Python基础之爬取豆瓣图书信息
概述
所谓爬虫,就是帮助我们从互联网上获取相关数据并提取有用的信息。在大数据时代,爬虫是数据采集非常重要的一种手段,比人工进行查询,采集数据更加方便,更加快捷。刚开始学爬虫时,一般从静态,结构比较规范的网页入手,然后逐步深入。今天以爬取豆瓣最受关注图书为例,简述 python教程在爬虫方面的初步应用,仅供学习分享使用,如有不足之处,还请指正。
涉及知识点
如果要实现爬虫,需要掌握的Pyhton相关知识点如下所示:
- requests模块:requests是python实现的最简单易用的HTTP库,建议爬虫使用requests。关于requests模块的相关内容,可参考及简书上的
- BeautifulSoup模块:Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库。它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式。关于BeautifulSoup的更多内容,可参考。
- json模块:JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,易于人阅读和编写。使用 JSON 函数需要导入 json 库。关于json的更多内容,可参考。
- re模块:re模块提供了与 Perl 语言类似的正则表达式匹配操作。关于re模块的更多内容,可参考。
目标页面
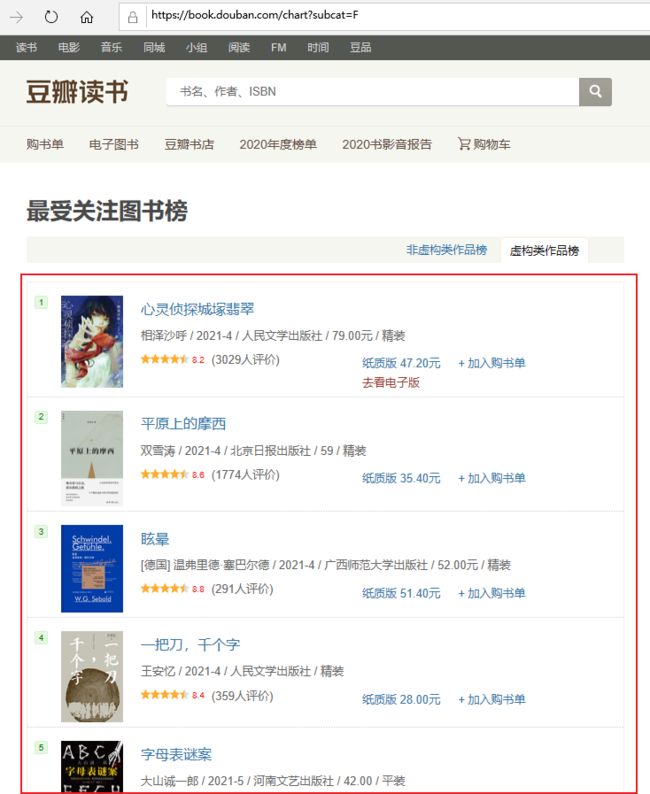
本例中爬取的信息为豆瓣最受关注图书榜信息,共10本当前最受欢迎图书。
爬取页面URL【Uniform Resource Locator,统一资源定位器】:https://book.douban.com/chart?subcat=F
爬取页面截图,如下所示:
爬取数据步骤
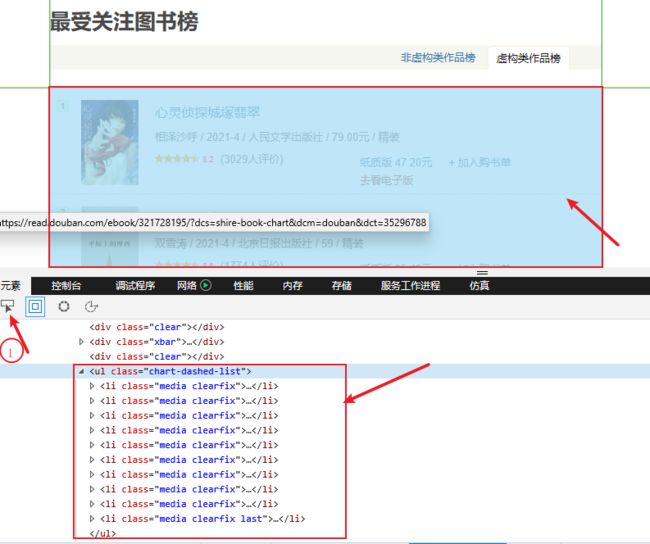
1. 分析页面
通过浏览器提供的开发人员工具(快捷键:F12),可以方便的对页面元素进行定位,经过定位分析,本次所要获取的内容,包括在UL【class=chart-dashed-list】标签内容,每一本书,都对应一个LI元素,是本次爬取的目标,如下所示:
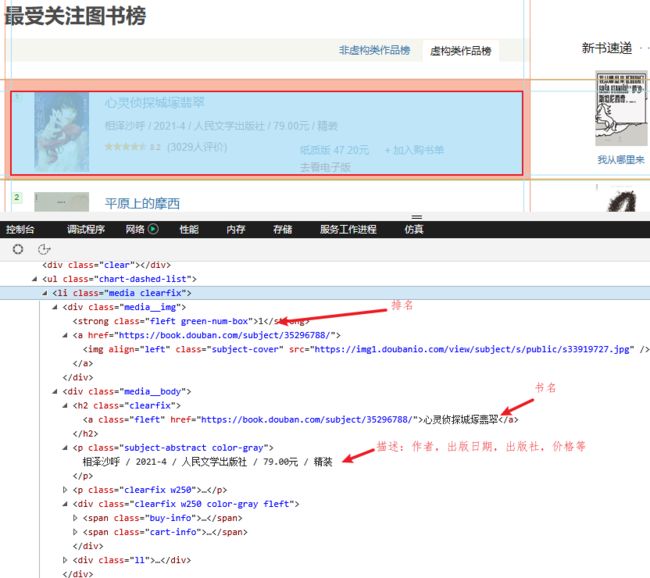
每一本书,对应一个Li【class=media clearfix】元素,书名为对应a【class=fleft】元素,描述为P【class=subject-abstract color-gray】标签元素内容,具体到每一本书的的详细内容,如下所示:
2. 下载数据
如果要分析数据,首先要进行下载,获取要爬取的数据信息,在Python中爬取数据,主要用requests模块,如下所示:

1 def get_data(url):
2 """
3 获取数据
4 :param url: 请求网址
5 :return:返回请求的页面内容
6 """
7 # 请求头,模拟浏览器,否则请求会返回418
8 header = {
9 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
10 'Chrome/70.0.3538.102 Safari/537.36 Edge/18.18363'}
11 resp = requests.get(url=url, headers=header) # 发送请求
12 if resp.status_code == 200:
13 # 如果返回成功,则返回内容
14 return resp.text
15 else:
16 # 否则,打印错误状态码,并返回空
17 print('返回状态码:', resp.status_code)
18 return ''
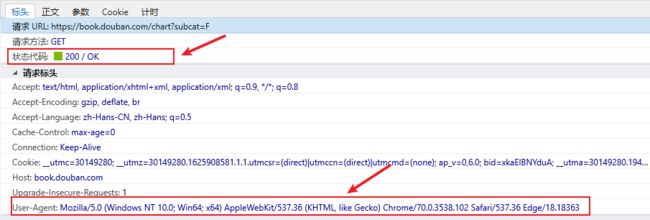
注意:在刚开始写爬虫时,通常会遇到“HTTP Error 418”,请求网站的服务器端会进行检测此次访问是不是人为通过浏览器访问,如果不是,则返回418错误码。检测请求头是常见的反爬虫策略,所为为了模拟浏览器访问,需要构造请求Header,然后即可正常访问。
正常浏览器访问成功的状态码为200,及请求标头中User-Agent。如下所示:
3. 解析数据
当获取到数据后,需要进行数据分析,才能得到想要的内容。requests模块获取到的内容为Html源码字符串,可以通过BeautifulSoup装载成对象,然后进行数据获取,如下所示:
1 def parse_data(html: str = None):
2 """
3 解析数据
4 :param html:
5 :return:返回书籍信息列表
6 """
7 bs = BeautifulSoup(html, features='html.parser') # 转换页面内容为BeautifulSoup对象
