万字攻略全面了解selenium_selenium教程
今天带大家一起学习下python爬虫4小分队(scrapy、beautifulsoup、selenium以及pyppeteer)之一的Selenium库,主要用于模拟浏览器运行,是一个用于web应用测试的工具。Selenium直接运行在浏览器中,看起来就像人在操作一样(也可无窗口模式运行)。支持的浏览器包括IE、Firefox、Safari、Chrome、Opera和Edge等。
下面主要以Chrome为例进行Selenium功能讲解,但是会附带其他浏览器的准备讲解。
0. 准备工作
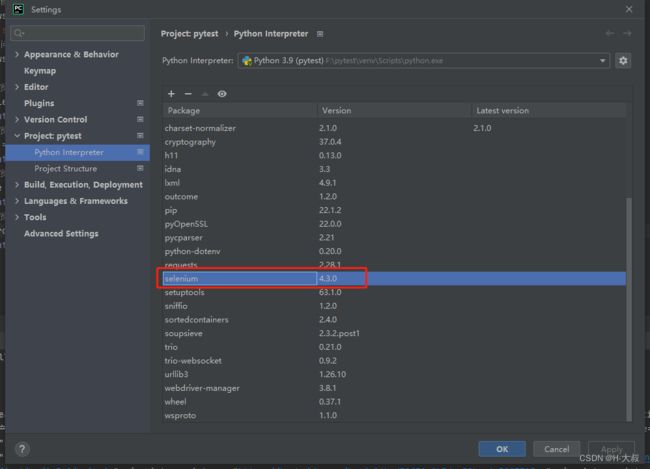
Python:3.9
selenium库:4.3.0
开发工具:PyCharm 2022.1.3
本文内容会涉及python3、selenium4、javascript、html等内容,需要有一定基础,或者有很强的的接受能力。
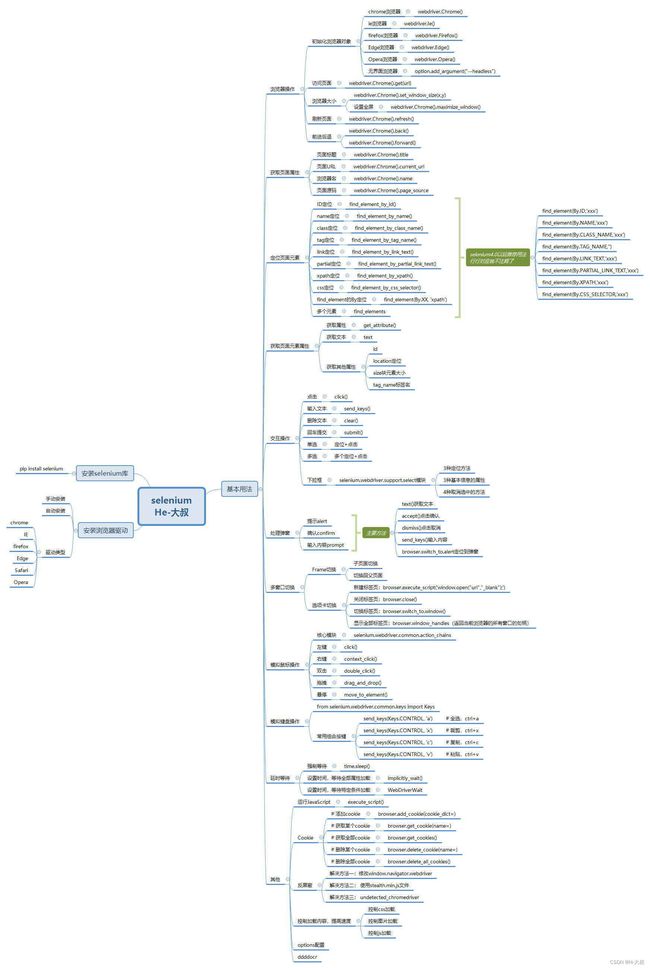
在学习之前,比较喜欢来个清晰的目录,让大家都有个整体的认识先,下面是我整理的思维导图,有需要高清图的朋友可以私信。
后面我们就开始先安装Chrome浏览器(省略哈)并配置好ChromeDriver,当然也要安装好selenium库!还有Python环境(也是省略,有需要的看下我其他关于安装Python环境文章)。
写在前面:出现 DeprecationWarning 警告的类型错误:该类型的警告大多属于版本已经更新,所使用的方法即将弃用。所以下面代码为了让读者更快捷辨识两个版本写法,都已经整理出来,记得点个赞哦。
通过webdriver对象的find_element_by_xx(" ")(在selenium的4.0版本中此种用法即将弃用,不推荐使用),要使用通过webdriver模块中的By,以指定方式定位元素。
1. 安装selenium库
pip install selenium2. 安装浏览器驱动
安装驱动,咱们可以分为两种方式去做,一种是手动下载驱动到本地,由项目直接调用,第二种就是通过第三方库来自动安装,下面我们都详细介绍两种方式具体操作。
这里省略掉chrome或者其他浏览器的安装过程,默认大家都已经安装好心仪浏览器了~~~
2.1 手动安装驱动
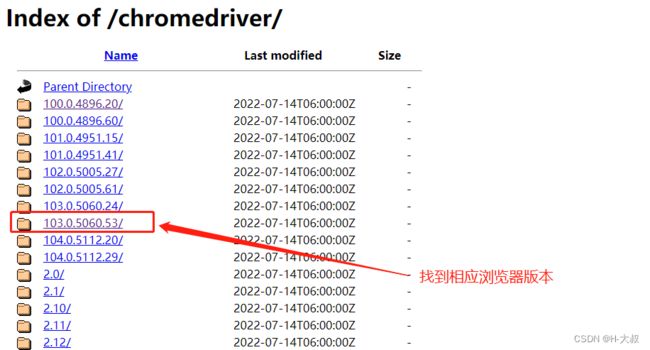
第一步:查看浏览器版本号
打开浏览器-说明-关于Google Chrome,就可以看到我们的版本号了。

第二步:根据版本号选择合适的浏览器驱动
ChromeDriver地址:https://registry.npmmirror.com/binary.html?path=chromedriver/
ChromeDrive国内源:https://mirrors.huaweicloud.com/chromedriver/
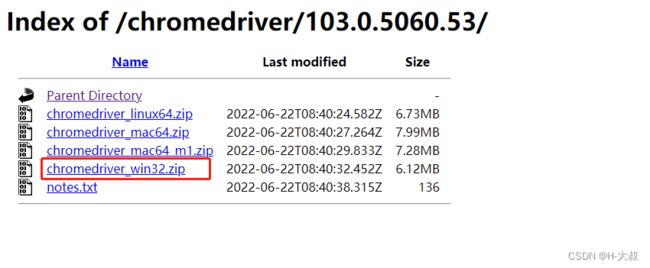 因为作者是windows的所以就选了win版,只有32位是能够兼容64位使用的,所以不用担心有什么问题。
因为作者是windows的所以就选了win版,只有32位是能够兼容64位使用的,所以不用担心有什么问题。
第三步:下载驱动到本地
将下载好的Driver文件放到项目目录下,方便在使用的时候填写路径(如果不写绝对路径,就要将driver文件移到python的script目录下)
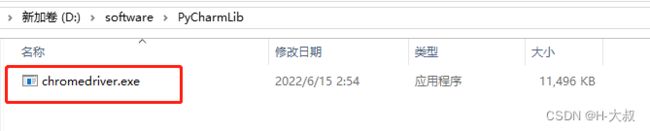
path = r'D:\software\PyCharmLib\chromedriver.exe' # 驱动文件存放的位置
# 如果存在DeprecationWarning警告,就需要使用新版本写法
path = Service(r'D:\software\PyCharmLib\chromedriver.exe')具体用法下面再详细说明。
第四步:其他浏览器的Driver地址
(IE浏览器)IEDriverServer地址:iedriverserver
(火狐浏览器)GeckoDriver地址:geckodriver
(safari浏览器)SafariDriver地址:驱动已存在本地,路径:/usr/bin/safaridriver
(opera浏览器)OperaDriver地址:operadriver
(edge浏览器)EdgeDriver地址:edgedriver
2.2 自动安装驱动
要想实现自动安装浏览器驱动,我们就需要用到第三方库 webdriver_manager ,直接下载该库使用即可。
pip install webdrivermanager如果是pycharm编辑器直接在项目里面添加:
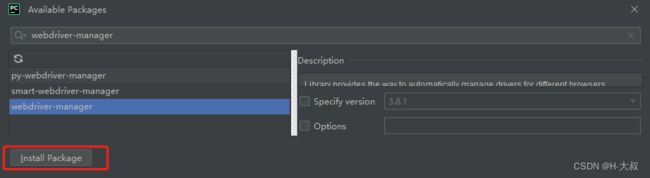
添加完,简单调用一下:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
# 新版本写法
browser = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
# 旧版写法
# browser = webdriver.Chrome(ChromeDriverManager().install())
browser.get('http://www.baidu.com')
# 新版写法
search = browser.find_element(By.ID, 'kw')
# 旧版写法
# search = browser.find_element_by_id('kw')
search.send_keys('python')
search.send_keys(Keys.ENTER)
# 关闭浏览器
browser.close()上面代码就是简单触发了一下浏览器,主要是由ChromeDriverManager().install() 方法自动安装默认浏览器的适配驱动,首先它会获取当前浏览器版本号,再去下载相关驱动。
注意:使用自动下载亲测每次启动都很慢,因为每次都会重新识别、调用,所以各位朋友慎用。
上面所有内容就是我们初步需要准备的基础。
3. selenium基本用法
下面开始讲初始化浏览器对象、访问页面、设置浏览器大小、刷新页面和前进后退等基础操作。
3.1 初始化浏览器对象
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
# 新版本写法
browser = webdriver.Chrome(service=
Service(r'D:\software\PyCharmLib\chromedriver.exe'))
# 旧版写法
# browser = webdriver.Chrome(r'D:\software\PyCharmLib\chromedriver.exe')
browser.get('http://www.baidu.com')
