NLP-Beginner任务四学习笔记:基于LSTM+CRF的序列标注
**用LSTM+CRF来训练序列标注模型:以Named Entity Recognition为例**
数据集:CONLL 2003,https://www.clips.uantwerpen.be/conll2003/ner/
任务一博客链接:https://blog.csdn.net/qq_51983316/article/details/129314052
任务二博客链接:https://blog.csdn.net/qq_51983316/article/details/129387225
任务三博客链接:https://blog.csdn.net/qq_51983316/article/details/129470730
参考论文:
1、https://arxiv.org/pdf/1603.01354.pdf
2、https://arxiv.org/pdf/1603.01360.pdf
目录
一、数据集
二、知识点学习
(一)命名实体识别任务(NER)
1、基本概念
2、主要方法
(二)条件随机场(CRF)
1、基本概念
2、基于CRF的命名实体识别
(三)LSTM+CRF
1、模型原理
2、模型详解
3、CRF损失函数
(四)模型评估
1、混淆矩阵
2、精确率(Precision)
3、准确度(Accuracy)
4、召回率(Recall)
5、F1-score
三、实验
(一)代码实现
1、main.py
2、utils.py
(二)结果分析
一、数据集
The first item on each line is a word, the second a part-of-speech (POS) tag, the third a syntactic chunk tag and the fourth the named entity tag.
原始数据集共有三个文件:train.txt, test.txt 和 dev.txt
CoNLL-2003共享任务数据文件包含由一个空格分隔的四列。每个单词都放在单独的一行,每个句子后面都有一个空行。每行上的第一项是一个单词,第二项是词性标签,第三项是句法组块标签,第四项是命名实体标签。块标记和命名实体标记的格式为I-TYPE,这意味着单词位于TYPE类型的短语内。只有当同一类型的两个短语紧跟在一起时,第二个短语的第一个单词才会有标记B-type,以显示它开始了一个新短语。标记为O的单词不是短语的一部分。下面是一个示例:

原数据:
Peter NNP B-NP B-PER
Blackburn NNP I-NP I-PER
输入文本: Peter Blackburn
输出序列: B-PER I-PER
原数据:
EU NNP B-NP B-ORG
rejects VBZ B-VP O
German JJ B-NP B-MISC
call NN I-NP O
to TO B-VP O
boycott VB I-VP O
British JJ B-NP B-MISC
lamb NN I-NP O
输入文本: EU rejects German call to boycott British lamb.
输出序列: B-ORG O B-MISC O O O B-MISC O O
二、知识点学习
(一)命名实体识别任务(NER)
1、基本概念
命名实体识别(Named Entity Recognition,NER)是信息提取、问答系统、句法分析、机器翻译等 NLP 应用领域的重要基础工具。一般而言,NER的任务就是识别出待处理文本中三大类(实体类、时间类和数字类)、七小类(人名、机构名、地名、时间、日期、货币和百分比)命名实体。
NER英文命名实体识别的目标是识别句子中每个词语的实体类型,包括5大类:PER(人名)、LOC(地名)、ORG(组织名)、MISC(其它类型实体)、O(非实体)。
由于实体可能是由多个词语构成的,因此使用标注B、l来区分该词语是该实体的起始词(Begin)还是中间词(Inside)
但随着 NLP 任务的不断扩充,在特定领域中会出现特定的类别,比如医药领域中,药名、疾病名称等类别。同时,实体类型是根据需求人为定义的,这种定义可以是有层次的。例如,产品类是一个大类,下面可能会包含手机类、电脑类、照相机类等等。这种定义就是本体建模。
NER任务常转化为序列标注问题,利用BIO、BIOES和BMES等常用的标注规则对经过分词的文本进行token标注。序列标注的命名实体识别方法中,CNN、BERT、LSTM等深度模型与条件随机场CRF结合已经成为最主流和普遍的方法。
2、主要方法
