MySQL 日志体系解析:保障数据一致性与恢复的三位英雄:Redo Log、Undo Log、Bin Log

- 前言
- Redo Log
-
- Redo Log 写入执行过程
- Redo Log 写入方式
- Undo Log
- Bin Log
-
- Bin Log、Redo Log 之间的区别
- Bin Log 写入方式
- Bin Log 恢复误删数据
- 二阶段提交>数据更新
- 总结
前言
MySQL Redo Log、Undo Log、Bin Log 三大日志与数据库事务相挂钩,之前在介绍 MySQL 事务时,提及到了它的四大特性,原子性、一致性、隔离性、持久性
- 原子性:由 MySQL Undo Log 日志来实现,并保证事务的原子性操作
- 隔离性:由隔离级别、锁来保证
- 持久性:通过 InnoDB 存储引擎 Redo Log 日志来实现
Redo Log
Redo Log 日志是 InnoDB 存储引擎中的日志文件,用它来保证事务的持久化操作,以下是 Redo Log 几大作用
- 数据持久性保证:Redo Log 记录了 InnoDB 存储引擎在执行事务期间所做的修改操作 > 插入、更新、删除操作等。通过将这些操作记录到 Redo Log 日志中,即使数据库发生异常关闭或重启,之前的记录也不会丢失,叫做
crash-safe - 事务持久性保证:在提交事务之前,InnoDB 存储引擎会先将记录写入到 Redo Log 日志中,并更新对应的内存缓冲区,同时会在合适的时机将修改后的记录刷写到磁盘中去。即使提交事务之前,发生了故障,MySQL 还可以通过 Redo Log 来重新执行未完成的事务,确保事务持久性
- 故障恢复:当数据库异常关闭或重启时,MySQL 可以利用 Redo Log 来进行故障恢复
- 提高性能:Redo Log 设计采用了顺序写的方式,相比于随机写入,顺序写入 Redo Log 的性能更高
Redo Log 写入执行过程
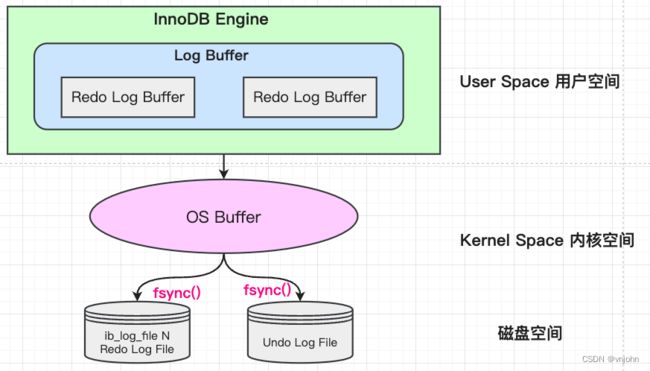
在操作系统中分为两种空间:用户空间、内核空间,最下面是磁盘空间
如上图,当更新完数据,一旦提交先将操作记录写入到 Redo Log 中,会保存到 Log Buffer 空间;随即 Log Buffer 会将数据写入到 OS Buffer,OS Buffer 会触发系统调用
fsync() 异步写入到磁盘中
Redo Log 写入方式
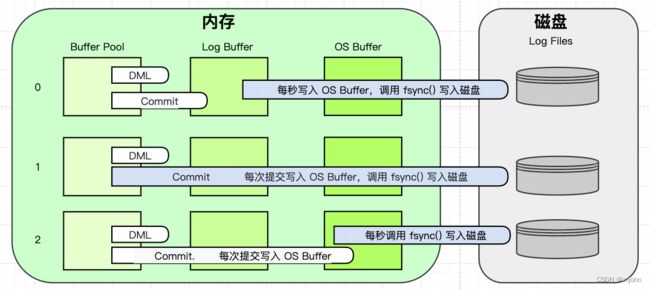
在 MySQL 中,Redo Log 写入方式可以通过 innodb_flush_log_at_trx_commit 参数进行配置,该参数有三个可选的取值:0、1、2,分别代表不同的写入方式,默认值为 1,通过以下 SQL 查看
show VARIABLES like 'innodb_flush_log_at_trx_commit';
- innodb_flush_log_at_trx_commit = 0: 表示异步写入方式,在每个事务提交时,Redo Log 写入磁盘操作被延迟,并且可能会与多个事务的写入操作组合在一起批量写入;这种方式可以提高较高的性能,但会存在一定的数据丢失风险,因为在发生故障时,尚未写入磁盘的 Redo Log 日志可能会丢失
- innodb_flush_log_at_trx_commit = 1: 表示同步写入方式,在每个事务提交时,Redo Log 写入操作会被立马刷写到磁盘中;这种方式可以提高最高的数据安全性,因为在事务提交后,Redo Log 已经持久化到磁盘中,即使发生故障,也可以保证不丢失任何已提交的事务
若提交的频率比较高,那么每次写入到磁盘都是一次磁盘 IO,这样产生的 IO 次数肯定是很多的,但相对于其他两种方式,每次都能保证写入到磁盘中
- innodb_flush_log_at_trx_commit = 2: 表示延迟写入方式,在每个事务提交时,Redo Log 写入操作被延迟,但在事务提交后的一定时间内会将数据刷写到磁盘中;这种方式折中了性能、数据安全性,可以提高很好的性能和一定程度的保护
0、2 这两种方式在批量提交时效率比较快,一秒钟可能积累的事务数会很多,但是数据存在不安全,可能会丢失一秒钟的数据
总而言之,数据安全性、性能两者不能同时都保证,选择适当的配置值需要根据应用程序的需求以及对数据安全性的要求两者进行 Trade Off!
在 MySQL 中,还有一些常用参数可以支持 Redo Log 配置,如下:
- innodb_log_file_size:该参数用于配置每个 Redo Log 文件大小,以字节为单位,较大的 Redo Log 文件大小可以减少 Redo Log 切换的频率,从而提升性能,默认值为 50 MB
- innodb_log_files_in_group:该参数用于配置 Redo Log 文件数量,增加 Redo Log 文件数量可以增加 Redo Log 并发写入能力,从而提交整体性能,默认值为 2
- innodb_log_buffer_size:该参数用于配置 Redo Log 缓冲区大小,以字节为单位,增加缓冲区大小可以提高 Redo Log 写入性能,但同时也会占用更多的内存,默认值为 16 MB
这些参数可以通过修改 MySQL 配置文件(my.cnf 或 my.ini)来进行设置,在进行更改之前建议备份数据库。不正确的参数配置可能会对数据库的性能、稳定性产生影响,并测试环境中进行充分测试和评估
Undo Log
Undo Log 日志是 InnoDB 存储引擎中的日志文件,用它来保证事务的原子性操作
在操作任何数据之前,首先将数据备份到一个地方(这个存储数据备份的地方成为 Undo Log)然后进行修改操作,若出现错误或者用户执行了 ROLLBACK 语句,系统可以利用 Undo Log 中的备份数据恢复到事务开始之前的状态
Undo Log 主要作用是支持数据库的事务回滚、MVCC(多版本并发控制)详细内容如下:
- 事务回滚:当发生事务回滚时,MySQL 可以使用 Undo Log 来撤销已经提交的事务所做的修改操作,将数据恢复到事务开始之前的状态。通过 Undo Log,MySQL 能够保证事务的原子性,即事务要么全部成功,要么全部回滚,不会出现部分提交的情况
Undo Log 是逻辑日志,可以理解为
1、当 delete 一条记录时,Undo Log 会生成一条对应的 insert 记录
2、当 insert 一条记录时,Undo Log 会生成一条对应的 delete 记录
3、当 update 一条记录时,Undo Log 会生成相反的 update 记录
- MVCC 支持:MySQL 使用 Undo Log 来实现 MVCC 机制,以支持并发事务之间的隔离性,在 MVCC 中,每个事务都能够看到一致性的数据快照,而不会被其他事务的修改所干扰(结合事务的隔离级别)
