【二等奖方案】系统访问风险识别「QDU」团队解题思路
第十届CCF大数据与计算智能大赛(2022 CCF BDCI)已圆满结束。大赛官方竞赛平台DataFountain(简称DF平台,官号统称DataFountain 或DataFountain数据科学)正在陆续释出各赛题获奖队伍的方案思路。
本方案为【系统访问风险识别】赛题的二等奖获奖方案,
赛题地址:https://www.datafountain.cn/competitions/580

获奖团队简介
团队名称:QDU
团队成员:QDU 是由青岛大学热爱数据挖掘竞赛的师生组成的团队,曾在CIKM AnalytiCup 2019(冠军)、WSDM CUP 2022(冠军)、KDD CUP 2020(初赛第1、决赛第6)、KDD CUP 2022 PaddlePaddle赛道第8名、携程云海大数据竞赛(冠军)、第二届融360天机风控大赛(亚军)取得优异成绩。本次比赛由计算机科学与技术系大三本科生赵颖颖、统计学系研三学生李芷若和计算机科学技术系教师吴舜尧组队参加。
所获奖项:二等奖
摘要
随着国家和企业对于系统安全问题的愈发重视,系统访问风险识别在统一身份管理系统中的重要性日益凸显。本次比赛便要求实现系统风险的评估流程。然而,本赛题存在着数据样本少、线上线下数据集分布不统一等诸多难点,因此,如何利用给定数据实现评估流程是一个不小的挑战。基于此,本文提出一种基于用户行为模式挖掘的系统风险识别方案。首先,对用户的行为模式进行分析与探索并提取出相关特征。进而,选择与线上测试集分布相近的前三个月数据集作为训练集,采用Lightgbm进行训练。最后,对得到的预测结果进行后处理,根据夜间数据有很高的风险这一规则修正标签值,得到最终结果。使用本评估流程得到的预测结果以0.94862310的成绩获得复赛第三名。
关键词
系统风险识别、用户行为模式挖掘、统一身份管理系统
引言
统一身份管理系统允许用户通过账号访问企业内各种信 息系统和 IT 服务,有利于提高企业管理效率[1]。然而,随着网络安全技术的更新换代,新型攻击手段日益多样,统一身份管理系统面临未知威胁难以识别的问题[2]。常用的安全防护手段包括扫码验证、人脸识别、指纹识别等。为了提高安全性,企业通常结合多种防护手段进行身份验证,但这大大降低了用户体验和识别效率。近年来,为了兼顾身份识别的效率和安全性,用户实体行为分析成为了统一身份管理系统方面的研究热点。用户实体行为分析是一种在企业基础设施中发现安全威胁的方法[3],它使用机器学习、算法和统计分析来检测实时网络攻击[4]。基于机器学习方法对用户和实体的行为进行模型建立与风险点识别,可以有效解决未知威胁难以检测的问题,增强企业网络安全防护能力[5,6]。
本次比赛针对统一身份管理系统的身份鉴别问题提出挑战,参赛者需根据用户历史的系统访问日志及是否存在风险标记等数据,构建相关的机器学习、人工智能等模型,进一步提高统一身份管理系统的安全性和身份识别效率。本赛题主要有三大难点:首先,数据样本量较少,容易出现过拟合现象,如何在有限的样本中提取有用信息是难点之一;其次,数据集的变量较少并多为离散型变量,如何挖掘用户行为模式、构造与风险识别高度相关的特征是难点之二;最后,线下数据集与线上测试集分布不一致,如何选取何时的数据构造模型是第三大难点。
为此,本文提出了一种基于用户行为模式挖掘的系统风险识别方案。首先,对用户行为模式进行深度挖掘,提取了有风险的访问的特点,分析了用户行为规律。进而,构造了多类特征,包括用户基本登录信息、基于认证时间的衍生特征、用户当天登录信息、用户行为规律特征以及交叉特征,并采用均方差检验进行特征选择。最后,选用与线上测试集分布一致的数据集建模,并依据实验结果选取了经过后处理的LightGBM 模型[7]作为最终模型。本团队方案在初赛榜单成绩为 0.9480,复赛榜单成绩为0.9486,排名第3。
用户行为模式挖掘
识别存在风险的用户行为模式是构建有效识别系统访问风险的基础。本章将利用用户历史登录数据深入挖掘用户行为模式,发现潜在规律或有用信息,从而指导后续的特征工程。
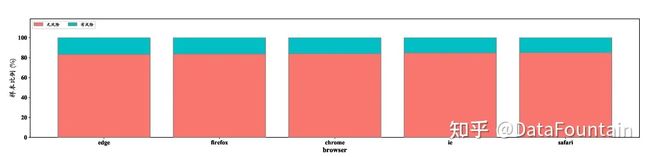
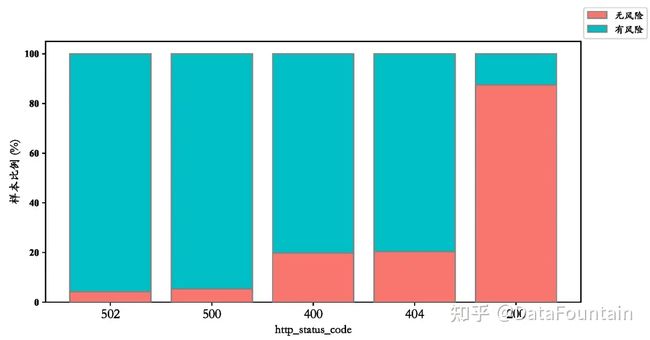
图1是对用户基本登录信息的模式分析。如图1(a)所示,认证城市为“国外”或“未知”的系统访问存在很大隐患,风险率远高于其他城市。图1(b)展现了登录网址和因变量存在的关联,即登录“getLoginType”和“getVerifyCode”两种网址存在很大的风险隐患。图1(c)表明异常http状态(不是“200”的状态编码)常伴随着较大风险。图1(d)则说明夜间(20:00~07:00)访问系统常出现风险。
(a)认证城市的风险率分析

