《Mybatis使用篇1》——只为使用,一篇足以
目录
快速入门系列
概述mybatis是什么?有什么特点?
前置工作
一,引入log4j
1.为什么要引入log4j
编辑 2.如何引入log4j
1.导入log4j依赖
2.创建log4j.properties配置文件详解 (不要改文件名字)
3.在mybatis全局配置文件中引入
二,mybatis的输入输出
1.mybatis的SQL传参
1.#{}(使用的最多,有利于防止sql注入)
2.${}(不安全)
2.mybatis输入
1.单个参数
2.实体类型参数
3.两个以上的简单类型的数据
4.Map类型的数据输入
总结
3.mybatis输入
1.返回单个简单类型数据
2.返回实体类型
3.返回Map类型
4.返回List数据
5.返回自增主键
6、数据库表字段和实体类属性对应关系
总结
快速入门系列
https://blog.csdn.net/weixin_64972949/article/details/130945007?spm=1001.2014.3001.5502
概述
mybatis是什么?有什么特点?
它是一款半自动的ORM持久层框架,具有较高的SQL灵活性,支持高级映射(一对一,一对多),动态SQL,延迟加载和缓存等特性,但它的数据库无关性较低
什么是ORM?
Object Relation Mapping,对象关系映射。对象指的是Java对象,关系指的是数据库中的关系模型,对象关系映射,指的就是在Java对象和数据库的关系模型之间建立一种对应关系,比如用一个Java的Student类,去对应数据库中的一张student表,类中的属性和表中的列一一对应。Student类就对应student表,一个Student对象就对应student表中的一行数据
为什么mybatis是半自动的ORM框架?
用mybatis进行开发,需要手动编写SQL语句。而全自动的ORM框架,如hibernate,则不需要编写SQL语句。用hibernate开发,只需要定义好ORM映射关系,就可以直接进行CRUD操作了。由于mybatis需要手写SQL语句,所以它有较高的灵活性,可以根据需要,自由地对SQL进行定制,也因为要手写SQL,当要切换数据库时,SQL语句可能就要重写,因为不同的数据库有不同的方言(Dialect),所以mybatis的数据库无关性低。虽然mybatis需要手写SQL,但相比JDBC,它提供了输入映射和输出映射,可以很方便地进行SQL参数设置,以及结果集封装。并且还提供了关联查询和动态SQL等功能,极大地提升了开发的效率。并且它的学习成本也比hibernate低很多
前置工作
首先,准备三张表,分别为emp3,t_customer,t_order。
emp3:
DROP TABLE IF EXISTS `emp3`;
CREATE TABLE `emp3` (
`emp_id` int(0) NOT NULL AUTO_INCREMENT,
`wkname` varchar(10) CHARACTER SET utf32 COLLATE utf32_general_ci NULL DEFAULT NULL,
`address` varchar(50) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NULL DEFAULT 'Unknown',
`job_id` int(0) NULL DEFAULT 0,
PRIMARY KEY (`emp_id`) USING BTREE,
INDEX `emp_name_index`(`wkname`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb3 COLLATE = utf8mb3_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of emp3
-- ----------------------------
INSERT INTO `emp3` VALUES (1, '张三', '衡阳', 12);
INSERT INTO `emp3` VALUES (2, '李四', '郴州', 13);
INSERT INTO `emp3` VALUES (3, '王五', '岳阳', 14);
SET FOREIGN_KEY_CHECKS = 1;t_order&t_customer
CREATE TABLE `t_customer` (`customer_id` INT NOT NULL AUTO_INCREMENT, `customer_name` CHAR(100), PRIMARY KEY (`customer_id`) );
CREATE TABLE `t_order` ( `order_id` INT NOT NULL AUTO_INCREMENT, `order_name` CHAR(100), `customer_id` INT, PRIMARY KEY (`order_id`) );
INSERT INTO `t_customer` (`customer_name`) VALUES ('c01');
INSERT INTO `t_order` (`order_name`, `customer_id`) VALUES ('o1', '1');
INSERT INTO `t_order` (`order_name`, `customer_id`) VALUES ('o2', '1');
INSERT INTO `t_order` (`order_name`, `customer_id`) VALUES ('o3', '1'); 一,引入log4j
1.为什么要引入log4j
首先为什么要引入log4j,先给大家看一个例子,在mybatis全局配置文件中,我将引入log4j的
先注释掉。