# 新版写法
search = browser.find_element(By.ID, 'kw')
# 旧版写法
# search = browser.find_element_by_id('kw')
search.send_keys('python')
search.send_keys(Keys.ENTER)
# 关闭浏览器
browser.close()通过上面代码会打开我们的浏览器界面后并关闭:

一般采用最简单的浏览器初始化都是带有界面的,但是我们还是设置成 无界面浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
# 设置无界面浏览器
option = webdriver.ChromeOptions() # 创建一个配置对象
option.add_argument("--headless") # 开启无界面模式
option.add_argument("--disable-gpu") # 禁用gpu
# options.set_headles() # 无界面模式的另外一种开启方式
# 实例化带有配置的driver对象
browser = webdriver.Chrome(service=
Service(r'D:\software\PyCharmLib\chromedriver.exe'), options=option)
browser.get('http://www.baidu.com')
# 新版写法
search = browser.find_element(By.ID, 'kw')
search.send_keys('python')
search.send_keys(Keys.ENTER)
# 关闭浏览器
browser.close()通过提前把参数准备好,在初始化的时候设置进去,这样子浏览器就不会打开任何界面。
3.2 访问页面
进行页面访问使用的是 get( url ) 方法,url就是待访问页面的URL地址参数。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# 实例化带有配置的driver对象
browser = webdriver.Chrome(
service=Service(r'D:\software\PyCharmLib\chromedriver.exe'))
# 访问页面
browser.get('http://www.baidu.com')
# 关闭浏览器
browser.close()3.3 设置浏览器大小
通过 set_window_size()方法就可以设置浏览器大小
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# 实例化带有配置的driver对象
browser = webdriver.Chrome(
service=Service(r'D:\software\PyCharmLib\chromedriver.exe'))
# 访问页面
browser.get('http://www.baidu.com')
# 设置浏览器大小为500*500像素
browser.set_window_size(500, 500)
# 关闭浏览器
# browser.close()还可以通过 maximize_window() 方法设置浏览器全屏
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# 实例化带有配置的driver对象
browser = webdriver.Chrome(
service=Service(r'D:\software\PyCharmLib\chromedriver.exe'))
# 访问页面
browser.get('http://www.baidu.com')
# 设置浏览器全屏
browser.maximize_window()
# 关闭浏览器
# browser.close()3.4 刷新页面
refresh()方法可以用来进行浏览器页面刷新,等同于我们平时用的F5按键,有些页面需要定时刷新,这也算是比较常用方法。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
# 实例化带有配置的driver对象
browser = webdriver.Chrome(
service=Service(r'D:\software\PyCharmLib\chromedriver.exe'))
# 访问页面
browser.get('http://www.baidu.com')
time.sleep(1)
# 刷新浏览器
try:
browser.refresh()
print('刷新页面成功')
except Exception as e:
print('刷新页面失败')3.5 前进后退
forward()方法可以用来实现前进,back()可以用来实现后退。下面我们来玩套组合拳。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
# 实例化
browser = webdriver.Chrome(
service=Service(r'D:\software\PyCharmLib\chromedriver.exe'))
# 打开百度页面
browser.get('https://www.baidu.com')
time.sleep(1)
# 打开csdn网页
browser.get('https://www.csdn.net/')
time.sleep(1)
# 后退回百度页面
browser.back()
time.sleep(1)
# 前进到csdn页面
browser.forward()这样就能开始连续跳动了,看起来就像人在操作一样。
这里设置睡眠时间是为了大家更直观看到效果,同时这个睡眠时间在实际应用中是十分有用的,搭配随机模块 time.sleep(random.uniform(intx,inty)) ,生成随机睡眠时间能够让网站更难判断出到底是不是自动化机器在收集数据,也算是 反屏蔽小手段 之一。
4. 获取页面基础属性
通过selenium打开网页后,我们就能获取到页面的title标题,current_url网页地址,name浏览器名,page_source网页源码等内容。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# 实例化
browser = webdriver.Chrome(
service=Service(r'D:\software\PyCharmLib\chromedriver.exe'))
# 访问csdn首页
browser.get('https://www.csdn.net/')
# 浏览器标题
title = browser.title
print(title)
