
一、前言
在今年初Epic放出了UE5技术演示Demo之后,关于UE5的讨论就一直未曾停止,相关技术讨论主要围绕两个新的feature:全局照明技术Lumen和极高模型细节技术Nanite,已经有一些文章[1][2]比较详细地介绍了Nanite技术。本文主要从UE5的RenderDoc分析和源码出发,结合一些已有的技术资料,旨在能够提供对Nanite直观和总览式的理解,并理清其算法原理和设计思想,不会涉及过多源码级别的实现细节。
二、次世代模型渲染,我们需要什么?
要分析Nanite的技术要点,首先要从技术需求的角度出发。近十年来,3A类游戏的发展都逐渐趋向于两个要点:互动式电影叙事和开放大世界。为了逼真的电影感cutscene,角色模型需要纤毫毕现;为了足够灵活丰富的开放世界,地图尺寸和物件数量呈指数级增长,这两者都大幅度提升了场景精细度和复杂度的要求:场景物件数量既要多,每个模型又要足够精细。
复杂场景绘制的瓶颈通常有两个:
- 每次Draw Call带来的CPU端验证及CPU-GPU之间的通信开销;
- 由于剔除不够精确导致的Overdraw和由此带来的GPU计算资源的浪费;
近年来渲染技术优化往往也都是围绕这两个难题,并形成了一些业内的技术共识。
针对CPU端验证、状态切换带来的开销,我们有了新一代的图形API(Vulkan、DX12和Metal),旨在让驱动在CPU端做更少的验证工作;将不同任务通过不同的Queue派发给GPU(Compute/Graphics/DMA Queue);要求开发者自行处理CPU和GPU之间的同步;充分利用多核CPU的优势多线程向GPU提交命令。得益于这些优化,新一代图形API的Draw Call数量相较于上一代图形API(DX11、OpenGL)提高了一个数量级[3]。
另一个优化方向是减少CPU和GPU之间的数据通讯,以及更加精确地剔除对最终画面没有贡献的三角形。基于这个思路,诞生了GPU Driven Pipeline。关于GPU Driven Pipeline以及剔除的更多内容,可以读一读笔者的这篇文章[4]。
得益于GPU Driven Pipeline在游戏中越来越广泛的应用,把模型的顶点数据进一步切分为更细粒度的Cluster(或者叫做Meshlet),让每个Cluster的粒度能够更好地适应Vertex Processing阶段的Cache大小,并以Cluster为单位进行各类剔除(Frustum Culling、Occulsion Culling和Backface Culling)已经逐渐成为了复杂场景优化的最佳实践,GPU厂商也逐渐认可了这一新的顶点处理流程。
但传统的GPU Driven Pipeline依赖Compute Shader剔除,剔除后的数据需要存储在GPU Buffer内,经由Execute Indirect这类API,把剔除后的Vertex/Index Buffer重新喂给GPU的Graphics Pipeline,无形中增加了一读一写的开销。此外顶点数据也会被重复读取(Compute Shader在剔除前读取以及Graphics Pipeline在绘制时通过Vertex Attribute Fetch读取)。
基于以上的原因,为了进一步提高顶点处理的灵活度,NVidia最先引入了Mesh Shader[5]的概念,希望能够逐步去掉传统顶点处理阶段的一些固定单元(VAF,PD一类的硬件单元),并把这些事交由开发者通过可编程管线(Task Shader/Mesh Shader)处理。


