Python3数据分析与挖掘建模(15)特征选择与特征变换
1 特征选择
1. 1 概述
特征选择是一种剔除与标注不相关或冗余的特征的方法,以减少特征集的维度和复杂性,并提高模型的性能和解释能力。特征选择的目标是选择那些对目标变量有预测能力且与其他特征不冗余的特征。
特征选择的方法可以分为三类:
(1)过滤式(Filter)特征选择:通过对特征进行评估,计算特征与目标变量之间的相关性或其他统计指标,然后根据设定的阈值选择特征。常见的方法包括相关系数、卡方检验、互信息等。
(2)包裹式(Wrapper)特征选择:将特征选择看作是一个搜索问题,根据模型的性能评估指标,使用特定的搜索算法(如递归特征消除、遗传算法等)选择最佳的特征子集。
(3)嵌入式(Embedded)特征选择:在模型训练的过程中,通过正则化或其他内置的特征选择方法自动选择特征。常见的方法包括L1正则化(Lasso)、决策树的特征重要性等。
特征选择可以帮助去除无关或冗余的特征,提高模型的泛化能力,减少过拟合的风险,同时还能提升模型的训练和预测效率。选择合适的特征选择方法需要结合数据集的特点、问题的领域知识和实际需求进行综合考虑。
1.2 过滤思想 (数据规约)
数据规约是指通过对数据进行压缩、聚合或转换等处理,减少数据量、降低数据维度或保留数据的关键特征,从而减少数据存储和计算的成本,提高数据处理效率。
在数据规约中,抽样是一种常用的思路之一。抽样是从大规模数据集中选择部分样本来代表整体数据集的方法。通过在保持样本代表性的前提下,减少样本数量,从而降低数据处理的复杂度和成本。
在进行抽样时,需要考虑以下几个方面:
(1)抽样方法:选择合适的抽样方法,如简单随机抽样、分层抽样、系统抽样等,根据实际情况确定使用哪种抽样方法。
(2)样本大小:确定抽样的样本数量,样本大小需要根据数据集的大小、特征分布以及分析需求等因素进行权衡和确定。
(3)采样策略:根据数据集的特点和需求,选择合适的采样策略,如均匀采样、重要性采样等,以确保样本的代表性和有效性。
(4)抽样误差控制:在进行抽样时,需要考虑抽样误差的控制,通过统计方法或抽样方案的设计来控制抽样误差,以保证样本的可靠性和有效性。
抽样是一种常见的数据规约方法,适用于大规模数据集或计算资源有限的情况下。通过合理的抽样策略和方法,可以减少数据处理的工作量和成本,同时保持数据的代表性和有效性。但需要注意的是,在抽样过程中可能会引入抽样误差,因此需要合理控制和评估抽样误差的影响。
| 数据类型 | 可用方法 |
| 连续---连续 | 相关系数、假设检验 |
| 连续---离散(二值) | 相关系数,连续二值化(最小Gini切分,最大熵增益切分) |
| 连续---离散(非二值) | 相关系数(定序) |
| 离散(二值)--- 离散(二值) | 相关系数,熵相关,F分值 |
| 离散--- 离散(非二值) | 熵相关,Gini,相关系数(定序) |
1.3 包裹思想(RFE算法)
包裹思想是特征选择的一种方法,它通过将特征选择问题转化为一个优化问题来进行特征选择。在包裹思想中,将特征选择看作是一个搜索问题,目标是找到最佳的特征子集,使得在该子集上训练得到的模型性能达到最优。
包裹思想的特点是使用特定的评估准则来评估特征子集的性能,通常是通过训练和验证模型来衡量。具体步骤如下:
(1)定义搜索空间:确定可供选择的特征子集的范围,可以是全部特征的组合,也可以是部分特征的组合。
(2)生成候选特征子集:根据定义的搜索空间,生成不同的特征子集作为候选。
(3)训练和验证模型:对每个候选特征子集,使用训练数据进行模型训练,并使用验证数据评估模型性能。评估准则可以是各种指标,如准确率、F1值、AUC等。
(4)选择最佳特征子集:根据评估准则的结果,选择性能最佳的特征子集作为最终的选择。
包裹思想的优点是可以考虑特征之间的相互关系,能够更准确地评估特征的贡献和重要性。然而,由于包裹思想需要在每个候选特征子集上训练和验证模型,计算复杂度较高,特别是当特征数量较多时,搜索空间庞大,可能会导致计算开销大。
因此,包裹思想在实际应用中常常需要权衡计算成本和性能收益,并根据具体情况选择合适的特征选择方法。
示例:
在特征选择中,将特征集合X拆分为特征子集S_1、S_2、...、S_n是一种常见的做法,其中每个特征子集代表一个特定的特征组合。
这种拆分可以通过多种方式进行,取决于特征选择的具体目标和需求。以下是几种常见的拆分方式:
(1)顺序拆分:按照特征的顺序逐个拆分特征集合。例如,从第一个特征开始,先选择单个特征作为特征子集S_1,然后选择两个特征作为特征子集S_2,依此类推,直到选择所有特征为特征子集S_n。
(2)组合拆分:通过组合特征来生成特征子集。例如,从特征集合中选择2个特征的组合作为特征子集S_1,选择3个特征的组合作为特征子集S_2,以此类推,直到选择所有特征的组合为特征子集S_n。
(3)筛选拆分:根据特定的评估准则筛选特征,逐步构建特征子集。例如,根据特征的重要性评分或其他统计指标,先选择得分最高的特征作为特征子集S_1,然后在剩余的特征中选择得分次高的特征作为特征子集S_2,以此类推,直到选择所有特征或满足特定条件为止。
这些拆分方式都可以根据具体问题和算法的需求进行调整和组合。关键是根据特征的相关性、重要性和模型性能的要求,选择合适的特征子集来进行特征选择,以提高模型的准确性和效率。
1.4 嵌入思想
嵌入思想中的简单回归模型可以用来对标注进行回归,得到特征与标注之间的系数。
