数据库mysql
数据库概念
数据
- 描述事物的符号记录
- 包括数字,文字,图形,图像,声音,档案记录等
- 以“记录”形式按统一的格式进行存储
表
- 将不同的记录组织在一起
- 用来存储具体数据
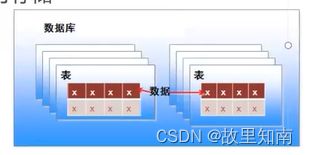
数据库
- 表的集合,是存储数据的仓库
- 以一定的组织方式存储的相互有关的数据集合
- 是按照数据结构来组织,存储和管理数据的仓库
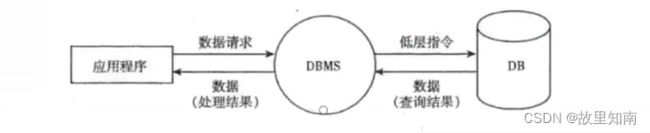
数据库管理系统(DBMS)
- 是实现对数据库资源有效组织、管理和存储的系统软件
- 数据库的建立和维护功能、数据定义功能、数据操纵功能、数据库的运行管理功能、通信功能
数据库系统
- 是一个人机系统、由硬件、OS、数据库、DBMS、应用软件和数据库用户组成
- 用户可以通过DBMS或应用程序操作数据库
数据库的发展
1.第一代数据库
自20世纪60年代起,第一代数据库系统问世
是层次模型与网状模型的数据库系统为统一管理和共享数据提供了有力的支撑
2.第二代数据库
20世纪70年代初,第二代数据库——关系数据库开始出现
20世纪80年代初,IBM公司的关系数据库系统DB2问世,开始逐步取代层次与网状模型的数据库,成为行业主流
到目前为止,关系数据库系统仍占领数据库应用的主要地位
3.第三代数据库
自20世纪80年代开始,适应不同领域的新型数据库系统不断涌现面向对象的数据库系统,实用性强、适应面广
20世纪90年代后期,形成了多种数据库系统共同支撑应用的局面
一些新的元素被添加进主流数据库系统中。例如,Oracle支持的 “关系-对象” 数据库模型
关系数据库系统是基于关系模型的数据库系统
关系模型的数据结构使用简单易懂的二维数据表
关系模型可用简单的 “实体-关系”(E-R)图来表示
E-R图中包含了实体(数据对象)、关系和属性三个要素
主流数据库介绍
| 数据库 |
说明 |
| SQL Server(微软公司产品) |
面向Windows操作系统 |
| Oracle (甲骨文公司产品) |
面向所有主流平台 |
| DB2(IBM公司产品) |
面向所有主流平台 |
| MySQL (甲骨文公司收购) |
免费、开源、体积小 |
数据库分类
关系型数据库
概念
关系数据库系统是基于关系模型的数据库系统
关系模型的数据结构使用简单易懂的二维数据表
关系模型可用简单的 “实体-关系”(E-R)图来表示
E-R图中包含了实体(数据对象)、关系和属性三个要素
关系型数据库存储结构
- 关系数据库的存储结构是二维表格
- 在每个二维表中
- 每一行称为一条记录,用来描述一个对象的信息
- 每一列称为一个字段,用来描述对象的一个属性
非关系型数据库
非关系数据库也被称为NoSQL(Not Only SQL)
存储数据不以关系模型为依据,不需要固定的表格式
非关系型数据库的优点
- 数据库可高并发读写
- 对海量数据高效率存储与访问
- 数据库具有高扩展性与高可用性
非关系数据库应用
| 数据库类型 |
相关应用 |
| 缓存型 |
Redis 、Memcached |
| 文档型 |
MongoDB |
| 搜索型 |
Elasticsearch |
| 时序型 |
Prometheus、InfluXDB |
Mysql数据库管理
库和表
行(记录):用来描述一个对象的信息
列(字段):用来描述对象的一个属性
常用的数据类型
| 数据类型 |
取值范围 |
| int(整型) |
无符号[0,232-1] 有符号[-231,231-1] |
| float(单精度浮点) |
4字节32位 |
| double(双精度浮点 ) |
8字节64位 |
| char(固定长度的字符类型) |
用户指定范围 |
| varchar(可变长度的字符类型) |
用户指定范围 |
| text(文本) |
文本字符串 |
| image(图片) |
根据图片格式类型而定 |
| decimal(5,2) |
最大五位数,固定两位小数 |
char和varchar区别
CHAR和VARCHAR类型类似,但它们保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同。在存储或检索过程中不进行大小写转换
下表显示了将各种字符串值保存到CHAR(4)和VARCHAR(4)列后的结果,说明了CHAR和VARCHAR之间的差别:
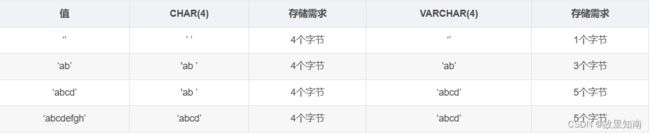
1)字节大小
①char无论是否有值,都会占用固定长度的字节大小,保存在磁盘上都是4字节
②varchar在保存字符时,默认会加一个隐藏的结束符,因此结束符会多算一个字节
2)优劣比较
①varchar比char节省磁盘空间
②但varchar类型的数据读写速度比char慢,因为char是连续的磁盘空间,而varchar在多次增删改查中会产生一些磁盘空间碎片
SQL语句
SQL语句用于维护管理数据库,包括数据查询、数据更新、访问控制、对象管理等功能
| 语句 |
含义 |
| DDL |
数据定义语言,用于创建数据库对象,如库、表、索引等 |
| DML |
数据操纵语言,用于对表中的数据进行管理 |
| DQL |
数据查询语言,用于从数据表中查找符合条件的数据记录 |
| DCL |
数据控制语言,用于设置或者更改数据库用户或角色权限 |
查看数据库结构
mysql> show databases; #查看当前服务器中的数据库
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| shiyan |
| sys |
| xiaozu |
+--------------------+
6 rows in set
#查看数据库中的表
mysql> use xiaozu; #切换到库名
Database changed
mysql> show tables; #查看库中的表名
+------------------+
| Tables_in_xiaozu |
+------------------+
| cx |
| xz |
| zuyuan |
+------------------+
3 rows in set
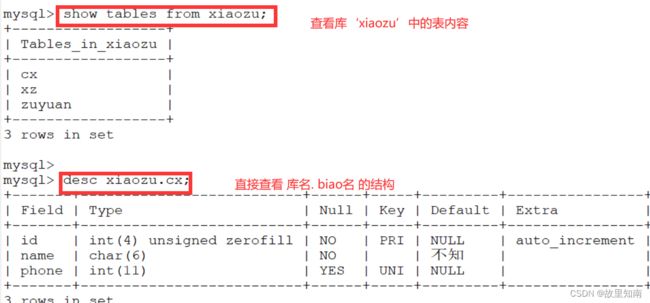
mysql> show tables from xiaozu; #查看库中的表名
+------------------+
| Tables_in_xiaozu |
+------------------+
| cx |
| xz |
| zuyuan |
+------------------+
3 rows in set
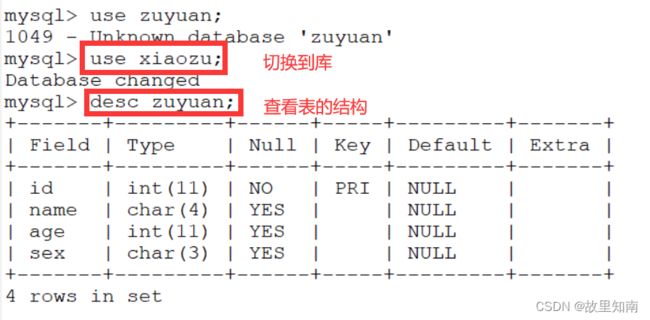
mysql> use zuyuan;
1049 - Unknown database 'zuyuan'
mysql> use xiaozu;
Database changed
mysql> desc zuyuan; #查看表的结构(字段)
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | char(4) | YES | | NULL | |
| age | int(11) | YES | | NULL | |
| sex | char(3) | YES | | NULL | |
+-------+---------+------+-----+---------+-------+
4 rows in set
mysql> desc xiaozu.zuyuan; #查看表中的结构(字段)
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | char(4) | YES | | NULL | |
| age | int(11) | YES | | NULL | |
| sex | char(3) | YES | | NULL | |
+-------+---------+------+-----+---------+-------+
4 rows in set

