}
if (!withExtensionAnnotation(type)) {
throw new IllegalArgumentException("Extension type (" + type +
") is not an extension, because it is NOT annotated with @" + SPI.class.getSimpleName() + "!");
}
// 获取本地缓存是否已存在【扩展加载器】
ExtensionLoader<T> loader = (ExtensionLoader<T>) EXTENSION_LOADERS.get(type);
if (loader == null) {
// 实例化扩展类加载器
EXTENSION_LOADERS.putIfAbsent(type, new ExtensionLoader<T>(type));
loader = (ExtensionLoader<T>) EXTENSION_LOADERS.get(type);
}
return loader;
}
首次从本地缓存中取,肯定是没有的,所以每次都会先创建好一个 ExtensionLoader 对象实例,如下:
private ExtensionLoader(Class<?> type) {
this.type = type;
// ExtensionFactory 默认实现 AdaptiveExtensionFactory
objectFactory = (type == ExtensionFactory.class ? null : ExtensionLoader.getExtensionLoader(ExtensionFactory.class).getAdaptiveExtension());
}
提到了创建 SPI 接口扩展的实现类,那么工厂就必然而然不可少了,在 Dubbo 中 ExtensionFactory 接口的默认实现类是 AdaptiveExtensionFactory > 创建和管理扩展实例
AdaptiveExtensionFactory 它是一个自适应扩展工厂,根据当前的上下文环境和配置动态地选择适合的扩展实例。AdaptiveExtensionFactory 通过 Dubbo 框架编译时生成代码的方式,在运行时实现了扩展实例的动态适配
ExtensionLoader#getAdaptiveExtension
创建好自适应工厂以后,接下来就是创建具体的扩展实例对象了,也就是调用 getAdaptiveExtension 方法,该方法源码如下:
public T getAdaptiveExtension() {
Object instance = cachedAdaptiveInstance.get();
if (instance == null) {
if (createAdaptiveInstanceError != null) {
throw new IllegalStateException("Failed to create adaptive instance: " +
createAdaptiveInstanceError.toString(),
createAdaptiveInstanceError);
}
// 双重检查锁,先两次从本地缓存中获取是否可以拿到
synchronized (cachedAdaptiveInstance) {
instance = cachedAdaptiveInstance.get();
if (instance == null) {
try {
// 创建扩展类实例
instance = createAdaptiveExtension();
cachedAdaptiveInstance.set(instance);
} catch (Throwable t) {
createAdaptiveInstanceError = t;
throw new IllegalStateException("Failed to create adaptive instance: " + t.toString(), t);
}
}
}
}
return (T) instance;
}
前期先从缓存读取扩展实例对象,若缓存中不存在,那么就调用 createAdaptiveExtension 方法创建新的实例,源码如下:
private T createAdaptiveExtension() {
try {
return injectExtension((T) getAdaptiveExtensionClass().newInstance());
} catch (Exception e) {
throw new IllegalStateException("Can't create adaptive extension " + type + ", cause: " + e.getMessage(), e);
}
}
private Class<?> getAdaptiveExtensionClass() {
getExtensionClasses();
if (cachedAdaptiveClass != null) {
return cachedAdaptiveClass;
}
return cachedAdaptiveClass = createAdaptiveExtensionClass();
}
由于 injectExtension 方法是外部的,它依赖于 getAdaptiveExtensionClass 方法返回的结果,所以先分析此方法
ExtensionLoader#loadExtensionClasses
private Map<String, Class<?>> getExtensionClasses() {
Map<String, Class<?>> classes = cachedClasses.get();
if (classes == null) {
synchronized (cachedClasses) {
classes = cachedClasses.get();
if (classes == null) {
classes = loadExtensionClasses();
cachedClasses.set(classes);
}
}
}
return classes;
}
又是一个双重检查锁,优先从缓存中读取,获取实例对象,核心方法执行在 loadExtensionClasses
private Map<String, Class<?>> loadExtensionClasses() {
// 观察此类型是否被 @SPI 注解所修饰,若有的话,只能给 name 属性指定一个值,多于一个会抛出中端异常,不会再往下执行
