

腾小云导读
2022年来,AIGC概念迅速出圈并快速形成产业生态,成为继PGC、UGC之后新的数字内容创作形式。QQ影像中心提出了自研的AI画画技术方案——QQGC,本文作者富宸、王锐将介绍在QQGC基础大模型训练中的实践和探索,接着往下看吧\~
看目录点收藏,随时涨技术
1 背景
1.1 扩散模型
1.2 DALLE 2
1.3 Stable Diffusion
2 技术方案
2.1 整体架构
2.2 Prior模型
2.3 Decoder模型
2.4 训练加速方案
3 结果展示
3.1 Text2Image
3.2 Image Variation
3.3 融合原图语义信息的img2img
3.4 CLIP向量编辑
4 总结展望
01、背景
2022年来,随着 DALLE2、ChatGPT 等技术的突破式发展,AIGC 迎来了快速的爆发式的增长,内容生产已经从专业生成内容(PGC)、用户生成内容(UGC),进入到人工智能生成内容 AIGC(AI-Generated Content)的时代。这其中关于AI画画的应用随着生成技术的不断完善、开源社区的推动、以及大量的商业化探索,成为未来最有希望落地并广泛使用的技术方向,为数字内容创作注入新能量。

而基础大模型作为 AIGC 生态中最底层一环发挥着重要作用,因此QQ影像中心提出了自研的QQGC-AI 画画技术方案,本文将分析现有 text2Image 技术方案,以及在AI画画大模型等探索和相关技术落地案例。
1.1 扩散模型
Diffusion Model 是近几年兴起的生成式模型,比如 OpenAI 的 GLIDE、DALLE2、Google 的 Imgen、Parti 等,它们都是采用扩散模型的 pipeline 完成高质量的图像生成。
扩散模型通常包括两个过程,从信号逐步到噪声的扩散过程和从噪声逐步到信号的逆向过程。 这两个过程建立起了复杂的数据分布与简单的噪声先验分布之间的双向联系。从数据分布到先验分布是一个预先定义好的加噪过程,通过按照预先设置好的规律逐渐融合数据与噪声,将复杂的分布转换为一个简单的分布。
Diffusion Model 的反向过程则是:将原始数据与噪声混合的数据送入模型,模型预测出其中的噪声(或者原始数据),通过逐渐降低先验分布中样本的噪声,实现了从简单分布中样本到数据分布中的样本的转换。

相比 GAN、VAE 而言,Diffusion Model 解决了由于对抗训练产生的训练不稳定的问题,并且有更高的生成质量和多样性。
1.2 DALLE 2
DALLE 2 是 OpenAI 公司发布的 text2image 算法,该算法在之前 GLIDE 生成模型的基础上,大幅提升了生成效果,首次将 text2image 算法提升到一个可用的水平,获得了社会各界的广泛关注。
DALLE 2 沿用了 OpenAI 之前 GLIDE 模型的技术路线,GLIDE 模型中选择transformer 模型提取文本特征,用了 Diffusion 模型作为图像生成模型,进行端到端的训练。DALLE 2 在此基础上,选择 CLIP 模型作为文本-图像桥梁,整体主要可以分为如下几部分:
| Prior 模型:使用 CLIP text embedding 作为输入,预测待生成图像的CLIP image embedding; Decoder 模型:输入 CLIP image embedding ,预测64分辨率的小图; Upsampler 模型:输入64分辨率的小图,通过两阶段超分,将图片分辨率超分到1024分辨率; |
|---|
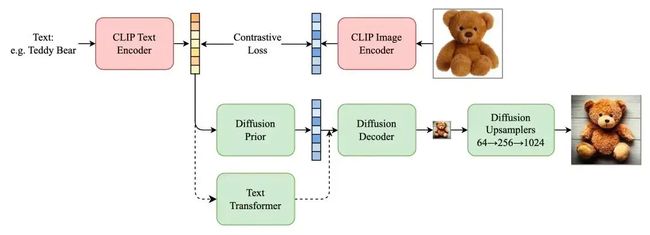
以上的方式以 CLIP 模型为桥梁,很好地将各部分任务解耦开来。对于每一项任务而言,大大降低了训练的难度。并且使用了 CLIP 作为已知的预训练模型,能够很好的提取文本图像特征,解决了端到端训练的 text transformer 能力不足问题。
1.3 Stable Diffusion
Stable Diffusion 模型是由 Stability 公司发布的一个开源的 text2image 模型,该模型以 latent-diffusion 模型为基础,融合了 DALLE2 以及 Imagen 等方法的优点。使用 CLIP text embedding 作为模型输入,预测一个 VAE 的 latent sapce ,然后通过 VAE decode 得到原始分辨率大小。

