Linux高性能异步I/O接口io_uring
Linux高性能异步I/O接口io_uring
由于最近研究高性能的物联网框架,而通信和IO是一个高并发系统最重要的需要考虑的方向。本文主要记录一下对于Linux最新的io_uring的研究和在网络通信方向应用的前景。
io_uring简介
io_uring的引入是从Linux内核5.1版本开始的。这是一个全新设计的,非常精巧的异步I/O框架。Linux系统很早期时间上就有一个异步IO接口,Linux AIO。但是这个接口的设计比较糟糕,使用比较繁琐,扩展也非常麻烦。有很多企业和开发人员试图对Linux AIO进行改进,不过由于最初的设计问题,使得改进极为困难。而且AIO支持直接IO,而不支持缓存IO,这就使得大量需要内核态缓存的应用(包括网络IO)没有办法用到AIO。
io_uring 实现了三个系统调用:
io_uring_setup, io_uring_enter 和 io_uring_register。这三个系统调用的功能分别是:
io_uring_setup用于建立一个io_uring的实体io_uring_enter用于将SQE(Submission Queue Entry)提交到SQ(Submission Queue)中去。io_uring_register用于预注册读写文件
io_uring的几个重要概念
- SQ - Submission Queue:提交队列,这是在内核态的一整块连续的内存空间存储的环形队列。用于存放将执行的操作数据项。
- CQ - Completion Queue:完成队列,这是在内核态的一整块连续的内存空间存储的环形队列。用于存放执行完成后的结果。
- SQE - Submission Queue Entry:提交队列项,这是储存在SQ中的数据项。
- CQE - Completion Queue Entry:完成队列项,这是储存在CQ中的数据项。
- Ring - Ring:环:SQ和CQ都是环形队列结构,Ring用来代表一个io_uring的实体。
io_uring的结构示意图
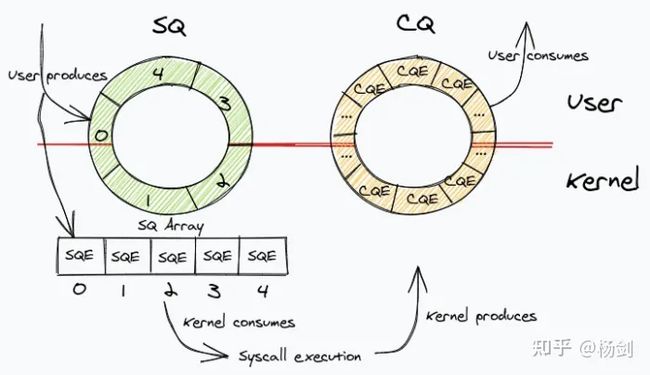
上述示意图大致描绘除了io_uring的结构,SQ和CQ这两个队列通过mmap系统调用建立起内核态和用户态的共享。从而实现了采用io_uring的应用程序,对于IO操作的提交和收割可以不用进行内核态存储区域和用户态的上下文切换,对于大量IO访问的情况下提高了性能。关于什么是内核态,什么是用户态,在下面关于Linux内核会做进一步的介绍。
Linux内核介绍
内核版本的要求
由于众所周知的原因,国内各大开源软件库通常需要用国内镜像。而有些不常用的下载升级功能由于没有国内镜像,就会非常麻烦。比如要升级Linux的内核到最新的版本就非常麻烦,因为对这种升级内核的需求不是太多。于是遇到这样的情况就要花很长时间来找办法安装。这里对内核的要求至少是>=5.7,最好能够是5.12以上,不然某些io_uring的高级功能可能无法支持。
内核态和用户态(Kernel & User)
下图是Linux操作系统内核态和用户态的划分,由于对系统安全性的考虑,普通的应用程序都是运行在用户态的。用户通过系统调用syscall访问内核态中的API功能,可以看到各种对底层硬件,存储设备,内存和网络等的访问和操作都是放在内核态中实现的。内核态和用户态不但是操作系统软件层面的设定,而且得到CPU硬件的支持,例如Intel的X86架构CPU就提供了从ring0 ~ ring3四个不同级别的CPU指令访问权限。ring0的权限最高,可以访问所有的CPU指令集。而ring3的权限最低,甚至不能够执行申请内存操作。Linux操作系统仅仅使用了ring0和ring3这两个指令集权限,分别对应的就是内核态(Kernel)和用户态(User)。在Linux系统的内存分配层面,将整个操作系统内存空间前1G地址用于内核态程序和数据,剩下的作为用户态使用。
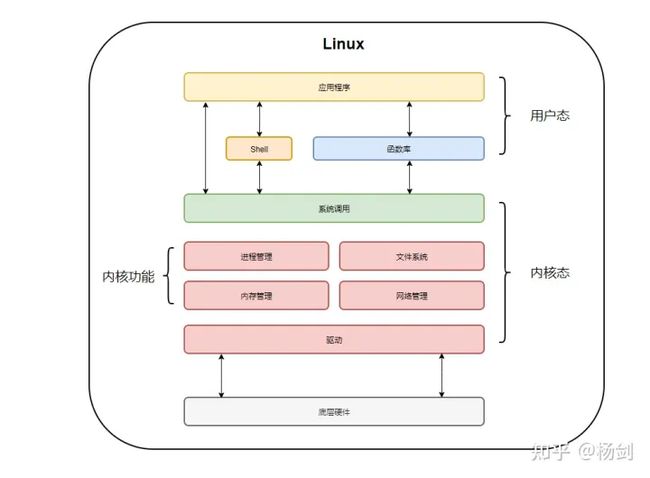
