00 预训练语言模型的前世今生(全文 24854 个词)
预训练语言模型的前世今生 - 从Word Embedding到BERT
本篇文章共 25027 个词,一个字一个字手码的不容易,转载请标明出处:
预训练语言模型的前世今生 - 从Word Embedding到BERT - 二十三岁的有德
文章目录
- 一、预训练
-
- 1.1 图像领域的预训练
- 1.2 预训练的思想
- 二、语言模型
-
- 2.1 统计语言模型
- 三、词向量
-
- 3.1 独热(Onehot)编码
- 3.2 Word Embedding
- 四、Word2Vec 模型
- 五、自然语言处理的预训练模型
- 六、RNN 和 LSTM
-
- 6.1 RNN
- 6.2 RNN 的梯度消失问题
- 6.3 LSTM
- 6.4 LSTM 解决 RNN 的梯度消失问题
- 七、ELMo 模型
-
- 7.1 ELMo 的预训练
- 7.2 ELMo 的 Feature-based Pre-Training
- 八、Attention
-
- 8.1 人类的视觉注意力
- 8.2 Attention 的本质思想
- 8.3 Self Attention 模型
- 8.4 Self Attention 和 RNN、LSTM 的区别
- 8.5 Masked Self Attention 模型
- 8.6 Multi-head Self Attention 模型
- 九、Position Embedding
- 十、Transformer
-
- 10.1 Transformer 的结构
- 10.2 Encoder
- 10.3 Decoder
- 10.4 Transformer 输出结果
- 十一、Transformer 动态流程展示
-
- 11.1 为什么 Decoder 需要做 Mask
- 11.2 为什么 Encoder 给予 Decoders 的是 K、V 矩阵
- 十二、GPT 模型
-
- 12.1 GPT 模型的预训练
- 12.2 GPT 模型的 Fine-tuning
- 十三、BERT 模型
-
- 13.1 BERT:公认的里程碑
- 13.2 BERT 的结构:强大的特征提取能力
- 13.3 BERT 之无监督训练
- 13.4 BERT之语言掩码模型(MLM)
- 13.5 BERT 之下句预测(NSP)
- 13.6 BERT 之输入表示
- 十四、BERT 下游任务改造
-
- 14.1 句对分类
- 14.2 单句分类
- 14.3 文本问答
- 14.4 单句标注
- 14.5 BERT效果展示
- 十五、预训练语言模型总结
- 十六、参考资料
Bert 最近很火,应该是最近最火爆的 AI 进展,网上的评价很高,从模型创新角度看一般,创新不算大。但是架不住效果太好了,基本刷新了很多 NLP 的任务的最好性能,有些任务还被刷爆了,这个才是关键。另外一点是 Bert 具备广泛的通用性,就是说绝大部分 NLP 任务都可以采用类似的两阶段模式直接去提升效果,这个第二关键。客观的说,把 Bert 当做最近两年 NLP 重大进展的集大成者更符合事实。
本文的主题是预训练语言模型的前世今生,会大致说下 NLP 中的预训练技术是一步一步如何发展到 Bert 模型的,从中可以很自然地看到 Bert 的思路是如何逐渐形成的,Bert 的历史沿革是什么,继承了什么,创新了什么,为什么效果那么好,主要原因是什么,以及为何说模型创新不算太大,为何说 Bert 是近年来 NLP 重大进展的集大成者。
预训练语言模型的发展并不是一蹴而就的,而是伴随着诸如词嵌入、序列到序列模型及 Attention 的发展而产生的。
DeepMind 的计算机科学家 Sebastian Ruder 给出了 21 世纪以来,从神经网络技术的角度分析,自然语言处理的里程碑式进展,如下表所示:
| 年份 | 2013 年 | 2014 年 | 2015 年 | 2016 年 | 2017 年 |
|---|---|---|---|---|---|
| 技术 | word2vec | GloVe | LSTM/Attention | Self-Attention | Transformer |
| 年份 | 2018 年 | 2019 年 | 2020 年 |
|---|---|---|---|
| 技术 | GPT/ELMo/BERT/GNN | XLNet/BoBERTa/GPT-2/ERNIE/T5 | GPT-3/ELECTRA/ALBERT |
本篇文章将会通过上表显示的 NLP 中技术的发展史一一叙述,由于 19 年后的技术大都是 BERT 的变体,在这里不会多加叙述,读者可以自行加以了解。
一、预训练
1.1 图像领域的预训练
在介绍图像领域的预训练之前,我们首先介绍下卷积神经网络(CNN),CNN 一般用于图片分类任务,并且CNN 由多个层级结构组成,不同层学到的图像特征也不同,越浅的层学到的特征越通用(横竖撇捺),越深的层学到的特征和具体任务的关联性越强(人脸-人脸轮廓、汽车-汽车轮廓),如下图所示:

由此,当领导给我们一个任务:阿猫、阿狗、阿虎的图片各十张,然后让我们设计一个深度神经网络,通过该网络把它们三者的图片进行分类。
对于上述任务,如果我们亲手设计一个深度神经网络基本是不可能的,因为深度学习一个弱项就是在训练阶段对于数据量的需求特别大,而领导只给我们合计三十张图片,显然这是不够的。
虽然领导给我们的数据量很少,但是我们是否可以利用网上现有的大量已做好分类标注的图片。比如 ImageNet 中有 1400 万张图片,并且这些图片都已经做好了分类标注。
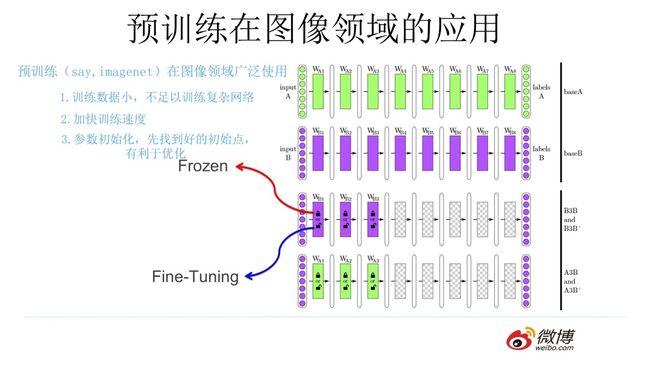
上述利用网络上现有图片的思想就是预训练的思想,具体做法就是:
- 通过 ImageNet 数据集我们训练出一个模型 A
- 由于上面提到 CNN 的浅层学到的特征通用性特别强,我们可以对模型 A 做出一部分改进得到模型 B(两种方法):
- 冻结:浅层参数使用模型 A 的参数,高层参数随机初始化,浅层参数一直不变,然后利用领导给出的 30 张图片训练参数
- 微调:浅层参数使用模型 A 的参数,高层参数随机初始化,然后利用领导给出的 30 张图片训练参数,但是在这里浅层参数会随着任务的训练不断发生变化
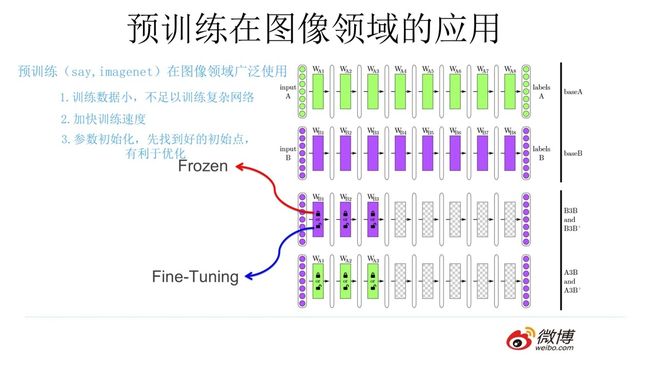
通过上述的讲解,对图像预训练做个总结(可参照上图):对于一个具有少量数据的任务 A,首先通过一个现有的大量数据搭建一个 CNN 模型 A,由于 CNN的浅层学到的特征通用性特别强,因此在搭建一个 CNN 模型 B,其中模型 B 的浅层参数使用模型 A 的浅层参数,模型 B 的高层参数随机初始化,然后通过冻结或微调的方式利用任务 A 的数据训练模型 B,模型 B 就是对应任务 A 的模型。
1.2 预训练的思想
有了图像领域预训练的引入,我们在此给出预训练的思想:任务 A 对应的模型 A 的参数不再是随机初始化的,而是通过任务 B 进行预先训练得到模型 B,然后利用模型 B 的参数对模型 A 进行初始化,再通过任务 A 的数据对模型 A 进行训练。注:模型 B 的参数是随机初始化的。
二、语言模型
想了解预训练语言模型,首先得了解什么是语言模型。
语言模型通俗点讲就是**计算一个句子的概率。**也就是说,对于语言序列 w 1 , w 2 , ⋯ , w n w_1,w_2,\cdots,w_n w1,w2,⋯,wn,语言模型就是计算该序列的概率,即 P ( w 1 , w 2 , ⋯ , w n ) P(w_1,w_2,\cdots,w_n) P(w1,w2,⋯,wn)。
下面通过两个实例具体了解上述所描述的意思:
- 假设给定两句话 “判断这个词的磁性” 和 “判断这个词的词性”,语言模型会认为后者更自然。转化成数学语言也就是: P ( 判断,这个,词,的,词性 ) > P ( 判断,这个,词,的,磁性 ) P(判断,这个,词,的,词性) \gt P(判断,这个,词,的,磁性) P(判断,这个,词,的,词性)>P(判断,这个,词,的,磁性)
- 假设给定一句话做填空 “判断这个词的____”,则问题就变成了给定前面的词,找出后面的一个词是什么,转化成数学语言就是: P ( 词性 ∣ 判断,这个,词,的 ) > P ( 磁性 ∣ 判断,这个,词,的 ) P(词性|判断,这个,词,的) \gt P(磁性|判断,这个,词,的) P(词性∣判断,这个,词,的)>P(磁性∣判断,这个,词,的)
通过上述两个实例,可以给出语言模型更加具体的描述:给定一句由 n n n 个词组成的句子 W = w 1 , w 2 , ⋯ , w n W=w_1,w_2,\cdots,w_n W=w1,w2,⋯,wn,计算这个句子的概率 P ( w 1 , w 2 , ⋯ , w n ) P(w_1,w_2,\cdots,w_n) P(w1,w2,⋯,wn),或者计算根据上文计算下一个词的概率 P ( w n ∣ w 1 , w 2 , ⋯ , w n − 1 ) P(w_n|w_1,w_2,\cdots,w_{n-1}) P(wn∣w1,w2,⋯,wn−1)。
下面将介绍语言模型的两个分支,统计语言模型和神经网络语言模型。
2.1 统计语言模型
统计语言模型的基本思想就是计算条件概率。
给定一句由 n n n 个词组成的句子 W = w 1 , w 2 , ⋯ , w n W=w_1,w_2,\cdots,w_n W=w1,w2,⋯,wn,计算这个句子的概率 P ( w 1 , w 2 , ⋯ , w n ) P(w_1,w_2,\cdots,w_n) P(w1,w2,⋯,wn) 的公式如下(条件概率乘法公式的推广,链式法则):
P ( w 1 , w 2 , ⋯ , w n ) = P ( w 1 ) P ( w 2 ∣ w 1 ) P ( w 3 ∣ w 1 , w 2 ) ⋯ p ( w n ∣ w 1 , w 2 , ⋯ , w n − 1 ) = ∏ i P ( w i ∣ w 1 , w 2 , ⋯ , w i − 1 ) \begin{align*} P(w_1,w_2,\cdots,w_n) & = P(w_1)P(w_2|w_1)P(w_3|w_1,w_2)\cdots p(w_n|w_1,w_2,\cdots,w_{n-1}) \\ & = \prod_i P(w_i|w1,w_2,\cdots,w_{i-1}) \end{align*} P(w1,w2,⋯,wn)=P(w1)P(w2∣w1)P(w3∣w1,w2)⋯p(wn∣w1,w2,⋯,wn−1)=i∏P(wi∣w1,w2,⋯,wi−1)
对于上一节提到的 “判断这个词的词性” 这句话,利用上述的公式,可以得到:
P ( 判断,这个,词,的,词性 ) = P ( 判断 ) P ( 这个 ∣ 判断 ) P ( 词 ∣ 判断,这个 ) P ( 的 ∣ 判断,这个,词 ) P ( 词性 ∣ 判断,这个,词,的 ) P ( 判断,这个,词,的,词性 ) \begin{align*} & P(判断,这个,词,的,词性) = \\ & P(判断)P(这个|判断)P(词|判断,这个) \\ & P(的|判断,这个,词)P(词性|判断,这个,词,的)P(判断,这个,词,的,词性) \end{align*} P(判断,这个,词,的,词性)=P(判断)P(这个∣判断)P(词∣判断,这个)P(的∣判断,这个,词)P(词性∣判断,这个,词,的)P(判断,这个,词,的,词性)
对于上一节提到的另外一个问题,当给定前面词的序列 “判断,这个,词,的” 时,想要知道下一个词是什么,可以直接计算如下概率:
P ( w n e x t ∣ 判断,这个,词,的 ) 公式(1) P(w_{next}|判断,这个,词,的)\quad\text{公式(1)} P(wnext∣判断,这个,词,的)公式(1)
其中, w n e x t ∈ V w_{next} \in V wnext∈V 表示词序列的下一个词, V V V 是一个具有 ∣ V ∣ |V| ∣V∣ 个词的词典(词集合)。
对于公式(1),可以展开成如下形式:
P ( w n e x t ∣ 判断,这个,词,的 ) = c o u n t ( w n e x t ,判断,这个,词,的 ) c o u n t ( 判断,这个,词,的 ) 公式(2) P(w_{next}|判断,这个,词,的) = \frac{count(w_{next},判断,这个,词,的)}{count(判断,这个,词,的)} \quad\text{公式(2)} P(wnext∣判断,这个,词,的)=count(判断,这个,词,的)count(wnext,判断,这个,词,的)公式(2)
对于公式(2),可以把字典 V V V 中的多有单词,逐一作为 w n e x t w_{next} wnext,带入计算,最后取最大概率的词作为 w n e x t w_{next} wnext 的候选词。
如果 ∣ V ∣ |V| ∣V∣ 特别大,公式(2)的计算将会非常困难,但是我们可以引入马尔科夫链的概念(当然,在这里只是简单讲讲如何做,关于马尔科夫链的数学理论知识可以自行查看其他参考资料)。
假设字典 V V V 中有 “火星” 一词,可以明显发现 “火星” 不可能出现在 “判断这个词的” 后面,因此(火星,判断,这个,词,的)这个组合是不存在的,并且词典中会存在很多类似于 “火星” 这样的词。
进一步,可以发现我们把(火星,判断,这个,词,的)这个组合判断为不存在,是因为 “火星” 不可能出现在 “词的” 后面,也就是说我们可以考虑是否把公式(1)转化为
P ( w n e x t ∣ 判断,这个,词,的 ) ≈ P ( w n e x t ∣ 词,的 ) 公式(3) P(w_{next}|判断,这个,词,的) \approx P(w_{next}|词,的)\quad\text{公式(3)} P(wnext∣判断,这个,词,的)≈P(wnext∣词,的)公式(3)
公式(3)就是马尔科夫链的思想:假设 w n e x t w_{next} wnext 只和它之前的 k k k 个词有相关性, k = 1 k=1 k=1 时称作一个单元语言模型, k = 2 k=2 k=2 时称为二元语言模型。
可以发现通过马尔科夫链后改写的公式计算起来将会简单很多,下面我们举个简单的例子介绍下如何计算一个二元语言模型的概率。
其中二元语言模型的公式为:
P ( w i ∣ w i − 1 ) = c o u n t ( w i − 1 , w i ) c o u n t ( w i − 1 ) 公式(4) P(w_i|w_{i-1})=\frac{count(w_{i-1},w_i)}{count(w_{i-1})}\quad\text{公式(4)} P(wi∣wi−1)=count(wi−1)count(wi−1,wi)公式(4)
假设有一个文本集合:
“词性是动词”
“判断单词的词性”
“磁性很强的磁铁”
“北京的词性是名词”
对于上述文本,如果要计算 P ( 词性 ∣ 的 ) P(词性|的) P(词性∣的) 的概率,通过公式(4),需要统计 “的,词性” 同时按序出现的次数,再除以 “的” 出现的次数:
P ( 词性 ∣ 的 ) = c o u n t ( 的,词性 ) c o u n t ( 的 ) = 2 3 公式(5) P(词性|的) = \frac{count(的,词性)}{count(的)} = \frac{2}{3}\quad\text{公式(5)} P(词性∣的)=count(的)count(的,词性)=32公式(5)
上述文本集合是我们自定制的,然而对于绝大多数具有现实意义的文本,会出现数据稀疏的情况,例如训练时未出现,测试时出现了的未登录单词。
由于数据稀疏问题,则会出现概率值为 0 的情况(填空题将无法从词典中选择一个词填入),为了避免 0 值的出现,会使用一种平滑的策略——分子和分母都加入一个非 0 正数,例如可以把公式(4)改为:
P ( w i ∣ w i − 1 ) = c o u n t ( w i − 1 , w i ) + 1 c o u n t ( w i − 1 ) + ∣ V ∣ 公式(6) P(w_i|w_{i-1}) = \frac{count(w_{i-1},w_i)+1}{count(w_{i-1})+|V|}\quad\text{公式(6)} P(wi∣wi−1)=count(wi−1)+∣V∣count(wi−1,wi)+1公式(6)
##2.2 神经网络语言模型
上一节简单的介绍了统计语言模型,并且在结尾处讲到统计语言模型存在数据稀疏问题,针对该问题,我们也提出了平滑方法来应对这个问题。
神经网络语言模型则引入神经网络架构来估计单词的分布,并且通过词向量的距离衡量单词之间的相似度,因此,对于未登录单词,也可以通过相似词进行估计,进而避免出现数据稀疏问题。