- 数据版本管理:Undo Log 记录了事务修改操作的逆操作日志,因此可以用来回滚事务、撤销数据的修改,通过维护不同版本的数据,MySQL 能够使得读取、写入操作可以同时进行,提高数据库的并发性能
- 回收空间:当事务提交后,Undo Log 对应的数据操作已经生效,并且数据库的数据文件已经发生了相应修改,此时,Undo Log 记录的旧版本数据可以被回收空间,释放占用的资源
Bin Log
Bin Log(二进制日志)日志是 MySQL Server 层面的日志文件,主要用于作 MySQL 功能层面的事情,同时它也可以用来作数据的复制、恢复、故障恢复工作
Bin Log 几个主要的作用如下:
- 数据复制:Bin Log 被用于数据库的主从复制,当启用了主从复制时,主数据库会将其接收到的修改操作记录到 Bin Log 中,然后从数据库通过读取 Bin Log 中数据进行重放,从而将主数据库的修改操作记录同步到从数据库,这样可以实现数据的复制、不同节点数据之间的同步
- 数据恢复:Bin Log 可以用于恢复数据,尤其在灾难恢复、误操作时非常有用;通过将 Bin Log 中操作重新执行,可以将数据库恢复到待定的时间点或待定的事务状态,Bin Log 对于数据额恢复、修复非常重要
- 故障恢复:当数据库发生故障、崩溃、宕机时,可以利用 Bin Log 来进行故障恢复,通过重新执行 Bin Log 中未提交的事务,可以恢复到故障发生前的状态,以此来确保数据的一致性、完整性
- 数据审计、追踪:Bin Log 记录了数据库所有修改操作,包括数据插入、更新、删除,这可以用来做数据审计、追踪,了解操作数据库的历史记录,跟踪特定数据的修改记录,以及满足合规、安全性要求
需要注意的是,Bin Log 是基于事务的日志,只记录对数据的修改操作,而不包括查询操作
Bin Log、Redo Log 之间的区别
- 作用范围不同:Redo Log 是 InnoDB 存储引擎独有的,Bin Log 是所有存储引擎都可以使用的
- 存储位置、形式不同
Bin Log 以文件的形式存储在磁盘上,通常会有多个 Bin Log 文件组成一个序列,每个文件都有一个递增的序号。Bin Log 文件是追加写入的,新的修改操作会不断追加到最新的 Bin Log 文件中
Redo Log 以循环写入的方式存储在磁盘上,通常会有多个 Redo Log 文件组成一个循环队列。当 Redo Log 写入位置到达文件末尾时,会回到文件的起始位置再次进行循环写入
- 写入时机、方式不同
Bin Log 写入是在事务提交时进行的,即在事务完成之后将修改操作记录到 Bin Log 中。Bin Log 写入可以是同步或异步的,可以通过参数配置来调整
Redo Log 写入是在事务执行期间进行的,即在事务进行修改操作时就会将相应的 Redo Log 记录写入到 Redo Log 文件中。Redo Log 写入是顺序写入的,采用追加写的方式
Bin Log 写入方式
Bin Log 写入方式可以通过 sync_binlog 参数进行配置,它有三种取值,如下:
- sync_binlog = 0:表示异步写入方式,即当事务提交后不等待将 Bin Log 数据写入到磁盘,而是将其缓存到内存中,从而提高写入性能
- sync_bin_log = 1:表示同步写入方式,即当事务提交后等待 Bin Log 数据写入到磁盘成功后,才返回给客户端结果,降低了写入性能提高了数据安全性
- sync_binlog = N(N > 1):表示每 N 个事务同步写入一次,当 N > 1 时,MySQL 将使用批量写入的方式,每处理 N 个事务后将 Bin Log 数据批量写入磁盘,并等待确认写入完成返回,折中了性能、数据安全性,减少了频繁的磁盘写入操作
Bin Log 恢复误删数据
首先通过 Bin Log 来恢复误删除的数据,要确认 Bin Log 是否开启,若未开启,可能你丢失的数据就很难溯源了
SHOW VARIABLES LIKE 'log_bin';
通过以下这种方式,开启 Bin Log
- 找到 MySQL 配置文件:my.cnf 或 my,ini,在 Linux 系统中,一般文件放在 /etc 目录下
- vim 打开配置文件,追加内容如下:
[mysqld]
# 服务 id,开启 bin log 要标识服务端
server-id=1
# 开启 Bin Log,二进制文件基本存储目录 > /var/lib/mysql/binlog
log_bin=/var/lib/mysql/binlog
:wq! 保存后退出,修改存储目录权限 > chomod 755 /var/lib/mysql/binlog
- 配置文件修改后保存好,执行重启 MySQL 命令:
sudo systemctl restart mysqld,等待数据库服务重启以后,再次执行SHOW VARIABLES LIKE 'log_bin';命令观察 Bin Log 是否开启成功
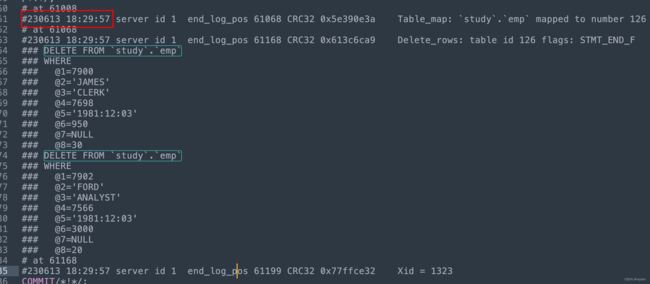
确认好 Bin Log 已开启好以后,操作一条删除语句,比如:
DELETE from emp where empno in(7900,7902);
然后在 /var/lib/mysql 目录下就能看到 bin log 日志文件了

通过以下命令来进行观察,将二机制转为 SQL 语句导出在本地文件 > output.sql,如下:
# --start-datetime="2023-06-13 18:28:00" --stop-datetime="2023-06-13 18:34:00"
# 通过时间点范围导出部分数据,而不是全量数据,便于快速定位到需要的数据部分
mysqlbinlog --no-defaults --base64-output=decode-rows -v binlog.000001 > output.sql
最终,通过观察文件内容找出了原始的数据,可以对它进行恢复操作
二阶段提交>数据更新
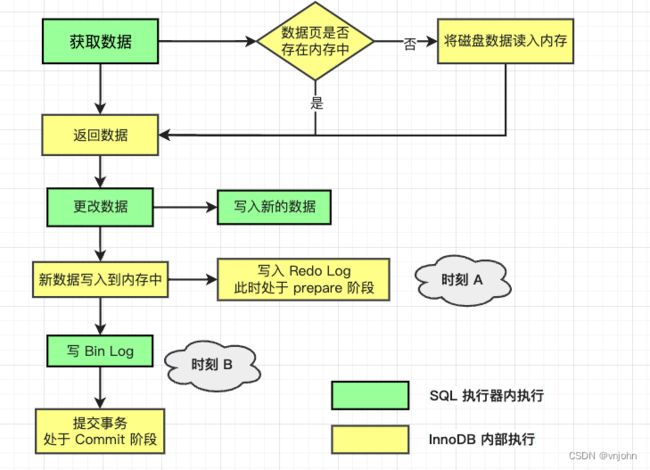
如上图,数据更新执行过程分为以下几点
- 执行器先从存储引擎获取数据,若在内存中直接返回,否则先从 B+ 树中查询后再返回
- 执行器获取数据后返回,进行数据的修改操作,然后调用存储引擎重新写入数据
- 存储引擎将数据更新到内存中,同时写数据到 Redo Log 中,当前处于 prepare 阶段,并通知执行器去继续向下执行,随时可以进行操作
- 执行器生成这个更新操作的 Bin Log
- 执行器调用存储引擎的事务机制提交数据,当前处于 commit 阶段,存储引擎把刚刚写完的 Redo Log 改为 commit 状态
为什么 Redo Log 要采用两阶段提交,假设不使用两阶段,举例场景如下:
1、先写完 Redo Log 后再写 Bin Log
属性:name,由 choshim -> vnjohn