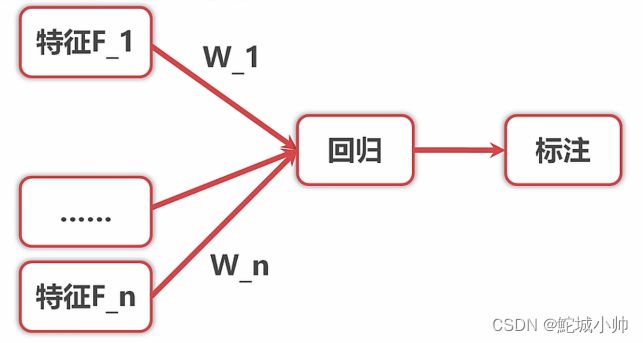
下面是基于嵌入思想建立简单回归模型的一般步骤:
(1)数据准备:收集包含特征F_1、F_2、...、F_n和对应的标注数据W_1、W_2、...、W_n的样本数据集。
(2)模型选择:根据特征与标注之间的关系和数据的特性,选择适合的回归模型。常见的回归模型包括线性回归、多项式回归、岭回归、Lasso回归等。
(3)模型训练:使用选定的回归模型对数据集进行训练。模型会根据样本数据学习特征与标注之间的关系,并得到特征的系数。
(4)特征系数获取:根据训练后的回归模型,可以获取特征F_1、F_2、...、F_n对应的系数W_1、W_2、...、W_n。这些系数表示了特征对标注的贡献程度,正负值表示了特征与标注之间的正向或负向关系。
(5)系数解释:分析特征系数的大小和符号,可以推断出特征与标注之间的关系。正系数表示该特征与标注正相关,负系数表示该特征与标注负相关。系数的绝对值越大,表示该特征对标注的影响越大。
通过以上步骤,可以建立简单回归模型并获取特征与标注之间的系数。这些系数可以帮助理解特征对标注的影响程度,从而进行特征选择或进一步的分析。
1.5 代码示例
import numpy as np
import pandas as pd
import scipy.stats as ss
from sklearn.tree import DecisionTreeRegressor
df=pd.DataFrame({"A":ss.norm.rvs(size=10),"B":ss.norm.rvs(size=10),"C":ss.norm.rvs(size=10),\
"D":np.random.randint(low=0,high=2,size=10)})
print(df)
print("------------------------")
X=df.loc[:,["A","B","C"]]
Y=df.loc[:,"D"]
from sklearn.feature_selection import SelectKBest,RFE,SelectFromModel
skb=SelectKBest(k=2)
skb.fit(X,Y)
print(skb.transform(X))
print("------------------------")
# 嵌入思想
sfm = SelectFromModel(estimator=DecisionTreeRegressor(), threshold=0.001)
print(sfm.fit_transform(X,Y))
print("------------------------")
这段代码的功能如下:
- 创建一个包含随机数据的DataFrame,其中包括列"A"、"B"、"C"和"D"。
- 使用
SelectKBest进行特征选择,选择前k个最佳特征。在这里,我们选择了k=2个最佳特征。 - 使用
fit方法拟合选择器到特征和目标变量上,并使用transform方法获取选定的特征。 - 使用嵌入思想,利用
SelectFromModel选择模型中的重要特征。这里使用DecisionTreeRegressor作为估计器,并设置阈值为0.001。 - 使用
fit_transform方法将模型应用于特征和目标变量,并返回选择的特征。
请注意,此代码段仅提供了特征选择的示例,并使用了SelectKBest和SelectFromModel方法。你可以根据需要调整相关参数或使用其他特征选择方法来适应你的数据分析任务。
2. 特征变换
2.1对指化
特征变换中的"对指化"(指数化)通常是指将特征进行指数转换,以改变特征的分布形态或增强特征的相关性。这种变换可以通过对特征值应用指数函数来实现。
2.2 指数化
2.2.1 概述
指数化就是将一个数变换为指数的过程,指数一般情况下取自然底数。如图,
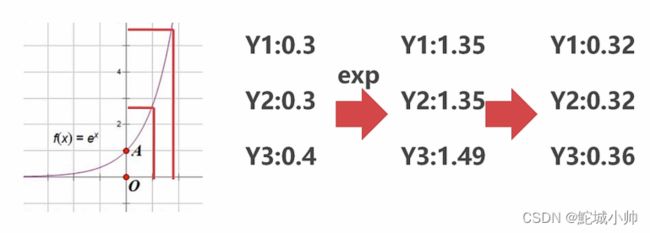
横轴标识自变量有很小的一段变化,纵轴有较大的一段变化。原来的Y轴分别是 0.3、0.3、0.4,指数化后成了 1.35、1.35、1.49,再进行归化后,分别是 0.32、0.32、0.36。相互间的最大差距从原来的0.4-0.3=0.1变成了0.36-0.32=0.04。
这个从获取指数到归化的整个过程,是一个Softmax函数。
2.2.2 示例
import numpy as np
# 创建一个包含随机数据的特征向量
X = np.array([1, 2, 3, 4, 5])
# 对指化
X_exp = np.exp(X)
print("原始特征向量:", X)
print("指数化后的特征向量:", X_exp)
在上述代码中,我们使用NumPy库将特征向量X中的每个值应用指数函数进行转换,得到指数化后的特征向量X_exp。
指数化通常用于处理偏态分布的特征,以使其更接近于正态分布,或者用于增强特征的相关性,例如在某些回归问题中。
2.3 对数化
2.3.1 概述
对数化(对数变换)是特征变换的一种常见方法,通过应用对数函数来转换特征的取值。对数化通常用于处理偏态分布的特征,以减小极端值的影响、降低变量的偏度,使其更接近于正态分布。

