CLIP使用教程
文章目录
- 前言
- 注意
- 使用
- 其他示例
原理篇
前言
本文主要介绍如何调用Hugging Face中openai提供的CLIP API.
注意
- 如果碰到模型无法自动下载,可手动下载到本地,注意本地调用路径后缀加
/。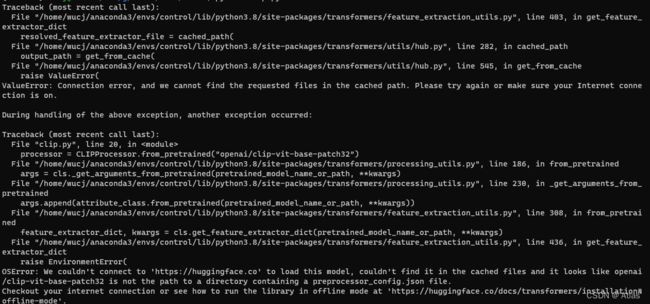
下载config.json、preprocessor_config.json、pytorch_model.bin、tokenizer.json

2. 其中processor中
text表示待检索文本,支持多语句搜索
images表示输入图片,支持多张图片搜索
return_tensors表示返回结果格式,
- 'tf': Return TensorFlow tf.constant objects.
- 'pt': Return PyTorch torch.Tensor objects.
- 'np': Return NumPy np.ndarray objects.
- 'jax': Return JAX jnp.ndarray objects.
使用
准备一张图片,本示例中图片000000039769.jpg如下,

from PIL import Image
import requests
from transformers import CLIPProcessor, CLIPModel
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
# model = CLIPModel.from_pretrained("./clip-vit-base-patch32/")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# processor = CLIPProcessor.from_pretrained("./clip-vit-base-patch32/")
img_path = "./data/clip/000000039769.jpg"
image = Image.open(img_path)
inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # this is the image-text similarity score
print(logits_per_image )
probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
print(probs)
打印结果如下,
tensor([[24.5701, 19.3049]], grad_fn=<PermuteBackward0>)
tensor([[0.9949, 0.0051]], grad_fn=<SoftmaxBackward0>)
返回logits_per_image 并非[0,1],对于多条语句比对时,可通过softmax归一化;
但当输入一条语句(“a photo of a cat”)及一张图片时,无法获得[0,1]之间相似度,难以设定阈值过滤
tensor([[24.5701]], grad_fn=<PermuteBackward0>)
tensor([[1.]], grad_fn=<SoftmaxBackward0>)
outputs结构如下,
return CLIPOutput(
loss=loss,
logits_per_image=logits_per_image,
logits_per_text=logits_per_text,
text_embeds=text_embeds,
image_embeds=image_embeds,
text_model_output=text_outputs,
vision_model_output=vision_outputs,
)
此时可通过本地计算text_embeds与image_embeds之间余弦相似度,完整代码如下,
from PIL import Image
import torch
from transformers import CLIPProcessor, CLIPModel
model = CLIPModel.from_pretrained("./clip-vit-base-patch32/")
processor = CLIPProcessor.from_pretrained("./clip-vit-base-patch32/")
img_path = "./data/clip/000000039769.jpg"
image = Image.open(img_path)
# inputs = processor(text=["a photo of a cat"], images=image, return_tensors="pt", padding=True)
inputs = processor(text=["a photo of a cat","a photo of a dog"], images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)
# logits_per_image = outputs.logits_per_image # this is the image-text similarity score
# print(logits_per_image)
# probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
# print(probs)
similarity = torch.cosine_similarity(outputs.text_embeds, outputs.image_embeds, dim=1)
print(similarity)
输出结果如下,
tensor([0.2457, 0.1930], grad_fn=<SumBackward1>)
猫相似度为0.2457,狗相似度为0.1930
其他示例
“a photo of iron man”
以下靓图similarity分别为:[0.3081, 0.2685]


可能电影相关任务,所有第二张图相似度比较高。