通过替换 CLIP 语言模型以及 classifier-free guidance 等方法,Stable Diffusion 做出了非常好的效果。而且由于其相对简洁的 pipeline,不需要超分作为后处理流程,大大降低了训练和部署成本。
很多社区和公司在 Stable Diffusion 的基础上改进衍生出了自己模型,使得 text2image 成功出圈,衍生了很多不同的生成技术和玩法。
02、技术方案
2.1 整体架构
通过对 DALLE2、Stable Diffusion 等方案的对比,QQ 影像中心探索了自研的 text2image 方案,包含如下几个重要的改进技术方向:
更强的文本特征提取:
通过 DALLE2 和 Stable Diffusion 等模型的改进方案可以看到,语言模型特征提取在图片生成过程中至关重要。包括 Google 的 Imagen 以及 Nvidia 等 ediff 等方案,都尝试在引入了更多更强大的语言模型作为文本特征提取器,并且取得效果上的显著提升;
对训练数据要求较低的技术框架:
高质量 text-image 成对的数据要求文本能够很好地描述图片,同时图片也有足够高的质量,其收集的难度远大于收集单独的高质量图片(或文本)。所以要求将文生图任务尽量解耦,降低对数据收集的要求,让训练更容易收敛;
更轻量低成本的训练部署:
Stable Diffusion 模型能够迅速破圈的原因在于其相对轻量的技术方案,通过减少超分等更大计算量的步骤,大大减少了训练及部署的成本,这一点在当前降本增效的大环境下显得更加重要;
基于以上分析,我们提出了如下的技术架构。核心主要包含 prior 模型和 decoder 模型两部分。在几乎不引入额外计算量的情况下,可以大幅超越 Stable Diffusion 开源模型,达到 DALLE2 等第一梯队 text2image 模型的水平。

