python--英文文章单词数量统计
目的:从txt文件中读取英文文章数据,并对出现的英文单词数量进行统计,将结果整体保存在一个新的txt文件中,并将单词数量排行前50的单词直接展示出来
# coding:UTF-8
try:
#将txt文件和当前py文件放在一个目录下,正确输入文件名称
fp=open("[英文]绿野仙踪(英文版).txt",mode='r',encoding='UTF-8')
#进行文件的读取,将读取的文件内容返回到一个列表str1中
str1=fp.readlines()
fp.close()
except FileNotFoundError:
print("打开文件错误,请重新检查文件")
else:
print("文件打开成功!")
#将列表中的第一个元素存到一个字符串str2中
str2=''
for i in str1:
str2+=i
#创建一个字典
str3=[]
#将字符串中的各种标点符号转换为空格
for i in '"".,;/?:!@#$%^&*()_-=+][{}`~\|1234567890':
str2 = str2.replace(i, " ")
str2=str2.lower()
#以空格分割字符串中的内容,同时返回一个列表
str2=str2.split()
dict1={}
for i in str2:
dict1[i]=str2.count(i)
#直接使用字典转换后的元组作为迭代对象)
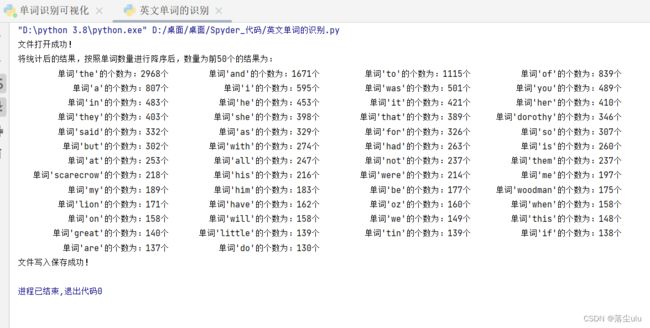
print('将统计后的结果,按照单词数量进行降序后,数量为前50个的结果为:')
list1=sorted(dict1.items(),key=lambda x:x[1],reverse=True)
for i in range(0, 50):
if (i % 4 == 0 and i!=0):
print()
try:
print((15-len(list1[i][0])-len(str(list1[i][1])))*" "+"单词'"+list1[i][0]+"'的个数为:"+str(list1[i][1])+"个",end='')
except ValueError:
print('发生错误,错误为:字符串下标大于或等于字符串的长度')
#将结果保存到一个新的文件中
try:
f = open('test1.txt',mode='w',encoding='UTF-8')
for i in range(0,len(list1)):
if (i % 4 == 0 and i!=0):
f.write('\n')
f.write((13-len(list1[i][0])-len(str(list1[i][1])))*" "+"单词'"+list1[i][0]+"'的个数为:"+str(list1[i][1])+"个")
f.close()
except FileNotFoundError:
print("打开文件错误,请重新检查文件")
else:
print("\n文件写入保存成功!")
统计结果展示:
统计结果保存在文件中: