简单回复一下基本的网络知识,希望对大家快速回顾起某个领域的主要知识有所提益
1. TCP/IP
TCP/IP 基本知识
1.1 IP报文格式
1.2 TCP 延迟确认
reference:
- https://cloud.tencent.com/developer/article/1004356
- https://www.villainhr.com/page/2016/07/19/%E5%8A%A0%E5%BF%AB%E7%BD%91%E7%BB%9C%E9%80%9F%E5%BA%A6-TCP%E4%BC%98%E5%8C%96
- TCP-IP详解 19章
1.2.1 why 延迟确认?
网络请求中可能真实的 ip包中,实际内容很少,比 ip报文少多了。大量小包加剧了网络拥堵,同时大大降低了网络使用率。
1.2.2 dealay ack 与nagle算法
- 通常 tcp接受到数据后并不会立刻返回ack,而是会在下一次数据返回中捎带这个ack确认。若是后面没有数据,则这个ack会有一个时延,超过时延,ack包就会被发送出去,一般时延是 200ms(接收端延迟)
- nagle算法: 一个TCP 连接上最多只能有一个没有被确认的ip分组,该分组确认到达之前不能发送其他分组。在此等待期间,会收集数据,在下一次一次发出去。
(1)如果包长度达到MSS,则允许发送;
(2)如果该包含有FIN,则允许发送;
(3)设置了TCP_NODELAY选项,则允许发送;
(4)未设置TCP_CORK选项时,若所有发出去的小数据包(包长度小于MSS)均被确认,则允许发送;
(5)上述条件都未满足,但发生了超时(一般为200ms),则立即发送。
小结:
- nagle 算法,发送端限制 大量小包的发送,可以使用 tcp_nodelay 关闭这个延迟
- delay ack,接受端会在响应数据的时候捎带 ack确认,当后面没有数据包的时候,时延一到,ack包就会发送出去。
- nagel 混合delay ack使用
1.3. tcp 拥塞控制与流量控制
流量控制: 滑动窗口协议
拥塞控制
.慢开始:在主机刚刚开始发送报文段时可先将拥塞窗口 cwnd 设置为一个最大报文段 MSS 的数值。在每收到一个对新的报文段的确认后,将拥塞窗口增加至多一个 MSS 的数值。用这样的方法逐步增大发送端的拥塞窗口 cwnd,可以使分组注入到网络的速率更加合理。每经过一个传输轮回,拥塞窗口(发送端)就加倍。*
2.拥塞避免:让拥塞窗口缓慢增大,每经过一个往返时间就加1,而不是加倍,按线性规律缓慢增长。拥塞窗口大于慢开始门限,就执行拥塞避免算法。“乘法减小”:指不论在慢开始还是拥塞避免阶段,只要出现超时重传就把慢开始门限值减半。"加分增大“:指执行拥塞避免算法后,使拥塞窗口缓慢增大,以防止网络过早出现拥塞。合起来叫AIMD算法。*
3.快重传算法:发送方只要一连收到三个重复确认就应当重传对方尚未收到的报文。而不必等到该分组的重传计时器到期。 *
4.快恢复算法:(1)当发送端收到连续三个重复的确认时,就执行“乘法减小”算法,把慢开始门限 ssthresh 减半。但接下去不执行慢开始算法。(2)由于发送方现在认为网络很可能没有发生拥塞,因此现在不执行慢开始算法,即拥塞窗口 cwnd 现在不设置为 1,而是设置为慢开始门限 ssthresh 减半后的数值,然后开始执行拥塞避免算法(“加法增大”),使拥塞窗口缓慢地线性增大.*
1.4 TCP time_wait 与端口耗尽
1.4.1 为什么会有 time_wait?
