LiveBot: Generating Live Video Comments Based on Visual and Textual Contexts 论文笔记
源码: https://go.ctolib.com/article/wiki/104234
弹幕,已经成为人们看视频的一种习惯;不同用户之间的弹幕往往会形成上下文回复关系,更让弹幕成为一种新的社交模式。基于这一现象,微软亚洲研究院设计了一款名为 LiveBot 的自动弹幕生成系统。在这一系统中需要克服两个难点:一是要充分理解视频内容,根据其他用户的评论弹幕生成适当的内容;二是要在合适的时间点显示在对应的视频帧之上。
实验结果表明,LiveBot 能够准确地学习到真实用户在观看视频时进行弹幕评论的行为特点,有效地进行了视频内容的理解和用户评论的交互,同时在客观评价指标上也取得优异的成绩。
无监督机器翻译的最新性能提升
最近一年,无监督机器翻译逐渐成为机器翻译界的一个研究热点。在无监督场景下,神经机器翻译模型主要通过联合训练(joint training)或交替回译(iterative back-translation)进行逐步迭代。但是由于缺乏有效的监督信号,回译得到的伪训练数据中会包含大量的噪音,这些噪音在迭代的过程中,会被神经机器翻译模型强大的模式匹配能力放大,从而损害模型最终的翻译性能。
摘要
弹幕的内容一般是对该视频的评论以及与其他弹幕的交流互动,自动生成实时的弹幕需要AI能理解视频内容和他人发的弹幕(真人),所以这是一个很适合AI同时处理动态视觉和语言的测试平台。在本次论文工作中,我们构建了一个大规模的弹幕数据集,包括了2361个视频中的895929条评论。然后我们将引入两个神经网络生成基于视觉和文本上下文的实时弹幕,比之前的seq2seq有着更好的表现。最后,我们针对自动实时评论提供一个基于检索的评估协议,要求模型对一组由对数似然得到的候选评论进行分类,并评估相应衡量指标(如平均倒数等级?)。最后放到一起,展示了第一个“livebot”
介绍
基于弹幕的种种优势,我们提出一个新的任务:自动弹幕生成。弹幕及有对视频的评论,也有对他人发的弹幕的回应,所以自动生成实时的弹幕需要AI能理解视频内容和他人发的弹幕(真人)并能做出回应。所以这是一个很适合AI同时处理动态视觉和语言的测试平台。
现在已经有很多任务可以用来评估AI处理视觉与语言的能力,包括 image captioning 图像字幕 (Donahue et al. 2017; Fang et al. 2015; Karpathy and Fei-Fei 2017), video description (Rohrbach et al. 2015; Venugopalan et al. 2015a; Venugopalan et al. 2015b), visual question answering (Agrawal, Batra, and Parikh 2016; Antol et al. 2015), and visual dialogue (Das et al. 2017).
弹幕生成与上述任务都不同,图像字幕目的是生成图像的文字描述,视频描述是生成对视频的描述,这两个任务都只需要机器理解图像或视频,而不需要与真人有交流。视觉问题回答和视觉对话则在人机交互迈出了重要的一步。给一个图像,机器要回答出关于图像的问题或者能与人类进行多轮对话。而与这两种任务不同的是,弹幕需要理解视频并且分享观点或观看他人经验,是一项更有挑战性的任务。
自动弹幕的独特挑战是评论与视频之间复杂的依赖关系,首先,弹幕与视频以及当前时刻的其他弹幕有关,而当前时刻的其他弹幕也都依赖与视频。其次,弹幕不仅取决于当前视频帧,还取决于当前帧的周围帧,因为观看者可以评论之前的视频内容或者即将播放的视频内容,所以,我们将弹幕任务表述为:给定视频V,视频中的一帧F,时间戳T和该相应时间周围的弹幕C(如果有的话),当框架I在时间戳附件,机器应该做出有关当前帧的评论或附近帧F的评论。
在这项工作中,我们制作了一个“livebot”去为视频生成弹幕,我们构建了一个包括了2361个视频和其中的895929条评论的数据集,相关数据从bilibili中收集。
弹幕数据集