# 浏览器地址
url = browser.current_url
print(url)
# 浏览器名
name = browser.name
print(name)
# 浏览器源码
source = browser.page_source
print(source)通过上面代码访问CSDN首页,获取到符合我们预期的属性内容。
其中获取到源码后,我们还可以通过正则、Xpath等方法对内容进行提取,但是个人建议用selenium做这个不太适合,还不如用beautifulsoup去实现,效率和效果都更好。
5. 定位页面元素
这是个十分重要的知识点,学的好不好决定了后面获取页面元素采集数据成功性。
5.1 ID定位 - find_element_by_id()
(id属性值与位置匹配的第一个元素将被返回。)
find_element_by_id('xx') 能够帮助我们获取到id为xx的元素
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
browser = webdriver.Chrome(
service=Service(r'D:\software\PyCharmLib\chromedriver.exe'))
# 访问csdn首页
browser.get('https://www.csdn.net/')
# 获取csdn首页id为toolbar-search-input的搜索框,并且输入python
browser.find_element(By.ID, 'toolbar-search-input').send_keys('Python')
# selenium4.0前版本写法
# browser.find_element_by_id('toolbar-search-input').send_keys('Python')
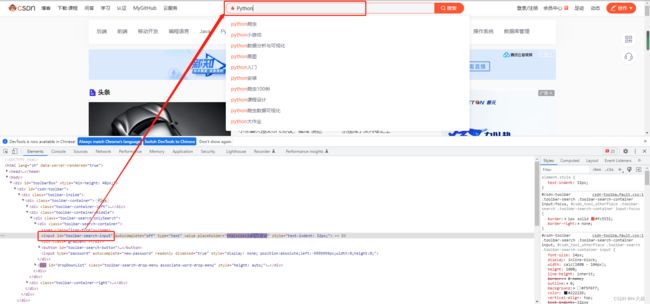
通过ID定位方法,我们成功找到搜索框并输入Pyhont内容。
5.2 name定位 - find_element_by_name()
(名称属性值与位置匹配的第一个元素将被返回。)
find_element_by_name('xx') 能够帮助我们获取到name为xx的元素
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
browser = webdriver.Chrome(
service=Service(r'D:\software\PyCharmLib\chromedriver.exe'))
# 访问百度首页
browser.get('https://www.baidu.com/')
# 获取百度首页name为wd的搜索框,并且输入python
browser.find_element(By.NAME, 'wd').send_keys('Python')
# selenium4.0前版本写法
# browser.find_element_by_name('wd').send_keys('Python')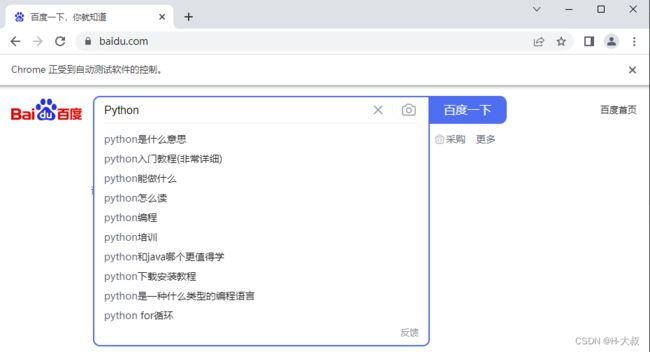
5.3 class定位 - find_element_by_class_name()
(具有匹配的类属性名称的第一个元素将被返回。)
通过find_element_by_class_name(‘xx’)方法就可以获取到网页中class名为xx的第一个元素。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
browser = webdriver.Chrome(
service=Service(r'D:\software\PyCharmLib\chromedriver.exe'))
# 访问百度首页
browser.get('https://www.baidu.com/')
# 获取百度首页classname为s_ipt的搜索框,并且输入python
browser.find_element(By.CLASS_NAME, 's_ipt').send_keys('Python')
# selenium4.0前版本写法
# browser.find_element_by_class_name('s_ipt').send_keys('Python')5.4 tag定位 - find_element_by_tag_name()
(具有给定标签名称的第一个元素将被返回。)
每个元素都有tag(标签)属性,如搜索框的标签属性,input是输入,table是表格等等。我们查看百度首页的html代码,可以看到有相同的Tag,很明显相同的tag太多,一般很少用tag来做定位。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
browser = webdriver.Chrome(
service=Service(r'D:\software\PyCharmLib\chromedriver.exe'))
# 访问csdn首页
browser.get('https://www.csdn.net/')
# 获取csdn首页tag为h3的文本内容
h = browser.find_element(By.TAG_NAME, 'h3').text
print(h)
# selenium4.0前版本写法
# browser.find_element_by_tag_name('h3').text
5.5 link定位 - find_element_by_link_text()
(链接文本值与位置匹配的第一个元素将被返回。)
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
browser = webdriver.Chrome(
service=Service(r'D:\software\PyCharmLib\chromedriver.exe'))
# 访问百度首页
browser.get('https://www.baidu.com/')
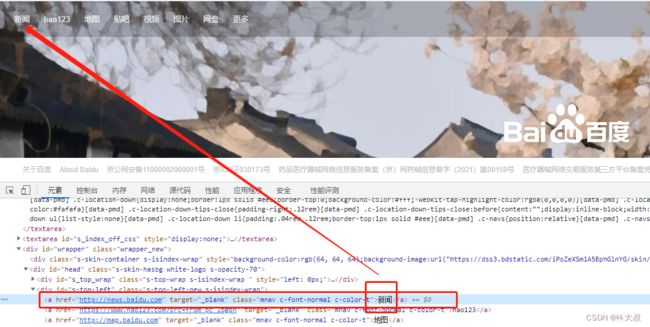
# 获取百度首页link内容为新闻的链接,并点击
browser.find_element(By.LINK_TEXT, '新闻').click()
# selenium4.0前版本写法
# browser.find_element_by_link_text('新闻').click()
获取到百度首页左上角的新闻链接并触发点击事件。
5.6 partial定位 - find_element_by_partial_link_text()
(具有部分链接文本值与位置匹配的第一个元素将被返回。)
相当于link定位的模糊搜索方法,一般一个链接文本都很长,要是全部都输入就太麻烦了,所以我们只需要输入关键词来进行匹配即可。