(1)基于规则和字典的方法:规则的设计一般基于句法、语法、词汇的模式及特定领域的知识。 制定好规则和词典后,通常使用匹配的方式对文本进行处理以实现命名实体识别。
(2)基于传统机器学习的方法,命名实体识别往往被视作序列标注问题,主要有以下方法:
- 隐马尔可夫模型(Hidden Markov Model, HMM)
- 最大熵(Maximum Entropy, ME)
- 最大熵马尔可夫模型(Maximum Entropy Markov Model, MEMM)
- 支持向量机(Support Vector Machine, SVM)
- 条件随机场( Conditional Random Fields, CRF)
(3)基于深度学习的方法,近年往往在基于神经网络的结构上加入注意力机制、图神经网络、迁移学习、远监督学习等热门研究技术进行NER任务的实现,主要有以下方法:
- BiLSTM-CRF
- IDCNN-CRF
- CAN-NER
- BERT-Attention
(二)条件随机场(CRF)
1、基本概念
条件随机场(CRF)是一种在已知一组输入随机变量条件的情况下,输出另一组随机变量的条件概率分布模型;其前提是假设输出随机变量构成马尔可夫随机场;条件随机场可以应用于不同类型的标注问题,例如:单个目标的标注、序列结构的标注和图结构的标注等。
CRF模型是在隐马尔可夫模型(HMM)模型的基础上发展起来的。根据HMM模型的齐次马尔科夫性假设:假设隐藏的马尔科夫链在任意时刻 t 的状态只依赖于其前一时刻的状态,与其他时刻的状态及观测无关,也与时刻 t 无关。但CRF模型不仅考虑前一时刻的状态,还考虑其前面与后面的多个状态。因此一般来说,CRF会具有更好的标记性能。
假设训练集为
,对应的标记序列为
以及多个特征函数,CRF 模型参数
和
的参数形式和条件概率分布
公式如下:
可以看出 CRF 有两类特征函数:其中一类是定义在
另一类特征函数是定义在 y 节点上的节点特征函数,只和当前节点有关,K 是定义在该节点的节点特征函数的总个数,i 是当前节点在序列的位置,公式如下:
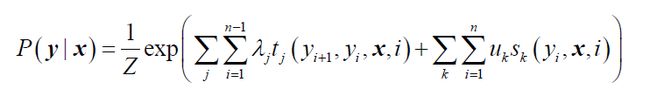


2、基于CRF的命名实体识别
采用 CRF 模型对每个字标注对应实体类型的BIO标记,BIO 标记有 B-Person-人名的开始部分、I-Person-人名的中间部分、B-Organization-组织机构的开始部分、I-Organization-组织机构的中间部分和 O-非实体信息。
例如:句子“白居易是中国杰出的诗人”,其对应的观察序列和标注序列如下所示:
根据 CRF 的特征函数可以构建上下文特征、词本身特征和词性特征等,如下:


(三)LSTM+CRF
1、模型原理
BiLSTM-CRF 的命名实体识别模型架构图如下:(来自论文《Neural Architectures for Named Entity Recognition》),每个句子按照词序逐个输入双向LSTM中,结合正反向隐层输出得到每个词属于每个实体类别标签的概率,输入CRF中,优化目标函数,从而得到每个词所属的实体类别。
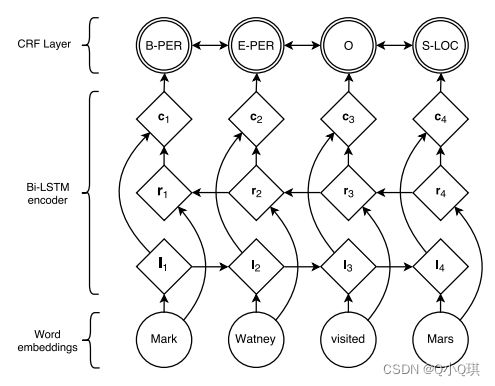
其中 BiLSTM 层的输入是每个词的向量表示;BiLSTM 层的输出是当前时刻的输入属于每个实体类别标签的概率;CRF 层主要负责计算得分,确定最终的标注序列。
2、模型详解
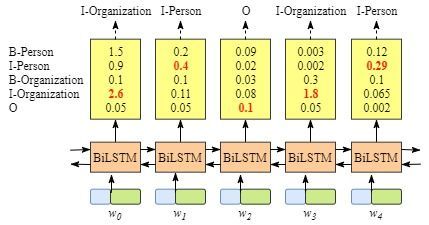
假设 x 是一个短句子序列,共包含5个单词,记为(w0,w1,w2,w3,w4)。其中,x 中 [w0,w1] 是人名,[w3] 是组织机构名称,其他非实体均为“O”。
第一层为词嵌入层。句中的每个单词是一条包含词嵌入和字嵌入的词向量,词嵌入通常是事先训练好的,字嵌入则是随机初始化的。所有的嵌入都会随着训练的迭代过程被调整。
第二层为 BiLSTM 编码。该层的输入是将单个词w0通过onehot编码,词嵌入之后的k维稠密向量,BiLSTM层的输出表示该单词对应各个类别的分数,见下图:
其中,W0,BiLSTM节点的输出是1.5 (B-Person), 0.9 (I-Person), 0.1 (B-Organization), 0.08 (I-Organization) and 0.05 (O),输出这些标签的概率得分后将其传入CRF层。
第三层为CRF打分层。所有的经 BiLSTM 层输出的分数将作为 CRF 层的输入,类别序列中分数最高的类别就是预测的最终结果。
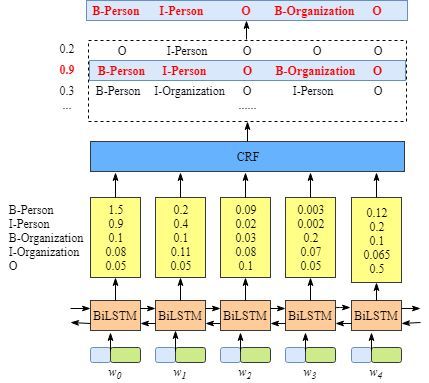
从上述描述来看,BiLSTM已然可以完成分类和序列标注工作,那CRF的作用又体现在哪里呢,是不是也可以去掉CRF层?