TCP 是双向连接的,所以关闭的时候也需要 发起两次 主动关闭。
主动关闭的一方 会进入 time_wait 状态。客户端主动关闭连接,发送完最后一个ack后,会进入time_wait状态。经过2MSL 后才进入closed状态。
引入 time_wait 的主要目的是:
- 当主动关闭的一方 最后发送的ack 没有被 接受方收到时,接收方会再发送一次 fin,假如这时候主动方已经关闭了,这个时候就会报错,connnection reset。为什么需要是 2MSL,因为假设 发送方发出的ack经过一个MSL后,没有收到,接收方再发出一个fin 也接过了一次MSL,所以大概是2MSL 的时长。
- 假如主动方 发出最后一个ack后,直接进入了closed 状态,有可能这个 ack 很慢。而 此时相同端口和ip的新连接又建立起来并发出了报文,还提前比上一个ack到达了,这样就造成了混乱。所以引入 2MSL也是为了确保,在建立新的连接的时候,网络上所有旧的分组已经没有了。(time_wait阶段是不允许再进行相同端口的tcp连接。)
- 旧的TCP连接已经不存在了,系统此时只能返回RST包
- 新的TCP连接被建立起来了,延迟包可能干扰新的连接
1.4.2 为什么会端口耗尽?
注意: 只有主动关闭的一方才会进入 time_wait 阶段。 一般端口耗尽的场景都是一些短连接场景
比如 A 服务器 请求B 服务器,短期内发起大量的请求,并关闭。如压测场景。
这时候A机器会有大量的端口处于time_wait阶段,还要等待2MSL 才会被回收。所以这个期间假如再大量发起请求,就会出现端口耗尽
一般这种时候可以 尝试优化下内核参数:一般有以下几个参数:
#收缩TIME_WAIT状态socket的回收时间窗口
net.ipv4.tcp_tw_timeout=3
表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭
net.ipv4.tcp_tw_recycle = 0
net.ipv4.tcp_tw_reuse = 0 表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭
注意是 调整请求发起方的机器
- syn flood
2. HTTP
2.1. HTTP 报文基本知识
http request = 请求行 +** 请求头** + 空行 + 请求数据
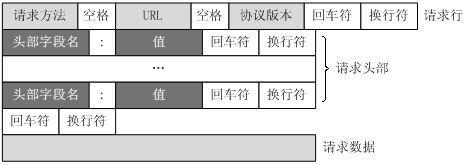
http response = 状态行 + 消息报头 + 空行 +返回数据

小结:
- ** 请求和响应中,头部和数据之间都有一个空行**
- ** GET 和 POST 区别**
get 提交,请求的数据会附在url 上,其http请求中 内容为空,最后一行是空行。
post 提交则不同, 请求的数据 会放在 http 请求中的 内容中。因此 地址栏不会显示
倘若请求数据太多,有些浏览器和web服务器会对 url的长度做限制,因此长度有时候会报错。
(cubes 中 下载明细的时候,把请求参数都弄在url中,get请求时backend 机会报一个长度超出限制的异常)
get 请求 url可能会被浏览器缓存 - 响应状态码
-
100 continue这个临时响应表明,迄今为止的所有内容都是可行的,客户端应该继续请求,如果已经完成,则忽略它。100 continue: 当curl 中 post数据量超过1K 的时候, curl会分为两步,1. 在请求体中 搞一个 expet "100-continue"的请求头,当服务器返回 100-continue的时候,再把内容 post过去。否则不post内容 -
200 OK客户端请求成功 -
201 Created客户端请求成功 -
301 Moved Permanently该请求已成功,并因此创建了一个新的资源 -
302 Moved Temporarily请求临时重定向 -
304 Not Modified文件未修改,可以直接使用缓存的文件。 -
400 Bad Request由于客户端请求有语法错误,不能被服务器所理解。 -
401 Unauthorized请求未经授权。这个状态代码必须和WWW-Authenticate报头域一起使用 -
403 Forbidden服务器收到请求,但是拒绝提供服务。服务器通常会在响应正文中给出不提供服务的原因 -
404 Not Found请求的资源不存在,例如,输入了错误的URL -
406 Not Acceptable请求的资源的内容特性无法满足请求头中的条件,因而无法生成响应实体。 -
500 Internal Server Error服务器发生不可预期的错误,导致无法完成客户端的请求。 -