(b)登录网址的风险率分析
(c) http状态的风险率分析

(d)是否夜间的风险率分析
图1:用户基本登录信息的模式分析
图2基于热力图分析了系统访问风险率的周期性。本文以一周(7天)为周期统计了每天的系统访问风险率。如图2所示,周六和周日的风险率通常都很高。第4周周一到周五风险率异常是因为这五天是春节假期,第13周周一和周二风险率偏高则是因为这两天是清明节。第3周周六和周日、第12周周六的风险率偏低是因为这三天是节假日调休,需正常工作。综上所述,有必要考虑周六、周日和节假日对系统访问风险率的影响。
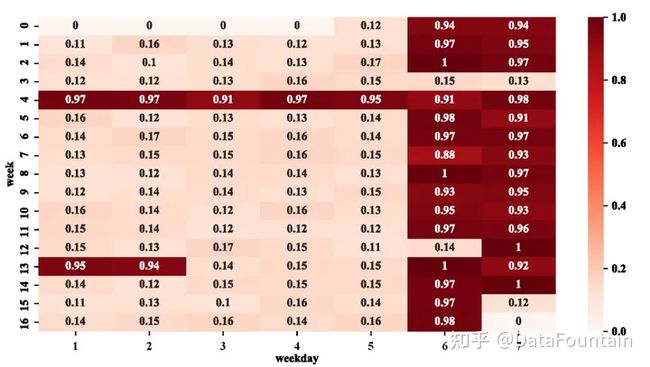
图2:系统访问风险率的热力图周期性分析
图3基于热力图分析了用户登录行为的周期性。本文以天和小时两个时间维度统计用户的登录次数。如图3(a)所示,用户guojianping9672在周三8:00-9:00、周四13:00-16:00等时间段登录较为频繁,周末几乎不登录。图3(b)则表明用户baojianhua2916经常会在工作日8:00-18:00的白天登录系统,且具有周期性。

