利用PostMan和Kibanan操作ElasticSearch和个人理解
目录
PostMan操作
常用命令
创建索引
查看索引index
删除索引index
关闭索引index
打开索引index
创建索引index并且进行映射mapping
Kibanan操作
创建索引
查询索引
删除索引
查询映射
添加映射
创建索引并添加映射
索引库中添加字段
操作文档document【kibana演示】
添加文档,指定id
查询文档
添加文档,不指定id
查询文档
查询文档
查询所有文档
删除文档
修改文档 根据id,id存在就是修改,id不存在就是添加
查询全部
全文查询-match查询
查询文档-term查询
关键字搜索数据
DSL 查询
① 根据年龄查询
② 查询年龄大于20岁的女性用户相应结果:
③ 全文搜索
高亮显示
聚合
指定响应字段
判断文档是否存在
批量操作
批量查询
批量插入数据:
批量删除:
分页
terms查询
range查询
exists 查询
整理尚硅谷ES笔记
PostMan操作
常用命令

创建索引
PUT http://localhost:9200/index
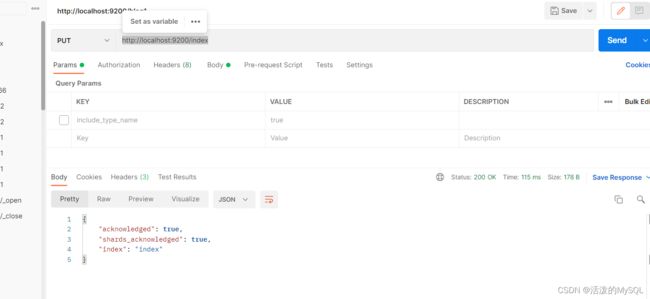
elasticsearch-head查看:请求localhost:9200
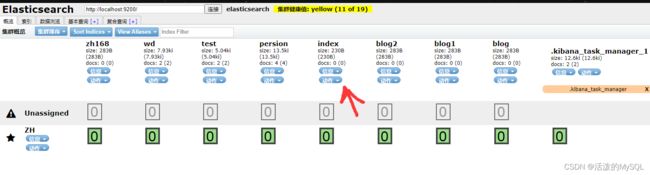
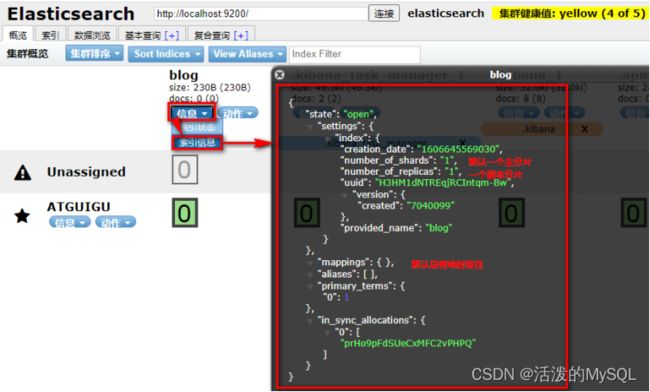
如果重复创建索引,会报错:

查看索引index
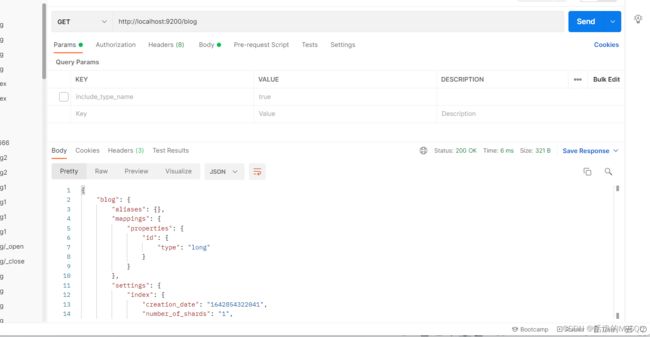
GET http://localhost:9200/blog
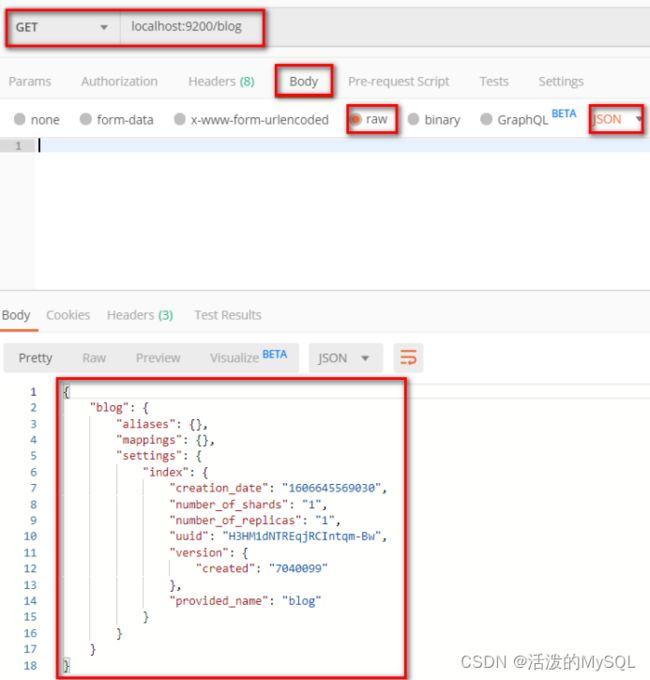
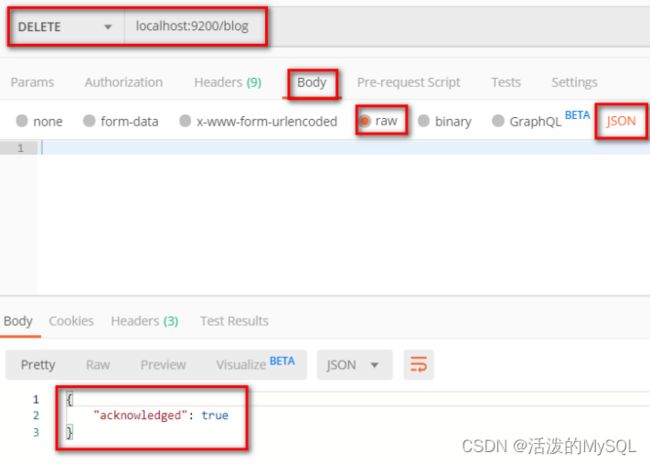
删除索引index
Delete http://localhost:9200/blog
关闭索引index
POST http://localhost:9200/blog/_close

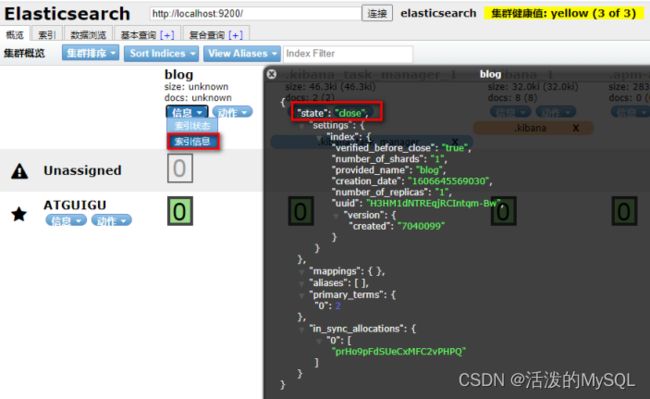
打开索引index
POST http://localhost:9200/blog/_open



创建索引index并且进行映射mapping
PUT http://localhost:9200/blog1

elasticsearch-head查看:

Kibanan操作
开启Kibanan
创建索引
PUT person查询索引
GET person删除索引
DELETE person查询映射
GET person/_mapping添加映射
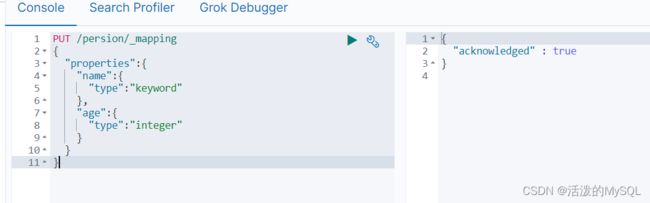
PUT person/_mapping
{
"properties":{
"name":{
"type":"keyword"
},
"age":{
"type":"integer"
}
}
}创建索引并添加映射
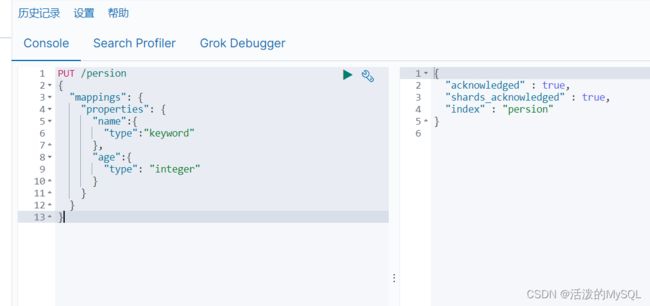
PUT person
{
"mappings": {
"properties": {
"name":{
"type": "keyword"
},
"age":{
"type":"integer"
}
}
}
}索引库中添加字段

PUT person/_mapping
{
"properties":{
"address":{
"type":"text"
}
}
}操作文档document【kibana演示】
• 添加文档
• 查询文档
• 修改文档
• 删除文档
# 查询索引
GET person添加文档,指定id
PUT person/_doc/1
{
"name":"张三",
"age":20,
"address":"深圳宝安区"
}查询文档
GET person/_doc/1添加文档,不指定id
POST person/_doc/
{
"name":"李四",
"age":20,
"address":"深圳南山区"
}查询文档
GET person/_doc/u8b2QHUBCR3n8iTZ8-Vk
# 添加文档,不指定id
POST person/_doc/
{
"name":"李四",
"age":20,
"address":"深圳南山区"
}查询文档
GET person/_doc/u8b2QHUBCR3n8iTZ8-Vk
查询所有文档
GET person/_search删除文档
DELETE person/_doc/1修改文档 根据id,id存在就是修改,id不存在就是添加
PUT person/_doc/2
{
"name":"硅谷",
"age":20,
"address":"深圳福田保税区"
}查询全部
GET person/_search全文查询-match查询
全文查询会分析查询条件,先将查询条件进行分词,然后查询,求并集(个人理解:会对查询的字符串分词,然后对比倒排索引)
# match 先会对查询的字符串进行分词,在查询,求交集
GET person/_search
{
"query": {
"match": {
"address": "深圳保税区"
}
}
}
查询文档-term查询
词条查询不会分析查询条件,只有当词条和查询字符串完全匹配时才匹配搜索(不会对查询字符串分词,只有相同的时候才匹配搜索)
# 查询 带某词条的数据
GET person/_search
{
"query": {
"term": {
"address": {
"value": "深圳南山区"
}
}
}
}貌似也可以这样写
GET /persion/_search
{
"query": {
"term": {
"address": "广"
}
}
}截图:
这个结果与使用的分词器有关。根据address字段,建立倒排索引时,需要对其分词,产生多个词条,而词条集合中没有"深圳南山区"的词条,故而查询不到数据。
大家可以查询“深”或“南山区”或“深圳”试试。

关键字搜索数据
# 查询名字等于张三的用户
GET person/_search?q=name:张三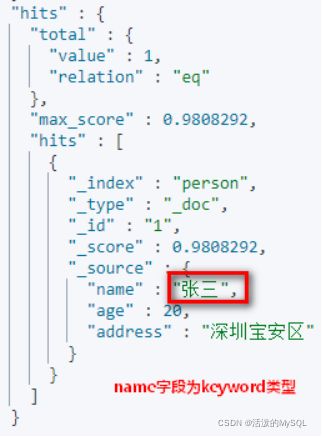
DSL 查询
url地址请求体,多添加几条数据,方便做查询
PUT shangguigu/_doc/1001
{
"id":"1001",
"name":"张三",
"age":20,
"sex":"男"
}
PUT shangguigu/_doc/1002
{
"id":"1002",
"name":"李四",
"age":25,
"sex":"女"
}
PUT shangguigu/_doc/1003
{
"id":"1003",
"name":"王五",
"age":30,
"sex":"女"
}
PUT shangguigu/_doc/1004
{
"id":"1004",
"name":"赵六",
"age":30,
"sex":"男"
}
添加结果: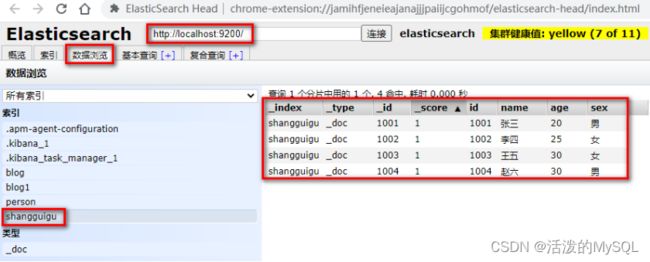
① 根据年龄查询
POST shangguigu/_doc/_search
{
"query":{
"match":{
"age":20
}
}
}请求结果:

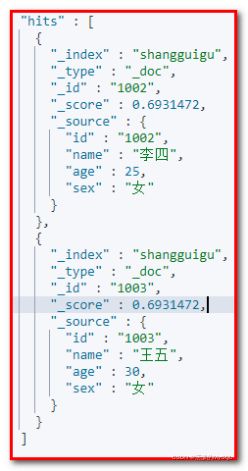
② 查询年龄大于20岁的女性用户相应结果:
GET shangguigu/_search
{
"query":{
"bool":{
"filter":{
"range":{
"age":{
"gt":20
}
}
},
"must":{
"match":{
"sex":"女"
}
}
}
}
}相应结果:
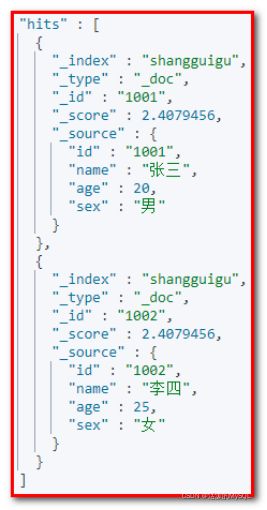
③ 全文搜索
请求URL地址
GET shangguigu/_search
{
"query":{
"match":{
"name": "张三 李四"
}
}
}响应数据
高亮显示
请求URL地址
请求体
GET shangguigu/_search
{
"query":{
"match":{
"name": "张三 李四"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}
聚合
在Elasticsearch中,支持聚合操作,类似SQL中的group by操作。
请求URL地址
请求体
GET shangguigu/_search
{
"aggs": {
"all_interests": {
"terms": {
"field": "age"
}
}
}
}响应体