2.2 Prior模型
经过实验我们发现,直接通过 CLIP text embedding 输入 Stable Diffusion 的方案在图文一致性上存在明显的缺陷。因此我们参考了 DALLE2 的模型设计思路,将 text embedding -> image 一步的思路,拆分成 text embedding -> image embedding -> image 两阶段,增加了 prior 模型作为从 text 特征域到 image 特征域的映射,这样可以显著降低训练难度以及提升生成效果。同时为了增强文本特征的提取能力,我们还融合了 T5 类语言模型作为特征提取模型,实现更强的语意理解能力。
2.3 Decoder模型
Decoder 模型的输入是 CLIP image embeddings,输出图片。在实现上,我们复用了 Stable Diffusion 的 pipeline,将 Stable Diffusion 的 condition 从CLIP text embedding 替换成 CLIP image embeddings。
在训练 Decoder 模型的过程中,不需要文本数据的参与,只需要收集高质量图片数据即可。对应地,训练 Prior 模型时,更关注训练数据中图文数据的语义匹配程度,对图文 pair 中图片的质量要求不高。这样,训练高质量文生图模型的数据收集要求被拆解、降低。
2.4 训练加速方案
如何用有限的资源和成本,快速高效的训练 text2image 大模型? 这是一项非常有挑战的任务。加速训练的核心在于消除整个训练 pipeline 中的性能短板,提高计算密度和计算效率。因此我们主要从如下几个方面入手进行了加速改进。
- 提高数据效率:
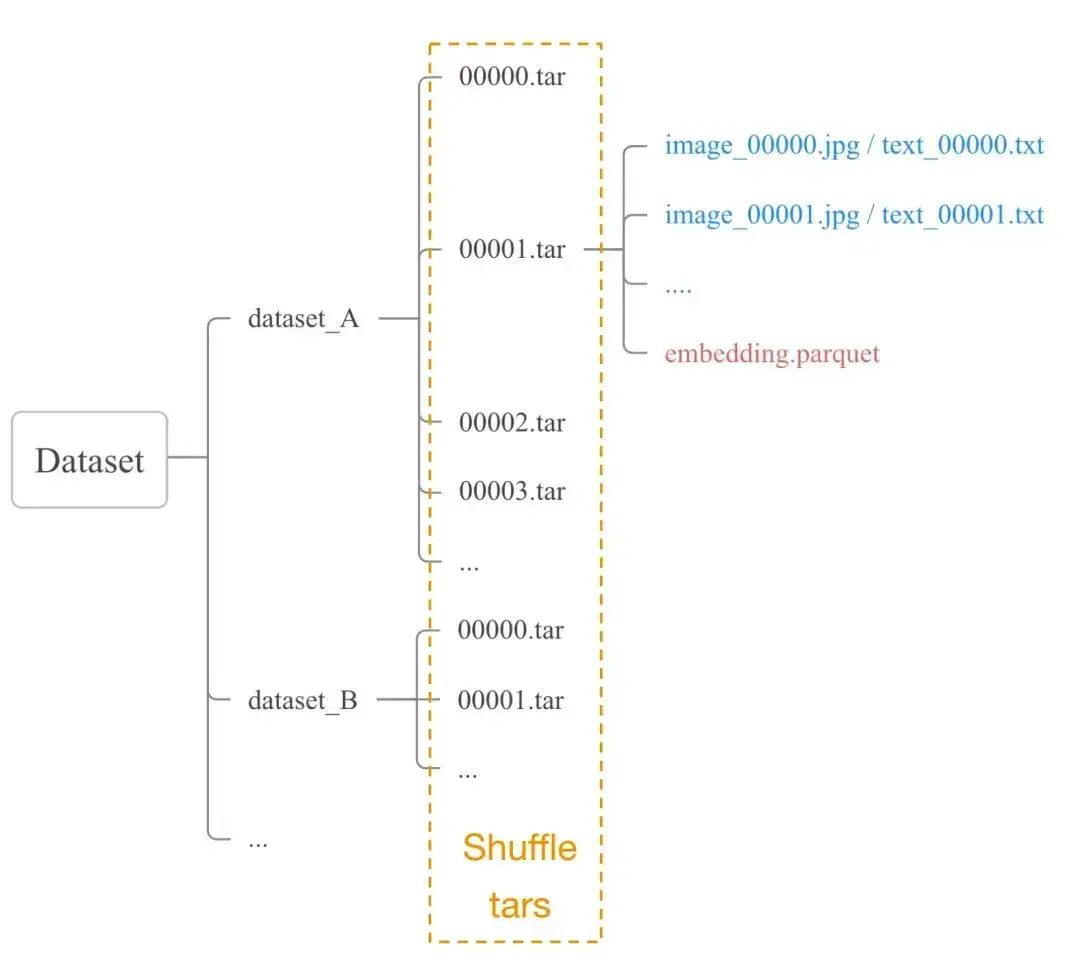