8 ul = bs.find(name='ul', attrs={'class': 'chart-dashed-list'}) # 获取列表的父级内容
9 lis = ul.find_all('li', attrs={'class': re.compile('^media clearfix')}) # 获取图书列表
10 books = [] # 定义图书列表
11 for li in lis:
12 # 循环遍历列表
13 strong_num = li.find(name='strong', attrs={'class': 'fleft green-num-box'}) # 获取书籍排名标签
14 book_num = strong_num.text # 编号
15 h2_a = li.find(name='a', attrs={'class': 'fleft'}) # 获取书名标签
16 book_name = h2_a.text # 获取书名
17 p_info = li.find(name='p', attrs={'class': "subject-abstract color-gray"}) # 书籍说明段落标签
18
19 book_info_str = p_info.text.strip() # 获取书籍说明,并 去前后空格
20 # book_info_list = book_info_str.split('/', -1) # 分隔符
21 books.append(
22 {'book_num': book_num, 'book_name': book_name, 'book_info': book_info_str}) # 将内容添加到列表
23
24 return books
4. 保存数据
解析到目标数据后,需要进行数据持久化,以便后续进一步分析。持久化通常可以保存到数据库中,本例为了简单,保存到本地json文件中,如下所示:
1 def save_data(res_list):
2 """
3 保存数据
4 :param res_list: 保存的内容文件
5 :return:
6 """
7 with open('books.json', 'w', encoding='utf-8') as f:
8 res_list_json = json.dumps(res_list, ensure_ascii=False)
9 f.write(res_list_json)
本例完整代码,如下所示:

1 import json # json 包,用于读取解析,生成json格式的文件内容
2 import requests # 请求包 用于发起网络请求
3 from bs4 import BeautifulSoup # 解析页面内容帮助包
4 import re # 正则表达式
5
6
7 def get_data(url):
8 """
9 获取数据
10 :param url: 请求网址
11 :return:返回请求的页面内容
12 """
13 # 请求头,模拟浏览器,否则请求会返回418
14 header = {
15 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
16 'Chrome/70.0.3538.102 Safari/537.36 Edge/18.18363'}
17 resp = requests.get(url=url, headers=header) # 发送请求
18 if resp.status_code == 200:
19 # 如果返回成功,则返回内容
20 return resp.text
21 else:
22 # 否则,打印错误状态码,并返回空
23 print('返回状态码:', resp.status_code)
24 return ''
25
26
27 def parse_data(html: str = None):
28 """
29 解析数据
30 :param html:
31 :return:返回书籍信息列表
32 """
33 bs = BeautifulSoup(html, features='html.parser') # 转换页面内容为BeautifulSoup对象
34 ul = bs.find(name='ul', attrs={'class': 'chart-dashed-list'}) # 获取列表的父级内容
35 lis = ul.find_all('li', attrs={'class': re.compile('^media clearfix')}) # 获取图书列表
36 books = [] # 定义图书列表
37 for li in lis:
38 # 循环遍历列表
39 strong_num = li.find(name='strong', attrs={'class': 'fleft green-num-box'}) # 获取书籍排名标签
40 book_num = strong_num.text # 编号