创建及删除数据库与表
DDL 用于管理数据库对象: 库 表 索引
mysql> create database test; #创建库名
Query OK, 1 row affected
mysql> show databases; #查看库
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| shiyan |
| sys |
| test |
| xiaozu |
+--------------------+
7 rows in set
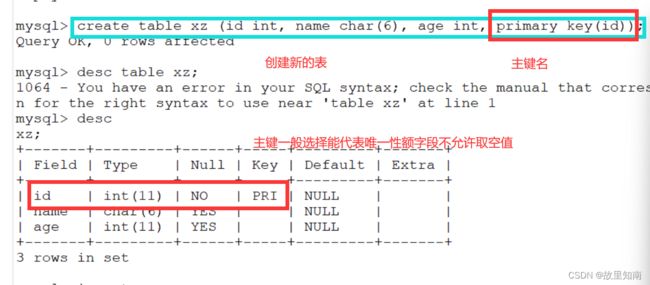
mysql> create table xz (id int, name char(6), age int, primary key(id));
管理表中的数据记录
DQL根据条件查询表数据
1.向数据表中插入新的数据记录
INSERT INTO 表名(字段1,字段2[,...]) VALUES(字段1的值,字段2的值,...);
2.查询数据记录
SELECT 字段名1,字段名2[,...] FROM 表名 [WHERE 条件表达式];
3.修改、更新数据表中的数据记录
UPDATE 表名 SET 字段名1=字段值1[,字段名2=字段值2] [WHERE 条件表达式];
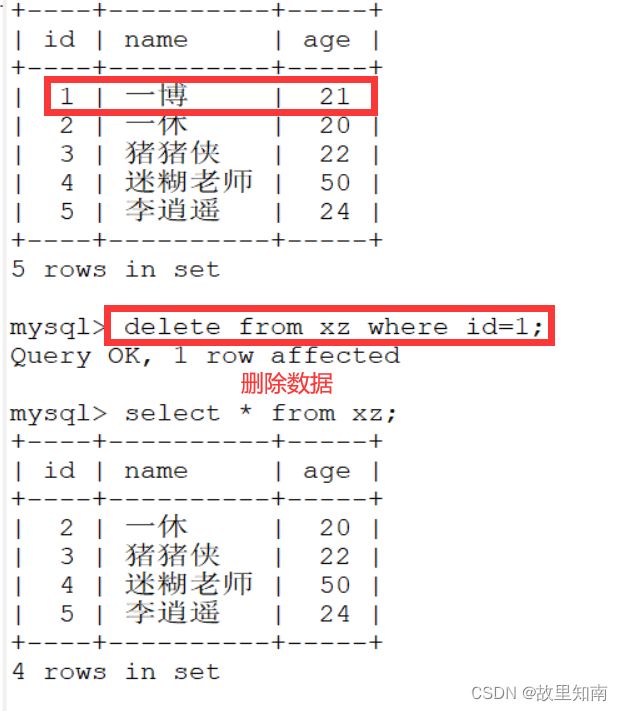
4.在数据表中删除指定的数据记录
DELETE FROM 表名 [WHERE 条件表达式];