上图为神经网络语言模型结构图,它的学习任务是输入某个句中单词 w t = b e r t w_t = bert wt=bert 前的 t − 1 t-1 t−1 个单词,要求网络正确预测单词 “bert”,即最大化:
P ( w t = b e r t ∣ w 1 , w 2 , ⋯ , w t − 1 ; θ ) 公式(7) P(w_t=bert|w_1,w_2,\cdots,w_{t-1};\theta)\quad\text{公式(7)} P(wt=bert∣w1,w2,⋯,wt−1;θ)公式(7)
上图所示的神经网络语言模型分为三层,接下来我们详细讲解这三层的作用:
- 神经网络语言模型的第一层,为输入层。首先将前 n − 1 n-1 n−1 个单词用 Onehot 编码(例如:0001000)作为原始单词输入,之后乘以一个随机初始化的矩阵 Q 后获得词向量 C ( w i ) C(w_i) C(wi),对这 n − 1 n-1 n−1 个词向量处理后得到输入 x x x,记作 x = ( C ( w 1 ) , C ( w 2 ) , ⋯ , C ( w t − 1 ) ) x=(C(w_1),C(w_2),\cdots,C(w_{t-1})) x=(C(w1),C(w2),⋯,C(wt−1))
- 神经网络语言模型的第二层,为隐层,包含 h h h 个隐变量, H H H 代表权重矩阵,因此隐层的输出为 H x + d Hx+d Hx+d,其中 d d d 为偏置项。并且在此之后使用 t a n h tanh tanh 作为激活函数。
- 神经网络语言模型的第三层,为输出层,一共有 ∣ V ∣ |V| ∣V∣ 个输出节点(字典大小),直观上讲,每个输出节点 y i y_i yi 是词典中每一个单词概率值。最终得到的计算公式为: y = s o f t m a x ( b + W x + U tanh ( d + H x ) ) y = softmax(b+Wx+U\tanh(d+Hx)) y=softmax(b+Wx+Utanh(d+Hx)),其中 W W W 是直接从输入层到输出层的权重矩阵, U U U 是隐层到输出层的参数矩阵。
三、词向量
在描述神经网络语言模型的时候,提到 Onehot 编码和词向量 C ( w i ) C(w_i) C(wi),但是并没有具体提及他们到底是什么玩意。
由于他们对于未来 BERT 的讲解非常重要,所以在这里重开一章来描述词向量到底是什么,如何表示。
3.1 独热(Onehot)编码
把单词用向量表示,是把深度神经网络语言模型引入自然语言处理领域的一个核心技术。
在自然语言处理任务中,训练集大多为一个字或者一个词,把他们转化为计算机适合处理的数值类数据非常重要。
早期,人们想到的方法是使用独热(Onehot)编码,如下图所示:
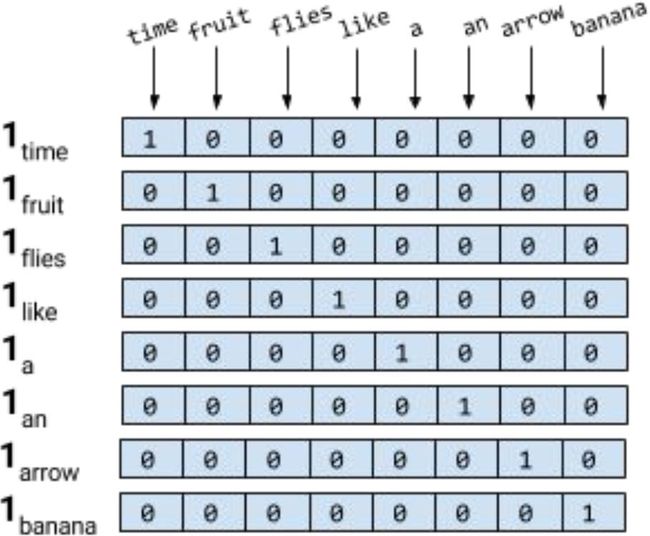
对于上图的解释,假设有一个包含 8 个次的字典 V V V,“time” 位于字典的第 1 个位置,“banana” 位于字典的第 8 个位置,因此,采用独热表示方法,对于 “time” 的向量来说,除了第 1 个位置为 1,其余位置为 0;对于 “banana” 的向量来说,除了第 8 个位置为 1,其余位置为 0。
但是,对于独热表示的向量,如果采用余弦相似度计算向量间的相似度,可以明显的发现任意两者向量的相似度结果都为 0,即任意二者都不相关,也就是说独热表示无法解决词之间的相似性问题。
3.2 Word Embedding
由于独热表示无法解决词之间相似性问题,这种表示很快就被词向量表示给替代了,这个时候聪明的你可能想到了在神经网络语言模型中出现的一个词向量 C ( w i ) C(w_i) C(wi),对的,这个 C ( w i ) C(w_i) C(wi) 其实就是单词对应的 Word Embedding 值,也就是我们这节的核心——词向量。
在神经网络语言模型中,我们并没有详细解释词向量是如何计算的,现在让我们重看神经网络语言模型的架构图:
上图所示有一个 V × m V×m V×m 的矩阵 Q Q Q,这个矩阵 Q Q Q 包含 V V V 行, V V V 代表词典大小,每一行的内容代表对应单词的 Word Embedding 值。
只不过 Q Q Q 的内容也是网络参数,需要学习获得,训练刚开始用随机值初始化矩阵 Q Q Q,当这个网络训练好之后,矩阵 Q Q Q 的内容被正确赋值,每一行代表一个单词对应的 Word embedding 值。
但是这个词向量有没有解决词之间的相似度问题呢?为了回答这个问题,我们可以看看词向量的计算过程:
$$
\begin{bmatrix}
0&0&0&1&0
\end{bmatrix}
\begin{bmatrix}
17&24&1\
23&5&7\
4&6&13\
10&12&19\
11&18&25
\end{bmatrix}
=
\begin{bmatrix}
10&12&19
\end{bmatrix}
\quad\text{公式(8)}
$$
通过上述词向量的计算,可以发现第 4 个词的词向量表示为 [ 10 12 19 ] [10\,12\,19] [101219]。
如果再次采用余弦相似度计算两个词之间的相似度,结果不再是 0 ,既可以一定程度上描述两个词之间的相似度。
下图给了网上找的几个例子,可以看出有些例子效果还是很不错的,一个单词表达成 Word Embedding 后,很容易找出语义相近的其它词汇。

