ClickHouse实时分析(四)- ClickHouse表引擎详解
目录
- 1. 表引擎的使用
- 2. 日志引擎系列
-
- 2.1 TinyLog
- 2.2 Log
- 2.3 StripeLog
- 3. MergeTree引擎系列
-
- 3.1 MergeTree
-
- 3.1.1 partition by分区(可选)
- 3.1.2 primary key 主键(可选)
- 3.1.3 order by(必选)
- 3.1.4 列和表的TTL
- 3.2 AggregatingMergeTree
- 3.3 CollapsingMergeTree
- 3.4 ReplacingMergeTree
- 3.5 SummingMergeTree
- 4. 集成的表引擎
- 5. 用于其他特定功能的引擎
- 6. 虚拟列
- 参考文献
原文地址:https://program-park.github.io/2022/03/23/clickhouse_4/
1. 表引擎的使用
表引擎是 ClickHouse 的一大特色。可以说,表引擎决定了如何存储表的数据。包括:
- 数据的存储方式和位置,写到哪里以及从哪里读取数据
- 支持哪些查询以及如何支持。
- 并发数据访问。
- 索引的使用(如果存在)。
- 是否可以执行多线程请求。
- 数据复制参数。
表引擎的使用方式就是必须显式在创建表时定义该表使用的引擎,以及引擎使用的相关参数。
特别注意:引擎的名称大小写敏感。
2. 日志引擎系列
这些引擎是为了需要写入许多小数据量(少于一百万行)的表的场景而开发的。包括下面这些:
- StripeLog
- Log
- TinyLog
共同特点:
- 数据存储在磁盘上;
- 写入时将数据追加在文件末尾;
- 不支持突变操作;
- 不支持索引;
- 这意味着
SELECT在范围查询时效率不高;
- 这意味着
- 非原子地写入数据;
- 如果某些事情破坏了写操作,例如服务器的异常关闭,你将会得到一张包含了损坏数据的表;
不同点:
Log和StripeLog引擎支持:
- 并发访问数据的锁;
INSERT请求执行过程中表会被锁定,并且其他的读写数据的请求都会等待直到锁定被解除。如果没有写数据的请求,任意数量的读请求都可以并发执行;
- 并行读取数据;
- 在读取数据时,ClickHouse 使用多线程。 每个线程处理不同的数据块;
Log引擎为表中的每一列使用不同的文件。StripeLog将所有的数据存储在一个文件中。因此StripeLog引擎在操作系统中使用更少的描述符,但是Log引擎提供更高的读性能。
TinyLog引擎是该系列中最简单的引擎并且提供了最少的功能和最低的性能。TinyLog引擎不支持并行读取和并发数据访问,并将每一列存储在不同的文件中。它比其余两种支持并行读取的引擎的读取速度更慢,并且使用了和Log引擎同样多的描述符。你可以在简单的低负载的情景下使用它。
2.1 TinyLog
最简单的表引擎,用于将数据存储在磁盘上。每列都存储在单独的压缩文件中。写入时,数据将附加到文件末尾。
并发数据访问不受任何限制:
- 如果同时从表中读取并在不同的查询中写入,则读取操作将抛出异常;
- 如果同时写入多个查询中的表,则数据将被破坏;
这种表引擎的典型用法是 write-once:首先只写入一次数据,然后根据需要多次读取。查询在单个流中执行。换句话说,此引擎适用于相对较小的表(建议最多 1,000,000 行)。如果您有许多小表,则使用此表引擎是适合的,因为它比Log引擎更简单(需要打开的文件更少)。当您拥有大量小表时,可能会导致性能低下,但在可能已经在其它 DBMS 时使用过,则您可能会发现切换使用TinyLog类型的表更容易。不支持索引。
一般保存少量数据的小表, 生产环境上作用有限。可以用于平时练习测试用。
在 Yandex.Metrica 中,TinyLog 表用于小批量处理的中间数据。
2.2 Log
Log与TinyLog的不同之处在于,标记的小文件与列文件存在一起。这些标记写在每个数据块上,并且包含偏移量,这些偏移量指示从哪里开始读取文件以便跳过指定的行数。这使得可以在多个线程中读取表数据。对于并发数据访问,可以同时执行读取操作,而写入操作则阻塞读取和其它写入。Log引擎不支持索引。同样,如果写入表失败,则该表将被破坏,并且从该表读取将返回错误。Log引擎适用于临时数据,write-once 表以及测试或演示目的。