修改表名和表结构
修改表名和表结构
1. #修改表名
alter table 旧的表名 rename 新的表名
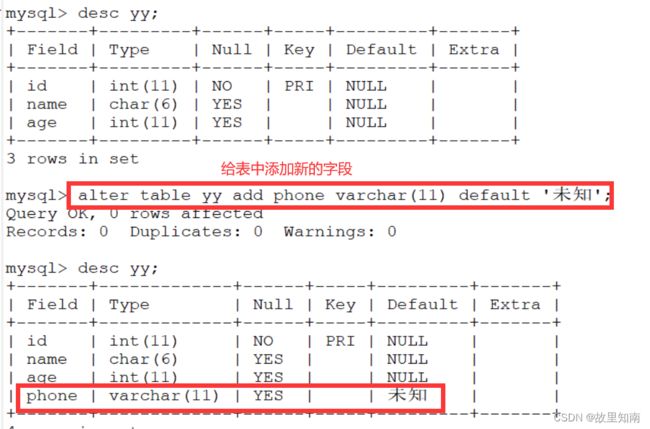
2. #扩展表结构(增加字段)
alter table 表名 add 字段 数据类型 default ' 默认值' ;
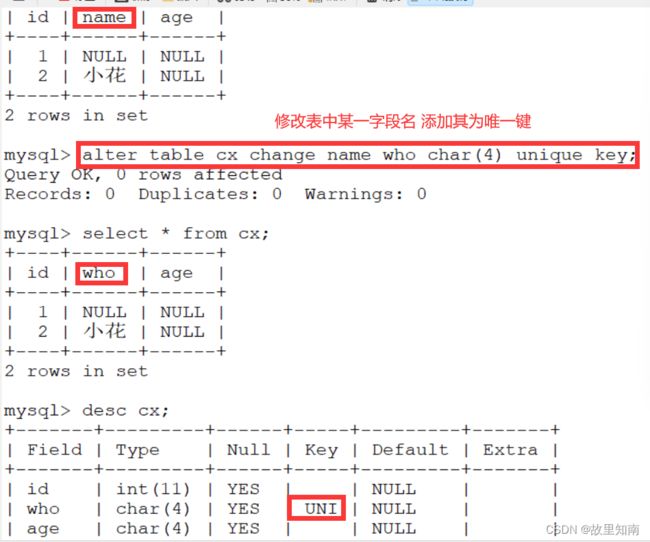
3. #修改字段(列)名,唯一键
alter table 表名 change 旧列名 新列名 数据类型 【unique key】;
4.# 删除字段
alter table 表名 drop 字段名;