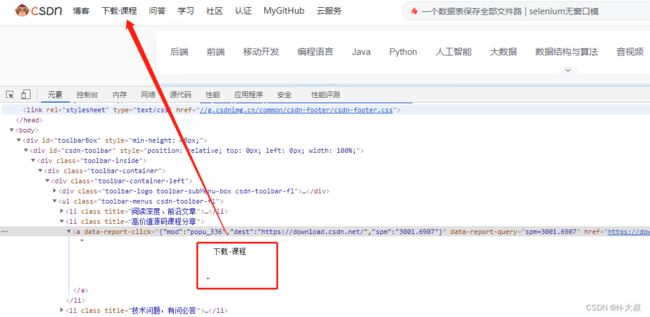
下面我们用csdn的首页“下载·课程”来做示例,我们只需要定位“课程”,然后触发点击。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
browser = webdriver.Chrome(
service=Service(r'D:\software\PyCharmLib\chromedriver.exe'))
# 访问csdn首页
browser.get('https://www.csdn.net/')
# 获取csdn首页link内容为课程的模糊检索链接,并点击
browser.find_element(By.PARTIAL_LINK_TEXT, '课程').click()
# selenium4.0前版本写法
# browser.find_element_by_partial_link_text('课程').click()5.7 Xpath定位 - find_element_by_xpath()
(xpath语法与位置匹配的第一个元素将被返回。)
前面介绍的id定位、name定位、tap定位、link定位都是比较理想化的定位方式,对于简单的网站来说使用起来效果不错,前提是这些内容都是唯一的,id唯一、name唯一、tap唯一、link内容唯一等,但是对于大型网站来说,就显得力不从心了,所以我们就要用更强大的定位工具xpath。
如果不太了解xpath语法的朋友可以先看下一文读懂XPATH基本语法
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
browser = webdriver.Chrome(
service=Service(r'D:\software\PyCharmLib\chromedriver.exe'))
# 访问csdn首页
browser.get('https://www.csdn.net/')
# 获取csdn首页,通过xpath检索搜索框,并输入python内容
browser.find_element(
By.XPATH, "//*[@id='toolbar-search-input']").send_keys('Python')
# selenium4.0前版本写法
# browser.find_element_by_xpath(
# "//*[@id='toolbar-search-input']").send_keys('Python')5.8 CSS定位 - find_selement_by_css_selector()
(具有匹配的CSS选择器的第一个元素将被返回。)
使用CSS定位方法会比xpath更加简洁,效率更高。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
browser = webdriver.Chrome(
service=Service(r'D:\software\PyCharmLib\chromedriver.exe'))
# 访问csdn首页
browser.get('https://www.csdn.net/')
# 获取csdn首页,通过css写法,获取id为toolbar-search-input的搜索框
browser.find_element(By.CSS_SELECTOR, "#toolbar-search-input")\
.send_keys('Python')
# selenium4.0前版本写法
# browser.find_element_by_css_selector('#toolbar-search-input')\
# .send_keys('Python')5.9 By定位 - find_selement(By.XXX, 定位置)
前文也提到过在新版的selenium库使用上述8种定位方法会出现警告,标识上面语法即将被弃用,建议大家使用下面方法来替换。
首先引入By类:
from selenium.webdriver.common.by import By上面一直使用都是By方式,同时也把即将弃用的方式写在下方方便大家学习的时候进行对比,咱这里就不再赘述了,还没掌握的朋友可以多浏览上面的内容。
5.10 多元素 - find_selements()
如果在网站中定位的元素不止一个,就需要用到find_elements(),得到的结果会是列表形式。简单点,就是element后面多了s,其他都一样,下面举一反三:
# 获取id为id的第一个元素
find_selement_by_id('id').click()
# 获取id为id的列表
find_selements_by_id('id')
# By写法:
find_selement(By.ID, 'id').click()
find_selements(By.ID, 'id')6 获取元素属性
通过第5点的定位方式,我们已经基本掌握了全部定位方式,那么我就可以通过定位后来获取定位元素的属性了,在进行Selenium数据收集/网络爬虫的时候,能让我们更方便对内容把控。
6.1 获取属性 - get_attribute()
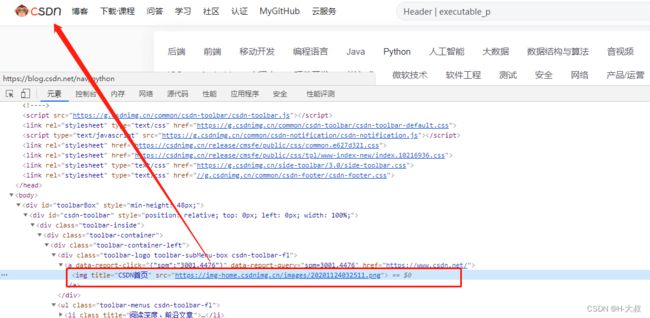
下面我们来学习通过get_attribute()方法获取csdn首页的LOGO属性。
这里获取比较复杂,但是这里也能更好锻炼我们之前学过的XPath方法,当然还有其他获取的方式,欢迎各位朋友在评论区发表自己的看法。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
browser = webdriver.Chrome(
service=Service(r'D:\software\PyCharmLib\chromedriver.exe'))
# 访问csdn首页
browser.get('https://www.csdn.net/')
# 获取csdn首页内容
logo = browser.find_element(
By.XPATH, "//div[@class='toolbar-logo toolbar-subMenu-box csdn-toolbar-fl']//img")
# 获取图片标题
logo_title = logo.get_attribute('title')
print(logo_title)
# 获取图片路径
logo_src = logo.get_attribute('src')
print(logo_src)
运行代码结果:这样我们就能同时获得logo的标题和图片地址

6.2 获取文本 - text
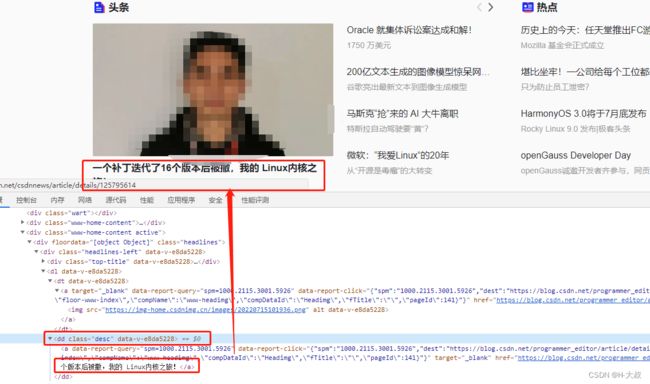
下面我们通过获取CSDN首页的头条内容标题的文本,我们发现a标签其实内容都一样,只能通过父级div定位到a标签再获取文本。