(a)用户guojianping9672的登陆行为热力图周期分析

(b)用户baojianhua2916的登陆行为热力图周期性分析
图3:用户登陆行为的热力图周期性分析
(a)浏览器的风险率分析

(b)浏览器和认证城市特征交叉后的风险率分析
图4:特征交叉前后风险率分析对比
图4给出了浏览器特征交叉前后的风险率对比。如图4(a)所示,采用不同浏览器访问系统的风险率基本一致。但将浏览器与认证城市交叉结合后,如图4(b)所示,可发现新特征存在一定规律。
特征工程
通过对用户模式的深入挖掘及分析,本文基于用户历史系统访问日志提取了几百个用户画像特征。进而,采用均方差检验[8,9](Mean Variance test,MV test)进行特征选择,以识别与因变量存在显著关联的特征。Mv test是一种简单高效、无任何分布假定的独立性检验方法,可检验一个连续型变量和一个离散型间是否存在关联。最终,选出了182个重要特征用于后续建模。图5展示了基于Mv test统计量排序的前10个重要特征。本文将182个特征分为五类,包括用户基本登录信息、基于认证时间的衍生特征、用户当天登录信息、用户行为规律特征以及交叉特征。
(1)用户基本登录信息。此类特征是基于用户行为模式挖掘发现的规律对用户基本信息处理后得到的二值特征。例如,基于图1(a)获取登陆城市是否为“国外”或“未知”,基于图1(b)获取网络状态编码是否为“200”,基于图1(c)获取登陆网址是否为“getLoginType”或“getVerifyCode”等。
(2)基于认证时间的衍生特征。考虑到系统访问认证时间对识别风险有重要作用,本文基于认证时间生成了一系列二值特征。例如,认证时间是否为夜间、认证时间是否为周末、认证时间是否为节假日、认证时间是否为调休期间、认证时间是否为工作日等。
(3)用户当天登录信息。本文提取了每位用户从当天00:00到当前的登录次数、IP转换次数、使用某种设备的登录次数、使用某IP地址的登录次数、访问某网址的次数等等。此类信息可以反映用户当天的活跃程度及行为模式。
(4)用户行为规律特征。此类特征包括时间差特征和统计特征。关于时间差特征,本文分别提取了往前划窗的时间差和往后划窗的时间差。在往前做划窗的时间差特征中,分别提取了每个用户距离前两次的时间差、用户上一次使用某种设备登陆的时间差、用户上一次使用某ip登陆的时间差、用户上一次访问某网址的时间差以及一些时间差的统计数据。例如,用户在节假日期间距离上一次使用某设备登陆的时间差的平均值、最大值、最小值和标准差,用户在周末距离上一次访问某网址的时间差的平均值、最大值、最小值和标准差等时间差的统计特征。在往后划窗的时间差(即下一次点击的时间差)特征中,由于直接求下一次点击时间差会存在数据穿越,故仅对训练集求上述时间差的统计数据,后直接聚合到测试集。关于用户登陆的统计特征,本文基于训练集数据分别了提取了用户在节假日和非节假日时每个小时的登录次数平均值、在一周的每一天中每个小时的登录次数平均值、在一周的每一天中每个小时使用某个信息登录的次数平均值等。此类特征一定程度上可以反映用户在不同时间点的登陆习惯,这对于预测样本是否存在风险也有用处。
(5)交叉特征。此类特征包括简单交叉特征和统计特征。简单交叉特征对给定的两种类别特征直接进行组合。如图4所示,将浏览器和认证城市两个特征结合得到的新特征“浏览器+认证城市”包含的信息量更多。统计特征是特征组合在一起共同求统计特征,例如,某部门访问某网址的平均次数等。

图 5 基于Mv test统计量排序的前10个重要特征
建模及后处理
本次比赛提供的线下数据集和线上测试集的数据分布存在差异。如图 6 所示,与全部线下数据集相比,前三个月数据集与线上测试集分布更相似。除此之外,本文还使用对抗验证的方法,将是否为测试集这一数据作为标签训练模型,并对训练集所有样本进行预测,结果表明前三个月预测准确率最高,与线上测试集分布更吻合。为此,本文选取与测试集分布最为相似的前三个月数据作为训练集。