因为BiLSTM模型的结果是单词对应各类别的分数,我们可以选择分数最高的类别作为预测结果。如W0,“B-Person”的分数最高(1.5),那么我们可以选定“B-Person”作为预测结果。同样的,w1是“I-Person”, w2是“O”,w3是 “B-Organization” ,w4是 “O”。尽管我们在该例子中得到了正确的结果,如左图。但实际情况并不总是这样,如右图。
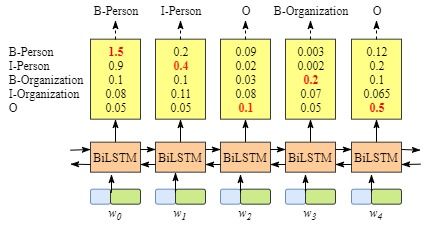
很明显,右图BiLSTM的输出并不正确。因此,CRF是必要的。
CRF能为BiLSTM提供转换的一些约束,拿词性标注举例子,形容词后面大概率会跟名词,名词后面大概率会跟动词,还可以提供整个序列的概率统计,前面出现了某些单词后,这个位置应该是谓词。因为LSTM只是对每一步的向量进行过滤和叠加,这些信息是LSTM不好捕捉的。
CRF层的约束可以在训练数据时被CRF层自动学习得到。
可能的约束条件如下,有了这些有用的约束,错误的预测序列将会大大减少。
- 句子的开头应该是“B-”或“O”,而不是“I-”。
- “B-label1 I-label2 I-label3…”,在该模式中,类别1,2,3应该是同一种实体类别。比如,“B-Person I-Person” 是正确的,而“B-Person I-Organization”则是错误的。
- “O I-label”是错误的,命名实体的开头应该是“B-”而不是“I-”。
因此,BiLSTM可以捕捉长距离的上下文信息,对于每一步能获得很好的语意向量,CRF是对整个序列进行似然概率统计,并且捕捉转换信息,将两者结合起来可以互补不足。
3、CRF损失函数
CRF损失函数由两部分组成,真实路径的分数 和 所有路径的总分数。真实路径的分数应该是所有路径中分数最高的。其中每条路径上的损失函数都包括两种类型的分数(状态分数+转移分数)。
(1)状态分数(Emission score):也称发射分数(状态分数),该分数来自BiLSTM层的输出,如上左图所示,w0被预测为B-Person的分数是1.5,该分数为发射分数。
(2)转移分数:表示从一个类别转移至另一个类别的得分,所有类别间的转移分数矩阵如下:【为了使转移分数矩阵更具鲁棒性,我们加上START 和 END两类标签。START代表一个句子的开始,END代表一个句子的结束】
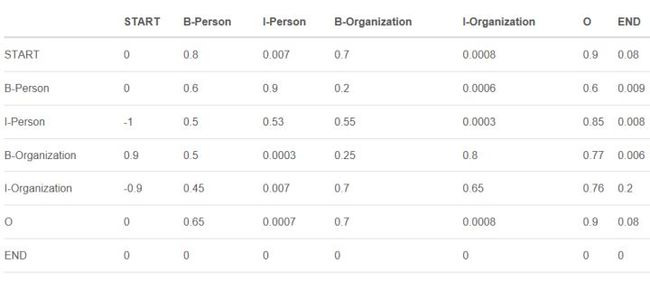
实际上,转移矩阵是BiLSTM-CRF模型的一个参数。在训练模型之前,你可以随机初始化转移矩阵的分数。这些分数将随着训练的迭代过程被更新,换言之,CRF层可以自己学到这些约束条件。
总体而言,CRF 的损失函数计算公式如下所示:

其中,对于5个词组成的句子,假定类别标签有5个(B-Person, I-Person, B-Organization, I-Organization, O),其可能的类别序列有![]() ,即 N = 3125。
,即 N = 3125。
总之,LSTM-CRF的模型结构如下:(来自论文《End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF》)
LSTM+CRF模型用字符级别的embedding作为输入捕捉字符信息,然后将其跟单词embedding拼接起来作为BiLSTM的输入。然后BiLSTM的输出给到CRF模型来进行序列的联合解码。BiLSTM的输入和输出都加了dropout。实验表明dropout可以有效提升模型表现。
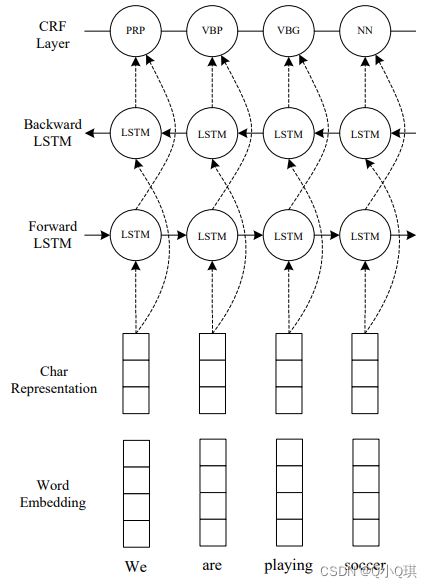 from "End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF"
from "End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF"
代码实现:
import torch
import torch.nn as nn
from torch.nn.utils.rnn import pack_padded_sequence
from torch.nn.utils.rnn import pad_packed_sequence
from torchcrf import CRF # pytorch-crf包提供了一个CRF层的PyTorch版本实现
"""定义神经网络模型类 LSTM_CRF"""
class LSTM_CRF(nn.Module):
# vocab_size: 词汇表的大小(即词汇量)。
# tag_to_index: 一个字典,将标签映射到索引。
# embedding_size: 嵌入层的维数。
# hidden_size: 隐藏层的大小。
# max_length: 句子的最大长度。
# vectors: 预训练词向量(默认为None)。
def __init__(self, vocab_size, tag_to_index, embedding_size, hidden_size, max_length, vectors=None):
# 调用父类的初始化函数
super(LSTM_CRF, self).__init__()
self.embedding_size = embedding_size
self.hidden_size = hidden_size
self.vocab_size = vocab_size
# 标签到索引的映射字典
self.tag_to_index = tag_to_index
# 标签数量
self.target_size = len(tag_to_index)
# 初始化嵌入层,如果提供了预训练词向量,则使用预训练词向量进行初始化
if vectors is None:
self.embedding = nn.Embedding(vocab_size, embedding_size)
else:
self.embedding = nn.Embedding.from_pretrained(vectors)
# 初始化BiLSTM模型
# hidden_size // 2 是整除运算符,表示将 hidden_size 的值除以 2 并向下取整,得到的结果作为新的 hidden_size 的值。
# 这个操作的目的是将 LSTM 层的 hidden_size 拆成两个部分,以便实现双向 LSTM。
# 如果 hidden_size 的值为 100,则 hidden_size // 2 的值为 50,即每个方向上的 LSTM 的 hidden_size 值都是 50。
self.lstm = nn.LSTM(embedding_size, hidden_size // 2, bidirectional=True)
# 定义一个全连接层,将隐藏层的输出映射到标签的数量
self.hidden_to_tag = nn.Linear(hidden_size, self.target_size)
# 定义条件随机场层
self.crf = CRF(self.target_size, batch_first=True)
# 存储最大句子长度
self.max_length = max_length
# 定义函数,根据给定的句子长度列表生成一个掩码
def get_mask(self, length_list):
# 函数根据输入的句子长度列表生成一个掩码张量,掩码张量用于屏蔽输入句子中的填充元素
mask = []
# 零填充: 根据长度列表生成掩码张量,其中长度小于最大长度的位置用0填充,否则用1填充。
for length in length_list:
mask.append([1 for i in range(length)] + [0 for j in range(self.max_length - length)])
return torch.tensor(mask, dtype=torch.bool)
# 定义LSTM层的前向传递函数
def LSTM_Layer(self, sentences, length_list):
# 将输入序列嵌入到低维空间中
embeds = self.embedding(sentences)
# 使用pack_padded_sequence函数将嵌入序列打包
packed_sentences = pack_padded_sequence(embeds, lengths=length_list, batch_first=True, enforce_sorted=False)
# 使用LSTM层处理打包后的序列
lstm_out, _ = self.lstm(packed_sentences)
# 将打包后的序列解包
result, _ = pad_packed_sequence(lstm_out, batch_first=True, total_length=self.max_length)
# 将结果传递到全连接层中进行标记预测
feature = self.hidden_to_tag(result)
return feature
# 计算给定排放分数的标签序列的条件对数似然性
def CRF_layer(self, input, targets, length_list):
"""input:发射得分张量,大小为(seq_length, batch_size, num_tags)或(batch_size, seq_length, num_tags),取决于batch_first参数是否为 True。
targets:标记序列张量,大小为(seq_length, batch_size)或(batch_size, seq_length),取决于batch_first参数是否为True。
length_list:每个句子的实际长度列表。
该函数调用了self.crf,它是一个torchcrf库中的CRF层。它接受3个参数:
emissions:发射得分张量,大小为(seq_length, batch_size, num_tags)或(batch_size, seq_length, num_tags),取决于batch_first参数是否为True。
tags:标记序列张量,大小为(seq_length, batch_size)或(batch_size, seq_length),取决于batch_first参数是否为True。
mask:掩码张量,大小为(seq_length, batch_size)或(batch_size, seq_length),取决于batch_first参数是否为True。
"""
return self.crf(input, targets, self.get_mask(length_list))
def forward(self, sentences, length_list, targets):
# length_list 包含了每个句子的实际长度;targets 包含了每个句子中每个词对应的标签
# 调用 LSTM_Layer 方法对输入序列进行处理得到 x。
x = self.LSTM_Layer(sentences, length_list)
# 将 x 和 targets 传递给 CRF_layer 方法,用于计算条件对数似然
x = self.CRF_layer(x, targets, length_list)
return x
def predict(self, sentences, length_list):
out = self.LSTM_Layer(sentences, length_list)
mask = self.get_mask(length_list)
# 将 LSTM_Layer 的输出 out 和 mask 传递给 decode 方法来预测每个词对应的标签序列,然后将预测得到的标签序列返回。
return self.crf.decode(out, mask)(四)模型评估

1、混淆矩阵
