量化业务背景
量化金融指依托金融大数据、金融科技和智能金融的技术进展,通过数量化方式及计算机程序发出交易指令,以获取稳定收益为目的的金融投资方式,在海外的发展已有几十年的历史,其投资业绩稳定,市场规模和份额不断扩大、得到了越来越多投资者认可。量化投资技术几乎覆盖了投资的全过程,包括量化选股、量化择时、股指期货套利、商品期货套利、统计套利、算法交易,资产配置,风险控制等。
量化的研究方向和优势
“AI+”量化投资模式将成为人工智能应用于量化投资中的主要发展方向。国内量化在 2018 年之前,还是以量价数据+人工挖掘的方式为主。在 2018 年之后,市场逐渐进入 AI 算法的时代,不管从因子挖掘、组合管理,还是风险优化等方面,进一步提升了整个量化投资的收益。到 2019 年之后,整个量化行业的规模快速增长,这是推动整个行业发展非常重要的动力。到 2020 年,量化行业已经到了大数据+AI 算法的阶段。整体来看,在量化行业突破 8000 亿的市场规模,大数据+AI 算法在未来的发展趋势势不可挡,不管是从数据的规模还是对于神经网络的应用,随着 AI+大数据的发展,亦是未来量化行业的主要增长来源。
量化数据特点
在了解量化数据特点之前,我们先看下量化数据都有哪些类别,一是市场的量价数据:交易所量价数据、交易量、成交量、价格、日内订单等;二是基本面数据:上市公司公告几千万条记录、公司财报数据数千万份、各大券商分析报告等;三是另类数据:个股新闻、商品数据、宏观数据、产业数据、个股指标、物流数据、供应链数据、电商数据等。这些数据具有以下特点:
- 基础量化数据量规模大
- 数据类型多,CSV,TXT,EXCEL,HDF file,DataBase
- 信噪比低,干扰数据多
- 衍生数据复杂,提取困难
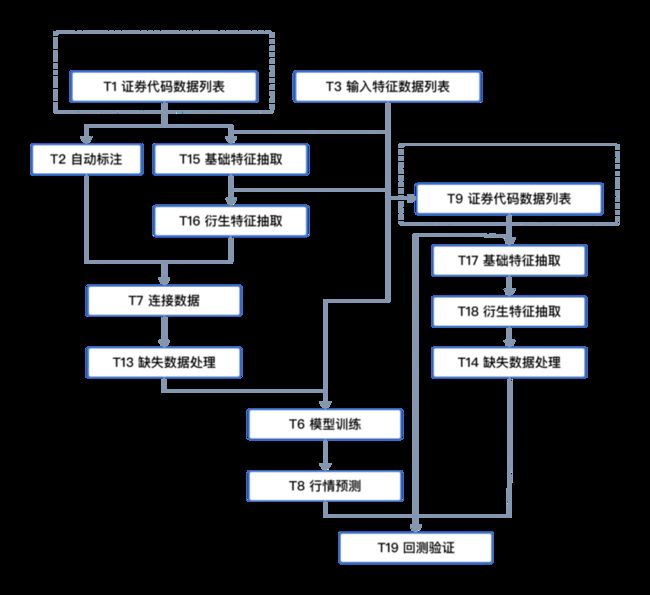
量化的业务流程
第一步:数据准备,划分训练集、测试集
首先我们应明确我们构建何种 AI 量化策略,如 A股、港股还是期货等,确定数据后,接着我们把历史数据按时间顺序切分为两部分。第一部分的数据用来训练模型,第二部分的数据用来验证模型效果。
第二步:选定目标:数据标注
其次我们要明确我们模型的训练目标,是预测股票收益率高低还是波动率高低。
AI 量化策略的目标(Label):人为定义的模型预测目标,例如未来 N 日收益率、未来 N 日波动率、未来 N 日的收益率排序等统计量,平台 AI 量化策略默认使用股票收益率作为目标。
AI 量化策略的标注:计算训练集数据所在时间阶段的每日目标值,比如按每日的未来 N 日收益率高低来定义股票的走势好坏等级,计算出每只股票未来N日收益率的好坏等级并标记在每只股票上。