四、Word2Vec 模型
2013 年最火的用语言模型做 Word Embedding 的工具是 Word2Vec ,后来又出了Glove(由于 Glove 和 Word2Vec 的作用类似,并对 BERT 的讲解没有什么帮助,之后不再多加叙述),Word2Vec是怎么工作的呢?看下图:
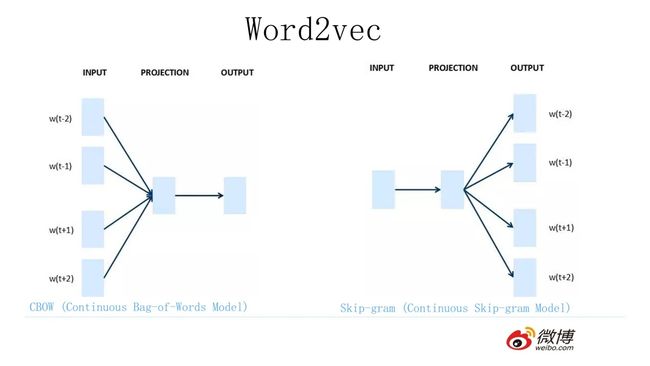
Word2Vec 的网络结构其实和神经网络语言模型(NNLM)是基本类似的,只是这个图长得清晰度差了点,看上去不像,其实它们是亲兄弟。不过这里需要指出:尽管网络结构相近,而且都是做语言模型任务,但是他们训练方法不太一样。
Word2Vec 有两种训练方法:
- 第一种叫 CBOW,核心思想是从一个句子里面把一个词抠掉,用这个词的上文和下文去预测被抠掉的这个词;
- 第二种叫做 Skip-gram,和 CBOW 正好反过来,输入某个单词,要求网络预测它的上下文单词。
而你回头看看,NNLM 是怎么训练的?是输入一个单词的上文,去预测这个单词。这是有显著差异的。
为什么 Word2Vec 这么处理?原因很简单,因为 Word2Vec 和 NNLM 不一样,NNLM 的主要任务是要学习一个解决语言模型任务的网络结构,语言模型就是要看到上文预测下文,而 Word Embedding只是 NNLM 无心插柳的一个副产品;但是 Word2Vec 目标不一样,它单纯就是要 Word Embedding 的,这是主产品,所以它完全可以随性地这么去训练网络。
为什么要讲 Word2Vec 呢?这里主要是要引出 CBOW 的训练方法,BERT 其实跟它有关系,后面会讲解它们之间的关系,当然它们的关系 BERT 作者没说,是我猜的,至于我猜的对不对,你看完这篇文章之后可以自行判断。
五、自然语言处理的预训练模型
突然在文章中插入这一段,其实就是给出一个问题:Word Embedding 这种做法能算是预训练吗?这其实就是标准的预训练过程。要理解这一点要看看学会 Word Embedding 后下游任务是怎么使用它的。
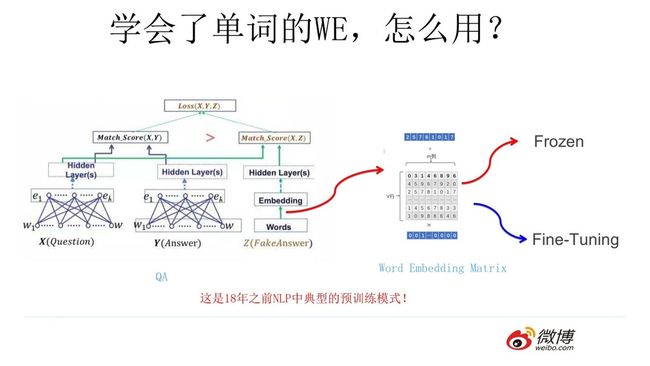
假设如上图所示,我们有个NLP的下游任务,比如 QA,就是问答问题,所谓问答问题,指的是给定一个问题 X,给定另外一个句子 Y,要判断句子 Y 是否是问题 X 的正确答案。
问答问题假设设计的网络结构如上图所示,这里不展开讲了,懂得自然懂,不懂的也没关系,因为这点对于本文主旨来说不关键,关键是网络如何使用训练好的 Word Embedding 的。
它的使用方法其实和前面讲的 NNLM 是一样的,句子中每个单词以 Onehot 形式作为输入,然后乘上学好的 Word Embedding 矩阵 Q,就直接取出单词对应的 Word Embedding 了。
这乍看上去好像是个查表操作,不像是预训练的做法是吧?其实不然,那个Word Embedding矩阵Q其实就是网络 Onehot 层到 embedding 层映射的网络参数矩阵。
所以你看到了,使用 Word Embedding 等价于什么?等价于把 Onehot 层到 embedding 层的网络用预训练好的参数矩阵 Q 初始化了。这跟前面讲的图像领域的低层预训练过程其实是一样的,区别无非 Word Embedding 只能初始化第一层网络参数,再高层的参数就无能为力了。
下游NLP任务在使用 Word Embedding 的时候也类似图像有两种做法,一种是 Frozen,就是 Word Embedding 那层网络参数固定不动;另外一种是 Fine-Tuning,就是 Word Embedding 这层参数使用新的训练集合训练也需要跟着训练过程更新掉。
上面这种做法就是18年之前NLP领域里面采用预训练的典型做法,并且 Word Embedding 其实对于很多下游 NLP 任务是有帮助的,只是帮助没有大到闪瞎忘记戴墨镜的围观群众的双眼而已。
六、RNN 和 LSTM
为什么要在这里穿插一个 RNN(Recurrent Neural Network) 和 LSTM(Long Short-Term Memory) 呢?
因为接下来要介绍的 ELMo(Embeddings from Language Models) 模型在训练过程中使用了双向长短期记忆网络(Bi-LSTM)。
当然,这里只是简单地介绍,想要详细了解的可以去查看网上铺天盖地的参考资料。
6.1 RNN
传统的神经网络无法获取时序信息,然而时序信息在自然语言处理任务中非常重要。
例如对于这一句话 “我吃了一个苹果”,“苹果” 的词性和意思,在这里取决于前面词的信息,如果没有 “我吃了一个” 这些词,“苹果” 也可以翻译为乔布斯搞出来的那个被咬了一口的苹果。
也就是说,RNN 的出现,让处理时序信息变为可能。
RNN 的基本单元结构如下图所示:
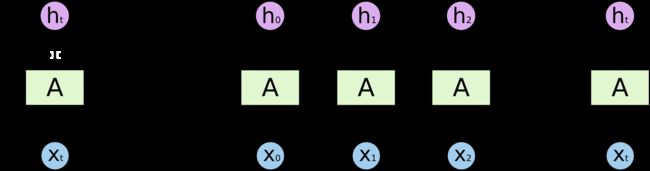
上图左边部分称作 RNN 的一个 timestep,在这个 timestep 中可以看到,在 t t t 时刻,输入变量 x t x_t xt,通过 RNN 的一个基础模块 A,输出变量 h t h_t ht,而 t t t 时刻的信息,将会传递到下一个时刻 t + 1 t+1 t+1。
如果把模块按照时序展开,则会如上图右边部分所示,由此可以看到 RNN 为多个基础模块 A 的互连,每一个模块都会把当前信息传递给下一个模块。
RNN 解决了时序依赖问题,但这里的时序一般指的是短距离的,首先我们先介绍下短距离依赖和长距离依赖的区别:
- 短距离依赖:对于这个填空题 “我想看一场篮球____”,我们很容易就判断出 “篮球” 后面跟的是 “比赛”,这种短距离依赖问题非常适合 RNN。
- 长距离依赖:对于这个填空题 “我出生在中国的瓷都景德镇,小学和中学离家都很近,……,我的母语是____”,对于短距离依赖,“我的母语是” 后面可以紧跟着 “汉语”、“英语”、“法语”,但是如果我们想精确答案,则必须回到上文中很长距离之前的表述 “我出生在中国的瓷都景德镇”,进而判断答案为 “汉语”,而 RNN 是很难学习到这些信息的。
6.2 RNN 的梯度消失问题
在这里我简单讲解下 RNN 为什么不适合长距离依赖问题。
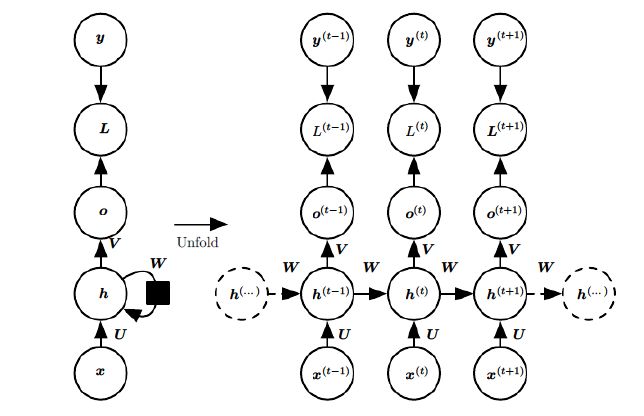
如上图所示,为RNN模型结构,前向传播过程包括:
- 隐藏状态: h ( t ) = σ ( z ( t ) ) = σ ( U x ( t ) + W h ( t − 1 ) + b ) h^{(t)} = \sigma (z^{(t)}) = \sigma(Ux^{(t)} + Wh^{(t-1)} + b) h(t)=σ(z(t))=σ(Ux(t)+Wh(t−1)+b) ,此处激活函数一般为 t a n h tanh tanh 。
- 模型输出: o ( t ) = V h ( t ) + c o^{(t)} = Vh^{(t)} + c o(t)=Vh(t)+c
- 预测输出: y ^ ( t ) = σ ( o ( t ) ) \hat{y}^{(t)} = \sigma(o^{(t)}) y^(t)=σ(o(t)) ,此处激活函数一般为softmax。
- 模型损失: L = ∑ t = 1 T L ( t ) L = \sum_{t = 1}^{T} L^{(t)} L=∑t=1TL(t)
RNN 所有的 timestep 共享一套参数 U , V , W U,V,W U,V,W,在 RNN 反向传播过程中,需要计算 U , V , W U,V,W U,V,W 等参数的梯度,以 W W W 的梯度表达式为例(假设 RNN 模型的损失函数为 L L L):
∂ L ∂ W = ∑ t = 1 T ∂ L ∂ y ( T ) ∂ y ( T ) ∂ o ( T ) ∂ o ( T ) ∂ h ( T ) ( ∏ k = t + 1 T ∂ h ( k ) ∂ h ( k − 1 ) ) ∂ h ( t ) ∂ W = ∑ t = 1 T ∂ L ∂ y ( T ) ∂ y ( T ) ∂ o ( T ) ∂ o ( T ) ∂ h ( T ) ( ∏ k = t + 1 T t a n h ′ ( z ( k ) ) W ) ∂ h ( t ) ∂ W 公式(9) \frac{\partial L}{\partial W} = \sum_{t = 1}^{T} \frac{\partial L}{\partial y^{(T)}} \frac{\partial y^{(T)}}{\partial o^{(T)}} \frac{\partial o^{(T)}}{\partial h^{(T)}} \left( \prod_{k=t + 1}^{T} \frac{\partial h^{(k)}}{\partial h^{(k - 1)}} \right) \frac{\partial h^{(t)}}{\partial W} \ \\ = \sum_{t = 1}^{T} \frac{\partial L}{\partial y^{(T)}} \frac{\partial y^{(T)}}{\partial o^{(T)}} \frac{\partial o^{(T)}}{\partial h^{(T)}} \left( \prod_{k=t+1}^{T} tanh^{'}(z^{(k)}) W \right) \frac{\partial h^{(t)}}{\partial W} \ \\ \quad\text{公式(9)} ∂W∂L=t=1∑T∂y(T)∂L∂o(T)∂y(T)∂h(T)∂o(T)(k=t+1∏T∂h(k−1)∂h(k))∂W∂h(t) =t=1∑T∂y(T)∂L∂o(T)∂y(T)∂h(T)∂o(T)(k=t+1∏Ttanh′(z(k))W)∂W∂h(t) 公式(9)
对于公式(9)中的 ( ∏ k = t + 1 T ∂ h ( k ) ∂ h ( k − 1 ) ) = ( ∏ k = t + 1 T t a n h ′ ( z ( k ) ) W ) \left( \prod_{k=t + 1}^{T} \frac{\partial h^{(k)}}{\partial h^{(k - 1)}} \right) = \left( \prod_{k=t+1}^{T} tanh^{'}(z^{(k)}) W \right) (∏k=t+1T∂h(k−1)∂h(k))=(∏k=t+1Ttanh′(z(k))W), tanh \tanh tanh 的导数总是小于 1 的,由于是 T − ( t + 1 ) T-(t+1) T−(t+1) 个 timestep 参数的连乘,如果 W W W 的主特征值小于 1,梯度便会消失;如果 W W W 的特征值大于 1,梯度便会爆炸。
需要注意的是,RNN和DNN梯度消失和梯度爆炸含义并不相同。
RNN中权重在各时间步内共享,最终的梯度是各个时间步的梯度和,梯度和会越来越大。因此,RNN中总的梯度是不会消失的,即使梯度越传越弱,也只是远距离的梯度消失。 从公式(9)中的 ( ∏ k = t + 1 T t a n h ′ ( z ( k ) ) W ) \left( \prod_{k=t+1}^{T} tanh^{'}(z^{(k)}) W \right) (∏k=t+1Ttanh′(z(k))W) 可以看到,RNN所谓梯度消失的真正含义是,梯度被近距离( t + 1 趋向于 T t+1 趋向于 T t+1趋向于T)梯度主导,远距离( t + 1 远离 T t+1 远离 T t+1远离T)梯度很小,导致模型难以学到远距离的信息。
6.3 LSTM
为了解决 RNN 缺乏的序列长距离依赖问题,LSTM 被提了出来,首先我们来看看 LSTM 相对于 RNN 做了哪些改进:
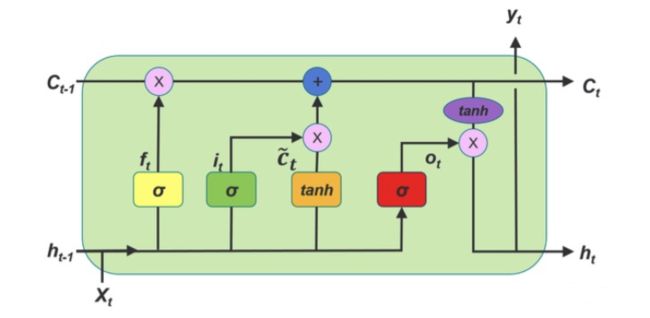
如上图所示,为 LSTM 的 RNN 门控结构(LSTM 的 timestep),LSTM 前向传播过程包括:
- **遗忘门:**决定了丢弃哪些信息,遗忘门接收 t − 1 t-1 t−1 时刻的状态 h t − 1 h_{t-1} ht−1,以及当前的输入 x t x_t xt,经过 Sigmoid 函数后输出一个 0 到 1 之间的值 f t f_t ft
- 输出: f t = σ ( W f h t − 1 + U f x t + b f ) f_{t} = \sigma(W_fh_{t-1} + U_fx_{t} + b_f) ft=σ(Wfht−1+Ufxt+bf)
- **输入门:**决定了哪些新信息被保留,并更新细胞状态,输入们的取值由 h t − 1 h_{t-1} ht−1 和 x t x_t xt 决定,通过 Sigmoid 函数得到一个 0 到 1 之间的值 i t i_t it,而 tanh \tanh tanh 函数则创造了一个当前细胞状态的候选 a t a_t at
- 输出: i t = σ ( W i h t − 1 + U i x t + b i ) i_{t} = \sigma(W_ih_{t-1} + U_ix_{t} + b_i) it=σ(Wiht−1+Uixt+bi) , C t ~ = t a n h W a h t − 1 + U a x t + b a \tilde{C_{t} }= tanhW_ah_{t-1} + U_ax_{t} + b_a Ct~=tanhWaht−1+Uaxt+ba
- **细胞状态:**旧细胞状态 C t − 1 C_{t-1} Ct−1 被更新到新的细胞状态 C t C_t Ct 上,
- 输出: C t = C t − 1 ⊙ f t + i t ⊙ C t ~ C_{t} = C_{t-1}\odot f_{t} + i_{t}\odot \tilde{C_{t} } Ct=Ct−1⊙ft+it⊙Ct~
- **输出门:**决定了最后输出的信息,输出门取值由 h t − 1 h_{t-1} ht−1 和 x t x_t xt 决定,通过 Sigmoid 函数得到一个 0 到 1 之间的值 o t o_t ot,最后通过 tanh \tanh tanh 函数决定最后输出的信息
- 输出: o t = σ ( W o h t − 1 + U o x t + b o ) o_{t} = \sigma(W_oh_{t-1} + U_ox_{t} + b_o) ot=σ(Woht−1+Uoxt+bo) , h t = o t ⊙ t a n h C t h_{t} = o_{t}\odot tanhC_{t} ht=ot⊙tanhCt
- 预测输出: y ^ t = σ ( V h t + c ) \hat{y}_{t} = \sigma(Vh_{t}+c) y^t=σ(Vht+c)
6.4 LSTM 解决 RNN 的梯度消失问题
明白了 RNN 梯度消失的原因之后,我们看 LSTM 如何解决问题的呢?
RNN 梯度消失的原因是,随着梯度的传导,梯度被近距离梯度主导,模型难以学习到远距离的信息。具体原因也就是 ∏ k = t + 1 T ∂ h k ∂ h k − 1 \prod_{k=t+1}^{T}\frac{\partial h_{k}}{\partial h_{k - 1}} ∏k=t+1T∂hk−1∂hk 部分,在迭代过程中,每一步 ∂ h k ∂ h k − 1 \frac{\partial h_{k}}{\partial h_{k - 1}} ∂hk−1∂hk 始终在 [0,1) 之间或者始终大于 1。
而对于 LSTM 模型而言,针对 ∏ k = t + 1 T ∂ C k ∂ C k − 1 \prod _{k=t+1}^{T} \frac{\partial C_{k}}{\partial C_{k-1}} ∏k=t+1T∂Ck−1∂Ck 求得:
∂ C k ∂ C k − 1 = f k + o t h e r ∏ k = t + 1 T ∂ C k ∂ C k − 1 = f k f k + 1 . . . f T + o t h e r \begin{align} & \frac{\partial C_{k}}{\partial C_{k-1}} = f_k + other \\ & \prod _{k=t+1}^{T} \frac{\partial C_{k}}{\partial C_{k-1}} = f_{k}f_{k+1}...f_{T} + other \\ \end{align} ∂Ck−1∂Ck=fk+otherk=t+1∏T∂Ck−1∂Ck=fkfk+1...fT+other
在 LSTM 迭代过程中,针对 ∏ k = t + 1 T ∂ C k ∂ C k − 1 \prod_{k=t+1}^{T} \frac{\partial C_{k}}{\partial C_{k-1}} ∏k=t+1T∂Ck−1∂Ck 而言,每一步 ∂ C k ∂ C k − 1 \frac{\partial C_{k}}{\partial C_{k-1}} ∂Ck−1∂Ck 可以自主的选择在 [0,1] 之间,或者大于1,因为 f k f_{k} fk 是可训练学习的。那么整体 ∏ k = t + 1 T ∂ C k ∂ C k − 1 \prod _{k=t+1}^{T} \frac{\partial C_{k}}{\partial C_{k-1}} ∏k=t+1T∂Ck−1∂Ck 也就不会一直减小,远距离梯度不至于完全消失,也就能够解决 RNN 中存在的梯度消失问题。
LSTM 遗忘门值 f t f_t ft 可以选择在 [0,1] 之间,让 LSTM 来改善梯度消失的情况。也可以选择接近 1,让遗忘门饱和,此时远距离信息梯度不消失;也可以选择接近 0,此时模型是故意阻断梯度流,遗忘之前信息。
另外需要强调的是LSTM搞的这么复杂,除了在结构上天然地克服了梯度消失的问题,更重要的是具有更多的参数来控制模型;通过四倍于RNN的参数量,可以更加精细地预测时间序列变量。
此外,我记得有一篇文章讲到,LSTM 在 200左右长度的文本上,就已经捉襟见肘了。
七、ELMo 模型
7.1 ELMo 的预训练
在讲解 Word Embedding 时,细心地读者一定已经发现,这些词表示方法本质上是静态的,每一个词都有一个唯一确定的词向量,不能根据句子的不同而改变,无法处理自然语言处理任务中的多义词问题。