在本节中,我们将介绍我们提出的实时评论数据集。 我们首先描述我们如何收集数据和拆分数据集。 然后我们分析弹幕的属性。
视频与弹幕的收集
抓取了前10页的搜索结果,查询包含19个类别,包括宠物,体育,动画,食品,娱乐,技术等等,删除掉重复以及短视频,过滤低质量或少量弹幕的视频,以保证数据质量。最后得到2361个视频。
在每个视频中,我们收集弹幕并抓取他们相应的时间戳,以便我们确定评论的背景(周围的帧和评论)。我们使用python的包——Jieba标记所有的弹幕。最后得到了895929条有时间戳相对应的弹幕。
我们还下载了视频的音频,我们发现将音频片段与评论对齐是比较困难的,所以我们不打算对音频你进行分段,而是保留视频的整个音频。
下图是一个例子。
数据集拆分
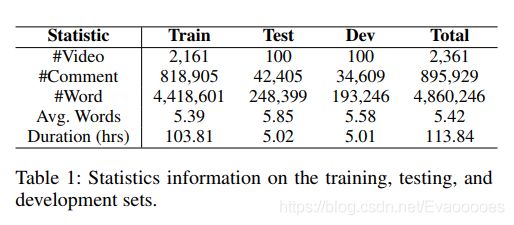
来自相同视频的弹幕不会只出现在在训练集或测试集中以免过拟合。最后,将数据集分为2161为训练集,100测试集,100验证集,弹幕拆分为818905训练集,42405测试集,34609个验证集。
数据统计
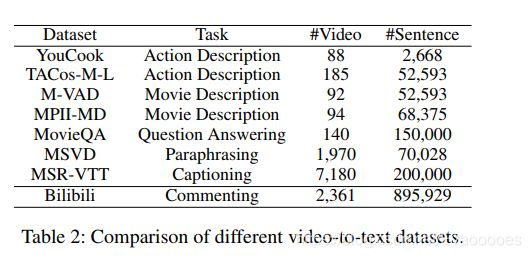
与其他数据集相比,bilibili数据集代表了最全面,最多样化,最复杂的可用于视频-文本学习的数据集
弹幕分析
1.长度分布
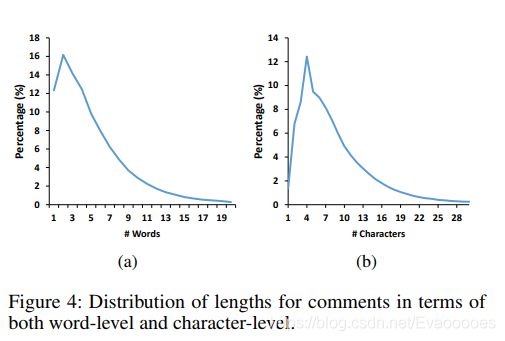
我们可以看到大多数弹幕不超过5个单词或10个字符。 一个原因是5个中文单词或者10个汉字包含足够的信息与他人交流。 另一个原因是观众经常在观看期间发弹幕,所以他们更喜欢简短快速的评论,而不是花很多时间做长而详细的评论。
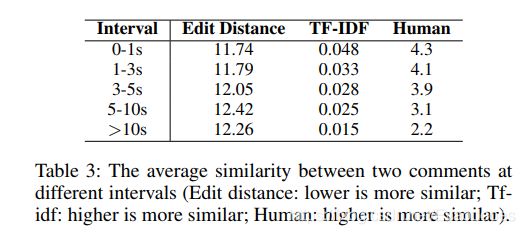
2.相邻评论之前的相关性
对于每条弹幕,我们选择相邻的20条弹幕形成20个弹幕对。我们就edit distance, tf-idf, and human scoring(编辑距离,df-idf,人类得分)这三个指标计算这些弹幕对。human scoring,我们要求三个注释器对两个注释之间的语义相关性进行评分,并且得分范围从1到5,根据弹幕的时间间隔,我们进行分组:0-1s,1-3s,3-5s,5-10s,以及10s以上。 我们取所有弹幕对的平均分数,结果如下,临近的弹幕相关性更高。
生成弹幕的一个挑战在于视频与弹幕复杂的依赖性关系。为了模拟这种依赖性,我们介绍两种基于视觉背景(周围帧)和文本上下文(周围的评论)可以生成弹幕的方法。这两种方法是基于两种流行的文本生成的架构:RNN和变压器。我们将两种方法表示为融合RNN模型和同一变压器模型。
问题表述
我们提供一个视频v,一个时间戳T,和该时间戳附近的评论C,模型应该可以生成一个该帧相应的或者可以回应该时间戳其他弹幕的新一条弹幕y。因为视频也许会比较长或者同一时间有很多弹幕,所以不用将整段视频和所有弹幕当作输入,我们只需保留时间戳T附近的m帧(我们帧之间的间隔设置为1秒)和n条弹幕。我们将m帧表示为 I = {I1, I2, · · · , Im},将n条弹幕表示为 C = {C1, C2, · · · , Cn} 。模型的目的是生成弹幕 y = {y1, y2, · · · , yk},k是句子中单词的数量。
模型1:融合RNN模型
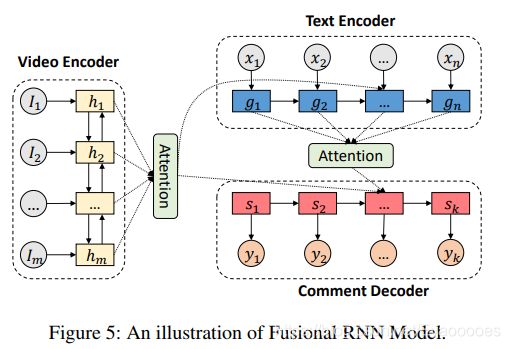
该模型由三部分组成:一个视频编码器,一个文本编码器,一个评论解码器,视频编码器使用CNN顶层的lstm层对m个连续帧进行编码,文本编码器将m帧周围的弹幕输入到LSTM层的向量中。最后,评论解码器生成弹幕。
(1)视频编码器:
在视频编码器中,每帧Ii首先通过卷积层将其编码为矢量vi。然后使用一个LSTM层将多有帧向量编码输入他们的隐藏层hi
vi = CNN(Ii) (1) hi = LSTM(vi , hi−1) (2)
(2)文本编码器:
每条周围弹幕Ci首先通过编码成为一系列字级表示,使用字级LSTM层:
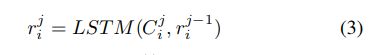
我们使用最后一层的隐藏状态![]() 作为代表
作为代表![]() 表示
表示![]() 然后我们使用句子级的LSTM层用注意机制编码所有到句子级的弹幕表示gi (注意机制???)