第三步:特征数据、找因子
选择构建可能影响目标的特征(量化策略中可称为因子),如模板策略中的 return_5 (5日收益)、return_10 (10日收益)等。
AI 量化策略的特征(features):反映事物在某方面的表现或性质的事项,在 AI 量化策略中,特征可以是换手率、市盈率、KDJ 技术指标等。
第四步:数据连接 + 缺失数据处理
将上述每只股票的标注数据与特征数据链接,以便下一步模型的学习与使用。
第五步:模型训练 + 股票预测
我们通过“好坏等级”对股票进行标注,贴上标签,连同其所对应的特征值一起来构建训练模型,通过归纳总结找到属性之间的关联,总结分类经验;
用验证集数据来检验训练前面构建好的模型,即检验模型根据验证集的特征数据预测出的目标值(股票走势好坏等级)是否准确。
第六步:回测验证
将验证集的预测结果放入历史真实数据中检测,使用历史数据验证前面模型训练和策略的验证的好坏和结果。
量化总体阶段业务特点
量化交易依托“AI + 机器学习”成为行业主流
机器学习作为人工智能的核心,其传统算法在解决很多问题上都表现出了高效性。随着近些年数据处理技术上的进步和计算能力的提升,深度学习在很多问题上应用非常深,在量化投资领域,机器学习尤其是由统计学延伸的各种算法一直以来都被尝试应用在选股、择时等策略的开发上,随着深度学习在其他领域上的突破,其在自动化交易甚至投资策略的自开发自学习方面的应用成为了各大私募机构和金融寡头探索的焦点。
通过机器学习和深度学习算法,帮助快速、准确地分析海量数据,并发现其中的规律和趋势。目前,深度学习最成功的场景应用是在模式识别上,即利用已知数据,对具有一定空间、时间分布信息的数据与类别标号之间的映射做一个较好的估计。深度学习可以表现得比传统机器学习算法更好,主要有以下 3 点原因:
- 深度学习的自动提取特征比传统机器学习的人为提取特征过程更加高效。特定的应用场景中,只需要微调结构,如神经元的激活函数,就可以得到较好的效果。
- 深度学习可以通过复杂的结构和多重非线性处理层更好地捕捉各类非线性关系。
- 深度学习随着数据量的增加模型效果会不断地改善,这也是当前深度学习有逐渐取代传统机器学习模型趋势的最大原因。
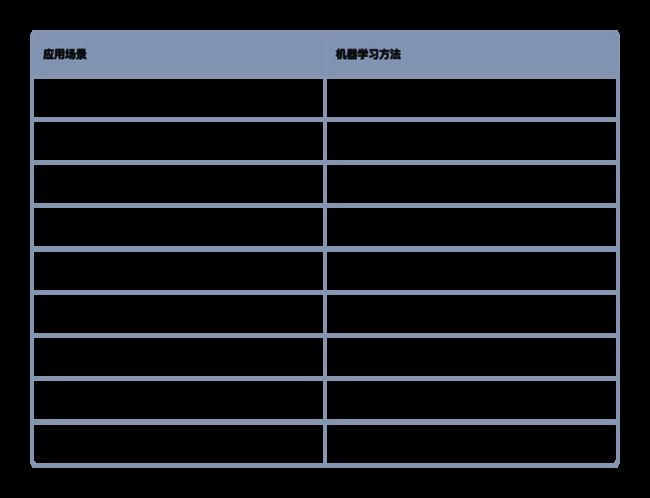
AI+机器学习算法在量化的应用场景
基于上述量化场景分析 得出如下存储要求
通过分析量化业务流程特点以及基于以 AI 和机器学习为基础的量化训练业务,每个步骤都会以不同方式给存储系统带来挑战。模型训练环节中,面临海量训练数据集的处理以及快速 I/O 响应的挑战;推理环节中,存储系统需要具备以最小延迟实时处理数据。深度学习算法的性质意味着它们会使用大量矩阵数学,这非常适合在 GPU 上执行,大量的 GPU 并行运算工作负载的复杂性加上深度学习训练所需的数据量,这带来极具挑战性的性能环境,深度学习存储系统设计必须在各种数据类型和深度学习模型中提供均衡的性能才能满足量化中模型训练的场景,具体为以下几点:
- 复杂庞大的训练数据集和神经网络的算力需求,单纯依赖内存缓存的方案已经无法满足业务的增长和快速迭代发展需求;
- 低延时+海量数据+AI 算力支撑对存储提出更高规格的要求,比如:数据量的变化、性能的要求、模型快速迭代的速度。在当今 CPU、GPU 处理能力快速提升的背景下,数据存储读写的性能往往很容易成为整个处理过程中的性能瓶颈。
- 由于量化投研采用神经网络和深度学习的技术,数据规模投入越大,模型精度就越高。大量的模型开发和训练的计算能力对于底层数据吞吐和 IOPS 提出了更高的挑战;
- 带宽和吞吐量,可以快速向计算硬件提供大量数据。无论数据特性如何,IOPS 都能维持高吞吐量; 以最小的延迟提供数据,因为与虚拟内存分页一样,当 GPU 等待新数据时,训练算法的性能会显著降低。
某创新型私募基金机构是国内领先的、业务全面的量化对冲基金,基于先进的高频交易构架,以及完善的资产管理系统,其业务线在国内期货、股票、期权等主流市场具有顶尖的盈利能力。
焱融科技在深度剖析百亿私募客户量化业务场景,发现其 IT 基础架构面临以下问题:
- 传统阵列烟囱式的架构 + 本地盘 + 单机训练模式无法支撑目前量化业务的需求;
- 基于目前使用的服务器内存和服务器本地盘的存储解决方案,不符合未来数据增长和业务增长的规划;
- 基于机器学习的量化业务,其数据量呈现猛增趋势,高性能存储横向扩展需求日渐突出;
- 量化训练模型对于多机多卡和更高算力的业务需求越加明确,对存储的性能要求越高;
- 量化训练业务容器化,支持无缝对接容器平台提供可持久化的容器存储;海量小文件的量化业务场景,要求采用最新技术如 “NVIDIA GPUDirect Storage(GDS)”,缩短显卡到存储的距离,大大提升业务的性能和效率。
极致性能提升 突破数据量限制
焱融全闪文件存储大显身手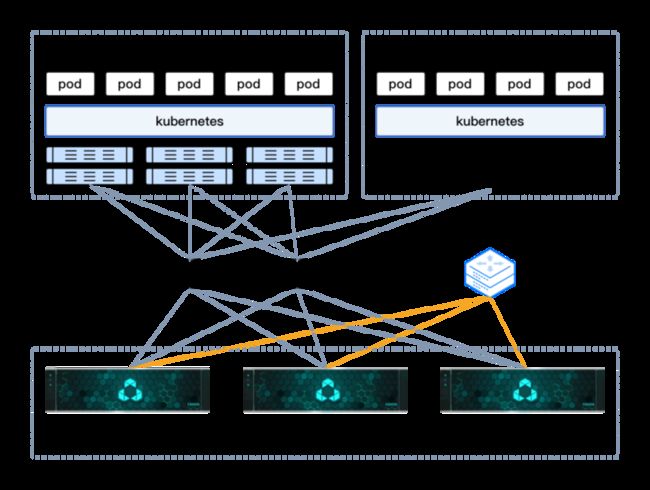
方案拓扑图
