WhoNet报不是有效dbf解决
由于现在Web已经部署到Linux上了,以前在Windows上导出dbf通过oledb执行sql生成dbf的路径已经不可用了,加上需要安装dataaccess驱动也麻烦,为此换了fastdbf生成dbf文件。
首先还算顺利,开始就碰到中文乱码问题,下载源码看代码解决了。最近碰到一个医院导出的dbf在Whonet软件死活就是报不是有效的dbf文件。我自己又用dbfview打开看了也没问题,用wps打开也没问题。当时把问题归结为是他的Whonet软件太老了,可能不支持新点的dbf文件,就没管这个事了。
昨天又有一个医院也是一样的报下图错误:

我就是意识到这应该不是用户环境问题,可能还是新导出方式导出的文件有点差异。但是Whonet的代码对我又是个黑盒,也不可能有开发配合我排查这问题,怎么办呢?
为此进行下面测试缩小范围:
1.在vs运行的Windows网站导出dbf测试,排查是否是Linux环境下的问。
2.测试Windows导出两条没问题,多了有问题后。用wps修改保存后测试是否有问题。
3.wps修改保存后没问题和wps修改后的文件比对,借助notepad++的插件HexEditer比对二进制差异,如下图:

发现少了一个1a结尾字节,还有第二个自己存的年不对。然后从下面sbase官网看dbf文件格式文档:
dbf格式文档

折腾一个下午比较懵,晚上回家又从9点梳理到11点总算理清了:
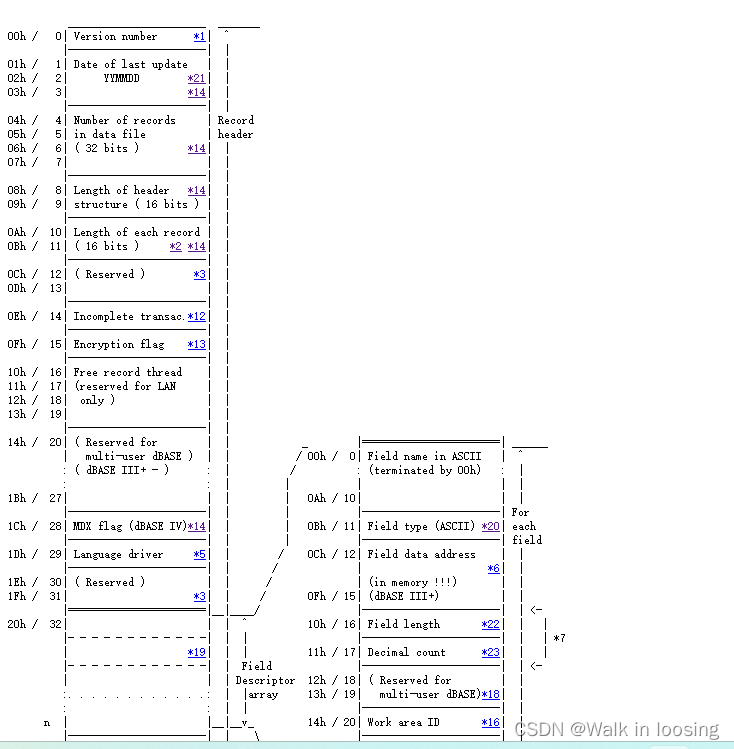
第0个字节表示当前的DBF版本信息(固定就行)
该文件的值是十六进制’03’,表示是FoxBASE+/Dbase III plus, no memo
1~3字节,表示最新的更新日期,按照YYMMDD格式**(FastDBF存的年默认是错误的,算成负数了)**
第一个字节的值 = 保存时的年 - 1900
第二个字节的值 = 保存时的月
第三个字节的值 = 保存时的日
该文件的第一个字节是十六进制74,对应十进制116,116+1900正好等于当前的年2016
第二个字节是十六进制07,对应十进制07,第三个字节是03,正好今天是7月3日
4~7字节,Int32类型,表示DBF文件中有多少条记录
可以看到值是02,正好当前文件确实只有两条记录
8~9,Int16类型,表示当前DBF的文件头占用的字节长度
该文件对应的值是十六进制的A1,对应十进制161
10~11,Int16类型,表示一条记录中的字节长度,即每行数据所占的长度
该文件的值是十六进制数3A,对应十进制的58
创建该文件时,一共4个字段,分别长度是20、8、8、21
计算4个列的长度和是57,比58少1
多出来的一个字节是每条记录最开始的特殊标志字节
12~13,2个字节,保留字节,用于以后添加新的说明性信息时使用,这里用0来填写
14,1个字节,表示未完成的操作
15,1个字节,dBASE IV编密码标记
16~27,12个字节,保留字节用于多用户处理时使用
28,1个字节,DBF文件的MDX标识
创建一个DBF表时,若使用MDX格式的索引文件,则DBF表头中该字节就自动被设置一个标志
当你下次试图重新打开这个DBF表的时候,数据引擎会自动识别这个标识
如果此标示为真,则数据引擎将试图打开相应MDX文件
29,1个字节,页码标记
30~31,2个字节,保留字节,用于以后添加新的说明性信息时使用,这里用0来填写。
32~N(x * 32),这段长度由表格中的列数(即字段数)决定
