【无标题】
原创 | 文 BFT机器人

01 研究背景

这篇论文的背景是在自动驾驶和机器人导航等领域,需要实现高精度、高效率的定位和地点识别。然而,传统的基于GPS或视觉的方法存在一些局限性,尤其在城市峡谷等环境中无法提供准确的位置信息。为了解决这一问题,使用3D LiDAR进行定位和地点识别已经成为一个热门的研究方向。
然而,现有的方法在实际应用中存在一些挑战。首先,这些方法通常需要大量的存储空间和计算资源,限制了它们在实际系统中的可行性和效率。其次,对于复杂场景中的遮挡和噪声等问题,现有方法缺乏足够的鲁棒性,导致定位和地点识别的准确性下降。
因此,本篇论文的目标是提出一种轻量级、高效、鲁棒性强的算法,以解决上述问题。该算法旨在降低存储需求和计算复杂度,以提高系统的效率。同时,它还致力于解决复杂场景中的遮挡和噪声等挑战,以提高定位和地点识别的准确性。
02 该篇论文的创新点
这篇论文的创新点主要涉及两个方面。
1、首先,作者提出了一种名为BoxGraph的新方法,该方法利用3D LiDAR数据进行语义地点识别和姿态估计。相比传统方法,BoxGraph方法具有更强的鲁棒性和轻量级计算的优势。这意味着它能够更好地应对复杂场景中的遮挡和噪声等问题,并且在实际应用中更高效。
2、其次,作者将基于相机的语义图像识别系统特化为基于3D点云的语义图形识别系统,并对该系统进行了扩展,以实现更精确的姿态估计。这一扩展使得系统能够更准确地估计物体的位置和方向,从而提高定位和地点识别的精度。
03 算法具体介绍
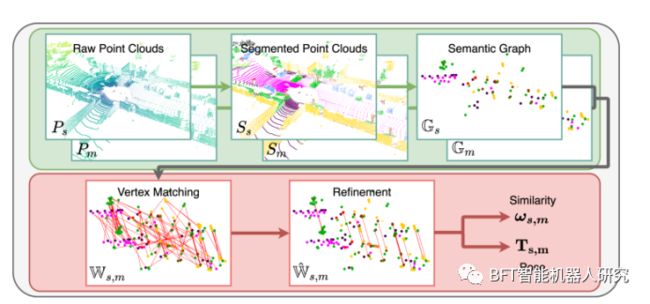
图1本篇论文提出的方法的系统框架图
使用LiDAR传感器获取点云数据时,希望将这些数据与预先构建好的地图进行匹配,以便实现定位、导航等应用。本文提出了一种匹配方法,具体步骤如下:
1.形状相似度计算:
首先,将LiDAR传感器流的点云表示为一个图形^Gs,将预先构建的地图中的点云表示为另一个图形^Gm。然后,使用形状相似度σv(vi)来找到这两个图形中相同类别的顶点之间的最佳匹配。形状相似度可以衡量两个顶点之间的相似程度。
2.异常值去除:
接下来,使用RANSAC算法来去除匹配中的异常值。RANSAC算法是一种迭代算法,可以通过拟合模型来剔除异常值。在本文中,使用RANSAC算法来估计相对变换Ts,即LiDAR传感器流点云相对于地图点云的变换。
3.相似度得分计算:
为了综合考虑匹配顶点和边之间的相似度,引入了相似度得分S。相似度得分S考虑了精细图^Gs和^Gm中匹配顶点和边之间的相似度。具体而言,σe(e12; e56)表示边之间的相似度,σv(v1; v5)和σv(v2; v6)表示匹配顶点之间的相似度。
4.最佳顶点对应关系获取:
在计算相似度得分后,可以得到两个图形中最佳顶点的对应关系W s,m。这个对应关系指示了LiDAR传感器流点云中的每个顶点与地图点云中的哪个顶点匹配。
5.姿态估计:
有了最佳顶点对应关系后,使用奇异值分解(SVD)技术对顶点质心进行估计,以获得6自由度的姿态。通过计算顶点质心的位移和旋转,可以得到LiDAR传感器流点云相对于地图点云的姿态信息。
6.错误匹配去除:
为了提高姿态估计的质量,再次利用RANSAC算法来去除可能存在的错误匹配。通过迭代计算,并剔除与拟合模型不符合的匹配对,可以得到更准确的姿态估计结果。
综上所述,这种匹配方法通过形状相似度计算、RANSAC算法的异常值去除、相似度得分计算以及奇异值分解和RANSAC算法的姿态估计与错误匹配去除,实现了LiDAR传感器流点云与预先构建的地图点云的精确匹配,并得到了相对变换和姿态信息。这种方法可以提高匹配准确性和姿态估计质量,为定位和导航等应用提供更可靠的结果。
04 实验部分

表1展示了使用不同位置识别方法存储单个扫描的全局定位系统的内存消耗分析。

表2 SemanticKITTI数据集的查准率和查全率的总和

表3 SemanticKITTI数据集的查准率和查全率曲线
实验结果:
在对语义KITTI数据集进行的实验中,作者提出的方法表现出卓越的姿态估计和地点识别性能,为解决相关问题提供了重要的解决方案。实验结果显示,该方法在各项指标上取得了显著的成绩,并具备了在实际场景中的实用潜力。
首先,作者的方法在地点识别方面表现出色,具备准确的姿态估计能力。这意味着该方法能够精确地确定目标在三维空间中的位置、方向和姿态信息。这对于自动驾驶、导航和环境感知等应用至关重要,因为准确的姿态估计可以为车辆或机器人做出正确的决策提供关键信息。
其次,作者的方法在没有地面真值分割的情况下仍然表现出良好的鲁棒性。这意味着该方法能够应对实际场景中存在的噪声、不完整数据或未标记数据等挑战,并仍然保持良好的性能水平。这种鲁棒性使得该方法具备了在实际应用中部署的能力,并能够适应不同的场景和数据条件。
此外,作者的方法在使用预测分割时表现出了优异的性能,甚至超过了使用地面真值分割的其他方法。这意味着该方法对于语义分割任务的预测能力非常强,能够准确地将点云数据进行语义分类,从而提供更准确的地点识别结果。
综上所述,实验结果明确证明了作者提出的方法在语义KITTI数据集上具备出色的姿态估计和地点识别性能,并且在实际应用中具有巨大的潜力。这些成果将为相关领域的研究和应用提供有力支持,并为未来的自动驾驶和智能导航系统等领域带来更准确和可靠的解决方案。
05 结论
作者提出的基于语义图的3D点云姿态估计和地点识别方法在KITTI数据集上取得了很好的性能,甚至在没有ground truth分割时仍然具有很好的鲁棒性。该方法使用预测分割表现出了很好的性能,甚至优于使用ground-truth分割的其他方法。因此,该方法具有很大潜力在实际应用中得到广泛应用。
论文标题:
BoxGraph: Semantic Place Recognition and Pose Estimation from 3D LiDAR
更多精彩内容请关注公众号:BFT机器人
本文为原创文章,版权归BFT机器人所有,如需转载请与我们联系。若您对该文章内容有任何疑问,请与我们联系,将及时回应。