然后,我们再随便执行我们的一个测试方法 ,我们会发现,控制台打印了一堆我们看不懂的东西(这是因为我之前引入了SLF4J和logback日志显示,这两个东西有利于我们知道是哪里在报错,如果不引入,信息会更少)。
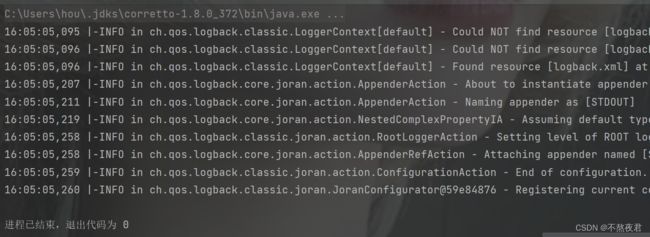
之后,我们在将注释取消,再执行同样的测试方法。我们会发现在控制台上有许多对我们有用的信息,最重要的就是它可以显示你当前执行的sql语句,和你传入的参数。这两个信息在我们调试方法的时候是非常有用的。所以我们引入log4j日志是十分有必要的。
 2.如何引入log4j
2.如何引入log4j
1.导入log4j依赖
log4j
log4j
1.2.12
2.创建log4j.properties配置文件详解 (不要改文件名字)
#将等级为DEBUG的日志信息输出到console和file这两个目的地,console和file的定义
log4j.rootLogger=DEBUG,console,file
#控制台输出的相关设置
log4j.appender.console = org.apache.log4j.ConsoleAppender
log4j.appender.console.Target = System.out
log4j.appender.console.Threshold=DEBUG
log4j.appender.console.layout = org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=[%c]-%m%n
#文件输出的相关设置
log4j.appender.file = org.apache.log4j.RollingFileAppender
log4j.appender.file.File=./log/fanlan.log
log4j.appender.file.MaxFileSize=10mb
log4j.appender.file.Threshold=DEBUG
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=[%p][%d{yyyy-MM-dd HH:mm:ss}][%c]%m%n
#日志输出级别
log4j.logger.org.mybatis=DEBUG
log4j.logger.java.sql=DEBUG
log4j.logger.java.sql.Statement=DEBUG
log4j.logger.java.sql.ResultSet=DEBUG
log4j.logger.java.sql.PreparedStatement=DEBUG3.在mybatis全局配置文件中引入
注意:在全局配置文件中配置信息的顺序是固定的,不可以随便改动。如下图,按照这张图的顺序去书写我们的配置信息。不然的话,就会报错。

大家可以参考一下,我的全局配置文件。注意:这里我导入了外部的jdbc.properties配置文件,至于properties配置文件我就不多讲了。
工程目录结构如下图:

二,mybatis的输入输出
1.mybatis的SQL传参
1.#{}(使用的最多,有利于防止sql注入)
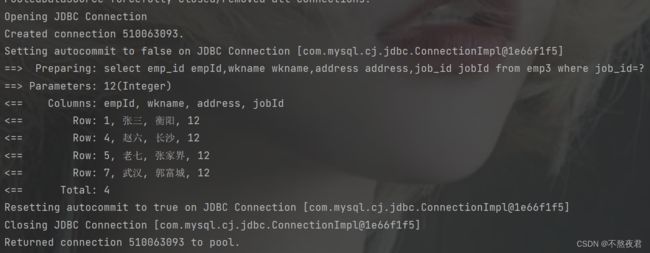
首先,调用查询方法,查询empId=1的员工。

对应的sql语句。
可以看到,#{}在mybatis中,最后会被解析为?,其实就是Jdbc的PreparedStatement中的?占位符,它有预编译的过程,会对输入参数进行类型解析(如果入参是String类型,设置参数时会自动加上引号),可以防止SQL注入,如果parameterType属性指定的入参类型是简单类型的话(简单类型指的是8种java原始类型再加一个String),#{}中的变量名可以任意。
2.${}(不安全)
将上面的sql语句改为。
然后,在执行相同的方法,我们发现${}在底层为我们做的是字符串拼接 ,熟悉sql注入的就知道,字符串拼接就是一个大坑。