在本项目的 IT 基础设施建设中,通过采用焱融全闪分布式文件存储产品达成了对海量数据支撑、存储性能以及建设成本三者都可兼顾的解决方案。焱融全闪 F8000X 采用全 NVMe SSD、InfiniBand 等高速网络,支持 RDMA、多网卡聚合技术,以极致性能充分释放计算潜力。结合 InfiniBand 技术和追光 F8000X 针对海量小文件高并发访问等方面的优化设计,获得了超高性能表现。同时,通过 YRCloudFile 分布式存储架构、数据智能加载和分层功能,针对异构存储并存的应用场景,灵活高效地驱动数据在不同存储平台流动,方便用户组织数据集进行计算分析;使用 F8000X 将数据按照生命周期管理策略分层到本地低速存储或者云端,对业务端提供统一命名空间,降低使用复杂度,提升了数据存储使用的经济性。焱融 YRCloudFile 高性能并行文件存储在量化交易场景大显身手,解决客户由于机器内存容量限制所导致的业务扩展和海量训练数据的性能瓶颈问题;
分布式架构,弹性扩展能力
焱融追光 F8000X 采用分布式架构,数据及元数据节点可按需扩展,达到容量与性能均线性增长的能力。支持 NVIDIA GPUDirect Storage(GDS)功能,实现以直接内存的存取方式将数据传输至 GPU,显著降低 I/O 延迟,提升数据带宽,充分释放 GPU 算力,将性能发挥到极致,轻松应对量化交易场景下的数据问题。
深度 IO 模型优化
焱融追光 F8000X 采用异步非阻塞 IO 模式,有效减少上下文切换,全路径实现了零拷贝,支持批量提交和回收,增加了并行能力。高效分配处理器核心资源,支撑网络层面高并发的数据收发处理的同时,避免大量线程的调度开销,充分发挥 NVMe SSD 磁盘性能。
海量数据支持
全对称、可扩展的元数据集群架构,在面对数十亿文件时,客户端对元数据的操作性能及读写性能仍然保持持续稳定。
兼容高性能网络,支持最高 400Gb 的 IB 网络
YRCloudFile 可兼容高性能网络,能够支持最高 400Gb 的 IB 网络,为机器学习和神经网络学习提供超高的带宽能力;集群内单存储节点性能可达 200 万 IOPS 性能,40GB/s 带宽;
容器持久化存储
焱融追光 F8000X 全闪文件存储支持 CSI 对接 Kubernetes 集群,提供高效、可靠的容器持久化存储服务,同时支持多种容器特性,使得容器平台使用、监控、管理存储资源变得更加的灵活高效。
数据权限管理的支持
焱融全闪文件存储具备完善的权限管理和数据隔离功能,支撑量化特殊业务场景对于数据和研究成果的保护和使用;
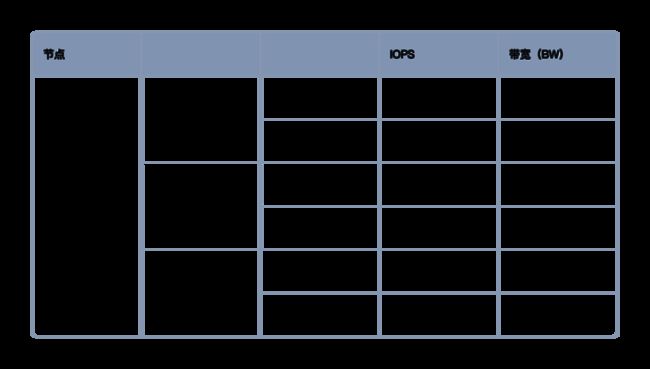
焱融全闪存储解决方案提供极致的性能输出
在量化行业数据存储痛点中,焱融高性能文件存储打造高质量的可靠存储底座,解决量化数据处理流程中不同环节带来的存储难题,实现完整的数据统一管理、场景多样化等一站式存储管理平台。