2.3 StripeLog
StripeLog的介绍前面已经说过了,在需要写入许多小数据量(小于一百万行)的表的场景下使用这个引擎。
对表的操作这里就不说了,感兴趣可以在官方文档中看:https://clickhouse.com/docs/zh/engines/table-engines/log-family/stripelog/
3. MergeTree引擎系列
适用于高负载任务的最通用和功能最强大的表引擎。这些引擎的共同特点是可以快速插入数据并进行后续的后台数据处理。 MergeTree 系列引擎支持数据复制(使用 Replicated* 的引擎版本),分区和一些其他引擎不支持的其他功能。
该系列的引擎有:
- MergeTree
- ReplacingMergeTree
- SummingMergeTree
- AggregatingMergeTree
- CollapsingMergeTree
- VersionedCollapsingMergeTree
- GraphiteMergeTree
3.1 MergeTree
Clickhouse 中最强大的表引擎当属MergeTree(合并树)引擎及该系列中的其他引擎。支持索引和分区,地位可以相当于 innodb 之于 Mysql。而且基于 MergeTree, 还衍生出了很多小弟,也是非常有特色的引擎。
MergeTree系列的引擎被设计用于插入极大量的数据到一张表当中。数据可以以数据片段的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合并。相比在插入时不断修改(重写)已存储的数据,这种策略会高效很多。
主要特点:
- 存储的数据按主键排序;
- 这使得您能够创建一个小型的稀疏索引来加快数据检索;
- 如果指定了 分区键 的话,可以使用分区;
- 在相同数据集和相同结果集的情况下 ClickHouse 中某些带分区的操作会比普通操作更快。查询中指定了分区键时 ClickHouse 会自动截取分区数据。这也有效增加了查询性能;
- 支持数据副本;
- ReplicatedMergeTree 系列的表提供了数据副本功能。更多信息,请参阅 数据副本 一节;
- 支持数据采样;
- 需要的话,您可以给表设置一个采样方法;
建表语句:
create table t_order_mt(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
插入数据:
insert into t_order_mt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');
MergeTree 其实还有很多参数(绝大多数用默认值即可),但是三个参数是更加重要的, 也涉及了关于 MergeTree 的很多概念。
3.1.1 partition by分区(可选)
- 作用:
- 和 hive 一样,分区的目的主要是降低扫描的范围,优化查询速度;
- 如果不填,只会使用一个分区;
- 分区目录:
- MergeTree 是以列文件+索引文件+表定义文件组成的,但是如果设定了分区那么这些文件就会保存到不同的分区目录中;
- 并行:
- 分区后,面对涉及跨分区的查询统计,ClickHouse 会以分区为单位并行处理;
- 数据写入与分区合并:
- 任何一个批次的数据写入都会产生一个临时分区,不会纳入任何一个已有的分区。写入后的某个时刻(大概 10-15 分钟后),ClickHouse 会自动执行合并操作(等不及也可以手动通过 optimize 执行),把临时分区的数据,合并到已有分区中。
optimize table xxxx final;
- 例如:
- 再次执行上面的插入操作,查看数据并没有纳入任何分区;
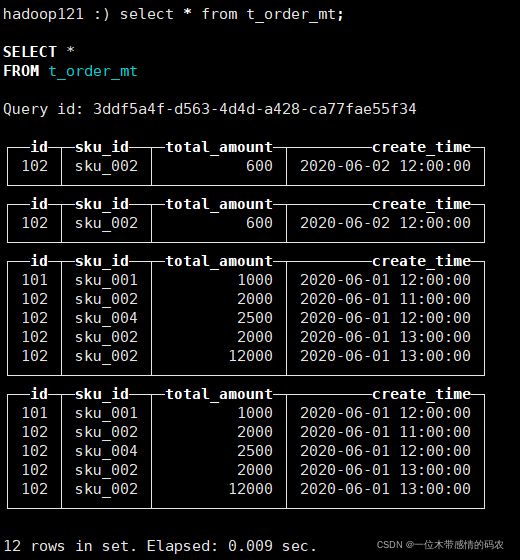
手动 optimize 之后,optimize table t_order_mt final;,再次查询:
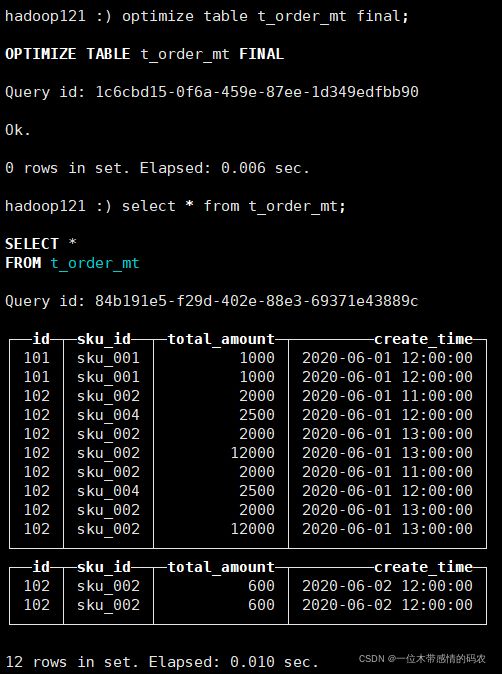
- 再次执行上面的插入操作,查看数据并没有纳入任何分区;
3.1.2 primary key 主键(可选)
ClickHouse 中的主键,和其他数据库不太一样,它只提供了数据的一级索引,但是却不是唯一约束。这就意味着是可以存在相同 primary key 的数据的。
主键的设定主要依据是查询语句中的 where 条件。
根据条件通过对主键进行某种形式的二分查找,能够定位到对应的 index granularity,避免了全表扫描。
index granularity: 直接翻译的话就是索引粒度,指在稀疏索引中两个相邻索引对应数据的间隔。ClickHouse 中的 MergeTree 默认是 8192。官方不建议修改这个值,除非该列存在大量重复值,比如在一个分区中几万行才有一个不同数据。
稀疏索引:
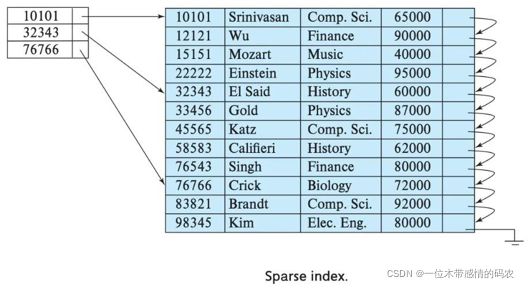
稀疏索引的好处就是可以用很少的索引数据,定位更多的数据,代价就是只能定位到索引粒度的第一行,然后再进行进行一点扫描。
3.1.3 order by(必选)
order by 设定了分区内的数据按照哪些字段顺序进行有序保存。
order by 是 MergeTree 中唯一一个必填项,甚至比 primary key 还重要,因为当用户不设置主键的情况,很多处理会依照 order by 的字段进行处理(比如后面会讲的去重和汇总)。
要求:主键必须是 order by 字段的前缀字段。
比如 order by 字段是 (id,sku_id) 那么主键必须是 id 或者(id,sku_id)。
3.1.4 列和表的TTL
TTL用于设置值的生命周期,它既可以为整张表设置,也可以为每个列字段单独设置。表级别的 TTL 还会指定数据在磁盘和卷上自动转移的逻辑。
详细介绍可以参考官网,这里就不细说了:https://clickhouse.com/docs/zh/engines/table-engines/mergetree-family/mergetree/#table_engine-mergetree-ttl
3.2 AggregatingMergeTree
该引擎继承自MergeTree,并改变了数据片段的合并逻辑。 ClickHouse 会将一个数据片段内所有具有相同主键(准确的说是排序键)的行替换成一行,这一行会存储一系列聚合函数的状态。
可以使用AggregatingMergeTree表来做增量数据的聚合统计,包括物化视图的数据聚合。
引擎使用以下类型来处理所有列:
- AggregateFunction
- SimpleAggregateFunction
AggregatingMergeTree适用于能够按照一定的规则缩减行数的情况。
详细操作可参考官方文档:https://clickhouse.com/docs/zh/engines/table-engines/mergetree-family/aggregatingmergetree/
3.3 CollapsingMergeTree
该引擎继承于MergeTree,并在数据块合并算法中添加了折叠行的逻辑。
CollapsingMergeTree会异步的删除(折叠)这些除了特定列 Sign 有 1 和 -1 的值以外,其余所有字段的值都相等的成对的行。没有成对的行会被保留。
因此,该引擎可以显著的降低存储量并提高 SELECT 查询效率。
详细操作可参考官方文档:https://clickhouse.com/docs/zh/engines/table-engines/mergetree-family/collapsingmergetree/
3.4 ReplacingMergeTree
ReplacingMergeTree是MergeTree的一个变种,它存储特性完全继承MergeTree,只是多了一个去重的功能。 尽管MergeTree可以设置主键,但是 primary key 其实没有唯一约束的功能。
ReplacingMergeTree和MergeTree的不同之处在于它会删除排序键值相同的重复项。
- 去重时机:
- 数据的去重只会在数据合并期间进行。合并会在后台一个不确定的时间进行,因此你无法预先作出计划。有一些数据可能仍未被处理。尽管你可以调用 OPTIMIZE 语句发起计划外的合并,但请不要依靠它,因为 OPTIMIZE 语句会引发对数据的大量读写;
- 去重范围:
- 如果表经过了分区,去重只会在分区内部进行去重,不能执行跨分区的去重;
因此,ReplacingMergeTree适用于在后台清除重复的数据以节省空间,但是它不保证没有重复的数据出现。
更多操作可参考官网:https://clickhouse.com/docs/zh/engines/table-engines/mergetree-family/replacingmergetree/
3.5 SummingMergeTree
该引擎继承自MergeTree。区别在于,当合并SummingMergeTree表的数据片段时,ClickHouse 会把所有具有相同主键的行合并为一行,该行包含了被合并的行中具有数值数据类型的列的汇总值。如果主键的组合方式使得单个键值对应于大量的行,则可以显著的减少存储空间并加快数据查询的速度。
ClickHouse 为了这种场景,提供了一种能够 “预聚合” 的引擎SummingMergeTree。
我们推荐将该引擎和MergeTree一起使用。例如,在准备做报告的时候,将完整的数据存储在MergeTree表中,并且使用SummingMergeTree来存储聚合数据。这种方法可以使你避免因为使用不正确的主键组合方式而丢失有价值的数据。
更多操作可参考官网:https://clickhouse.com/docs/zh/engines/table-engines/mergetree-family/summingmergetree/
4. 集成的表引擎
ClickHouse 提供了多种方式来与外部系统集成,包括表引擎。像所有其他的表引擎一样,使用 CREATE TABLE 或 ALTER TABLE 查询语句来完成配置。然后从用户的角度来看,配置的集成看起来像查询一个正常的表,但对它的查询是代理给外部系统的。这种透明的查询是这种方法相对于其他集成方法的主要优势之一,比如外部字典或表函数,它们需要在每次使用时使用自定义查询方法。
以下是支持的集成方式:
- ODBC
- JDBC
- MySQL
- MongoDB
- HDFS
- S3
- Kafka
- EmbeddedRocksDB
- RabbitMQ
- PostgreSQL
- SQLite
- Hive
感兴趣的可自行去官网查看:https://clickhouse.com/docs/zh/engines/table-engines/integrations/
5. 用于其他特定功能的引擎
该类型的引擎:
- Distributed
- MaterializedView
- Dictionary
- Merge
- File
- Null
- Set
- Join
- URL
- View
- Memory
- Buffer
感兴趣的可自行去官网查看:https://clickhouse.com/docs/zh/engines/table-engines/#yong-yu-qi-ta-te-ding-gong-neng-de-yin-qing
6. 虚拟列
虚拟列是表引擎组成的一部分,它在对应的表引擎的源代码中定义。
您不能在 CREATE TABLE 中指定虚拟列,并且虚拟列不会包含在 SHOW CREATE TABLE 和 DESCRIBE TABLE 的查询结果中。虚拟列是只读的,所以您不能向虚拟列中写入数据。
如果想要查询虚拟列中的数据,您必须在 SELECT 查询中包含虚拟列的名字。SELECT * 不会返回虚拟列的内容。
若您创建的表中有一列与虚拟列的名字相同,那么虚拟列将不能再被访问。我们不建议您这样做。为了避免这种列名的冲突,虚拟列的名字一般都以下划线开头。
参考文献
【1】https://clickhouse.com/docs/zh/
【2】https://www.bilibili.com/video/BV1Yh411z7os?from=search&seid=4579023877699743987&spm_id_from=333.337.0.0