假设在 Redo Log 写完,Bin Log 还未写完时,MySQL 进程异常重启;由于前面所提及到的,Redo Log 写完之后,即使系统崩溃了,仍然能够把数据恢复回来,所以恢复后 name 值变为 choshim,但是由于 Bin Log 没写完就 crash 了,这时候 Bin Log 里面讲究没有这条语句;因此,在之后备份日志的时候,Bin Log 存起来的数据里面就没有这条语句;最后,你会发现,若使用这个 Bin Log 来恢复临时库的话,由于这条语句的 Bin Log 丢失,临时库就会少了这一次数据更新,恢复出来的这一条数据 name 值为 choshim,与原有库中的值不同
2、先写 Bin Log 后再写 Redo Log
属性:name,由 choshim -> vnjohn
假设在 Bin Log 写完之后 crash 了,由于 Redo Log 还没写,崩溃恢复这个事务无效,所以这一条数据 name 属性值为 choshim;但 Bin Log 里面已经记录了 “把 name 从 choshim 改为 vnjohn” 日志;所以,之后用 Bin Log 来进行恢复时就会多出了一条更新操作的事务出来,恢复出来的这一条数据 name 属性值为 vnjohn,与原有库值不同
因为以上这两种问题,谁先写谁后写都会发生问题,所以要解决这种一致性问题,就不得已要采取分阶段的方式来保证事务的完整性
如上图在时刻 A 的地方,也就是写入 Redo Log 处于 prepare 阶段之后、写 Bin Log 之前,发生了系统崩溃 crash,由于此时 Bin Log 还没写入,Redo Log 也还没进行提交;所以崩溃恢复时,这个事务会进行回滚,同时,Bin Log 还没写入,所以也不会传给备用库
若在 Redo Log 里面的事务是完整的,也就是有了 commit 标识,则直接提交;若 Redo Log 里面的事务只有完整的 prepare 阶段,则判断对应事务的 Bin Log 是否存在并完整
1、若事务的 Bin Log 完整,则提交事务
2、若事务的 Bin Log 不完整,则回滚事务
若是在时刻 B 发生 crash,在崩溃恢复过程中事务是会被提交的
PS:两阶段提交的最后一阶段操作本身是不会失败的,除非是系统或硬件发生了错误,所以也就不再需要回滚
总结
该篇博文从浅入深的讲解了 MySQL 中三大日志 > Redo Log、Undo Log、Bin Log 三大日志体系,Redo Log、Undo Log 是 InnoDB 存储引擎内的日志,Bin Log 是 MySQL Server 层面的日志,接着仔细说明了它们各自的作用,包括了写入的执行过程、写入的方式,实战方面,演示了如何使用 Bin Log 恢复误删的数据,最后,分析了为什么要采用两阶段提交方式来完成 Redo Log、Bin Log 记录以及数据更新!
MySQL 专栏高质量博文如下:
MySQL 内置的监控工具介绍及使用篇
构建优化之城:MySQL 数据建模、数据类型优化与索引常识全面解析
MySQL 数据结构优化与索引细节解析:打造高效数据库的优化秘笈
MySQL 数据访问与查询优化:提升性能的实战策略和解耦优化技巧
深度解析 MySQL 事务、隔离级别和 MVCC 机制:构建高效并发的数据交响乐
如果觉得博文不错,关注我 vnjohn,后续会有更多实战、源码、架构干货分享!
推荐专栏:Spring、MySQL,订阅一波不再迷路
大家的「关注❤️ + 点赞 + 收藏⭐」就是我创作的最大动力!谢谢大家的支持,我们下文见!