503 Service Unavailable服务器当前不能够处理客户端的请求,在一段时间之后,服务器可能会恢复正常。
2.2 HTTP 连接管理
reference: https://juejin.im/entry/5880e3df1b69e60058cb7b71
2.2.1 串行连接
每个请求起一个 tcp连接。这样大部分开销都花在了 tcp连接建立的时间上。而且http请求只能一个接着一个来,俗称串行请求
2.2.2 并行连接
可以同时开多个tcp连接。并行连接不一定能够加快。因为总的带宽是有限的,太多并行连接会竞争带宽资源。对服务端是一个性能灾难,同时维持这么多个连接,一下就崩了。
而且 多个tcp连接很耗内存,客户端基于这个考虑也会限制 并行数量。
一般浏览器限制时4 个,谷歌是6条tcp连接。
2.2.2 持久连接
- http/1.1 后引入 connnection:keep-alive 。1.1 中默认是长连接的
- 什么时候 关闭连接?:服务器可以在任何时候关闭该条tcp连接
- 关闭时先关闭 输出端,再关闭输入端。tcp半关闭
2.2.3 管道连接
3 http 缓存
3.1 浏览器缓存
referrence: https://www.cnblogs.com/lyzg/p/5125934.html
强缓存
cache-control: Cache-Control:max-age=315360000 相对时间,以秒为单位,第一次请求资源后,浏览器会把响应结果跟 header头存起来,下一次再 请求时,根据当前时间与max-age 算出缓存是否还生效。生效就直接从浏览器里获取这个资源。
expire: 也是设置一个失效时间,但是又有一个不同服务器的时间偏差的问题。当cache-control 和expire两个同时存在只会生效一个,cache-control 优先级比较高
小结:强缓存不会与服务器进行通信。直接从本地浏览器缓存获取。这是与304一个比较大的区别,但强随之会引入一个资源更新的问题。一般的方法是: 1. 利用文件摘要对资源进行命名。2. 非覆盖式的,每次修改新增一个资源文件。3.发布时 全量更新资源文件,再灰度更新 html文件。协商缓存
当强缓存失效后,会发一个请求到服务器,验证协商缓存是否命中。
主要使用 [last-modified, if-modifyed-since] 和 [etag if-none-match] 来管理的last-modified 和 if-modified-since:
浏览器在第一次请求资源的时候,服务器返回响应中会返回一个 last-modified 这个值。
浏览器下一次请求该资源,会 将 if-modified-since 设置为 last-modified 的值,服务器收到请求后,会根据文件的最后修改时间判断,若文件未修改,则返回304,浏览器则从缓存中加载数据,若资源修改了,则服务器返回资源内容,并更新last-modifeid 值。
但经常会有文件修改了,但是最后修改时间却没有变化的情况。所以又引入了etag 和 if-none-match 来解决这种情况。ETag 和if-none-match:
ETag 可以看成文件的摘要信息,只要文件修改,etag就会相应修改。
浏览器初次请求资源,服务器会返回一个Etag值,
浏览器下次再请求的时候,会将 if-none-match 设置为etag的值,服务器根据收到请求中的if-none-match和资源生成的etag进行比对,若相同,则文件没有改变,返回304,同时返回 etag值。
分布式情况下 每台机器生成的etag都不一样,同时需要注意 last-modified要保持一致。
etag的优先级要高于last-modified启发式缓存
3.2 不使用缓存
可以通过在head中加入 下面这一行来表示当前页面内容不缓存
4 http 访问控制
refernce: https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Access_control_CORS
http://www.ruanyifeng.com/blog/2016/04/cors.html
前端跨域:
- 浏览器在头中 增加origin: xxx
- 服务器端 会根据浏览器中的 origin 进行判断,域名在允许的列表中时会正常返回,同时在头部中会返回
access-control-allow-origin,(该值必须要返回,要么为*,要么为固定的几个列表,浏览器才能判断请求是否合法),Access-Control-Allow-Credentials,option,表示是否要发送浏览器的cookie.
如果要发送cookie,则allow-origin 不能设置为*号- 1.0 和2.0 协议区别
- HTTPS 实现?