对数的底可以自然数e,也可以取10或2。如果一个数远大于1,那么横轴的变化很大的时候,纵轴的变化也不会很大。这样可以把一个很大的数,缩放到我们容易计算的范围内。
2.3.2 示例:
以下是一个对数化的示例代码:
import numpy as np
# 创建一个包含随机数据的特征向量
X = np.array([1, 10, 100, 1000, 10000])
# 对数化
X_log = np.log(X)
print("原始特征向量:", X)
print("对数化后的特征向量:", X_log)
在上述代码中,我们使用NumPy库将特征向量X中的每个值应用对数函数进行转换,得到对数化后的特征向量X_log。
对数化可用于压缩较大的值范围,减小变量之间的差异度,同时也有助于处理右偏或左偏分布的特征。然而,对数化可能不适用于包含零值或负值的特征,因为对数函数在这些情况下无法定义。
3 离散化
3.1 概述
离散化是特征变换的一种方法,它将连续变量划分为若干个离散的区间或类别,使得原始连续数据变成离散的取值。离散化的目的可以是克服数据的缺陷、满足某些算法的要求,或者进行非线性数据映射。
(1)离散化的过程通常包括以下步骤:
- 选择离散化的方式:常见的离散化方式包括等宽离散化(将数据划分为等宽的区间)、等频离散化(将数据划分为等频的区间)和聚类离散化(利用聚类算法将数据划分为簇)等。
- 确定离散化的区间或类别个数:根据数据的特性和需求,确定离散化的区间或类别个数。这一步可以根据业务知识、数据分布或算法要求来确定。
- 对数据进行离散化:根据选择的离散化方式和区间或类别个数,将连续变量的取值划分为相应的离散区间或类别。
离散化可以使得连续变量变得更易于处理,可以减小异常值的影响、降低算法的复杂性,并且有助于捕捉非线性关系。然而,离散化也可能会损失一些信息,因此在选择离散化方式和确定离散化的区间或类别时需要谨慎考虑。
(2)示例:
import numpy as np
# 创建一个包含连续数据的特征向量
X = np.array([1.2, 2.5, 3.7, 4.1, 5.9, 7.2, 8.6])
# 等宽离散化为3个区间
bins = np.linspace(np.min(X), np.max(X), 4)
# 对数据进行离散化
X_discrete = np.digitize(X, bins)
print("原始特征向量:", X)
print("离散化后的特征向量:", X_discrete)
在上述代码中,我们使用NumPy库将连续特征向量X进行等宽离散化,将其划分为3个区间。通过np.digitize函数可以将原始数据映射到相应的离散区间。
离散化可以使得连续变量变得更易于处理,可以减小异常值的影响、降低算法的复杂性,并且有助于捕捉非线性关系。然而,离散化也可能会损失一些信息,因此在选择离散化方式和确定离散化的区间或类别时需要谨慎考虑。
3.2 离散化方法
离散化是将连续变量划分为离散的取值区间或类别的过程。在离散化中,常用的离散化方法包括等频离散化、等距离散化和自定义因变量优化离散化。
(1)等频离散化(Equal Frequency Discretization):等频离散化将数据划分为具有相同观测数量的区间或类别。通过这种方式,可以确保每个区间或类别中包含相似数量的观测值。等频离散化可以减少极端值对离散化结果的影响。
(2)等距离散化(Equal Width Discretization):等距离散化将数据划分为具有相同宽度的区间或类别。通过这种方式,每个区间或类别的取值范围相等。等距离散化适用于数据分布比较均匀的情况,但对于数据分布不均匀的情况可能会导致某些区间或类别中观测数量过少或过多。
(3)自定义因变量优化离散化(Custom Discretization with Target Optimization):这是一种根据因变量(目标变量)的分布特征进行优化的离散化方法。通过考虑因变量与连续变量之间的关系,可以将连续变量划分为离散的区间或类别,使得每个区间或类别内的观测值在因变量上具有相似的分布特征。这种离散化方法可以帮助更好地捕捉因变量与连续变量之间的非线性关系。
在选择离散化方法时,需要考虑数据的分布特征、业务需求以及模型建立的目的。不同的离散化方法可能适用于不同的情况,因此需要根据具体问题进行选择和实验。
在实际应用中,可以使用各种统计和机器学习工具包来进行离散化操作,例如Python中的pandas、scikit-learn等。这些工具包提供了丰富的离散化函数和方法,可以根据具体需求进行调用和应用。
3.3 分箱
3.3.1 概述
离散化中的分箱是指将连续变量划分为若干个箱子或区间的过程。分箱的目的是将连续变量转化为有序的离散类别,以便更好地理解和分析数据。
在进行分箱时,可以考虑两个关键因素:分箱的深度和宽度。
(1)分箱深度(Bucketing Depth):分箱深度指的是将连续变量划分为多少个不同的箱子或区间。选择合适的分箱深度需要考虑数据的分布特征、样本数量以及业务需求等因素。较浅的分箱深度可能无法捕捉到连续变量的细微差异,而较深的分箱深度可能导致过拟合或过多的类别,增加建模的复杂性。
(2) 分箱宽度(Bucket Width):分箱宽度指的是每个箱子或区间的取值范围。分箱宽度可以是等距的(每个箱子的宽度相等)或根据数据分布特征进行自适应调整。较宽的分箱宽度可能会损失数据的细节和差异,而较窄的分箱宽度可能导致某些箱子中观测数量过少或过多。