如上图所示,例如多义词 Bank,有两个常用含义,但是 Word Embedding 在对 bank 这个单词进行编码的时候,是区分不开这两个含义的。
因为尽管这两句含有 bank 的句子中 bank 上下文环境中出现的单词不同,但是在用语言模型训练的时候,不论什么上下文的句子经过 Word2Vec,都是预测相同的单词 bank,而同一个单词占用的是同一行的参数空间,这会导致两种不同的上下文信息都会编码到相同的 Word Embedding 空间里,进而导致Word Embedding 无法区分多义词的不同语义。
所以对于比如 Bank 这个词,它事先学好的 Word Embedding 中混合了几种语义 ,在应用中来了个新句子,即使从上下文中(比如句子包含 money 等词)明显可以看出它代表的是 “银行” 的含义,但是对应的 Word Embedding 内容也不会变,它还是混合了多种语义。
针对 Word Embedding 中出现的多义词问题,ELMo 提供了一个简洁优雅的解决方案。
ELMo 的本质思想是:我事先用语言模型学好一个单词的 Word Embedding,此时多义词无法区分,不过这没关系。在我实际使用 Word Embedding 的时候,单词已经具备了特定的上下文了,这个时候我可以根据上下文单词的语义再去调整单词的 Word Embedding 表示,这样经过调整后的 Word Embedding 更能表达在这个上下文中的具体含义,自然也就解决了多义词的问题了。所以 ELMo 本身是个根据当前上下文对 Word Embedding 动态调整的思路。
ELMo 采用了典型的两阶段过程:
- 第一个阶段是利用语言模型进行预训练;
- 第二个阶段是在做下游任务时,从预训练网络中提取对应单词的网络各层的 Word Embedding 作为新特征补充到下游任务中。
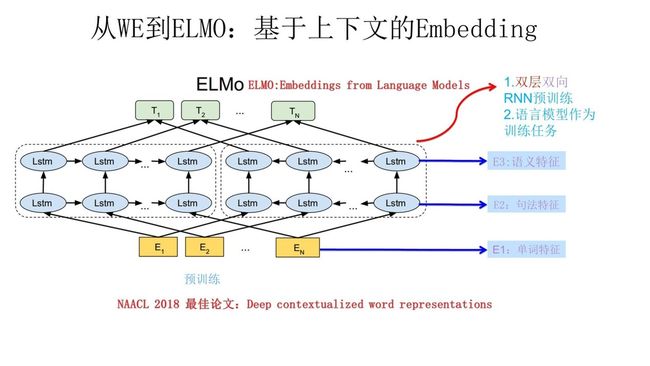
上图展示的是其第一阶段预训练过程,它的网络结构采用了双层双向 LSTM,目前语言模型训练的任务目标是根据单词 w i w_i wi 的上下文去正确预测单词 w i w_i wi, w i w_i wi 之前的单词序列 Context-before 称为上文,之后的单词序列 Context-after 称为下文。
图中左端的前向双层 LSTM 代表正方向编码器,输入的是从左到右顺序的除了预测单词外 W i W_i Wi 的上文 Context-before;右端的逆向双层 LSTM 代表反方向编码器,输入的是从右到左的逆序的句子下文Context-after;每个编码器的深度都是两层 LSTM 叠加。
这个网络结构其实在 NLP 中是很常用的。使用这个网络结构利用大量语料做语言模型任务就能预先训练好这个网络,如果训练好这个网络后,输入一个新句子 s n e w s_{new} snew ,句子中每个单词都能得到对应的三个 Embedding:
- 最底层是单词的 Word Embedding;
- 往上走是第一层双向 LSTM 中对应单词位置的 Embedding,这层编码单词的句法信息更多一些;
- 再往上走是第二层 LSTM 中对应单词位置的 Embedding,这层编码单词的语义信息更多一些。
也就是说,ELMo 的预训练过程不仅仅学会单词的 Word Embedding,还学会了一个双层双向的 LSTM 网络结构,而这两者后面都有用。
7.2 ELMo 的 Feature-based Pre-Training
上面介绍的是 ELMo 的第一阶段:预训练阶段。那么预训练好网络结构后,如何给下游任务使用呢?
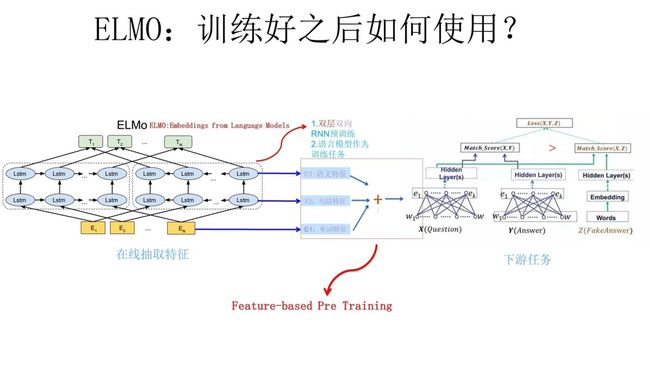
上图展示了下游任务的使用过程,比如我们的下游任务仍然是 QA 问题,此时对于问句 X:
- 我们可以先将句子 X 作为预训练好的 ELMo 网络的输入,这样句子 X 中每个单词在 ELMO 网络中都能获得对应的三个 Embedding;
- 之后给予这三个 Embedding 中的每一个 Embedding 一个权重 a,这个权重可以学习得来,根据各自权重累加求和,将三个 Embedding 整合成一个;
- 然后将整合后的这个 Embedding 作为 X 句在自己任务的那个网络结构中对应单词的输入,以此作为补充的新特征给下游任务使用。
- 对于上图所示下游任务 QA 中的回答句子 Y 来说也是如此处理。
因为 ELMo 给下游提供的是每个单词的特征形式,所以这一类预训练的方法被称为 “Feature-based Pre-Training”。
至于为何这么做能够达到区分多义词的效果,原因在于在训练好 ELMo 后,在特征提取的时候,每个单词在两层 LSTM 上都会有对应的节点,这两个节点会编码单词的一些句法特征和语义特征,并且它们的 Embedding 编码是动态改变的,会受到上下文单词的影响,周围单词的上下文不同应该会强化某种语义,弱化其它语义,进而就解决了多义词的问题。
八、Attention
上面巴拉巴拉了一堆,都在为 BERT 的讲解做铺垫,而接下来要叙述的 Attention 和 Transformer 同样如此,它们都只是 BERT 构成的一部分。
8.1 人类的视觉注意力
Attention 是注意力的意思,从它的命名方式看,很明显借鉴了人类的注意力机制,因此,我们首先介绍人类的视觉注意力。
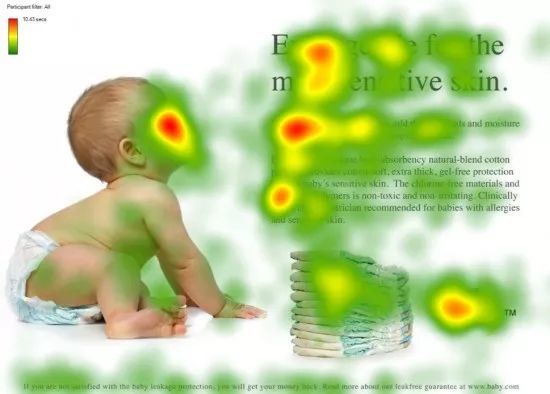
视觉注意力机制是人类视觉所特有的大脑信号处理机制。人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,也就是一般所说的注意力焦点,而后对这一区域投入更多注意力资源,以获取更多所需要关注目标的细节信息,而抑制其他无用信息。
这是人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段,是人类在长期进化中形成的一种生存机制,人类视觉注意力机制极大地提高了视觉信息处理的效率与准确性。
上图形象化展示了人类在看到一副图像时是如何高效分配有限的注意力资源的,其中红色区域表明视觉系统更关注的目标,很明显对于上图所示的场景,人们会把注意力更多投入到人的脸部,文本的标题以及文章首句等位置。
深度学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似,核心目标也是从众多信息中选择出对当前任务目标更关键的信息。
8.2 Attention 的本质思想
从人类的视觉注意力可以看出,注意力模型 Attention 的本质思想为:从大量信息中有选择地筛选出少量重要信息并聚焦到这些重要信息上,忽略不重要的信息。
在详细讲解 Attention之前,我们在讲讲 Attention的其他作用。之前我们讲解 LSTM 的时候说到,虽然 LSTM 解决了序列长距离依赖问题,但是单词超过 200 的时候就会失效。而 Attention 机制可以更加好的解决序列长距离依赖问题,并且具有并行计算能力。现在不明白这点不重要,随着我们对 Attention 的慢慢深入,相信你会明白。
首先我们得明确一个点,注意力模型从大量信息 Values 中筛选出少量重要信息,这些重要信息一定是相对于另外一个信息 Query 而言是重要的,例如对于上面那张婴儿图,Query 就是观察者。也就是说,我们要搭建一个注意力模型,我们必须得要有一个 Query 和一个 Values,然后通过 Query 这个信息从 Values 中筛选出重要信息。
通过 Query 这个信息从 Values 中筛选出重要信息,简单点说,就是计算 Query 和 Values 中每个信息的相关程度。
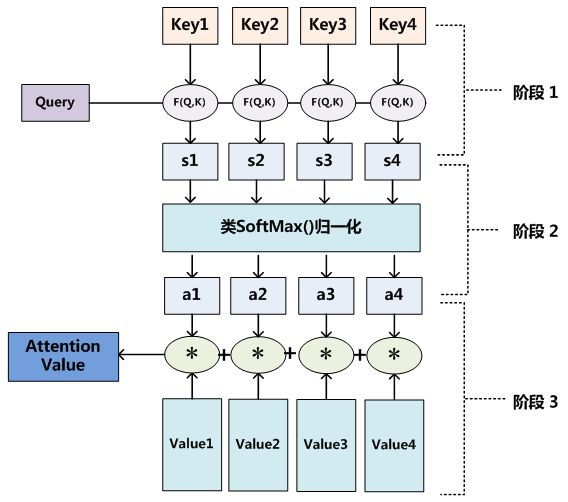
再具体点,通过上图,Attention 通常可以进行如下描述,表示为将 Query(Q) 和 key-value pairs(把 Values 拆分成了键值对的形式) 映射到输出上,其中 query、每个 key、每个 value 都是向量,输出是 V 中所有 values 的加权,其中权重是由 Query 和每个 key 计算出来的,计算方法分为三步:
- 第一步:计算比较 Q 和 K 的相似度,用 f 来表示: f ( Q , K i ) i = 1 , 2 , ⋯ , m f(Q,K_i)\quad i=1,2,\cdots,m f(Q,Ki)i=1,2,⋯,m,一般第一步计算方法包括四种
- 点乘(Transformer 使用): f ( Q , K i ) = Q T K i f(Q,K_i) = Q^T K_i f(Q,Ki)=QTKi
- 权重: f ( Q , K i ) = Q T W K i f(Q,K_i) = Q^TWK_i f(Q,Ki)=QTWKi
- 拼接权重: f ( Q , K i ) = W [ Q T ; K i ] f(Q,K_i) = W[Q^T;K_i] f(Q,Ki)=W[QT;Ki]
- 感知器: f ( Q , K i ) = V T tanh ( W Q + U K i ) f(Q,K_i)=V^T \tanh(WQ+UK_i) f(Q,Ki)=VTtanh(WQ+UKi)
- 第二步:将得到的相似度进行 softmax 操作,进行归一化: α i = s o f t m a x ( f ( Q , K i ) d k ) \alpha_i = softmax(\frac{f(Q,K_i)}{\sqrt d_k}) αi=softmax(dkf(Q,Ki))
- 这里简单讲解除以 d k \sqrt d_k dk 的作用:假设 Q Q Q , K K K 里的元素的均值为0,方差为 1,那么 A T = Q T K A^T=Q^TK AT=QTK 中元素的均值为 0,方差为 d。当 d 变得很大时, A A A 中的元素的方差也会变得很大,如果 A A A 中的元素方差很大(分布的方差大,分布集中在绝对值大的区域),在数量级较大时, softmax 将几乎全部的概率分布都分配给了最大值对应的标签,由于某一维度的数量级较大,进而会导致 softmax 未来求梯度时会消失。总结一下就是 softmax ( A ) \operatorname{softmax}\left(A\right) softmax(A) 的分布会和d有关。因此 A A A 中每一个元素乘上 1 d k \frac{1}{\sqrt{d_k}} dk1 后,方差又变为 1,并且 A A A 的数量级也将会变小。
- 第三步:针对计算出来的权重 α i \alpha_i αi,对 V V V 中的所有 values 进行加权求和计算,得到 Attention 向量: A t t e n t i o n = ∑ i = 1 m α i V i Attention = \sum_{i=1}^m \alpha_i V_i Attention=∑i=1mαiVi
8.3 Self Attention 模型
上面已经讲了 Attention 就是从一堆信息中筛选出重要的信息,现在我们来通过 Self Attention 模型来详细讲解如何找到这些重要的信息。
Self Attention 模型的架构如下图所示,接下来我们将按照这个模型架构的顺序来逐一解释。
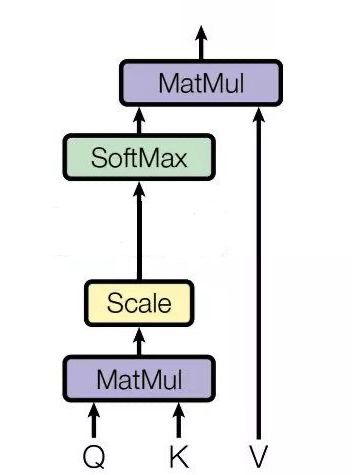
首先可以看到 Self Attention 有三个输入 Q、K、V:对于 Self Attention,Q、K、V 来自句子 X 的 词向量 x 的线性转化,即对于词向量 x,给定三个可学习的矩阵参数 W Q , W k , W v W_Q,W_k,W_v WQ,Wk,Wv,x 分别右乘上述矩阵得到 Q、K、V。
接下来为了表示的方便,我们先通过向量的计算叙述 Self Attention 计算的流程,然后再描述 Self Attention 的矩阵计算过程
-
第一步,Q、K、V 的获取
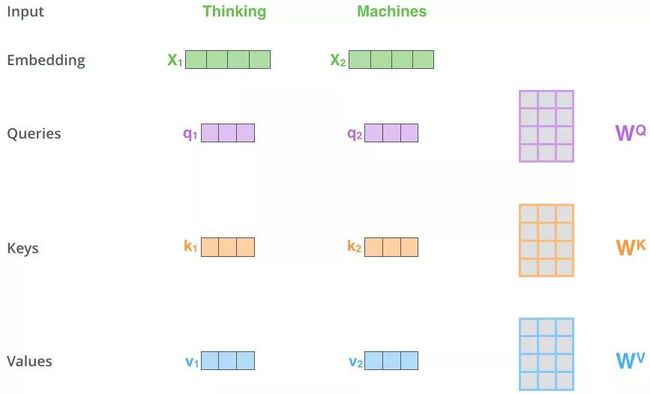
上图操作:两个单词 Thinking 和 Machines。通过线性变换,即 x i x_i xi 和 x 2 x_2 x2 两个向量分别与 W q , W k , W v W_q,W_k,W_v Wq,Wk,Wv 三个矩阵点乘得到 ${q_1,q_2},{k_1,k_2},{v_1,v_2} $ 共 6 个向量。矩阵 Q 则是向量 q 1 , q 2 q_1,q_2 q1,q2 的拼接,K、V 同理。
-
第二步,MatMul
-
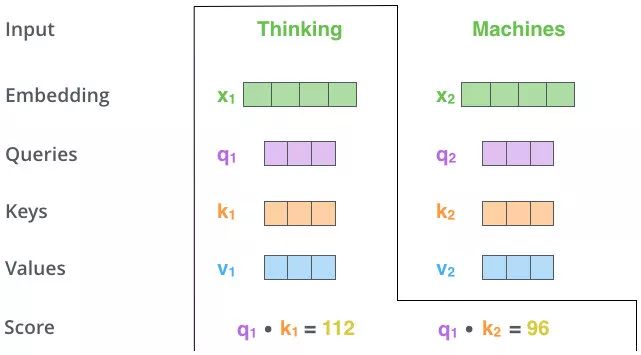
上图操作:向量 q 1 , k 1 {q_1,k_1} q1,k1 做点乘得到得分 112, q 1 , k 2 {q_1,k_2} q1,k2 做点乘得到得分96。注意:这里是通过 q 1 q_1 q1 这个信息找到 x 1 , x 2 x_1,x_2 x1,x2 中的重要信息。
-
-
第三步和第四步,Scale + Softmax
上图操作:对该得分进行规范,除以 d k = 8 \sqrt {d_k} = 8 dk=8
-
-
第五步,MatMul
-
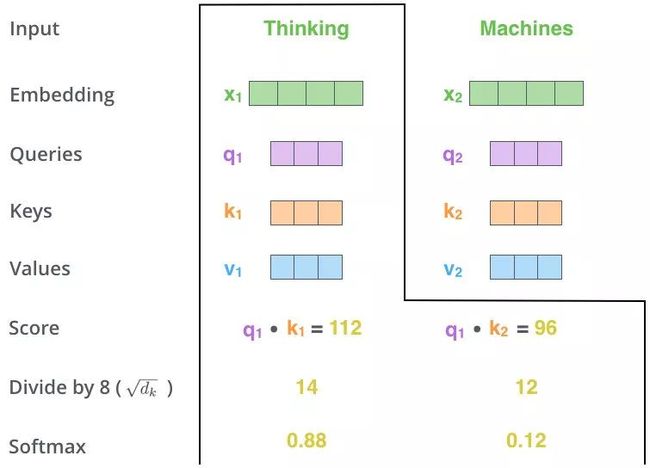
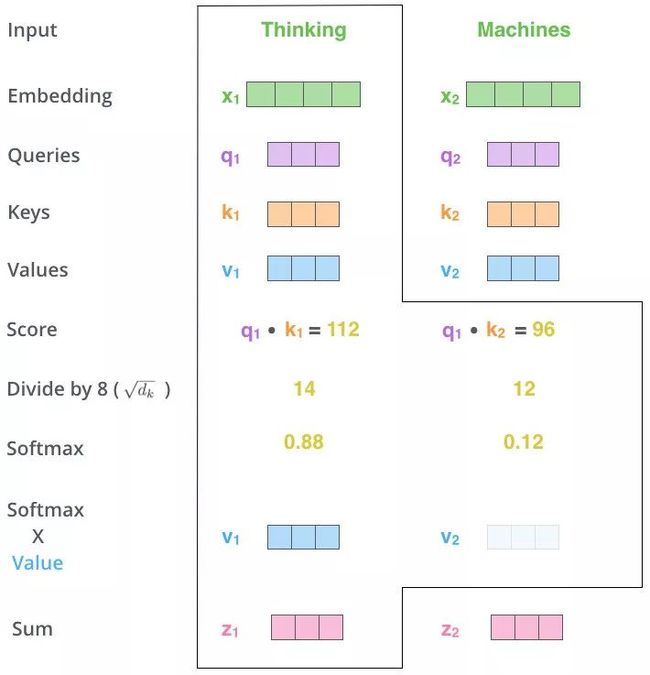
用得分比例 [0.88,0.12] 乘以 [ v 1 , v 2 ] [v_1,v_2] [v1,v2] 值得到一个加权后的值,将这些值加起来得到 z 1 z_1 z1。
上述所说就是 Self Attention 模型所做的事,仔细感受一下,用 q 1 q_1 q1、 K = [ k 1 , k 2 ] K=[k_1,k_2] K=[k1,k2] 去计算一个 Thinking 相对于 Thinking 和 Machine 的权重,再用权重乘以 Thinking 和 Machine 的 V = [ v 1 , v 2 ] V=[v_1,v_2] V=[v1,v2] 得到加权后的 Thinking 和 Machine 的 V = [ v 1 , v 2 ] V=[v_1,v_2] V=[v1,v2],最后求和得到针对各单词的输出 z 1 z_1 z1。
同理可以计算出 Machine 相对于 Thinking 和 Machine 的加权输出 z 2 z_2 z2,拼接 z 1 z_1 z1 和 z 2 z_2 z2 即可得到 Attention 值 Z = [ z 1 , z 2 ] Z=[z_1,z_2] Z=[z1,z2],这就是 Self Attention 的矩阵计算,如下所示。
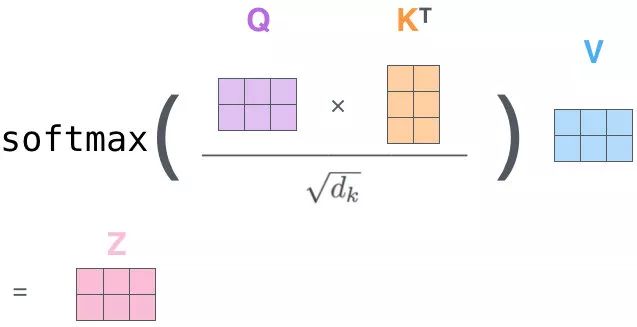
之前的例子是单个向量的运算例子。这张图展示的是矩阵运算的例子,输入是一个 [2x4] 的矩阵(句子中每个单词的词向量的拼接),每个运算是 [4x3] 的矩阵,求得 Q、K、V。