每个字段的长度为32,如果有x列,则占用的长度为x * 32
这每32个字节里面又按其规则填写每个字段的名称、类型等信息
N+1,1个字节,作为字段定义的终止标志,值为0x0D
然后每个字段的定义是32个字节,0-10存名称,不足的后面设置0.所以DBF列名最长11个字母。11位置存字段的数据类型,C字符、N数字、D日期、B二进制、等。12-15保留字节,用于以后添加新的说明性信息时使用,默认为0。16字段的长度,表示该字段对应的值在后面的记录中所占的长度。17字段的精度。18-19保留字节,用于以后添加新的说明性信息时使用,默认为0。20工作区ID。21-31保留字节,用于以后添加新的说明性信息时使用,默认为0。
所以整体的就是:
03 年 月 日 行 行 行 头 头 总 总 空 空 空 空 空 空 空 空 空 空 空 空 空 空 空 空 空 空 空
1列名称撑到11位 类 空 空 空 空 长 精 空 空 空 空 空 空 空 空 空 空 空 空 空 空
2列名称撑到11位 类 空 空 空 空 长 精 空 空 空 空 空 空 空 空 空 空 空 空 空 空
3列名称撑到11位 类 空 空 空 空 长 精 空 空 空 空 空 空 空 空 空 空 空 空 空 空
4列名称撑到11位 类 空 空 空 空 长 精 空 空 空 空 空 空 空 空 空 空 空 空 空 空
0D标识头结尾
1按列长度组装的数据,如1234列分别为1,8,10,50那么每行数据占69字节,每列字符位数不够后面存0
2按列长度组装的数据,如1234列分别为1,8,10,50那么每行数据占69字节,每列字符位数不够后面存0
3按列长度组装的数据,如1234列分别为1,8,10,50那么每行数据占69字节,每列字符位数不够后面存0
4按列长度组装的数据,如1234列分别为1,8,10,50那么每行数据占69字节,每列字符位数不够后面存0
5按列长度组装的数据,如1234列分别为1,8,10,50那么每行数据占69字节,每列字符位数不够后面存0
6按列长度组装的数据,如1234列分别为1,8,10,50那么每行数据占69字节,每列字符位数不够后面存0
1A结尾符
行的3个字节是int32记录的有多少行数据。
头的两个字节是int16记录的头的长度,从开始到0D的字节数。需要根据有多少列而定,每列定义占32个。长度等于固定长度+列数x32
总的两个自己是int16记录的总的字节长度,从开始到结束。长度等于头长度+行数x所有列长度和
按要求把fastdbf输出不对的部分修复后测试感觉应该好了。然而还是报格式不对,这里就想到把DBF当数据库用列名需要符合表列名要求。既:以字母开头,只能带数字和下划线,长度不能大于11.就把fastdbf的添加列方法按要求卡了一下,再导出测试成功。
修改的类:
DbfFile
///
/// Author: Ahmed Lacevic
/// Date: 12/1/2007
/// Desc: This class represents a DBF file. You can create, open, update and save DBF files using this class and supporting classes.
/// Also, this class supports reading/writing from/to an internet forward only type of stream!