下面我们通过获取CSDN首页的头条标题来看下实际效果:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
browser = webdriver.Chrome(
service=Service(r'D:\software\PyCharmLib\chromedriver.exe'))
# 访问csdn首页
browser.get('https://www.csdn.net/')
# 获取csdn首页内容
txt = browser.find_element(
By.XPATH, "//dd[@class='desc']//a").text
print(txt)运行后的结果:

6.3 获取其他属性 - id、location、size、tag_name
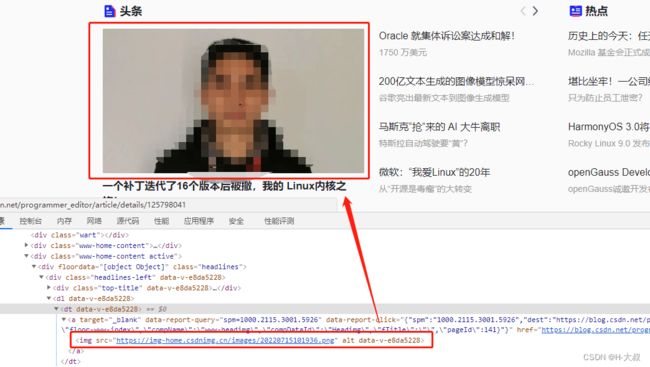
除了文本常用之外,我们还需要关注下其他几个常用属性,例如id、locaition位置、size大小(图片)、tag_name标签名等。
下面我们通过获取CSDN首页的头条图片来看下实际效果:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
browser = webdriver.Chrome(
service=Service(r'D:\software\PyCharmLib\chromedriver.exe'))
# 访问csdn首页
browser.get('https://www.csdn.net/')
# 获取csdn首页内容
hot_img = browser.find_element(
By.XPATH, "//dt[@data-v-e8da5228]/a/img")
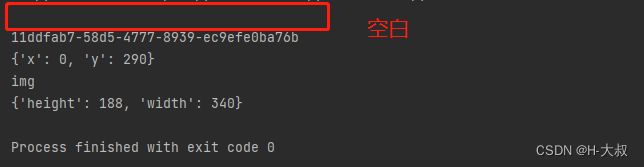
print(hot_img.text)
print(hot_img.id)
print(hot_img.location)
print(hot_img.tag_name)
print(hot_img.size)运行后的结果:因为没有文本内容text,所以第一行打印是空白的。
7 交互效果
7.1 输入文本 - send_keys()
在上面我们已经使用过该函数,一般在可输入文本的地方使用。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
browser = webdriver.Chrome(
service=Service(r'D:\software\PyCharmLib\chromedriver.exe'))
# 访问csdn首页
browser.get('https://www.csdn.net/')
# 获取csdn首页id为toolbar-search-input的搜索框,并且输入python
browser.find_element(By.ID, 'toolbar-search-input').send_keys('Python')7.2 点击 - click()
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
browser = webdriver.Chrome(
service=Service(r'D:\software\PyCharmLib\chromedriver.exe'))
# 访问百度首页
browser.get('https://www.baidu.com/')
# 获取百度首页link内容为新闻的链接,并点击
browser.find_element(By.LINK_TEXT, '新闻').click()7.3 清除文本 - clear()
既然有输入,那就有清除。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome(
service=Service(r'D:\software\PyCharmLib\chromedriver.exe'))
# 访问csdn首页
browser.get('https://www.csdn.net/')
# 获取csdn首页id为toolbar-search-input的搜索框,并且输入python
sea = browser.find_element(By.ID, 'toolbar-search-input')
# 输入python
sea.send_keys('Python')
time.sleep(2)
# 清除文本
sea.clear()7.4 回车确认 - submit()
实际效果就像表单提交一样,例如我们在输入框输入python后,触发submit就可以提交搜索了。
注意:并不是所有的输入框都能触发,只有下方存在input type=submit情况下才能成功触发。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome(
service=Service(r'D:\software\PyCharmLib\chromedriver.exe'))
# 访问百度首页
browser.get('https://www.baidu.com/')
time.sleep(1)
# 获取百度首页id为kw的搜索框,并且输入python
inputs = browser.find_element(By.ID, 'kw')
inputs.send_keys('Python')
time.sleep(1)
# 搜索python
inputs.submit()7.5 单选
单选没有特定函数,基本思路就是find_element()定位到需要单选的某个元素,然后click()点击一下即可。
下面咱们就用上面学过的内容来做一次联合操作,来保存百度首页的搜索设置:将“全部语言”改成“简体中文”。
代码如下:
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.by import By
browser = webdriver.Chrome(
service=Service(r'D:\software\PyCharmLib\chromedriver.exe'))
# 固定窗口大小,方便浏览
browser.set_window_size(1260, 925)
# 访问百度首页
browser.get('https://www.baidu.com/')
time.sleep(1)
# 悬停操作
div_element = browser.find_element(By.ID, 's-usersetting-top')
ActionChains(browser).move_to_element(div_element).perform()
time.sleep(1)
# 获取搜索设置按钮,并点击
browser.find_element(By.XPATH, '//div[@class="s-user-setting-pfmenu"]')\