- http限流
- cookie
- 安全
3. 网络编程--netty
3.1 linux 网络IO 模型
reference:
https://segmentfault.com/a/1190000003063859#articleHeader12
阻塞IO 模型:
[图片上传失败...(image-2ca914-1524292196821)]
进程读写数据,进入内核空间。系统调用知道数据包达到 被复制到应用进程的缓冲区才会返回,该期间进程一直被阻塞。阻塞不耗费CPU。非阻塞IO 模型
[图片上传失败...(image-547bfc-1524292196821)]
系统调用的时候,若内核缓冲区没有数据,则马上返回一个错误。应用程序会轮询检查这个状态,看内核数据是否准备完成。IO 复用模型
[图片上传失败...(image-f89171-1524292196821)]
3.2 IO 复用 select poll epoll
IO 复用 应用在 服务器需要同时处理多个处于监听状态或者多个连接状态的套接字
3.2.1 select
reference: https://cloud.tencent.com/developer/article/1005481
select 过程:
- 当用户进程 调用select的时候,会将注册在该select上的 socket 集合拷贝到内核空间上
- 然后遍历 socket集合,看是否有可读事件,遍历完后,发现没有可读时间,就会进入睡眠,(有个timeout时间)
- 若睡眠事件有可读事件,则继续上面的流程,否则就等timeout后再统一去check一遍。
小结:
- 由于单个进程打开的文件描述符是有限的,一般会有一个设置,1024/2048是默认的。这也就决定二楼select能处理有限的socket。
- 虽然可以 调高 这个数量,但是select的时候,内核要把消息通知给用户空间,所以会把整个 socket 集合从 用户空间拷到 内核态,然后再在内核进行一一扫描,所以当socket 集合增大,这个复制时间也是线性增长的,一旦太高可能会出现频繁的超时。
- 同时,每次可读事件来了,都不知道哪个socket是可读的,所以还要线性扫描一遍整个集合,也是非常耗时的。
3.2.2 poll
poll 是在select 基础上改进的,唯一改进的点就是 公用一个文件描述符集合,使用链表来存储,因此不会有 文件描述符 1024的限制,但是仍然需要数据的拷贝,以及线性扫描整个socket集合。
3.3.2 epoll
红黑树 + 链表 +mmap
epoll 主要解决上面两个问题:
1. socket 集合数据拷贝问题.
2. socket 线性扫描问题
首先,内核要把fd的消息通知给用户空间,那么内存复制就是不可避免的,但是重点的是如何减少不必要的内存复制。
epoll 通过 区分 注册事件,将fds 集合分散,按需,只有监听的事件来了,才会拷贝到内核空间中。对于高频的事件,则用mmap来减少内存复制。
那么如何能够快速找到监听的事件?同时进行增删改?
epoll 引入了 红黑树,来进行查找等操作。
当使用epoll_ctl 注册号所有要交监听的事件后,红黑树建立完毕。同时每个事件都会在网卡建立一个回调关系,当事件来了之后,就会去回调这个callback函数。
callback 函数主要做的事情就是去红黑树找到这个事件的节点,然后添加到双向链表中。
然后双向链表再拷贝到内存中。
这样就减少了 不必要的内存拷贝。同时也解决了无效的线性扫描问题
[图片上传失败...(image-59e1f4-1524292196821)]
- epoll_wait调用ep_poll,当rdlist为空(无就绪fd)时挂起当前进程,直到rdlist不空时进程才被唤醒。
- 文件fd状态改变(buffer由不可读变为可读或由不可写变为可写),导致相应fd上的回调函数ep_poll_callback()被调用。
- ep_poll_callback将相应fd对应epitem加入rdlist,导致rdlist不空,进程被唤醒,epoll_wait得以继续执行。
- ep_events_transfer函数将rdlist中的epitem拷贝到txlist中,并将rdlist清空。
- ep_send_events函数(很关键),它扫描txlist中的每个epitem,调用其关联fd对用的poll方法。此时对poll的调用仅仅是取得fd上较新的events(防止之前events被更新),之后将取得的events和相应的fd发送到用户空间(封装在struct epoll_event,从epoll_wait返回)。
Epoll 工作模式:
LT模式:当epoll_wait检测到描述符事件发生并将此事件通知应用程序,应用程序可以不立即处理该事件。下次调用epoll_wait时,会再次响应应用程序并通知此事件。
ET模式:当epoll_wait检测到描述符事件发生并将此事件通知应用程序,应用程序必须立即处理该事件。如果不处理,下次调用epoll_wait时,不会再次响应应用程序并通知此事件。
3.3 java NIO 与 netty
todo 待续