在模型评价中,一般会用准确度(Accuracy)评估模型好坏,但准确度并不总是衡量分类性能的重要指标,准确度、召回率和F1-score在评测分类模型性能起到非常重要的作用。为了帮助确定这些指标的重要性,定义了混淆矩阵:

True Positives (TP):正确分类为阳性的阳性实例数
False Positives (FP):错误分类为阳性的阴性实例数
True Negatives (TN):正确分类为否定的否定实例数
False Negatives (FN):错误分类为阴性的阳性实例数
2、精确率(Precision)
精确率(Precision)是真正例(TP)占所有正例(TP+FP)的比例。精确率也叫查准率,以物体检测为例,精确率高表示模型检测出的物体中大部分确实是物体,只有少量不是物体的对象被当成物体。该指标能够说明模型的正例预测有多精确。当我们认为假阳性比假阴性更重要时,精确度很重要(例如反欺诈识别)。

3、准确度(Accuracy)
准确率(Accuracy)是最直观的评价指标,即模型判断正确的数据(TP+TN)占总数据的比例。

使用准确度的一个问题是当数据不平衡时,没法准确评估精度,数据越不平衡,问题就越严重。
4、召回率(Recall)
召回率(Recall)是模型正确判断出的正例(TP)占数据集中所有正例的比例。召回率也叫查全率,该指标衡量了模型能够正确召回的实际正例的数量。当我们认为假阴性比假阳性更重要时,召回很重要(例如,癌症检测)。

这种权衡试图解决的问题以及偏向误报而非误报的任何固有后果(反之亦然)。
以癌症为例:
设计一个具有高召回率的模型可以识别大多数癌症患者(真阳性),挽救他们的生命,但代价是将健康个体误诊为癌症(假阳性),让他们接受昂贵而危险的治疗。另一方面,设计一个精确的模型可以得到可靠的诊断(即,预测患有癌症的人很可能确实患有癌症),但代价是无法识别每个患有该疾病的人(假阴性),从而对那些未被诊断的人造成潜在的致命后果。(因为假阴性会导致死亡,我们的分类阈值可能会被设置为优化查全率而非查准率)。
5、F1-score
考虑到这种相互竞争的权衡,拥有一个同时考虑精确度和召回率的单一性能指标将非常重要。因此,诞生了F1-score,该指标同时考虑了精确度和召回率,通过取两个指标的调和平均值来计算:

在精确度或召回率较差的情况下,F1-score也会较差。只有当准确率和召回率都有很好的表现时,F1-score才会很高。它是比较多分类器性能的一种很好的方法。当在多个模型之间进行选择时,所有模型都具有不同的精度和/或召回值,它在实践中经常被用作根据性能对模型进行排名的度量。
三、实验
参数设置:
训练集:train.txt中前14000条数据
测试集:test.txt中前3200条数据
模型:LSTM-CRF
词嵌入初始化:GloVe预训练模型初始化(glove.6B.50d.txt)random_seed:2023
学习率:0.001n_classes = 5 # 分类个数
batch_size:250
embedding_size:50 # 每个词向量有几维
hidden_size:50
epochs:20
运行环境:
python:3.7
pytorch:1.7.0(gpu)
torchtext:0.8.0
cuda版本:10.1
(一)代码实现
1、main.py
import os
import numpy as np
import time
import torch
import matplotlib.pyplot as plt
from torchtext.vocab import Vectors
from utils import read_data
from utils import get_dataloader
from utils import pre_processing
from utils import compute_f1
from model import LSTM_CRF
# 参数设置
n_classes = 5 # 分类个数
batch_size = 250
embedding_size = 50 # 每个词向量有几维(几个特征)
hidden_size = 50
epochs = 20
vectors = Vectors('data/glove.6B.50d.txt')
def train(model, vocab_size, tag2idx, embedding_size, hidden_size, max_length, vectors=None):
# model: 要训练的模型,类型为 LSTMCRF。
# vocab_size: 词汇表大小,即训练集中不同词汇的数量。
# tag2idx: 标签到索引的映射字典。
# embedding_size: 嵌入层的维度大小。
# hidden_size: LSTM 隐藏层的维度大小。
# max_length: 训练集中句子的最大长度。
# vectors: 预训练的词向量矩阵。
model = model(vocab_size, tag2idx, embedding_size, hidden_size, max_length, vectors=vectors)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# loss_history 记录了每个 epoch 的平均损失,f1_history 记录了每个 epoch 的平均 F1 分数
loss_history = []
# 训练集数据加载器的长度,等于训练集中的样本数量除以batch size
print("dataloader length: ", len(train_dataloader))
model.train()
f1_history = []
# 循环次数为epochs,epoch次数 = 迭代次数 / batch size;迭代次数 = 样本数量 / batch size
for epoch in range(epochs):
total_loss = 0.