.find_element(By.XPATH, '//a[1]/span').click()
time.sleep(1)
# 在设置中将语言范围设置为仅简体中文
browser.find_element(By.ID, 'SL_1').click()
time.sleep(1)
# 保存设置
browser.find_element(By.XPATH, '//div[@id="se-setting-7"]/a[2]').click()
time.sleep(1)
# 关闭确认窗口
alert = browser.switch_to.alert
alert.accept()上面都有注释,就不再累述了。除了 确认Alert窗口 之外其他上面都已经学过了。
7.6 多选
多选一样没有特定的函数,方法也跟单选一样是先定位在点击,只是多选可以遍历操作。这里也不再举例子说明了,大家举一反三亲自动手试试。
7.7 下拉框 - Select
想操作下拉框,我们就需要借助 Select 模块帮忙了。先导入该模块:
from selenium.webdriver.support.select import Select
然后我们再来总结下Select模块给咱们带来的新操作:
1、定位选择框的方法:
select_by_index() # 通过索引定位,index从0开始算
select_by_value() # 通过option中value属性的值来定位
select_by_visible_text() # 通过文本值定位,即下拉框的值
2、获取基本信息
voptions # 返回select元素所有options
all_selected_options # 返回select元素中已选的所有options
first_selected_options # 返回select元素中已选的第一个options
3、取消已选中项的方法:
deselect_all() # 取消已选中的所有项
deselect_by_index() # 取消已选中的等于index索引的项
deselect_by_value() # 取消已选中的等于value值的项
deselect_by_visible_text() # 取消已选中的等于文本值的项
下面咱们来实战,就会更容易明白各个方法和属性的作用和效果,由于临时找不到合适的教材,咱们直接准备了一个html案例,fruit.html,代码如下:
selenium select test
然后就是我们通过 Select模块 操作下拉框的代码
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.select import Select
# 初始化浏览器,并打开本地文件
browser = webdriver.Chrome(
service=Service(r'D:\software\PyCharmLib\chromedriver.exe'))
browser.get('file://C:/Users/root/Desktop/fruit.html')
time.sleep(1)
# 选中下拉框元素
sel = Select(browser.find_element(By.NAME, 'fruit'))
num = 0
for i in sel.options:
num = num+1
print('选项%d:%s'%(num, i.text))
# 通过index定位
sel.select_by_index(1)
print('第一个选中项:%s'%(sel.first_selected_option.text))
time.sleep(2)
# 通过value定位
sel.select_by_value('banana')
for j in sel.all_selected_options:
print('全部选中项:%s'%j.text)
time.sleep(2)
# 通过文本定位
sel.select_by_visible_text('西瓜')
time.sleep(2)下面就是我们的运行结果:

基本上对于元素的处理基本就到这里了,后面还有关于元素属性的增删改操作。
8 处理弹窗
通过上面7.5单选的示例代码在运行的时候就会碰到有alert弹窗提示,下面我们就详细介绍alert提示弹窗、确认confirm弹窗、输入内容prompt弹窗。顺便说下核心方法主要有:
text() # 获取文本值
accept() # 点击“确认”
dismiss() # 点击“取消”或者是关闭叉掉对话框
send_keys() # 输入文本值 ,仅限于prompt,在alert和confirm上没有输入框
下面直接上示例,在我们本地运行 alert.html ,代码如下:
selenium alert
test_Alert
test_Confirm
test_Prompt
然后,我们对不同弹窗间的处理:
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 初始化浏览器,并打开本地文件
browser = webdriver.Chrome(
service=Service(r'D:\software\PyCharmLib\chromedriver.exe'))
browser.get('file://C:/Users/root/Desktop/alert.html')
time.sleep(1)
# 用于提示
def test_alert():
# 定位元素
browser.find_element(By.ID, 'alert').click()
# 切换到alert
alert = browser.switch_to.alert
print(alert.text) # 打印alert内容
time.sleep(3)
alert.accept() # 相当于点击确认按钮
# 用于确认
def test_confirm():
# 定位元素
browser.find_element(By.ID, 'confirm').click()
# 切换到alert
confirm = browser.switch_to.alert
# 打印alert内容
print(confirm.text)
time.sleep(3)
# 相当于点击确认按钮
confirm.accept()
# 相当于点击取消按钮
# confirm.dismiss()
# 用于输入内容
def test_prompt():
# 定位元素
browser.find_element(By.ID, 'prompt').click()
# 切换到alert
prompt = browser.switch_to.alert
print(prompt.text) # 打印alert内容
# 输入文本
prompt.send_keys('记得点个赞!!!')
