基于Amazon Connect、Lex、Kendra和 LangChain 构建企业专属智能客服机器人

01
概述
客户联络中心在现代是构成一个完整企业的重要组成部分,作为企业与顾客的连接纽带,在销售、服务支持以及提升顾客满意度方面发挥着至关重要的作用。使用 Amazon Connect 出海企业可以快速搭建自己的全球客服联络中心。当前客服联络中心也面临诸多的挑战,如长时间的电话等待、沟通困难、有用信息的缺乏、对客户的回复缺乏标准难以统一,这些对客户都可能会带来不好的体验。当连接建立后,客户又需要重复地讲述求助的原因、个人的身份、订单信息等。通过对话机器人接收客户问题、回答客户问题,可以让客户不需要排队等待。对于已识别的客户,对话机器人有更多的相关信息,可以避免无效的问答,专注于更相关的信息。
Amazon Lex 是基于 AI 聊天机器人的框架,可以根据业务场景设置各种各样的意图(Intent)来预训练机器人的基础模型,然后借助自然语言理解(NLU)实现与客户的对话。交付一个更快速更顺畅的客户体验的同时也节省了人力成本。
但随着业务场景的增加,需要负责维护机器人的人员尽可能罗列出所有分支场景,并设计相应的意图,同时还要保证最新的数据能够及时更新到基础模型中,这会带来巨大的维护成本与挑战。为了解决上述问题,我们需要引入检索增强生成(Retrieval Augmented Generation,RAG)技术,并结合生成式人工智能(GenAI)和大型语言模型(LLMs),将机器人的响应限制在公司的数据范围内,为用户提供更加专业精准的应答,并且无需花费大量的人力整理知识库、预训练机器人的基础模型。通过接入知识库丰富客户对话内容,提升对话体验。
本文将演示如何结合 Amazon Connect、Amazon Lex、Amazon Kendra、Amazon Lambda 和 Amazon SageMaker,以及 LangChain 对大模型的调用,打造企业专属的智能客服。
02
架构概述

使用 Amazon Connect 的核心组件 — 联系流(Contact Flow),创建符合自身业务场景的 IVR(Interactive Voice Response),并将获取用户输入的模块设置为 Amazon Lex,实现用户对话的语义理解。
Amazon Connect 将用户的呼入语音或文字输入传入 Amazon Lex,通过在 Lex 中设置 Lambda 函数,将每一次用户的对话内容发送给 Lambda 函数做相应处理,最后将结果返回到 Lex,实现人机对话。这里有个技巧是:我们无需人工为机器人创建大量的意图用于预训练,由于没有预训练模型去匹配用户的问题,Lex 会自动匹配系统默认的 FallbackIntent 并发送给 Lambda。我们将核心问题语义理解部分从 Lex 转移到了大语言模型, 再由 Lambda 将大语言模型回复的内容嵌入 FallbackIntent 中,完成一次对话闭环,这样就大大节省了设计和维护预训练数据的人力成本。
Lambda 获取用户问题后,将用户问题作为关键字,调用 Amazon Kendra 的知识库索引,利用 Kendra 自身的向量比对与自然语言理解特性,查询出匹配度高的结果集并返回给 Lambda。Kendra 支持多种文件格式和第三方平台作为数据源,本文选择网页爬虫作为数据源连接器,利用此连接器的定期爬取功能,实现知识库的自动更新。Kendra 在抓去数据和建立索引时,会根据自身在14个主要行业(计算机、工业、汽车、电信、人力资源、法律、健康、能源、旅游、医疗、传媒、保险、制药和新闻)领域中的知识,对数据做文本切割和 Embedding,并借助自身的自然语言理解(NLU)特性,进一步提升查询匹配的精准度。
Lambda 函数拿到 Kendra 返回的数据后,会作为上下文通过 Langchain 生成相应的提示词(Prompt)并发送给大语言模型。提示词大致的格式为:“请在以下内容中回答<用户提问>”。由于 Kendra 对数据源提前做了 Embedding,内容更加精准,所以我们仅需截取排序前三的内容作为上下文拼接在提示词中,从而避免了大语言模型中 Token 数量限制问题,同时更加精简的提示词也能提升大模型的响应速率。
在 SageMaker 中部署大语言模型作为推理的终端节点。本文使用了清华大学开源的模型——ChatGLM-6B,对中文支持的表现较好,基于 General Language Model (GLM) 架构,具有62亿参数。
Lambda 函数将大模型返回的信息通过 Lex 传递给 Connect,Connect 通过 Amazon Polly 进行语音回复,也可以通过 Connect 文字聊天 API 进行文字回复。
如果系统多次无法解答用户问题,或者用户明确说出转人工的指令,系统会将用户转到 Connect 的人工座席进行详细沟通。
下来将详细讲解如何实现上述方案。
03
部署方案
前提条件
确保拥有 Amazon 账号并能访问控制台。
确保登录到 Amazon 的用户拥有操作 Amazon Connect、Kendra、Lambda、SageMaker、Lex 的权限。
本文所使用的源代码 Github 地址:
https://github.com/JustinTanCQ/aws-connect-lex-kendra-langchain-chatglm-demo
本文的操作将以 Amazon us-west-2 区域为例。
在 Amazon Kendra 创建知识库
Step 1 创建索引
进入 Amazon Kendra 控制台:https://us-west-2.console.aws.amazon.com/kendra/home?region=us-west-2
点击右上方的“Create an Index” 创建索引。
输入索引名称,在 IAM role 部分,选择“Create a new role”,在 Role name 中输入角色名称,然后点击“Next”按钮(请注意:系统会自动为名称生成相应的前缀,此前缀不能更改或删除,否则会造成异常)。
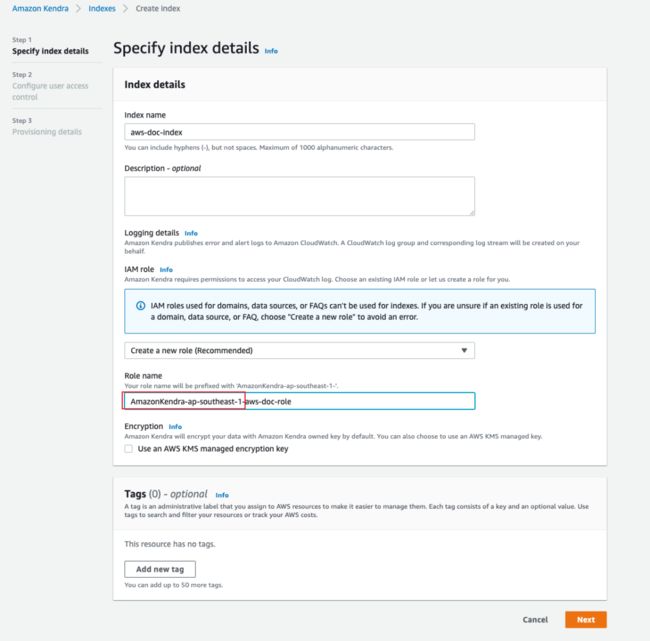
后续两页保持默认选项,最后点“Create”按钮创建索引。整个创建过程大概需要5-10分钟。
Step 2 创建数据源
在索引详情页中,点击“Add data sources”创建数据源。

Kendra 支持多种数据源,这里我们选择网页爬虫作为数据源,可以从指定的 URL 中定时爬取和更新相关内容,适用于知识库更新比较频繁的场景。

输入数据源名称,Language 部分可根据自身知识库的语言选择。因为本文使用中文知识库,所以选择“Chinese(zh)”,然后点击“Next”。
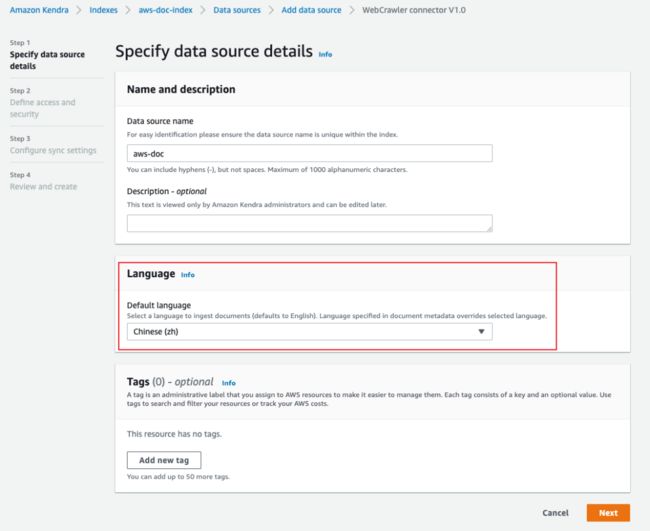
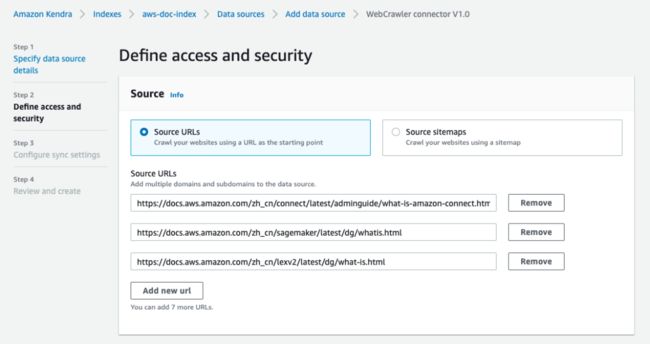
输入目标网页的 URL,最多可以输入10个。如果需要访问内部网页,则在“Web proxy”部分设置网页的域名、端口号和访问凭证。

IAM role 选择”Create a new role”,并输入角色名称(请注意:系统会自动为名称生成相应的前缀,此前缀不能更改或删除,否则会造成异常)。
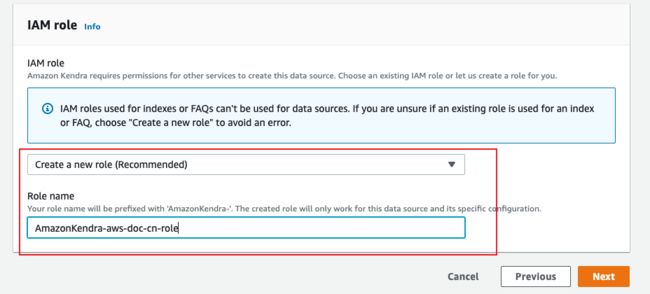
配置爬虫爬取的范围与深度。
设置定期同步网页数据的周期,也可以设置手动同步(Run on demand)。然后点“Next”,最后一页确认信息后点“Create”按钮创建数据源。

数据源创建完成后,点右上角的“Sync now”开始爬取或同步指定网页的数据。此过程根据爬取的范围和深度,可能需要几分钟到几个小时。此过程首先会对文档进行爬取以确定要索引的文档,然后再对选定的文档建立索引。
等待数据源同步成功后,可以点击右边栏“Search indexed content”测试索引情况。
因为我们爬取的中文文档,所以需要点击右边扳手图标,将语言设置为“Chinese (zh)”并点”Save“,最后在顶部搜索输入框中直接输入问题查看返回结果。

创建 ChatGLM SageMaker Endpoint
进入 Amazon SageMaker 控制台:
https://us-west-2.console.aws.amazon.com/sagemaker/home?region=us-west-2
在左边菜单点击 Notebook -> Notebook instances,如果当前没有实例可以复用,点击 Create notebook instance 按钮创建新的 notebook instance。
输入 Notebook instance name,instance type 选择 m5.xlarge,Platform identifier 保持不变,IAM Role 选择 Create a new role,其它保持默认设置,最后点击 Create notebook instance 按钮完成创建。
当实例状态变为 InService 后,点击 Open JupyterLab,打开 Jupyter 工作台
点击上传图标,将 Github 上 /llm/chatglm/chatglm_sagemaker_byos.ipynb 上传到工作台。
点击新建文件夹图片,新建名为 code 的文件夹,将 Github 上 /LLM/chatglm/code 目录下的两个文件也上传到工作台。

双击 ipynb 打开笔记本,按照介绍顺序执行笔记本中的代码。其中第二步是将 ChatGLM 部署到 SageMaker 的推理节点,耗时大概5分钟左右,成功后可以运用笔记本中后面的步骤做相应的测试。请注意,如果执行第二步时出现 ResourceLimitExceeded 错误,说明在该区域还没有相应资源的配额,请到 Service Quotas 中输入 endpoint 查看该区域哪些实例类型支持 endpoint。如果 Applied quota value 为 0,需要选中实例类型后,点 Request quata increase 按钮申请。数量建议填1,否则可能会有申请失败。

在左边菜单中点击 Inference -> Endpoints 可以看到新创建 Endpoint,状态为 InService 说明正常运行。将 Name 复制下来,供后续配置 Lambda 环境变量使用。
创建 Lambda 函数
进入 Amazon Lambda 控制台:
https://us-west-2.console.aws.amazon.com/lambda/home?region=us-west-2#/functions
首先为 Lambda 添加 langchain 的 Lambda Layer。点击左边菜单栏的“Layer”,并点击右上角“Create layer”按钮。
名称填写 langchain,文件选择 Github 上 /Lambda/lambda-layer/lazip。
点击右上角“Create function”按钮创建 Lambda 函数。
输入函数名称,Runtime 选择“Python 3.9”,Architecture 选择“x86_64”,Execution Role 选择“Create a new role with Lambda permissions”,然后点“Create function”按钮。稍后我们再为这个角色添加操作 Lex 与 SageMaker Endpoint 的权限。
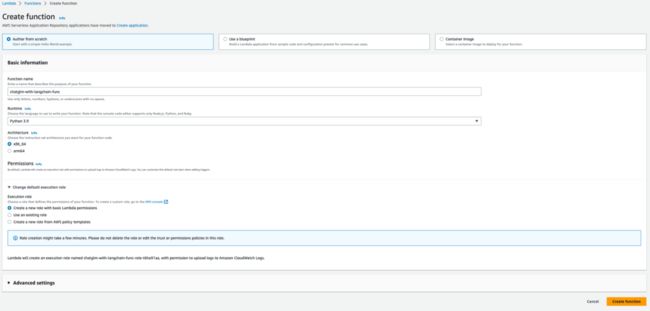
创建成功后,点击“Upload from”按钮,下拉菜单中选“.zip file”,然后选择 Github 上,/Lambda/script.zip,点击“Save”。
点击 Code 这一栏,在 Runtime settings 部分点击 Edit 按钮,将 Handler 这里改为 script.lambda_function.lambda_handler,这是因为我们上传了名为 script.zip 文件,需要修改入口程序的目录结构。
点击 Code 这一栏,在底部 Layers 部分点击“Add a layer”按钮添加 LangChain Lambda Layer。

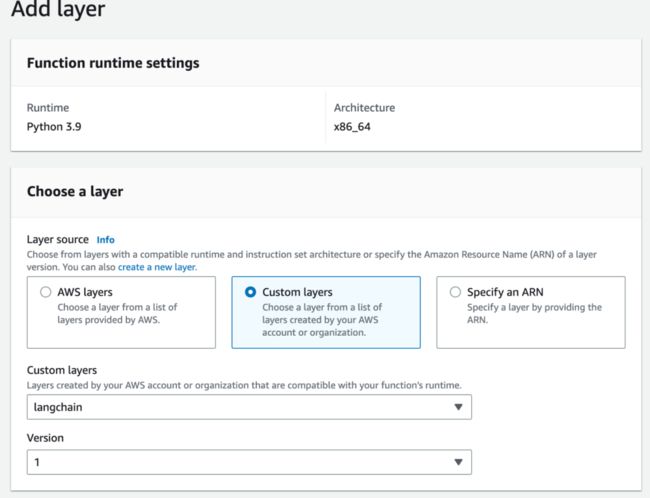
点击 Configuration 栏,然后点击右边的“Edit”按钮,修改函数运行的基本参数。

设置函数运行内存为 4096MB,Timeout 设置为 1 分钟,其它设置保持默认,点击“Save”按钮保存设置。
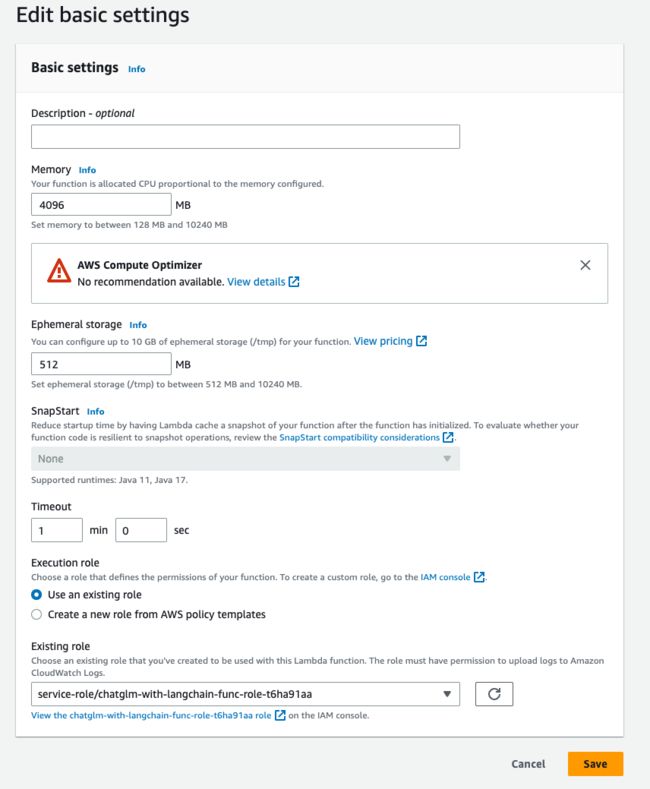
继续点击右边“Environment variables”,点击 Edit 按钮设置两个环境变量,Kendra 索引 ID 与 ChatGLM SageMaker endpoint 名称:
Key = KENDRA_INDEX_ID,Value = 在 Kendra 中的 Index ID
Key = CHATGLM_ENDPOINT,Value = 部署 ChatGLM 模型的 SageMaker endpoint 名称

转到 IAM 控制台,点击右边的“Roles”,在列表中点选这个 Lambda 函数所关联的 Role,点开 Policy name 下面的加号,然后点击“Edit”按钮。
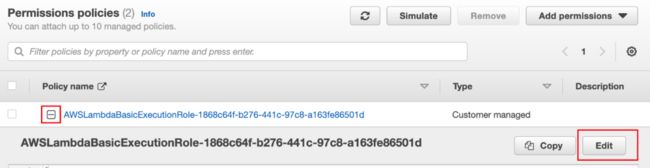
将如下 JSON 代码贴在现有代码后面,为 Lambda 函数赋予操作 Kendra 与 SageMaker 的权限。请注意 JSON 格式。
{
"Effect": "Allow",
"Action": [
"sagemaker:InvokeEndpoint",
"kendra:Query"
],
"Resource": "*"
}左滑查看更多
使用 Amazon Lex 创建智能对话机器人
进入 Amazon Lex 控制台:
https://us-west-2.console.aws.amazon.com/lexv2/home?region=us-west-2#bots
点击右上角“Action”按钮,在下拉菜单中选择“Import”。
输入机器人名称,并选择 Github 上 /lex/chatgpt-bot-DRAFT-OEZEFSCJIQ-LexJson.zip 文件,IAM Permission 选择“Create a role with basic Amazon Lex permissions”,COPPA 部分选择“No”,最后点击“Import”按钮导入机器人。
点击导入成功后的机器人名称,在左边菜单中 Aliases ->TestBotAliases,并在 Languages 下点击 Mandarin(PRC),在 Lambda Function 选择上面创建的 Lambda 函数,点 Save 按钮保存设置。

点击左边菜单栏 Mandarin (PRC),再点击右上角 Build 按钮构建机器人。

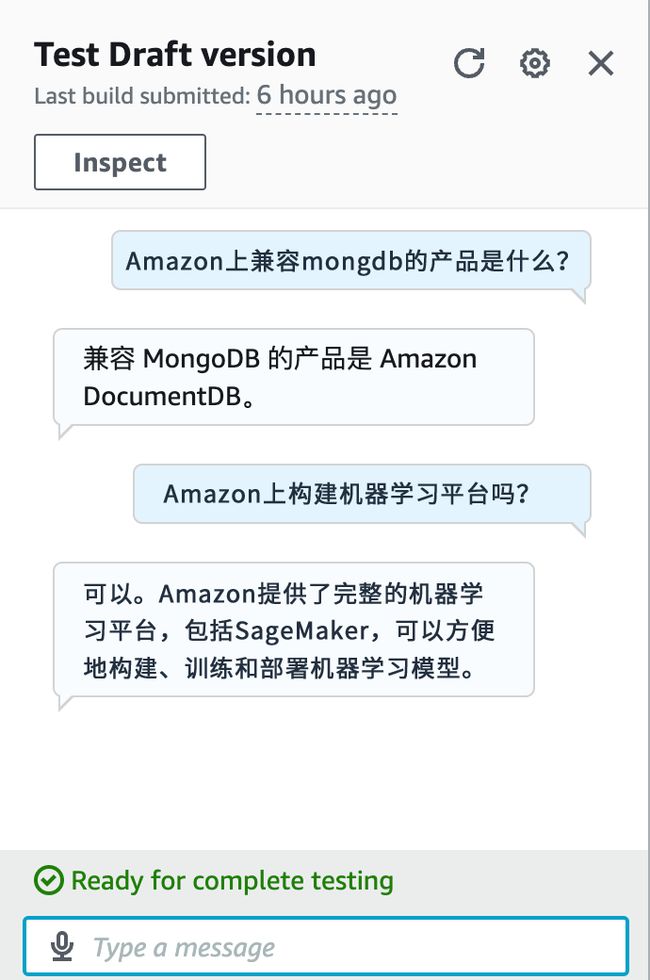
构建成功后,点击 Test 按钮可以测试前面所有步骤是否配置成功。如报错或返回“Intent FallbackIntent is fulfilled”,说明执行 Lambda 时发生异常,可以到 CloudWatch Log Group 中查看 Lambda 日志,定位错误原因。测试成功的结果如下图所示:
最后使用 Amazon Connect 构建客户联络中心
进入 Amazon Connect 控制台:
https://us-west-2.console.aws.amazon.com/connect/v2/app/instances?region=us-west-2
点击 Create instance 按钮创建 Connect 实例。Identity management 保持默认,输入英文字母组成的别名后,点 Next。
为 Connect 管理控制台创建超级管理员,输入相关信息后点 Next,后两页保持默认选项,最后点 Create instance 按钮完成创建。
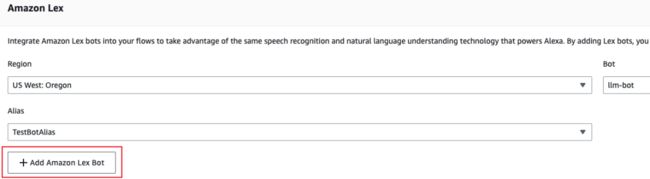
Connect 实例创建成功后,点击左边菜单中的 Flows,在 Amazon Lex 部分,选择同区域的 Bot,然后点击 Add Amazon Lex Bot 按钮添加 Bot。
点击左边菜单栏的 Instances,点击 Access URL 中的链接,使用 Connect 超级管理员的账号密码登录。
成功登录到 Connect 控制台后,点击“查看流”,然后点击“创建联系流”按钮。
点击右上角三角形按钮,在下拉菜单中选择“导入”,选择 Github 中 /Connect/LLM-Lex-InboundFlow 文件导入联系流。
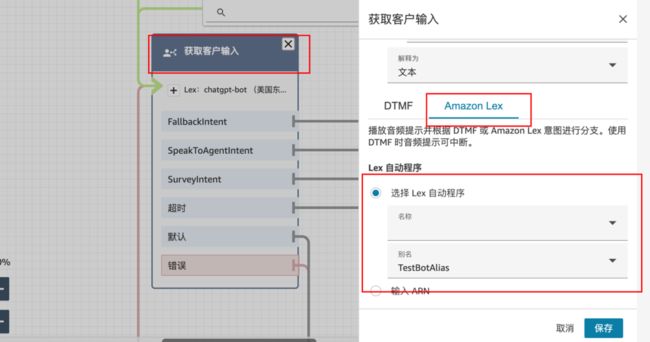
双击“获取用户输入”模块,确认 Amazon Lex 选择为前面步骤创建的 Bot,最后点击“发布”按钮发布此联系流。
回到控制面板,点击“开始”按钮创建一个电话号码。

根据实际业务需要,选择不同国家的电话号码,如果国家不在列表中,需要开工单申请。本文以美国的免费电话为例。
创建成功后,点击“查看电话号码”,然后点击该电话号码,在“联系流/IVR”中选择先前创建的联系流。
回到控制面板,点击“测试聊天”,然后点击“测试设置”,选中刚刚创建的联系流,点击应用按钮。
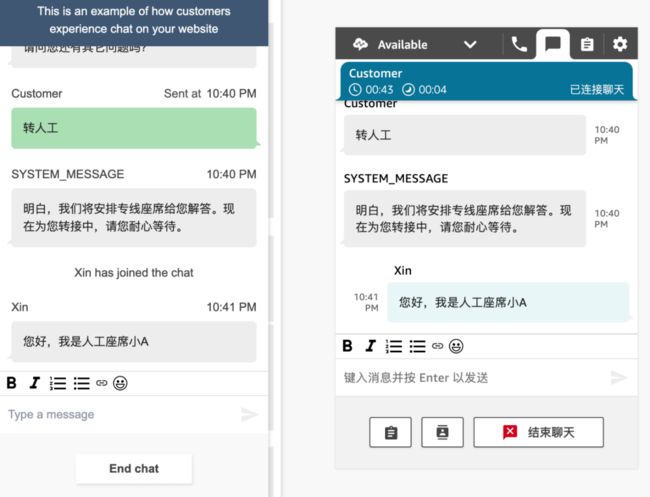
如下图所示:左边部分是模拟用户聊天界面,右边是座席服务台。当前用户的会话会自动由 Amazon Lex 机器人接替,只有当客户输入“转人工”字样才会将会话转到人工座席。

测试结果
此界面模拟用户向座席发起文字聊天,由于我们在联系流中设置了 Lex 机器人,所以客户的问题将由 Lex 机器人结合内部知识库与大语言模型来回答。

当用户输入“转人工”字样,系统会将用户的对话转入到人工座席。

人工座席接受聊天请求后,就可以通过文字聊天与用户。
04
总结
通过 Amazon Connect 和 Amazon LEX 实现客服联络中心的自动客服机器人,借助 Amazon Lambda 调用 Amazon Kendra+ChatGLM 扩展了自动客服机器人的对话能力,使对话机器人在没有预设的对话流的情况下,查询知识库回答客户的问题,提升顾客体验的同时减少了在顾客服务上的人力资源投入。在此框架下,可以继续不断完善自动机器人及大语言模型在回答问题方面的准确度。
本篇作者

谭欣
亚马逊云科技解决方案架构师,负责帮助客户设计和优化符合自身业务场景的云架构,并提供技术支持。在直播音视频架构设计方面有着丰富的实战经验。

姜可
亚马逊云科技资深解决方案架构师,负责协助客户业务系统上云的解决方案架构设计和咨询,现致力于 DevOps、IoT、汽车相关领域的研究。在加入亚马逊云科技之前,从事金融、制造、政府等行业解决方案相关的研发。
2023亚马逊云科技中国峰会即将开启!
点击下方图片即刻注册



听说,点完下面4个按钮
就不会碰到bug了!