如果聚合查询报错:
![]()
修改下查询语句
{
"aggs": {
"all_interests": {
"terms": {
"field": "age.keyword"
}
}
}
}指定响应字段
在响应的数据中,如果我们不需要全部的字段,可以指定某些需要的字段进行返回
GET shangguigu/_doc/1001?_source=id,name等价于
GET /shangguigu/_search
{
"query": {
"match": {
"id": "1001"
}
},
"_source": ["id","name"]
}
判断文档是否存在
如果我们只需要判断文档是否存在,而不是查询文档内容,那么可以这样:
HEAD /shangguigu/_doc/1001存在返回:200 - OK
不存在返回:404 – Not Found
批量操作
有些情况下可以通过批量操作以减少网络请求。如:批量查询、批量插入数据。
批量查询
请求体
POST shangguigu/_doc/_mget
{
"ids" : [ "1001", "1003" ]
}响应
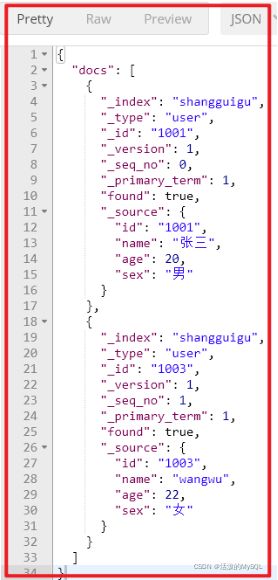
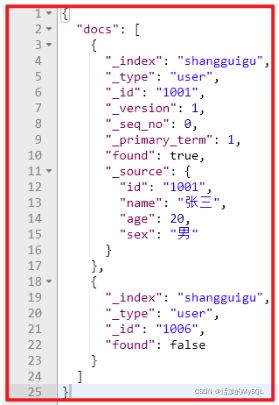
如果,某一条数据不存在,不影响整体响应,需要通过found的值进行判断是否查询到数据。
请求体:
{
"ids" : [ "1001", "1006" ]
}
_bulk操作
在Elasticsearch中,支持批量的插入、修改、删除操作,都是通过_bulk的api完成的。
请求格式如下:(请求格式不同寻常)
{ action: { metadata }}\n
{ request body }\n
{ action: { metadata }}\n
{ request body }\n
...
批量插入数据:
POST _bulk
{"create":{"_index":"atguigu","_id":2001}}
{"id":2001,"name":"name1","age": 20,"sex": "男"}
{"create":{"_index":"atguigu","_id":2002}}
{"id":2002,"name":"name2","age": 20,"sex": "男"}
{"create":{"_index":"atguigu","_id":2003}}
{"id":2003,"name":"name3","age": 20,"sex": "男"}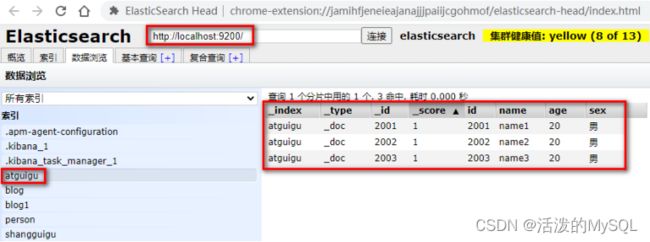
批量删除:
POST _bulk
{"delete":{"_index":"atguigu","_id":2001}}
{"delete":{"_index":"atguigu","_id":2002}}
{"delete":{"_index":"atguigu","_id":2003}}由于delete没有请求体,所以,action的下一行直接就是下一个action。
分页
SQL使用 LIMIT 关键字返回只有一页的结果一样,Elasticsearch接受 from 和 size 参数:
size: 结果数,默认10
from: 跳过开始的结果数,默认0
如果你想每页显示5个结果,页码从1到3,那请求如下:
GET /_search?size=5
GET /_search?size=5&from=5
GET /_search?size=5&from=10请求路径
GET shangguigu/_search?size=1&from=2响应体

POST atguigu/_bulk
{"index":{"_index":"atguigu"}}
{"name":"张三","age": 20,"mail": "[email protected]","hobby":"羽毛球、乒乓球、足球"}
{"index":{"_index":"atguigu"}}
{"name":"李四","age": 21,"mail": "[email protected]","hobby":"羽毛球、乒乓球、足球、篮球"}
{"index":{"_index":"atguigu"}}
{"name":"王五","age": 22,"mail": "[email protected]","hobby":"羽毛球、篮球、游泳、听音乐"}
{"index":{"_index":"atguigu"}}
{"name":"赵六","age": 23,"mail": "[email protected]","hobby":"跑步、游泳"}
{"index":{"_index":"atguigu"}}
{"name":"孙七","age": 24,"mail": "[email protected]","hobby":"听音乐、看电影"}测试搜索:
POST atguigu/_search
{
"query" : {
"match" : {
"hobby" : "音乐 羽毛球"
}
},
"from": 0,
"size": 2
}terms查询
terms 跟 term 有点类似,但 terms 允许指定多个匹配条件。 如果某个字段指定了多个值,那么文档需要一起去做匹配:
POST atguigu/_search
{
"query" : {
"terms" : {
"age" : [20,21]
}
}
}range查询
range 过滤允许我们按照指定范围查找一批数据:
范围操作符包含:
gt :: 大于
gte :: 大于等于
lt :: 小于
lte :: 小于等于
POST atguigu/_search
{
"query": {
"range": {
"age": {
"gte": 20,
"lte": 22
}
}
}
}exists 查询
exists 查询可以用于查找文档中是否包含指定字段或没有某个字段,类似于SQL语句中的 IS_NULL 条件
# "exists": 必须包含
POST atguigu/_search
{
"query": {
"exists": {
"field": "mail"
}
}
}