41 h2_a = li.find(name='a', attrs={'class': 'fleft'}) # 获取书名标签
42 book_name = h2_a.text # 获取书名
43 p_info = li.find(name='p', attrs={'class': "subject-abstract color-gray"}) # 书籍说明段落标签
44
45 book_info_str = p_info.text.strip() # 获取书籍说明,并 去前后空格
46 # book_info_list = book_info_str.split('/', -1) # 分隔符
47 books.append(
48 {'book_num': book_num, 'book_name': book_name, 'book_info': book_info_str}) # 将内容添加到列表
49
50 return books
51
52
53 def save_data(res_list):
54 """
55 保存数据
56 :param res_list: 保存的内容文件
57 :return:
58 """
59 with open('books.json', 'w', encoding='utf-8') as f:
60 res_list_json = json.dumps(res_list, ensure_ascii=False)
61 f.write(res_list_json)
62
63
64 # 开始执行,调用函数
65 url = 'https://book.douban.com/chart?subcat=F'
66 html = get_data(url=url) # 获取数据
67 books = parse_data(html) # 解析数据
68 save_data(books) # 保存数据
69 print('done')
本例爬取内容,保存到books.json文件中,如下所示:
1 [
2 {
3 "book_num": "1",
4 "book_name": "心灵侦探城塚翡翠",
5 "book_info": "相泽沙呼 / 2021-4 / 人民文学出版社 / 79.00元 / 精装"
6 },
7 {
8 "book_num": "2",
9 "book_name": "平原上的摩西",
10 "book_info": "双雪涛 / 2021-4 / 北京日报出版社 / 59 / 精装"
11 },
12 {
13 "book_num": "3",
14 "book_name": "眩晕",
15 "book_info": "[德国] 温弗里德·塞巴尔德 / 2021-4 / 广西师范大学出版社 / 52.00元 / 精装"
16 },
17 {
18 "book_num": "4",
19 "book_name": "一把刀,千个字",
20 "book_info": "王安忆 / 2021-4 / 人民文学出版社 / 精装"
21 },
22 {
23 "book_num": "5",
24 "book_name": "字母表谜案",
25 "book_info": "大山诚一郎 / 2021-5 / 河南文艺出版社 / 42.00 / 平装"
26 },
27 {
28 "book_num": "6",
29 "book_name": "星之继承者",
30 "book_info": "[英] 詹姆斯·P.霍根 / 2021-4 / 新星出版社 / 58.00元 / 精装"
31 },
32 {
33 "book_num": "7",
34 "book_name": "美丽黑暗",
35 "book_info": "[法] 法比安·韦尔曼 编 / [法] 凯拉斯科多 绘 / 2021-4 / 后浪丨中国纺织出版社 / 88.00元 / 精装"
36 },
37 {
38 "book_num": "8",
39 "book_name": "心",
40 "book_info": "[日] 夏目漱石 / 2021-3-30 / 江苏凤凰文艺出版社 / 45.00元 / 精装"
41 },
42 {
43 "book_num": "9",
44 "book_name": "奇迹唱片行",
45 "book_info": "[英] 蕾秋·乔伊斯 / 2021-6-11 / 北京联合出版公司 / 48 / 平装"
46 },
47 {
48 "book_num": "10",
49 "book_name": "派对恐惧症",
50 "book_info": "[美]卡门•玛丽亚•马查多 / 2021-5 / 世纪文景/上海人民出版社 / 59.00元 / 精装"
51 }
52 ]
备注
望岳
唐·杜甫
岱宗夫如何?齐鲁青未了。
造化钟神秀,阴阳割昏晓。
荡胸生曾云,决眦入归鸟。( 曾 同:层)
会当凌绝顶,一览众山小。
作者:Alan.hsiang