通过上面的介绍,我们其实可以发现,如果普通应用程序运行的用户态需要访问硬件设备,或者访问网络,读取磁盘文件时,那就必须通过调用Linux提供的系统API,将命令参数压入用户态的应用栈中,系统调用将应用栈中命令参数取到内核执行栈中,在内核态中执行指令。而且读取数据的时候,数据会先从硬件进入内核态的缓存区,然后再写入用户态的内存区域中。写入设备也是如此,要求调用系统API接口分配内存,并将用户态内存中数据复制到内核态区域,然后再写入设备。这就是内核和用户态的上下文切换。这种切换和内存拷贝,在IO访问量大的时候对系统的资源占用和消耗很大,尤其对于那些需要高性能的应用程序影响特别大。
MMAP系统调用
上面我们大致介绍了一下,应用在内核态和用户态的切换。那如果我们进行大量数据的读写,或者进行非常频繁的IO操作(服务器的Socket访问)的时候,我们应该如何减少内核态用户态的切换呢?一个最常用的系统调用就是mmap系统调用。这个在所有高性能IO相关程序中都有广泛的应用,io_uring也不例外。其中的SQ和CQ就要用到mmap进行用户态虚拟内存映射一段共享内存,进行读取和写入。
void * mmap(void *start, size_t length, int prot , int flags, int fd, off_t offset)在这里,我并不想对这个系统调用的使用进行详细的解释,只是对于其在io_uring中的使用一下简单的介绍。这里用了golang语言作为示例。我们需要通过golang的golang.org/x/sys/unix包或者syscall包进行调用。在使用io_uring的时候,我们首先会通过调用io_uring_setup这个系统调用创建io_uring实体,然后将SQ,CQ和SQEs用Mmap系统调用进行映射。
func mmapSQ(iour *IOURing) (err error) {
sq := iour.sq
params := iour.params
sq.size = params.SQOffset.Array + params.SQEntries*uint32Size
sqdata, err := unix.Mmap(iour.fd, int64(iouring_syscall.IORING_OFF_SQ_RING), int(sq.size), unix.PROT_READ|unix.PROT_WRITE, unix.MAP_SHARED|unix.MAP_POPULATE)
if err != nil {
return fmt.Errorf("mmap sq ring create error: %w", err)
}
sq.ptr = uintptr(unsafe.Pointer(&sqdata[0]))
sq.head = (*uint32)(unsafe.Pointer(sq.ptr + uintptr(params.SQOffset.Head)))
sq.tail = (*uint32)(unsafe.Pointer(sq.ptr + uintptr(params.SQOffset.Tail)))
sq.mask = (*uint32)(unsafe.Pointer(sq.ptr + uintptr(params.SQOffset.RingMask)))
sq.entries = (*uint32)(unsafe.Pointer(sq.ptr + uintptr(params.SQOffset.RingEntries)))
sq.flags = (*uint32)(unsafe.Pointer(sq.ptr + uintptr(params.SQOffset.Flags)))
sq.dropped = (*uint32)(unsafe.Pointer(sq.ptr + uintptr(params.SQOffset.Dropped)))
sq.array = *(*[]uint32)(unsafe.Pointer(&reflect.SliceHeader{
Data: sq.ptr + uintptr(params.SQOffset.Array),
Len: int(params.SQEntries),
Cap: int(params.SQEntries),
}))