f1 = 0
for idx, (inputs, targets, length_list) in enumerate(train_dataloader):
# 梯度清零,以免梯度累积
model.zero_grad()
# 计算每个样本的损失,并将损失加到总损失中。损失是模型的负对数似然损失
loss = (-1) * model(inputs, length_list, targets)
total_loss += loss.item()
# 这两行代码计算每个样本的预测结果,并将F1分数加到总F1分数中
pred = model.predict(inputs, length_list)
f1 += compute_f1(pred, targets, length_list)
# 计算模型的梯度、对梯度进行剪裁,然后使用优化器
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)
optimizer.step()
# 每 10 个批次输出一次当前 epoch 的平均损失和 F1 分数
if (idx + 1) % 10 == 0 and idx:
cur_loss = total_loss
loss_history.append(cur_loss / (idx+1))
f1_history.append(f1 / (idx+1))
total_loss = 0
# batch指一次性处理的一组训练样本,将其分为多个小批次,每个小批次包含的样本数量为batch size
print("epochs : {}, batch : {}, loss : {}, f1 : {}".format(epoch+1, idx*batch_size,
cur_loss / (idx * batch_size), f1 / (idx+1)))
# 绘制损失图
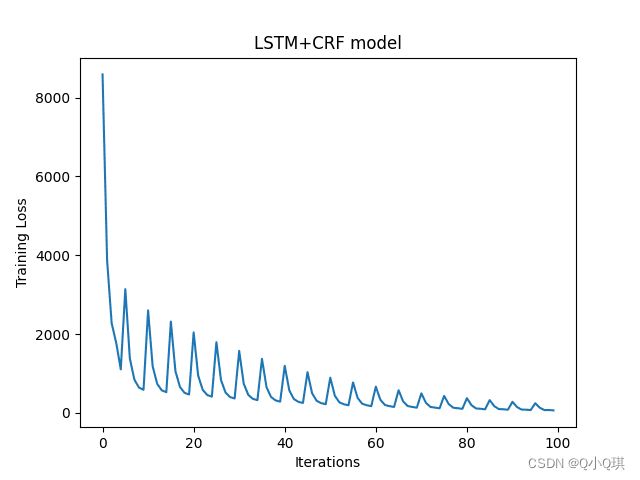
plt.plot(np.arange(len(loss_history)), np.array(loss_history))
plt.xlabel('Iterations')
plt.ylabel('Training Loss')
plt.title('LSTM+CRF model')
plt.show()
# 绘制f1得分图
plt.plot(np.arange(len(f1_history)), np.array(f1_history))
plt.title('train f1 scores')
plt.show()
# 将模型设置为评估模式,这意味着在模型的前向传播过程中,不会更新权重,也不会计算梯度,以加快模型的执行速度
model.eval()
f1 = 0
f1_history = []
s = 0
with torch.no_grad():
# 迭代测试数据集的每个batch,其中inputs是输入序列,targets是对应的标签序列,length_list是每个输入序列的实际长度。
for idx, (inputs, targets, length_list) in enumerate(test_dataloader):
loss = (-1) * model(inputs, length_list, targets)
total_loss += loss.item()
# 使用模型进行预测,并返回预测的标签序列
pred = model.predict(inputs, length_list)
# 计算预测标签序列和真实标签序列之间的F1值,并将结果累加到f1中
f1 += compute_f1(pred, targets, length_list) * 250
print("f1 score : {}, test size = {}".format(f1/3200, 3200))
if __name__ == '__main__':
x_train, y_train = read_data("data/train.txt", 14000)
x_test, y_test = read_data("data/test.txt", 3200)
word2idx, tag2idx, vocab_size = pre_processing()
train_dataloader, train_max_length = get_dataloader(x_train, y_train, batch_size)
test_dataloader, test_max_length = get_dataloader(x_test, y_test, 250)
train(LSTM_CRF, vocab_size, tag2idx, embedding_size, hidden_size, max_length=train_max_length, vectors=None)2、utils.py
import torch
from torch.utils.data import DataLoader, Dataset
""" 读取数据 """
def read_data(path, length): # length 限制读取的句子数量
sentences_list = [] # 每一个元素是一整个句子
sentences_list_labels = [] # 每个元素是一整个句子的标签
with open(path, 'r', encoding='UTF-8') as f:
sentence_labels = [] # 每个元素是这个句子的每个单词的标签
sentence = [] # 每个元素是这个句子的每个单词
for line in f:
line = line.strip() # 对于文件中的每一行,删除字符串前后的空白字符