Cluster示意图
传统的GPU Driven Pipeline,剔除依赖CS,剔除的数据通过VRAM向顶点处理管线传递
基于Mesh Shader的Pipeline,Cluster剔除成为了顶点处理阶段的一部分,减少没必要的Vertex Buffer Load/Store
三、这些就够了吗?
至此,模型数、三角形顶点数和面数的问题已经得到了极大的优化改善。但高精度的模型、像素级别的小三角形给渲染管线带来了新的压力:光栅化和重绘(Overdraw)的压力。
软光栅化是否有机会打败硬光栅化?
要弄清楚这个问题,首先需要理解硬件光栅化究竟做了什么,以及它设想的一般应用场景是什么样的,推荐感兴趣的读者读一读这篇文章[6]。简单来说:传统光栅化硬件设计之初,设想的输入三角形大小是远大于一个像素的。基于这样的设想,硬件光栅化的过程通常是层次式的。
以N卡的光栅器为例,一个三角形通常会经历两个阶段的光栅化:Coarse Raster和Fine Raster,前者以一个三角形作为输入,以8x8像素为一个块,将三角形光栅化为若干块(你也可以理解成在尺寸为原始FrameBuffer 1/8*1/8大小的FrameBuffer上做了一次粗光栅化)。
在这个阶段,借由低分辨率的Z-Buffer,被遮挡的块会被整个剔除,N卡上称之为Z Cull;在Coarse Raster之后,通过Z Cull的块会被送到下一阶段做Fine Raster,最终生成用于着色计算的像素。在Fine Raster阶段,有我们熟悉的Early Z。由于Mip-Map采样的计算需要,我们必须知道每个像素相邻像素的信息,并利用采样UV的差分作为Mip-Map采样层级的计算依据。为此,Fine Raster最终输出的并不是一个个像素,而是2x2的小像素块(Pixel Quad)。
对于接近像素大小的三角形来说,硬件光栅化的浪费就很明显了。首先,Coarse Raster阶段几乎是无用的,因为这些三角形通常都是小于8x8的,对于那些狭长的三角形,这种情况更糟糕,因为一个三角形往往横跨多个块,而Coarse Raster不但无法剔除这些块,还会增加额外的计算负担;另外,对于大三角形来说,基于Pixel Quad的Fine Raster阶段只会在三角形边缘生成少量无用的像素,相较于整个三角形的面积,这只是很少的一部分;但对于小三角形来说,Pixel Quad最坏会生成四倍于三角形面积的像素数,并且这些像素也包含在Pixel Shader的执行阶段,使得WARP中有效的像素大大减少。
小三角形由于Pixel Quad造成的光栅化浪费
基于上述的原因,在像素级小三角形这一特定前提下,软光栅化(基于Compute Shader)的确有机会打败硬光栅化。这也正是Nanite的核心优化之一,这一优化使得UE5在小三角形光栅化的效率上提升了3倍[7]。
Deferred Material
重绘的问题长久以来都是图形渲染的性能瓶颈,围绕这一话题的优化也层出不穷。在移动端,有我们熟悉的Tile Based Rendering架构[8];在渲染管线的进化历程中,也先后有人提出了Z-Prepass、Deferred Rendering、Tile Based Rendering以及Clustered Rendering,这些不同的渲染管线框架,实际上都是为了解决同一个问题:当光源超过一定数量、材质的复杂度提升后,如何尽量避免Shader中大量的渲染逻辑分支,以及减少无用的重绘。有关这个话题,可以读一读我的这篇文章[9]。
通常来说,延迟渲染管线都需要一组称之为G-Buffer的Render Target,这些贴图内存储了一切光照计算需要的材质信息。当今的3A游戏中,材质种类往往复杂多变,需要存储的G-Buffer信息也在逐年增加,以2009年的游戏《Kill Zone 2》为例,整个G-Buffer布局如下:

除去Lighting Buffer,实际上G-Buffer需要的贴图数量为4张,共计16 Bytes/Pixel;而到了2016年,游戏《Uncharted 4》的G-Buffer布局如下:


G-Buffer的贴图数量为8张,即32 Bytes/Pixel。也就是说,相同分辨率的情况下,由于材质复杂度和逼真度的提升,G-Buffer需要的带宽足足提高了一倍,这还不考虑逐年提高的游戏分辨率的因素。
对于Overdraw较高的场景,G-Buffer的绘制产生的读写带宽往往会成为性能瓶颈。于是学界提出了一种称之为Visibility Buffer的新渲染管线[10][11]。基于Visibility Buffer的算法不再单独产生臃肿的G-Buffer,而是以带宽开销更低的Visibility Buffer作为替代,Visibility Buffer通常需要这些信息:
(1)Instance ID,表示当前像素属于哪个Instance(16~24 bits);
(2)Primitive ID,表示当前像素属于Instance的哪个三角形(8~16 bits);
(3)Barycentric Coord,代表当前像素位于三角形内的位置,用重心坐标表示(16 bits);
(4)Depth Buffer,代表当前像素的深度(16~24 bits);
(5)Material ID,表示当前像素属于哪个材质(8~16 bits);
以上,我们只需要存储大约8~12 Bytes/Pixel即可表示场景中所有几何体的材质信息,同时,我们需要维护一个全局的顶点数据和材质贴图表,表中存储了当前帧所有几何体的顶点数据,以及材质参数和贴图。
在光照着色阶段,只需要根据Instance ID和Primitive ID从全局的Vertex Buffer中索引到相关三角形的信息;进一步地,根据该像素的重心坐标,对Vertex Buffer内的顶点信息(UV,Tangent Space等)进行插值得到逐像素信息;再进一步地,根据Material ID去索引相关的材质信息,执行贴图采样等操作,并输入到光照计算环节最终完成着色,有时这类方法也被称为Deferred Texturing。
下面是基于G-Buffer的渲染管线流程:
这是基于Visibility-Buffer的渲染管线流程: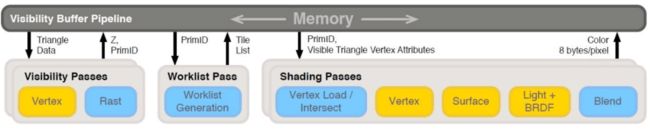
直观地看,Visibility Buffer减少了着色所需要信息的储存带宽(G-Buffer -> Visibility Buffer);此外,它将光照计算相关的几何信息和贴图信息读取延迟到了着色阶段,于是那些屏幕不可见的像素不必再读取这些数据,而是只需要读取顶点位置即可。基于这两个原因,Visibility Buffer在分辨率较高的复杂场景下,带宽开销相比传统G-Buffer大大降低。但同时维护全局的几何和材质数据,增加了引擎设计的复杂度,同时也降低了材质系统的灵活度,有时候还需要借助Bindless Texture[12]等尚未全硬件平台支持的Graphics API,不利于兼容。
四、Nanite中的实现
罗马绝非一日建成。任何成熟的学术和工程领域孕育出的技术突破都一定有前人的思考和实践,这也是为什么我们花费了大量的篇幅去介绍相关技术背景。Nanite正是总结前人方案,结合现时硬件的算力,并从下一代游戏技术需求出发得到的优秀工程实践。
它的核心思想可以简单拆解为两大部分:顶点处理的优化和像素处理的优化。其中顶点处理的优化主要是GPU Driven Pipeline的思想;像素处理的优化,是在Visibility Buffer思想的基础上,结合软光栅化完成的。借助UE5 Ancient Valley技术演示的RenderDoc抓帧和相关的源码,我们可以一窥Nanite的技术真面目。整个算法流程如图:
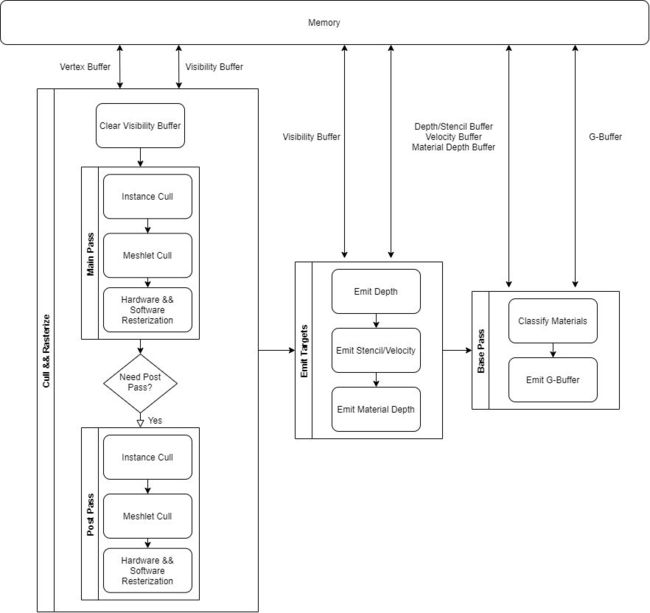
Instance Cull && Persistent Cull
当我们详细地解释了GPU Driven Pipeline的发展历程以后,就不难理解Nanite的实现:每个Nanite Mesh在预处理阶段,会被切成若干Cluster,每个Cluster包含128个三角形,整个Mesh以BVH(Bounding Volume Hierarchy)的形式组织成树状结构,每个叶节点代表一个Cluster。剔除分两步,包含了视锥剔除和基于HZB的遮挡剔除。其中Instance Cull以Mesh为单位,通过Instance Cull的Mesh会将其BVH的根节点送到Persistent Cull阶段进行层次式地剔除(若某个BVH节点被剔除,则不再处理其子节点)。
这就需要考虑一个问题:如何把Persistent Cull阶段的剔除任务数量映射到Compute Shader的线程数量?最简单的方法是给每棵BVH树一个单独的线程,也就是一个线程负责一个Nanite Mesh。但由于每个Mesh的复杂度不同,其BVH树的节点数、深度差异很大,这样的安排会导致每个线程的任务处理时长大不相同,线程间互相等待,最终导致并行性很差;那么能否给每个需要处理的BVH节点分配一个单独的线程呢?这当然是最理想的情形,但实际上我们无法在剔除前预先知道会有多少个BVH节点被处理,因为整个剔除是层次式的、动态的。
Nanite解决这个问题的思路是:设置固定数量的线程,每个线程通过一个全局的FIFO任务队列去取BVH节点进行剔除,若该节点通过了剔除,则把该节点的所有子节点也放进任务队列尾部,然后继续循环从全局队列中取新的节点,直到整个队列为空且不再产生新的节点。这其实是一个多线程并发的经典生产-消费者模式,不同的是,这里的每个线程既充当生产者,又充当消费者。通过这样的模式,Nanite就保证了各个线程之间的处理时长大致相同。
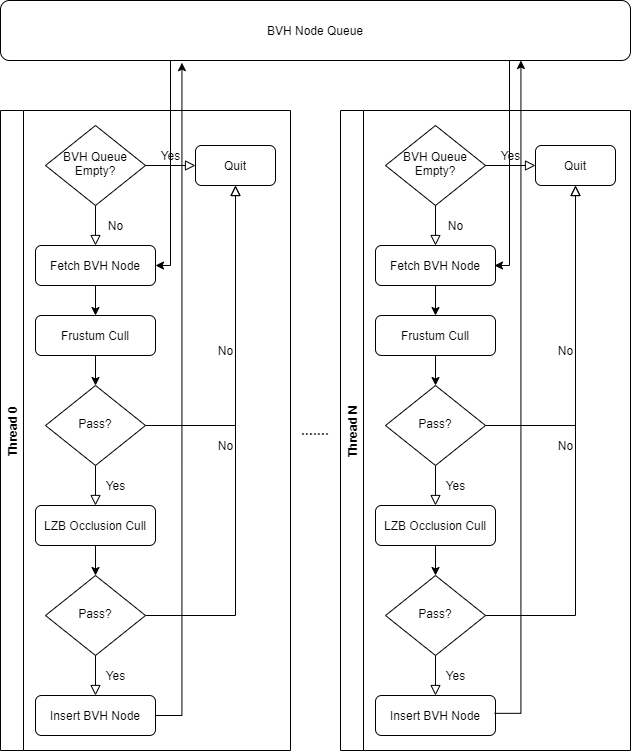
整个剔除阶段分为两个Pass:Main Pass和Post Pass(可以通过控制台变量设置为只有Main Pass)。这两个Pass的逻辑基本是一致的,区别仅仅在于Main Pass遮挡剔除使用的HZB是基于上一帧数据构造的,而Post Pass则是使用Main Pass结束后构建的当前帧的HZB,这样是为了防止上一帧的HZB错误地剔除了某些可见的Mesh。
需要注意的是,Nanite并未使用Mesh Shader,究其原因,一方面是因为Mesh Shader的支持尚未普及;另一方面是由于Nanite使用软光栅化,Mesh Shader的输出仍要写回GPU Buffer再用于软光栅化输入,因此相较于CS的方案并没有太多带宽的节省。
Rasterization
在剔除结束之后,每个Cluster会根据其屏幕空间的大小送至不同的光栅器,大三角形和非Nanite Mesh仍然基于硬件光栅化,小三角形基于Compute Shader写成的软光栅化。Nanite的Visibility Buffer为一张R32G32_UINT的贴图(8 Bytes/Pixel),其中R通道的0~6 bit存储Triangle ID,7~31 bit存储Cluster ID,G通道存储32 bit深度:

Cluster ID

Triangle ID

Depth
整个软光栅化的逻辑比较简单:基于扫描线算法,每个Cluster启动一个单独的Compute Shader,在Compute Shader初始阶段计算并缓存所有Clip Space Vertex Positon到Shared Memory,而后CS中的每个线程读取对应三角形的Index Buffer和变换后的Vertex Position,根据Vertex Position计算出三角形的边,执行背面剔除和小三角形(小于一个像素)剔除,然后利用原子操作完成Z-Test,并将数据写进Visibility Buffer。值得一提的是,为了保证整个软光栅化逻辑的简洁高效,Nanite Mesh不支持带有骨骼动画、材质中包含顶点变换或者Mask的模型。
Emit Targets
为了保证数据结构尽量紧凑,减少读写带宽,所有软光栅化需要的数据都存进了一张Visibility Buffer,但是为了与场景中基于硬件光栅化生成的像素混合,我们最终还是需要将Visibility Buffer中的额外信息写入到统一的Depth/Stencil Buffer以及Motion Vector Buffer当中。这个阶段通常由几个全屏Pass组成:
(1)Emit Scene Depth/Stencil/Nanite Mask/Velocity Buffer,这一步根据最终场景需要的RenderTarget数据,最多输出四个Buffer,其中Nanite Mask用0/1表示当前像素是普通Mesh还是Nanite Mesh(根据Visibility Buffer对应位置的Cluster ID得到),对于Nanite Mesh Pixel,将Visibility Buffer中的Depth由UINT转为float写入Scene Depth Buffer,并根据Nanite Mesh是否接受贴花,将贴花对应的Stencil Value写入Scene Stencil Buffer,并根据上一帧位置计算当前像素的Motion Vector写入Velocity Buffer,非Nanite Mesh则直接Discard跳过。

Nanite Mask

Velocity Buffer
 Scene Depth/Stencil Buffer
Scene Depth/Stencil Buffer
(2)Emit Material Depth,这一步将生成一张Material ID Buffer,稍有不同的是,它并未存储在一张UINT类型的贴图,而是将UINT类型的Material ID转为float存储在一张格式为D32S8的Depth/Stencil Target上(稍后我们会解释这么做的理由),理论上最多支持2^32种材质(实际上只有14 bits用于存储Material ID),而Nanite Mask会被写入Stencil Buffer中。

Material Depth Buffer
Classify Materials && Emit G-Buffer
我们已经详细地介绍了Visibility Buffer的原理,在着色计算阶段的一种实现是维护一个全局材质表,表中存储材质参数以及相关贴图的索引,根据每个像素的Material ID找到对应材质,解析材质信息,利用Virtual Texture或者Bindless Texture/Texture Array等技术方案获取对应的贴图数据。对于简单的材质系统这是可行的,但是UE包含了一套极其复杂的材质系统,每种材质有不同的Shading Model,同种Shading Model下各个材质参数还可以通过材质编辑器进行复杂地连线计算,这种基于连连看动态生成材质Shader Code的模式显然无法用上述方案实现。
为了保证每种材质的Shader Code仍然能基于材质编辑器动态生成,每种材质的PS Shader至少要执行一次,但我们只有屏幕空间的材质ID信息,于是不同于以往逐个物体绘制地同时运行其对应的材质Shader(Object Space),Nanite的材质Shader是在Screen Space执行的,以此将可见性计算和材质参数计算解耦,这也是Deferred Material名字的由来。但这又引发了新的性能问题:场景中的材质动辄成千上万,每个材质都用一个全屏Pass去绘制,则重绘带来的带宽压力势必非常高,如何减少无意义的重绘就成为了新的挑战。
为此,Nanite在Base Pass绘制阶段并不是每种材质一个全屏Pass,而是将屏幕空间分成若干8x8的块,比如屏幕大小为800x600,则每种材质绘制时生成100x75个块,每块对应屏幕位置。为了能够整块地剔除,在Emit Targets之后,Nanite会启动一个CS用于统计每个块内包含的Material ID的种类。由于Material ID对应的Depth值预先是经过排序的,所以这个CS会统计每个8x8的块内Material Depth的最大最小值作为Material ID Range存储在一张R32G32_UINT的贴图中:

Material ID Range
有了这张图之后,每种材质在其VS阶段,都会根据自身块的位置去采样这张贴图对应位置的Material ID Range,若当前材质的Material ID处于Range内,则继续执行材质的PS;否则表示当前块内没有像素使用该材质,则整块可以剔除,此时只需将VS的顶点位置设置为NaN,GPU就会将对应的三角形剔除。由于通常一个块内的材质种类不会太多,这种方法可以有效地减少不必要的Overdraw。
实际上通过分块分类减少材质分支,进而简化渲染逻辑的思路也并非第一次被提出,比如《Uncharted 4》在实现他们的延迟光照时[13],由于材质包含多种Shading Model,为了避免每种Shading Model启动一个单独的全屏CS,他们也将屏幕分块(16x16),并统计了块内Shading Model的种类,根据块内Shading Model的Range给每个块单独启动一个CS,取Range内对应的Lighting Shader,以此避免多遍全屏Pass或者一个包含大量分支逻辑的Uber Shader,从而大幅度提高了延迟光照的性能。

Uncharted 4中分块统计Shading Model Range
在完成了逐块地剔除后,Material Depth Buffer就派上了用场。在Base Pass PS阶段,Material Depth Buffer被设置为Depth/Stencil Target,同时Depth/Stencil Test被打开,Compare Function设置为Equal。只有当前像素的Material ID和待绘制的材质ID相同(Depth Test Pass)且该像素为Nanite Mesh(Stencil Test Pass)时才会真正执行PS,于是借助硬件的Early Z/Stencil我们完成了逐像素的材质ID剔除,整个绘制和剔除的原理见下图:

红色表示被剔除的区域
整个Base Pass分为两部分,首先绘制非Nanite Mesh的G-Buffer,这部分仍然在Object Space执行,和UE4的逻辑一致;之后按照上述流程绘制Nanite Mesh的G-Buffer,其中材质需要的额外VS信息(UV,Normal,Vertex Color等)通过像素的Cluster ID和Triangle ID索引到相应的Vertex Position,并变换到Clip Space,根据Clip Space Vertex Position和当前像素的深度值求出当前像素的重心坐标以及Clip Space Position的梯度(DDX/DDY),将重心坐标和梯度代入各类Vertex Attributes中插值即可得到所有的Vertex Attributes及其梯度(梯度可用于计算采样的Mip Map层级)。
至此,我们分析了Nanite的技术背景和完整实现逻辑。
参考
[1] 《A Macro View of Nanite》
[2] 《UE5 Nanite实现浅析》
[3] 《Vulkan API Overhead Test Added to 3DMark》
[4] 《剔除:从软件到硬件》
[5] 《Mesh Shading: Towards Greater Efficiency of Geometry Processing》
[6] 《A Trip Through the Graphics Pipeline》
[7] 《Nanite | Inside Unreal》
[8] 《Tile-Based Rendering》
[9] 《游戏引擎中的渲染管线》
[10] 《The Visibility Buffer: A Cache-Friendly Approach to Deferred Shading》
[11] 《Triangle Visibility Buffer》
[12] 《Bindless Texture》
[13] 《Deferred Lighting in Uncharted 4》
这是侑虎科技第983篇文章,感谢作者洛城供稿。欢迎转发分享,未经作者授权请勿转载。如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:793972859)
作者主页:https://www.zhihu.com/people/...,目前就职于腾讯游戏研发效能部引擎中台部门,再次感谢洛城的分享,如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群:793972859)