MapReduce基础
函数式编程概念
MapReduce程序是设计用来并行计算大规模海量数据的,这需要把工作流分划到大量的机器上去,如果组件(component)之间可以任意的共享数据,那这个模型就没法扩展到大规模集群上去了(数百或数千个节点),用来保持节点间数据的同步而产生的通信开销会使得系统在大规模集群上变得不可靠和效率低下。
实际上,所有在MapReduce上的数据元素都是不可变的,这就意味着它们不能够被更新。如果在一个mapping任务中你改变了一个输入键值对,它并不会反馈到输入文件;节点间的通信只在产生新的输出键值对((key,value)pairs)时发生,Hadoop系统会把这些输出传到下一个执行阶段。
列表处理(List Processing)
从概念上讲,MapReduce程序转变输入数据元素列表成输出数据元素列表。一个MapReduce程序会重复这个步骤两次,并用两个不同的术语描述:map和reduce,这些术语来自于列表处理语言,如:LISP,Scheme,或ML。
Mapping数据列表(Lists)
MapReduce程序的第一步叫做mapping,在这一步会有一些数据元素作为Mapper函数的输入数据,每次一个,Mapper会把每次map得到的结果单独的传到一个输出数据元素里。

图4.1 Mapping通过对输入数据列表中的每一个元素应用一个函数创建了一个新的输出数据列表
这里举一个map功能的例子:假设你有一个函数toUpper(str),用来返回输入字符串的大写版本。你可以在map中使用这个函数把常规字符串列表转换成大写的字符串列表。注意,在这里我们并没有改变输入字符串:我们返回了一个新的字符串,它是新的输出列表的组成部分之一。
Reducing数据列表(Lists)
Reducing可以让你把数据聚集在一起。reducer函数接收来自输入列表的迭代器,它会把这些数据聚合在一起,然后返回一个输出值。

图4.2 通过列表迭代器对输入数据进行reducing操作来输出聚合结果。
Reducing一般用来生成”总结“数据,把大规模的数据转变成更小的总结数据。比如,"+"可以用来作一个reducing函数,去返回输入数据列表的值的总和。
把它们一起放在MapReduce中
Hadoop的MapReduce框架使用了上面的那些概念并用它们来处理大规模的数据信息。MapReduce程序有着两个组件:一个实现了mapper,另一个实现了reducer。上面描叙的Mapper和Reducer术语在Hadoop中有了更细微的扩展,但基本的概念是相同的。
键和值:在MapReduce中,没有一个值是单独的,每一个值都会有一个键与其关联,键标识相关的值。举个例子,从多辆车中读取到的时间编码车速表日志可以由车牌号码标识,就像下面一样:
AAA-123 65mph, 12:00pm
ZZZ-789 50mph, 12:02pm
AAA-123 40mph, 12:05pm
CCC-456 25mph, 12:15pm
...
mapping和reducing函数不是仅接收数值(Values),而是(键,值)对。这些函数的每一个输出都是一样的:都是一个键和一个值,它们将被送到数据流的下一个列表。
对于Mapper和Reducer是如何工作的,MapReduce没有像其它语言那样严格。在更正式的函数式mapping和reducing设置中,mapper针对每一个输入元素都要生成一个输出元素,reducer针对每一个输入列表都要生成一个输出元素。但在MapReduce中,每一个阶段都可以生成任意的数值;mapper可能把一个输入map为0个,1个或100个输出。reducer可能计算超过一个的输入列表并生成一个或多个不同的输出。
根据键划分reduce空间:reducing函数的作用是把大的数值列表转变为一个(或几个)输出数值。在MapReduce中,所有的输出数值一般不会被reduce在一起。有着相同键的所有数值会被一起送到一个reducer里。作用在有着不同键关联的数值列表上的reduce操作之间是独立执行的。
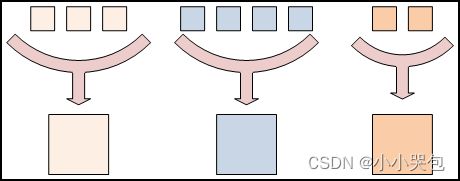
图4.3 不同颜色代表不同的键,有着相同键的数值都被传到同一个reduce任务里。
应用例子:词频统计(Word Count)
写一个简单的MapReduce程序就可以用来统计不同的词在一个文件集中出现的次数。比如,我们有这样的文件:
foo.txt: Sweet, this is the foo file
bar.txt: This is the bar file
我们期望输出会是这样子:
sweet 1
this 2
is 2
the 2
foo 1
bar 1
file 2
当然没问题,我们可以写一个MapReduce程序来计算得到这个输出。高层结构看起来会是这样子:
mapper (filename, file-contents):
for each word in file-contents:
emit (word, 1)
reducer (word, values):
sum = 0
for each value in values:
sum = sum + value
emit (word, sum)列表4.1 MapReduce词频统计伪代码
若干个mapper函数的实例会被创建在我们的集群的不同机器上,每个实例接收一个不同的输入文件(这里假设我们有很多个文件)。mappers输出的(word,1)键值对会被转到reducers那里去。若干个reducer方法实例也会在不同机子上被实例化。每个reducer负责处理关联到不同词的数值列表,数值列表中的值都是1;reducer把这些“1”值总和到一个关联了某个词的最终计数里。reducer然后生成最终的(word,count)输出,并把它写到一个输出文件里。