if not line: # 如果遇到了空白行
if sentence: # 如果上一个句子不是空句子(防止空白行连续多个,导致出现空白的句子)
sentences_list.append(' '.join(sentence)) # 将单词合并为句子,并将该句子加入到列表sentences_list中
sentences_list_labels.append(' '.join(sentence_labels)) # 将标签合并为标签序列,并将该标签序列加入到列表sentences_list_labels中
sentence = []
sentence_labels = [] # 重置,开始处理下一个句子的单词和标签
else:
res = line.split() # 将一行字符串按空格划分为单词、空格、标签、空格四个部分
assert len(res) == 4 # 断言每一行都必须划分为4个部分
if res[0] == '-DOCSTART-': #如果该行为起始标志,忽略该行,开始处理下一行
continue
sentence.append(res[0]) # 将单词加入到sentence列表中
sentence_labels.append(res[3]) # 将标签加入到sentence_labels列表中
if sentence: # 处理最后一个句子,防止最后一个句子没有空白行
sentences_list.append(' '.join(sentence))
sentences_list_labels.append(' '.join(sentence_labels))
return sentences_list[:length], sentences_list_labels[:length] # 返回处理好的句子及其对应的标签序列,length指定了返回的句子数量
""" 构建词典(分词)"""
def build_vocab(sentences_list): # sentences_list 包含多个句子的列表
vocab = []
# 使用列表解析式将 sentences 拆分成单个单词,并返回一个由这些单词组成的列表。
for sentences in sentences_list:
vocab += [word for word in sentences.split()]
# 首先使用 set 函数将列表中的元素去重,然后将去重后的元素转换为列表
return list(set(vocab))
""" 自定义数据集 """
class ClsDataset(Dataset): # 用于将输入的数据和标签转换为可迭代的数据集对象
def __init__(self, x: torch.Tensor, y: torch.Tensor, length_list):
self.x = x
self.y = y
self.length_list = length_list
def __getitem__(self, index): # 返回给定索引的数据项
data = self.x[index] # 使用给定索引从输入特征张量中获取相应的输入数据
labels = self.y[index] # 使用给定索引从目标变量张量中获取相应的标签数据
length = self.length_list[index] # 使用给定索引从输入序列长度列表中获取相应的序列长度
return data, labels, length
def __len__(self): # 返回数据集的长度
return len(self.x)
""" 返回单词在字典中的索引 """
def get_idx(word, d):
# 判断字典 d 中是否包含单词 word 的索引,如果包含则返回该索引
if d[word] is not None:
return d[word]
# 如果字典 d 中不包含单词 word 的索引,则返回字典中预先定义好的 '' 对应的索引
else:
return d['']
""" 将句子转换为由词汇表中的单词索引组成的向量 """
def sentence2vector(sentence, d): # d为词汇表,由单词索引组成的字典
# 使用列表推导式将句子分割成单词,对于每个单词调用get_idx函数获得它在字典中的索引,然后将所有的单词索引组成的列表返回
return [get_idx(word, d) for word in sentence.split()]
"""用指定值填充序列"""
def padding(x, max_length, d):
length = 0
# 确定填充长度后,将 对应的值标记添加到 x 的末尾,进行填充
for i in range(max_length - len(x)):
x.append(d[''])
return x
""" 将原始文本数据集 x 和 y 转换为 PyTorch 的数据加载器 """
def get_dataloader(x, y, batch_size):
word2idx, tag2idx, vocab_size = pre_processing() # 预处理数据并建立词表和标签表
inputs = [sentence2vector(s, word2idx) for s in x] # 每一个句子都转化成vector
targets = [sentence2vector(s, tag2idx) for s in y]
# 计算每个句子的长度
length_list = [len(sentence) for sentence in inputs]
# 找到最长的句子的长度并将其截断为124
max_length = max(max(length_list), 124)