Q 对 K 转制做点乘,除以 d k \sqrt d_k dk,做一个 softmax 得到合为 1 的比例,对 V 做点乘得到输出 Z。那么这个 Z 就是一个考虑过 Thinking 周围单词 Machine 的输出。
注意看这个公式, Q K T QK^T QKT 其实就会组成一个 word2word 的 attention map!(加了 softmax 之后就是一个合为 1 的权重了)。比如说你的输入是一句话 “i have a dream” 总共 4 个单词,这里就会形成一张 4x4 的注意力机制的图:

这样一来,每一个单词对应每一个单词都会有一个权重,这也是 Self Attention 名字的来源,即 Attention 的计算来源于 Source(源句) 和 Source 本身,通俗点讲就是 Q、K、V 都来源于输入 X 本身。
8.4 Self Attention 和 RNN、LSTM 的区别
引入 Self Attention 有什么好处呢?或者说通过 Self Attention 到底学到了哪些规律或者抽取出了哪些特征呢?我们可以通过下述两幅图来讲解:
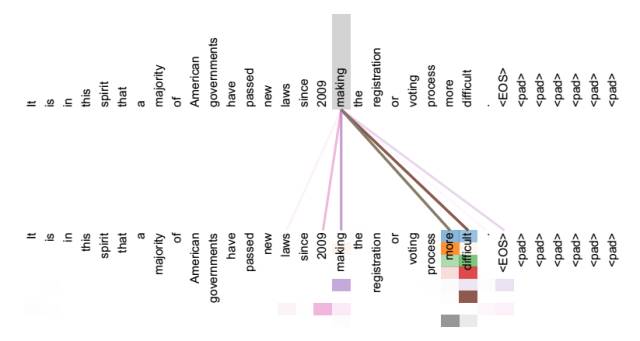
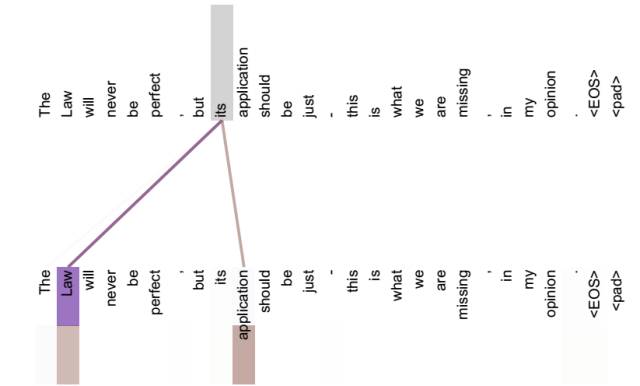
从上述两张图可以看出,Self Attention 可以捕获同一个句子中单词之间的一些句法特征(例如第一张图展示的有一定距离的短语结构)或者语义特征(例如第二张图展示的 its 的指代对象为 Law)。
有了上述的讲解,我们现在可以来看看 Self Attention 和 RNN、LSTM 的区别:
- RNN、LSTM:如果是 RNN 或者 LSTM,需要依次序列计算,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来,而距离越远,有效捕获的可能性越小。
- Self Attention:
- 通过上述两幅图,很明显的可以看出,引入 Self Attention 后会更容易捕获句子中长距离的相互依赖的特征,因为 Self Attention 在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征;
- 除此之外,Self
Attention 对于一句话中的每个单词都可以单独的进行 Attention 值的计算,也就是说 Self Attention 对计算的并行性也有直接帮助作用,而对于必须得依次序列计算的 RNN 而言,是无法做到并行计算的。
从上面的计算步骤和图片可以看出,无论句子序列多长,都可以充分捕获近距离上往下问中的任何依赖关系,进而可以很好的提取句法特征还可以提取语义特征;而且对于一个句子而言,每个单词的计算是可以并行处理的。
理论上 Self-Attention (Transformer 50 个左右的单词效果最好)解决了 RNN 模型的长序列依赖问题,但是由于文本长度增加时,训练时间也将会呈指数增长,因此在处理长文本任务时可能不一定比 LSTM(200 个左右的单词效果最好) 等传统的 RNN 模型的效果好。
上述所说的,则是为何 Self Attention 逐渐替代 RNN、LSTM 被广泛使用的原因所在。
8.5 Masked Self Attention 模型
趁热打铁,我们讲讲 Transformer 未来会用到的 Masked Self Attention 模型,这里的 Masked 就是要在做语言模型(或者像翻译)的时候,不给模型看到未来的信息,它的结构如下图所示:
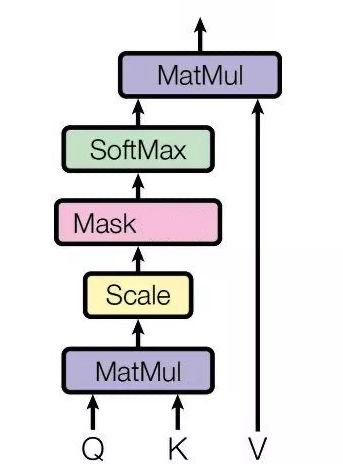
上图中和 Self Attention 重复的部分此处就不讲了,主要讲讲 Mask 这一块。
假设在此之前我们已经通过 scale 之前的步骤得到了一个 attention map,而 mask 就是沿着对角线把灰色的区域用0覆盖掉,不给模型看到未来的信息,如下图所示:
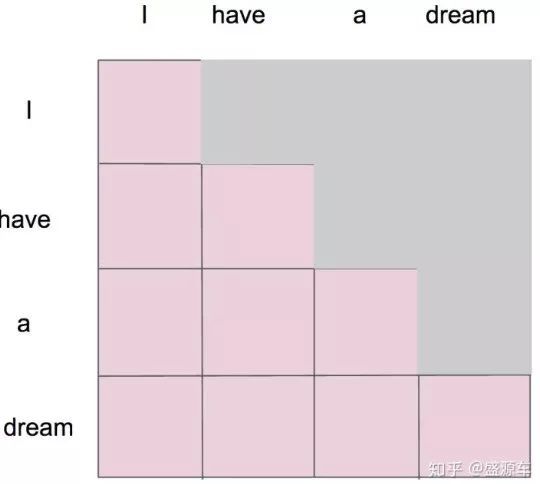
详细来说:
- “i” 作为第一个单词,只能有和 “i” 自己的 attention;
- “have” 作为第二个单词,有和 “i、have” 前面两个单词的 attention;
- “a” 作为第三个单词,有和 “i、have、a” 前面三个单词的 attention;
- “dream” 作为最后一个单词,才有对整个句子 4 个单词的 attention。
并且在做完 softmax 之后,横轴结果合为 1。如下图所示:
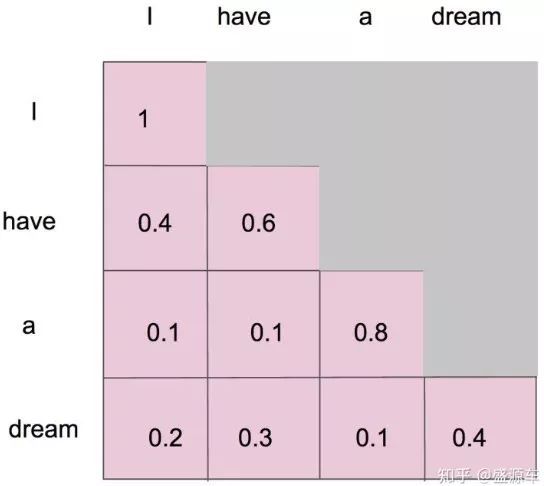
具体为什么要 mask,未来再讲解 Transformer 的时候我们会详细解释。
8.6 Multi-head Self Attention 模型
由于 Transformer 使用的都是 Self Attention 的进阶版 Multi-head Self Attention,我们简单讲讲 Multi-head Self Attention 的架构,并且在该小节结尾处讲讲它的优点。
Multi-Head Attention 就是把 Self Attention 得到的注意力值 Z Z Z 切分成 n 个 Z 1 , Z 2 , ⋯ , Z n Z_1,Z_2,\cdots,Z_n Z1,Z2,⋯,Zn,然后通过全连接层获得新的 Z ′ Z' Z′.

我们还是以上面的形式来解释,我们对 Z Z Z 进行 8 等份的切分得到 8 个 Z i Z_i Zi 矩阵:

为了使得输出与输入结构相同,拼接矩阵 Z i Z_i Zi 后乘以一个线性 W 0 W_0 W0 得到最终的Z:

可以通过下图看看 multi-head attention 的整个流程:
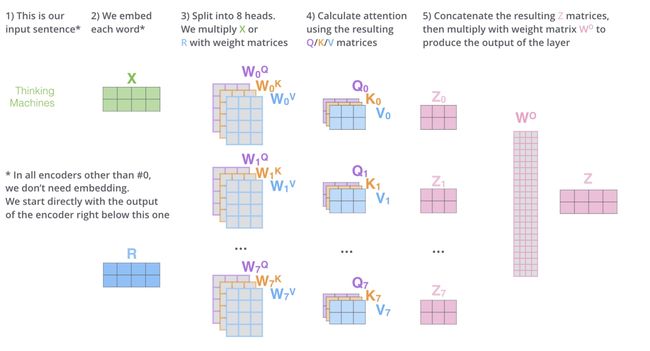
上述操作有什么好处呢?多头相当于把原始信息 Source 放入了多个子空间中,也就是捕捉了多个信息,对于使用 multi-head(多头) attention 的简单回答就是,多头保证了 attention 可以注意到不同子空间的信息,捕捉到更加丰富的特征信息。其实本质上是论文原作者发现这样效果确实好。
九、Position Embedding
在 Attention 和 RNN、LSTM 的对比中,我们说到 Attention 解决了长距离依赖问题,并且可以支持并行化,但是它就真的百利而无一害了吗?
其实不然,我们往前回顾,Self Attention 的 Q、K、V 三个矩阵是由同一个输入 X 1 = ( x 1 , x 2 , ⋯ , x n ) X_1=(x_1,x_2,\cdots,x_n) X1=(x1,x2,⋯,xn) 线性转换而来,也就是说对于这样的一个被打乱序列顺序的 X 2 = ( x 2 , x 1 , ⋯ , x n ) X_2=(x_2,x_1,\cdots,x_n) X2=(x2,x1,⋯,xn) 而言,由于 Attention 值的计算最终会被加权求和,也就是说两者最终计算的 Attention 值都是一样的,进而也就表明了 Attention 丢掉了 X 1 X_1 X1 的序列顺序信息。

如上图所示,为了解决 Attention 丢失的序列顺序信息,Transformer 的提出者提出了 Position Embedding,也就是对于输入 X X X 进行 Attention 计算之前,在 X X X 的词向量中加上位置信息,也就是说 X X X 的词向量为 X f i n a l _ e m b e d d i n g = E m b e d d i n g + P o s i t i o n a l E m b e d d i n g X_{final\_embedding} = Embedding + Positional\, Embedding Xfinal_embedding=Embedding+PositionalEmbedding
但是如何得到 X X X 的位置向量呢?
其中位置编码公式如下图所示:

其中 pos 表示位置、i 表示维度、 d m o d e l d_{model} dmodel表示位置向量的向量维度 、 2 i 、 2 i + 1 2i、2i+1 2i、2i+1 表示的是奇偶数(奇偶维度),上图所示就是偶数位置使用 sin \sin sin 函数,奇数位置使用 cos \cos cos 函数。
有了位置编码,我们再来看看位置编码是如何嵌入单词编码的(其中 512 表示编码维度),通过把单词的词向量和位置向量进行叠加,这种方式就称作位置嵌入,如下图所示:
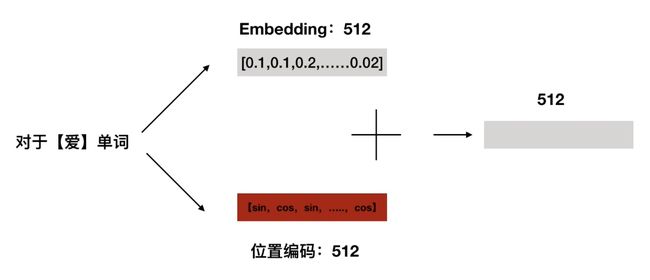
Position Embedding 本身是一个绝对位置的信息,但在语言模型中,相对位置也很重要。那么为什么位置嵌入机制有用呢?
我们不要去关心三角函数公式,可以看看下图公式(3)中的第一行,我们做如下的解释,对于 “我爱吃苹果” 这一句话,有 5 个单词,假设序号分别为 1、2、3、4、5。

假设 p o s = 1 = 我、 k = 2 = 爱、 p o s + k = 3 = 吃 pos=1=我、k=2=爱、pos+k=3=吃 pos=1=我、k=2=爱、pos+k=3=吃,也就是说 p o s + k = 3 pos+k=3 pos+k=3 位置的位置向量的某一维可以通过 p o s = 1 pos=1 pos=1 位置的位置向量的某一维线性组合加以线性表示,通过该线性表示可以得出 “吃” 的位置编码信息蕴含了相对于前两个字 “我” 的位置编码信息。
总而言之就是,某个单词的位置信息是其他单词位置信息的线性组合,这种线性组合就意味着位置向量中蕴含了相对位置信息。
十、Transformer
10.1 Transformer 的结构
万事俱备,只欠东风,下面我们来讲讲我们的重点之一,Transformer,你可以先记住这一句话:Transformer 简单点看其实就是 self-attention 模型的叠加,首先我们来看看 Transformer 的整体框架。
Transformer 的整体框架如下图所示:
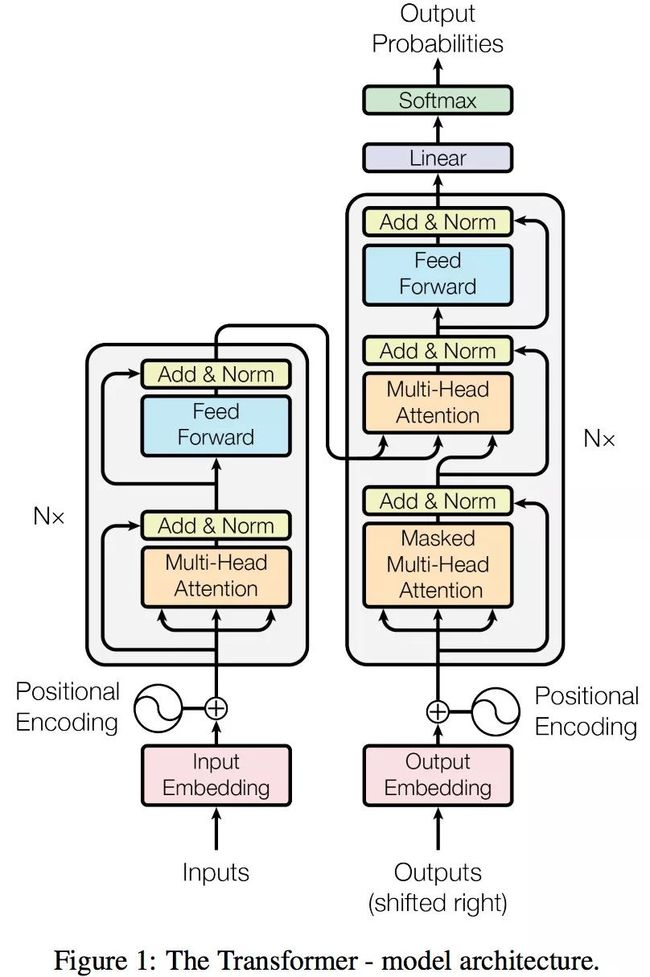
上图所示的整体框架乍一眼一看非常复杂,由于 Transformer 起初是作为翻译模型,因此我们以翻译举例,简化一下上述的整体框架:

从上图可以看出 Transformer 相当于一个黑箱,左边输入 “Je suis etudiant”,右边会得到一个翻译结果 “I am a student”。
再往细里讲,Transformer 也是一个 Seq2Seq 模型(Encoder-Decoder 框架的模型),左边一个 Encoders 把输入读进去,右边一个 Decoders 得到输出,如下所示:
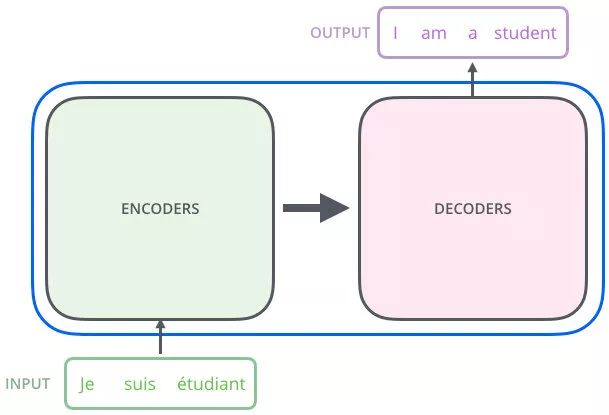
在这里,我们穿插描述下 Encoder-Decoder 框架的模型是如何进行文本翻译的:
- 将序列 ( x 1 , x 2 , ⋯ , x n ) (x_1,x_2,\cdots,x_n) (x1,x2,⋯,xn) 作为 Encoders 的输入,得到输出序列 ( z 1 , z 2 , ⋯ , z n ) (z_1,z_2,\cdots,z_n) (z1,z2,⋯,zn)
- 把 Encoders 的输出序列 ( z 1 , z 2 , ⋯ , z n ) (z_1,z_2,\cdots,z_n) (z1,z2,⋯,zn) 作为 Decoders 的输入,生成一个输出序列 ( y 1 , y 2 , ⋯ , y m ) (y_1,y_2,\cdots,y_m) (y1,y2,⋯,ym)。注:Decoders 每个时刻输出一个结果
第一眼看到上述的 Encodes-Decoders 框架图,随之产生问题就是 Transformer 中 左边 Encoders 的输出是怎么和右边 Decoders 结合的。因为decoders 里面是有N层的,再画张图直观的看就是这样:
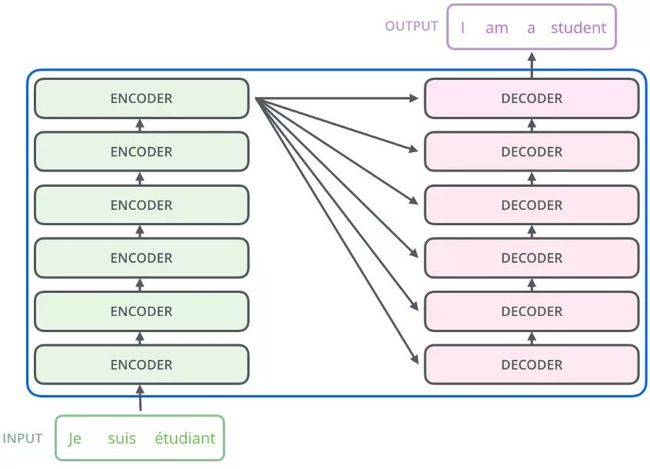
也就是说,Encoders 的输出,会和每一层的 Decoder 进行结合。
现在我们取其中一层进行详细的展示:

通过上述分析,发现我们想要详细了解 Transformer,只要了解 Transformer 中的 Encoder 和 Decoder 单元即可,接下来我们将详细阐述这两个单元。
10.2 Encoder
有了上述那么多知识的铺垫,我们知道 Eecoders 是 N=6 层,通过上图我们可以看到每层 Encoder 包括两个 sub-layers:
- 第一个 sub-layer 是 multi-head self-attention,用来计算输入的 self-attention;
- 第二个 sub-layer 是简单的前馈神经网络层 Feed Forward;
注意:在每个 sub-layer 我们都模拟了残差网络(在下面的数据流示意图中会细讲),每个sub-layer的输出都是 L a y e r N o r m ( x + S u b _ l a y e r ( x ) ) LayerNorm(x+Sub\_layer(x)) LayerNorm(x+Sub_layer(x)),其中 s u b _ l a y e r sub\_layer sub_layer 表示的是该层的上一层的输出
现在我们给出 Encoder 的数据流示意图,一步一步去剖析
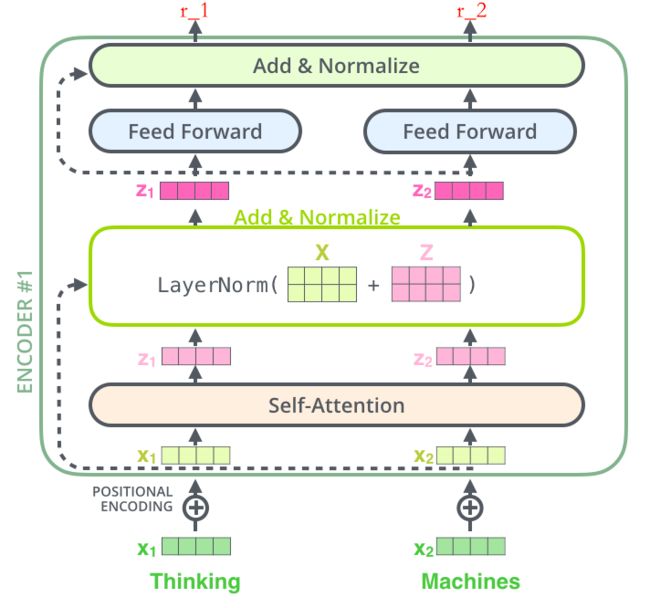
- 深绿色的 x 1 x_1 x1 表示 Embedding 层的输出,加上代表 Positional Embedding 的向量之后,得到最后输入 Encoder 中的特征向量,也就是浅绿色向量 x 1 x_1 x1;
- 浅绿色向量 x 1 x_1 x1 表示单词 “Thinking” 的特征向量,其中 x 1 x_1 x1 经过 Self-Attention 层,变成浅粉色向量 z 1 z_1 z1;
- x 1 x_1 x1 作为残差结构的直连向量,直接和 z 1 z_1 z1 相加,之后进行 Layer Norm 操作,得到粉色向量 z 1 z_1 z1;
- 残差结构的作用:避免出现梯度消失的情况
- Layer Norm 的作用:为了保证数据特征分布的稳定性,并且可以加速模型的收敛
- z 1 z_1 z1 经过前馈神经网络(Feed Forward)层,经过残差结构与自身相加,之后经过 LN 层,得到一个输出向量 r 1 r_1 r1;
- 该前馈神经网络包括两个线性变换和一个ReLU激活函数: F F N ( x ) = m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x) = max(0,xW_1+b_1)W_2+b2 FFN(x)=max(0,xW1+b1)W2+b2
- 由于 Transformer 的 Encoders 具有 6 个 Encoder, r 1 r_1 r1 也将会作为下一层 Encoder 的输入,代替 x 1 x_1 x1 的角色,如此循环,直至最后一层 Encoder。
需要注意的是,上述的 x 、 z 、 r x、z、r x、z、r 都具有相同的维数,论文中为 512 维。
10.3 Decoder
Decoders 也是 N=6 层,通过上图我们可以看到每层 Decoder 包括 3 个 sub-layers:
- 第一个 sub-layer 是 Masked multi-head self-attention,也是计算输入的 self-attention;
- 在这里,先不解释为什么要做 Masked,后面在 “Transformer 动态流程展示” 这一小节会解释
- 第二个 sub-layer 是 Encoder-Decoder Attention 计算,对 Encoder 的输入和 Decoder 的Masked multi-head self-attention 的输出进行 attention 计算;
- 在这里,同样不解释为什么要对 Encoder 和 Decoder 的输出一同做 attention 计算,后面在 “Transformer 动态流程展示” 这一小节会解释
- 第三个 sub-layer 是前馈神经网络层,与 Encoder 相同。
10.4 Transformer 输出结果
以上,就讲完了 Transformer 编码和解码两大模块,那么我们回归最初的问题,将 “机器学习” 翻译成 “machine learing”,解码器的输出是一个浮点型的向量,怎么转化成 “machine learing” 这两个词呢?让我们来看看 Encoders 和 Decoders 交互的过程寻找答案:
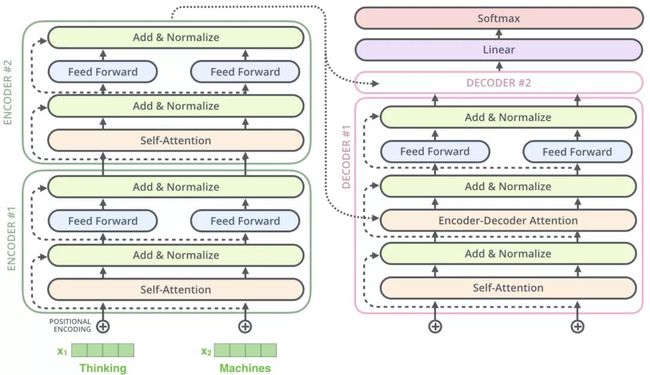
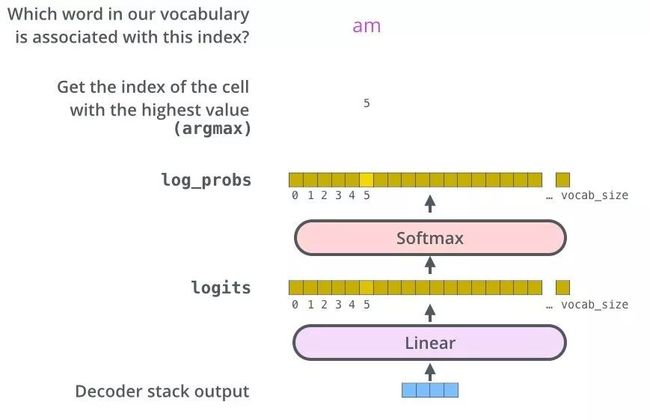
从上图可以看出,Transformer 最后的工作是让解码器的输出通过线性层 Linear 后接上一个 softmax
- 其中线性层是一个简单的全连接神经网络,它将解码器产生的向量 A 投影到一个更高维度的向量 B 上,假设我们模型的词汇表是10000个词,那么向量 B 就有10000个维度,每个维度对应一个惟一的词的得分。
- 之后的softmax层将这些分数转换为概率。选择概率最大的维度,并对应地生成与之关联的单词作为此时间步的输出就是最终的输出啦!
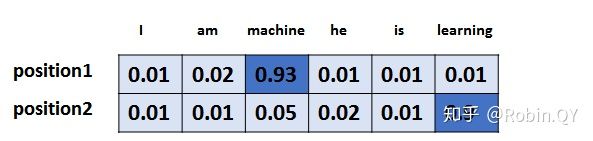
假设词汇表维度是 6,那么输出最大概率词汇的过程如下:
十一、Transformer 动态流程展示
首先我们来看看拿 Transformer 作翻译时,如何生成翻译结果的:
继续进行:
假设上图是训练模型的某一个阶段,我们来结合 Transformer 的完整框架描述下这个动态的流程图:
- 输入 “je suis etudiant” 到 Encoders,然后得到一个 K e K_e Ke、 V e V_e Ve 矩阵;
- 输入 “I am a student” 到 Decoders ,首先通过 Masked Multi-head Attention 层得到 “I am a student” 的 attention 值 Q d Q_d Qd,然后用 attention 值 Q d Q_d Qd 和 Encoders 的输出 K e K_e Ke、 V e V_e Ve 矩阵进行 attention 计算,得到第 1 个输出 “I”;
- 输入 “I am a student” 到 Decoders ,首先通过 Masked Multi-head Attention 层得到 “I am a student” 的 attention 值 Q d Q_d Qd,然后用 attention 值 Q d Q_d Qd 和 Encoders 的输出 K e K_e Ke、 V e V_e Ve 矩阵进行 attention 计算,得到第 2 个输出 “am”;
- ……
现在我们来解释我们之前遗留的两个问题。
11.1 为什么 Decoder 需要做 Mask
-
训练阶段:我们知道 “je suis etudiant” 的翻译结果为 “I am a student”,我们把 “I am a student” 的 Embedding 输入到 Decoders 里面,翻译第一个词 “I” 时
- 如果对 “I am a student” attention 计算不做 mask,“am,a,student” 对 “I” 的翻译将会有一定的贡献
- 如果对 “I am a student” attention 计算做 mask,“am,a,student” 对 “I” 的翻译将没有贡献
-
测试阶段:我们不知道 “我爱中国” 的翻译结果为 “I love China”,我们只能随机初始化一个 Embedding 输入到 Decoders 里面,翻译第一个词 “I” 时:
- 无论是否做 mask,“love,China” 对 “I” 的翻译都不会产生贡献
- 但是翻译了第一个词 “I” 后,随机初始化的 Embedding 有了 “I” 的 Embedding,也就是说在翻译第二词 “love” 的时候,“I” 的 Embedding 将有一定的贡献,但是 “China” 对 “love” 的翻译毫无贡献,随之翻译的进行,已经翻译的结果将会对下一个要翻译的词都会有一定的贡献,这就和做了 mask 的训练阶段做到了一种匹配
总结下就是:Decoder 做 Mask,是为了让训练阶段和测试阶段行为一致,不会出现间隙,避免过拟合
11.2 为什么 Encoder 给予 Decoders 的是 K、V 矩阵
我们在讲解 Attention 机制中曾提到,Query 的目的是借助它从一堆信息中找到重要的信息。
现在 Encoder 提供了 K e 、 V e K_e、V_e Ke、Ve 矩阵,Decoder 提供了 Q d Q_d Qd 矩阵,通过 “我爱中国” 翻译为 “I love China” 这句话详细解释下。
当我们翻译 “I” 的时候,由于 Decoder 提供了 Q d Q_d Qd 矩阵,通过与 K e 、 V e K_e、V_e Ke、Ve 矩阵的计算,它可以在 “我爱中国” 这四个字中找到对 “I” 翻译最有用的单词是哪几个,并以此为依据翻译出 “I” 这个单词,这就很好的体现了注意力机制想要达到的目的,把焦点放在对自己而言更为重要的信息上。
- 其实上述说的就是 Attention 里的 soft attention机制,解决了曾经的 Encoder-Decoder 框架的一个问题,在这里不多做叙述,有兴趣的可以参考网上的一些资料。
- 早期的 Encoder-Decoder 框架中的 Encoder 通过 LSTM 提取出源句(Source) “我爱中国” 的特征信息 C,然后 Decoder 做翻译的时候,目标句(Target)“I love China” 中的任何一个单词的翻译都来源于相同特征信息 C,这种做法是极其不合理的,例如翻译 “I” 时应该着眼于 “我”,翻译 “China” 应该着眼于 “中国”,而早期的这种做法并没有体现出,然而 Transformer 却通过 Attention 的做法解决了这个问题。
十二、GPT 模型
12.1 GPT 模型的预训练
在讲解 ELMo 的时候,我们说到 ELMo 这一类预训练的方法被称为 “Feature-based Pre-Training”。并且如果把 ELMo 这种预训练方法和图像领域的预训练方法对比,发现两者模式看上去还是有很大差异的。
除了以 ELMo 为代表的这种基于特征融合的预训练方法外,NLP 里还有一种典型做法,这种做法和图像领域的方式就是看上去一致的了,一般将这种方法称为 “基于Fine-tuning的模式”,而 GPT 就是这一模式的典型开创者,下面先让我们看看 GPT 的网络结构。
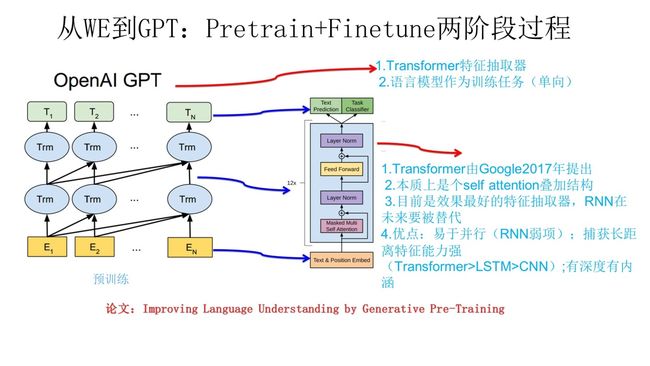
GPT 是 “Generative Pre-Training” 的简称,从名字看其含义是指的生成式的预训练。
GPT也采用两阶段过程:
- 第一个阶段:利用语言模型进行预训练;
- 第二个阶段:通过 Fine-tuning 的模式解决下游任务。
上图展示了 GPT 的预训练过程,其实和 ELMo 是类似的,主要不同在于两点:
- 首先,特征抽取器用的不是 RNN,而是用的 Transformer,它的特征抽取能力要强于RNN,这个选择很明显是很明智的;
- 其次,
- GPT 的预训练虽然仍然是以语言模型作为目标任务,但是采用的是单向的语言模型,所谓 “单向” 的含义是指:语言模型训练的任务目标是根据 w i w_i wi 单词的上下文去正确预测单词 w i w_i wi , w i w_i wi 之前的单词序列Context-before称为上文,之后的单词序列Context-after称为下文。
- ELMo 在做语言模型预训练的时候,预测单词 w i w_i wi 同时使用了上文和下文,而 GPT 则只采用 Context-before 这个单词的上文来进行预测,而抛开了下文。
- GPT 这个选择现在看不是个太好的选择,原因很简单,它没有把单词的下文融合进来,这限制了其在更多应用场景的效果,比如阅读理解这种任务,在做任务的时候是可以允许同时看到上文和下文一起做决策的。如果预训练时候不把单词的下文嵌入到 Word Embedding 中,是很吃亏的,白白丢掉了很多信息。
12.2 GPT 模型的 Fine-tuning
上面讲的是 GPT 如何进行第一阶段的预训练,那么假设预训练好了网络模型,后面下游任务怎么用?它有自己的个性,和 ELMO 的方式大有不同。
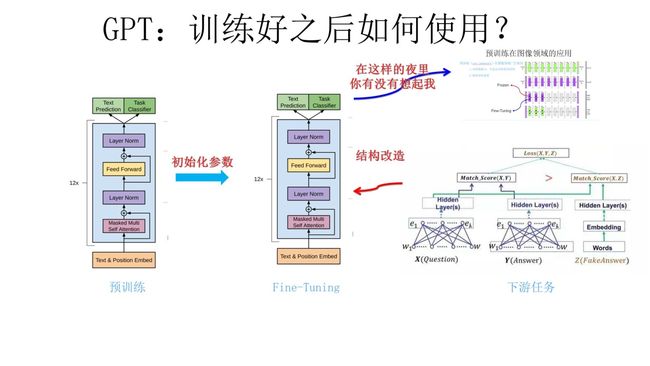
上图展示了 GPT 在第二阶段如何使用:
-
首先,对于不同的下游任务来说,本来你可以任意设计自己的网络结构,现在不行了,你要向 GPT 的网络结构看齐,把任务的网络结构改造成和 GPT 一样的网络结构。
-
然后,在做下游任务的时候,利用第一步预训练好的参数初始化 GPT 的网络结构,这样通过预训练学到的语言学知识就被引入到你手头的任务里来了。
-
再次,你可以用手头的任务去训练这个网络,对网络参数进行 Fine-tuning,使得这个网络更适合解决手头的问题。就是这样。
这有没有让你想起最开始提到的图像领域如何做预训练的过程,对,这跟那个预训练的模式是一模一样的。
对于 NLP 各种花样的不同任务,怎么改造才能靠近 GPT 的网络结构呢?由于 GPT 对下游任务的改造过程和 BERT 对下游任务的改造极其类似,并且我们主要目的是为了讲解 BERT,所以这个问题将会在 BERT 那里得到回答。
十三、BERT 模型
13.1 BERT:公认的里程碑
BERT 模型可以作为公认的里程碑式的模型,但是它最大的优点不是创新,而是集大成者,并且这个集大成者有了各项突破,下面让我们看看 BERT 是怎么集大成者的。
- BERT 的意义在于:从大量无标记数据集中训练得到的深度模型,可以显著提高各项自然语言处理任务的准确率。
- 近年来优秀预训练语言模型的集大成者:参考了 ELMO 模型的双向编码思想、借鉴了 GPT 用 Transformer 作为特征提取器的思路、采用了 word2vec 所使用的 CBOW 方法
- BERT 和 GPT 之间的区别:
- GPT:GPT 使用 Transformer Decoder 作为特征提取器、具有良好的文本生成能力,然而当前词的语义只能由其前序词决定,并且在语义理解上不足
- BERT:使用了 Transformer Encoder 作为特征提取器,并使用了与其配套的掩码训练方法。虽然使用双向编码让 BERT 不再具有文本生成能力,但是 BERT 的语义信息提取能力更强
- 单向编码和双向编码的差异,以该句话举例 “今天天气很{},我们不得不取消户外运动”,分别从单向编码和双向编码的角度去考虑 {} 中应该填什么词:
- 单向编码:单向编码只会考虑 “今天天气很”,以人类的经验,大概率会从 “好”、“不错”、“差”、“糟糕” 这几个词中选择,这些词可以被划为截然不同的两类
- 双向编码:双向编码会同时考虑上下文的信息,即除了会考虑 “今天天气很” 这五个字,还会考虑 “我们不得不取消户外运动” 来帮助模型判断,则大概率会从 “差”、“糟糕” 这一类词中选择
13.2 BERT 的结构:强大的特征提取能力
-
如下图所示,我们来看看 ELMo、GPT 和 BERT 三者的区别
-
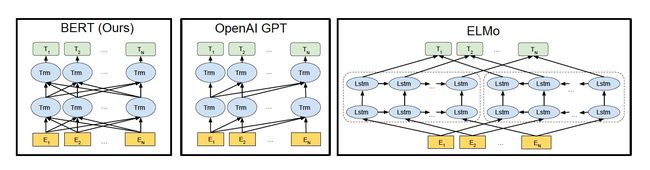
- ELMo 使用自左向右编码和自右向左编码的两个 LSTM 网络,分别以 P ( w i ∣ w 1 , ⋯ , w i − 1 ) P(w_i|w_1,\cdots,w_{i-1}) P(wi∣w1,⋯,wi−1) 和 P ( w i ∣ w i + 1 , ⋯ , w n ) P(w_i|w_{i+1},\cdots,w_n) P(wi∣wi+1,⋯,wn) 为目标函数独立训练,将训练得到的特征向量以拼接的形式实现双向编码,本质上还是单向编码,只不过是两个方向上的单向编码的拼接而成的双向编码。
- GPT 使用 Transformer Decoder 作为 Transformer Block,以 P ( w i ∣ w 1 , ⋯ , w i − 1 ) P(w_i|w_1,\cdots,w_{i-1}) P(wi∣w1,⋯,wi−1) 为目标函数进行训练,用 Transformer Block 取代 LSTM 作为特征提取器,实现了单向编码,是一个标准的预训练语言模型,即使用 Fine-Tuning 模式解决下游任务。
- BERT 也是一个标准的预训练语言模型,它以 P ( w i ∣ w 1 , ⋯ , w i − 1 , w i + 1 , ⋯ , w n ) P(w_i|w_1,\cdots,w_{i-1},w_{i+1},\cdots,w_n) P(wi∣w1,⋯,wi−1,wi+1,⋯,wn) 为目标函数进行训练,BERT 使用的编码器属于双向编码器。
- BERT 和 ELMo 的区别在于使用 Transformer Block 作为特征提取器,加强了语义特征提取的能力;
- BERT 和 GPT 的区别在于使用 Transformer Encoder 作为 Transformer Block,并且将 GPT 的单向编码改成双向编码,也就是说 BERT 舍弃了文本生成能力,换来了更强的语义理解能力。
-
BERT 的模型结构如下图所示:
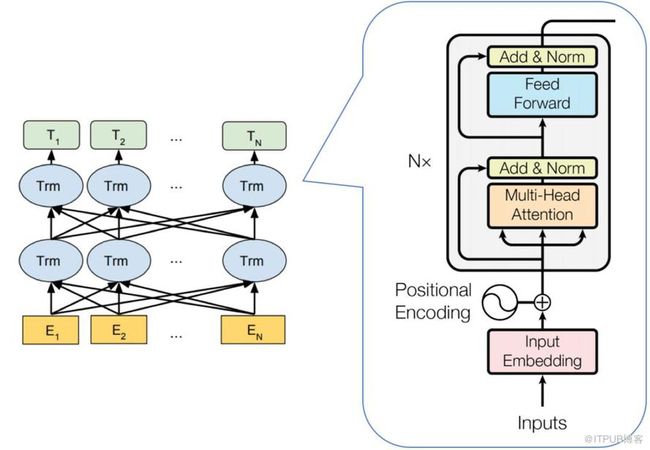
从上图可以发现,BERT 的模型结构其实就是 Transformer Encoder 模块的堆叠。在模型参数选择上,论文给出了两套大小不一致的模型。
B E R T B A S E BERT_{BASE} BERTBASE :L = 12,H = 768,A = 12,总参数量为 1.1 亿
B E R T L A R G E BERT_{LARGE} BERTLARGE:L = 24,H = 1024,A = 16,总参数量为 3.4 亿
其中 L 代表 Transformer Block 的层数;H 代表特征向量的维数(此处默认 Feed Forward 层中的中间隐层的维数为 4H);A 表示 Self-Attention 的头数,使用这三个参数基本可以定义 BERT的量级。
BERT 参数量级的计算公式:
词向量参数 + 12 ∗ ( M u l t i − H e a d s 参数 + 全连接层参数 + l a y e r n o r m 参数) = ( 30522 + 512 + 2 ) ∗ 768 + 768 ∗ 2 + 12 ∗ ( 768 ∗ 768 / 12 ∗ 3 ∗ 12 + 768 ∗ 768 + 768 ∗ 3072 ∗ 2 + 768 ∗ 2 ∗ 2 ) = 108808704.0 ≈ 110 M \begin{align*} & 词向量参数+ 12 * (Multi-Heads参数 + 全连接层参数 + layernorm参数)\\ & = (30522+512 + 2)* 768 + 768 * 2 \\ & + 12 * (768 * 768 / 12 * 3 * 12 + 768 * 768 + 768 * 3072 * 2 + 768 * 2 * 2) \\ & = 108808704.0 \\ & \approx 110M \end{align*} 词向量参数+12∗(Multi−Heads参数+全连接层参数+layernorm参数)=(30522+512+2)∗768+768∗2+12∗(768∗768/12∗3∗12+768∗768+768∗3072∗2+768∗2∗2)=108808704.0≈110M
训练过程也是很花费计算资源和时间的,总之表示膜拜,普通人即便有 idea 没有算力也只能跪着。
13.3 BERT 之无监督训练
和 GPT 一样,BERT 也采用二段式训练方法:
- 第一阶段:使用易获取的大规模无标签余料,来训练基础语言模型;
- 第二阶段:根据指定任务的少量带标签训练数据进行微调训练。
不同于 GPT 等标准语言模型使用 P ( w i ∣ w 1 , ⋯ , w i − 1 ) P(w_i|w_1,\cdots,w_{i-1}) P(wi∣w1,⋯,wi−1) 为目标函数进行训练,能看到全局信息的 BERT 使用 P ( w i ∣ w 1 , ⋯ , w i − 1 , w i + 1 , ⋯ , w n ) P(w_i|w_1,\cdots,w_{i-1},w_{i+1},\cdots,w_n) P(wi∣w1,⋯,wi−1,wi+1,⋯,wn) 为目标函数进行训练。
并且 BERT 用语言掩码模型(MLM)方法训练词的语义理解能力;用下句预测(NSP)方法训练句子之间的理解能力,从而更好地支持下游任务。
13.4 BERT之语言掩码模型(MLM)
BERT 作者认为,使用自左向右编码和自右向左编码的单向编码器拼接而成的双向编码器,在性能、参数规模和效率等方面,都不如直接使用深度双向编码器强大,这也是为什么 BERT 使用 Transformer Encoder 作为特征提取器,而不使用自左向右编码和自右向左编码的两个 Transformer Decoder作为特征提取器的原因。
由于无法使用标准语言模型的训练模式,BERT 借鉴完形填空任务和 CBOW 的思想,使用语言掩码模型(MLM )方法训练模型。
MLM 方法也就是随机去掉句子中的部分 token(单词),然后模型来预测被去掉的 token 是什么。这样实际上已经不是传统的神经网络语言模型(类似于生成模型)了,而是单纯作为分类问题,根据这个时刻的 hidden state 来预测这个时刻的 token 应该是什么,而不是预测下一个时刻的词的概率分布了。
随机去掉的 token 被称作掩码词,在训练中,掩码词将以 15% 的概率被替换成 [MASK],也就是说随机 mask 语料中 15% 的 token,这个操作则称为掩码操作。注意:在CBOW 模型中,每个词都会被预测一遍。
但是这样设计 MLM 的训练方法会引入弊端:在模型微调训练阶段或模型推理(测试)阶段,输入的文本中将没有 [MASK],进而导致产生由训练和预测数据偏差导致的性能损失。
考虑到上述的弊端,BERT 并没有总用 [MASK] 替换掩码词,而是按照一定比例选取替换词。在选择 15% 的词作为掩码词后这些掩码词有三类替换选项:
- 80% 练样本中:将选中的词用 [MASK] 来代替,例如:
“地球是[MASK]八大行星之一”
- 10% 的训练样本中:选中的词不发生变化,该做法是为了缓解训练文本和预测文本的偏差带来的性能损失,例如:
“地球是太阳系八大行星之一”
- 10% 的训练样本中:将选中的词用任意的词来进行代替,该做法是为了让 BERT 学会根据上下文信息自动纠错,例如:
“地球是苹果八大行星之一”
作者在论文中提到这样做的好处是,编码器不知道哪些词需要预测的,哪些词是错误的,因此被迫需要学习每一个 token 的表示向量,另外作者也表示双向编码器比单项编码器训练要慢,进而导致BERT 的训练效率低了很多,但是实验也证明 MLM 训练方法可以让 BERT 获得超出同期所有预训练语言模型的语义理解能力,牺牲训练效率是值得的。
13.5 BERT 之下句预测(NSP)
在很多自然语言处理的下游任务中,如问答和自然语言推断,都基于两个句子做逻辑推理,而语言模型并不具备直接捕获句子之间的语义联系的能力,或者可以说成单词预测粒度的训练到不了句子关系这个层级,为了学会捕捉句子之间的语义联系,BERT 采用了下句预测(NSP )作为无监督预训练的一部分。
NSP 的具体做法是,BERT 输入的语句将由两个句子构成,其中,50% 的概率将语义连贯的两个连续句子作为训练文本(连续句对一般选自篇章级别的语料,以此确保前后语句的语义强相关),另外 50% 的概率将完全随机抽取两个句子作为训练文本。
连续句对:[CLS]今天天气很糟糕[SEP]下午的体育课取消了[SEP]
随机句对:[CLS]今天天气很糟糕[SEP]鱼快被烤焦啦[SEP]
其中 [SEP] 标签表示分隔符。 [CLS] 表示标签用于类别预测,结果为 1,表示输入为连续句对;结果为 0,表示输入为随机句对。
通过训练 [CLS] 编码后的输出标签,BERT 可以学会捕捉两个输入句对的文本语义,在连续句对的预测任务中,BERT 的正确率可以达到 97%-98%。
13.6 BERT 之输入表示
BERT 在预训练阶段使用了前文所述的两种训练方法,在真实训练中一般是两种方法混合使用。
由于 BERT 通过 Transformer 模型堆叠而成,所以 BERT 的输入需要两套 Embedding 操作:
- 一套为 One-hot 词表映射编码(对应下图的 Token Embeddings);
- 另一套为位置编码(对应下图的 Position Embeddings),不同于 Transformer 的位置编码用三角函数表示,BERT 的位置编码将在预训练过程中训练得到(训练思想类似于Word Embedding 的 Q 矩阵)
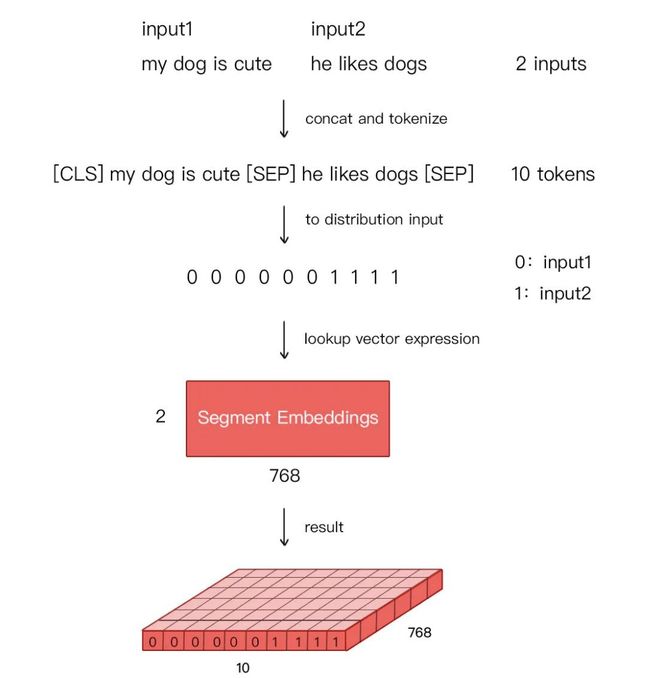
- 由于在 MLM 的训练过程中,存在单句输入和双句输入的情况,因此 BERT 还需要一套区分输入语句的分割编码(对应下图的 Segment Embeddings),BERT 的分割编码也将在预训练过程中训练得到
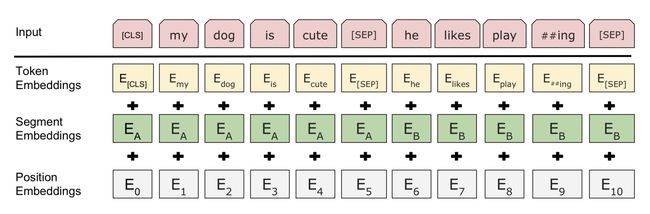
对于分割编码,Segment Embeddings 层只有两种向量表示。前一个向量是把 0 赋给第一个句子中的各个 token,后一个向量是把 1 赋给第二个句子中的各个 token ;如果输入仅仅只有一个句子,那么它的 segment embedding 就是全 0,下面我们简单举个例子描述下:
[CLS]I like dogs[SEP]I like cats[SEP] 对应编码 0 0 0 0 0 1 1 1 1
[SEP]I Iike dogs and cats[SEP] 对应编码 0 0 0 0 0 0 0
十四、BERT 下游任务改造
BERT 根据自然语言处理下游任务的输入和输出的形式,将微调训练支持的任务分为四类,分别是句对分类、单句分类、文本问答和单句标注,接下来我们将简要的介绍下 BERT 如何通过微调训练适应这四类任务的要求。
14.1 句对分类
给定两个句子,判断它们的关系,称为句对分类,例如判断句对是否相似、判断后者是否为前者的答案。
针对句对分类任务,BERT 在预训练过程中就使用了 NSP 训练方法获得了直接捕获句对语义关系的能力。
如下图所示,句对用 [SEP] 分隔符拼接成文本序列,在句首加入标签 [CLS],将句首标签所对应的输出值作为分类标签,计算预测分类标签与真实分类标签的交叉熵,将其作为优化目标,在任务数据上进行微调训练。
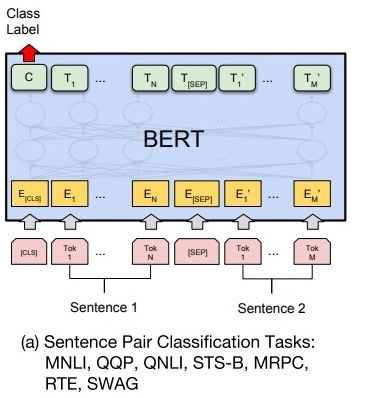
针对二分类任务,BERT 不需要对输入数据和输出数据的结构做任何改动,直接使用与 NSP 训练方法一样的输入和输出结构就行。
针对多分类任务,需要在句首标签 [CLS] 的输出特征向量后接一个全连接层和 Softmax 层,保证输出维数与类别数目一致,最后通过 arg max 操作(取最大值时对应的索引序号)得到相对应的类别结果。
下面给出句对分相似性任务的实例:
任务:判断句子 “我很喜欢你” 和句子 “我很中意你” 是否相似
输入改写:“[CLS]我很喜欢你[SEP]我很中意你”
取 “[CLS]” 标签对应输出:[0.02, 0.98]
通过 arg max 操作得到相似类别为 1(类别索引从 0 开始),即两个句子相似
14.2 单句分类
给定一个句子,判断该句子的类别,统称为单句分类,例如判断情感类别、判断是否为语义连贯的句子。
针对单句二分类任务,也无须对 BERT 的输入数据和输出数据的结构做任何改动。
如下图所示,单句分类在句首加入标签 [CLS],将句首标签所对应的输出值作为分类标签,计算预测分类标签与真实分类标签的交叉熵,将其作为优化目标,在任务数据上进行微调训练。
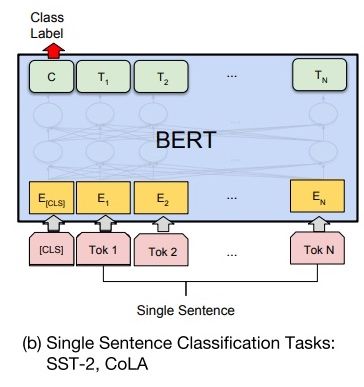
同样,针对多分类任务,需要在句首标签 [CLS] 的输出特征向量后接一个全连接层和 Softmax 层,保证输出维数与类别数目一致,最后通过 argmax 操作得到相对应的类别结果。
下面给出语义连贯性判断任务的实例:
任务:判断句子“海大球星饭茶吃” 是否为一句话
输入改写:“[CLS]海大球星饭茶吃”
取 “[CLS]” 标签对应输出:[0.99, 0.01]
通过 arg max 操作得到相似类别为 0,即这个句子不是一个语义连贯的句子
14.3 文本问答
给定一个问句和一个蕴含答案的句子,找出答案在后这种的位置,称为文本问答,例如给定一个问题(句子 A),在给定的段落(句子 B)中标注答案的其实位置和终止位置。
文本问答任何和前面讲的其他任务有较大的差别,无论是在优化目标上,还是在输入数据和输出数据的形式上,都需要做一些特殊的处理。
为了标注答案的起始位置和终止位置,BERT 引入两个辅助向量 s(start,判断答案的起始位置) 和 e(end,判断答案的终止位置)。
如下图所示,BERT 判断句子 B 中答案位置的做法是,将句子 B 中的每一个次得到的最终特征向量 T i ′ T_i' Ti′ 经过全连接层(利用全连接层将词的抽象语义特征转化为任务指向的特征)后,分别与向量 s 和 e 求内积,对所有内积分别进行 softmax 操作,即可得到词 Tok m( m ∈ [ 1 , M ] m\in [1,M] m∈[1,M])作为答案其实位置和终止位置的概率。最后,去概率最大的片段作为最终的答案。
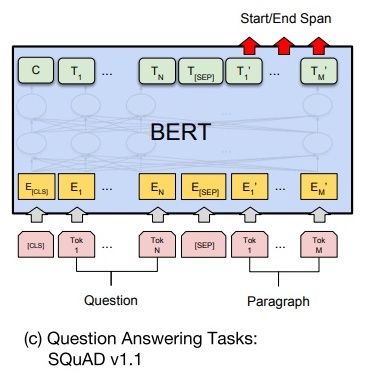
文本回答任务的微调训练使用了两个技巧:
- 用全连接层把 BERT 提取后的深层特征向量转化为用于判断答案位置的特征向量
- 引入辅助向量 s 和 e 作为答案其实位置和终止位置的基准向量,明确优化目标的方向和度量方法
下面给出文本问答任务的实例:
任务:给定问句 “今天的最高温度是多少”,在文本 “天气预报显示今天最高温度 37 摄氏度” 中标注答案的起始位置和终止位置
输入改写:“[CLS]今天的最高温度是多少[SEP]天气预报显示今天最高温度 37 摄氏度”
BERT Softmax 结果:
篇章文本 天气 预报 显示 今天 最高温 37 摄氏度 起始位置概率 0.01 0.01 0.01 0.04 0.10 0.80 0.03 终止位置概率 0.01 0.01 0.01 0.03 0.04 0.10 0.80 对 Softmax 的结果取 arg max,得到答案的起始位置为 6,终止位置为 7,即答案为 “37 摄氏度”
14.4 单句标注
给定一个句子,标注每个次的标签,称为单句标注。例如给定一个句子,标注句子中的人名、地名和机构名。
单句标注任务和 BERT 预训练任务具有较大差异,但与文本问答任务较为相似。
如下图所示,在进行单句标注任务时,需要在每个词的最终语义特征向量之后添加全连接层,将语义特征转化为序列标注任务所需的特征,单句标注任务需要对每个词都做标注,因此不需要引入辅助向量,直接对经过全连接层后的结果做 Softmax 操作,即可得到各类标签的概率分布。
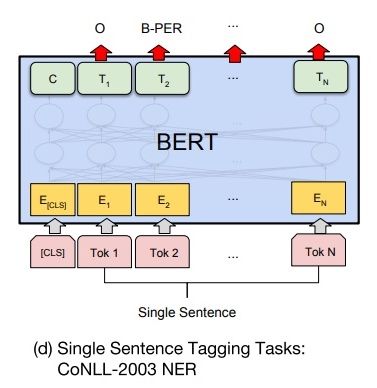
由于 BERT 需要对输入文本进行分词操作,独立词将会被分成若干子词,因此 BERT 预测的结果将会是 5 类(细分为 13 小类):
- O(非人名地名机构名,O 表示 Other)
- B-PER/LOC/ORG(人名/地名/机构名初始单词,B 表示 Begin)
- I-PER/LOC/ORG(人名/地名/机构名中间单词,I 表示 Intermediate)
- E-PER/LOC/ORG(人名/地名/机构名终止单词,E 表示 End)
- S-PER/LOC/ORG(人名/地名/机构名独立单词,S 表示 Single)
将 5 大类的首字母结合,可得 IOBES,这是序列标注最常用的标注方法。
下面给出命名实体识别(NER)任务的示例:
任务:给定句子 “爱因斯坦在柏林发表演讲”,根据 IOBES 标注 NER 结果
输入改写:“[CLS]爱 因 斯坦 在 柏林 发表 演讲”
BERT Softmax 结果:
BOBES 爱 因 斯坦 在 柏林 发表 演讲 O 0.01 0.01 0.01 0.90 0.01 0.90 0.90 B-PER 0.90 0.01 0.01 0.01 0.01 0.01 0.01 I-PER 0.01 0.90 0.01 0.01 0.01 0.01 0.01 E-PER 0.01 0.01 0.90 0.01 0.01 0.01 0.01 S-LOC 0.01 0.01 0.01 0.01 0.01 0.01 0.01 对 Softmax 的结果取 arg max,得到最终地 NER 标注结果为:“爱因斯坦” 是人名;“柏林” 是地名
14.5 BERT效果展示
无论如何,从上述讲解可以看出,NLP 四大类任务都可以比较方便地改造成 Bert 能够接受的方式,总之不同类型的任务需要对模型做不同的修改,但是修改都是非常简单的,最多加一层神经网络即可。这其实是 Bert 的非常大的优点,这意味着它几乎可以做任何NLP的下游任务,具备普适性,这是很强的。
但是讲了这么多,**一个新模型好不好,效果才是王道。**那么Bert 采用这种两阶段方式解决各种 NLP 任务效果如何?
在 11 个各种类型的 NLP 任务中达到目前最好的效果,某些任务性能有极大的提升。