选择合适的分箱深度和宽度需要结合实际问题进行调整和优化。常用的分箱算法包括等频分箱、等距分箱、卡方分箱等。这些算法可以根据数据的分布特征和业务需求来选择合适的分箱策略。
在实际应用中,可以使用统计和机器学习工具包提供的函数和方法来进行分箱操作,如pandas的cut()函数和scikit-learn的KBinsDiscretizer类。这些工具可以根据给定的分箱深度和宽度参数,将连续变量进行分箱处理,并生成对应的离散类别特征。
3.3.2 分箱示例
如:有9个数,分别是 6 8 10 15 16 24 25 40 67。
3.3.2.1 等宽分箱
要对上述的9个数值进行等宽分箱,将其分为3个箱子,可以按照以下步骤进行操作:
(1)找出这9个数值的最小值和最大值。在这个示例中,最小值是6,最大值是67。
(2)计算每个箱子的宽度。将最大值和最小值的差值除以箱子的数量,即 (最大值 - 最小值) / 箱子数量。在这个示例中,宽度 = (67 - 6) / 3 = 20.33。
(3)确定各个箱子的取值范围。从最小值开始,依次按照宽度递增,确定每个箱子的上界和下界。
- 箱子1的下界为最小值,上界为下界 + 宽度。在这个示例中,箱子1的取值范围为6-26.33。
- 箱子2的下界为箱子1的上界,上界为下界 + 宽度。在这个示例中,箱子2的取值范围为26.33-46.66。
- 箱子3的下界为箱子2的上界,上界为最大值。在这个示例中,箱子3的取值范围为46.66-67。
(4)将每个数值根据其大小放入对应的箱子中。根据上述的取值范围,将6, 8, 10放入箱子1,15, 16, 24放入箱子2,25, 40, 67放入箱子3。
通过这样的等宽分箱操作,将9个数值划分为3个箱子,每个箱子的取值范围相等。请注意,等宽分箱可能导致某些箱子内的数据点较少或较多,需要根据具体情况进行评估和调整。
3.3.2.2 等深分箱
对于上述的9个数值进行等深分箱的步骤如下:
(1)确定要分成的箱子数量。在这个示例中,假设要分成3个箱子。
(2)计算每个箱子中的数据数量。将总数据量除以箱子的数量,即 总数据量 / 箱子数量。在这个示例中,假设总数据量为9个。
- 箱子1中应包含的数据数量为 总数据量 / 箱子数量 = 9 / 3 = 3个。
- 箱子2中应包含的数据数量也为3个。
- 箱子3中应包含的数据数量也为3个。
(3)将数据按照升序排序。
排序后的数值序列为:6, 8, 10, 15, 16, 24, 25, 40, 67。
(4)根据计算得到的每个箱子应包含的数据数量,在排序后的数据中,依次取出对应数量的数据放入每个箱子中。
- 箱子1中放入前3个最小的数值:6, 8, 10。
- 箱子2中放入接下来的3个数值:15, 16, 24。
- 箱子3中放入剩下的3个最大的数值:25, 40, 67。
通过上述步骤,将9个数值进行了等深分箱,每个箱子中包含了相同数量的数据。请注意,等深分箱是根据数据在排序后的位置进行分割,而不考虑数值的大小。
3.3.3 python-分箱示例
import pandas as pd
lst = [6, 8, 10, 15, 16, 24, 25, 40, 67]
# 使用pd.qcut进行等深分箱,分为3个箱子
qcut_result = pd.qcut(lst, q=3)
print(qcut_result)
# 使用pd.cut进行等宽分箱,分为3个箱子,并指定标签
cut_result = pd.cut(lst, bins=3, labels=["low", "medium", "high"])
print(cut_result)
代码说明:
- 在上述代码中,我们使用了
pd.qcut和pd.cut函数来进行数据的分箱操作。 pd.qcut函数实现了等深分箱,将数据分为指定数量的箱子,并保证每个箱子中包含的数据数量相等。pd.cut函数实现了等宽分箱,将数据根据数值范围进行分割,并指定了分割后每个箱子的标签。- 在代码中,我们先定义了一个列表
lst,其中包含了需要进行分箱的数值。 pd.qcut(lst, q=3)表示将lst列表中的数值进行等深分箱,分为3个箱子,并返回分箱的结果。pd.cut(lst, bins=3, labels=["low", "medium", "high"])表示将lst列表中的数值进行等宽分箱,分为3个箱子,并给每个箱子指定了标签"low"、"medium"、"high",返回分箱的结果。- 最后,我们分别打印输出了等深分箱和等宽分箱的结果。
4. 归一化与标准化
归一化(Normalization)和标准化(Standardization)是常用的特征预处理方法,用于将不同特征的数值转换到相同的尺度或范围,以便更好地进行比较和分析。它们的目的是消除特征之间的量纲差异,使得模型能够更好地处理数据。
4.1 归一化
4.1.1 概述
归一化是将数值缩放到一个固定的范围,通常是[0, 1]或[-1, 1]之间。常见的归一化方法有最小-最大缩放(Min-Max Scaling)和小数定标(Decimal Scaling)方法。
最小-最大缩放方法将原始数据减去最小值,然后除以最大值和最小值的差,公式如下:
X_normalized = (X - X_min) / (X_max - X_min)
其中,X是原始数据,X_min是最小值,X_max是最大值。
小数定标方法将原始数据除以一个固定的基数,通常是10的幂次方,使得数据落在[-1, 1]之间。公式如下:
X_normalized = (X - X_min) / (X_max - X_min)
其中,X是原始数据,j是使得最大绝对值小于1的整数。
4.1.2 示例
假设有一个数据集,其中包含两个特征:年龄和收入。年龄的取值范围在18到65岁之间,收入的取值范围在10000到50000之间。我们可以使用最小-最大缩放方法将这两个特征归一化到[0, 1]的范围内。例如,将年龄为30岁的数据归一化后的值为0.4,将收入为30000的数据归一化后的值为0.5。
4.2 标准化
4.2.1 概述
标准化是将数据转换为均值为0,标准差为1的分布。常见的标准化方法是Z-score标准化方法。
Z-score标准化方法将原始数据减去均值,然后除以标准差,公式如下:
X_standardized = (X - mean) / std
其中,X是原始数据,mean是均值,std是标准差。
归一化和标准化的选择取决于具体的情况和模型的要求。归一化通常适用于对特征的绝对值大小不敏感的情况,而标准化通常适用于对特征的分布形状和离群值敏感的情况。可以根据实际需求选择适合的方法进行特征预处理。
4.2.2 示例
假设有一个数据集,其中包含一个特征:房屋面积。房屋面积的取值范围在1000到2000之间,而均值为1500,标准差为200。我们可以使用Z-score标准化方法将房屋面积标准化为均值为0,标准差为1的分布。例如,一个房屋面积为1700的数据经过标准化后的值为0.5,表示该房屋面积高于平均水平的0.5个标准差。
4.3 python示例
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler, StandardScaler
# 使用 MinMaxScaler 进行数据归一化
print(MinMaxScaler().fit_transform(np.array([1, 4, 10, 15, 21]).reshape(-1, 1)))
# 使用 StandardScaler 进行标准化
print(StandardScaler().fit_transform(np.array([1, 1, 1, 1, 0, 0, 0, 0]).reshape(-1, 1)))
# 使用 StandardScaler 进行标准化
print(StandardScaler().fit_transform(np.array([1, 0, 0, 0, 0, 0, 0, 0]).reshape(-1, 1)))
分析:
- 第一个打印语句使用了
MinMaxScaler对数组[1, 4, 10, 15, 21]进行归一化处理。归一化的目标是将数据缩放到指定的范围内(通常是[0, 1]),这里将数组的值映射到[0, 1]之间,并打印归一化后的结果。 - 第二个打印语句使用了
StandardScaler对数组[1, 1, 1, 1, 0, 0, 0, 0]进行标准化处理。标准化的目标是将数据转换为均值为0,标准差为1的分布。这里将数组的值标准化,并打印标准化后的结果。 - 第三个打印语句同样使用了
StandardScaler对数组[1, 0, 0, 0, 0, 0, 0, 0]进行标准化处理,与第二个打印语句的输入不同。同样地,它将数组的值标准化,并打印标准化后的结果。
这些操作是常用的数据预处理步骤,用于将数据转换为更适合机器学习模型的形式。归一化和标准化可以消除不同特征之间的量纲差异,帮助模型更好地处理数据。
执行结果如下:
[[0. ]
[0.15]
[0.45]
[0.7 ]
[1. ]]
[[ 1.]
[ 1.]
[ 1.]
[ 1.]
[-1.]
[-1.]
[-1.]
[-1.]]
[[ 2.64575131]
[-0.37796447]
[-0.37796447]
[-0.37796447]
[-0.37796447]
[-0.37796447]
[-0.37796447]
[-0.37796447]]5. 数值化
5.1 概述
数值化是将非数值型数据转换为数值型数据的过程,使得这些数据可以用于数值计算和机器学习算法中。在数值化的过程中,可以根据不同的性质对数据进行分类,包括定类、定序、定距和定比。
(1) 定类(Nominal):将非数值型数据分成不同的类别,每个类别用一个独特的数值表示。这种数值化方法仅表示类别之间的差异,而没有顺序或大小的含义。例如,将颜色分为红、绿、蓝,用0、1、2来表示各个颜色类别。
(2)定序(Ordinal):将非数值型数据分成不同的类别,并给予它们一定的顺序或优先级。这种数值化方法表示了类别之间的相对关系,具有一定的顺序性。例如,将产品评级分为优、良、差,用1、2、3来表示评级的顺序。
(3)定距(Interval):将数值型数据映射到一定的数值范围,保持了数值之间的相对关系和间隔。定距数值化方法可以进行加减运算,但没有绝对的零点,即零并不表示完全缺失或无意义。例如,将温度从摄氏度转换为华氏度。
(4)定比(Ratio):将数值型数据映射到一定的数值范围,保持了数值之间的相对关系、间隔和比例关系。定比数值化方法可以进行加减乘除运算,并且具有绝对的零点,零表示完全缺失或无意义。例如,将长度从厘米转换为米。
不同的数值化方法适用于不同类型的数据和分析需求,选择合适的数值化方法可以更好地表达数据的特征和关系。
5.2 转换问题
定类(Nominal)和定序(Ordinal)数据通常需要进行数值化的原因是为了在机器学习算法中能够处理和分析这些数据。机器学习算法通常基于数值计算和统计方法,需要将输入数据转换为数值形式才能进行计算和模型构建。
(1)定类数据的数值化:定类数据是无序的分类数据,例如颜色、性别、城市等。数值化定类数据可以将不同的类别映射为不同的数值,以便机器学习算法能够对其进行处理。常见的数值化方法包括独热编码(One-Hot Encoding),将每个类别表示为一个二进制向量。
(2)定序数据的数值化:定序数据是有序的分类数据,例如评级、程度等。数值化定序数据可以将不同的类别赋予一个数值,以表示其相对顺序或优先级。这样可以在算法中保留类别之间的顺序关系,以便进行排序和比较操作。
定距(Interval)数据通常需要进行归一化的原因是为了消除不同特征之间的量纲差异,使得它们具有可比性,并有助于提高机器学习算法的性能和收敛速度。
(3)定距数据的归一化:定距数据是具有等间隔的数值数据,例如温度、时间、身高等。这些数据的数值范围可能会有很大差异,导致在算法中对于不同特征的权重和影响力不均衡。通过归一化,将数据映射到一个特定的范围(通常是0到1之间或其他固定范围),可以消除量纲差异,使得不同特征具有相似的尺度和重要性,提高算法的性能和可解释性。
综上所述,数值化定类和定序数据以及归一化定距数据的目的是为了适应机器学习算法的要求,确保数据能够被正确地处理和分析。这样可以提高算法的准确性、稳定性和可解释性,同时确保不同类型的数据能够在同一框架下进行统一处理和比较。
5.3 数值化-标准化
5.3.1 概述
数值化的标签化是指将分类变量的标签(类别)转换为数值形式,以便机器学习算法能够处理和分析。标签化是特征工程中的一个重要步骤,通常用于处理定类(Nominal)和定序(Ordinal)类型的数据。
在数值化的标签化过程中,需要为每个不同的类别分配一个唯一的数值,以表示其在数据中的存在。这样做的目的是为了将分类变量转换为数值形式,以便算法能够对其进行计算和建模。
常见的数值化标签化方法包括:
(1)整数编码:为每个类别分配一个整数值。例如,对于颜色特征,可以使用0表示红色,1表示蓝色,2表示绿色,依此类推。
(2)独热编码(One-Hot Encoding):将每个类别表示为一个二进制向量,其中只有一个位置为1,其余位置为0。每个位置对应一个类别,该位置为1表示数据属于该类别,为0表示不属于该类别。独热编码可以消除类别之间的顺序关系,并确保每个类别在算法中被平等对待。
(3)标签编码(Label Encoding):将类别按照一定的顺序进行编码,例如按照字母顺序或频率顺序。标签编码可以保留类别之间的顺序关系,但不同于独热编码,它将类别映射为有序的整数值。
数值化的标签化可以使分类变量适应机器学习算法的要求,使算法能够处理和分析这些数据。然而,在使用标签化时需要注意,不同的编码方法可能会对算法产生不同的影响,因此需要根据具体情况选择合适的编码方式。此外,还需要注意对于定序类型的数据,应该使用能够保留顺序关系的编码方式,以确保模型能够正确理解和利用这些信息。
5.3.2 python示例
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
import numpy as np
# 对["Down", "Down", "Up", "Down", "Up"]进行标签化转换
print(LabelEncoder().fit_transform(np.array(["Down", "Down", "Up", "Down", "Up"]).reshape(-1, 1)))
# 对["Low", "Medium", "Low", "High", "Medium"]进行标签化转换
print(LabelEncoder().fit_transform(np.array(["Low", "Medium", "Low", "High", "Medium"]).reshape(-1, 1)))
# 实例化LabelEncoder对象,对["Red", "Yellow", "Blue", "Green"]进行拟合
lb_encoder = LabelEncoder()
lb_encoder = lb_encoder.fit(np.array(["Red", "Yellow", "Blue", "Green"]))
# 使用拟合好的lb_encoder对象,对["Red", "Yellow", "Blue", "Green"]进行转换
lb_trans_f = lb_encoder.transform(np.array(["Red", "Yellow", "Blue", "Green"]))
# 实例化OneHotEncoder对象,对数值化结果进行独热编码
oht_enoder = OneHotEncoder().fit(lb_trans_f.reshape(-1, 1))
# 使用lb_encoder对象将["Red", "Blue"]进行转换,然后使用oht_enoder对象进行独热编码转换
print(oht_enoder.transform(lb_encoder.transform(np.array(["Red", "Blue"])).reshape(-1, 1)).toarray())
执行结果:
[0 0 1 0 1]
[1 2 1 0 2]
[[0. 0. 1. 0.]