图 6 特征browser_diff1_max在全部训练集、前三个月数据集以及测试集上的分布对比
由图1(d)可知,夜间的系统访问存在很大风险。为此,利用此规则对预测结果进行后处理,将所有夜间样本的预测结果修正为1(有风险)。实验结果表明,修改后线上线下均有提升。除此之外,本文也尝试过其他后处理方式。例如,将短时间内下载量超过5次的预测结果修正为1,虽然线下有提升,但线上会有下降。
实验结果与分析

表 1 实验结果对比
为进行线下效果评估,本文对前三个月的数据集进行五折交叉验证,并且选用Lightgbm、Catboost、Xgboost 、DeepFM和DCN等模型。如表1所示,Lightgbm在线上、线下的预测效果最佳;后处理可使所有模型的预测效果有小幅度提升。因而,选择进行后处理的Lightgbm当做最终方案。
总结与展望
为实现本赛题的要求,本文提出了基于用户行为模式挖掘的系统风险识别方案。首先,在传统规则分析技术的基础上,深入挖掘用户行为规律,提取出和系统访问风险密切相关的182个特征,包括用户基本登录信息、基于认证时间的衍生特征、用户当天登录信息、用户行为规律特征以及交叉特征五大类。进而,通过分析数据集的分布,观察到前三个月的数据分布与测试集更为相似,因此仅用前三个月作为训练集训练数据,解决了测试集和赛题训练集分布不一致的问题。最后,根据表1的结果发现,Lightgbm+后处理的模型表现最佳,且分数稳健,故选用此模型进行训练,最终获得不错的预测效果。
虽然本文方案取得了较好效果,但存在一些值得研究和探讨的方向。例如,可尝试提取用户登录序列等时间序列,采用卷积神经网络和循环神经网络建模,有望更好的捕获用户行为特点。
致谢
感谢2022 CCF大数据与计算智能大赛的组织。感谢DataFountain平台和竹云科技股份有限公司提供的帮助和讲解。
参考
[1] 章思宇, 黄保青, 姜开达. 统一身份认证日志集中管理与账号风险检测[J].东南大学学报(自然科学版), 2017, 47(S1): 113-117.
[2] 崔景洋, 陈振国, 田立勤, 张光华. 基于机器学习的用户与实体行为分析技术综述[J]. 计算机工程,2022,48(02): 10-24. DOI: 10.19678/j.issn.1000-3428.0062623.
[3] Lukashin, A., Popov, M., Bolshakov, A., Nikolashin, Y. (2020). Scalable Data Processing Approach and Anomaly Detection Method for User and Entity Behavior Analytics Platform. In: Kotenko, I., Badica, C., Desnitsky, V., El Baz, D., Ivanovic, M. (eds) Intelligent Distributed Computing XIII. IDC 2019. Studies in Computational Intelligence, vol 868. Springer, Cham. https://doi.org/10.1007/978-3-030-32258-8_40
[4] M. A. Salitin and A. H. Zolait, "The role of User Entity Behavior Analytics to detect network attacks in real time," 2018 International Conference on Innovation and Intelligence for Informatics, Computing, and Technologies (3ICT), 2018, pp. 1-5, doi: 10.1109/3ICT.2018.88
[5] 莫凡, 何帅, 孙佳, 范渊, 刘博. 基于机器学习的用户实体行为分析技术在账号异常检测中的应用[J]. 通信技术, 2020,53(05): 1262-1267.
[6] M. Shashanka, M. -Y. Shen and J. Wang, "User and entity behavior analytics for enterprise security," 2016 IEEE International Conference on Big Data (Big Data), 2016, pp. 1867-1874, doi: 10.1109/BigData.2016.7840805.55782.
[7] Ke G, Meng Q, Finley T, et al. Lightgbm: A highly efficient gradient boosting decision tree[J]. Advances in neural information processing systems, 2017, 30.
[8] Hengjian Cui, Runze Li, Wei Zhong. Model-Free Feature Screening For Ultrahigh Dimensional Discriminant Analysis. Journal of the American Statistical Association. 2015, 110(510): 630-641.
[9] Hengjian Cui, Wei Zhong. A distribution-free test of independence based on mean variance index. Computational Statistics & Data Analysis. 2019, 139: 117-133.
—End—