案例扩展
use kgc;
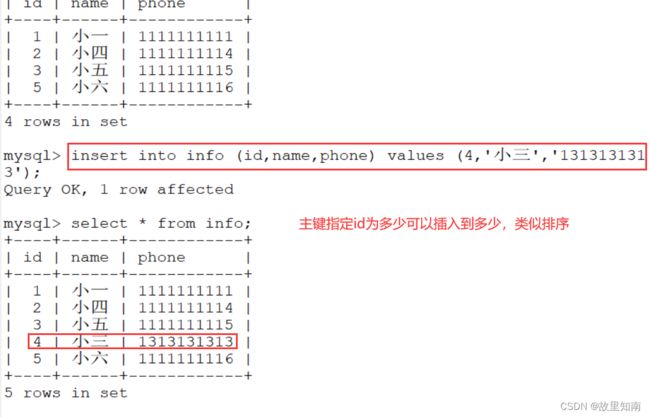
create table if not exists info (
id int(4) zerofill primary key auto_increment, #指定主键的第二种方式
name varchar(10) not null default '匿名',
cardid int(18) not null unique key,
hobby varchar(50));
----------------------------------------------------------------------------------------------------------
#if not exists:表示检测要创建的表是否已存在,如果不存在就继续创建
#int(4) zerofill:表示若数值不满4位数,则前面用“0”填充,例0001
#auto_increment:表示此字段为自增长字段,即每条记录自动递增1,默认从1开始递增;自增长字段数据不可以重复;自增长字段必须是主键;如添加的记录数据没有指定此字段的值且添加失败也会自动递增一次
#unique key:表示此字段唯一键约束,此字段数据不可以重复;一张表中只能有一个主键, 但是一张表中可以有多个唯一键
#not null:表示此字段不允许为NULL
#int(N) zerofill 零填充

数据表高级操作
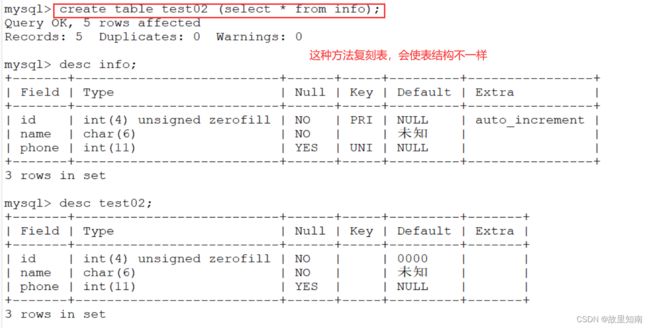
克隆表,将数据表的数据记录生成到新的表中
方法一:
create table 新表 like 旧表; #通过 LIKE 方法,复制旧 表结构生成 新 表
insert into test01 select * from 旧表;
#此方法能保证 新表的表结构、表数据 跟旧表都是一致的
方法二:
CREATE TABLE 新表 (SELECT * from 旧表);
#此方法创建的新表的表数据和旧表是一样的,但可能会出现新表的表结构和旧表的不一致
show create table 新表\G #获取数据表的表结构、索引等信息
SELECT * from 新表;