然后我们使用句子级的LSTM层用注意机制编码所有到句子级的弹幕表示gi (注意机制???)
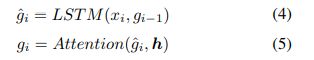
在注意的帮助下,评论表示包含来自视频的信息
(3)评论解码器:
这个模型生成的评论是基于周围弹幕以及周围帧的。因此,生成语句的概率愤怒如下:
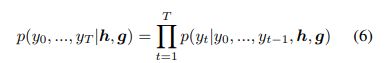
单词wi的概率分布如下:
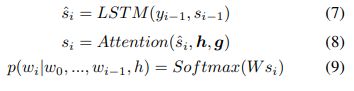
模型二:统一变压器模型
同一变压器模型不同于融合RNN模型的层次结构,而是使用线性结构来捕获弹幕和视频的依赖关系。与融合RNN模型相似的是,同一变压器模型也包含三个部分:视频编码,文本编码以及评论解码
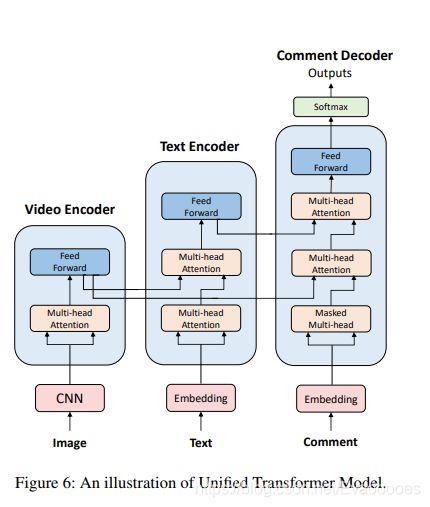
(1)视频编码器:
与融合RNN模型相似,这里视频编码器首先使用卷积层将每一帧Ii编码为向量vi。然后使用一个变压器层将所有帧向量编码入最后的表示层hi
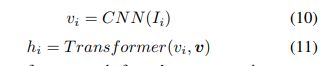
在变压器内,每个帧的表示层vi与其他帧表示层一同表示为v的集合 v = {v1, v2, · · · , vm}.
(2)文本编码器
不同于融合RNN模型,我们将所有弹幕串联为一个单词序列, e = {e1, e2, · · · , eL},作为文本编码器的输入,这样每个单词可以直接促成自我注意组件(self-attention)【 Self attention是Google在“Attention is all you need”论文中提出的”The transformer”模型中主要的概念之一,我们可以把”The transformer”想成是个黑盒子,将输入句输入这个黑盒子,就会產生目标句。】
表示层中每个弹幕中的单词可被表示为![]()
在文本编码器内部,有两个多头注意组件,第一个参与文本输入e,第二个参与视频编码的输出h。
(3)评论解码器
我们使用变压器层生成弹幕。概率分布为
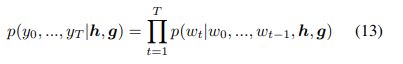
单词yi的计算为
![]()
![]()
在评论解码器内部,有三个多头注意组件,第一个参与评论输入y,后两个分别参与视频输出编码器h和文本编码器g。
评估指标
关于视频的弹幕内容是非常丰富的,找出可与模型输出结果进行比较的参考是比较困难的。blue和rouge等评估指标是不适合此次项目的。受到对话模型评估的启发,我们将评估方法指定为排名。要求模型对一组候选的弹幕进行基于对数似然进行排序。由于模型生成评分最高的评论,所以通过排名判断一个好的模型,在候选的顶层正确的评论是合理的(?)。
候选评论集有以下:
正确:人类提供的相应视频的真实评论。
也许正确:50个最与视频标题相似的弹幕。我们使用视频标题作为查询来检索基于训练集的评论关于它们的tf-idf值的余弦相似性。我们选择前30条不是正确评论的作为也许正确的评论。
次数最多:来自数据集前20条出现次数最多的评论。这些评论一般都是无意义的,比如“2333”“哈哈哈哈”,因为不带有信息,因此被视为不正确评论。
随机:在选择完正确、也许正确、次数最多的后,为了填满候选集,我们可以从训练集中随机地选择一些评论。直到候选集中有100条不同地评论
我们根据以下指标衡量排名:recall(在前K个提供评论中人类评论地比例),mean rank(人类评论的平均等级),平均倒数排名(人类评论平均倒数的排名)
实验
设置
对这两种模型,词汇量都要限制训练集内出现次数最多地30000词汇内,我们在编码器和解码器中使用一个共享潜入层,并将嵌入层大小设为512。对于CNN编码器,使用 Pytorch提供的一个18层的预训练resnet。对于这两个模型, batch size设为64, 隐藏层尺寸512。我们使用 Adam优化方法训练我们的模型。Adam超参数为 learning rate α = 0.0003,两个动量参数β1 = 0.9、β2 = 0.999,以及![]()
baselines
-
S2S-I :解码器生成目标弹幕的基础上,使用CNN对帧进行编码。此模型仅使用视频作为输入
-
S2S-C: 解码器生成评论的基础上,使用一层LSTM处理周围的弹幕,这个模型可以看作传统的seq2seq,只使用周围弹幕作为输入。
-
S2S-IC:可以同时使用视频和文本信息。该模型有两个编码器分别对画面及评论进行编码,然后连接两个编码器的输出,用LSTM解码器对输出结果进行解码。
结果
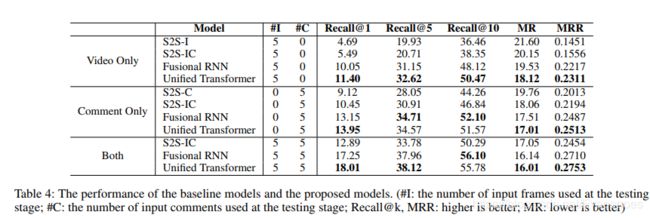
训练阶段,我们对 S2S-IC、融合RNN模型,统一变压器模型都进行了视频和文本训练。S2S-I只是用了视频进行训练,S2S-C只是用了弹幕进项训练。在测试阶段,我们在三种设置下评估这些模型:仅视频,仅评论和两者都有。仅有视频,表示模型仅使用图像作为输入(最近的5帧),这模拟了没有周围评论可用的情况。 仅有评论表示模型仅接收周围弹幕的输入(最近的5条弹幕),这模拟了视频质量低的情况。 两者都表示视频和周围评论都可用于模型的情况(最近的5帧和评论)。
以下结果可以看出,我们提出的模型在任何情况下都优于baseline,仅有弹幕作为输入的结果优于仅有视频作为输入,是因为周围的弹幕可以提供有关下一条弹幕的信息。
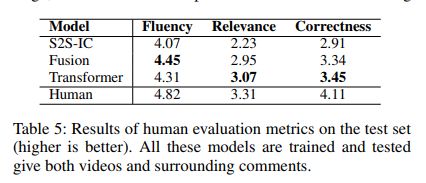
我们从三个方面评估生成的弹幕:流畅性:生成评论是否流利(无视与视频相关性);相关性:衡量生成弹幕与视频的相关性。正确性:综合测量由人类产生的弹幕在上下文中的置信度。在以上三个方面,我们都规定了得分为{1,2,3,4,5}中的整数。越高越好。 分数由三个人类注解评估最后我们将三个评分的平均值作为最终结果。结果如下,在三个模型中,我们提出的模型表现最好。不过相关性始终低于其他两个是因为弹幕不是总与视频内容相关,也许与周围的弹幕有关。统一变压器生成的弹幕相对来说,更接近真人发出的弹幕。
相关工作:
一个与本课题类似的课题是图像标题生成,这是一个已经研究很长时间的领域,目前的工作是通过逐步合并网络改善表现。
另一个比较类似的课题是视频字幕生成,Venugopalan et al. (2015a)建议使用CNN提取图像特征,使用LSTM进行编码并解码出一个句子。Das et al. (2017)介绍了一个视觉对话系统,ai需要通过给定图像或对话历史图像来回答问题。
有关注意机制还不太了解,下一篇读下 https://arxiv.org/pdf/1706.03762.pdf
https://kexue.fm/archives/4765
https://www.yiyibooks.cn/yiyibooks/Attention_Is_All_You_Need/index.html