[1. 0. 0. 0.]]代码分析:
- 第一个打印语句将字符串数组
["Down", "Down", "Up", "Down", "Up"]进行标签化转换,输出数值化后的结果。 - 第二个打印语句将字符串数组
["Low", "Medium", "Low", "High", "Medium"]进行标签化转换,输出数值化后的结果。 - 首先实例化一个
LabelEncoder对象,并将其赋值给lb_encoder变量,然后对字符串数组["Red", "Yellow", "Blue", "Green"]进行拟合。 - 使用拟合好的
lb_encoder对象,对字符串数组["Red", "Yellow", "Blue", "Green"]进行转换,得到数值化的结果lb_trans_f。 - 实例化一个
OneHotEncoder对象,并对数值化结果lb_trans_f进行独热编码的拟合。 - 使用
lb_encoder对象将字符串数组["Red", "Blue"]进行转换,然后使用拟合好的oht_enoder对象进行独热编码转换,输出独热编码后的结果。
注意:LabelEncoder用于将离散的定性变量转换为数值,OneHotEncoder用于将数值型的离散变量进行独热编码。独热编码将每个离散值转换为一个新的二进制特征,以表示是否具有该值。
6. 正规化
6.1 概述
正规化(Normalization)是一种常用的特征变换方法,它将数值特征缩放到一个特定的范围或统一的尺度,以消除不同特征之间的量纲差异。正规化可以使得数据在相同的尺度上进行比较和分析,有助于提升模型的性能和稳定性。
常见的正规化方法包括最小-最大缩放(Min-Max Scaling)和Z-score标准化(Z-score Standardization)。
6.1.1 最小-最大缩放(Min-Max Scaling):
最小-最大缩放是将数值特征线性地缩放到一个指定的最小值和最大值之间的范围,通常是[0, 1]。该方法的公式为:
X_scaled = (X - X_min) / (X_max - X_min)
其中,X为原始特征值,X_scaled为缩放后的特征值,X_min和X_max分别为特征的最小值和最大值。
6.1.2 Z-score标准化(Z-score Standardization):
Z-score标准化将数值特征转换为均值为0、标准差为1的正态分布。该方法的公式为:
X_scaled = (X - X_mean) / X_std其中,X为原始特征值,X_scaled为标准化后的特征值,X_mean为特征的平均值,X_std为特征的标准差。
正规化可以使得数据分布更加集中,有助于提高模型的收敛速度和稳定性。它常用于需要计算距离或相似度的算法(如KNN、聚类算法)以及需要将特征值映射到固定范围的场景中。
下面是示例代码以及注释:
import numpy as np
from sklearn.preprocessing import MinMaxScaler, StandardScaler
# 示例数据
data = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
# 最小-最大缩放(将特征缩放到[0, 1]范围)
scaler = MinMaxScaler()
scaled_data = scaler.fit_transform(data)
print("Min-Max Scaling:")
print(scaled_data)
print("------------------")
# Z-score标准化(将特征转换为均值为0、标准差为1的正态分布)
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
print("Z-score Standardization:")
print(scaled_data)上述代码中,首先使用`MinMaxScaler`进行最小-最大缩放,将数据的特征缩放到[0, 1]的范围内。然后使用`StandardScaler`进行Z-score标准化,将数据的特征转换为均值为0、
6.2 L1与L2正则化
6.2.1 L1
L1正则化和L2正则化是机器学习中常用的正则化方法,用于在模型训练过程中对模型的复杂度进行惩罚,以防止过拟合。
L1正则化(L1 Regularization)是指在损失函数中添加L1范数(绝对值)惩罚项。它的作用是促使模型的部分权重(系数)趋向于零,从而实现特征选择和稀疏性的效果。L1正则化可以将一些不重要的特征的权重压缩至零,从而达到特征选择和降维的目的。L1正则化的数学表达式如下:
L1正则化:![]()
该公式用于将向量x的每个元素xi除以所有元素绝对值的总和。它的目的是将向量的元素缩放到总和为1的范围内,从而使得向量的元素和为1。这种归一化方法可以保留向量的方向信息,并且适用于处理具有不同尺度或幅度的特征。
公式解释:
- xi 表示向量x的第i个元素
- |xj| 表示向量x的第j个元素的绝对值
- n 表示向量x的维度
计算步骤:
- 对向量x的每个元素xi,计算其绝对值|xj|
- 计算向量x所有元素绝对值的总和,即Σ|xj|
- 将向量x的每个元素xi除以绝对值的总和Σ|xj|,得到归一化后的新向量x'
这种归一化方法可以用于处理具有不同尺度的特征,使得它们在相同的范围内进行比较和分析。同时,它也可以用于处理稀疏向量,其中绝对值总和可能为零或接近零的情况。
6.2.2 L1正规化示例
示例: (1,1,3,-1,2)->L1->(1/8,1/8,3/8,-1/8,2/8)
针对上述示例,我们可以对向量进行L1范数归一化(L1-norm normalization)。L1范数归一化是通过将向量的每个元素除以向量中所有元素的绝对值之和来实现的。
计算步骤如下:
1. 计算向量中每个元素的绝对值之和,即|1| + |1| + |3| + |-1| + |2| = 1 + 1 + 3 + 1 + 2 = 8。
2. 将向量中的每个元素除以绝对值之和,得到归一化后的新向量。
- 第一个元素:1 / 8 = 1/8
- 第二个元素:1 / 8 = 1/8
- 第三个元素:3 / 8 = 3/8
- 第四个元素:-1 / 8 = -1/8
- 第五个元素:2 / 8 = 1/4
因此,向量 (1, 1, 3, -1, 2) 经过L1范数归一化后的结果为 (1/8, 1/8, 3/8, -1/8, 1/4)。每个元素被除以绝对值之和,使得向量的所有元素之和等于1,并且每个元素的比例得到保持。这种归一化方法适用于处理具有不同尺度的特征,并可以用于一些机器学习算法中。