cacheDefaultExtensionName();
Map<String, Class<?>> extensionClasses = new HashMap<>();
// 通过 Java SPI 获取 LoadingStrategy 接口下所有的实现类
for (LoadingStrategy strategy : strategies) {
loadDirectory(extensionClasses, strategy.directory(), type.getName(), strategy.preferExtensionClassLoader(), strategy.overridden(), strategy.excludedPackages());
loadDirectory(extensionClasses, strategy.directory(), type.getName().replace("org.apache", "com.alibaba"), strategy.preferExtensionClassLoader(), strategy.overridden(), strategy.excludedPackages());
}
return extensionClasses;
}
通过 Java SPI 获取 LoadingStrategy 接口下所有的实现类,也就是在上面分析到的加载策略,分别为 DubboInternalLoadingStrategy、DubboLoadingStrategy、ServicesLoadingStrategy
DubboInternalLoadingStrategy > 处理的目录:META-INF/dubbo/internal/
DubboLoadingStrategy > 处理的目录:META-INF/dubbo/
ServicesLoadingStrategy > 处理的目录:META-INF/services/
它们对应的扩展实现类统一在 loadDirectory 方法中进行加载,由于该方法源码流程过于长,画图如下:
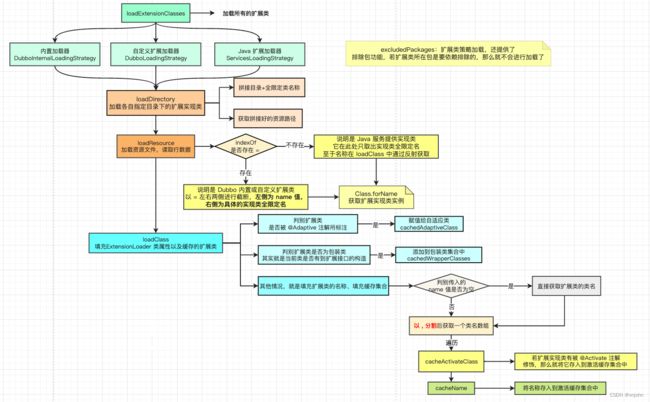
主要的核心处理方法有这几个 loadDirectory > loadResource > loadClass
loadDirectory:通过不同的扩展类加载策略来拼接文件名称以及资源路径
loadResource:通过资源路径来调用 Class.forName 实例化扩展实现类,同时设置好对应的扩展类名称;若是 Dubbo 内置或自定义的,都直接取用 = 截断字段的左侧全称即可;若不是,那么就取用扩展实现类的类名作为名称
loadClass:通过扩展实现类的不同功能,来对当前所在 ExtensionLoader 对象填充属性,在这里最重要的是这个 cachedActivates 激活缓存集合,只有标注了 @Activate 注解的扩展实现类才会被添加进,在实际开发中也是通过这种方式来引入自定义扩展类的~
Dubbo SPI 实战篇
当我们在实际工作中会用到 Dubbo SPI 机制,去作自定义的一些扩展工作,比如:服务之间相互调用时,我想让上层服务已经认证好的用户信息 > Token,通过无代码侵入的方式传入到下层服务,通过 Header 方式传递,而在 Dubbo 内置的 TokenFilter 它是以 URL 拼接方式传入的,这对系统来说是不安全的
创建好我们自定义的过滤器类,如下:
@Slf4j
@Activate(group = CommonConstants.CONSUMER)
public class ConsumerAuthTokenFilter implements Filter {
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
log.info("methodName: {}, arguments: {}, attachments: {}", invocation.getMethodName(), invocation.getArguments(), invocation.getAttachments());
// 从线程本地持有中获取 > ThreadLocal
String token = ThreadContextHolder.getToken();
if (StringUtils.isNotEmpty(token)) {
log.info("dubbo consumer filter");
// Rpc 上下文传递 AutoToken 参数
RpcContext.getContext().setAttachment(Constant.AUTH_TOKEN, TokenContextHolder.getToken());
}
return invoker.invoke(invocation);
}
}
自定义扩展类准备好了,接着作以下事情
1、首先要在 resource 目录下创建好 META-INF/dubbo 目录
2、在该目录下新建文件,上述问题,我们通过过滤器来解决,所以文件名称为 org.apache.dubbo.rpc.Filter
3、文件内容:authTokenFilter=org.vnjohn.filter.ConsumerAuthTokenFilter
那么,Dubbo 是通过什么方式去找到这些自定义扩展类的呢?
在 Dubbo SPI > Filter 处,已经组装好过滤器链了,当触发 RPC 服务调用时,会先经过这些过滤器,从而就会调用 ConsumerAuthTokenFilter#invoke 方法,将 AuthToken 进行服务上下文传递!
总结
该篇博文介绍 Java SPI 服务提供接口,是如何基于 ServiceLoader 核心类实现的,以经典的 SQL 驱动扩展类作为案例,揭开底层源码的加载逻辑,从这方面我们可以来做一些自己的扩展工作;同时,还仔细阐述了在 Dubbo 是如何基于原有的 SPI,作一些自己的扩展和优化的,它还支持我们自定义扩展实现其他的加载策略,只要你需要!以过滤器链为序幕,揭开 Dubbo 底层是如何基于 ExtensionLoader 作扩展实现的;最后,以 Dubbo Rpc 服务之间传递 Token 的实战案例,作为这篇博文最后的结尾,其他不足之处尽请见谅,有问题可以留言或私信喔~
如果觉得博文不错,关注我 vnjohn,后续会有更多实战、源码、架构干货分享!
推荐专栏:Spring、MySQL,订阅一波不再迷路
大家的「关注❤️ + 点赞 + 收藏⭐」就是我创作的最大动力!谢谢大家的支持,我们下文见!