///
/// Revision History:
/// -----------------------------------
/// Author:
/// Date:
/// Desc:
using System;
using System.Collections.Generic;
using System.Text;
using System.IO;
namespace SocialExplorer.IO.FastDBF
{
/// True if read a record was read, otherwise false. If you read end of file false will be returned and oFillRecord will NOT be modified!
/// The parameter record (oFillRecord) must match record size specified by the header and number of columns as well.
/// It does not have to come from the same header, but it must match the structure. We are not going as far as to check size of each field.
/// The idea is to be flexible but safe. It's a fine balance, these two are almost always at odds.
///
public bool Read(long index, DbfRecord oFillRecord)
{
//check if we can fill this record with data. it must match record size specified by header and number of columns.
//we are not checking whether it comes from another DBF file or not, we just need the same structure. Allow flexibility but be safe.
if (oFillRecord.Header != _header && (oFillRecord.Header.ColumnCount != _header.ColumnCount || oFillRecord.Header.RecordLength != _header.RecordLength))
throw new Exception("Record parameter does not have the same size and number of columns as the " +
"header specifies, so we are unable to read a record into oFillRecord. " +
"This is a programming error, have you mixed up DBF file objects?");
//DBF file reader can be null if stream is not readable...
if (_dbfFileReader == null)
throw new Exception("ReadStream is null, either you have opened a stream that can not be " +
"read from (a write-only stream) or you have not opened a stream at all.");
//move to the specified record, note that an exception will be thrown is stream is not seekable!
//This is ok, since we provide a function to check whether the stream is seekable.
long nSeekToPosition = _header.HeaderLength + (index * _header.RecordLength);
//check whether requested record exists. Subtract 1 from file length (there is a terminating character 1A at the end of the file)
//so if we hit end of file, there are no more records, so return false;
if (index < 0 || _dbfFile.Length - 1 <= nSeekToPosition)
return false;
//move to record and read
_dbfFile.Seek(nSeekToPosition, SeekOrigin.Begin);
//read the record
bool bRead = oFillRecord.Read(_dbfFile);
if (bRead)
oFillRecord.RecordIndex = index;
return bRead;
}
public bool ReadValue(int rowIndex, int columnIndex, out string result)
{
result = String.Empty;
DbfColumn ocol = _header[columnIndex];
//move to the specified record, note that an exception will be thrown is stream is not seekable!
//This is ok, since we provide a function to check whether the stream is seekable.
long nSeekToPosition = _header.HeaderLength + (rowIndex * _header.RecordLength) + ocol.DataAddress;
//check whether requested record exists. Subtract 1 from file length (there is a terminating character 1A at the end of the file)
//so if we hit end of file, there are no more records, so return false;
if (rowIndex < 0 || _dbfFile.Length - 1 <= nSeekToPosition)
return false;
//move to position and read
_dbfFile.Seek(nSeekToPosition, SeekOrigin.Begin);
//read the value
byte[] data = new byte[ocol.Length];
_dbfFile.Read(data, 0, ocol.Length);
result = new string(encoding.GetChars(data, 0, ocol.Length));
return true;
}
/// Null if record can not be read, otherwise returns a new record.
public DbfRecord Read(long index)
{
//create a new record and fill it.
DbfRecord orec = new DbfRecord(_header);
return Read(index, orec) ? orec : null;
}
/// DbfHeader
///
/// Author: Ahmed Lacevic
/// Date: 12/1/2007
/// Desc:
///
/// Revision History:
/// -----------------------------------
/// Author:
/// Date:
/// Desc:
using System;
using System.Collections.Generic;
using System.Text;
using System.IO;
namespace SocialExplorer.IO.FastDBF
{
/// column index (0 based) or -1 if not found.
public int FindColumn(string sName)
{
if (_columnNameIndex == null)
{
_columnNameIndex = new Dictionary<string, int>(_fields.Count);
//create a new index
for (int i = 0; i < _fields.Count; i++)
{
_columnNameIndex.Add(_fields[i].Name.ToUpper(), i);
}
}
int columnIndex;
if (_columnNameIndex.TryGetValue(sName.ToUpper(), out columnIndex))
return columnIndex;
return -1;
}
/// 耗时快一天,开心的解决Whonet导出失败的难题,对DBF的文件格式算是熟了 20230613 zlz