time.sleep(3)
prompt.accept() # 相当于点击确认按钮
time.sleep(3)
# confirm.dismiss() # 相当于点击取消按钮
test_alert()
test_confirm()
test_prompt()
9 窗口切换
当我们实际应用之中很容易因为网站的流程或者我们爬取的业务过程中产生很多的窗口,这时候我们要切换窗口进行操作,所以下面讲解下同一页面不同子页面的切换、同一浏览器不同选项卡窗口的切换。
9.1 父子页面切换
switch_to.frame() # 切换同一页面的不同子页面
switch_to.parent_frame() # 切换回父页面
9.2 选项卡窗口切换
新建标签页:browser.execute_script('window.open("url","_blank");')
关闭标签页:browser.close()
切换标签页:browser.switch_to.window()
显示全部标签页:browser.window_handles(返回当前浏览器的所有窗口的句柄)
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
options = Options()
options.add_argument('--disable-gpu')
options.add_argument('lang=zh_CN.UTF-8')
# 初始化浏览器,并打开百度
browser = webdriver.Chrome(
service=Service(r'D:\software\PyCharmLib\chromedriver.exe'),
options=options)
browser.get('https://www.baidu.com')
time.sleep(1)
# 创建新标签页,打开csdn
browser.execute_script('window.open("https://csdn.net","_blank");')
print(browser.window_handles)
time.sleep(3)
# 切换回百度首页
browser.switch_to.window(browser.window_handles[0])
time.sleep(2)
# 再切换回csdn首页
browser.switch_to.window(browser.window_handles[-1])
time.sleep(2)
# 关闭当前页面,此时window的句柄还在csdn首页
browser.close()
# 切换回csdn首页,这时句柄才是百度页面
browser.switch_to.window(browser.window_handles[0])10 模拟鼠标操作
上面所有内容都是讲如何模拟浏览器操作的,当然我们有时也要模拟鼠标和键盘的操作,这里就先讲模拟鼠标操作。通过ActionChains模块即可实现鼠标左键点击、右键点击、双击、拖拽、悬停等。
from selenium.webdriver.common.action_chains import ActionChains
由于部分内容重复出现,所以下面代码就只显示核心部分+注释说明。
10.1 左键点击 - click()
其实就是我们上面经常用到的click()函数,这里就不累赘了。
10.2 右键点击 - context_click()
# ActionChains(browser)将browser作为参数传入ActionChains类中调用
# context_click(元素)对相应元素鼠标右键操作
# perform()类似于动作的提前准备
ActionChains(browser).context_click(元素).perform()10.3 双击 - double_click()
ActionChains(browser).double_click(元素).perform()10.4 悬停 - move_to_element()
ActionChains(browser).move_to_element(元素).perform()10.5 拖拽 - drag_and_drop()
这是一个可以帮助我们处理滑动验证码的好方法,但是这里并不打算重点讲这部分内容,有兴趣的可以看看我其他文章如何实现的。
ActionChains(browser).drag_and_drop(被拖元素,被拽到的元素).perform()10.6 定位移动 - move_by_offset()
通过拖拽可以处理好验证码,但是对于视频的控件有时不太理想,例如进度,这时候就需要我们计算定位进行点击。重点:move_by_offset()中使用坐标都是针对上一步的计算的,若不想计算,可使用reset_actions() 重置为(0,0)
# 当执行reset_actions后,x和y就是按浏览器左上角位置计算
# 不执行reset_actions,并且有其他动作时,以当前位置增加x和y的量计算位置
ActionChains(driver).move_by_offset(x, y).click().perform()
# 重置定位
action.reset_actions()如果不注意位置的计算,很容易遇到报错:move target out of bounds !
11 模拟键盘操作
既然有模拟鼠标操作,就会有模拟键盘操作了,但是使用的模块不一样,这次模拟键盘操作用的是Keys()模块,然后再通过send_keys()、key_down()、key_up()等函数搭配使用。
from selenium.webdriver.common.keys import Keys
11.1 常用的键盘按钮
Keys.BACK_SPACE # 删除键
Keys.SPACE # 空格
Keys.TAB # 制表键
Keys.ESCAPE # 回退键
Keys.ENTER # 回车键
Keys.ALT # alt键
Keys.CONTROL # ctrl键
Keys.SHIRT # shirt键
Keys.F1...Keys.F12 # f1到f12键
11.2 常用组合按键
send_keys(Keys.CONTROL, 'a') # 全选,ctrl+a
send_keys(Keys.CONTROL, 'x') # 裁剪,ctrl+x
send_keys(Keys.CONTROL, 'c') # 复制,ctrl+c
send_keys(Keys.CONTROL, 'v') # 粘贴,ctrl+v
敲黑板:如果使用上面方法没有效果的话,建议使用下面写法,完全模拟真实操作。
(类似平时先按住ctrl键,再松开)
ActionChains(driver).key_down(Keys.CONTROL).send_keys('a').key_up(Keys.CONTROL)
.perform()
12 加载等待
在做数据收集(python爬虫)的时候,每个网站打开后加载内容的时间都不是固定的,一旦我们在元素未加载出来前就操作,就会报错:找不到相应元素。那这时候我们就可以引入我们等待加载的技术了,平时测试的时候可以用 time.sleep()来强制固定时间等待,生产环境下就需要用更高级点的implicitly_wait()来固定时间等待页面元素全部加载完成,最推荐的还是使用WebDriverWait特定条件加固定时间来判断等待的结果。
12.1 强制等待
在driver.get(url)执行后触发即可,也可在其他操作后设置等待,防止报错,使用time.sleep()控制。
12.2 implicitly_wait()等待
# 等待页面元素全部加载出来,时间为5秒
driver.implicitly_wait(5) 12.3 WebDriverWait等待【推荐】
在这里我们需要用到WebDriverWait模块,以及EC模块。
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
WebDriverWait()的用法说明:
webwait = WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)- driver:浏览器驱动
- timeout:超时时间,秒
- poll_frequency:检测频率,默认是0.5秒一次
- ignored_exceptions:超时后的报错信息,默认是
NoSuchElementException异常
WebDriverWait().until()的用法说明:
当某元素出现或什么条件成立则继续执行
webwait.until(method,msg='')- method:在等待期间,每隔一段时间调用这个传入的方法,直到返回值不是False
- msg:如果超时,抛出
TimeoutException,将msg传入异常
WebDriverWait().until_not()的用法说明:
当某元素消失或什么条件不成立则继续执行,与until()相反。
webwait.until_not(method,msg='')使用参考示例:
webwait = WebDriverWait(browser, 6)
c = webwait.until(EC.presence_of_element_located((By.ID, 'ym')))
c.click()13 补充内容
13.1 Javascript调用
这里简单列出几个常用的,有兴趣的可以自行看下javascript的用法。
# 下拉滚动条
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')
# 弹出提示框
driver.execute_script('alert("到底了。")')
# 修改元素属性
driver.execute_script("arguments[0].setAttribute(arguments[1],arguments[2])", 元素, 属性名, 属性值)13.2 Cookie调用