清空表,删除表内的所有数据
方法一
delete from test01;
#DELETE清空表后,返回的结果内有删除的记录条目;DELETE工作时是一行一行的删除记录数据的;如果表中有自增长字段,使用DELETE FROM 删除所有记录后,再次新添加的记录会从原来最大的记录 ID 后面继续自增写入记录。
方法二
truncate table test01;
#TRUNCATE 清空表后,没有返回被删除的条目;TRUNCATE 工作时是将表结构按原样重新建立,因此在速度上 TRUNCATE 会比 DELETE 清空表快;使用 TRUNCATE TABLE 清空表内数据后,ID 会从 1 开始重新记录。
在生产环境中,推荐使用方法二、因为第一种是一个一个山,会占用cpu,容易高负荷创建临时表
临时表创建成功之后,使用SHOW TABLES命令是看不到创建的临时表的,临时表会在连接退出后被销毁。 如果在退出连接之前,也可以可执行增删改查等操作,比如使用 DROP TABLE 语句手动直接删除临时表。
CREATE TEMPORARY TABLE 表名 (字段1 数据类型,字段2 数据类型[,...][,PRIMARY KEY (主键名)]);
Mysql 常用的6大约束
primary key 主键约束 字段的值不能重复,不能为null,一个表只能有一个主键
unique key 唯一性约束 字段的值不能重读,能为null,一个表可有多个唯一键
not null 非空约束 字段的值不能为null
default 默认值约束 字段的值如果没有设置则使用默认值自动填充
auto_increment 自增约束 字段的值如果没有设置,默认会从1开始递增1,要求自增字段必须为主键字段
foreign key 外键约束 保证相关联表数据的完整性和一致性
数据库用户管理
1)新建用户
CREATE USER '用户名'@'来源地址' [IDENTIFIED BY [PASSWORD] '密码'];
-------------------------------------------------------------
'用户名':指定将创建的用户名
'来源地址':指定新创建的用户可在哪些主机上登录,可使用IP地址、网段、主机名的形式,本地用户可用localhost,允许任意主机登录可用通配符%
'密码':若使用明文密码,直接输入'密码',插入到数据库时由Mysql自动加密;
若使用加密密码,需要先使用SELECT PASSWORD('密码'); 获取密文,再在语句中添加 PASSWORD '密文';
若省略“IDENTIFIED BY”部分,则用户的密码将为空(不建议使用)

2)查看用户信息
###创建后的用户保存在 mysql 数据库的 user 表里
USE mysql;
SELECT User,authentication_string,Host from user;
#查看当前登录用户
select user();

3)重命名用户
RENAME USER 'kb1'@'localhost' TO 'kongbai1'@'localhost';

4)删除用户
DROP USER 'zzz'@'localhost';

5)修改当前登录用户密码
SET PASSWORD = PASSWORD('123');
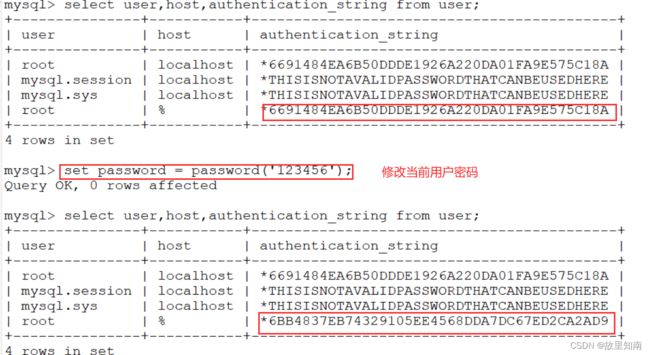
6)修改其他用户密码
SET PASSWORD FOR 'zzz'@'localhost' = PASSWORD('abc');
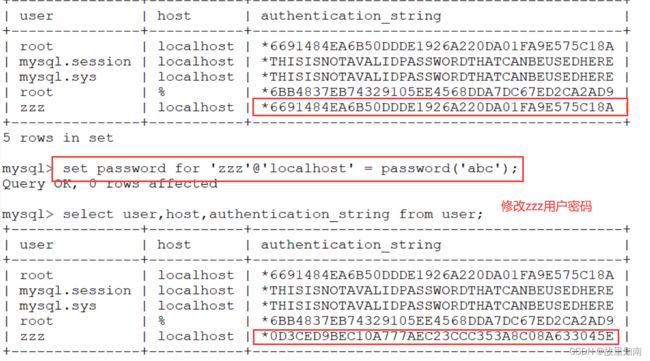
7)忘记 root 密码的解决办法
1)修改 /etc/my.cnf 配置文件,不使用密码直接登录到 mysql
vim /etc/my.cnf
[mysqld]
skip-grant-tables
###添加,使登录mysql不使用授权表
systemctl restart mysqld
mysql
###直接登录
2)使用 update 修改 root 密码,刷新数据库
UPDATE mysql.user SET AUTHENTICATION_STRING = PASSWORD('123') where user='root';
FLUSH PRIVILEGES;
quit
mysql -u root -p123
注意:最后再把 /etc/my.cnf 配置文件里的 skip-grant-tables 删除,并重启 mysql 服务