6.2.3 L2
L2正则化(L2 Regularization),也称为岭回归(Ridge Regression)或权重衰减(Weight Decay),是指在损失函数中添加L2范数(平方和)惩罚项。它的作用是使模型的权重(系数)趋向于较小的值,以控制模型的复杂度,并减少不同特征之间的差异。L2正则化对所有权重进行平衡的惩罚,不会将权重压缩至零。L2正则化的数学表达式如下:
L2正则化:![]()
您提供的公式是一种归一化方法,称为L2范数归一化(L2-norm normalization),也被称为最小二乘归一化(Least Squares normalization)或欧几里得归一化(Euclidean normalization)。
该公式用于将向量x的每个元素xi除以所有元素绝对值的平方和的开平方。它的目的是将向量的元素缩放到单位长度,从而使得向量的欧几里得范数(L2范数)等于1。这种归一化方法可以保留向量的方向信息,并且适用于处理具有不同尺度或幅度的特征。
公式解释:
- xi 表示向量x的第i个元素
- |xj|^2 表示向量x的第j个元素的绝对值的平方
- n 表示向量x的维度
计算步骤:
- 对向量x的每个元素xi,计算其绝对值的平方,即|xj|^2
- 计算向量x所有元素绝对值的平方和的开平方,即(Σ|xj|^2)^(1/2)
- 将向量x的每个元素xi除以平方和的开平方(Σ|xj|^2)^(1/2),得到归一化后的新向量x'
这种归一化方法可以用于处理具有不同尺度的特征,使得它们具有相同的单位长度。它常用于机器学习算法中,例如支持向量机(SVM)和神经网络,以提高模型的性能和收敛速度。
需要注意的是,L2范数归一化也会改变向量的原始分布形状,并使得所有元素都在一个较小的范围内,且欧几里得距离相对保持不变。
L1正则化和L2正则化都可以用于控制模型的复杂度,防止过拟合,并提高模型的泛化能力。选择使用哪种正则化方法取决于具体的问题和数据。L1正则化倾向于产生稀疏解,适用于特征选择和降维;而L2正则化倾向于使权重接近于零,适用于控制模型的复杂度。在实际应用中,通常会根据模型的性质和数据的特点选择适当的正则化方法。
6.2.4 L2正规化示例
示例: (1,1,3,-1,2)->L2 ->(1/4,1/4,3/4,-1/4,2/4)
根据上述示例,我们可以对向量进行L2范数归一化(L2-norm normalization)。L2范数归一化是通过将向量的每个元素除以向量的L2范数(即欧几里德范数)来实现的。
计算步骤如下:
1. 计算向量的L2范数,即 sqrt(1^2 + 1^2 + 3^2 + (-1)^2 + 2^2) = sqrt(1 + 1 + 9 + 1 + 4) = sqrt(16) = 4。
2. 将向量中的每个元素除以L2范数,得到归一化后的新向量。
- 第一个元素:1 / 4 = 1/4
- 第二个元素:1 / 4 = 1/4
- 第三个元素:3 / 4 = 3/4
- 第四个元素:-1 / 4 = -1/4
- 第五个元素:2 / 4 = 1/2
因此,向量 (1, 1, 3, -1, 2) 经过L2范数归一化后的结果为 (1/4, 1/4, 3/4, -1/4, 1/2)。通过除以L2范数,每个元素的平方和等于1,并且向量的方向保持不变。L2范数归一化常用于特征向量的归一化,以确保特征在数值上具有可比性,并减小不同尺度特征对模型的影响。
6.3 正规化的用途
正规化(Normalization)在机器学习和数据分析中具有多种用途,包括:
(1) 特征归一化:在特征工程中,正规化常用于将不同尺度或取值范围的特征缩放到相同的范围,以避免某些特征对模型的影响过大。例如,在使用梯度下降等优化算法时,对特征进行归一化可以加快收敛速度,提高模型性能。
(2)数据预处理:在一些机器学习算法中,正规化可以帮助改善数据的分布特性,例如使数据更加接近正态分布、减小偏度或尖峰度等。这有助于提升模型的稳定性和可靠性。
(3)特征表示:对于基于特征矩阵的方法(如文本表示、图像表示等),正规化可用于处理不同特征之间的差异,使得它们在相同的尺度上进行比较和加权。
(4)模型参数正则化:正规化也用于控制模型的复杂度,防止过拟合。例如,在回归模型中,使用L1或L2正则化可以对模型的系数进行惩罚,促使模型更倾向于选择较小的参数值,避免模型对训练数据的过度拟合。
总的来说,正规化在机器学习和数据分析中被广泛应用,可以提高模型性能、改善数据分布、处理特征差异和控制模型复杂度。具体使用时需要根据问题和数据的特点进行选择。
6.4 python归一化示例
import numpy as np
from sklearn.preprocessing import Normalizer
# 创建一个numpy数组
arr = np.array([[1, 1, 3, -1, 2]])
# 使用L1范数进行规范化
normalized_l1 = Normalizer(norm="l1").fit_transform(arr)
print("L1正规化结果:")
print(normalized_l1)
# 使用L2范数进行规范化
normalized_l2 = Normalizer(norm="l2").fit_transform(arr)
print("L2正规化结果:")
print(normalized_l2)
结果分别如下:
L1正规化结果:
[[ 0.125 0.125 0.375 -0.125 0.25 ]]
L2正规化结果:
[[ 0.25 0.25 0.75 -0.25 0.5 ]]
以上代码演示了使用Normalizer类对数组进行规范化(归一化)的过程。
-
对于L1正规化,
norm="l1"指定了使用L1范数进行规范化,即将每个样本的每个特征值除以该样本特征值的绝对值之和。结果中的每个值表示原始值在样本中的相对比例,总和为1。 -
对于L2正规化,
norm="l2"指定了使用L2范数进行规范化,即将每个样本的每个特征值除以该样本特征值的平方和的平方根。结果中的每个值表示原始值在样本中的相对比例,使得每个样本的特征向量的L2范数(欧几里得范数)为1。
通过正规化,可以将原始数据的特征值按照不同的规范化方法进行调整,使其满足一定的标准或要求,例如将特征值映射到0到1的范围内,或者将特征值缩放为单位长度。这样做可以消除特征值之间的差异,使得数据更具可比性和可解释性。