# 使用padding将每个句子填充为最大长度
inputs = torch.tensor([padding(sentence, max_length, word2idx) for sentence in inputs])
targets = torch.tensor([padding(sentence, max_length, tag2idx) for sentence in targets], dtype=torch.long)
# 创建数据集并使用DataLoader加载数据
dataset = ClsDataset(inputs, targets, length_list)
dataloader = DataLoader(dataset, shuffle=False, batch_size=batch_size)
# 返回数据加载器和最大长度
return dataloader, max_length
""" 数据预处理 """
def pre_processing():
# 调用 read_data 函数读取训练集和测试集数据,返回两个元组,每个元组包含两个列表,分别是输入数据和标签数据
x_train, y_train = read_data("data/train.txt", 14000)
x_test, y_test = read_data("data/test.txt", 3200)
# 调用 build_vocab 函数,分别对输入和标签数据建立词汇表。这里将训练集和测试集合并后一起建立词汇表。
d_x = build_vocab(x_train+x_test)
d_y = build_vocab(y_train+y_test)
# 将每个词汇/标签映射到一个唯一的整数,用字典存储。字典的键是词汇/标签,值是整数。
word2idx = {d_x[i]: i for i in range(len(d_x))}
tag2idx = {d_y[i]: i for i in range(len(d_y))}
# 为起始标签和终止标签分别添加索引值。这些标签通常用于序列标注任务中。
tag2idx[""] = 9
tag2idx[""] = 10
# 为填充标记添加索引。将填充标记添加到词汇表和标签字典的末尾。
pad_idx = len(word2idx)
word2idx[''] = pad_idx
tag2idx[''] = len(tag2idx)
# 计算词汇表的大小,建立标签到索引的反向映射字典。输出标签到索引的字典。
vocab_size = len(word2idx)
# idx2tag = {value: key for key, value in tag2idx.items()}
print(tag2idx)
# 返回词汇表、标签字典和词汇表大小
return word2idx, tag2idx, vocab_size
""" 计算F1-score """
def compute_f1(pred, targets, length_list):
# 初始化 TP, FN 和 FP
tp, fn, fp = [], [], []
# 共有15个标签
for i in range(15):
tp.append(0)
fn.append(0)
fp.append(0)
# 遍历每个句子的标签预测结果和真实标签,更新计数。
for i, length in enumerate(length_list):
for j in range(length):
# 获取预测的标签和真实的标签。
a, b = pred[i][j], targets[i][j]
# 若预测的标签和真实的标签一致,则增加标签的 TP 计数。
if (a == b):
tp[a] += 1
else:
fp[a] += 1
fn[b] += 1
# 计算所有有效标签的TP/FP/FN
tps = 0
fps = 0
fns = 0
for i in range(9):
tps += tp[i]
fps += fp[i]
fns += fn[i]
# 计算 Precision 和 Recall
p = tps / (tps + fps)
r = tps / (tps + fns)
# 计算 F1 分数并返回
return 2 * p * r / (p + r) (二)结果分析
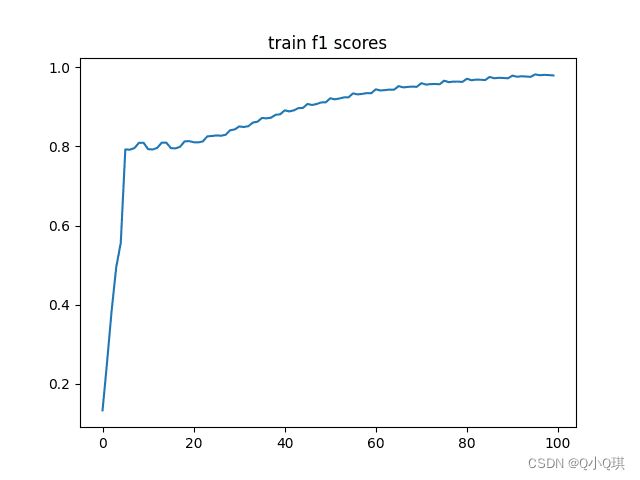

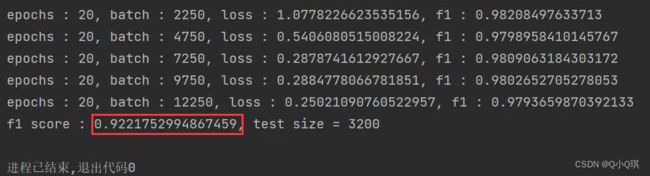
总结:
由于是初学者,学习过程中参考了很多大佬的资料和代码,均附上参考链接:
1、https://blog.csdn.net/Raki_J/article/details/122435674
2、邱锡鹏——《神经网络与深度学习》
3、https://blog.csdn.net/qq_42365109/article/details/119246515
4、NLP入门(四)命名实体识别(NER) - 简书 (jianshu.com)
5、命名实体识别系列(一)NER任务介绍_一鸣鸣的博客-CSDN博客
6、https://blog.csdn.net/weixin_45884316/article/details/118684681
7、https://blog.csdn.net/qq_41773806/article/details/115598437
8、https://zhuanlan.zhihu.com/p/519982682
9、https://cloud.tencent.com/developer/article/1490456
10、https://blog.csdn.net/qfikh/article/details/103588744
以上就是NLP-Beginner的任务四,欢迎各位前辈批评指正!