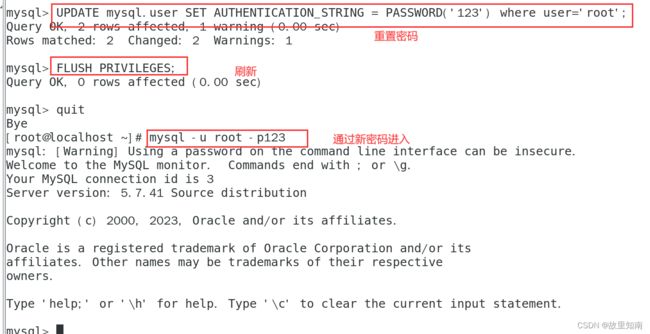
注意:最后再把 /etc/my.cnf 配置文件里的 skip-grant-tables 删除,并重启 mysql 服务。
数据库用户授权
1)授予权限
GRANT语句:专门用来设置数据库用户的访问权限。当指定的用户名不存在时,GRANT语句将会创建新的用户;当指定的用户名存在时, GRANT 语句用于修改用户信息
GRANT 权限列表 ON 数据库名.表名 TO '用户名'@'来源地址' [IDENTIFIED BY '密码'];
-------------------------------------------------------------
###权限列表:用于列出授权使用的各种数据库操作,以逗号进行分隔,如“select,insert,update”。使用“all”表示所有权限,可授权执行任何操作。
#数据库名.表名:用于指定授权操作的数据库和表的名称,其中可以使用通配符“*”。例如,使用“kgc.*”表示授权操作的对象为 kgc数据库中的所有表。
###'用户名@来源地址':用于指定用户名称和允许访问的客户机地址,即谁能连接、能从哪里连接。来源地址可以是域名、IP地址,还可以使用“%”通配符,表示某个区域或网段内的所有地址,如“%.kb.com”、“192.168.58.%”等。
###IDENTIFIED BY:用于设置用户连接数据库时所使用的密码字符串。在新建用户时,若省略“IDENTIFIED BY”部分,则用户的密码将为空。
-------------------------------------------------------------
###允许用户 kongbai1 在本地查询 kb 数据库中 所有表的数据记录,但禁止查询其他数据库中的表的记录
GRANT select ON kb.* TO 'kongbai1'@'localhost' IDENTIFIED BY '123';
#允许用户 lisi 在所有终端远程连接 mysql ,并拥有所有权限。
GRANT ALL [PRIVILEGES] ON *.* TO 'kongbai1'@'%' IDENTIFIED BY '123';
flush privileges;
quit
mysql -u kongbai1 -p123
use kb;
show tables;
select * from kb;

2)查看权限
SHOW GRANTS FOR 用户名@来源地址;

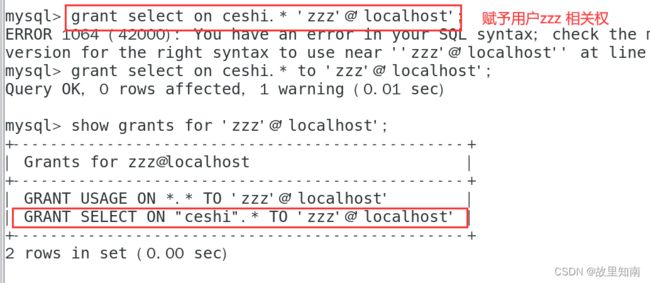

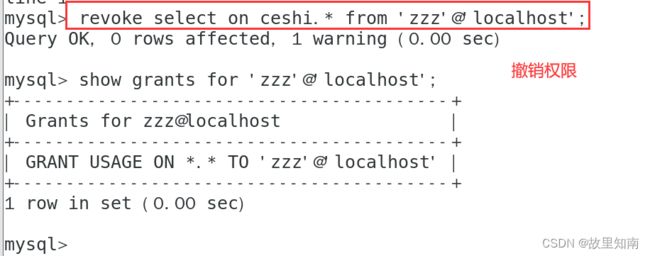
3)撤销权限
REVOKE 权限列表 ON 数据库名.表名 FROM 用户名@来源地址;
SHOW GRANTS FOR 'kongbai1'@'%';
###USAGE权限只能用于数据库登陆,不能执行任何操作;USAGE权限不能被回收,即 REVOKE 不能删除用户
flush privileges;
###刷新权限,立即生效