十五、预训练语言模型总结

到这里我们可以再梳理下几个模型之间的演进关系。
从上图可见,Bert 其实和 ELMO 及 GPT 存在千丝万缕的关系,比如如果我们把 GPT 预训练阶段换成双向语言模型,那么就得到了 Bert;而如果我们把 ELMO 的特征抽取器换成 Transformer,那么我们也会得到Bert。
所以你可以看出:Bert最关键两点,一点是特征抽取器采用 Transformer;第二点是预训练的时候采用双向语言模型。
那么新问题来了:对于 Transformer 来说,怎么才能在这个结构上做双向语言模型任务呢?乍一看上去好像不太好搞。我觉得吧,其实有一种很直观的思路,怎么办?看看 ELMO 的网络结构图,只需要把两个 LSTM 替换成两个 Transformer,一个负责正向,一个负责反向特征提取,其实应该就可以。
当然这是我自己的改造,Bert 没这么做。那么 Bert 是怎么做的呢?我们前面不是提过 Word2Vec 吗?我前面肯定不是漫无目的地提到它,提它是为了在这里引出那个 CBOW 训练方法,所谓写作时候埋伏笔的 “草蛇灰线,伏脉千里”,大概就是这个意思吧?
前面提到了 CBOW 方法,它的核心思想是:在做语言模型任务的时候,我把要预测的单词抠掉,然后根据它的上文 Context-Before 和下文 Context-afte r去预测单词。
其实 Bert 怎么做的?Bert 就是这么做的。从这里可以看到方法间的继承关系。当然 Bert 作者没提 Word2Vec 及 CBOW 方法,这是我的判断,Bert 作者说是受到完形填空任务的启发,这也很可能,但是我觉得他们要是没想到过 CBOW 估计是不太可能的。
从这里可以看出,在文章开始我说过 Bert 在模型方面其实没有太大创新,更像一个最近几年 NLP 重要技术的集大成者,原因在于此,当然我不确定你怎么看,是否认同这种看法,而且我也不关心你怎么看。其实 Bert 本身的效果好和普适性强才是最大的亮点。
最后,我讲讲我对Bert的评价和看法,我觉得 Bert 是 NLP 里里程碑式的工作,对于后面 NLP 的研究和工业应用会产生长久的影响,这点毫无疑问。但是从上文介绍也可以看出,从模型或者方法角度看,Bert 借鉴了 ELMO,GPT 及 CBOW,主要提出了 Masked 语言模型及 Next Sentence Prediction,但是这里 Next Sentence Prediction 基本不影响大局,而 Masked LM 明显借鉴了 CBOW 的思想。所以说 Bert 的模型没什么大的创新,更像最近几年 NLP 重要进展的集大成者,这点如果你看懂了上文估计也没有太大异议,如果你有大的异议,杠精这个大帽子我随时准备戴给你。
如果归纳一下这些进展就是:首先是两阶段模型,第一阶段双向语言模型预训练,这里注意要用双向而不是单向,第二阶段采用具体任务 Fine-tuning 或者做特征集成;第二是特征抽取要用Transformer 作为特征提取器而不是 RNN 或者 CNN;第三,双向语言模型可以采取 CBOW 的方法去做(当然我觉得这个是个细节问题,不算太关键,前两个因素比较关键)。Bert 最大的亮点在于效果好及普适性强,几乎所有 NLP 任务都可以套用 Bert 这种两阶段解决思路,而且效果应该会有明显提升。可以预见的是,未来一段时间在 NLP 应用领域,Transformer 将占据主导地位,而且这种两阶段预训练方法也会主导各种应用。
另外,我们应该弄清楚预训练这个过程本质上是在做什么事情,本质上预训练是通过设计好一个网络结构来做语言模型任务,然后把大量甚至是无穷尽的无标注的自然语言文本利用起来,预训练任务把大量语言学知识抽取出来编码到网络结构中,当手头任务带有标注信息的数据有限时,这些先验的语言学特征当然会对手头任务有极大的特征补充作用,因为当数据有限的时候,很多语言学现象是覆盖不到的,泛化能力就弱,集成尽量通用的语言学知识自然会加强模型的泛化能力。如何引入先验的语言学知识其实一直是 NLP 尤其是深度学习场景下的 NLP 的主要目标之一,不过一直没有太好的解决办法,而 ELMO/GPT/Bert 的这种两阶段模式看起来无疑是解决这个问题自然又简洁的方法,这也是这些方法的主要价值所在。
对于当前 NLP 的发展方向,我个人觉得有两点非常重要:
- 一个是需要更强的特征抽取器,目前看 Transformer 会逐渐担当大任,但是肯定还是不够强的,需要发展更强的特征抽取器;
- 第二个就是如何优雅地引入大量无监督数据中包含的语言学知识,注意我这里强调地是优雅,而不是引入,此前相当多的工作试图做各种语言学知识的嫁接或者引入,但是很多方法看着让人牙疼,就是我说的不优雅。
目前看预训练这种两阶段方法还是很有效的,也非常简洁,当然后面肯定还会有更好的模型出现。
完了,这就是预训练语言模型的前世今生。
由于个人刚入门 NLP 方向,就不妄自总结,上述总结全部来自知乎文章:从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史-张俊林
十六、参考资料
我只是知识的搬运工,想详细了解各个知识点的读者可以自行选择参考下列资料。
参考书籍:
《预训练语言模型》- 卲浩、刘一烽
《基于 BERT 模型的自然语言处理实战》- 李金洪
参考论文:
- Attention Is All You Need
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
参考博客:
- 深度学习中的注意力模型(2017版)
- 细讲 | Attention Is All You Need
- 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
- Attention和Transformer详解
- 【NLP】Transformer模型原理详解
- LSTM如何解决RNN带来的梯度消失问题
- The Illustrated Transformer