针对这个,我们可以在Hadoop MapReduce中写一个很相似的程序;它被包括在Hadoop分发包中,具体在src/examples/org/apache/hadoop/examples/WordCount.java。它的部分代码如下:
public static class MapClass extends MapReduceBase
implements Mapper {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value,
OutputCollector output,
Reporter reporter) throws IOException {
String line = value.toString();
StringTokenizer itr = new StringTokenizer(line);
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
output.collect(word, one);
}
}
}
/**
* A reducer class that just emits the sum of the input values.
*/
public static class Reduce extends MapReduceBase
implements Reducer {
public void reduce(Text key, Iterator values,
OutputCollector output,
Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
} 列表4.2 MapReduce词频统计Java源码
实际Java实现与上述伪代码之间有一些微小的差别。首先,Java没有原生的emit关键字;你得到的OutputCollector输入对象会接收数值并emit到下一执行阶段。第二,Hadoop使用的默认输入格式把输入文件的每一行作为mapper单独的一个输入,不是一次整个文件。其中还使用了一个StringTokenizer对象用来把一行数据拆分为词组。这个操作没有对输入数据做任何规格化处理,所以“cat”,“Cat”,“cat,”都被认为是不同的字符串。注意,类变量word在每一次mapper输出另外一个(word,1)键值对时都被重复使用;这个举措节省了为每个输出创建一个新的变量的时间。output.collect()方法会拷贝它收到的数值作为输入数据,所以你可以覆盖你使用的变量。
驱动方法
Hadoop MapReduce程序的最后一个组件叫做Driver,它会初始化Job和指示Hadoop平台在输入文件集合上执行你的代码,并控制输出文件的放置地址。下面是Hadoop自带的Java实现例子里的一个整理版本driver的代码:
public void run(String inputPath, String outputPath) throws Exception {
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount");
// the keys are words (strings)
conf.setOutputKeyClass(Text.class);
// the values are counts (ints)
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(MapClass.class);
conf.setReducerClass(Reduce.class);
FileInputFormat.addInputPath(conf, new Path(inputPath));
FileOutputFormat.setOutputPath(conf, new Path(outputPath));
JobClient.runJob(conf);
}列表4.3 Hadoop MapReduce词频统计驱动器
这个方法建立了一个在给定输入文件夹(inputPath参数)里的文件上执行词频统计程序的作业(Job)。reducers的输出被写到outputath指定的文件夹内。用于运行job的配置信息保存在JobConf对象里。通过setMapperClass()和setReducerClass()方法可以设定mapping和reducing函数。reducer生成的数据类型由setOutputKeyClass()和setOutputValueClass()方法设定。默认情况下假定这些也是mapper的输出数据类型。如果你想设定不同的数据格式的话,可以通过JobConf的setMapOutputKeyClass()和 setMapOutputValueClass()方法设定。mapper的输入数据类型由InputFormat控制。输入格式在这里有详细的讨论。默认的输入格式是“TextInputFormat”,它会以(LongWritable,Text)键值对的方式加载数据。long值表示某一行在文件中的偏移量,Text对象则保存某一行的字符串内容。
通过调用JobClient.runJob(conf)即可向MapReduce提交job,这个调用会阻塞直到job完成。如果job失败了,它会抛出一个IOException。JobClient还提供了一个非阻塞版本的调用方法submitJob()。