6.2.1 Spark Core(Spark概述、RDD编程【特点、RDD创建、Transformation(常见算子)、Key-ValueRDD操作】)
Spark Core
文章目录
- Spark Core
- 第1节 Spark概述
-
- 1.1 什么是Spark
- 1.2 Spark 与 Hadoop
- 1.3 系统架构
- 1.4 Spark集群部署模式
- 1.5 相关术语
- 第3节 RDD编程
-
- 3.1 什么是RDD
- 3.2 RDD的特点
-
- **1、分区**
- **2、只读**
- 3、依赖
- 4、缓存
- 5、checkpoint
- 3.3 Spark编程模型
- 3.4 RDD的创建
-
- 1、SparkContext
- 2、从集合创建RDD
- 3、从文件系统创建RDD
- 4、从RDD创建RDD
- 3.5 Transformation【重要】
-
- **常见转换算子1**
- 常见转换算子2
- 常见转换算子3
- 3.6 Action
- 3.7 Key-Value RDD操作
-
- 3.7.1 创建Pair RDD
- 3.7.2 Transformation操作
-
- **1、类似 map 操作**
- **2、聚合操作【重要、难点】**
-
- groupByKey
- reduceByKey
- foldByKey
- aggregateByKey
- 3、排序操作
- 4、join操作
- 3.7.3 Action操作
- 3.8 输入与输出
-
- 3.8.1 文件输入与输出
-
- 1、文本文件
- 2、csv文件
- 3、json文件
- 4、SequenceFile
- 5、对象文件
- 3.8.2 JDBC
- 3.9 算子综合应用案例
-
- 1、WordCount - scala
- 2、WordCount - java
- 3、计算圆周率
- 4、广告数据统计
- 5、找共同好友
- 6、Super WordCount
第1节 Spark概述
1.1 什么是Spark
Spark是当今大数据领域最活跃、最热门、最高效的大数据通用计算引擎
2009年诞生于美国加州大学伯克利分校AMP 实验室
2010年通过BSD许可协议开源发布
2013年捐赠给Apache软件基金会并切换开源协议到切换许可协议至 Apache2.0
2014年2月,Spark 成为 Apache 的顶级项目
2014年11月, Spark的母公司Databricks团队使用Spark刷新数据排序世界记录
Spark 成功构建起了一体化、多元化的大数据处理体系。在任何规模的数据计算中,
Spark 在性能和扩展性上都更具优势

Spark 是一个快速、通用的计算引擎。Spark的特点:
- 速度快。与 MapReduce 相比,Spark基于内存的运算要快100倍以上,基于硬
盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内
存来高效处理数据流; - 使用简单。Spark支持 Scala、Java、Python、R的API,还支持超过80种高级算
法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala
的shell,可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法; - 通用。Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询
(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算
(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。Spark统一的
解决方案非常具有吸引力,企业想用统一的平台去处理遇到的问题,减少开发和
维护的人力成本和部署平台的物力成本; - 兼容好。Spark可以非常方便地与其他的开源产品进行融合。Spark可以使用
YARN、Mesos作为它的资源管理和调度器;可以处理所有Hadoop支持的数
据,包括HDFS、HBase和Cassandra等。这对于已经部署Hadoop集群的用户特
别重要,因为不需要做任何数据迁移就可以使用Spark的强大处理能力。Spark
也可以不依赖于第三方的资源管理和调度器,它实现了Standalone作为其内置
的资源管理和调度框架,这样进一步降低了Spark的使用门槛,使得所有人都可
以非常容易地部署和使用Spark。此外,Spark还提供了在EC2上部署
Standalone的Spark集群的工具。
1.2 Spark 与 Hadoop
从狭义的角度上看:Hadoop是一个分布式框架,由存储、资源调度、计算三部分组
成;
Spark是一个分布式计算引擎,由 Scala 语言编写的计算框架,基于内存的快速、通
用、可扩展的大数据分析引擎;
从广义的角度上看,Spark是Hadoop生态中不可或缺的一部分;
MapReduce的不足:
- 表达能力有限
- 磁盘IO开销大
- 延迟高
- 任务之间的衔接有IO开销
- 在前一个任务执行完成之前,后一个任务无法开始。难以胜任复杂的、多阶
段计算任务
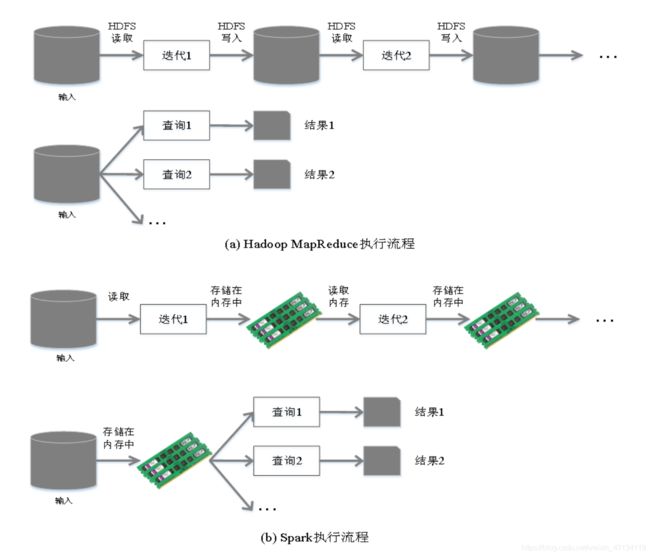
Spark在借鉴MapReduce优点的同时,很好地解决了MapReduce所面临的问题。

备注:Spark的计算模式也属于MapReduce;Spark框架是对MR框架的优化;
在实际应用中,大数据应用主要包括以下三种类型:
- 批量处理(离线处理):通常时间跨度在数十分钟到数小时之间
- 交互式查询:通常时间跨度在数十秒到数分钟之间
- 流处理(实时处理):通常时间跨度在数百毫秒到数秒之间
当同时存在以上三种场景时,传统的Hadoop框架需要同时部署三种不同的软件。
如:
- MapReduce / Hive 或 Impala / Storm
这样做难免会带来一些问题:
- 不同场景之间输入输出数据无法做到无缝共享,通常需要进行数据格式的转换
- 不同的软件需要不同的开发和维护团队,带来了较高的使用成本
- 比较难以对同一个集群中的各个系统进行统一的资源协调和分配
Spark所提供的生态系统足以应对上述三种场景,即同时支持批处理、交互式查询和
流数据处理:
- Spark的设计遵循“一个软件栈满足不同应用场景”的理念(all in one),逐渐形
成了一套完整的生态系统 - 既能够提供内存计算框架,也可以支持SQL即席查询、实时流式计算、机器学习
和图计算等 - Spark可以部署在资源管理器YARN之上,提供一站式的大数据解决方案
Spark 为什么比 MapReduce 快:
1、Spark积极使用内存。MR框架中一个Job 包括一个 map 阶段(一个或多个map
task) 和一个 reduce 阶段(一个或多个 reduce Task)。如果业务处理逻辑复杂,
此时需要将多个 job 组合起来;然而前一个job的计算结果必须写到HDFS,才能交给
后一个job。这样一个复杂的运算,在MR框架中会发生很多次写入、读取操作;
Spark框架可以把多个map reduce task组合在一起连续执行,中间的计算结果不需
要落地;
复杂的MR任务:mr + mr + mr + mr +mr …
复杂的Spark任务:mr -> mr -> mr …
2、多进程模型(MR) vs 多线程模型(Spark)。MR框架中的的Map Task和Reduce
Task是进程级别的,而Spark Task是基于线程模型的。MR框架中的 map task、
reduce task都是 jvm 进程,每次启动都需要重新申请资源,消耗了不必要的时间。
Spark则是通过复用线程池中的线程来减少启动、关闭task所需要的系统开销。
1.3 系统架构
Spark运行架构包括:
- Cluster Manager
- Worker Node
- Driver
- Executor
Cluster Manager 是集群资源的管理者。Spark支持3种集群部署模式:
Standalone、Yarn、Mesos;
Worker Node 工作节点,管理本地资源;
Driver Program。运行应用的 main() 方法并且创建了 SparkContext。由Cluster
Manager分配资源,SparkContext 发送 Task 到 Executor 上执行;
Executor:在工作节点上运行,执行 Driver 发送的 Task,并向 Driver 汇报计算结
果;

1.4 Spark集群部署模式
Spark支持3种集群部署模式:Standalone、Yarn、Mesos;
1、Standalone模式
- 独立模式,自带完整的服务,可单独部署到一个集群中,无需依赖任何其他资源
管理系统。从一定程度上说,该模式是其他两种的基础 - Cluster Manager:Master
- Worker Node:Worker
- 仅支持粗粒度的资源分配方式
2、Spark On Yarn模式
- Yarn拥有强大的社区支持,且逐步已经成为大数据集群资源管理系统的标准
- 在国内生产环境中运用最广泛的部署模式
- Spark on yarn 的支持两种模式:
- yarn-cluster:适用于生产环境
- yarn-client:适用于交互、调试,希望立即看到app的输出
- Cluster Manager:ResourceManager
- Worker Node:NodeManager
- 仅支持粗粒度的资源分配方式
3、Spark On Mesos模式
- 官方推荐的模式。Spark开发之初就考虑到支持Mesos
- Spark运行在Mesos上会比运行在YARN上更加灵活,更加自然
- Cluster Manager:Mesos Master
- Worker Node:Mesos Slave
- 支持粗粒度、细粒度的资源分配方式
粗粒度模式(Coarse-grained Mode):每个应用程序的运行环境由一个Dirver和
若干个Executor组成,其中,每个Executor占用若干资源,内部可运行多个Task。
应用程序的各个任务正式运行之前,需要将运行环境中的资源全部申请好,且运行过
程中要一直占用这些资源,即使不用,最后程序运行结束后,回收这些资源。
细粒度模式(Fine-grained Mode):鉴于粗粒度模式会造成大量资源浪费,Spark
On Mesos还提供了另外一种调度模式:细粒度模式,这种模式类似于现在的云计
算,核心思想是按需分配。
三种集群部署模式如何选择:
- 生产环境中选择Yarn,国内使用最广的模式
- Spark的初学者:Standalone,简单
- 开发测试环境,可选择Standalone
- 数据量不太大、应用不是太复杂,建议可以从Standalone模式开始
- mesos不会涉及到
1.5 相关术语
http://spark.apache.org/docs/latest/cluster-overview.html

第3节 RDD编程
3.1 什么是RDD
RDD是 Spark 的基石,是实现 Spark 数据处理的核心抽象。
RDD 是一个抽象类,它代表一个不可变、可分区、里面的元素可并行计算的集合。
RDD(Resilient Distributed Dataset)是 Spark 中的核心概念,它是一个容错、
可以并行执行的分布式数据集。

RDD包含5个特征:
- 一个分区的列表
- 一个计算函数compute,对每个分区进行计算
- 对其他RDDs的依赖(宽依赖、窄依赖)列表
- 对key-value RDDs来说,存在一个分区器(Partitioner)【可选的】
- 对每个分区有一个优先位置的列表【可选的】
- 一组分片(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都
会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定
RDD的分片个数,如果没有指定,那么就会采用默认值; - 一个对分区数据进行计算的函数。Spark中RDD的计算是以分片为单位的,每个
RDD都会实现 compute 函数以达到该目的。compute函数会对迭代器进行组
合,不需要保存每次计算的结果; - RDD之间存在依赖关系。RDD的每次转换都会生成一个新的RDD,RDD之间形
成类似于流水线一样的前后依赖关系(lineage)。在部分分区数据丢失时,
Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分
区进行重新计算; - 对于 key-value 的RDD而言,可能存在分区器(Partitioner)。Spark 实现了两
种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围
的RangePartitioner。只有 key-value 的RDD,才可能有Partitioner,非key-
value的RDD的Parititioner的值是None。Partitioner函数决定了RDD本身的分
片数量,也决定了parent RDD Shuffle输出时的分片数量; - 一个列表,存储存储每个Partition的优先位置(preferred location)。对于一
个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照 “移
动计算不移动数据” 的理念,Spark在任务调度的时候,会尽可能地将计算任务
分配到其所要处理数据块的存储位置。
3.2 RDD的特点
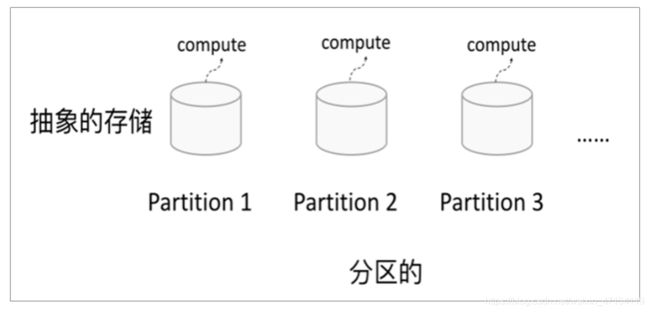
1、分区
RDD逻辑上是分区的,每个分区的数据是抽象存在的,计算的时候会通过一个
compute 函数得到每个分区的数据。如果RDD是通过已有的文件系统构建,则
compute函数是读取指定文件系统中的数据,如果RDD是通过其他RDD转换而来,
则compute函数是执行转换逻辑将其他RDD的数据进行转换。
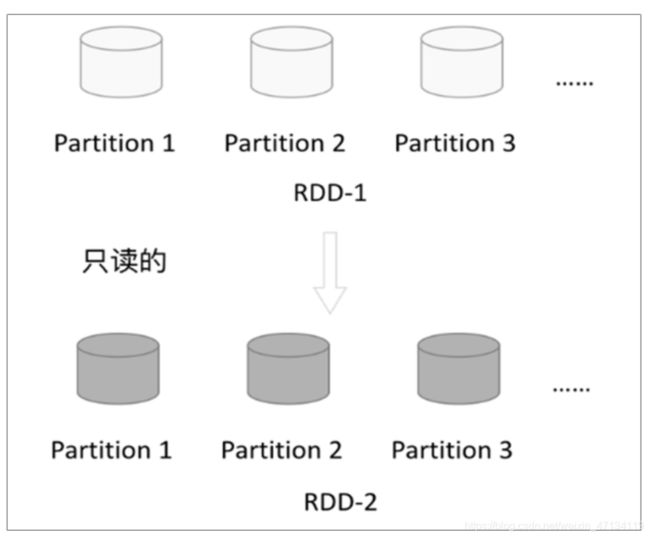
2、只读
RDD是只读的,要想改变RDD中的数据,只能在现有的RDD基础上创建新的RDD;
一个RDD转换为另一个RDD,通过丰富的操作算子(map、filter、union、join、
reduceByKey… …)实现,不再像MR那样只能写map和reduce了。
RDD的操作算子包括两类:
- transformation。用来对RDD进行转化,延迟执行(Lazy);
- action。用来触发RDD的计算;得到相关计算结果或者将RDD保存的文件系统
中;
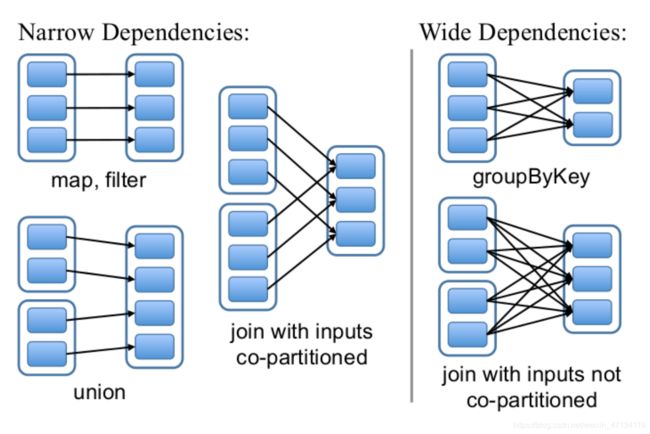
3、依赖
RDDs通过操作算子进行转换,转换得到的新RDD包含了从其他RDDs衍生所必需的
信息,RDDs之间维护着这种血缘关系(lineage),也称之为依赖。依赖包括两种:
- 窄依赖。RDDs之间分区是一一对应的(1:1 或 n:1)
- 宽依赖。子RDD每个分区与父RDD的每个分区都有关,是多对多的关系(即
n:m)。有shuffle发生
4、缓存
可以控制存储级别(内存、磁盘等)来进行缓存。
如果在应用程序中多次使用同一个RDD,可以将该RDD缓存起来,该RDD只有在第
一次计算的时候会根据血缘关系得到分区的数据,在后续其他地方用到该RDD的时
候,会直接从缓存处取而不用再根据血缘关系计算,这样就加速后期的重用。
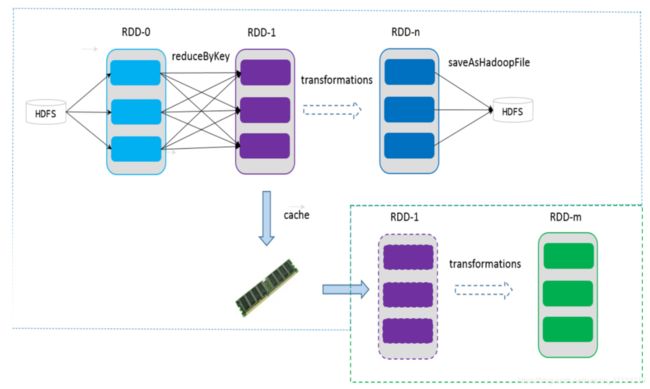
5、checkpoint
虽然RDD的血缘关系天然地可以实现容错,当RDD的某个分区数据失败或丢失,可
以通过血缘关系重建。
但是于长时间迭代型应用来说,随着迭代的进行,RDDs之间的血缘关系会越来越
长,一旦在后续迭代过程中出错,则需要通过非常长的血缘关系去重建,势必影响性
能。
RDD支持 checkpoint 将数据保存到持久化的存储中,这样就可以切断之前的血缘关
系,因为checkpoint后的RDD不需要知道它的父RDDs了,它可以从 checkpoint 处
拿到数据。
3.3 Spark编程模型

- RDD表示数据对象
- 通过对象上的方法调用来对RDD进行转换
- 最终显示结果 或 将结果输出到外部数据源
- RDD转换算子称为Transformation是Lazy的(延迟执行)
- 只有遇到Action算子,才会执行RDD的转换操作
要使用Spark,需要编写 Driver 程序,它被提交到集群运行
- Driver中定义了一个或多个 RDD ,并调用 RDD 上的各种算子
- Worker则执行RDD分区计算任务

3.4 RDD的创建
1、SparkContext
SparkContext是编写Spark程序用到的第一个类,是Spark的主要入口点,它负责和
整个集群的交互;

如把Spark集群当作服务端,那么Driver就是客户端,SparkContext 是客户端的核
心;
SparkContext是Spark的对外接口,负责向调用者提供 Spark 的各种功能;
SparkContext用于连接Spark集群、创建RDD、累加器、广播变量;
在 spark-shell 中 SparkContext 已经创建好了,可直接使用;
编写Spark Driver程序第一件事就是:创建SparkContext;

建议:Standalone模式或本地模式学习RDD的各种算子;
不需要HA;不需要IDEA
2、从集合创建RDD
从集合中创建RDD,主要用于测试。Spark 提供了以下函数:parallelize、
makeRDD、range

val rdd1 = sc.parallelize(Array(1,2,3,4,5))
val rdd2 = sc.parallelize(1 to 100)
// 检查 RDD 分区数
rdd2.getNumPartitions
rdd2.partitions.length
// 创建 RDD,并指定分区数
val rdd2 = sc.parallelize(1 to 100)
rdd2.getNumPartitions
val rdd3 = sc.makeRDD(List(1,2,3,4,5))
val rdd4 = sc.makeRDD(1 to 100)
rdd4.getNumPartitions
val rdd5 = sc.range(1, 100, 3)
rdd5.getNumPartitions
val rdd6 = sc.range(1, 100, 2 ,10)
rdd6.getNumPartitions

备注:rdd.collect 方法在生产环境中不要使用,会造成Driver OOM
3、从文件系统创建RDD
用 textFile() 方法来从文件系统中加载数据创建RDD。方法将文件的 URI 作为参数,
这个URI可以是:
- 本地文件系统
- 使用本地文件系统要注意:该文件是不是在所有的节点存在(在Standalone
模式下)
- 使用本地文件系统要注意:该文件是不是在所有的节点存在(在Standalone
- 分布式文件系统HDFS的地址
- Amazon S3的地址
// 从本地文件系统加载数据
val lines = sc.textFile("file:///root/data/wc.txt")
// 从分布式文件系统加载数据
val lines =sc.textFile("hdfs://linux121:9000/user/root/data/wc.txt")
val lines = sc.textFile("/user/root/data/wc.txt")
val lines = sc.textFile("data/wc.txt")

4、从RDD创建RDD
本质是将一个RDD转换为另一个RDD。详细信息参见 3.5 Transformation
3.5 Transformation【重要】
RDD的操作算子分为两类:
- Transformation。用来对RDD进行转化,这个操作时延迟执行的(或者说是Lazy 的);
- Action。用来触发RDD的计算;得到相关计算结果 或者 将结果保存的外部系统中;
- Transformation:返回一个新的RDD
- Action:返回结果int、double、集合(不会返回新的RDD)
- 要很准确区分Transformation、Action
每一次 Transformation 操作都会产生新的RDD,供给下一个“转换”使用;
转换得到的RDD是惰性求值的。也就是说,整个转换过程只是记录了转换的轨迹,
并不会发生真正的计算,只有遇到 Action 操作时,才会发生真正的计算,开始从血
缘关系(lineage)源头开始,进行物理的转换操作;

常见转换算子1
map(func):对数据集中的每个元素都使用func,然后返回一个新的RDD
filter(func):对数据集中的每个元素都使用func,然后返回一个包含使func为true
的元素构成的RDD
flatMap(func):与 map 类似,每个输入元素被映射为0或多个输出元素
mapPartitions(func):和map很像,但是map是将func作用在每个元素上,而
mapPartitions是func作用在整个分区上。假设一个RDD有N个元素,M个分区(N>> M),那么map的函数将被调用N次,而mapPartitions中的函数仅被调用M次,一次处理一个分区中的所有元素
mapPartitionsWithIndex(func):与 mapPartitions 类似,多了分区索引值信息全部都是窄依赖
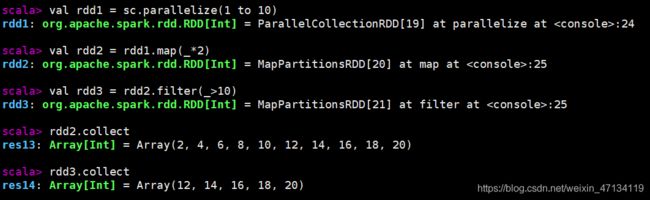
val rdd1 = sc.parallelize(1 to 10)
val rdd2 = rdd1.map(_*2)
val rdd3 = rdd2.filter(_>10)
// 以上都是 Transformation 操作,没有被执行。如何证明这些操作按预期执行,此时需要引入Action算子
rdd2.collect
rdd3.collect
// collect 是Action算子,触发Job的执行,将RDD的全部元素从 Executor 搜集到 Driver 端。生产环境中禁用
// flatMap 使用案例
val rdd4 = sc.textFile("/data/wc.txt")
rdd4.collect
rdd4.flatMap(_.split("\\s+")).collect

// RDD 是分区,rdd1有几个区,每个分区有哪些元素
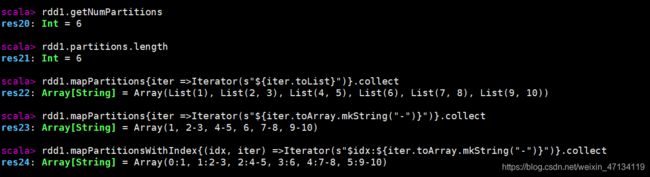
rdd1.getNumPartitions
rdd1.partitions.length
rdd1.mapPartitions{iter =>Iterator(s"${iter.toList}")}.collect
rdd1.mapPartitions{iter =>Iterator(s"${iter.toArray.mkString("-")}")}.collect
rdd1.mapPartitionsWithIndex{(idx, iter) =>Iterator(s"$idx:${iter.toArray.mkString("-")}")}.collect
// 每个元素 * 2
val rdd5 = rdd1.mapPartitions(iter => iter.map(_*2))
rdd5.collect

map 与 mapPartitions 的区别
- map:每次处理一条数据
- mapPartitions:每次处理一个分区的数据,分区的数据处理完成后,数据才能
释放,资源不足时容易导致OOM - 最佳实践:当内存资源充足时,建议使用mapPartitions,以提高处理效率
常见转换算子2
groupBy(func):按照传入函数的返回值进行分组。将key相同的值放入一个迭代器
glom():将每一个分区形成一个数组,形成新的RDD类型 RDD[Array[T]]
sample(withReplacement, fraction, seed):采样算子。以指定的随机种子
(seed)随机抽样出数量为fraction的数据,withReplacement表示是抽出的数据是否
放回,true为有放回的抽样,false为无放回的抽样
distinct([numTasks])):对RDD元素去重后,返回一个新的RDD。可传入
numTasks参数改变RDD分区数
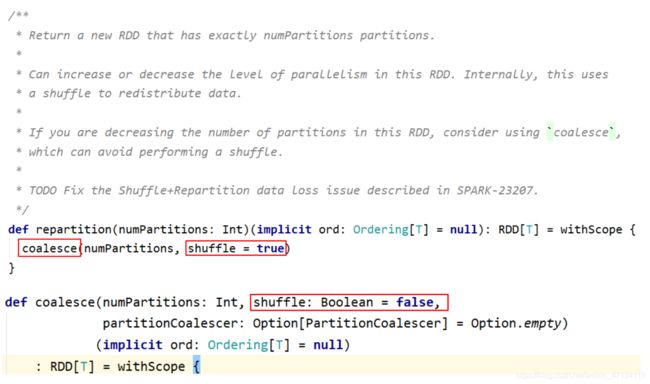
coalesce(numPartitions):缩减分区数,无shuffle
repartition(numPartitions):增加或减少分区数,有shuffle
sortBy(func, [ascending], [numTasks]):使用 func 对数据进行处理,对处理后
的结果进行排序
宽依赖的算子(有shuffle):groupBy、distinct、repartition、sortBy
// 将 RDD 中的元素按照3的余数分组
val rdd = sc.parallelize(1 to 10)
val group = rdd.groupBy(_%3)
group.collect
// 将 RDD 中的元素每10个元素分组
val rdd = sc.parallelize(1 to 101)
rdd.glom.map(_.sliding(10, 10).toArray).collect
![]()
// sliding是Scala中的方法
// 对数据采样。fraction采样的百分比,近似数
// 有放回的采样,使用固定的种子
rdd.sample(true, 0.2, 2).collect
// 无放回的采样,使用固定的种子
rdd.sample(false, 0.2, 2).collect
// 有放回的采样,不设置种子
rdd.sample(false, 0.2).collect

注:fraction(0.2)这个量越小越不准,会浮动
// 数据去重
val random = scala.util.Random
val arr = (1 to 20).map(x => random.nextInt(10))
val rdd = sc.makeRDD(arr)
rdd.distinct.collect
// RDD重分区
val rdd1 = sc.range(1, 10000, numSlices=10)
val rdd2 = rdd1.filter(_%2==0)
rdd2.getNumPartitions
// 减少分区数;都生效了
val rdd3 = rdd2.repartition(5)
rdd3.getNumPartitions
val rdd4 = rdd2.coalesce(5)
rdd4.getNumPartitions
// 增加分区数
val rdd5 = rdd2.repartition(20)
rdd5.getNumPartitions
// 增加分区数,这样使用没有效果
val rdd6 = rdd2.coalesce(20)
rdd6.getNumPartitions
// 增加分区数的正确用法
val rdd6 = rdd2.coalesce(20, true)
rdd6.getNumPartitions
// RDD元素排序
val random = scala.util.Random
val arr = (1 to 20).map(x => random.nextInt(10))
val rdd = sc.makeRDD(arr)
rdd.collect
// 数据全局有序,默认升序
rdd.sortBy(x=>x).collect
// 降序
rdd.sortBy(x=>x,false).collect

coalesce 与 repartition 的区别
小结:
- repartition:增大或减少分区数;有shuffle
- coalesce:一般用于减少分区数(此时无shuffle)
常见转换算子3
RDD之间的交、并、差算子,分别如下:
- intersection(otherRDD)
- union(otherRDD)
- subtract (otherRDD)
cartesian(otherRDD):笛卡尔积
zip(otherRDD):将两个RDD组合成 key-value 形式的RDD,默认两个RDD的
partition数量以及元素数量都相同,否则会抛出异常。
宽依赖的算子(shuffle):intersection、subtract
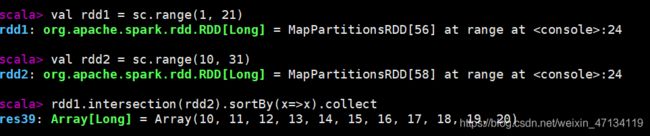
val rdd1 = sc.range(1, 21)
val rdd2 = sc.range(10, 31)
// 元素求交集
rdd1.intersection(rdd2).sortBy(x=>x).collect
// 元素求并集,不去重
rdd1.union(rdd2).sortBy(x=>x).collect
rdd1.subtract(rdd2).sortBy(x=>x).collect
![]()
// 检查分区数
rdd1.intersection(rdd2).getNumPartitions
rdd1.union(rdd2).getNumPartitions
rdd1.subtract(rdd2).getNumPartitions

// 笛卡尔积
val rdd1 = sc.range(1, 5)
val rdd2 = sc.range(6, 10)
rdd1.cartesian(rdd2).collect
// 检查分区数
rdd1.cartesian(rdd2).getNumPartitions

备注:
- union是窄依赖。得到的RDD分区数为:两个RDD分区数之和
- cartesian是窄依赖
- 得到RDD的元素个数为:两个RDD元素个数的乘积
- 得到RDD的分区数为:两个RDD分区数的乘积
- 使用该操作会导致数据膨胀,慎用
// 拉链操作
rdd1.zip(rdd2).collect
rdd1.zip(rdd2).getNumPartitions
// zip操作要求:两个RDD的partition数量以及元素数量都相同,否则会抛出异常
val rdd2 = sc.range(6, 20)
rdd1.zip(rdd2).collect

3.6 Action
Action 用来触发RDD的计算,得到相关计算结果;
Action触发Job。一个Spark程序(Driver程序)包含了多少 Action 算子,那么就
有多少Job;
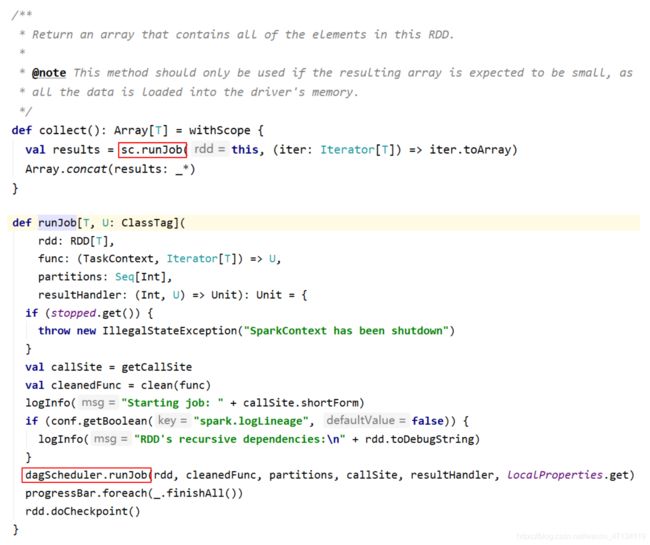
典型的Action算子: collect / count
collect() => sc.runJob() => … => dagScheduler.runJob() => 触发了Job
要求:能快速准确的区分:Transformation、Action
action:
collect() / collectAsMap()
stats / count / mean / stdev / max / min
reduce(func) / fold(func) / aggregate(func)

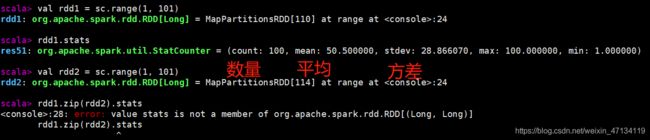
// 返回统计信息。仅能作用 RDD[Double] 类型上调用
val rdd1 = sc.range(1, 101)
rdd1.stats
val rdd2 = sc.range(1, 101)
// 不能调用
rdd1.zip(rdd2).stats
// count在各种类型的RDD上,均能调用
rdd1.zip(rdd2).count
// 聚合操作
val rdd = sc.makeRDD(1 to 10, 2)
rdd.reduce(_+_)
rdd.fold(0)(_+_)
rdd.fold(1)(_+_)
rdd.fold(1)((x, y) => {
println(s"x=$x, y=$y")
x+y
})
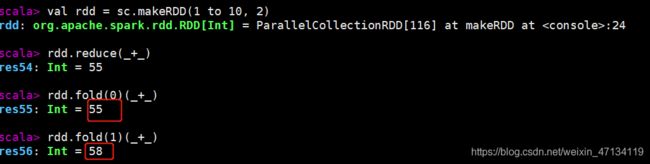
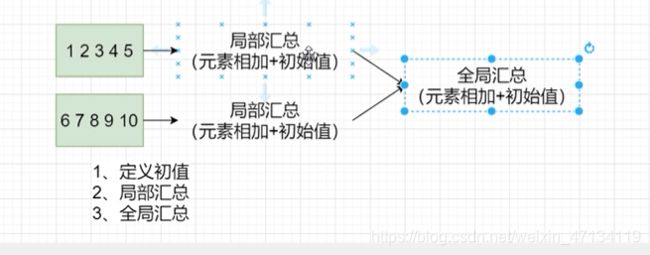
这里几个分区fold(1) 就会多分区数+1

rdd.aggregate(0)(_+_, _+_)
rdd.aggregate(1)(_+_, _+_)
rdd.aggregate(1)(
(a, b) => {
println(s"a=$a, b=$b")
a+b
},
(x, y) => {
println(s"x=$x, y=$y")
x+y
})


first():Return the first element in this RDD
take(n):Take the first num elements of the RDD
top(n):按照默认(降序)或者指定的排序规则,返回前num个元素。
takeSample(withReplacement, num, [seed]):返回采样的数据
foreach(func) / foreachPartition(func):与map、mapPartitions类似,区别是foreach 是 Action
saveAsTextFile(path) / saveAsSequenceFile(path) / saveAsObjectFile(path)
// first / take(n) / top(n) :获取RDD中的元素。多用于测试
rdd.first
rdd.take(10)
rdd.top(10)
// 采样并返回结果
rdd.takeSample(false, 5)
// 保存文件到指定路径(rdd有多少分区,就保存为多少文件,保存文件时注意小文件问题)
rdd.saveAsTextFile("data/t1")
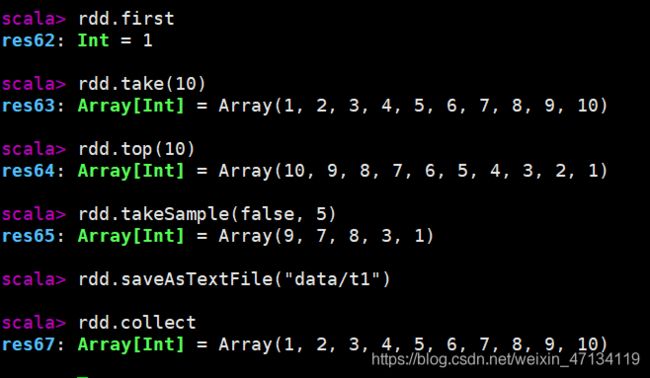
rdd.saveAsTextFile(“data/t1”) 将文件保存到了HDFS

3.7 Key-Value RDD操作
RDD整体上分为 Value 类型和 Key-Value 类型。
前面介绍的是 Value 类型的RDD的操作,实际使用更多的是 key-value 类型的RDD,也称为 PairRDD。
Value 类型RDD的操作基本集中在 RDD.scala 中;
key-value 类型的RDD操作集中在 PairRDDFunctions.scala 中;

前面介绍的大多数算子对 Pair RDD 都是有效的。Pair RDD还有属于自己的Transformation、Action 算子;
3.7.1 创建Pair RDD
val arr = (1 to 10).toArray
val arr1 = arr.map(x => (x, x*10, x*100))
// rdd1 不是 Pair RDD
val rdd1 = sc.makeRDD(arr1)
// rdd2 是 Pair RDD
val arr2 = arr.map(x => (x, (x*10, x*100)))
val rdd2 = sc.makeRDD(arr2)

3.7.2 Transformation操作
1、类似 map 操作
mapValues / flatMapValues / keys / values,这些操作都可以使用 map 操作实现,是简化操作。
val a = sc.parallelize(List((1,2),(3,4),(5,6)))
// 使用 mapValues 更简洁
val b = a.mapValues(x=>1 to x)
b.collect
// 可使用map实现同样的操作
val b = a.map(x => (x._1, 1 to x._2))
b.collect
val b = a.map{case (k, v) => (k, 1 to v)}
b.collect

// flatMapValues 将 value 的值压平
val c = a.flatMapValues(x=>1 to x)
c.collect
val c = a.mapValues(x=>1 to x).flatMap{case (k, v) => v.map(x=> (k, x))}
c.collect
c.keys
c.values
c.map{case (k, v) => k}.collect
c.map{case (k, _) => k}.collect
c.map{case (_, v) => v}.collect

2、聚合操作【重要、难点】
PariRDD(k, v)使用范围广,聚合
groupByKey / reduceByKey / foldByKey / aggregateByKey
combineByKey(OLD) / combineByKeyWithClassTag (NEW) => 底层实现
subtractByKey:类似于subtract,删掉 RDD 中键与 other RDD 中的键相同的元素
小案例:给定一组数据:(“spark”, 12), (“hadoop”, 26), (“hadoop”, 23), (“spark”,
15), (“scala”, 26), (“spark”, 25), (“spark”, 23), (“hadoop”, 16), (“scala”, 24), (“spark”,
16), 键值对的key表示图书名称,value表示某天图书销量。计算每个键对应的平均
值,也就是计算每种图书的每天平均销量。
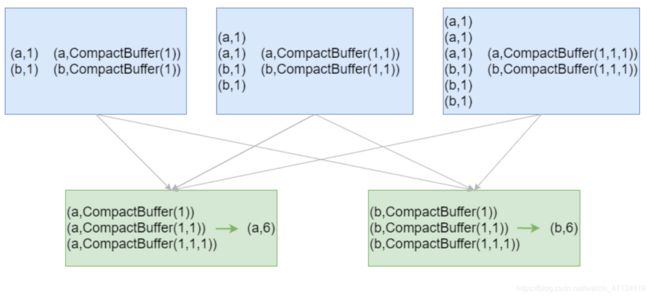
groupByKey
scala> val rdd = sc.makeRDD(Array(("spark", 12), ("hadoop", 26),("hadoop", 23), ("spark", 15), ("scala", 26), ("spark", 25),("spark", 23), ("hadoop", 16), ("scala", 24), ("spark", 16)))
rdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[0] at makeRDD at <console>:24
scala> rdd.groupByKey.collect
res0: Array[(String, Iterable[Int])] = Array((scala,CompactBuffer(26, 24)), (hadoop,CompactBuffer(26, 23, 16)), (spark,CompactBuffer(12, 25, 23, 15, 16)))
#按key进行groupby,转换为集合
scala> rdd.groupByKey.map(x => (x._1,x._2.toArray))
res1: org.apache.spark.rdd.RDD[(String, Array[Int])] = MapPartitionsRDD[3] at map at <console>:26
scala> rdd.groupByKey.map(x => (x._1,x._2.toArray)).collect
res2: Array[(String, Array[Int])] = Array((scala,Array(26, 24)), (hadoop,Array(26, 23, 16)), (spark,Array(12, 25, 23, 15, 16)))
#x._2.sum 按照value进行求和
scala> rdd.groupByKey.map(x => (x._1,x._2.sum)).collect
res3: Array[(String, Int)] = Array((scala,50), (hadoop,65), (spark,91))
scala> rdd.groupByKey.map(x => (x._1,x._2.sum / x._2.size)).collect
res4: Array[(String, Int)] = Array((scala,25), (hadoop,21), (spark,18))
#最终求每个key,value的平均值
#方式一
scala> rdd.groupByKey.map(x => (x._1,x._2.sum.toDouble / x._2.size)).collect
res5: Array[(String, Double)] = Array((scala,25.0), (hadoop,21.666666666666668), (spark,18.2))
#方式二
scala> rdd.groupByKey.map{case(k,v) =>(k,v.sum * 1.0 /v.size)}.collect
res6: Array[(String, Double)] = Array((scala,25.0), (hadoop,21.666666666666668), (spark,18.2))
#方式三
scala> rdd.groupByKey.mapValues(v => v.sum *1.0 /v.size).collect
res7: Array[(String, Double)] = Array((scala,25.0), (hadoop,21.666666666666668), (spark,18.2))
reduceByKey
scala> rdd.reduceByKey(_+_).collect
res8: Array[(String, Int)] = Array((scala,50), (hadoop,65), (spark,91))
#这里虽然求和了,但是丢掉了元素个数用如下方式记录求和和个数
scala> rdd.mapValues(x =>(x,1)).collect
res9: Array[(String, (Int, Int))] = Array((spark,(12,1)), (hadoop,(26,1)), (hadoop,(23,1)), (spark,(15,1)), (scala,(26,1)), (spark,(25,1)), (spark,(23,1)), (hadoop,(16,1)), (scala,(24,1)), (spark,(16,1)))
scala> rdd.mapValues(x =>(x,1)).reduceByKey(
| (x,y) => (x._1 + y._1 ,x._2 + y._2)
| ).collect
res10: Array[(String, (Int, Int))] = Array((scala,(50,2)), (hadoop,(65,3)), (spark,(91,5)))
scala> rdd.mapValues(x =>(x,1)).reduceByKey(
| (x,y) => (x._1 + y._1 ,x._2 + y._2)
| ).mapValues(v => v._1.toDouble / v._2).collect
res11: Array[(String, Double)] = Array((scala,25.0), (hadoop,21.666666666666668), (spark,18.2))
foldByKey
#foldByKey((0,0)) 赋予初始值,初始值是(0,0)就相当于reduceByKey,如果初始值不是0,就需要用foldByKey
scala> rdd.mapValues(x =>(x,1)).foldByKey((0,0))(
| (x,y) => (x._1 + y._1 ,x._2 + y._2)
| ).mapValues(v => v._1.toDouble / v._2).collect
res12: Array[(String, Double)] = Array((scala,25.0), (hadoop,21.666666666666668), (spark,18.2))
aggregateByKey
特点:aggregateByKey => 定义初值 + 分区内的聚合函数 + 分区间的聚合函数
scala> rdd.mapValues((_, 1)).aggregateByKey((0,0))(
| (x, y) => (x._1 + y._1, x._2 + y._2),
| (a, b) => (a._1 + b._1, a._2 + b._2)
| ).mapValues(x=>x._1.toDouble / x._2).collect
res13: Array[(String, Double)] = Array((scala,25.0), (hadoop,21.666666666666668), (spark,18.2))
// 初值(元祖)与RDD元素类型(Int)可以不一致
scala> rdd.aggregateByKey((0, 0))(
| (x, y) => {println(s"x=$x, y=$y"); (x._1 + y, x._2 + 1)},
| (a, b) => {println(s"a=$a, b=$b"); (a._1 + b._1, a._2 +b._2)}
| ).mapValues(x=>x._1.toDouble/x._2).collect
res14: Array[(String, Double)] = Array((scala,25.0), (hadoop,21.666666666666668), (spark,18.2))
// 分区内的合并与分区间的合并,可以采用不同的方式;这种方式是低效的!
scala> rdd.aggregateByKey(scala.collection.mutable.ArrayBuffer[Int]())(
| (x,y) => {x.append(y);x},
| (a,b) => {a ++ b}
| ).mapValues(v => v.sum.toDouble / v.size).collect
res17: Array[(String, Double)] = Array((scala,25.0), (hadoop,21.666666666666668), (spark,18.2))
// combineByKey(理解就行)
rdd.combineByKey(
(x: Int) => {println(s"x=$x"); (x,1)},
(x: (Int, Int), y: Int) => {println(s"x=$x, y=$y");(x._1+y,x._2+1)},
(a: (Int, Int), b: (Int, Int)) => {println(s"a=$a, b=$b");
(a._1+b._1, a._2+b._2)}
).mapValues(x=>x._1.toDouble/x._2).collect
res19: Array[(String, Double)] = Array((scala,25.0), (hadoop,21.666666666666668), (spark,18.2))
// subtractByKey
val rdd1 = sc.makeRDD(Array(("spark", 12), ("hadoop", 26),("hadoop", 23), ("spark", 15)))
val rdd2 = sc.makeRDD(Array(("spark", 100), ("hadoop", 300)))
scala> rdd1.subtractByKey(rdd2).collect()
res20: Array[(String, Int)] = Array()
// subtractByKey
val rdd = sc.makeRDD(Array(("a",1), ("b",2), ("c",3), ("a",5),("d",5)))
val other = sc.makeRDD(Array(("a",10), ("b",20), ("c",30)))
scala> rdd.subtractByKey(other).collect()
res21: Array[(String, Int)] = Array((d,5))
#subtractByKey只与key有关
结论:效率相等用最熟悉的方法;groupByKey在一般情况下效率低,尽量少用
初学:最重要的是实现;如果使用了groupByKey,寻找替换的算子实现;

groupByKey Shuffle过程中传输的数据量大,效率低
3、排序操作
sortByKey:sortByKey函数作用于PairRDD,对Key进行排序。在
org.apache.spark.rdd.OrderedRDDFunctions 中实现:

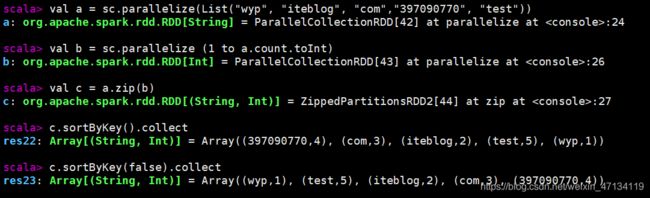
val a = sc.parallelize(List("wyp", "iteblog", "com","397090770", "test"))
val b = sc.parallelize (1 to a.count.toInt)
val c = a.zip(b)
c.sortByKey().collect
c.sortByKey(false).collect
4、join操作
cogroup / join / leftOuterJoin / rightOuterJoin / fullOuterJoin

val rdd1 = sc.makeRDD(Array((1,"Spark"), (2,"Hadoop"),(3,"Kylin"), (4,"Flink")))
val rdd2 = sc.makeRDD(Array((3,"李四"), (4,"王五"), (5,"赵六"),(6,"冯七")))
val rdd3 = rdd1.cogroup(rdd2)
rdd3.collect.foreach(println)
rdd3.filter{case (_, (v1, v2)) => v1.nonEmpty &v2.nonEmpty}.collect
// 仿照源码实现join操作
rdd3.flatMapValues( pair =>
for (v <- pair._1.iterator; w <- pair._2.iterator) yield
(v, w)
)
val rdd1 = sc.makeRDD(Array(("1","Spark"),("2","Hadoop"),("3","Scala"),("4","Java")))
val rdd2 = sc.makeRDD(Array(("3","20K"),("4","18K"),("5","25K"),("6","10K")))
rdd1.join(rdd2).collect
rdd1.leftOuterJoin(rdd2).collect
rdd1.rightOuterJoin(rdd2).collect
rdd1.fullOuterJoin(rdd2).collect


3.7.3 Action操作
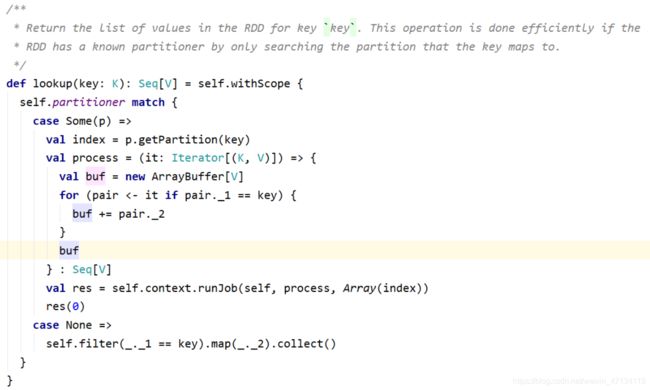
collectAsMap / countByKey / lookup(key)
countByKey源码:

lookup(key):高效的查找方法,只查找对应分区的数据(如果RDD有分区器的话)
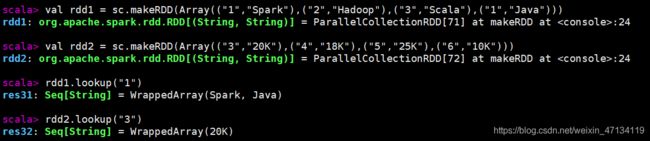
val rdd1 = sc.makeRDD(Array(("1","Spark"),("2","Hadoop"),("3","Scala"),("1","Java")))
val rdd2 = sc.makeRDD(Array(("3","20K"),("4","18K"),("5","25K"),("6","10K")))
rdd1.lookup("1")
rdd2.lookup("3")
3.8 输入与输出
3.8.1 文件输入与输出
1、文本文件
数据读取:textFile(String)。可指定单个文件,支持通配符。
这样对于大量的小文件读取效率并不高,应该使用 wholeTextFiles
def wholeTextFiles(path: String, minPartitions: Int = defaultMinPartitions):RDD[(String, String)])
返回值RDD[(String, String)],其中Key是文件的名称,Value是文件的内容
数据保存:saveAsTextFile(String)。指定的输出目录。
2、csv文件
读取 CSV(Comma-Separated Values)/TSV(Tab-Separated Values) 数据和读
取 JSON 数据相似,都需要先把文件当作普通文本文件来读取数据,然后通过将每一
行进行解析实现对CSV的读取。
CSV/TSV 数据的输出也是需要将结构化RDD通过相关的库转换成字符串RDD,然后
使用 Spark 的文本文件 API 写出去。
3、json文件
如果 JSON 文件中每一行就是一个JSON记录,那么可以通过将JSON文件当做文本文
件来读取,然后利用相关的JSON库对每一条数据进行JSON解析。
JSON数据的输出主要是通过在输出之前将由结构化数据组成的 RDD 转为字符串
RDD,然后使用 Spark 的文本文件 API 写出去。
json文件的处理使用SparkSQL最为简洁。
4、SequenceFile
SequenceFile文件是Hadoop用来存储二进制形式的key-value对而设计的一种平面
文件(Flat File)。 Spark 有专门用来读取 SequenceFile 的接口。在 SparkContext
中,可以调用:sequenceFile[keyClass, valueClass];
调用 saveAsSequenceFile(path) 保存PairRDD,系统将键和值能够自动转为
Writable类型。
5、对象文件
对象文件是将对象序列化后保存的文件,采用Java的序列化机制。
通过 objectFile[k,v](path) 接收一个路径,读取对象文件,返回对应的 RDD,
也可以通过调用saveAsObjectFile() 实现对对象文件的输出。因为是序列化所以要指
定类型。
3.8.2 JDBC
详见综合案例
3.9 算子综合应用案例
1、WordCount - scala
备注:打包上传服务器运行
package cn.lagou.sparkcore
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
//1.创建SparkContext
val conf = new SparkConf().setAppName("WordCount")
val sc = new SparkContext(conf)
//设置打印日志的级别
sc.setLogLevel("WARN")
//2.读取文件
//使用本地文件
//val lines: RDD[String] = sc.textFile("data/wc.txt")
//使用HDFS文件 --无配置文件
//val lines: RDD[String] =sc.textFile("hdfs://linux121:9000/wcinput/wc.txt")
//使用HDFS文件 --有配置文件
//val lines: RDD[String] = sc.textFile("/wcinput/wc.txt")
// 2、读本地文件(集群运行:输入参数)
val lines: RDD[String] = sc.textFile(args(0))
//3.RDD转换,\\s+ 包含了一个或多个空格
val words: RDD[String] = lines.flatMap(line => line.split("\\s+"))
val wordsMap: RDD[(String, Int)] = words.map(x => (x, 1))
val result: RDD[(String, Int)] = wordsMap.reduceByKey(_ + _)
//4.输出
result.foreach(println)
//5.关闭SparkContext
sc.stop()
//6.打包,使用spark-submit提交集群运行
// spark-submit --master local[*] --class cn.lagou.sparkcore.WordCount \
// original-LagouBigData-1.0-SNAPSHOT.jar /wcinput/*
// spark-submit --master yarn --class cn.lagou.sparkcore.WordCount \
// original-LagouBigData-1.0-SNAPSHOT.jar /wcinput/*
}
}
第6步

将original-LagouBigData-1.0-SNAPSHOT.jar上传到服务器,然后进入服务器,执行
[root@linux121 ~]# spark-submit --master local[*] --class cn.lagou.sparkcore.WordCount \
> original-LagouBigData-1.0-SNAPSHOT.jar /wcinput/*
2、WordCount - java
Spark提供了:Scala、Java、Python、R语言的API;
对 Scala 和 Java 语言的支持最好;

import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
public class JavaWordCount {
public static void main(String[] args) {
//1.创建SparkContext
SparkConf conf = new SparkConf().setAppName("JavaWordCount").setMaster("local[*]");
JavaSparkContext jsc=new JavaSparkContext(conf);
jsc.setLogLevel("warn");
//2.生成RDD
JavaRDD<String> lines = jsc.textFile("file:///D:\\workspace\\spark\\LagouBigData\\data\\wc.txt");
//3.RDD转换
JavaRDD<String> words = lines.flatMap(line -> Arrays.stream(line.split("\\s+")).iterator());
JavaPairRDD<String, Integer> wordsMap = words.mapToPair(word -> new Tuple2<>(word, 1));
JavaPairRDD<String, Integer> results = wordsMap.reduceByKey((x, y) -> x + y);
//4.结果输出
results.foreach(elem -> System.out.println(elem));
//5.关闭SparkContext
jsc.stop();
}
}
备注:
- Spark入口点:JavaSparkContext
- Value-RDD:JavaRDD;key-value RDD:JavaPairRDD
- JavaRDD 和 JavaPairRDD转换
- JavaRDD => JavaPairRDD:通过mapToPair函数
- JavaPairRDD => JavaRDD:通过map函数转换
- lambda表达式使用 ->
3、计算圆周率
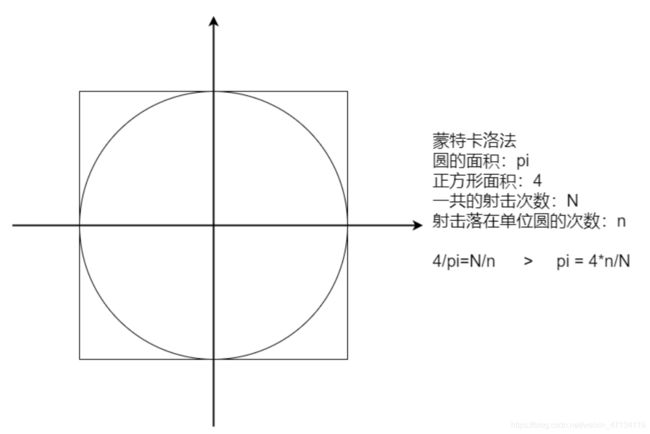
package cn.lagou.sparkcore
import org.apache.spark.{SparkConf, SparkContext}
import scala.math.random
object SparkPi {
def main(args: Array[String]): Unit = {
println(this.getClass.getCanonicalName.init)
//1.创建SparkContext
val conf = new SparkConf().setAppName(this.getClass.getCanonicalName.init).setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val slices = if(args.length>0) args(0).toInt else 10 //设置10个分区
val N=10000000
//2.生成RDD
val n: Double = sc.makeRDD(1 to N, slices).map(
idx => {
val (x, y) = (random, random)
if (x * x + y * y <= 1) 1 else 0
}
).sum()
//3.输出结果
val pi=4.0 * n /N
println(s"pi = $pi")
//5.关闭SparkContext
sc.stop()
}
}
4、广告数据统计
数据格式:
timestamp province city userid adid
时间点 省份 城市 用户 广告
1562085629599 Hebei Shijiazhuang 564 1
1562085629621 Hunan Changsha 14 6
1562085629636 Hebei Zhangjiakou 265 9
需求:
1、统计每一个省份点击TOP3的广告ID
2、统计每一个省份每一个小时的TOP3广告ID
package cn.lagou.sparkcore
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Adstat {
def main(args: Array[String]): Unit = {
//1.创建SparkContext
val conf = new SparkConf().setAppName(this.getClass.getCanonicalName.init).setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val N=3
//2.生成RDD;
val lines: RDD[String] = sc.textFile("file:///D:\\workspace\\spark\\LagouBigData\\data\\advert.log")
//3.RDD转换
//时间点 省份 城市 用户 广告
/**
* 需求1、统计每一个省份点击TOP3的广告ID
*/
//得到 省份、广告
val stat1RDD: RDD[(String, String)] = lines.map { line =>
val fields: Array[String] = line.split("\\s+")
(fields(1), fields(4))
}
//求出每个省,每个广告点击了多少次(按身份、广告汇总)
val reduce1RDD: RDD[((String, String), Int)] = stat1RDD.map { case (provice, adid) => ((provice, adid), 1) }
.reduceByKey(_ + _)
//对以上汇总信息求TOP3
reduce1RDD.map{case ((provice,adid),count)=>(provice,(adid,count))}
.groupByKey()
.mapValues(buf => buf.toList.sortWith(_._2 > _._2).take(N).map(_._1).mkString(":"))
.foreach(println)
println("***********************************************************************")
/**
* 需求2、统计每一个省份每一个小时的TOP3广告ID
*/
//得到 时间点、 省份、广告
val reduce2RDD: RDD[((String, Int), Iterable[(String, Int)])] = lines.map { line =>
val fields: Array[String] = line.split("\\s+")
((getHour(fields(0)), fields(1), fields(4)), 1)
}.reduceByKey(_ + _)
.map { case ((hour, provice, adid), count) => ((provice, hour), (adid, count)) }
.groupByKey()
/*结果如下
((Henan,0),CompactBuffer((9,2180), (5,2189), (2,2178), (3,2163), (8,2187), (0,2237), (1,2182), (6,2287), (4,2201), (7,2151)))
((Hubei,0),CompactBuffer((5,2204), (2,2237), (8,2289), (0,2144), (4,2195), (6,2241), (7,2150), (3,2192), (1,2215), (9,2168)))
((Hunan,0),CompactBuffer((5,2273), (1,2202), (3,2157), (0,2162), (6,2082), (2,2193), (4,2140), (8,2189), (9,2122), (7,2132)))
((Jiangsu,0),CompactBuffer((0,2147), (6,2192), (1,2166), (2,2131), (5,2184), (4,2150), (9,2145), (3,2199), (7,2250), (8,2151)))
((Hebei,0),CompactBuffer((2,2132), (7,2250), (8,2240), (6,2180), (1,2208), (0,2210), (4,2215), (5,2145), (3,2234), (9,2197)))
*/
//对以上汇总信息TOP3
reduce2RDD.mapValues(buf => buf.toList.sortWith(_._2 >_._2).take(N).map(_._1).mkString(":")).foreach(println)
//4.输出结果
//5.关闭SparkContext
sc.stop()
}
//定义时间戳转换小时函数
//1562085629599 =>Hour
def getHour(str:String):Int = {
import org.joda.time.DateTime
val dt = new DateTime(str.toLong)
dt.getHourOfDay()
}
}


时间戳转换为小时
导入pom包
<dependency>
<groupId>joda-timegroupId>
<artifactId>joda-timeartifactId>
<version>2.9.7version>
dependency>
import org.joda.time.DateTime
object test2 {
def main(args: Array[String]): Unit = {
//1562085629599 =>Hour
val str="1562085629599"
//在spark core程序中一定不要使用java8之前的时间类型(线程不安全)
//使用第三方的时间日期类型包,一定要确认其是线程安全的
val dt = new DateTime(str.toLong)
val hour: Int = dt.getHourOfDay()
println(hour)
}
}
在Java 8出现前的很长时间内成为Java中日期时间处理的事实标准,用来弥补JDK的不足。
Joda 类具有不可变性,它们的实例无法被修改。(不可变类的一个优点就是它们是线程安全的)
在 Spark Core 程序中使用时间日期类型时,不要使用 Java 8 以前的时间日期类型,线程不安全。
5、找共同好友
原始数据:
100, 200 300 400 500 600
200, 100 300 400
300, 100 200 400 500
400, 100 200 300
500, 100 300
600, 100
第一列表示用户,后面的表示该用户的好友
要求:
1、查找两两用户的共同好友
2、最后的结果按前两个id号有序排序

package cn.lagou.sparkcore
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object FindFriends {
def main(args: Array[String]): Unit = {
//1.创建SparkContext
val conf = new SparkConf().setAppName(this.getClass.getCanonicalName.init).setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val lines: RDD[String] = sc.textFile("file:///D:\\workspace\\spark\\LagouBigData\\data\\fields.dat")
val friendsRDD: RDD[(String, Array[String])] = lines.map { line =>
val fieds: Array[String] = line.split(",")
val userId: String = fieds(0).trim
val friends: Array[String] = fieds(1).trim.split("\\s+")
(userId, friends)
}
//方法一:核心思想利用笛卡儿积求两两好友,然后去除多余的数据
val tuples: RDD[((String, Array[String]), (String, Array[String]))] = friendsRDD.cartesian(friendsRDD)
.filter { case ((id1, friends1), (id2, friends2)) => id1 < id2 }
tuples.foreach(x =>println(x._1._1,x._1._2.toBuffer,x._2._1,x._2._2.toBuffer))
println("----------------------------------------------")
tuples.map{case ((id1,friends1),(id2,friends2))=>
((id1,id2),friends1.toSet & friends2.toSet)
}.sortByKey().foreach(println)
//方法二:消除笛卡尔积,更高效。
// 核心思想:将数据变形,找到两两的好友, 再执行数据的合并
println("*****************************************************************")
val value = friendsRDD.flatMapValues { friends =>
friends.combinations(2)
}
value.collect.foreach(x=> println(x._1,x._2.toBuffer))
/*
(100,ArrayBuffer(200, 300))
(100,ArrayBuffer(200, 400))
(100,ArrayBuffer(200, 500))
*/
value.map(x =>(x._2.mkString(" & "),x._1))
/*
(200 & 300,100)
(200 & 400,100)
(200 & 500,100)
*/
println("----------------------------------------------")
value.map(x =>(x._2.mkString(" & "),Set(x._1)))
/*
(100 & 200,Set(400))
(100 & 300,Set(400))
(200 & 300,Set(100))
*/
.reduceByKey(_ | _)
.sortByKey()
.collect().foreach(println)
// 备注:flatMapValues / combinations / 数据的变形 / reduceByKey / 集合的操作
val s1 = (1 to 5).toSet
val s2 = (3 to 8).toSet
// 交。intersect
println(s1 & s2)
// 并。union
println(s1 | s2)
// 差。diff
println(s1 &~ s2)
//5.关闭SparkContext
sc.stop()
}
}
6、Super WordCount
要求:将单词全部转换为小写,去除标点符号(难),去除停用词(难);最后按照count 值降序保存到文件,同时将全部结果保存到MySQL(难);标点符号和停用词可以自定义。
停用词:语言中包含很多功能词。与其他词相比,功能词没有什么实际含义。最普遍的功能词是[限定词](the、a、an、that、those),介词(on、in、to、from、over等)、代词、数量词等。
Array[(String, Int)] => scala jdbc => MySQL
package cn.lagou.sparkcore
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SuperWordCount1 {
private val stopWords = "in on to from by a an the is are were was i we you your he his some any of as can it each".split("\\s+")
private val punctuation = "[\\)\\.,:;'!\\?]"
def main(args: Array[String]): Unit = {
//定义
//1.创建SparkContext
val conf = new SparkConf().setAppName(this.getClass.getCanonicalName.init).setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
//RDD转换
//换为小写,去除标点符号,去除停用词
val lines: RDD[String] = sc.textFile("file:///D:\\workspace\\spark\\LagouBigData\\data\\swc.dat")
lines.flatMap(_.split("\\s+"))
.map(_.toLowerCase) //转为了小写
.map(_.replaceAll(punctuation, "")) //去标点符号
.filter(!stopWords.contains(_)) //去除停用词
.map((_,1)) //余下词语放入map的key中,value为1用来计数
.reduceByKey(_+_) //通过key来计数求和
.sortBy(_._2,false) //根据求和进行排序
.collect.foreach(println)
//5.关闭SparkContext
sc.stop()
}
}
Array[(String, Int)] => scala jdbc => MySQL
引入依赖
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.44version>
dependency>
package cn.lagou.sparkcore
import java.sql.{Connection, DriverManager, PreparedStatement}
object JDBCDemo {
def main(args: Array[String]): Unit = {
//1.定义结果集
val str = "hadoop spark java scala hbase hive sqoop hue tez atlas datax grinffin zk kafka"
val result: Array[(String, Int)] = str.split("\\s+").zipWithIndex
//2.定义参数
val username = "hive"
val password = "12345678"
val url = "jdbc:mysql://linux123:3306/ebiz? useUnicode=true&characterEncoding=utf-8&useSSL=false"
var conn: Connection = null
var stmt: PreparedStatement = null
val sql = "insert into wordcount values (?, ?)"
//3.jdbc保存数据
try{
conn=DriverManager.getConnection(url,username,password)
stmt=conn.prepareStatement(sql)
result.foreach{case (k,v)=>
stmt.setString(1,k)
stmt.setInt(2,v)
stmt.executeUpdate()
}
}catch {
case e:Exception =>e.printStackTrace()
}finally {
if(stmt !=null) stmt.close()
if(conn !=null) conn.close()
}
}
}
create table wordcount(word varchar(30), count int);
未优化的程序:使用 foreach 保存数据,要创建大量的链接
package cn.lagou.sparkcore
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SuperWordCount2 {
private val stopWords = "in on to from by a an the is are were was i we you your he his some any of as can it each".split("\\s+")
private val punctuation = "[\\)\\.,:;'!\\?]"
private val username = "hive"
private val password = "12345678"
private val url = "jdbc:mysql://linux123:3306/ebiz? useUnicode=true&characterEncoding=utf-8&useSSL=false"
def main(args: Array[String]): Unit = {
//定义
//1.创建SparkContext
val conf = new SparkConf().setAppName(this.getClass.getCanonicalName.init).setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
//RDD转换
//换为小写,去除标点符号,去除停用词
val lines: RDD[String] = sc.textFile("file:///D:\\workspace\\spark\\LagouBigData\\data\\swc.dat")
val resultRDD: RDD[(String, Int)] = lines.flatMap(_.split("\\s+"))
.map(_.toLowerCase) //转为了小写
.map(_.replaceAll(punctuation, "")) //去标点符号
.filter(!stopWords.contains(_)) //去除停用词
.map((_, 1)) //余下词语放入map的key中,value为1用来计数
.reduceByKey(_ + _) //通过key来计数求和
.sortBy(_._2, false) //根据求和进行排序
//结果输出
resultRDD.saveAsTextFile(path = "file:///D:\\workspace\\spark\\LagouBigData\\data\\superwc")
//输出到mysql
resultRDD.foreach{case (k,v)=>
var conn: Connection = null
var stmt: PreparedStatement = null
val sql = "insert into wordcount values (?, ?)"
//3.jdbc保存数据
try {
conn = DriverManager.getConnection(url, username, password)
stmt = conn.prepareStatement(sql)
stmt.setString(1, k)
stmt.setInt(2, v)
stmt.executeUpdate()
} catch {
case e: Exception => e.printStackTrace()
} finally {
if (stmt != null) stmt.close()
if (conn != null) conn.close()
}
}
//5.关闭SparkContext
sc.stop()
}
}
优化后的程序:使用 foreachPartition 保存数据,一个分区创建一个链接;cacheRDD
package cn.lagou.sparkcore
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SuperWordCount3 {
private val stopWords = "in on to from by a an the is are were was i we you your he his some any of as can it each".split("\\s+")
private val punctuation = "[\\)\\.,:;'!\\?]"
private val username = "hive"
private val password = "12345678"
private val url = "jdbc:mysql://linux123:3306/ebiz? useUnicode=true&characterEncoding=utf-8&useSSL=false"
def main(args: Array[String]): Unit = {
//定义
//1.创建SparkContext
val conf = new SparkConf().setAppName(this.getClass.getCanonicalName.init).setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
//RDD转换
//换为小写,去除标点符号,去除停用词
val lines: RDD[String] = sc.textFile("file:///D:\\workspace\\spark\\LagouBigData\\data\\swc.dat")
val resultRDD: RDD[(String, Int)] = lines.flatMap(_.split("\\s+"))
.map(_.toLowerCase) //转为了小写
.map(_.replaceAll(punctuation, "")) //去标点符号
.filter(!stopWords.contains(_)) //去除停用词
.map((_, 1)) //余下词语放入map的key中,value为1用来计数
.reduceByKey(_ + _) //通过key来计数求和
.sortBy(_._2, false) //根据求和进行排序
//结果输出
resultRDD.saveAsTextFile(path = "file:///D:\\workspace\\spark\\LagouBigData\\data\\superwc")
//输出到mysql
//使用foreachPartition,对每条记录创建连接
resultRDD.foreachPartition { iter =>
saveAsMysql(iter)
}
//5.关闭SparkContext
sc.stop()
}
//保存到MySQL方法
def saveAsMysql(iter:Iterator[(String,Int)]):Unit={
var conn: Connection = null
var stmt: PreparedStatement = null
val sql = "insert into wordcount values (?, ?)"
try {
conn = DriverManager.getConnection(url, username, password)
stmt = conn.prepareStatement(sql)
iter.foreach { case (k, v) =>
stmt.setString(1, k)
stmt.setInt(2, v)
stmt.executeUpdate()
}
} catch {
case e: Exception => e.printStackTrace()
} finally {
if (stmt != null) stmt.close()
if (conn != null) conn.close()
}
}
}
备注:
- SparkSQL有方便的读写MySQL的方法,给参数直接调用即可;
- 但以上掌握以上方法非常有必要,因为SparkSQL不是支持所有的类型的数据库