Text2image 训练依赖海量的数据,不同于传统CV任务,数据量的增加了几个量级,需要设计面向大数据的高效 dataloader,解决数据读取方面的短板。这里我们选取了 tar 包形式的数据组织方式,将数据分层存储,将 百M 条数据分 每10K 数据打包成一个 tar 包,这样就降低了数据读取的难度,数据的 shuffle 等操作仅在 tar 包这一层级进行。
- 提高计算密度/效率:
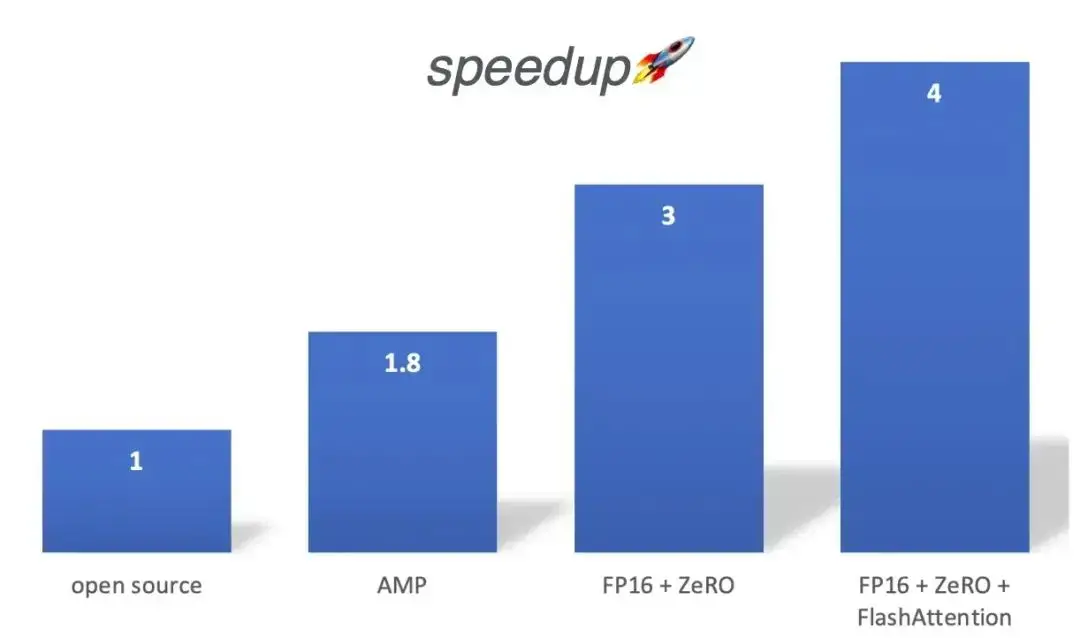
提高训练速度最有效的方式就是尽量提高计算密度,即在一张 GPU 上部署更大的 batchsize 。我们使用了 FP16 半精度训练、activation checkpoint,以及 ZeRO(零冗余优化器) flash attention算子优化等方法显著的减少了显存占用,单卡 batchsize 增加了8倍,训练速度提升到了4倍。
- 减少通信开销:
在部署分布式多机训练时,由于模型参数量较大,多机间的通信耗时往往是模型训练的瓶颈。我们采用 GPU RDMA 网络直连通信,能够保证基础的网络通信性能。我们使用梯度累加,以及优化器方面的优化工作,来减少通信量,节约通信的成本。经过上述优化,我们可以在64卡集群上就可以很快的进行超过 2B 参数量模型的训练。
03、结果展示
3.1 Text2Image
我们在 COCO-30k 上评测了 FID 和 CLIP-score 指标的表现,结果达到同等级SOTA 水平。
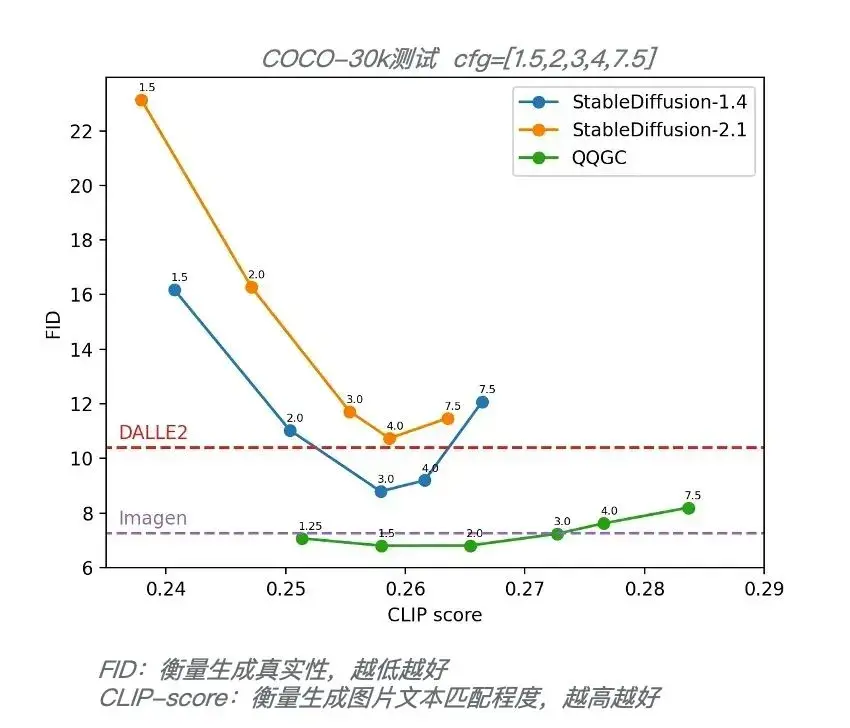
以下为一些自研模型的生成效果,可以作为通用大模型已经可以生成非常高质量的不同物体、风格、及抽象概念的图像。