# 添加cookie
browser.add_cookie(cookie_dict=)
# 获取某个cookie
browser.get_cookie(name=)
# 获取全部cookie
browser.get_cookies()
# 删除某个cookie
browser.delete_cookie(name=)
# 删除全部cookie
browser.delete_all_cookies()13.3 反屏蔽
一般来讲,使用selenium访问某个网址(浏览器以Chrome为例),都会有Chrome正受到自动测试软件的控制的提示
检测的基本原理:
检测当前浏览器窗口下的window.navigator对象是否包含webdriver这个属性。因为在正常使用浏览器的情况下,这个属性是undefined的,然而,一旦我们使用了selenium,selenium会给Window.navigator设置webdriver属性,很多网站就通过JavaScript判断,如果webdriver存在就直接屏蔽。
解决方法一:修改window.navigator.webdriver关键字返回结果
def chrome_driver():
option = webdriver.ChromeOptions()
# 无头模式,隐藏运行
option.add_argument('--headless')
# 沙盒模式
option.add_argument('--no-sandbox')
# 禁用gpu加速(过慢时可考虑移除此项)
option.add_argument('--disable-gpu')
option.add_argument('--disable-dev-shm-usage')
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option('useAutomationExtension', False)
drivers = webdriver.Chrome(options=option)
drivers.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': 'Object.defineProperty(navigator, "webdriver", {get:()=>undefined})'
})
return drivers
driver = chrome_driver()
driver.get('https://baidu.com')此方法有效性比较局限。
解决方法二: 使用stealth.min.js文件
stealth.min.js文件下载:点击下载-CSDN
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
import time
options = Options()
options.add_argument("--headless")
# driverurl自行替换浏览器驱动
driver = Chrome(service='driverurl', options=options)
with open('/stealth.min.js') as f:
js = f.read()
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": js
})
解决方法三: undetected_chromedriver
undetected_chromedriver的源码地址
可自动下载浏览器驱动,可以防止浏览器特征被识别,基本可以解决selenium被识别的问题。
import undetected_chromedriver as uc
driver = uc.Chrome()
driver.get('https://nowsecure.nl')
13.4 控制加载内容,提升速度
在实际使用中,如果使用浏览器的“检查”功能进行网页的逆向工程不是很复杂,就最好使用浏览器的“检查”功能。不过,也有些方法可以用Selenium控制浏览器加载的内容,从而加快Selenium的爬取速度。
13.4.1 控制CSS加载
# 控制 css
from selenium import webdriver
fp = webdriver.FirefoxProfile()
fp.set_preference("permissions.default.stylesheet",2)
driver = webdriver.Firefox(firefox_profile=fp,
executable_path = r'C:\Users\santostang\Desktop\geckodriver.exe')
# 把上述地址改成你电脑中geckodriver.exe程序的地址
driver.get("http://www.santostang.com/2018/07/04/hello-world/")13.4.2 控制图片加载
# 限制图片的加载
from selenium import webdriver
fp = webdriver.FirefoxProfile()
fp.set_preference("permissions.default.image", 2)
driver = webdriver.Firefox(firefox_profile=fp,
executable_path=r'C:\Users\santostang\Desktop\geckodriver.exe')
# 把上述地址改成你电脑中geckodriver.exe程序的地址
driver.get("https://www.santostang.com/2018/07/04/hello-world/")13.4.3 控制js的运行
# 限制JavaScript的执行
from selenium import webdriver
fp = webdriver.FirefoxProfile()
fp.set_preference("javascript.enabled", False)
driver = webdriver.Firefox(firefox_profile=fp,
executable_path=r'C:\Users\santostang\Desktop\geckodriver.exe')
# 把上述地址改成你电脑中geckodriver.exe程序的地址
driver.get("http://www.santostang.com/2018/07/04/hello-world/")13.5 options配置
参考文献:请点击
options.add_argument(‘headless’) # 无头模式
options.add_argument(‘window-size={}x{}’.format(width, height)) # 直接配置大小和set_window_size一样
options.add_argument(‘disable-gpu’) # 禁用GPU加速
options.add_argument(‘proxy-server={}’.format(self.proxy_server)) # 配置代理
options.add_argument(’–no-sandbox’) # 沙盒模式运行
options.add_argument(’–disable-setuid-sandbox’) # 禁用沙盒
options.add_argument(’–disable-dev-shm-usage’) # 大量渲染时候写入/tmp而非/dev/shm
options.add_argument(’–user-data-dir={profile_path}’.format(profile_path)) # 用户数据存入指定文件
options.add_argument('no-default-browser-check) # 不做浏览器默认检查
options.add_argument("–disable-popup-blocking") # 允许弹窗
options.add_argument("–disable-extensions") # 禁用扩展
options.add_argument("–ignore-certificate-errors") # 忽略不信任证书
options.add_argument("–no-first-run") # 初始化时为空白页面
options.add_argument(’–start-maximized’) # 最大化启动
options.add_argument(’–disable-notifications’) # 禁用通知警告
options.add_argument(’–enable-automation’) # 通知(通知用户其浏览器正由自动化测试控制)
options.add_argument(’–disable-xss-auditor’) # 禁止xss防护
options.add_argument(’–disable-web-security’) # 关闭安全策略
options.add_argument(’–allow-running-insecure-content’) # 允许运行不安全的内容
options.add_argument(’–disable-webgl’) # 禁用webgl
options.add_argument(’–homedir={}’) # 指定主目录存放位置
options.add_argument(’–disk-cache-dir={临时文件目录}’) # 指定临时文件目录
options.add_argument(‘disable-cache’) # 禁用缓存
options.add_argument(‘excludeSwitches’, [‘enable-automation’]) # 开发者模式
14 写在最后
在此感谢提供学习教材的网站。
CSDN首页:CSDN - 专业开发者社区
百度首页:百度一下,你就知道
技术本无罪,请把爬虫用在正途之上。