2.mybatis输入
1.单个参数
int deleteEmpolyeeById(Integer empId);对应sql
delete from emp3 where emp_id=#{empId}
当只有一个参数的时候,直接传就好,但是注意 :sql语句中写字段名,#{}中写对应的属性名
单个简单类型参数,在#{}中可以随意命名,但是没有必要。通常还是使用和接口方法参数同名。
2.实体类型参数
int updateEmpolyeeById(Empolyee empolyee);对应sql
update emp3 set wkname=#{wkname},address=#{address}
where emp_id=#{empId}
Mybatis会根据#{}中传入的数据,加工成getXxx()方法,通过反射在实体类对象中调用这个方法,从而获取到对应的数据。填充到#{}解析后的问号占位符这个位置。所以,使用实体类型数据的时候,#{}中的名字不可以自定义,不然无法通过getXxx()方法获取的值。
3.两个以上的简单类型的数据
int updateEmployee(@Param("empId") Integer empId,@Param("empSalary") Double empSalary);sql
update t_emp set emp_salary=#{empSalary} where emp_id=#{empId}
零散的多个简单类型参数,如果没有特殊处理,那么Mybatis无法识别自定义名称,所以我们需要使用@Param注解去标记。
4.Map类型的数据输入
int updateEmployeeByMap(Map paramMap); sql
update t_emp set emp_salary=#{empSalaryKey} where emp_id=#{empIdKey}
#{}写上Map中的Key值,就可以取出数据给到sql,语句中。
总结
1.对于单个简单类型的参数,在#{}中我们可以自定义他的名字,但是通常还是使用和接口方法参数同名。
2.对于实体类型参数,Mybatis会根据#{}中传入的数据,加工成getXxx()方法,通过反射在实体类对象中调用这个方法,从而获取到对应的数据。填充到#{}解析后的问号占位符这个位置
3.对于两个以上的简单的参数,我们需要使用@Param注解,不然mybatis无法识别
4.对于Map类型的数据,#{}中写Map中的key
3.mybatis输入
1.返回单个简单类型数据
int selectEmpCount();sql
Mybatis 内部给常用的数据类型设定了很多别名。 以 int 类型为例,可以写的名称有:int、integer、Integer、java.lang.Integer、Int、INT、INTEGER 等等。
2.返回实体类型
Empolyee selectEmpolyee(Integer empId);
sql
返回实体类型的时候,我们只需要将resultType设置成对应的实体类的全类名就好。
3.返回Map类型
Map selectEmpNameAndMaxJobId(); sql
如下图,通过下面运行产生的日志文件,我们可以知道,返回的Map数据的Key值是字段名,而Value值就是查询出来的内容,比如说(”job_id“,"16")。

4.返回List数据
适用于SQL查询返回的各个字段综合起来并不和任何一个现有的实体类对应,没法封装到实体类对象中。能够封装成实体类类型的,就不使用Map类型。
List selectAll(); sql
这里的resultType照样是写我们List集合中的元素的全类名
5.返回自增主键
通常我们会将数据库表的主键id设为自增。在插入一条记录时,我们不设置其主键id,而让数据库自动生成该条记录的主键id,那么在插入一条记录后,如何得到数据库自动生成的这条记录的主键id呢?有两种方式
1.使用useGeneratedKeys和keyProperty属性(要求数据库支持自增主键,比如说Mysql)
insert into t_emp(emp_name,emp_salary)
values(#{empName},#{empSalary})
注意:Mybatis是将自增主键的值设置到实体类对象中,而不是以Mapper接口方法返回值的形式返回。
2.使用子标签(用于不支持自增主键的数据库,比如说Oracle)
select employee_seq.nextval from dual
insert into orcl_employee(id,last_name,email,gender) values(#{id},#{lastName},#{email},#{gender})
6、数据库表字段和实体类属性对应关系
1.别名
将字段的别名设置成和实体类属性一致。
就比如我们在写select语句的时候,我们在字段名后面写上实体类的属性名。
2.全局配置自动识别驼峰式命名规则
在Mybatis全局配置文件加入如下配置:
注意:加的时候依然要注意写的顺序
如果加了这个配置,那么你的select语句中就不用再去写别名了,但是前提是你的属性名和数据库中的字段名都需要符合命名规则:
比如说在数据库中字段名是emp_id,而属性名就是empId,其实就是将下划线后面的一个字母大写就好了。
3.使用resultMap
使用resultMap标签定义对应关系,再在后面的SQL语句中引用这个对应关系

总结
1.返回简单类型的数据时,比如说int数据类型,你可以在resultType中写名称有:int、integer、Integer、java.lang.Integer、Int、INT、INTEGER。
2.返回实体类型的数据的时候,直接在resultType中写上实体类型的全类名。
3.返回Map类型的数据的时候,返回的Map数据的Key值是字段名,而Value值就是查询出来的内容,比如说(”job_id“,"16")。
4.返回List数据的时候,resultType照样是写我们List集合中的元素的全类名。
5.返回自增主键时,有两种方式,一种使用useGeneratedKeys和keyProperty属性适用于可自增主键的数据库——Mysql,还有一种使用selectKey标签适用于不可自增主键的数据库——Oracle。
6.数据库表字段和实体类属性对应关系,有三种方式——1.别名,2.自动匹配,3.使用resltMap进行绑定,只要实现其中的一种方式就可以了。
最后
本篇博客最Mybatis的介绍就到这里了,如果本篇博客对你的有帮助的话,请点一个小赞支持一下,谢谢!本系列还有2.3.4 。。。(感觉写太长了,没人看,也不好把握,所以就分开写吧!)
咱们下篇博客再见!