以下是一些模型生成效果示例,在语义贴合度、美观度方面远超 StableDiffusion 模型:
3.2 Image Variation
Decoder 模型可以根据图片的 CLIP embedding 来重建图片。下面是用我们训练的 Decoder 模型重建各种图片的示例:

可以看到,无论是艺术画,还是肢体复杂的自然图片,包括由其它(Parti 和 DALLE2)生成的复杂图片,我们的 Decoder 的模型都能重建还原其神韵,在语义层次很接近。证明我们训练的 Decoder 模型有较强的还原 Clip image embedding 能力,只要 Prior 模型能生成符合 prompt 描述的 Clip image embedding ,组合两者就可以得到一个强大的文生图模型。
3.3 融合原图语义信息的 img2img
Stable Diffusion 除了可以用来实现文生图生成,也可以通过用加噪的图片取代一部分 Diffusion 过程,实现 img2img。用于加噪的图片也常被称为垫图。但是基于 Stable Diffusion 实现的的 img2img 只利用了输入图片的加噪结果,常常面临保留原图更多信息和保留 prompt 对应效果之间的权衡。而 QQGC-AI 画画模型由于将生成步骤拆分成了两个阶段,可以在 Decoder 生成图片过程中,利用垫图的加噪结果,融合垫图的语义特征和 prompt 对应的特征,实现融合原图语义信息的 img2img。
比如使用如下 prompt:
| two women standing next to each other holding hands, portrait, elegant, intricate, digital painting, artstation, concept art, smooth, sharp focus, illustration, art by konstantin korovin and daniel f. gerhartz and john howe |
|---|
调用 QQGC-AI 画画模型完成文生图任务:
类似于 Stable Diffsuion 实现的 img2img,QQGC-AI 画画模型也可以给定一个垫图,在由 Prior 生成的 condition 向量控制下实现基础的 img2img:
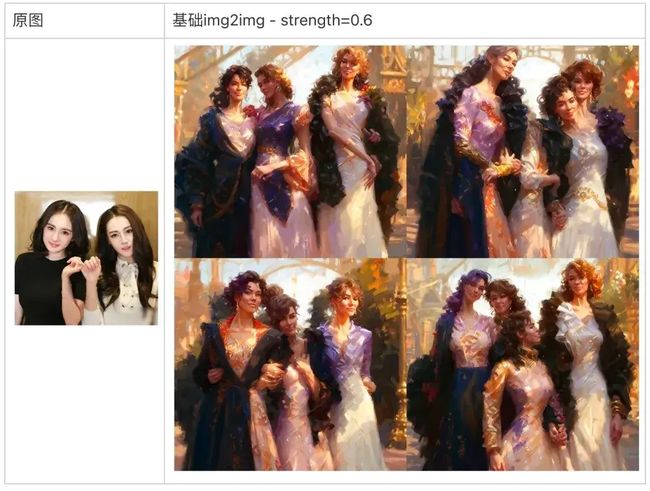
可以注意到,由于这种基础的 img2img 完全不考虑原图的语义信息,只是用了原图的结构(色块),导致生成图只保留了一些比如右边女性的头发区域是黑色这样的信息,但完全忽略了这部分区域是头发的语义信息,生成图对应区域成了黑色的袖子。
为了融合原图的语言信息,可以将 prompt 对应的 image embedding 和原图的 embedding 混合,然后由 Decoder 将混合 image embedding 转化为图片。借此,实现了融合了原图语义信息的 img2img:

3.4 CLIP 向量编辑
由于二阶段模型提供了两个域很好的解耦性,我们可以直接在 CLIP Embedding 域做向量编辑来达到对图片的精细修改的效果,如下图展示了通过对向量做编辑,实现精准的水印文字去除甚至增加水印的能力:

同时,为了让模型生成内容更加健康正能量、主体更美观,在输入 text 包含血腥、色情等描述时,也可以在 diffusion 过程中对 CLIP embbeding 做控制,达到生成内容更加真善美的目的。

04、总结展望
通过以上结果可以看到,QQ 影像中心自主研发的 QQGC 两阶段生成大模型具备:更好的文本图像域解耦、更精准的生成语意匹配度、更低模型训练部署成本、支持更为复杂丰富的编辑控制操作等特性。
QQGC 基础大模型作为 AIGC 技术落地中的 Foundation 模型将会发挥重要作用,QQ 影像中心也以 QQGC 大模型为基础,上线了小世界“魔法画室”功能。后台回复**「QQ」**,体验AI绘画。
可以根据用户的自由输入直接生成高质量的生成结果:

同时,在业界很关注的在不同风格、场景的生成图片中保留身份特征、更强的生成控制能力上,我们也在持续探索,会在未来的活动中上线,欢迎大家在腾讯云开发者公众号评论区中反馈讨论交流\~

欢迎在腾讯云开发者公众号评论区聊一聊对AI绘画的看法。AI绘画的出现会替代某些岗位吗?AI绘画能有哪些应用场景?我们将选取1则最有创意的评论,送出腾讯云开发者-鼠标垫1个(见下图)。6月1日中午12点开奖。