上面的代码用于在用户态访问SQ Ring的存储空间,这个操作是通过mmap调用实现的。我们调用io_uring_setup以后,系统会返回这个io_ring的文件描述符iour.fd,然后通过这个文件描述符和SQ在内核态内存地址偏移量(IORING_OFF_SQ_RING)就能够定位到SQ的实际地址,我么通过Mmap这个系统调用就建立了用户态虚拟地址和内核态的SQ的实际物理地址的对应关系。而参数unix.PROT_READ|unix.PROT_WRITE则表示允许进行读和写操作。虽然这样的内存mapping能够提高性能,但是我们也应该意识到,实际上这样的操作允许应用程序以某种方式读写内核态的内存空间。这给系统的整体安全性带来一定的风险,因此对于io_uring的安全问题,尤其在生产环境的使用,我们其实还需要进行更加慎重地考量。
io_uring的使用
由于网上的资料比较零散,对于如何使用io_uring的介绍都是一两年前的了。那时候对于io_uring的使用大多还处于探索阶段,而且io_uring本身的开发还在快速迭代中,所以对于io_uring的应用还处于摸索阶段,尤其是在网络IO这方面还不太成熟。尽管如此,网络IO一定会成为io_uring的一个重要应用领域。目前主流的高性能网络IO架构主要还是采用的,poll/epoll接口和reactor的模式。io_uring这样原生的异步接口直接就能够采用proactor这样的主动通知模式,减少了轮询的开销,同时还能够设置内核线程自动提交SQE中的任务,理论上io_uring的IO性能一定是超过epoll接口和reactor模式的。当然,编写proactor模式的IO框架不能够照搬reactor的轮询和分发模式。而应该采用事件驱动的模式设计架构,这样才能够真正发挥出io_uring这种异步接口的全部潜力。
传统epoll接口+reactor模式
下图是在Netty中的reactor模型的工作流程,整个网络IO的起始位置是处理accept事件的线程,一旦有网络连接请求进来,就会通过reactor进程执行accept并创建socket。并将这个socket后续的处理转交sub-reactor线程,用于处理连接状态的socket的read请求。一旦收到了read请求,我们就可以将剩余的工作发送到工作线程池中进一步处理。像Netty这样的NIO,非阻塞网络框架都是采用的这样的模式。这提高了线程的利用率,减少了程序空转和等待的时间。epoll总共有三个系统调用,分别是epoll_create,epoll_ctl和epoll_wait。分别用于创建epoll事件,加入epoll的调用以及轮询完成的事件。事实上,我们需要不断调用epoll_wait来获得事件执行的结果,这种不断进行系统调用的方式在处理高并发请求是也会影响系统的性能。

我们虽然已经通过Linux中的内核epoll这种IO轮询模式的网络IO实现做到了非常高的性能。不过对于轮子研发者来说,还是希望能够尝试进一步利用新一代的纯异步IO来压榨出更多性能。在基于io_uring的net I/O框架的设计方式上,可以采取传统的类似Netting的Boss+Worker的型式(在Golang可以变为Boss+协程的模式);这种模式将Accept的处理和Read/Write分开。这在reactor方式下,基本是默认的形式。但是在完全异步接口的情况下,这种分来处理的方式似乎并没有必要。
我们希望能够将所有的事件在同一个IO对象处理,也就是Accept,Read和Write都扔到同一个io_uring中去处理。这就要求对不同IO事件的判断逻辑进行处理。当然我们也可以将不同的I/O请求放到不同的io_ring对象中。这看起来在代码实现上将会更加容易,而且整体的逻辑也会更加清晰,在代码层面上会更加容易维护,但是我们采用异步IO的主要目的是提高性能。异步IO本身的特性决定了并不需要同一个应用创建多个io_uring实体,这么做反而会增加系统资源的开销和冗余。
因此在试验开发的io_uring的net I/O框架中,我试图采用One Ring For All的模式。这个模式会在整个应用中只开一个io_uring,处理所有的Accept,read和write事件。而不是传统的reactor这样的模式。One ring for all能够充分发挥出io_uring异步处理的特性,从而减少了reactor模式中master group和worker group的区分。在采用epoll模式的网络访问系统中,非常常见的模式就是mater group中的线程介绍accept然后将后续的read,write等操作扔给worker group中的线程执行。